Oggi siamo lieti di annunciarlo Amazon DataZone è ora in grado di presentare informazioni sulla qualità dei dati per le risorse di dati. Queste informazioni consentono agli utenti finali di prendere decisioni informate sull'opportunità o meno di utilizzare risorse specifiche.
Molte organizzazioni già utilizzano Qualità dei dati di AWS Glue definire e applicare norme sulla qualità dei dati sui propri dati, convalidare i dati rispetto a regole predefinite, tenere traccia delle metriche sulla qualità dei dati e monitorare la qualità dei dati nel tempo utilizzando l’intelligenza artificiale (AI). Altre organizzazioni monitorano la qualità dei propri dati tramite soluzioni di terze parti.
Amazon DataZone ora si integra direttamente con AWS Glue per visualizzare i punteggi di qualità dei dati per le risorse del catalogo dati di AWS Glue. Inoltre, Amazon DataZone ora offre API per importare punteggi di qualità dei dati da sistemi esterni.
In questo post, discutiamo delle ultime funzionalità di Amazon DataZone per la qualità dei dati, dell'integrazione tra Amazon DataZone e AWS Glue Data Quality e di come importare punteggi di qualità dei dati prodotti da sistemi esterni in Amazon DataZone tramite API.
Le sfide
Una delle domande più comuni che riceviamo dai clienti è relativa alla visualizzazione dei punteggi di qualità dei dati nel file Catalogo dei dati aziendali di Amazon DataZone per consentire agli utenti aziendali di avere visibilità sullo stato e sull'affidabilità dei set di dati.
Poiché i dati diventano sempre più cruciali per guidare le decisioni aziendali, gli utenti di Amazon DataZone sono fortemente interessati a fornire i più elevati standard di qualità dei dati. Riconoscono l'importanza di dati accurati, completi e tempestivi nel consentire un processo decisionale informato e nel promuovere la fiducia nei loro processi di analisi e reporting.
Le risorse dati di Amazon DataZone possono essere aggiornate a frequenze diverse. Man mano che i dati vengono aggiornati, possono verificarsi modifiche attraverso processi a monte che li mettono a rischio di non mantenere la qualità prevista. I punteggi di qualità dei dati ti aiutano a capire se i dati hanno mantenuto il livello di qualità previsto per l'utilizzo da parte dei consumatori di dati (attraverso l'analisi o processi a valle).
Dal punto di vista del produttore, gli steward dei dati possono ora configurare Amazon DataZone per importare automaticamente i punteggi di qualità dei dati da AWS Glue Data Quality (programmato o su richiesta) e includere queste informazioni nel catalogo Amazon DataZone per condividerle con gli utenti aziendali. Inoltre, ora puoi utilizzare le nuove API Amazon DataZone per importare punteggi di qualità dei dati prodotti da sistemi esterni nelle risorse di dati.
Con l'ultimo miglioramento, gli utenti di Amazon DataZone possono ora realizzare quanto segue:
- Accedi a informazioni dettagliate sugli standard di qualità dei dati direttamente dal portale Web Amazon DataZone
- Visualizza i punteggi di qualità dei dati su vari KPI, tra cui completezza, unicità e accuratezza dei dati
- Assicurati che gli utenti abbiano una visione olistica della qualità e dell'affidabilità dei loro dati.
Nella prima parte di questo post, esaminiamo l'integrazione tra AWS Glue Data Quality e Amazon DataZone. Parleremo di come visualizzare i punteggi di qualità dei dati in Amazon DataZone, abilitare AWS Glue Data Quality durante la creazione di una nuova origine dati Amazon DataZone e abilitare la qualità dei dati per un asset di dati esistente.
Nella seconda parte di questo post, discuteremo di come importare i punteggi di qualità dei dati prodotti da sistemi esterni in Amazon DataZone tramite API. In questo esempio utilizziamo Amazon EMR senza server in combinazione con la libreria open source Pydeequ fungere da sistema esterno per la qualità dei dati.
Visualizza i punteggi di qualità dei dati di AWS Glue in Amazon DataZone
Ora puoi visualizzare i punteggi di qualità dei dati di AWS Glue negli asset di dati che sono stati pubblicati nel catalogo aziendale di Amazon DataZone e che sono ricercabili tramite il portale Web di Amazon DataZone.
Se per l'asset è abilitato AWS Glue Data Quality, ora puoi visualizzare rapidamente il punteggio di qualità dei dati direttamente nel riquadro di ricerca del catalogo.
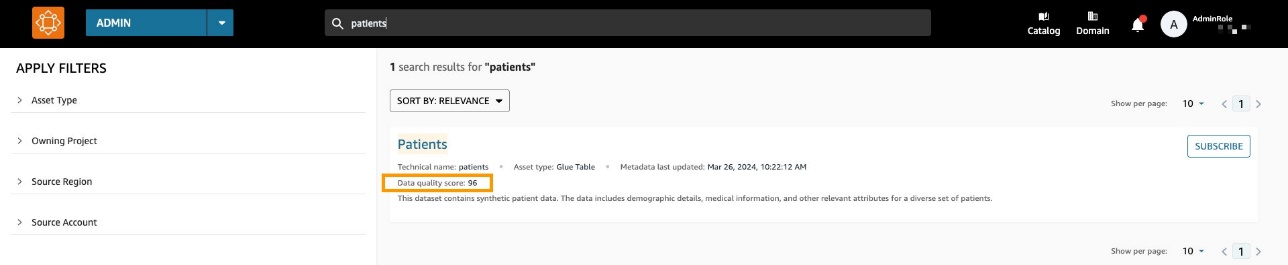
Selezionando la risorsa corrispondente è possibile comprenderne il contenuto tramite il file readme, termini del glossarioe metadati tecnici e aziendali. Inoltre, l'indicatore del punteggio di qualità complessivo viene visualizzato nel file Dettagli asset .

