L'elaborazione dei dati in streaming consente di agire sui dati in tempo reale. L'analisi dei dati in tempo reale può aiutarti a ottenere risposte puntuali e ottimizzate, migliorando al tempo stesso l'esperienza complessiva del cliente.
I carichi di lavoro di streaming di dati spesso richiedono che i dati nel flusso vengano arricchiti tramite fonti esterne (come database o altri flussi di dati). Il precaricamento dei dati di riferimento fornisce bassa latenza e throughput elevato. Tuttavia, questo modello potrebbe non essere adatto a determinati tipi di carichi di lavoro:
- Aggiornamenti dei dati di riferimento ad alta frequenza
- L'applicazione di streaming deve effettuare una chiamata esterna per calcolare la logica aziendale
- La precisione dell'output è importante e l'applicazione non deve utilizzare dati obsoleti
- La cardinalità dei dati di riferimento è molto elevata e il set di dati di riferimento è troppo grande per essere conservato nello stato dell'applicazione di streaming
Ad esempio, se ricevi dati sulla temperatura da una rete di sensori e hai bisogno di ottenere metadati aggiuntivi dei sensori per analizzare il modo in cui questi sensori si associano a posizioni geografiche fisiche, devi arricchirla con i dati dei metadati dei sensori.
Apache Flink è un framework di calcolo distribuito che consente l'elaborazione dei dati con stato in tempo reale. Fornisce un unico set di API per la creazione di processi batch e in streaming, consentendo agli sviluppatori di lavorare facilmente con dati limitati e illimitati. Servizio gestito da Amazon per Apache Flink (successore di Amazon Kinesis Data Analytics) è un servizio AWS che fornisce un'infrastruttura serverless completamente gestita per l'esecuzione di applicazioni Apache Flink. Gli sviluppatori possono creare applicazioni Apache Flink altamente disponibili, tolleranti ai guasti e scalabili con facilità e senza dover diventare esperti nella creazione, configurazione e manutenzione di cluster Apache Flink su AWS.
Puoi utilizzare diversi approcci per arricchire i tuoi dati in tempo reale in Amazon Managed Service per Apache Flink a seconda del caso d'uso e del livello di astrazione di Apache Flink. Ciascun metodo ha effetti diversi sulla velocità effettiva, sul traffico di rete e sull'utilizzo della CPU (o della memoria). Per una panoramica generale dei modelli di arricchimento dei dati, fare riferimento a Modelli comuni di arricchimento dei dati in streaming in Amazon Managed Service per Apache Flink.
Questo post illustra come implementare l'arricchimento dei dati per eventi di streaming in tempo reale con Apache Flink e come ottimizzare le prestazioni. Per confrontare le prestazioni dei modelli di arricchimento, abbiamo eseguito test delle prestazioni basati su dati sintetici. Il risultato di questo test è utile come riferimento generale. È importante notare che le prestazioni effettive del carico di lavoro Flink dipenderanno da vari e diversi fattori, come la latenza dell'API, la velocità effettiva, la dimensione dell'evento e il rapporto di riscontro nella cache.
Discutiamo tre modelli di arricchimento, dettagliati nella tabella seguente.
| . | Arricchimento sincrono | Arricchimento asincrono | Arricchimento memorizzato nella cache sincrono |
| Approccio di arricchimento | Richieste sincrone con blocco per record all'endpoint esterno | Richieste parallele non bloccanti all'endpoint esterno, utilizzando I/O asincrono | Le informazioni a cui si accede frequentemente vengono memorizzate nella cache nello stato dell'applicazione Flink, con un TTL fisso |
| Freschezza dei dati | Dati di arricchimento sempre aggiornati | Dati di arricchimento sempre aggiornati | I dati di arricchimento potrebbero essere obsoleti, fino al TTL |
| Complessità di sviluppo | Modello semplice | Più difficile da eseguire il debug, a causa del multi-threading | Più difficile da eseguire il debug, poiché si basa sullo stato Flink |
| Gestione degli errori | schietto | Più complesso, utilizzando i callback | schietto |
| Impatto sull'API di arricchimento | Max: una richiesta per messaggio | Max: una richiesta per messaggio | Riduci I/O all'API di arricchimento (dipende dal TTL della cache) |
| Latenza dell'applicazione | Sensibile alla latenza dell'API di arricchimento | Meno sensibile alla latenza dell'API di arricchimento | Riduci la latenza dell'applicazione (dipende dalla percentuale di riscontri nella cache) |
| Altre considerazioni | nessuna | nessuna |
TTL personalizzabile. Solo implementazione sincrona a partire da Flink 1.17 |
| Risultato del test comparativo (Throughput) | ~350 eventi al secondo | ~2,000 eventi al secondo | ~28,000 eventi al secondo |
Panoramica della soluzione
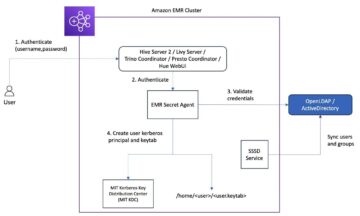
Per questo post, utilizziamo un esempio di rete di sensori di temperatura (componente 1 nel seguente diagramma dell'architettura) che emette informazioni sul sensore, come temperatura, ID sensore, stato e timestamp in cui è stato prodotto questo evento. Questi eventi di temperatura vengono assorbiti Flussi di dati di Amazon Kinesis (2). I sistemi a valle richiedono anche le informazioni sulla marca e sul codice paese dei sensori, per analizzare, ad esempio, l'affidabilità per marca e la temperatura per lato dell'impianto.
