Introduzione
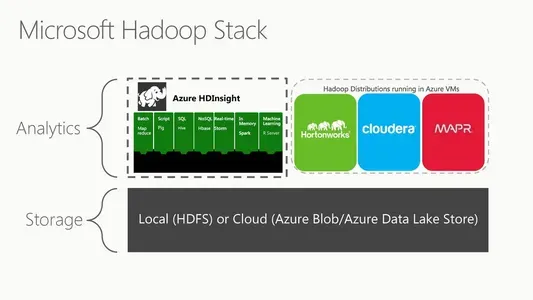
Microsoft Azure HDInsight (o Microsoft HDFS) è una versione del file system distribuito Hadoop basata su cloud. Un file system distribuito viene eseguito su hardware di base e gestisce enormi raccolte di dati. Si tratta di un ambiente basato su cloud completamente gestito per l'analisi e l'elaborazione di enormi volumi di dati. HDInsight funziona perfettamente con l'ecosistema Hadoop, che include tecnologie come MapReduce, Hive, Pig e Spark. È inoltre compatibile con le potenti tecnologie di elaborazione dei dati di Microsoft come Azure Data Lake Storage e Azure Blob Storage.
La scalabilità è una delle caratteristiche più essenziali di HDInsight. Microsoft Azure HDInsight include anche funzionalità di sicurezza a livello aziendale, tra cui il controllo degli accessi in base al ruolo, la crittografia e l'isolamento della rete. HDInsight si integra facilmente con gli altri servizi cloud di Microsoft, tra cui Power BI, Azure Stream Analytics e Azure Data Factory. Infine, è un servizio basato su cloud completamente gestito, il che significa che Microsoft è responsabile dell'infrastruttura, della manutenzione e degli aggiornamenti sottostanti.
obiettivi formativi
- Esamineremo Microsoft HDFS e come funziona in un contesto di dati significativo.
- Comprendere come utilizzare Azure HDInsight nel cloud per gestire e analizzare enormi volumi di dati
- Esamineremo gli strumenti Hadoop come MapReduce, Hive e Spark e come possono essere utilizzati con HDInsight.
- Scoprirai anche le funzioni dei diversi nodi in HDInsight.
Questo articolo è stato pubblicato come parte di Blogathon sulla scienza dei dati.
Sommario
HDInsight di Azure è una soluzione cloud completamente gestita che esegue importanti tecnologie di elaborazione dei dati come Apache Hadoop e Apache Spark. È un'implementazione Hadoop basata su cloud per l'elaborazione e l'analisi di dati su larga scala in un sistema distribuito. Hadoop è un framework software disponibile gratuitamente per la condivisione di enormi set di dati tra i nodi di elaborazione. Svolge un ruolo cruciale nell'intera infrastruttura Hadoop. Si tratta di un file system distribuito che memorizza i dati delle applicazioni su server a basso costo in diverse posizioni, rendendoli accessibili ad alta velocità. L'architettura master/slave di HDFS garantisce che anche i set di dati più grandi possano essere archiviati e gestiti senza alcuna perdita di integrità o prestazioni.
Il file system distribuito di HDInsight è HDFS. Quando gli utenti inviano attività a HDInsight, i dati vengono distribuiti automaticamente tra i nodi del cluster e salvati in HDFS. HDInsight include anche altri componenti dell'ecosistema Hadoop come MapReduce, Hive, Pig e Spark per l'elaborazione e l'analisi dei dati in HDFS. HDInsight è una piattaforma basata su cloud che consente ai clienti di sfruttare le funzionalità di Hadoop e dei suoi prodotti dell'ecosistema senza richiedere la gestione dell'infrastruttura sottostante. Utilizza HDFS come file system per facilitare l'archiviazione e l'elaborazione distribuita dei dati.
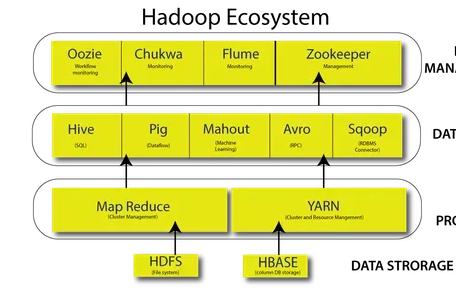
Fonte: http://www.hkrtrainings.com
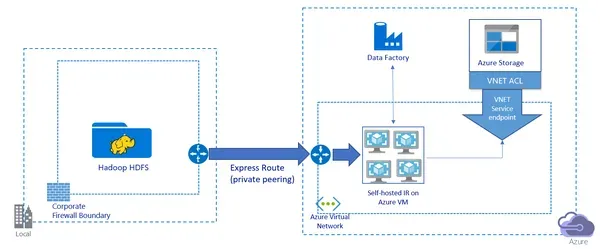
D2. Come funziona Microsoft Azure Data Lake Storage Gen2 con HDFS?