Un punteggio di qualità dei dati funge da indicatore generale della qualità di un set di dati, calcolato in base alle regole definite.
Sulla Qualità dei dati scheda, è possibile accedere ai dettagli degli indicatori di panoramica della qualità dei dati e ai risultati delle esecuzioni della qualità dei dati.

Gli indicatori mostrati sul Panoramica vengono calcolati in base ai risultati dei set di regole delle esecuzioni della qualità dei dati.
Ad ogni regola viene assegnato un attributo che concorre al calcolo dell'indicatore. Ad esempio, le regole che hanno l'estensione Completeness contribuirà al calcolo dell'indicatore corrispondente sul Panoramica scheda.
Per filtrare i risultati sulla qualità dei dati, scegli il file Colonna applicabile menu a discesa e scegli il parametro di filtro desiderato.

Puoi anche visualizzare la qualità dei dati a livello di colonna a partire da Schema scheda.

Quando la qualità dei dati è abilitata per la risorsa, i risultati della qualità dei dati diventano disponibili, fornendo punteggi di qualità approfonditi che riflettono l'integrità e l'affidabilità di ciascuna colonna all'interno del set di dati.
Quando scegli uno dei link dei risultati sulla qualità dei dati, vieni reindirizzato alla pagina dei dettagli della qualità dei dati, filtrata in base alla colonna selezionata.

Risultati storici sulla qualità dei dati in Amazon DataZone
La qualità dei dati può cambiare nel tempo per molte ragioni:
- I formati dei dati possono cambiare a causa di cambiamenti nei sistemi di origine
- Man mano che i dati si accumulano nel tempo, potrebbero diventare obsoleti o incoerenti
- La qualità dei dati può essere influenzata da errori umani nell'immissione, nell'elaborazione o nella manipolazione dei dati
In Amazon DataZone, ora puoi monitorare la qualità dei dati nel tempo per confermarne l'affidabilità e l'accuratezza. Analizzando l'istantanea del report storico, è possibile identificare le aree di miglioramento, implementare modifiche e misurare l'efficacia di tali modifiche.

