מבוא
בעולם של אחזור מידע, שבו אוקיינוסים של נתוני טקסט ממתינים לחקירה, היכולת לאתר מסמכים רלוונטיים ביעילות היא לא יסולא בפז. לחיפוש המסורתי מבוסס מילות מפתח יש מגבלות, במיוחד כאשר עוסקים בנתונים אישיים וסודיים. כדי להתגבר על האתגרים הללו, אנו פונים למיזוג של שני כלים יוצאי דופן: מינוף GPT-2 ו-LlamaIndex, ספריית קוד פתוח שנועדה לטפל בנתונים אישיים בצורה מאובטחת. במאמר זה, נתעמק בקוד המציג כיצד שתי הטכנולוגיות הללו משלבות כוחות כדי לשנות את אחזור המסמכים.

מטרות למידה
- למד כיצד לשלב ביעילות את העוצמה של GPT-2, מודל שפה רב תכליתי, עם LLAMAINDEX, ספרייה ממוקדת פרטיות, כדי לשנות את אחזור המסמכים.
- השג תובנות לגבי הטמעת קוד פשוטה המדגימה את תהליך הוספה לאינדקס של מסמכים ודירוגם על סמך דמיון לשאילתת משתמש באמצעות הטמעות GPT-2.
- חקור את המגמות העתידיות באחזור מסמכים, כולל שילוב של מודלים שפות גדולים יותר, תמיכה בתוכן רב-מודאלי ושיקולים אתיים, והבין כיצד מגמות אלו יכולות לעצב את התחום.
מאמר זה פורסם כחלק מה- בלוגתון מדעי הנתונים.
תוכן העניינים
GPT-2: חושפת את ענק מודל השפה
ביטול המסכה של GPT-2
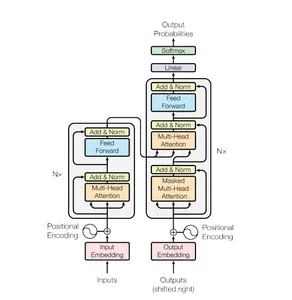
GPT-2 מייצג "שנאי 2 מאומן מראש", וזה היורש של דגם ה-GPT המקורי. פותח על ידי OpenAI, GPT-2 פרץ לזירה עם יכולות פורצות דרך בהבנה ויצירת טקסט דמוי אדם. הוא מתהדר בארכיטקטורה יוצאת דופן הבנויה על דגם ה-Transformer, שהפך לאבן הפינה של ה-NLP המודרני.
ארכיטקטורת הרובוטריק
הבסיס של GPT-2 הוא ארכיטקטורת ה-Transformer, עיצוב רשת עצבית שהוצג על ידי Ashish Vaswani וחב'. במאמר "תן לזה להיות מה שאתה רוצה שזה יהיה." מודל זה חולל מהפכה ב-NLP על ידי הגדלת העקביות, היעילות והיעילות. תכונות הליבה של Transformer כמו ניטור עצמי, טרנספורמציה מרחבית והאזנה מרובה ראשים מאפשרות ל-GPT-2 להבין תוכן ויחסים בטקסט כמו שלא היה מעולם.
למידה מרובה משימות
GPT-2 מייחד את עצמו בזכות יכולתו המדהימה בלמידה מרובה משימות. בניגוד למודלים המוגבלים למשימת עיבוד שפה טבעית אחת (NLP), GPT-2 מצטיין במערך מגוון שלהם. היכולות שלו כוללות משימות כמו השלמת טקסט, תרגום, מענה על שאלות ויצירת טקסט, ומבססות אותו ככלי רב תכליתי וניתן להתאמה עם ישימות רחבה בתחומים שונים.