Archiviazione Microsoft Azure Data Lake Gen2 è una soluzione di archiviazione basata su cloud con un file system gerarchico per l'archiviazione e l'analisi di enormi volumi di dati. Ha lo scopo di interagire con piattaforme di elaborazione dati di grandi dimensioni come Hadoop e Spark e si interfaccia agevolmente con HDFS. Azure Data Lake Storage Gen2 include un'interfaccia HCFS (Hadoop Compatible File System), che consente ad Hadoop e ad altri strumenti di elaborazione di Big Data di accedere ai dati in Data Lake Storage Gen2 come se fossero in HDFS. I clienti possono gestire e analizzare i dati archiviati in Data Lake Storage Gen2 utilizzando gli strumenti e le applicazioni Hadoop esistenti.
Quando i processi Hadoop vengono eseguiti in HDInsight, i dati vengono distribuiti automaticamente tra i nodi del cluster e archiviati in HDFS. Tuttavia, Azure Data Lake Storage Gen2 può archiviare i dati direttamente nell'account di archiviazione senza creare una raccolta HDInsight. È quindi possibile accedere a questi dati utilizzando l'interfaccia HCFS, che fornisce le stesse funzionalità di HDFS. Azure Data Lake Storage Gen2 offre anche funzionalità avanzate come l'integrazione dell'archiviazione BLOB di Azure, l'integrazione di Azure Active Directory e funzionalità di sicurezza di livello aziendale come il controllo degli accessi in base al ruolo e la crittografia. Nel complesso, Data Lake Storage Gen2 offre una soluzione di archiviazione scalabile e sicura per l'elaborazione e l'analisi di big data e si integra perfettamente con Hadoop e HDFS.
D3. Puoi spiegare il ruolo di NameNode e DataNode in HDFS?
I componenti NameNode e DataNode di HDFS creano un ambiente di archiviazione ed elaborazione distribuito per enormi set di dati. Ecco come funzionano:
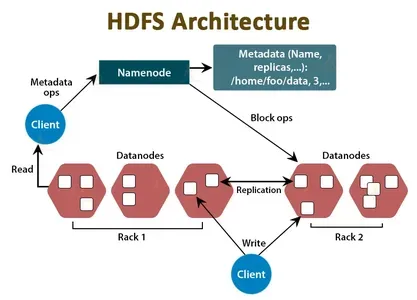
- NomeNodo: Il NameNode funge da coordinatore centrale e archivio di metadati del cluster HDFS. Mantiene le informazioni sulle posizioni dei file, la gerarchia e le proprietà di file e directory. Il NameNode memorizza queste informazioni in memoria e su disco ed è responsabile della gestione dell'accesso ai dati HDFS. Quando un'applicazione client deve leggere o scrivere dati da HDFS, contatta innanzitutto il NameNode per recuperare la posizione dei dati e altre informazioni.
- Nodo dati: Il DataNode è il cavallo di battaglia di HDFS. È responsabile della memorizzazione dei blocchi di dati che compongono i file in HDFS. Ogni DataNode gestisce l'archiviazione per un sottoinsieme dei dati nel cluster HDFS e duplica i dati in altri DataNode per la ridondanza e la tolleranza ai guasti. Quando un'applicazione client deve leggere o scrivere dati, dialoga direttamente con i nodi di dati che contengono i blocchi di dati.
In sintesi, NameNode e DataNode collaborano per produrre un file system distribuito in grado di archiviare ed elaborare enormi set di dati. Il NameNode gestisce le informazioni sui file, mentre i DataNode contengono i blocchi di dati effettivi. Per fornire ridondanza dei dati, tolleranza agli errori e recupero rapido dei dati, NameNode e DataNode interagiscono tra loro.
D4. In che modo HDFS garantisce l'affidabilità dei dati e la tolleranza ai guasti?