In base all'ID del sensore, arricchiamo le informazioni del sensore dalla Sensor Info API (3), che ci fornisce informazioni sul marchio, sulla posizione e su un'immagine. Il flusso arricchito risultante viene inviato a un altro flusso di dati Kinesis e può quindi essere analizzato in un file Servizio gestito da Amazon per Apache Flink Studio taccuino (4).
Prerequisiti
Per iniziare a implementare modelli di arricchimento dei dati in tempo reale, puoi clonare o scaricare il codice da Repository GitHub. Questo repository implementa l'applicazione di streaming Flink che abbiamo descritto. Puoi trovare le istruzioni su come configurare Flink in Amazon Managed Service per Apache Flink o in altre opzioni di distribuzione Flink disponibili nella README.md file.
Se vuoi sapere come vengono implementati questi modelli e come ottimizzare le prestazioni per la tua applicazione Flink, puoi semplicemente seguire questo post senza distribuire gli esempi.
Panoramica del progetto
Il progetto è strutturato come segue:
Il main metodo in ProcessTemperatureStream class configura l'ambiente di esecuzione e accetta i parametri dalla riga di comando, se si tratta di un ambiente locale, oppure utilizza le proprietà dell'applicazione da Amazon Managed Service per Apache Flink. In base al parametro EnrichmentStrategy, decide quale implementazione scegliere: arricchimento sincrono (impostazione predefinita), arricchimento asincrono o arricchimento memorizzato nella cache basato sul concetto Flink di Stato con chiave.
Esaminiamo i tre approcci nelle sezioni seguenti.
Arricchimento sincrono dei dati
Se desideri arricchire i tuoi dati da un provider esterno, puoi utilizzare la ricerca sincrona per record. Quando la tua applicazione Flink elabora un evento in entrata, effettua una chiamata HTTP esterna e dopo aver inviato ogni richiesta, deve attendere finché non riceve la risposta.
Poiché Flink elabora gli eventi in modo sincrono, il thread che esegue l'arricchimento viene bloccato finché non riceve la risposta HTTP. Ciò fa sì che il processore rimanga inattivo per un periodo significativo di tempo di elaborazione. D'altro canto, il modello sincrono è più semplice da progettare, eseguire il debug e tracciare. Permette inoltre di avere sempre i dati più aggiornati.
Può essere integrato nella tua applicazione di streaming in quanto tale:
L'implementazione della funzione di arricchimento è simile al seguente codice:
Per ottimizzare le prestazioni per l'arricchimento sincrono, è possibile utilizzare il file Mantieni vivo flag perché il client HTTP verrà riutilizzato per più eventi.
Per le applicazioni con operatori legati all'I/O (come l'arricchimento dei dati esterni), può anche avere senso aumentare il parallelismo dell'applicazione senza aumentare le risorse dedicate all'applicazione. Puoi farlo aumentando il ParallelismoPerKPU impostazione dell'applicazione Amazon Managed Service per Apache Flink. Questa configurazione descrive il numero di attività secondarie parallele che un'applicazione può eseguire per Kinesis Processing Unit (KPU) e un valore più elevato di ParallelismPerKPU può portare al pieno utilizzo delle risorse KPU. Ma tieni presente che aumentare il parallelismo non funziona in tutti i casi, come quando lo sei consumando da fonti con pochi frammenti o partizioni.
Nei nostri test sintetici con Amazon Managed Service per Apache Flink, abbiamo riscontrato un throughput di circa 350 eventi al secondo su una singola KPU con 4 parallelismi per KPU e le impostazioni predefinite.
Arricchimento asincrono dei dati
L'arricchimento sincrono non sfrutta appieno le risorse di elaborazione. Questo perché Fink attende risposte HTTP. Ma Flink offre I/O asincrono per l'accesso ai dati esterni. Ciò consente di arricchire gli eventi dello stream in modo asincrono, in modo che possa inviare una richiesta per altri elementi nello stream mentre attende la risposta per il primo elemento e le richieste possono essere raggruppate per una maggiore efficienza.