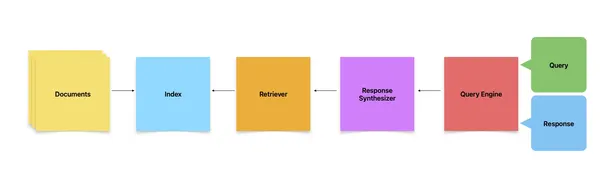
פירוט קוד: אחזור מסמכים לשמירה על הפרטיות
כעת, נתעמק ביישום קוד פשוט של LLAMAINDEX הממנף מודל GPT-2 שמקורו בספריית Hugging Face Transformers. בדוגמה המחשה הזו, אנו מעסיקים את LLAMAINDEX כדי להוסיף אוסף של מסמכים המכילים תיאורי מוצרים. מסמכים אלה מדורגים לאחר מכן על סמך הדמיון שלהם לשאילתת משתמש, ומציגים את האחזור המאובטח והיעיל של מידע רלוונטי.
הערה: יבוא שנאים אם עדיין לא השתמשת ב: !pip התקנת שנאים
import torch
from transformers import GPT2Tokenizer, GPT2Model
from sklearn.metrics.pairwise import cosine_similarity # Loading GPT2 model and its tokenizer
model_name = "gpt2" tokenizer = GPT2Tokenizer.from_pretrained(model_name)
tokenizer.pad_token = "[PAD]" model = GPT2Model.from_pretrained(model_name) # Substitute with your documents
documents = [ "Introducing our flagship smartphone, the XYZ Model X.", "This cutting-edge device is designed to redefine your mobile experience.", "With a 108MP camera, it captures stunning photos and videos in any lighting condition.", "The AI-powered processor ensures smooth multitasking and gaming performance. ", "The large AMOLED display delivers vibrant visuals, and the 5G connectivity offers blazing-fast internet speeds.", "Experience the future of mobile technology with the XYZ Model X.",
] # Substitute with your query
query = "Could you provide detailed specifications and user reviews for the XYZ Model X smartphone, including its camera features and performance?" # Creating embeddings for documents and query
def create_embeddings(texts): inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True) with torch.no_grad(): outputs = model(**inputs) embeddings = outputs.last_hidden_state.mean(dim=1).numpy() return embeddings # Passing documents and query to create_embeddings function to create embeddings
document_embeddings = create_embeddings(documents)
query_embedding = create_embeddings(query) # Reshape embeddings to 2D arrays
document_embeddings = document_embeddings.reshape(len(documents), -1)
query_embedding = query_embedding.reshape(1, -1) # Calculate cosine similarities between query and documents
similarities = cosine_similarity(query_embedding, document_embeddings)[0] # Rank and display the results
results = [(document, score) for document, score in zip(documents, similarities)]
results.sort(key=lambda x: x[1], reverse=True) print("Search Results:")
for i, (result_doc, score) in enumerate(results, start=1): print(f"{i}. Document: {result_doc}n Similarity Score: {score:.4f}")

מגמות עתידיות: אחזור מודעת להקשר
שילוב של מודלים גדולים יותר של שפה
העתיד מבטיח שילוב של דגמי שפה גדולים עוד יותר במערכות אחזור מסמכים. מודלים העולים על קנה המידה של GPT-2 נמצאים באופק, ומציעים הבנת שפה והבנת מסמכים שאין שני להם. ענקיות אלו יאפשרו אחזור מדויק יותר ומודע יותר להקשר, ולשפר את איכות תוצאות החיפוש.
תמיכה בתוכן רב-מודאלי
שליפת מסמכים אינה מוגבלת עוד לטקסט בלבד. העתיד טומן בחובו שילוב של תוכן רב-מודאלי, הכולל טקסט, תמונות, אודיו ווידאו. מערכות אחזור יצטרכו להסתגל לטיפול בסוגי נתונים מגוונים אלה, ולהציע חווית משתמש עשירה יותר. הקוד שלנו, עם התמקדות ביעילות ואופטימיזציה, סולל את הדרך לשילוב חלק של יכולות אחזור מולטי-מודאליות.
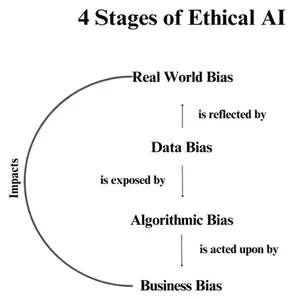
שיקולים אתיים והפחתת הטיה
ככל שמערכות אחזור מסמכים מתקדמות במורכבותן, שיקולים אתיים מופיעים כמוקד מרכזי. ההכרח של השגת תוצאות אחזור שוויוניות וחסרות פניות הופך להיות בעל חשיבות עליונה. פיתוחים עתידיים יתרכזו בשימוש באסטרטגיות הפחתת הטיה, קידום שקיפות ושמירה על עקרונות בינה מלאכותית אחראית. הקוד שבדקנו מניח את הבסיס לבניית מערכות אחזור אתיות המדגישות הוגנות וחוסר משוא פנים בגישה למידע.