Abilita AWS Glue Data Quality durante la creazione di una nuova origine dati Amazon DataZone
In questa sezione, esaminiamo i passaggi per abilitare AWS Glue Data Quality durante la creazione di una nuova origine dati Amazon DataZone.
Prerequisiti
Per proseguire, dovresti avere un dominio per Amazon DataZone, un progetto Amazon DataZone e un nuovo Ambiente Amazon DataZone (con un DataLakeProfile). Per istruzioni, fare riferimento a Avvio rapido di Amazon DataZone con i dati di AWS Glue.
È inoltre necessario definire ed eseguire un set di regole sui dati, ovvero un insieme di regole sulla qualità dei dati in AWS Glue Data Quality. Per impostare le regole sulla qualità dei dati e per ulteriori informazioni sull'argomento, fare riferimento ai seguenti post:
Dopo aver creato le regole sulla qualità dei dati, assicurati che Amazon DataZone disponga delle autorizzazioni per accedere al database AWS Glue gestito Formazione AWS Lake. Per istruzioni, vedere Configura le autorizzazioni Lake Formation per Amazon DataZone.
Nel nostro esempio, abbiamo configurato un set di regole rispetto a una tabella contenente i dati del paziente all'interno di un file set di dati sintetici sanitari generato utilizzando Sintea. Synthea è un generatore sintetico di pazienti che crea dati pazienti realistici e cartelle cliniche associate che possono essere utilizzate per testare applicazioni software sanitarie.
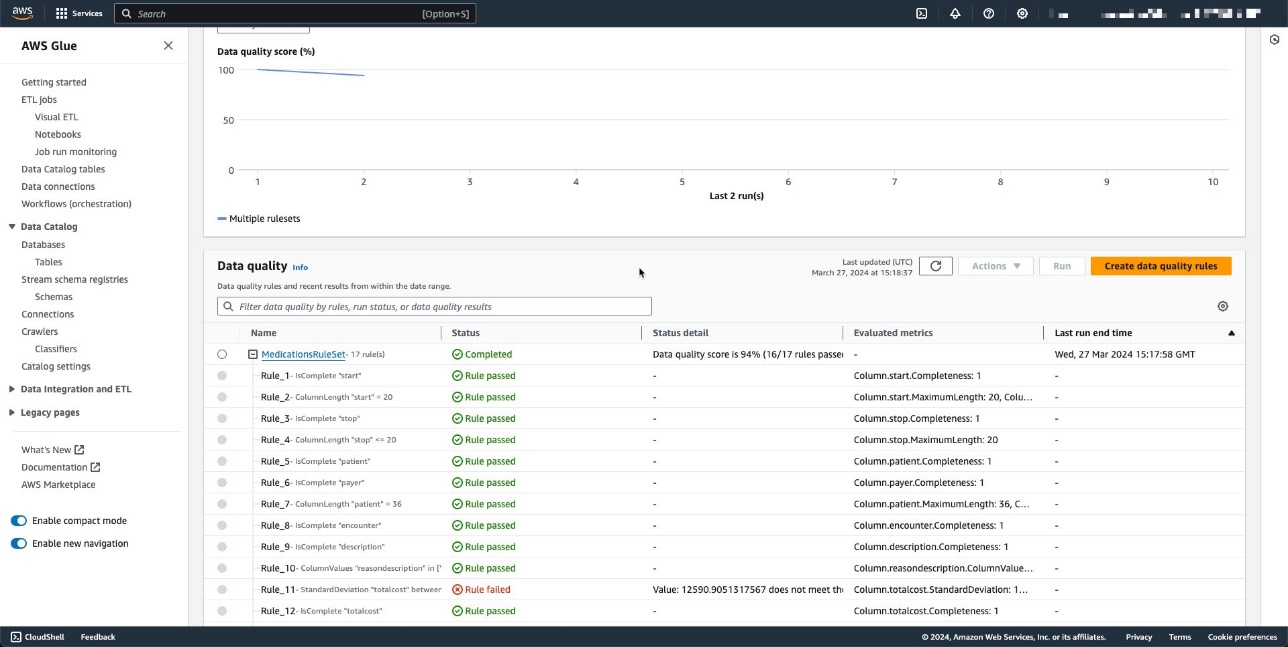
Il set di regole contiene 27 regole individuali (una delle quali fallisce), quindi il punteggio complessivo sulla qualità dei dati è del 96%.

Se utilizzi policy gestite di Amazon DataZone, non è necessaria alcuna azione perché queste verranno aggiornate automaticamente con le azioni necessarie. Altrimenti, devi consentire ad Amazon DataZone di disporre delle autorizzazioni necessarie per elencare e ottenere risultati di qualità dei dati di AWS Glue, come mostrato nella figura Guida per l'utente di Amazon DataZone.
Crea un'origine dati con la qualità dei dati abilitata
In questa sezione creiamo un'origine dati e abilitiamo la qualità dei dati. Puoi anche aggiornare un'origine dati esistente per abilitare la qualità dei dati. Utilizziamo questa origine dati per importare informazioni sui metadati relativi ai nostri set di dati. Amazon DataZone importerà anche informazioni sulla qualità dei dati relative alle (una o più) risorse contenute nell'origine dati.
- Nella console Amazon DataZone, scegli Fonti dei dati nel pannello di navigazione.
- Scegli Crea origine dati.

- Nel Nome, inserisci un nome per l'origine dati.
- Nel Tipo di origine dati, selezionare Colla AWS.
- Nel Ambiente, scegli il tuo ambiente.

- Nel Nome del database, immettere un nome per il database.
- Nel Criteri di selezione della tabella, scegli i tuoi criteri.
- Scegli Avanti.

- Nel Qualità dei dati, selezionare Abilita la qualità dei dati per questa origine dati.
Se la qualità dei dati è abilitata, Amazon DataZone recupererà automaticamente i punteggi di qualità dei dati da AWS Glue a ogni esecuzione dell'origine dati.
- Scegli Avanti.

Ora puoi eseguire l'origine dati.

Durante l'esecuzione dell'origine dati, Amazon DataZone importa gli ultimi 100 risultati di esecuzione di AWS Glue Data Quality. Queste informazioni sono ora visibili nella pagina della risorsa e saranno visibili a tutti gli utenti Amazon DataZone dopo la pubblicazione della risorsa.

