מבוא
חילוץ מידע על מסמכים כולל שימוש באלגוריתמי מחשב כדי לחלץ נתונים מובנים (כמו שם עובד, כתובת, ייעוד, מספר טלפון וכו') ממסמכים לא מובנים או מובנים למחצה, כגון דוחות, מיילים ודפי אינטרנט. ניתן להשתמש במידע שחולץ למטרות שונות, כגון ניתוח וסיווג. DocVQA (Document Visual Question Answering) היא גישה מתקדמת המשלבת ראייה ממוחשבת וטכניקות עיבוד שפה טבעית כדי לענות באופן אוטומטי על שאלות לגבי תוכן המסמך. מאמר זה יחקור חילוץ מידע באמצעות DocVQA עם חבילת Pix2Struct של גוגל.
מטרות למידה
- שימושיות DocVQA על פני תחומים מגוונים
- אתגרים ועבודה קשורה של DocVQA
- הבן ויישם את טכניקת Pix2Struct של גוגל
- היתרון החיוני של טכניקת Pix2Struct

מאמר זה פורסם כחלק מה- בלוגאת מדע הנתונים.
תוכן העניינים
מקרה שימוש ב-DocVQA
חילוץ מסמכים מחלץ באופן אוטומטי מידע רלוונטי ממסמכים לא מובנים, כגון חשבוניות, קבלות, חוזים וטפסים. המגזר הבא ייהנה בגלל זה:
- אוצר: בנקים ומוסדות פיננסיים משתמשים בחילוץ מסמכים כדי להפוך משימות לאוטומטיות כגון עיבוד חשבוניות, עיבוד בקשות להלוואה ופתיחת חשבון. על ידי אוטומציה של משימות אלו, חילוץ מסמכים יכול להפחית שגיאות וזמני עיבוד ולשפר את היעילות.
- בריאות: בתי חולים וספקי שירותי בריאות משתמשים בחילוץ מסמכים כדי לחלץ נתוני מטופל חיוניים מהרשומות הרפואיות, כגון קודי אבחון, תוכניות טיפול ותוצאות בדיקות. זה יכול לעזור לייעל את הטיפול בחולה ולשפר את תוצאות המטופל.
- ביטוח: חברות הביטוח משתמשות בחילוץ מסמכים כדי לטפל בתביעות, בקשות לפוליסה ומסמכי חיתום. חילוץ מסמכים יכול להפחית את זמני העיבוד ולשפר את הדיוק על ידי אוטומציה של משימות אלו.
- ממשלה: סוכנויות ממשלתיות משתמשות בחילוץ מסמכים כדי לעבד כמויות גדולות של נתונים לא מובנים, כגון טפסי מס, בקשות ומסמכים משפטיים. על ידי אוטומציה של משימות אלה, חילוץ מסמכים יכול לעזור להפחית עלויות, לשפר את הדיוק ולשפר את היעילות.
- משפטי: משרדי עורכי דין ומחלקות משפטיות משתמשים בחילוץ מסמכים כדי לחלץ מידע קריטי ממסמכים משפטיים, כגון חוזים, כתבי טענות ומסמכי גילוי. זה ישפר את היעילות והדיוק במחקר משפטי ובסקירת מסמכים.
לחילוץ מסמכים יש יישומים רבים בתעשיות העוסקות בכמויות גדולות של נתונים לא מובנים. אוטומציה של משימות עיבוד מסמכים יכולה לעזור לארגונים לחסוך זמן, להפחית שגיאות ולשפר את היעילות.
אתגרים
ישנם מספר אתגרים הקשורים לחילוץ מידע מסמכים. האתגר העיקרי הוא השונות בפורמטים ובמבנים של מסמכים. לדוגמה, למסמכים שונים עשויים להיות צורות ופריסות שונות, מה שמקשה על חילוץ מידע באופן עקבי. אתגר נוסף הוא רעש בנתונים, כמו שגיאות כתיב ומידע לא רלוונטי. זה יכול להוביל לתוצאות חילוץ לא מדויקות או לא שלמות.
תהליך חילוץ מידע המסמך כולל מספר שלבים.
- הבנת מסמכים
- עיבוד מקדים של המסמכים, הכולל ניקוי והכנת הנתונים לניתוח. עיבוד מוקדם יכול לכלול הסרת עיצוב מיותר, כגון כותרות עליונות ותחתונות, והמרת הנתונים לטקסט רגיל.