סיכום
לסיכום, האיחוד של GPT-2 ו-LLAMAINDEX מציע דרך מבטיחה לשיפור תהליכי אחזור מסמכים. להתאמה דינמית זו יש פוטנציאל לחולל מהפכה בדרך שבה אנו ניגשים למידע טקסטואלי ומתקשרים איתו. משמירה על הפרטיות ועד למתן תוצאות מודעות להקשר, הכוח המשותף של טכנולוגיות אלו פותח דלתות להמלצות מותאמות אישית ואחזור נתונים מאובטח. ככל שאנו יוצאים לעתיד, חיוני לאמץ את המגמות המתפתחות, כגון מודלים של שפה גדולים יותר, תמיכה בסוגי מדיה מגוונים ושיקולים אתיים, כדי להבטיח שמערכות אחזור מסמכים ימשיכו להתפתח בהרמוניה עם הנוף המשתנה של גישה למידע .
המנות העיקריות
- המאמר מדגיש את מינוף ה-GPT-2 ו-LLAMAINDEX, ספריית קוד פתוח המיועדת לטיפול מאובטח בנתונים. ההבנה כיצד שתי הטכנולוגיות הללו יכולות לעבוד יחד היא חיונית לאחזור מסמכים יעיל ומאובטח.
- יישום הקוד שסופק מציג כיצד להשתמש ב-GPT-2 כדי ליצור הטמעות מסמכים ולדרג מסמכים על סמך הדמיון שלהם לשאילתת משתמש. זכור את השלבים העיקריים הכרוכים בקוד זה כדי ליישם טכניקות דומות על משימות אחזור המסמכים שלך.
- הישאר מעודכן לגבי הנוף המתפתח של אחזור מסמכים. זה כולל שילוב של מודלים שפה גדולים עוד יותר, תמיכה בעיבוד תוכן רב-מודאלי (טקסט, תמונות, אודיו, וידאו), והחשיבות הגוברת של שיקולים אתיים והפחתת הטיה במערכות אחזור.
שאלות נפוצות
ת1: ניתן לכוונן עדין את LLAMAINDEX על נתונים רב לשוניים, מה שמאפשר לו לבצע אינדקס ולחפש ביעילות תוכן במספר שפות.
ת2: כן, בעוד LLAMAINDEX היא חדשה יחסית, ספריות קוד פתוח כמו Hugging Face Transformers יכולות להתאים למטרה זו.
ת3: כן, ניתן להרחיב את LLAMAINDEX לעיבוד ואינדקס תוכן מולטימדיה על ידי מינוף טכניקות תמלול והטמעה של אודיו ווידאו.
A4: LLAMAINDEX יכול לשלב טכניקות לשמירה על הפרטיות, כגון למידה מאוחדת, כדי להגן על נתוני המשתמש ולהבטיח אבטחת מידע.
ת5: הטמעת LLAMAINDEX יכולה להיות אינטנסיבית מבחינה חישובית, ודורשת גישה ל-GPUs או TPUs רבי עוצמה, אך פתרונות מבוססי ענן יכולים לסייע בהפחתת אילוצי משאבים אלו.
הפניות
- Brown, TB, Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). מודלים של שפה הם לומדים ריבוי משימות ללא פיקוח. arXiv preprint arXiv:2005.14165.
- תיעוד LlamaIndex. תיעוד רשמי עבור LlamaIndex.
- OpenAI. (2019). GPT-2: דוגמנות שפה ללא פיקוח ב-Python. מאגר GitHub.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, AN, … & Polosukhin, I. (2017). תשומת לב היא כל מה שאתה צריך. בהתקדמות במערכות עיבוד מידע עצבי (עמ' 30-38).
- Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., … & Gebru, T. (2019). כרטיסי דגם לדיווח דגמים. בהליכי הכנס בנושא הגינות, אחריות ושקיפות (עמ' 220-229).
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). שיפור הבנת השפה על ידי אימון מקדים גנרטיבי.
- OpenAI. (2023). InstructGPT API תיעוד.
המדיה המוצגת במאמר זה אינה בבעלות Analytics Vidhya והיא משמשת לפי שיקול דעתו של המחבר.
מוצרים מקושרים
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.analyticsvidhya.com/blog/2023/09/leveraging-gpt-2-and-llamaindex/
- :יש ל
- :הוא
- :לֹא
- :איפה
- ][עמ'
- 1
- 10
- 16
- 2005
- 2017
- 2018
- 2019
- 2020
- 2023
- 2D
- 5G
- 9
- a
- יכולת
- אודות
- גישה
- דין וחשבון
- השגתי
- לרוחב
- להסתגל
- מותאם
- לקדם
- התקדמות
- AI
- מונע AI
- AL
- תעשיות
- לבד
- כְּבָר
- an
- ניתוח
- אנליטיקה וידיה
- ו
- כל
- API
- החל
- ארכיטקטורה
- ARE
- מערך
- מאמר
- AS
- שאל
- At
- תשומת לב
- אודיו
- מחבר
- זמין
- שדרה
- לחכות
- b
- מבוסס
- בסיס
- BE
- להיות
- הופך להיות
- לפני
- בֵּין
- הטיה
- בלוגתון
- מתגאה
- התמוטטות
- רחב
- נבנה
- אבל
- by
- לחשב
- חדר
- CAN
- יכולות
- לוכדת
- כרטיסים
- מֶרכָּזִי
- האתגרים
- משתנה
- קוד
- שיתוף פעולה
- אוסף
- לשלב
- השלמה
- מורכבות
- להתרכז
- מסקנה
- מצב
- כנס
- קישוריות
- שיקולים
- מוגבל
- אילוצים
- בנייה
- תוכן
- קשר
- להמשיך
- ליבה
- אבן פינה
- יכול
- לִיצוֹר
- יוצרים
- מכריע
- שיא הטכנולוגיה
- נתונים
- אבטחת מידע
- התמודדות
- אספקה
- מספק
- להתעמק
- מדגים
- עיצוב
- מעוצב
- מְפוֹרָט
- מפותח
- התפתחויות
- מכשיר
- שיקול דעת
- לְהַצִיג
- שונה
- מסמך
- תיעוד
- מסמכים
- עושה
- תחומים
- דלתות
- דינמי
- E&T
- יעילות
- יְעִילוּת
- יְעִילוּת
- יעיל
- יעילות
- הטבעה
- לחבק
- לצאת
- להדגיש
- העצמה
- לאפשר
- מה שמאפשר
- להקיף
- מקיף
- שיפור
- לְהַבטִיחַ
- מבטיח
- הוֹגֶן
- במיוחד
- חיוני
- מקימים
- Ether (ETH)
- אֶתִי
- אֲפִילוּ
- להתפתח
- מתפתח
- דוגמה
- ניסיון
- חקירה
- פָּנִים
- הגינות
- תכונות
- שדה
- מתאים
- דגל
- להתמקד
- בעד
- כוחות
- החל מ-
- פונקציה
- היתוך
- עתיד
- ההתפתחויות העתידיות
- המשחקים
- gebru
- יצירת
- דור
- גנרטטיבית
- ענק
- ענקים
- GitHub
- גומז
- GPUs
- פורץ דרך
- עבודות קרקע
- גדל
- לטפל
- טיפול
- הרמוניה
- יש
- לעזור
- פסים
- מחזיק
- אופק
- איך
- איך
- HTTPS
- האצ'ינסון
- i
- if
- תמונה
- תמונות
- הֶכְרֵחִי
- הפעלה
- יישום
- לייבא
- חשיבות
- שיפור
- in
- כולל
- כולל
- בע"מ
- גדל