Ha lo scopo di offrire storage con tolleranza ai guasti per enormi set di dati. Lo fa duplicando i dati su diversi nodi del cluster, rilevando e ripristinando i guasti e mantenendo l'affidabilità e l'accuratezza dell'archiviazione dei dati. HDFS garantisce l'affidabilità dei dati e la tolleranza ai guasti nei seguenti modi:
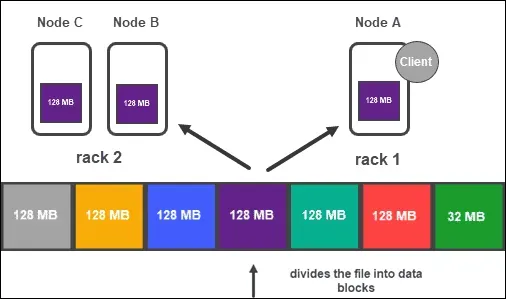
- Memorizza i dati in blocchi duplicati su diversi nodi di dati nel cluster. Ogni blocco viene replicato tre volte per impostazione predefinita, sebbene ciò possa essere modificato in base alle esigenze dell'applicazione. La replica dei dati su più nodi garantisce che i dati siano disponibili su altri nodi anche se uno o più falliscono.
- Rilevamento e ripristino degli errori: HDFS controlla continuamente l'integrità dei nodi di dati del cluster. Ogni volta che un DataNode ha esito negativo o non risponde, il NameNode rileva l'errore e duplica i dati del nodo in errore su altri nodi nel cluster. Il NameNode quindi aggiorna i metadati per riflettere le nuove posizioni dei blocchi di dati replicati.
- Coerenza dei dati: utilizzando un'architettura WORM (write-once-read-many), HDFS assicura che i dati vengano salvati in modo affidabile e preciso. I dati che sono stati scritti su HDFS non possono essere modificati. Ciò garantisce che la coerenza dei dati venga mantenuta anche quando numerosi client accedono contemporaneamente agli stessi dati.
- Posizionamento dei blocchi: per garantire che i blocchi di dati vengano posizionati su rack distinti nel cluster, HDFS utilizza una strategia di posizionamento basata sul rack. Ciò garantisce che, anche in caso di guasto di un intero frame, i dati siano ancora accessibili sugli altri rack del cluster.
Nel complesso, duplicando i dati su diversi nodi, rilevando e ripristinando i guasti, garantendo la coerenza dei dati e impiegando una politica di posizionamento compatibile con il rack per ridurre la perdita di dati dovuta a guasti del rack, HDFS fornisce una soluzione di archiviazione affidabile e tollerante ai guasti per enormi set di dati.
Q5. Puoi descrivere quali sono i ruoli NameNode e DataNode in HDFS?
HDFS è un file system distribuito che archivia e gestisce enormi set di dati su hardware di base in un cluster. Come spiegato nella domanda precedente, l'architettura HDFS comprende due componenti chiave: NameNode e DataNode. Per fornire affidabilità dei dati e tolleranza agli errori, NameNode e DataNode interagiscono. Quando un client deve leggere o scrivere dati da HDFS, dialoga con NameNode per trovare i blocchi di dati. Il client discute quindi direttamente con i DataNode per leggere o scrivere blocchi di dati.
MapReduce, un framework di elaborazione dati distribuito, è spesso combinato con HDFS. MapReduce ha lo scopo di gestire grandi set di dati dividendoli in parti più piccole, distribuendo l'elaborazione di quei blocchi su un cluster di processori e aggregando i risultati. Ecco come MapReduce interagisce con HDFS:
- I dati di input vengono salvati in HDFS. MapReduce riceve i dati di input da HDFS e li divide in blocchi più piccoli chiamati input split.
- Le divisioni di input vengono distribuite nel cluster e assegnate a specifici processi di mappatura utilizzando MapReduce. Ogni processo Map gestisce una singola divisione di input e produce coppie chiave-valore intermedie.
- Le coppie chiave-valore intermedie vengono quindi ordinate e mescolate prima di essere inviate ai lavori di riduzione. Ogni job Riduci raccoglie input intermedi e genera il risultato finale.
- Il risultato finale viene salvato in HDFS.
Nel complesso, HDFS e MapReduce collaborano per creare un'architettura scalabile e tollerante ai guasti per l'elaborazione di enormi set di dati. Offre un'archiviazione affidabile per i dati di input e output, mentre MapReduce diffonde l'elaborazione dei dati in tutto il cluster.
D6.Cosa rende HDFS diverso dagli altri file system e quali sono i vantaggi dell'utilizzo di HDFS in un enorme ambiente di dati?
HDFS varia dai file system standard in numerose aree cruciali e queste distinzioni apportano numerosi vantaggi quando si lavora con enormi quantità di dati. Queste sono alcune importanti distinzioni e vantaggi dell'utilizzo di HDFS in un ambiente di dati di grandi dimensioni:
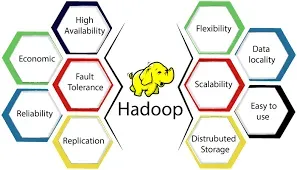
- Scalabilità: i file system convenzionali non sono progettati per gestire le enormi quantità di dati che sono frequenti nelle situazioni di big data. È progettato per crescere orizzontalmente, il che significa che può contenere petabyte o addirittura exabyte di archiviazione ed elaborazione dei dati distribuendo i dati su un cluster di hardware di base.