- חלץ את המידע הרלוונטי מהמסמכים באמצעות שילוב של אלגוריתמים מבוססי כללים ולמידת מכונה. אלגוריתמים מבוססי כללים משתמשים בקבוצה של כללים מוגדרים מראש כדי להסיר סוגים ספציפיים של מידע, כגון שמות, תאריכים וכתובות.
- אלגוריתמים של למידת מכונה להשתמש במודלים סטטיסטיים כדי לזהות דפוסים בנתונים ולחלץ מידע רלוונטי.
- לאמת ולחדד את המידע שחולץ. זה כרוך בבדיקת דיוק המידע שחולץ וביצוע תיקונים נחוצים. שלב זה חיוני כדי להבטיח שהנתונים שחולצו יהיו אמינים במדויק לניתוח נוסף.
חוקרים מפתחים אלגוריתמים וטכניקות חדשות למיצוי מידע מסמכים כדי להתמודד עם אתגרים אלו. אלה כוללים טכניקות לטיפול בשונות במבני מסמכים, כגון שימוש באלגוריתמי למידה עמוקה ללימוד מבני מסמכים באופן אוטומטי. הם כוללים גם טכניקות לטיפול בנתונים רועשים, כגון שימוש טכניקות עיבוד שפה טבעית לזהות ולתקן שגיאות כתיב.
DocVQA ראשי תיבות של Document Visual Question Answering. זוהי משימה בראייה ממוחשבת ועיבוד שפה טבעית שמטרתה לענות על שאלות לגבי התוכן של תמונת מסמך נתונה. השאלות יכולות להיות על כל היבט של טקסט המסמך. DocVQA היא משימה מאתגרת מכיוון שהיא דורשת הבנת התוכן החזותי של המסמך ויכולת לקרוא ולהבין את הטקסט שבו. למשימה זו יש יישומים רבים בעולם האמיתי, כגון אחזור מסמכים, חילוץ מידע וכו'.
LayoutLM, Flan-T5 וסופגנייה
LayoutLM, Flan-T5 ו-Donut הן שלוש גישות לניתוח פריסת מסמכים וזיהוי טקסט עבור מענה חזותי של מסמכים (DOCVQA).
זהו מודל שפה מיומן מראש המשלב מידע חזותי כגון פריסת מסמך, מיקומי טקסט OCR ותוכן טקסטואלי. ניתן לכוונן את LayoutLM למשימות NLP שונות, כולל DOCVQA. לדוגמה, LayoutLM ב-DOCVQA יכולה לסייע באיתור מדויק של הטקסט הרלוונטי של המסמך ואלמנטים ויזואליים אחרים, אשר חיוניים למענה על שאלות הדורשות מידע ספציפי להקשר.
Flan-T5 היא שיטה המשתמשת בארכיטקטורה מבוססת שנאים לביצוע הן זיהוי טקסט והן ניתוח פריסה. מודל זה מאומן מקצה לקצה על תמונות מסמכים ויכול להתמודד עם מסמכים רב לשוניים, מה שהופך אותו למתאים ליישומים שונים. לדוגמה, שימוש ב-Flan-T5 ב-DOCVQA מאפשר זיהוי טקסט וניתוח פריסה מדויקים, שיכולים לעזור לשפר את ביצועי המערכת.
דונאט הוא מודל למידה עמוקה המשתמש בארכיטקטורה חדשנית לביצוע זיהוי טקסט במסמכים עם פריסות לא סדירות. השימוש ב-Donut ב-DOCVQA יכול לסייע בחילוץ מדויק של טקסט ממסמכים בעלי פריסות מורכבות, דבר חיוני למענה על שאלות הדורשות מידע ספציפי. היתרון המשמעותי הוא שהוא נטול OCR.
בסך הכל, שימוש במודלים אלו ב-DOCVQA יכול לשפר את הדיוק והביצועים של המערכת על ידי חילוץ מדויק של טקסט ומידע רלוונטי אחר מתמונות המסמך. אנא עיין בבלוגים הקודמים שלי סופגניהו FLAN -T5 ו-LAYOUTLM.