Abilita la qualità dei dati per un asset di dati esistente
In questa sezione abilitiamo la qualità dei dati per una risorsa esistente. Ciò potrebbe essere utile per gli utenti che dispongono già di origini dati e desiderano abilitare la funzionalità in un secondo momento.
Prerequisiti
Per proseguire, dovresti aver già eseguito l'origine dati e prodotto un asset di dati della tabella AWS Glue. Inoltre, dovresti aver definito un set di regole in AWS Glue Data Quality sulla tabella di destinazione nel Catalogo dati.

Per questo esempio, abbiamo eseguito il processo di qualità dei dati più volte rispetto alla tabella, producendo i relativi punteggi di qualità dei dati di AWS Glue, come mostrato nello screenshot seguente.
Importa i punteggi di qualità dei dati nell'asset di dati
Completa la procedura seguente per importare i punteggi di qualità dei dati AWS Glue esistenti nell'asset di dati in Amazon DataZone:
- All'interno del progetto Amazon DataZone, vai al file Dati di inventario riquadro e scegli l'origine dati.
Se si sceglie la Qualità dei dati scheda, puoi vedere che non sono ancora disponibili informazioni sulla qualità dei dati perché l'integrazione di AWS Glue Data Quality non è ancora abilitata per questo asset di dati.
- Sulla Qualità dei dati scheda, scegliere Abilita la qualità dei dati.

- Nel Qualità dei dati sezione, selezionare Abilita la qualità dei dati per questa origine dati.
- Scegli Risparmi.

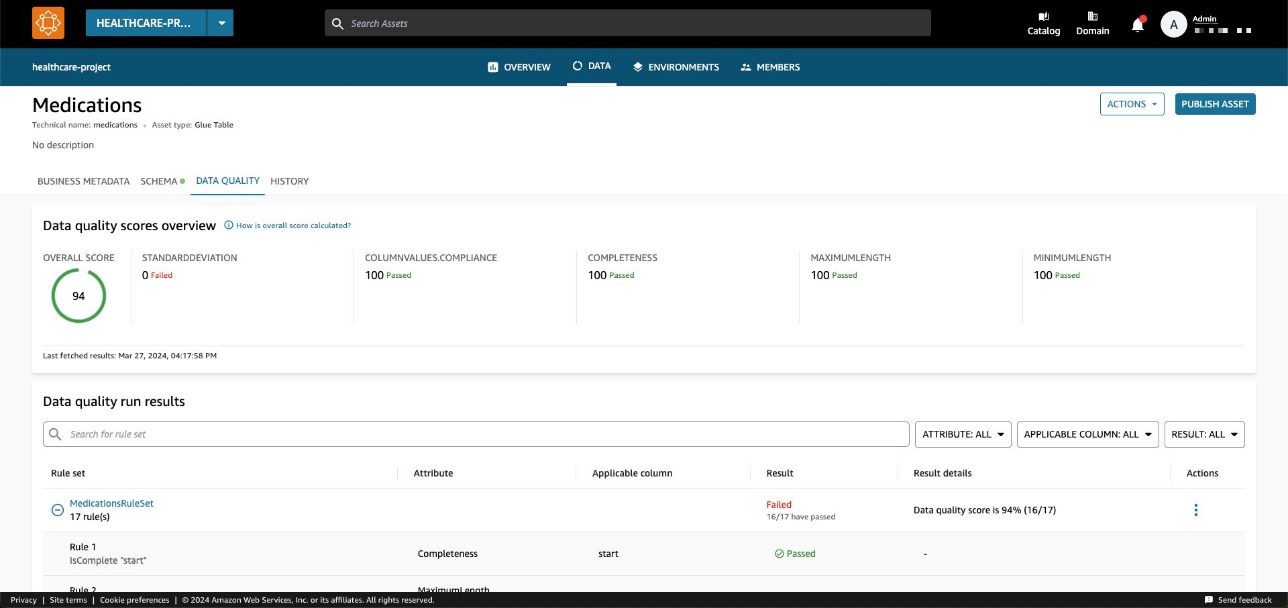
Ora, tornando al riquadro Dati inventario, puoi vedere una nuova scheda: Qualità dei dati.