- Tolleranza ai guasti: è progettato per essere tollerante ai guasti. Può sopportare l'errore di singoli nodi nel cluster duplicando i dati su diversi nodi del cluster. Dispone inoltre di tecniche per rilevare e ripristinare automaticamente i guasti dei nodi.
- È pensato per avere un throughput elevato sia per la lettura che per la scrittura di dati. Mentre si lavora con file di grandi dimensioni, HDFS può raggiungere velocità di lettura e scrittura elevate poiché è specializzato per trasferimenti di dati massicci.
- Località dei dati: è progettato per massimizzare la località dei dati, il che significa che i dati vengono archiviati ed elaborati sugli stessi nodi del cluster, ove possibile. La riduzione del transito dei dati sulla rete riduce al minimo il traffico di rete e aumenta le prestazioni.
- Economicità: poiché è progettato per essere eseguito su hardware di base, può essere implementato su server a basso costo o nel cloud. Di conseguenza, fornisce un'opzione a basso costo per l'archiviazione e l'elaborazione di enormi volumi di dati.
Nel complesso, i vantaggi dell'utilizzo di HDFS in un contesto di big data sono la scalabilità, la tolleranza ai guasti, l'elevato throughput, la localizzazione dei dati e l'economicità. Sfruttando queste funzionalità, le organizzazioni possono archiviare, gestire e analizzare enormi set di dati in modo più efficiente ed economico rispetto ai file system tradizionali.
Conclusione
In questo articolo sono state esaminate diverse funzionalità di Microsoft HDFS, tra cui l'introduzione, l'architettura, l'utilizzo di Azure Data Lake Storage Gen2 e la sua funzione in MapReduce. Abbiamo anche risposto a domande comuni di intervista sia nelle configurazioni di Amazon che di Microsoft. È importante per le applicazioni di big data perché fornisce storage scalabile e con tolleranza ai guasti per set di dati di grandi dimensioni. Comprendere la progettazione e il funzionamento è essenziale per i data engineer e gli sviluppatori che lavorano con soluzioni per Big Data.
Ecco alcuni punti chiave da asporto:
- È un file system distribuito che archivia e gestisce enormi set di dati su hardware di base in un cluster.
- Il NameNode e il DataNode sono i due componenti fondamentali di HDFS. Il NameNode mantiene le informazioni del file system, mentre il DataNode memorizza i blocchi di dati effettivi che comprendono i file.
- È progettato per essere estremamente tollerante ai guasti e per fornire uno storage affidabile per le applicazioni di big data. Può contenere petabyte o addirittura exabyte di archiviazione ed elaborazione dei dati distribuendo i dati su un cluster di computer di base.
- MapReduce, un framework di elaborazione dati distribuito, può essere utilizzato in combinazione con HDFS. MapReduce divide enormi set di dati in bit più piccoli e distribuisce la loro elaborazione su un cluster di processori.
- Infine, Microsoft fornisce HDInsight, una distribuzione Hadoop basata su cloud contenente HDFS, MapReduce e altri componenti.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
Leggi Anche
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/03/top-6-microsoft-hdfs-interview-questions/
- :È
- $ SU
- a
- WRI
- accesso
- accessibile
- accessibile
- ospitare
- Il mio account
- precisione
- Raggiungere
- operanti in
- attivo
- Active Directory
- Avanzate
- vantaggi
- Consentire
- Sebbene il
- Amazon
- tra
- importi
- .