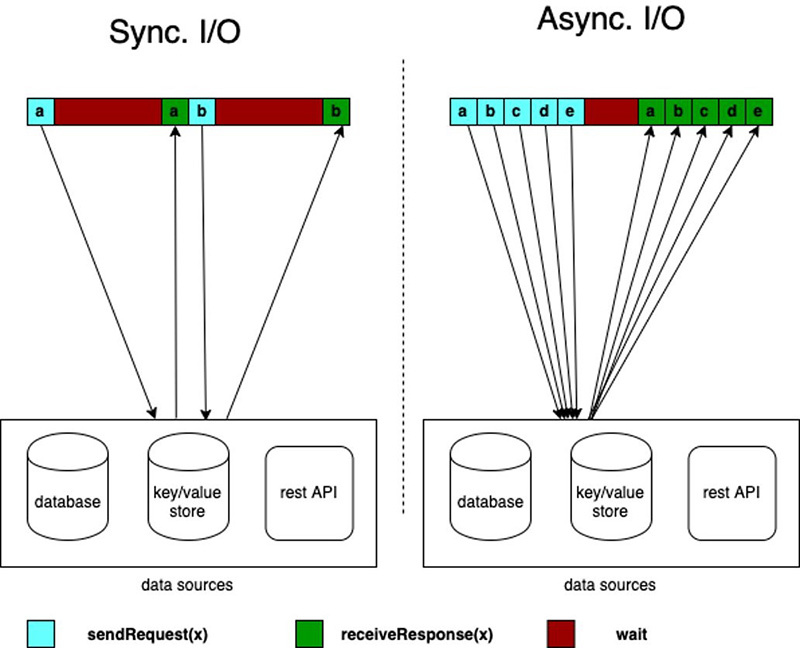
Mentre usi questo modello, devi decidere tra unorderedWait (dove emette il risultato all'operatore successivo non appena viene ricevuta la risposta, ignorando l'ordine degli elementi sullo stream) e orderedWait (dove attende il completamento di tutte le operazioni I/O in volo, quindi invia i risultati all'operatore successivo nello stesso ordine in cui gli elementi originali sono stati inseriti nello stream). Quando il tuo caso d'uso non richiede l'ordinamento degli eventi, unorderedWait fornisce una migliore produttività e meno tempi di inattività. Fare riferimento a Arricchisci il tuo flusso di dati in modo asincrono utilizzando Amazon Managed Service per Apache Flink per saperne di più su questo modello.
L'arricchimento asincrono può essere aggiunto come segue:
La funzione di arricchimento funziona in modo simile all'implementazione sincrona. Innanzitutto recupera le informazioni del sensore come a Futuro Java, che rappresenta il risultato di un calcolo asincrono. Non appena è disponibile, analizza le informazioni e quindi unisce entrambi gli oggetti in un file EnrichedTemperature:
Nei nostri test con Amazon Managed Service per Apache Flink, abbiamo riscontrato un throughput di 2,000 eventi al secondo su una singola KPU con 2 parallelismi per KPU e le impostazioni predefinite.
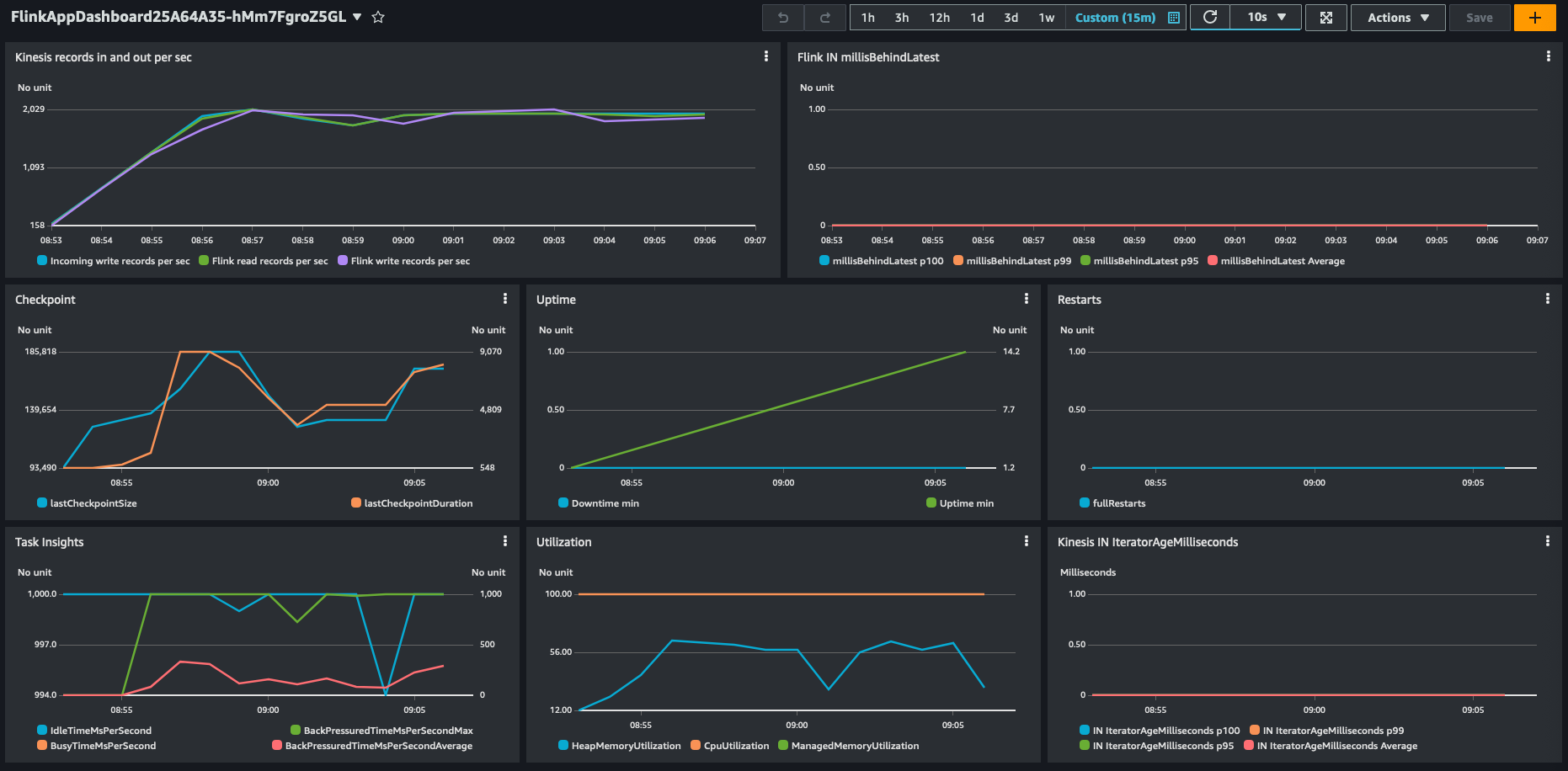
Arricchimento sincrono dei dati memorizzati nella cache
Sebbene numerose operazioni in un flusso di dati si concentrino su singoli eventi in modo indipendente, come l'analisi degli eventi, esistono alcune operazioni che conservano le informazioni su più eventi. Queste operazioni, come gli operatori delle finestre, vengono definite con stato per la loro capacità di mantenere lo stato.