Sulla Qualità dei dati scheda, puoi visualizzare i punteggi di qualità dei dati importati da AWS Glue Data Quality.
Acquisisci punteggi di qualità dei dati da una fonte esterna utilizzando le API Amazon DataZone
Molte organizzazioni utilizzano già sistemi che calcolano la qualità dei dati eseguendo test e asserzioni sui propri set di dati. Amazon DataZone ora supporta l'importazione di punteggi di qualità dei dati originati da terze parti tramite API, consentendo agli utenti che navigano nel portale web di visualizzare queste informazioni.
In questa sezione simuliamo un sistema di terze parti che inserisce i punteggi di qualità dei dati in Amazon DataZone tramite API Boto3 (SDK Python per AWS).
Per questo esempio usiamo lo stesso set di dati sintetici come prima, generato con Sintea.
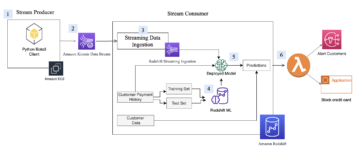
Il diagramma seguente illustra l'architettura della soluzione.

Il flusso di lavoro è costituito dai seguenti passaggi:
- Leggere un set di dati di pazienti in Servizio di archiviazione semplice Amazon (Amazon S3) direttamente da Amazon EMR utilizzando Spark.
Il set di dati viene creato come raccolta di risorse S3 generica in Amazon DataZone.

- In Amazon EMR, esegui regole di convalida dei dati rispetto al set di dati.
- I parametri vengono salvati in Amazon S3 per avere un output persistente.
- Utilizza le API Amazon DataZone tramite Boto3 per inviare metadati personalizzati sulla qualità dei dati.
- Gli utenti finali possono visualizzare i punteggi di qualità dei dati accedendo al portale dei dati.
Prerequisiti
Usiamo Amazon EMR senza server e Pydeequ per gestire un'attività completamente gestita Scintilla ambiente. Per saperne di più su Pydeequ come framework di test dei dati, vedere Testare la qualità dei dati su larga scala con Pydeequ.
Per consentire ad Amazon EMR di inviare dati al dominio Amazon DataZone, assicurati che il ruolo IAM utilizzato da Amazon EMR disponga delle autorizzazioni per effettuare quanto segue:
- Leggi e scrivi nei bucket S3
- Chiama il
post_time_series_data_pointsazione per Amazon DataZone:
Assicurati di aver aggiunto il ruolo EMR come a membro del progetto nel progetto Amazon DataZone. Nella console Amazon DataZone, vai al file Membri del progetto pagina e scegli Aggiungere membri.

Aggiungi il ruolo EMR come collaboratore.

Inserisci e analizza il codice PySpark
In questa sezione analizziamo il codice PySpark che utilizziamo per eseguire controlli di qualità dei dati e inviare i risultati ad Amazon DataZone. Puoi scaricare il completo Script PySpark.
Per eseguire interamente lo script, puoi inviare un lavoro a EMR Serverless. Il servizio si occuperà di pianificare il lavoro e di allocare automaticamente le risorse necessarie, consentendoti di tenere traccia del stati di esecuzione del lavoro durante tutto il processo.
Puoi inviare un lavoro a EMR all'interno della console Amazon EMR utilizzando EMR Studio o a livello di codice, utilizzando il file CLI AWS o utilizzando uno dei SDK AWS.
In Apache Spark, a SparkSession è il punto di ingresso per interagire con DataFrames e le funzioni integrate di Spark. Lo script inizierà a inizializzare a SparkSession:
Leggiamo un set di dati da Amazon S3. Per una maggiore modularità, è possibile utilizzare l'input dello script per fare riferimento al percorso S3:
Successivamente, impostiamo un repository di parametri. Ciò può essere utile per rendere persistenti i risultati dell'esecuzione in Amazon S3.
Pydeequ ti consente di creare regole di qualità dei dati utilizzando il pattern builder, che è un noto modello di progettazione dell'ingegneria del software, concatenando le istruzioni per istanziare un VerificationSuite oggetto:
Di seguito è riportato l'output per le regole di convalida dei dati:
A questo punto vogliamo inserire questi valori di qualità dei dati in Amazon DataZone. Per fare ciò, utilizziamo il file post_time_series_data_points funzione nel client Boto3 Amazon DataZone.
Il API DataZone PostTimeSeriesDataPoints ti consente di inserire nuovi punti dati di serie temporali per un determinato asset o elenco, senza creare una nuova revisione.
A questo punto potresti anche voler avere maggiori informazioni su quali campi vengono inviati come input per l'API. Puoi usare il API per ottenere le specifiche per i tipi di modulo Amazon DataZone; nel nostro caso, lo è amazon.datazone.DataQualityResultFormType.
Puoi anche utilizzare l'AWS CLI per richiamare l'API e visualizzare la struttura del modulo:
Questo output aiuta a identificare i parametri API richiesti, inclusi campi e limiti di valore:
Per inviare i dati del modulo appropriati, dobbiamo convertire l'output Pydeequ in modo che corrisponda al file DataQualityResultsFormType contrarre. Ciò può essere ottenuto con una funzione Python che elabora i risultati.
Per ogni riga DataFrame, estraiamo informazioni dalla colonna dei vincoli. Ad esempio, prendi il seguente codice:
Lo convertiamo nel seguente:
Assicurati di inviare un output che corrisponda ai KPI che desideri monitorare. Nel nostro caso, stiamo aggiungendo _custom al nome della statistica, ottenendo il seguente formato per i KPI:
Completeness_customUniqueness_custom
In uno scenario reale, potresti voler impostare un valore che corrisponda al tuo framework di qualità dei dati in relazione ai KPI che desideri monitorare in Amazon DataZone.
Dopo aver applicato una funzione di trasformazione, abbiamo un oggetto Python per ogni valutazione della regola:
Usiamo anche il constraint_status colonna per calcolare il punteggio complessivo:
Nel nostro esempio, ciò si traduce in una percentuale di passaggio dell'85.71%.
Impostiamo questo valore nel file passingPercentage campo di input insieme alle altre informazioni relative alle valutazioni presenti nell'input del metodo Boto3 post_time_series_data_points:
Boto3 invoca il API di Amazon DataZone. In questi esempi abbiamo utilizzato Boto3 e Python, ma puoi sceglierne uno SDK AWS sviluppato nella lingua che preferisci.
Dopo aver impostato il dominio e l'ID risorsa appropriati ed aver eseguito il metodo, possiamo verificare sulla console Amazon DataZone che la qualità dei dati della risorsa sia ora visibile nella pagina della risorsa.
Possiamo osservare che il punteggio complessivo corrisponde al valore di input dell'API. Possiamo anche vedere che siamo stati in grado di aggiungere KPI personalizzati nella scheda Panoramica tramite i valori dei parametri dei tipi personalizzati.