- analitica
- Analisi Vidhya
- analizzare
- l'analisi
- ed
- Un altro
- Apache
- Apache Spark
- Applicazioni
- applicazioni
- architettura
- SONO
- aree
- articolo
- AS
- addetto
- At
- automaticamente
- disponibile
- azzurro
- basato
- BE
- perché
- diventa
- prima
- essendo
- vantaggi
- Big
- Big Data
- Bloccare
- Blocchi
- blogathon
- portare
- costruito
- by
- detto
- Materiale
- non può
- funzionalità
- capace
- centrale
- caratteristiche
- carica
- Controlli
- cliente
- clienti
- Cloud
- servizi cloud
- Cluster
- collaboreranno
- collezione
- collezioni
- raccoglie
- COM
- combinazione
- combinato
- merce
- Uncommon
- compatibile
- componenti
- computer
- informatica
- conclusione
- contatti
- contesto
- continuamente
- di controllo
- convenzionale
- dell'esame
- creare
- Creazione
- cruciale
- Clienti
- dati
- Lago di dati
- Perdita di dati
- elaborazione dati
- memorizzazione dei dati
- dataset
- Predefinito
- affidabile
- descrivere
- Design
- progettato
- rivelazione
- sviluppatori
- diverso
- direttamente
- discrezione
- dispersi
- distinto
- distribuito
- elaborazione dati distribuita
- distribuzione
- distribuzione
- duplicati
- ogni
- ecosistema
- in modo efficiente
- impiega
- Abilita
- crittografia
- Ingegneri
- enorme
- garantire
- assicura
- di livello enterprise
- di livello enterprise
- Intero
- Ambiente
- essential
- Anche
- di preciso
- esistente
- Spiegare
- ha spiegato
- estremamente
- facilitare
- fabbrica
- fallito
- fallisce
- Fallimento
- FAST
- fattibile
- Caratteristiche
- Compila il
- File
- finale
- Infine
- Trovate
- Nome
- i seguenti
- Nel
- TELAIO
- Contesto
- frequente
- frequentemente
- da
- completamente
- function
- funzionalità
- funzioni
- fondamentale
- genera
- Crescere
- di garanzia
- garanzie
- Hadoop
- maniglia
- Maniglie
- Hardware
- Avere
- Salute e benessere
- qui
- gerarchia
- Alta
- Alveare
- tenere
- Come
- Tutorial
- Tuttavia
- HTTPS
- Enorme
- implementazione
- implementato
- importante
- in
- inclusi
- Compreso
- Aumenta
- individuale
- poco costoso
- informazioni
- Infrastruttura
- ingresso
- Integra
- integrazione
- interezza
- interagire
- interagisce
- Interfaccia
- interfacce
- Intermedio
- Colloquio
- Domande di un'intervista
- Introduzione
- da solo
- IT
- SUO
- Lavoro
- Offerte di lavoro
- Le
- lago
- grandi
- IMPARARE
- Leva
- piace
- Localizzazione
- località
- posizioni
- spento
- a basso costo
- mantiene
- manutenzione
- make
- FA
- Fare
- gestire
- gestito
- gestione
- gestisce
- gestione
- carta geografica
- massiccio
- Massimizzare
- si intende
- Media
- Memorie
- Metadati
- Microsoft
- Microsoft Azure
- Scopri di più
- maggior parte
- nav
- esigenze
- Rete
- traffico di rete
- New
- nodo
- nodi
- numerose
- of
- offrire
- Offerte
- on
- ONE
- operazione
- Opzione
- organizzazioni
- Altro
- complessivo
- Di proprietà
- coppie
- parte
- performance
- pezzi
- piattaforma
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- punti
- politica
- energia
- Power BI
- potente
- precisamente
- lavorazione
- processori
- produrre
- Prodotti
- proprietà
- fornire
- fornisce
- pubblicato
- Q2
- Q3
- domanda
- Domande
- veloce
- Leggi
- Lettura
- riceve
- recupero
- recupero
- ridurre
- riducendo
- riflettere
- relazionato
- rapporto
- problemi di
- replicato
- replicazione
- responsabile
- colpevole
- Risultati
- recensioni
- Ruolo
- ruoli
- Correre
- running
- stesso
- Scalabilità
- scalabile
- Scienze
- senza soluzione di continuità
- sicuro
- problemi di
- Server
- serve
- servizio
- Servizi
- alcuni
- compartecipazione
- mostrato
- significativa
- contemporaneamente
- da
- singolo
- situazioni
- inferiore
- liscio
- Software
- soluzione
- Soluzioni
- alcuni
- Fonte
- Scintilla
- specializzata
- specifico
- velocità
- dividere
- Si divide
- Diffondere
- spread
- Standard
- Ancora
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- Strategia
- ruscello
- inviare
- tale
- SOMMARIO
- sistema
- SISTEMI DI TRATTAMENTO
- trattativa
- task
- tecniche
- Tecnologie
- che
- Il
- loro
- Li
- Strumenti Bowman per analizzare le seguenti finiture:
- tre
- Attraverso
- per tutto
- portata
- volte
- a
- tolleranza
- strumenti
- top
- tradizionale
- traffico
- trasferimenti
- transito
- sottostante
- e una comprensione reciproca
- Aggiornamenti
- Upgrades
- utenti
- utilizzare
- utilizzati
- Utilizzando
- versione
- volumi
- modi
- Che
- quale
- while
- volere
- con
- senza
- Lavora
- lavoro
- lavori
- verme
- scrivere
- scrittura
- scritto
- zefiro