<h2 id="Pix2Struct
העיתון מציג Pix2Struct מ-Google, מודל תמונה לטקסט מאומן מראש להבנת שפה הממוקמת חזותית. המודל מאומן באמצעות טכניקת הלמידה החדשה כדי לנתח צילומי מסך מכוסים של דפי אינטרנט לתוך HTML פשוט, מה שמספק מקור נתוני אימון מקדים המתאים באופן משמעותי למגוון הפעילויות במורד הזרם. בנוסף לאסטרטגיית ההכשרה החדשה, המאמר מציג אינטגרציה גמישה יותר של תשומות לשוניות וחזותיות וייצוג קלט ברזולוציה משתנה. כתוצאה מכך, המודל משיג תוצאות מתקדמות בשש מתוך תשע משימות ב-4 תחומים כמו מסמכים, איורים, ממשקי משתמש ותמונות טבעיות. הבאים תמונה מציג את הפרטים לגבי הדומיינים הנחשבים. (התמונה למטה נמצאת בעמוד החמישי של pix5struct עבודת מחקר)
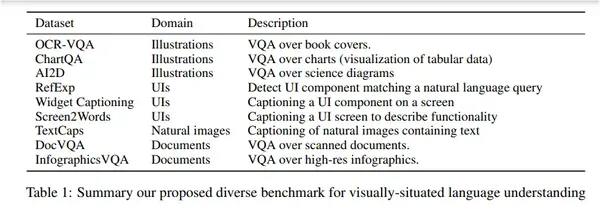
Pix2Struct הוא מודל מאומן מראש המשלב את הפשטות של קלט ברמת הפיקסלים בלבד עם הכלליות והמדרוג הניתנים על ידי אימון מקדים בפיקוח עצמי מנתוני אינטרנט מגוונים ושופעים. המודל עושה זאת על ידי המלצה על מטרת ניתוח של צילום מסך שצריכה לחזות ניתוח מבוסס HTML מתוך צילום מסך של דף אינטרנט שהוסווה חלקית. עם הגיוון והמורכבות של אלמנטים טקסטואליים וויזואליים שנמצאים באינטרנט, Pix2Struct לומדת ייצוגים עשירים של המבנה הבסיסי של דפי אינטרנט, שיכולים לעבור ביעילות למשימות שונות של הבנת שפה חזותית במורד הזרם.
Pix2Struct מבוסס על Vision Transformer (ViT), דגם של מקודד-תמונות-מפענח טקסט. עם זאת, Pix2Struct מציע שינוי קטן אך משפיע על ייצוג הקלט כדי להפוך את המודל לחזק יותר לצורות שונות של שפה הממוקמת חזותית. ViT סטנדרטי מחלץ תיקונים בגודל קבוע לאחר שינוי קנה מידה של תמונות קלט לרזולוציה קבועה מראש. זה מעוות את יחס הגובה-רוחב המתאים של התמונה, שיכול להיות משתנה מאוד עבור מסמכים, ממשק משתמש נייד ודמויות.
כמו כן, העברת מודלים אלה למשימות במורד הזרם עם רזולוציה גבוהה יותר היא מאתגרת, שכן המודל צופה ברזולוציה ספציפית אחת בלבד במהלך אימון מקדים. Pix2Struct מציע לשנות את קנה המידה של תמונת הקלט למעלה או למטה כדי לחלץ את המספר המרבי של טלאים שמתאימים באורך הרצף הנתון. גישה זו חזקה יותר ביחסי גובה-רוחב קיצוניים, הנפוצים בתחומים שבהם Pix2Struct מתנסים. בנוסף, הדגם יכול להתמודד עם שינויים תוך כדי תנועה באורך וברזולוציה של הרצף. כדי לטפל ברזולוציות משתנות באופן חד משמעי, נעשה שימוש בהטבעות מיקום אבסולוטי דו-ממדי עבור תיקוני הקלט.
Pix2Struct מספקת שני דגמים
- דגם בסיס: google/pix2struct-docvqa-base (~ 1.3 GB)
- דגם גדול: google/pix2struct-docvqa-large (~ 5.4 GB)
תוצאות
דגם Pix2Struct-Large עלה על דגם הדונאט המתקדם ביותר ב- DocVQA מערך נתונים. מודל LayoutLMv3 משיג ביצועים גבוהים במשימה זו באמצעות שלושה רכיבים, כולל מערכת OCR ומקודדים מאומנים מראש. עם זאת, מודל Pix2Struct מתפקד בצורה תחרותית ללא שימוש בנתוני אימון מקדים בתוך התחום ומסתמך אך ורק על ייצוגים חזותיים. (אנו מתייחסים רק לתוצאות DocVQA.)