Con le nuove API Amazon DataZone, puoi caricare regole sulla qualità dei dati da sistemi di terze parti in un asset di dati specifico. Con questa funzionalità, Amazon DataZone ti consente di estendere i tipi di indicatori presenti in AWS Glue Data Quality (come completezza, minimo e unicità) con indicatori personalizzati.
ripulire
Consigliamo di eliminare eventuali risorse potenzialmente inutilizzate per evitare di incorrere in costi imprevisti. Ad esempio, puoi eliminare il dominio Amazon DataZone e la Applicazione EMR hai creato durante questo processo.
Conclusione
In questo post, abbiamo evidenziato le ultime funzionalità di Amazon DataZone per la qualità dei dati, offrendo agli utenti finali un contesto e una visibilità migliorati sulle proprie risorse di dati. Inoltre, abbiamo approfondito la perfetta integrazione tra Amazon DataZone e AWS Glue Data Quality. Puoi anche utilizzare le API di Amazon DataZone per l'integrazione con fornitori esterni di qualità dei dati, consentendoti di mantenere una strategia dati completa e solida all'interno del tuo ambiente AWS.
Per ulteriori informazioni su Amazon DataZone, consulta il Guida per l'utente di Amazon DataZone.
Informazioni sugli autori
 Andrea Filippo è un Partner Solutions Architect presso AWS che supporta partner e clienti del settore pubblico in Italia. Si concentra sulle moderne architetture di dati e sull'aiutare i clienti ad accelerare il loro percorso verso il cloud con tecnologie serverless.
Andrea Filippo è un Partner Solutions Architect presso AWS che supporta partner e clienti del settore pubblico in Italia. Si concentra sulle moderne architetture di dati e sull'aiutare i clienti ad accelerare il loro percorso verso il cloud con tecnologie serverless.
 Emanuele è un Solutions Architect presso AWS, con sede in Italia, dopo aver vissuto e lavorato per più di 5 anni in Spagna. Gli piace aiutare le grandi aziende nell'adozione delle tecnologie cloud e la sua area di competenza si concentra principalmente sull'analisi dei dati e sulla gestione dei dati. Al di fuori del lavoro, gli piace viaggiare e collezionare action figure.
Emanuele è un Solutions Architect presso AWS, con sede in Italia, dopo aver vissuto e lavorato per più di 5 anni in Spagna. Gli piace aiutare le grandi aziende nell'adozione delle tecnologie cloud e la sua area di competenza si concentra principalmente sull'analisi dei dati e sulla gestione dei dati. Al di fuori del lavoro, gli piace viaggiare e collezionare action figure.
 Varsha Velagapudi è Senior Technical Product Manager presso Amazon DataZone presso AWS. Si concentra sul miglioramento dell'individuazione e della cura dei dati necessari per l'analisi dei dati. La sua passione è semplificare il percorso di analisi e intelligenza artificiale dei clienti per aiutarli ad avere successo nelle loro attività quotidiane. Al di fuori del lavoro, le piacciono la natura e le attività all'aria aperta, la lettura e i viaggi.
Varsha Velagapudi è Senior Technical Product Manager presso Amazon DataZone presso AWS. Si concentra sul miglioramento dell'individuazione e della cura dei dati necessari per l'analisi dei dati. La sua passione è semplificare il percorso di analisi e intelligenza artificiale dei clienti per aiutarli ad avere successo nelle loro attività quotidiane. Al di fuori del lavoro, le piacciono la natura e le attività all'aria aperta, la lettura e i viaggi.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/amazon-datazone-now-integrates-with-aws-glue-data-quality-and-external-data-quality-solutions/
- :ha
- :È
- :non
- $ SU
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 16