Il stato con chiave è archiviato all'interno di un archivio di valori-chiave incorporato, concettualizzato come parte dell'architettura di Flink. Questo stato viene partizionato e distribuito insieme ai flussi utilizzati dagli operatori con stato. Di conseguenza, l'accesso allo stato chiave-valore è limitato ai flussi con chiave, ovvero è possibile accedervi solo dopo uno scambio di dati con chiave o partizionato ed è limitato ai valori associati alla chiave dell'evento corrente. Per ulteriori informazioni sui concetti, fare riferimento a Elaborazione del flusso con stato.
È possibile utilizzare lo stato con chiave per le informazioni a cui si accede frequentemente che non cambiano spesso, come le informazioni del sensore. Ciò non solo consentirà di ridurre il carico sulle risorse downstream, ma aumenterà anche l'efficienza dell'arricchimento dei dati poiché non è necessario alcun viaggio di andata e ritorno verso una risorsa esterna per le chiavi già recuperate e non è inoltre necessario ricalcolare le informazioni. Tieni però presente che Amazon Managed Service per Apache Flink archivia i dati temporanei in un backend RocksDB, il che aggiunge una latenza al recupero delle informazioni. Ma poiché RocksDB è locale rispetto al nodo che elabora i dati, è più veloce che raggiungere risorse esterne, come puoi vedere nell'esempio seguente.
Per utilizzare flussi con chiave, devi partizionare il flusso utilizzando il file .keyBy(...) metodo, che garantisce che gli eventi per la stessa chiave, in questo caso l'ID del sensore, verranno instradati allo stesso lavoratore. Puoi implementarlo come segue:
Stiamo utilizzando l'ID del sensore come chiave per partizionare il flusso e successivamente arricchirlo. In questo modo, possiamo quindi memorizzare nella cache le informazioni del sensore come parte dello stato con chiave. Quando scegli una chiave di partizione per il tuo caso d'uso, scegline una che abbia una cardinalità elevata. Ciò porta a una distribuzione uniforme degli eventi tra i diversi lavoratori.