יישום
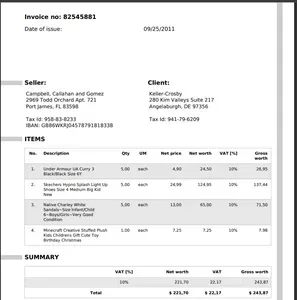
תן לנו לעבור על ההטמעה של DocVQA. למטרת ההדגמה, הבה נבחן את החשבונית לדוגמה מנדלי דאטה.
1. התקן את החבילות
!pip install git+https://github.com/huggingface/transformers pdf2image
!sudo apt install poppler-utils12diff2. ייבא את החבילות
from pdf2image import convert_from_path, convert_from_bytes
import torch
from functools import partial
from PIL import Image
from transformers import Pix2StructForConditionalGeneration as psg
from transformers import Pix2StructProcessor as psp3. אתחל את הדגם עם משקולות מאומנות מראש
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model = psg.from_pretrained("google/pix2struct-docvqa-large").to(DEVICE)
processor = psp.from_pretrained("google/pix2struct-docvqa-large")4. פונקציות עיבוד
def generate(model, processor, img, questions): inputs = processor(images=[img for _ in range(len(questions))], text=questions, return_tensors="pt").to(DEVICE) predictions = model.generate(**inputs, max_new_tokens=256) return zip(questions, processor.batch_decode(predictions, skip_special_tokens=True)) def convert_pdf_to_image(filename, page_no): return convert_from_path(filename)[page_no-1]
5. ציין את הנתיב המדויק ומספר העמוד עבור קובץ PDF.
questions = ["what is the seller name?", "what is the date of issue?", "What is Delivery address?", "What is Tax Id of client?"]
FILENAME = "/content/invoice_107_charspace_108.pdf"
PAGE_NO = 1
6. הפק את התשובות
image = convert_pdf_to_image(FILENAME, PAGE_NO)
print("pdf to image conversion complete.")
generator = partial(generate, model, processor)
completions = generator(image, questions)
for completion in completions: print(f"{completion}") ## answers
('what is the seller name?', 'Campbell, Callahan and Gomez')
('what is the date of issue?', '09/25/2011')
('What is Delivery address?', '2969 Todd Orchard Apt. 721')
('What is Tax Id of client?', '941-79-6209')נסה את הדוגמה שלך על פנים מחבקות רווחים.
מחברות: pix2struck מחברה
סיכום
לסיכום, מיצוי מידע על מסמכים הוא תחום מחקר חיוני עם יישומים בתחומים רבים. זה כרוך בשימוש באלגוריתמים ממוחשבים כדי לזהות ולחלץ מידע רלוונטי ממסמכים מבוססי טקסט. למרות שמספר אתגרים קשורים למיצוי מידע מסמכים, חוקרים מפתחים אלגוריתמים וטכניקות חדשות להתמודדות עם אתגרים אלו ולשפר את הדיוק והאמינות של המידע שחולץ.
עם זאת, כמו לכל מודלים של למידה עמוקה, ל-DocVQA יש כמה מגבלות. לדוגמה, זה דורש הרבה נתוני אימון כדי לבצע ביצועים טובים ואולי צריך עזרה עם מסמכים מורכבים או סמלים ופונטים נדירים. זה עשוי להיות רגיש גם לאיכות תמונת הקלט ולדיוק של מערכת OCR (זיהוי תווים אופטי) המשמשת לחילוץ טקסט מהמסמך.
המנות העיקריות
- ה-pix2struct עובד היטב כדי להבין את ההקשר תוך כדי תשובה.
- ה-pix2struct הוא הדגם העדכני ביותר של DocVQA.
- אין צורך במנוע OCR חיצוני ספציפי.
- ה-pix2struct עובד טוב יותר בהשוואה ל-DONUT עבור הנחיות דומות.
- ניתן להשתמש ב-pix2struct עבור מענה על שאלות טבלאות.
- הסקת המעבד תהיה איטית יותר (~ 1 דקה/שאלה אחת). את הדגם הגדול יותר ניתן לטעון לתוך 1GB RAM.