- 2%
- 20
- 2000
- 22
- 27
- 325
- 345
- 375
- 400
- 5
- 7
- 8
- a
- capace
- WRI
- accelerare
- accesso
- realizzare
- precisione
- preciso
- raggiunto
- Legge
- Action
- azioni
- attività
- aggiungere
- aggiunto
- Inoltre
- Adozione
- influenzato
- Dopo shavasana, sedersi in silenzio; saluti;
- dopo
- contro
- AI
- AI / ML
- Tutti
- consentire
- Consentire
- consente
- lungo
- già
- anche
- Amazon
- Amazon EMR
- Amazon Web Services
- an
- .
- analitica
- analizzare
- l'analisi
- ed
- Andrea
- Annunciare
- in qualsiasi
- Apache
- Apache Spark
- api
- API
- applicazioni
- AMMISSIONE
- opportuno
- architettura
- architetture
- SONO
- RISERVATA
- aree
- artificiale
- intelligenza artificiale
- AS
- attività
- pagina delle risorse
- Attività
- addetto
- associato
- At
- automaticamente
- disponibile
- evitare
- AWS
- Colla AWS
- precedente
- basato
- BE
- perché
- diventare
- diventa
- stato
- fra
- costruttore
- incassato
- affari
- ma
- by
- calcolare
- calcolato
- calcolo
- Materiale
- capacità
- che
- Custodie
- catalogo
- il cambiamento
- Modifiche
- dai un'occhiata
- Controlli
- Scegli
- cli
- cliente
- Cloud
- codice
- Raccolta
- collezione
- Colonna
- colonne
- combinazione
- Uncommon
- comunicare
- Aziende
- completamento di una
- globale
- Calcolare
- configurato
- Confermare
- consiste
- consolle
- costrizione
- Consumatori
- contenute
- contenente
- contiene
- contenuto
- contesto
- contratto
- contribuire
- contribuisce
- collaboratore
- convertire
- Corrispondente
- Costi
- creare
- creato
- crea
- Creazione
- criteri
- cruciale
- curation
- costume
- Clienti
- personalizzate
- dati
- Dati Analytics
- inserimento dati
- gestione dei dati
- punti dati
- elaborazione dati
- qualità dei dati
- strategia di dati
- Banca Dati
- dataset
- Data
- giorno per giorno
- Decision Making
- decisioni
- definire
- definito
- Richiesta
- descrizione
- Design
- desiderato
- dettaglio
- dettagli
- sviluppato
- diagramma
- direttamente
- scoperta
- discutere
- Dsiplay
- visualizzati
- visualizzazione
- do
- effettua
- dominio
- doppio
- scaricare
- guida
- durante
- ogni
- In precedenza
- effetto
- efficacia
- che abilita
- Potenzia
- enable
- abilitato
- consentendo
- imporre
- Ingegneria
- migliorata
- aumento
- entrare
- interamente
- iscrizione
- Ambiente
- errore
- errori
- Etere (ETH)
- valutazione
- valutazioni
- esempio
- Esempi
- esistente
- previsto
- competenza
- estendere
- esterno
- estratto
- FAIL
- in mancanza di
- caratteristica
- Caratteristiche
- campo
- campi
- Cifre
- filtro
- Nome
- concentrato
- si concentra
- seguire
- i seguenti
- Nel
- modulo
- formato
- formazione
- formati
- promozione
- Contesto
- da
- completamente
- function
- funzioni
- Inoltre
- generato
- generatore
- ottenere
- GitHub
- dato
- accadere
- Avere
- he
- Salute e benessere
- assistenza sanitaria
- Aiuto
- utile
- aiutare
- aiuta
- massimo
- Evidenziato
- il suo
- storico
- olistica
- Come
- Tutorial
- HTML
- http
- HTTPS
- umano
- IAM
- ID
- identificare
- if
- illustra
- realizzare
- importare
- importanza
- importazione
- importazioni
- miglioramento
- miglioramento
- in
- includere
- Compreso
- è aumentato
- sempre più
- individuale
- informazioni
- informati
- ingresso
- perspicace
- intuizioni
- istruzioni
- numero intero
- integrare
- Integra
- integrazione
- interezza
- Intelligence
- destinato
- si interagisce
- interessato
- ai miglioramenti
- inventario
- dati di inventario
- invoca
- coinvolto
- IT
- Italia
- SUO
- Lavoro
- viaggio
- jpg
- json
- Le
- lago
- Lingua
- grandi
- Cognome
- con i più recenti
- IMPARARE
- lasciare