Per memorizzare le informazioni del sensore, utilizziamo il file ValueState. Per configurare la gestione dello stato, dobbiamo descrivere il tipo di stato utilizzando il file TipoSuggerimento. Inoltre, possiamo configurare per quanto tempo un determinato stato verrà memorizzato nella cache specificando il file tempo di vivere (TTL) prima che lo stato venga ripulito e debba essere recuperato o ricalcolato nuovamente.
A partire da Flink 1.17, l'accesso allo stato non è possibile nelle funzioni asincrone, quindi l'implementazione deve essere sincrona.
Innanzitutto controlla se esistono le informazioni del sensore per questa particolare chiave; se è così, si arricchisce. Altrimenti, recupera le informazioni del sensore, le analizza e quindi unisce entrambi gli oggetti in un file EnrichedTemperature:
Nei nostri test sintetici con Amazon Managed Service per Apache Flink, abbiamo riscontrato un throughput di 28,000 eventi al secondo su una singola KPU con 4 parallelismi per KPU e le impostazioni predefinite.
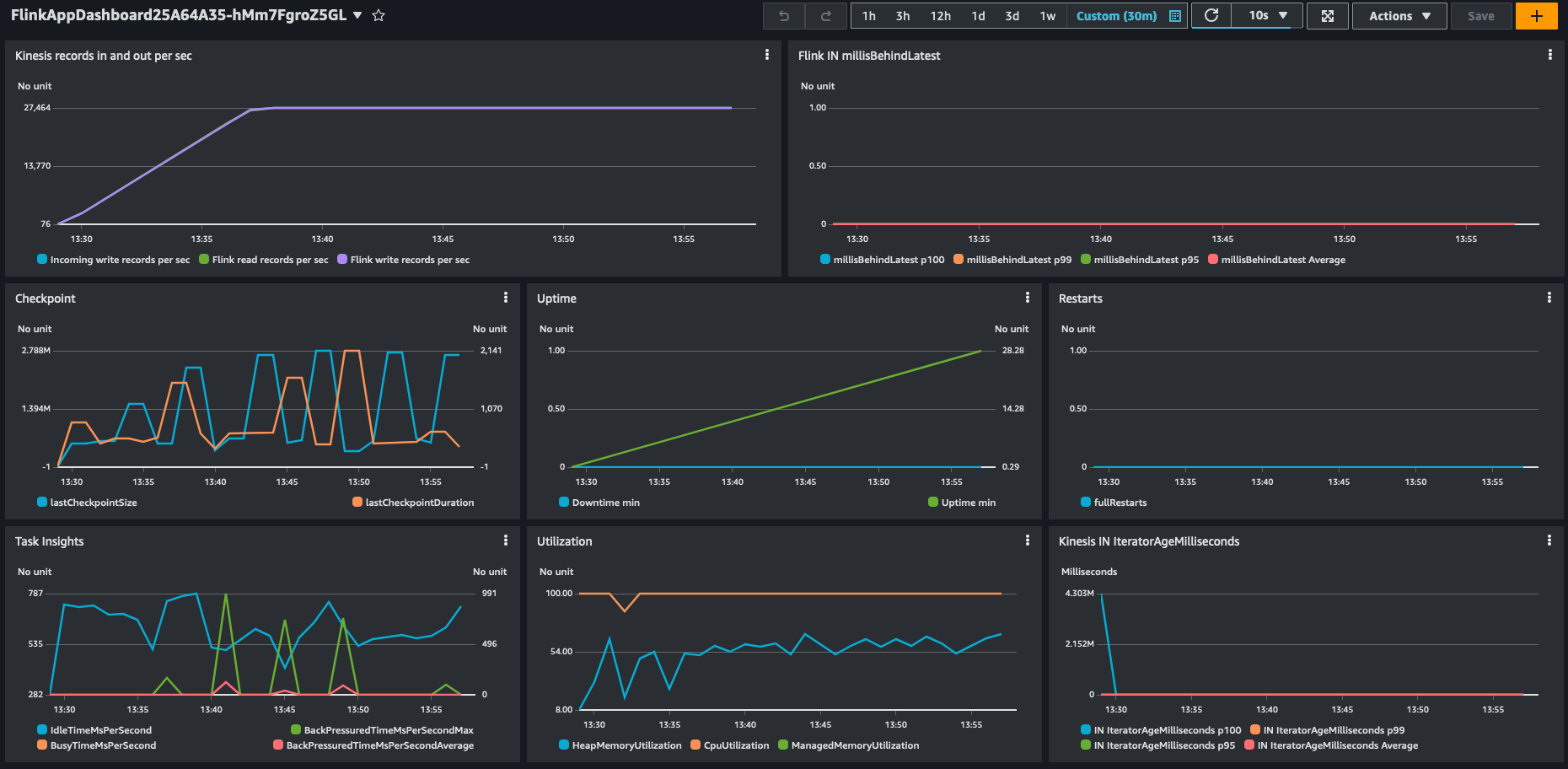
Puoi anche vedere l'impatto e il carico ridotto sull'API del sensore downstream.