כדי ללמוד עוד על זה, אנא צור קשר ב- Linkedin. נא לאשר אם אתה מצטט מאמר זה או מאגר זה.
התייחסות
- https://unsplash.com/photos/lbO1iCnbTW0
- https://unsplash.com/photos/zwd435-ewb4
- https://arxiv.org/pdf/2210.03347.pdf
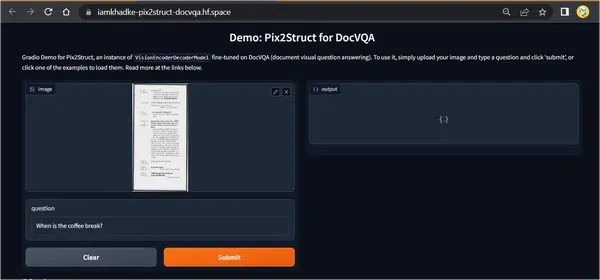
- https://iamkhadke-pix2struct-docvqa.hf.space/
- https://arxiv.org/abs/2007.00398
- https://data.mendeley.com/
המדיה המוצגת במאמר זה אינה בבעלות Analytics Vidhya והיא משמשת לפי שיקול דעתו של המחבר.
מוצרים מקושרים
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- הטבעת העתיד עם אדריאן אשלי. גישה כאן.
- מקור: https://www.analyticsvidhya.com/blog/2023/04/document-information-extraction-using-pix2struct/
- :יש ל
- :הוא
- :לֹא
- $ למעלה
- 1
- 1.3
- a
- יכולת
- אודות
- בנוגע לזה
- מוּחלָט
- שופע
- חֶשְׁבּוֹן
- דיוק
- מדויק
- במדויק
- משיגה
- הודה
- לרוחב
- פעילויות
- תוספת
- בנוסף
- כתובת
- כתובות
- יתרון
- לאחר
- סוכנויות
- מטרות
- אלגוריתמים
- תעשיות
- מאפשר
- גם
- למרות
- an
- אנליזה
- ניתוח
- אנליטיקה וידיה
- ו
- אחר
- לענות
- תשובות
- כל
- בקשה
- יישומים
- גישה
- גישות
- APT
- ארכיטקטורה
- ARE
- AREA
- מאמר
- AS
- אספקט
- המשויך
- At
- אוטומטי
- באופן אוטומטי
- אוטומציה
- בנקים
- מבוסס
- BE
- כי
- היה
- להלן
- תועלת
- מוטב
- בלוגים
- שניהם
- אבל
- by
- CAN
- אשר
- לאתגר
- האתגרים
- אתגר
- שינוי
- שינויים
- אופי
- זיהוי תווים
- לבדוק
- בדיקה
- טענות
- מיון
- ניקוי
- לקוחות
- קופונים
- שילוב
- משלב
- שילוב
- Common
- חברות
- לעומת
- להשלים
- השלמה
- מורכב
- מורכבות
- רכיבים
- לִהַבִין
- המחשב
- ראייה ממוחשבת
- מסקנה
- לשקול
- נחשב
- צור קשר
- תוכן
- הקשר
- חוזים
- המרה
- תיקונים
- עלויות
- CPU
- קריטי
- שיא הטכנולוגיה
- נתונים
- תַאֲרִיך
- תאריכים
- עסקה
- עמוק
- למידה עמוקה
- מסירה
- הַדגָמָה
- מחלקות
- מינוי
- פרט
- מתפתח
- מכשיר
- אחר
- קשה
- תגלית
- שיקול דעת
- שונה
- גיוון
- מסמך
- מסמכים
- עושה
- תחומים
- מטה
- בְּמַהֲלָך
- יעילות
- יְעִילוּת
- אלמנטים
- מיילים
- עובד
- מקצה לקצה
- מנוע
- לְהַבטִיחַ
- שגיאות
- חיוני
- וכו '
- Ether (ETH)
- דוגמה
- לחקור
- חיצוני
- תמצית
- הוֹצָאָה
- תמציות
- קיצוני
- פָּנִים
- דמויות
- שלח
- כספי
- גופים פיננסיים
- חברות
- מתאים
- גמיש
- הבא
- גופנים
- בעד
- צורות
- מצא
- החל מ-
- נוסף
- ליצור
- גנרטור
- לקבל
- נתן
- גומז
- גוגל
- ממשלה
- לטפל
- טיפול
- יש
- כותרות
- בריאות
- לעזור
- גָבוֹהַ
- גבוה יותר
- מאוד
- בתי חולים
- אולם
- HTML
- HTTPS
- חיבוק פנים
- ID
- לזהות
- if
- תמונה
- תמונות
- בר - השפעה
- ליישם
- הפעלה
- לייבא
- לשפר
- in
- לֹא מְדוּיָק
- לכלול
- כולל
- שילוב
- תעשיות
- מידע
- מיצוי מידע
- קלט
- להתקין
- מוסדות
- ביטוח
- השתלבות
- ממשקים
- אל תוך
- מציג
- מבוא
- עיבוד חשבוניות
- כרוך
- סוגיה
- IT
- שפה
- גָדוֹל
- גדול יותר
- האחרון
- חוק
- - עורכי דין
- מערך
- עוֹפֶרֶת
- לִלמוֹד
- למידה
- משפטי
- אורך
- כמו
- מגבלות
- לינקדין
- להלוות
- מגרש
- גדול
- לעשות
- עשייה
- רב
- מקסימום
- מאי..
- מדיה
- רפואי
- שיטה
- סלולרי
- מודל
- מודלים
- יותר
- שם
- שמות
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- NAV
- הכרחי
- צורך
- צרכי
- חדש
- NLP
- רעש
- רומן
- מספר
- רב
- מטרה
- מתבונן
- OCR
- of
- on
- ONE
- רק
- פתיחה
- אופטי
- זיהוי תווים אופטי
- or
- ארגונים
- אחר
- הַחוּצָה
- בבעלות
- חבילה
- עמוד
- מאמר
- חלק
- טלאים
- נתיב
- חולה
- טיפול בחולה
- נתוני מטופלים
- דפוסי
- לבצע
- ביצועים
- מבצע
- טלפון
- תמונה
- מישור
- תוכניות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- אנא
- מדיניות
- עמדות
- ניבוי
- התחזיות
- העריכה
- קודם
- תהליך
- תהליך
- מעבד
- תָקִין
- מציע
- ובלבד
- ספקים
- מספק
- מתן
- PSG
- לאור
- אַך וְרַק
- מטרה
- למטרות
- איכות
- שאלה
- שאלות
- RAM
- רכס
- נדיר
- יחס
- יחסים
- חומר עיוני
- עולם אמיתי
- קבלות
- הכרה
- ממליץ
- רשום
- להפחית
- לחדד
- קָשׁוּר
- רלוונטי
- אמינות
- אָמִין
- להסיר
- הסרת
- דוחות לדוגמא
- נציגות
- לדרוש
- נדרש
- דורש
- מחקר
- חוקרים
- החלטה
- תוצאה
- תוצאות
- לַחֲזוֹר
- סקירה
- עשיר
- חָסוֹן
- כללי
- שמור
- בקרת מערכות ותקשורת
- סולם
- דרוג
- מדע
- צילומי מסך
- מגזר
- רגיש
- רצף
- סט
- כמה
- הראה
- משמעותי
- באופן משמעותי
- דומה
- פשטות
- פשוט
- שישה
- קטן
- כמה
- מָקוֹר
- מֶרחָב
- ספציפי
- תֶקֶן
- עומד
- מדינה-of-the-art
- סטטיסטי
- שלב
- צעדים
- אִסטרָטֶגִיָה
- לייעל
- מִבְנֶה
- מובנה
- כזה
- מַתְאִים
- מערכת
- המשימות
- משימות
- מס
- טכניקות
- מבחן
- זיהוי טקסט
- זֶה
- השמיים
- אלה
- הֵם
- זֶה
- שְׁלוֹשָׁה
- דרך
- זמן
- פִּי
- ל
- לפיד
- מְאוּמָן
- הדרכה
- להעביר
- מעביר
- רוֹבּוֹטרִיקִים
- טיפול
- סוגים
- בְּסִיסִי
- להבין
- הבנה
- חיתום
- us
- להשתמש
- מְשׁוּמָשׁ
- משתמש
- באמצעות
- לנצל
- שונים
- חזון
- חיוני
- כרכים
- היה
- we
- אינטרנט
- טוֹב
- מה
- מה
- אשר
- בזמן
- יצטרך
- עם
- בתוך
- לְלֹא
- תיק עבודות
- עובד
- היה
- אתה
- זפירנט