- Livello
- Biblioteca
- limiti
- Collegamento
- Lista
- annuncio
- vita
- caricare
- principalmente
- mantenere
- mantenuto
- mantenimento
- make
- gestito
- gestione
- direttore
- molti
- carta geografica
- partita
- fiammiferi
- max
- Maggio..
- misurare
- medicale
- Soddisfare
- membro
- Menu
- Metadati
- metodo
- Metrica
- forza
- verbale
- ordine
- modello
- moderno
- Monitorare
- Scopri di più
- maggior parte
- multiplo
- Nome
- Natura
- Navigare
- navigazione
- Navigazione
- Bisogno
- di applicazione
- New
- no
- Nessuna
- adesso
- numero
- oggetto
- oggetti
- osservare
- ottenere
- of
- Offerte
- on
- ONE
- aprire
- open source
- operazione
- or
- organizzazioni
- originato
- Altro
- altrimenti
- nostro
- antiquato
- All'aperto
- produzione
- al di fuori
- ancora
- complessivo
- panoramica
- Packages
- pagina
- vetro
- parametro
- parametri
- parte
- partner
- partner
- passare
- Di passaggio
- appassionato
- sentiero
- paziente
- dati del paziente
- pazienti
- Cartamodello
- percentuale
- eseguire
- esecuzione
- permessi
- prospettiva
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- contento
- punto
- punti
- Termini e Condizioni
- Portale
- Post
- Post
- potenzialmente
- preferire
- presenti
- processi
- i processi
- lavorazione
- Prodotto
- produzione
- Prodotto
- product manager
- progetto
- fornitori
- fornitura
- la percezione
- pubblicato
- editoriale
- Spingi
- spingendo
- metti
- Python
- qualità
- Domande
- rapidamente
- corse
- Leggi
- Lettura
- mondo reale
- realistico
- motivi
- riconoscere
- raccomandare
- record
- riferimento
- riflettere
- relazionato
- relazione
- problemi di
- rapporto
- Reportistica
- deposito
- necessario
- risorsa
- Risorse
- colpevole
- risultante
- Risultati
- Rischio
- robusto
- Ruolo
- RIGA
- Regola
- norme
- set di regole
- Correre
- running
- corre
- stesso
- salvato
- Scala
- scenario
- in programma
- programmazione
- Punto
- punteggi
- copione
- sdk
- senza soluzione di continuità
- Cerca
- Secondo
- Sezione
- settore
- vedere
- select
- selezionato
- Selezione
- prodotti
- inviare
- anziano
- inviato
- Serie
- serverless
- serve
- servizio
- Servizi
- set
- regolazione
- Condividi
- lei
- dovrebbero
- mostrato
- Un'espansione
- semplificando
- simulare
- Istantanea
- So
- Software
- Ingegneria del software
- soluzione
- Soluzioni
- Fonte
- fonti
- Spagna
- Scintilla
- specifico
- specificazione
- standard
- inizia a
- Di partenza
- dichiarazione
- Stato dei servizi
- Passi
- Ancora
- conservazione
- Strategia
- Corda
- La struttura
- inviare
- avere successo
- il successo
- tale
- Supporto
- supporti
- sicuro
- sintetico
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- TAG
- Fai
- Target
- task
- Consulenza
- Tecnologie
- Testing
- test
- testo
- di
- che
- Il
- L’ORIGINE
- loro
- Li
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- di parti terze standard
- questo
- quelli
- Attraverso
- per tutto
- tempo
- Serie storiche
- tempestivo
- volte
- timestamp
- a
- argomento
- Totale
- pista
- Trasformazione
- Di viaggio
- vero
- Affidati ad
- attendibilità
- Tipi di
- capire
- Inaspettato
- unicità
- non usato
- Aggiornanento
- aggiornato
- uso
- utilizzato
- utile
- Utente
- utenti
- utilizzando
- convalida
- APPREZZIAMO
- Valori
- vario
- variando
- versione
- via
- Visualizza
- visibilità
- visibile
- visualizzare
- camminare
- volere
- we
- sito web
- servizi web
- noto
- sono stati
- quando
- se
- quale
- volere
- con
- entro
- senza
- Lavora
- flusso di lavoro
- lavoro
- scrivere
- X
- anni
- ancora
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- Codice postale