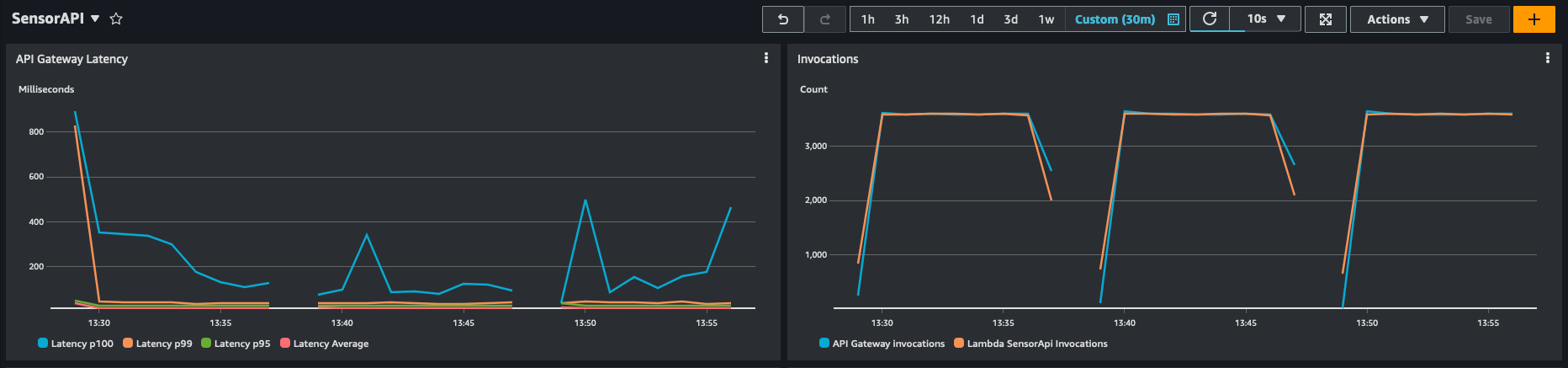
Metti alla prova il tuo carico di lavoro su Amazon Managed Service per Apache Flink
Questo post mette a confronto diversi approcci per eseguire un'applicazione su Amazon Managed Service per Apache Flink con 1 KPU. Il test con una singola KPU fornisce una buona base di prestazioni che consente di confrontare i modelli di arricchimento senza generare un carico di lavoro di produzione su vasta scala.
È importante comprendere che le prestazioni effettive dei modelli di arricchimento dipendono dal carico di lavoro effettivo e da altri sistemi esterni con cui interagisce l'applicazione Flink. Ad esempio, le prestazioni dell'arricchimento della cache possono variare in base alla percentuale di riscontri nella cache. L'arricchimento sincrono può comportarsi diversamente a seconda della latenza di risposta dell'endpoint di arricchimento.
Per valutare quale approccio si adatta meglio al tuo carico di lavoro, dovresti prima eseguire test ridotti con 1 KPU e un throughput limitato di dati realistici, possibilmente sperimentando diversi valori di parallelismo per KPU. Dopo aver identificato l'approccio migliore, è importante testare l'implementazione su vasta scala, con dati reali e integrandola con sistemi esterni reali, prima di passare alla produzione.
Sommario
Questo post ha esplorato diversi approcci per implementare l'arricchimento dei dati in tempo reale utilizzando Flink, concentrandosi su tre modelli di comunicazione: arricchimento sincrono, arricchimento asincrono e memorizzazione nella cache con Flink KeyedState.
Abbiamo confrontato il throughput ottenuto da ciascun approccio con la memorizzazione nella cache utilizzando Flink KeyedState essendo fino a 14 volte più veloce rispetto all'utilizzo di I/O asincrono, in questo particolare esperimento con dati sintetici. Inoltre, abbiamo approfondito l'ottimizzazione delle prestazioni di Apache Flink, in particolare su Amazon Managed Service per Apache Flink. Abbiamo discusso strategie e best practice per massimizzare le prestazioni delle applicazioni Flink in un ambiente gestito, consentendoti di sfruttare appieno le funzionalità di Flink per le tue esigenze di arricchimento dei dati in tempo reale.
Nel complesso, questa panoramica offre approfondimenti sui diversi modelli di arricchimento dei dati, sulle relative caratteristiche prestazionali e sulle tecniche di ottimizzazione quando si utilizza Apache Flink, in particolare nel contesto di scenari di arricchimento dei dati in tempo reale e su Amazon Managed Service per Apache Flink.
Accogliamo con favore il tuo feedback. Per favore lascia i tuoi pensieri e domande nella sezione commenti.