- מדד
- מידע
- הודעה
- תשומות
- תובנות
- להתקין
- שילוב
- השתלבות
- אינטראקציה
- אינטרנט
- אל תוך
- הציג
- החדרה
- לֹא יְסוּלֵא בְּפָּז
- מעורב
- IT
- שֶׁלָה
- עצמו
- ג'ונס
- מפתח
- נוף
- שפה
- שפות
- גָדוֹל
- גדול יותר
- מניח
- למידה
- מנופים
- מינוף
- ספריות
- סִפְרִיָה
- תְאוּרָה
- כמו
- מגבלות
- מוגבל
- האזנה
- טוען
- עוד
- מדיה
- בינוני
- מדדים
- להקל
- הֲקָלָה
- סלולרי
- טכנולוגיה ניידת
- מודל
- דוגמנות
- מודלים
- מודרני
- יותר
- מולטימדיה
- מספר
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- צורך
- רשת
- עצביים
- רשת עצבית
- NeurIPS
- לעולם לא
- חדש
- NLP
- לא
- אוקיינוסים
- of
- מוצע
- הצעה
- המיוחדות שלנו
- רשמי
- on
- עַל גַבֵּי
- קוד פתוח
- OpenAI
- נפתח
- אופטימיזציה
- or
- מְקוֹרִי
- שלנו
- תוצאות
- תפוקה
- להתגבר על
- שֶׁלוֹ
- בבעלות
- נתיב
- זיווג
- הגדול ביותר
- חלק
- חולף
- ביצועים
- אישי
- מידע אישי
- אישית
- תמונות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- פוטנציאל
- כּוֹחַ
- חזק
- צורך
- עקרונות
- פְּרָטִיוּת
- הליכים
- תהליך
- תהליכים
- תהליך
- מעבד
- המוצר
- מבטיח
- מבטיח
- קידום
- להגן
- לספק
- ובלבד
- תְעוּזָה
- לאור
- מטרה
- פיתון
- איכות
- לדרג
- מדורג
- דירוג
- המלצות
- הגדר מחדש
- מערכות יחסים
- יחסית
- רלוונטי
- ראוי לציון
- לזכור
- דווח
- מאגר
- דרישות
- לעצב מחדש
- משאב
- אחראי
- תוצאות
- לַחֲזוֹר
- חוות דעת של לקוחותינו
- לְחוֹלֵל מַהְפֵּכָה
- חוללה מהפכה
- s
- שְׁמִירָה
- סולם
- סצינה
- מדע
- ציון
- בצורה חלקה
- חיפוש
- לבטח
- מאובטח
- אבטחה
- צוּרָה
- לראווה
- הראה
- דומה
- הדמיון
- פשוט
- יחיד
- טלפון חכם
- להחליק
- פתרונות
- מקור
- מרחבית
- מפרטים
- מהירויות
- שלבים
- עומד
- צעדים
- פשוט
- אסטרטגיות
- מדהים
- כזה
- תמיכה
- מְצוּיָן
- מערכות
- T
- המשימות
- משימות
- טכניקות
- טכנולוגיות
- טכנולוגיה
- טֶקסט
- דור טקסט
- טקסטואלית
- זֶה
- השמיים
- העתיד
- העולם
- שֶׁלָהֶם
- אותם
- אז
- שם.
- אלה
- זֶה
- דרך
- ל
- יַחַד
- כלי
- כלים
- לפיד
- מסורתי
- לשנות
- טרנספורמציה
- שנאי
- רוֹבּוֹטרִיקִים
- תרגום
- שקיפות
- מגמות
- תור
- שתיים
- סוגים
- להבין
- הבנה
- בניגוד
- ללא תחרות
- חשפה
- על
- להשתמש
- מְשׁוּמָשׁ
- משתמש
- חוויית משתמש
- ביקורות משתמשים
- באמצעות
- שונים
- מיזם
- רב צדדי
- מלא חיים
- וִידֵאוֹ
- וידאו
- חזותיים
- רוצה
- היה
- דֶרֶך..
- we
- webp
- מה
- מתי
- אשר
- בזמן
- יצטרך
- עם
- תיק עבודות
- לעבוד יחד
- עוֹלָם
- wu
- X
- כן
- אתה
- זפירנט