Circa gli autori
 Luis Morales lavora come Senior Solutions Architect con aziende native digitali per supportarle nel reinventarsi costantemente nel cloud. È appassionato di ingegneria del software, sistemi distribuiti nativi del cloud, sviluppo basato su test e tutto ciò che riguarda codice e sicurezza.
Luis Morales lavora come Senior Solutions Architect con aziende native digitali per supportarle nel reinventarsi costantemente nel cloud. È appassionato di ingegneria del software, sistemi distribuiti nativi del cloud, sviluppo basato su test e tutto ciò che riguarda codice e sicurezza.
 Lorenzo Nicora lavora come Senior Streaming Solution Architect aiutando i clienti in tutta l'area EMEA. Da diversi anni realizza sistemi cloud-native ad alta intensità di dati, lavorando nel settore finanziario sia attraverso consulenze che per aziende di prodotti fin-tech. Ha sfruttato ampiamente le tecnologie open source e ha contribuito a diversi progetti, tra cui Apache Flink.
Lorenzo Nicora lavora come Senior Streaming Solution Architect aiutando i clienti in tutta l'area EMEA. Da diversi anni realizza sistemi cloud-native ad alta intensità di dati, lavorando nel settore finanziario sia attraverso consulenze che per aziende di prodotti fin-tech. Ha sfruttato ampiamente le tecnologie open source e ha contribuito a diversi progetti, tra cui Apache Flink.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/implement-apache-flink-real-time-data-enrichment-patterns/
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 100
- 11
- 12
- 125
- 13
- 130
- 14
- 15%
- 17
- 19
- 23
- 28
- 7
- 9
- 913
- a
- capacità
- WRI
- astrazione
- accesso
- accessibile
- raggiunto
- operanti in
- Legge
- presenti
- aggiunto
- aggiuntivo
- Inoltre
- Aggiunge
- Vantaggio
- Dopo shavasana, sedersi in silenzio; saluti;
- ancora
- Tutti
- consentire
- consente
- lungo
- già
- anche
- sempre
- Amazon
- Cinesi amazzonica
- Amazon Web Services
- an
- analitica
- analizzare
- analizzato
- ed
- Un altro
- Apache
- api
- API
- Applicazioni
- applicazioni
- approccio
- approcci
- circa
- architettura
- SONO
- AS
- associato
- assicura
- At
- disponibile
- AWS
- BACKEND
- basato
- Linea di base
- BE
- perché
- diventare
- stato
- prima
- comportarsi
- essendo
- MIGLIORE
- best practice
- Meglio
- fra
- Big
- bloccato
- blocco
- entrambi
- marca
- Rompere
- costruire
- Costruzione
- affari
- aziende
- ma
- by
- nascondiglio
- chiamata
- Materiale
- funzionalità
- Custodie
- casi
- lotta
- certo
- il cambiamento
- caratteristiche
- dai un'occhiata
- Controlli
- Scegli
- classe
- cliente
- Cloud
- codice
- Commenti
- Comunicazione
- Aziende
- confrontare
- rispetto
- completamento di una
- complesso
- componente
- calcolo
- Calcolare
- informatica
- concetto
- concetti
- Configurazione
- congiunzione
- costantemente
- consumato
- contiene
- contesto
- contribuito
- nazione
- copre
- CPU
- Corrente
- cliente
- esperienza del cliente
- Clienti
- dati
- Dati Analytics
- arricchimento dei dati
- Scambio di dati
- elaborazione dati
- banche dati
- decide
- dedicato
- Predefinito
- dipendere
- Dipendente
- dipende
- distribuzione
- deployment
- descrivere
- descritta
- Design
- dettagliati
- sviluppatori
- Mercato
- diverso
- diversamente
- discutere
- discusso
- trascurando
- distribuito
- sistemi distribuiti
- distribuzione
- do
- documentazione
- non
- scaricare
- dovuto
- e
- ogni
- alleviare
- più facile
- facile
- effetti
- efficienza
- o
- elemento
- elementi
- altro
- incorporato
- consentendo
- endpoint
- Ingegneria
- arricchire
- arricchito
- arricchimento
- Ambiente
- Etere (ETH)
- valutare
- Anche
- Evento
- eventi
- Ogni
- esempio
- eccezione
- exchange
- esistente
- esiste
- esperienza
- esperimento
- esperto
- Esplorazione
- si estende
- descrive
- esterno
- Fattori
- più veloce
- feedback
- Recuperato
- pochi
- Compila il
- finale
- finanziare
- Trovate
- Nome
- fisso
- flusso
- Focus
- messa a fuoco
- seguire
- i seguenti
- segue
- Nel
- Contesto
- frequentemente
- da
- pieno
- su vasta scala
- completamente
- function
- funzioni
- Inoltre
- futuro
- Generale
- la generazione di
- geografico
- ottenere
- dà
- Go
- buono
- maggiore
- cura
- Avere
- he
- Eroe
- Aiuto
- aiutare
- Alta
- superiore
- vivamente
- Colpire
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- ID
- identificare
- Idle
- if
- Immagine
- Impact
- realizzare
- implementazione
- implementato
- Implementazione
- attrezzi
- importante
- miglioramento
- in
- Compreso
- In arrivo
- Aumento
- crescente
- indipendentemente
- individuale
- industria
- info
- informazioni
- Infrastruttura
- intuizioni
- istruzioni
- integrato
- Integrazione
- interagisce
- ai miglioramenti
- IT
- Offerte di lavoro
- jpg
- mantenere
- Le
- Tasti
- Latenza
- dopo
- con i più recenti
- portare
- Leads
- IMPARARE
- Lasciare
- meno
- Livello
- leveraged
- piace
- Limitato
- linea
- caricare
- locale
- località
- posizioni
- Lunghi
- SEMBRA
- ricerca
- Basso
- Principale
- mantenere
- mantenimento
- make
- FA
- Fare
- gestito
- gestione
- carta geografica
- Massimizzare
- Maggio..
- significato
- Memorie
- Unire
- unioni
- Metadati
- metodo
- millisecondi
- mente
- modello
- Scopri di più
- in movimento
- multiplo
- devono obbligatoriamente:
- necessaria
- Bisogno
- che necessitano di
- esigenze
- Rete
- traffico di rete
- New
- GENERAZIONE
- no
- nodo
- Nota
- taccuino
- numero
- numerose
- oggetti
- of
- Offerte
- di frequente
- on
- ONE
- esclusivamente
- aprire
- open source
- Operazioni
- operatore
- Operatori
- ottimizzazione
- OTTIMIZZA
- ottimizzati
- ottimizzazione
- Opzioni
- or
- oracolo
- minimo
- i
- Altro
- altrimenti
- nostro
- su
- produzione
- ancora
- complessivo
- panoramica
- Parallel
- parametro
- parametri
- parte
- particolare
- particolarmente
- appassionato
- Cartamodello
- modelli
- per
- eseguire
- performance
- periodo
- Fisico
- scegliere
- posto
- impianto
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- possibile
- forse
- Post
- pratiche
- un bagno
- i processi
- lavorazione
- Processore
- Prodotto
- Prodotto
- Produzione
- progetto
- progetti
- proprietà
- fornire
- fornitore
- fornisce
- la percezione
- Domande
- rapporto
- raggiungendo
- di rose
- tempo reale
- dati in tempo reale
- realistico
- ricevuto
- riceve
- ricevente
- ridurre
- Ridotto
- riferimento
- riferimento
- di cui
- problemi di
- basandosi
- deposito
- rappresenta
- richiesta
- richieste
- richiedere
- risorsa
- Risorse
- risposta
- risposte
- limitato
- colpevole
- risultante
- Risultati
- conservare
- ritorno
- Correre
- running
- stesso
- sega
- scalabile
- Scala
- Scenari
- Secondo
- Sezione
- sezioni
- problemi di
- vedere
- inviare
- invio
- invia
- anziano
- senso
- delicata
- sensore
- inviato
- serverless
- servizio
- Servizi
- set
- Set
- regolazione
- impostazioni
- flessibile.
- alcuni
- dovrebbero
- lato
- significativa
- simile
- semplicemente
- singolo
- Taglia
- So
- Software
- Ingegneria del software
- soluzione
- Soluzioni
- Arrivo
- Fonte
- fonti
- in particolare
- iniziato
- Regione / Stato
- statico
- Stato dei servizi
- soggiorno
- Tornare al suo account
- memorizzati
- negozi
- strategie
- Strategia
- ruscello
- Streaming
- flussi
- Corda
- strutturato
- tale
- adatto
- abiti
- supporto
- Interruttore
- sintetico
- dati sintetici
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- prende
- tecniche
- Tecnologie
- test
- Testing
- test
- di
- che
- Il
- le informazioni
- Lo Stato
- loro
- Li
- si
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- cose
- questo
- tre
- Attraverso
- portata
- tempo
- volte
- timestamp
- a
- pure
- tracciare
- traffico
- prova
- Digitare
- Tipi di
- capire
- unità
- fino a quando
- up-to-date
- Aggiornamenti
- URL
- us
- uso
- caso d'uso
- utile
- usa
- utilizzando
- APPREZZIAMO
- Valori
- vario
- variare
- molto
- via
- vs
- aspettare
- attese
- volere
- Prima
- Modo..
- we
- sito web
- servizi web
- il benvenuto
- sono stati
- quando
- quale
- while
- wikipedia
- volere
- finestra
- con
- entro
- senza
- Lavora
- lavoratore
- lavoratori
- lavoro
- lavori
- anni
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro