מודלים של למידת מכונה הפכו למרכיב אינטגרלי בקבלת החלטות בתעשיות מרובות, אך לעתים קרובות הם נתקלים בקושי כאשר מתמודדים עם מערכי נתונים רועשים או מגוונים. זה המקום שבו למידת אנסמבל נכנסת לתמונה.
מאמר זה יבטל את המיסטי של למידת האנסמבל ויציג בפניכם את אלגוריתם היער האקראי החזק שלו. לא משנה אם אתה מדען נתונים המחפש לחדד את ערכת הכלים שלך או מפתח המחפש תובנות מעשיות לבניית מודלים חזקים של למידת מכונה, היצירה הזו מיועדת לכולם!
עד סוף מאמר זה, תקבלו ידע מעמיק בלימוד אנסמבל וכיצד פועלים יערות אקראיים בפייתון. אז בין אם אתה מדען נתונים מנוסה או פשוט סקרן להרחיב את יכולות למידת המכונה שלך, הצטרף אלינו להרפתקה זו וקדם את מומחיות למידת המכונה שלך!
למידת אנסמבל היא גישת למידת מכונה שבה תחזיות ממספר מודלים חלשים משולבים זה בזה כדי לקבל תחזיות חזקות יותר. הרעיון מאחורי למידת אנסמבל הוא הפחתת ההטיה והטעויות ממודלים בודדים על ידי מינוף כוח הניבוי של כל מודל.
כדי לקבל דוגמה טובה יותר, בואו ניקח דוגמה לחיים, דמיינו שראיתם חיה ואינכם יודעים לאיזה מין חיה זו שייכת. אז במקום לשאול מומחה אחד, אתה שואל עשרה מומחים ותקבל את ההצבעה של רובם. זה ידוע בשם הצבעה קשה.
הצבעה קשה הוא כאשר אנו לוקחים בחשבון את תחזיות המחלקות עבור כל מסווג ולאחר מכן מסווגים קלט על סמך מספר ההצבעות המקסימלי למחלקה מסוימת. מצד שני, הצבעה רכה הוא כאשר אנו לוקחים בחשבון את תחזיות ההסתברות עבור כל מחלקה על ידי כל מסווג ולאחר מכן מסווגים קלט למחלקה עם הסתברות מקסימלית בהתבסס על ההסתברות הממוצעת (בממוצע על פני ההסתברויות של המסווגן) עבור אותה מחלקה.
למידת אנסמבל משמשת תמיד לשיפור ביצועי המודל הכוללת שיפור דיוק הסיווג והקטנת השגיאה המוחלטת הממוצעת עבור מודלים של רגרסיה. בנוסף לאנסמבל זה, הלומדים תמיד מניבים מודל יציב יותר. לומדי אנסמבל עובדים במיטבם כאשר המודלים אינם מתואמים אז כל מודל יכול ללמוד משהו ייחודי ולעבוד על שיפור הביצועים הכוללים.
למרות שניתן ליישם למידה אנסמבלית בדרכים רבות, אולם כאשר מדובר ביישום לתרגול ישנן שלוש אסטרטגיות שזכו לפופולריות רבה בשל היישום והשימוש הקלים שלהן. שלושת האסטרטגיות הללו הן:
- תיק: Bagging שהיא קיצור של bootstrap aggregation היא אסטרטגיית למידה אנסמבלית שבה המודלים מאומנים באמצעות דגימות אקראיות של מערך הנתונים.
- הערמה: Stacking שהיא קיצור של Stacked Generalization היא אסטרטגיית למידה אנסמבלית שבה אנו מאמנים מודל לשילוב מודלים מרובים שאומנו על הנתונים שלנו.
- הגברת: Boosting היא טכניקת למידה אנסמבלית המתמקדת בבחירת הנתונים המסווגים שגויים לאימון המודלים עליהם.
בואו נצלול עמוק יותר לתוך כל אחת מהאסטרטגיות הללו ונראה כיצד נוכל להשתמש ב-Python כדי לאמן את המודלים הללו במערך הנתונים שלנו.
אגירה לוקחת דגימות אקראיות של נתונים, ומשתמשת באלגוריתמי למידה ובממוצע כדי למצוא הסתברויות אגירה; ידוע גם בשם צבירה של bootstrap; הוא אוסף תוצאות ממספר מודלים כדי לקבל תוצאה אחת רחבה.
גישה זו כוללת:
- פיצול מערך הנתונים המקורי למספר קבוצות משנה עם החלפה.
- פתח מודלים בסיסיים עבור כל אחת מתת-הקבוצות הללו.
- הפעלת כל הדגמים במקביל לפני הפעלת כל התחזיות כדי לקבל תחזיות סופיות.
Scikit-ללמוד מספק לנו את היכולת ליישם גם א BaggingClassifier ו BaggingRegressor. BaggingMetaEstimator מזהה תת-קבוצות אקראיות של מערך נתונים מקורי כדי להתאים לכל מודל בסיס, ואז צובר תחזיות מודל בסיס בודדים? -?או באמצעות הצבעה או ממוצע?-?לניבוי סופי על-ידי צבירת תחזיות מודל בסיס בודדים לחיזוי מצטבר באמצעות הצבעה או ממוצע . שיטה זו מפחיתה את השונות על ידי ביצוע אקראי של תהליך הבנייה שלהם.
ניקח דוגמה שבה אנו משתמשים באומדן השקיות באמצעות sikit learn:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
סיווג השקיות לוקח בחשבון מספר פרמטרים:
- base_estimator: מודל הבסיס המשמש בגישת השקיות. כאן אנו משתמשים במסווג עץ ההחלטות.
- n_estimators: מספר האומדנים בהם נשתמש בגישת השקיות.
- max_samples: מספר הדגימות שיישאבו ממערך האימונים עבור כל מעריך בסיס.
- max_features: מספר התכונות שישמשו לאימון כל מעריך בסיס.
כעת נתאים את המיון הזה לסט האימונים ונבקיע אותו.
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
אנחנו יכולים לעשות את אותו הדבר עבור משימות רגרסיה, ההבדל יהיה שבמקום זאת נשתמש באומדי רגרסיה.
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)הערמה היא טכניקה לשילוב אומדנים מרובים על מנת למזער את ההטיות שלהם ולייצר תחזיות מדויקות. תחזיות מכל מעריך משולבות ואז מוזנות למטא-מודל חיזוי אולטימטיבי מאומן באמצעות אימות צולב; ניתן ליישם ערימה הן על בעיות סיווג והן על בעיות רגרסיה.
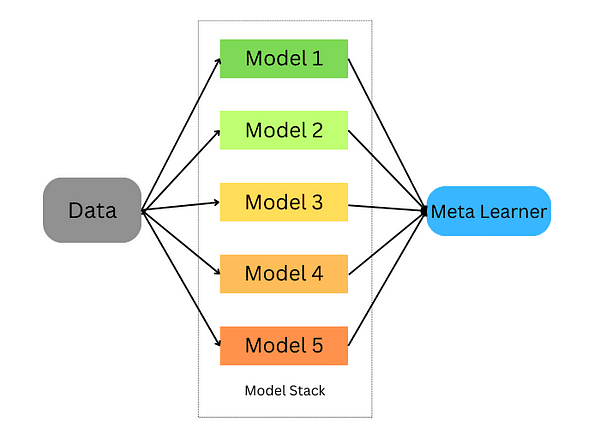
לימוד אנסמבל הערימה
הערימה מתרחשת בשלבים הבאים:
- פצל את הנתונים לסט הדרכה ואימות
- חלקו את ערכת האימון לקפלי K
- אמנו מודל בסיס על קפלי k-1 וערכו תחזיות על קיפול ה-k
- חזור על הפעולה עד שתהיה לך תחזית עבור כל קיפול
- התאימו את דגם הבסיס על כל סט האימונים
- השתמש במודל כדי ליצור תחזיות על מערך הבדיקה
- חזור על שלבים 3-6 עבור דגמי בסיס אחרים
- השתמש בתחזיות ממערך הבדיקות כתכונות של מודל חדש (המודל המטא)
- בצע תחזיות סופיות על מערך המבחן באמצעות המטא-מודל
בדוגמה זו להלן, אנו מתחילים ביצירת שני מסווגים בסיסיים (RandomForestClassifier ו-GradientBoostingClassifier) ומטה מסווג אחד (LogisticRegression) ומשתמשים באימות צולב כפול K כדי להשתמש בחיזויים ממסווגים אלה על נתוני אימון (מערך קשתית) עבור תכונות קלט עבור המטא מסווג שלנו (LogisticRegression).
לאחר שימוש באימות צולב כפול K לביצוע חיזויים ממסווג הבסיס על מערכי נתוני בדיקה כתכונות קלט עבור המטא-מסווג שלנו, חיזויים על ערכות בדיקה תוך שימוש בשתי הסטים יחד ומעריכים את הדיוק שלהם מול עמיתיהם הנערמים בהרכב.
# Load the dataset
data = load_iris()
X, y = data.data, data.target # Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Define base classifiers
base_classifiers = [ RandomForestClassifier(n_estimators=100, random_state=42), GradientBoostingClassifier(n_estimators=100, random_state=42)
] # Define a meta-classifier
meta_classifier = LogisticRegression() # Create an array to hold the predictions from base classifiers
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers))) # Perform stacking using K-fold cross-validation
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train): train_fold, val_fold = X_train[train_index], X_train[val_index] train_target, val_target = y_train[train_index], y_train[val_index] for i, clf in enumerate(base_classifiers): cloned_clf = clone(clf) cloned_clf.fit(train_fold, train_target) base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold) # Train the meta-classifier on base classifier predictions
meta_classifier.fit(base_classifier_predictions, y_train) # Make predictions using the stacked ensemble
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers): stacked_predictions[:, i] = clf.predict(X_test) # Make final predictions using the meta-classifier
final_predictions = meta_classifier.predict(stacked_predictions) # Evaluate the stacked ensemble's performance
accuracy = accuracy_score(y_test, final_predictions)
print(f"Stacked Ensemble Accuracy: {accuracy:.2f}")חיזוק היא טכניקת אנסמבל למידת מכונה המפחיתה הטיות ושונות על ידי הפיכת לומדים חלשים ללומדים חזקים. לומדים חלשים אלו מיושמים ברצף על מערך הנתונים; ראשית על ידי יצירת מודל ראשוני והתאמתו לסט האימונים. לאחר שזוהו שגיאות מהדגם הראשון, דגם אחר מתוכנן לתקן אותן.
ישנם אלגוריתמים ויישומים פופולריים להגברת טכניקות למידת אנסמבל. בואו לחקור את המפורסמים שבהם.
6.1. AdaBoost
AdaBoost היא טכניקת לימוד אנסמבל יעילה, המעסיקה לומדים חלשים ברצף למטרות הדרכה. כל איטרציה נותנת עדיפות לתחזיות שגויות תוך הפחתת המשקל המוקצה למופעים החזויים בצורה נכונה; הדגש האסטרטגי הזה על תצפיות מאתגרות מאלץ את AdaBoost להפוך ליותר ויותר מדויק עם הזמן, כאשר התחזית האולטימטיבית שלה נקבעת על ידי קולות רוב מצטברים או סכום משוקלל של הלומדים החלשים שלה.
AdaBoost הוא אלגוריתם רב תכליתי המתאים למשימות רגרסיה וגם למשימות סיווג, אך כאן אנו מתמקדים ביישום שלו לבעיות סיווג באמצעות Scikit-learn. הבה נבחן כיצד אנו יכולים להשתמש בו למשימות סיווג בדוגמה שלהלן:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
בדוגמה זו, השתמשנו ב-AdaBoostClassifier מ-skit learn והגדרנו את n_estimators ל-100. ברירת המחדל של למידה היא עץ החלטות ואתה יכול לשנות אותו. בנוסף לכך, ניתן לכוון את הפרמטרים של עץ ההחלטות.
2. שיפור הדרגתי קיצוני (XGBoost)
eXtreme Gradient Boosting או הידוע יותר בשם XGBoost, הוא אחד המימושים הטובים ביותר של הגברת לומדי אנסמבל בשל החישובים המקבילים שלו, מה שהופך אותו למוטב מאוד להפעלה על מחשב יחיד. XGBoost זמין לשימוש דרך חבילת xgboost שפותחה על ידי קהילת למידת המכונה.
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)3. LightGBM
LightGBM הוא אלגוריתם נוסף להגברת הדרגות המבוסס על למידת עצים. עם זאת, זה שונה מאלגוריתמים מבוססי עצים אחרים בכך שהוא משתמש בצמיחת עצים נבנית מה שגורם לו להתכנס מהר יותר.

צמיחת עץ נבונה עלים / תמונה מאת LightGBM
בדוגמה שלהלן ניישם את LightGBM על בעיית סיווג בינארי:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt', 'objective': 'binary', 'num_leaves': 40, 'learning_rate': 0.1, 'feature_fraction': 0.9 }
gbm = lgb.train(params, lgb_train, num_boost_round=200, valid_sets=[lgb_train, lgb_eval], valid_names=['train','valid'], )
למידת אנסמבל ויערות אקראיים הם מודלים רבי עוצמה של למידת מכונה המשמשים תמיד מתרגלי למידת מכונה ומדעני נתונים. במאמר זה, כיסינו את האינטואיציה הבסיסית מאחוריהם, מתי להשתמש בהם, ולבסוף, כיסינו את האלגוריתמים הפופולריים ביותר מהם וכיצד להשתמש בהם ב-Python.
יוסף רפעת הוא חוקר ראיית מחשב ומדען נתונים. המחקר שלו מתמקד בפיתוח אלגוריתמים של ראייה ממוחשבת בזמן אמת עבור יישומי בריאות. הוא גם עבד כמדען נתונים במשך יותר מ-3 שנים בתחום השיווק, הפיננסים והבריאות.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- BlockOffsets. מודרניזציה של בעלות על קיזוז סביבתי. גישה כאן.
- מקור: https://www.kdnuggets.com/ensemble-learning-techniques-a-walkthrough-with-random-forests-in-python?utm_source=rss&utm_medium=rss&utm_campaign=ensemble-learning-techniques-a-walkthrough-with-random-forests-in-python
- :הוא
- :לֹא
- :איפה
- 1
- 10
- 100
- 12
- 16
- 24
- 40
- 9
- a
- יכולות
- יכולת
- מוּחלָט
- חֶשְׁבּוֹן
- דיוק
- מדויק
- לרוחב
- תוספת
- לקדם
- הַרפַּתקָה
- נגד
- לְקַבֵּץ
- - צבירה
- אַלגוֹרִיתְם
- אלגוריתמים
- תעשיות
- אלפא
- גם
- תמיד
- an
- ו
- בעלי חיים
- אחר
- בקשה
- יישומים
- יישומית
- החל
- מריחה
- גישה
- ARE
- מערך
- מאמר
- AS
- לשאול
- לשאול
- שהוקצה
- At
- זמין
- מְמוּצָע
- ממוצעת
- בסיס
- מבוסס
- בסיסי
- BE
- להיות
- היה
- לפני
- להתחיל
- מאחור
- שייך
- להלן
- הטוב ביותר
- מוטב
- הטיה
- הטיות
- חיזוק
- אוזן נעל
- שניהם
- רחב
- בִּניָן
- אבל
- by
- CAN
- אתגר
- שינוי
- בכיתה
- מיון
- לסווג
- CLF
- לשלב
- משולב
- שילוב
- מגיע
- קהילה
- רְכִיב
- חישובים
- המחשב
- ראייה ממוחשבת
- מושג
- התחשבות
- בניה
- לְהִתְכַּנֵס
- לתקן
- צורה נכונה
- מְתוּאָם
- מכוסה
- לִיצוֹר
- יוצרים
- סקרן
- נתונים
- מדען נתונים
- מערך נתונים
- ערכות נתונים
- התמודדות
- החלטה
- קבלת החלטות
- עץ החלטות
- עמוק יותר
- בְּרִירַת מֶחדָל
- לְהַגדִיר
- לפשט
- מעוצב
- נחוש
- מפותח
- מפתח
- מתפתח
- הבדל
- קושי
- צלילה
- שונה
- do
- תחום
- נמשך
- ראוי
- כל אחד
- קל
- אפקטיבי
- או
- דגש
- מעסיקה
- פְּגִישָׁה
- סוף
- שגיאה
- שגיאות
- Ether (ETH)
- להעריך
- כל
- דוגמה
- לְהַרְחִיב
- מנוסה
- מומחה
- מומחים
- לחקור
- קיצוני
- מפורסם
- מהר יותר
- תכונות
- הפד
- סופי
- בסופו של דבר
- לממן
- ראשון
- קוֹדֶם כֹּל
- מתאים
- הוֹלֵם
- להתמקד
- מתמקד
- קפלים
- הבא
- בעד
- יער
- החל מ-
- לְהַשִׂיג
- צבר
- לקבל
- צמיחה
- יד
- יש
- he
- בריאות
- כאן
- שֶׁלוֹ
- להחזיק
- איך
- איך
- אולם
- HTML
- HTTPS
- i
- מזוהה
- מזהה
- if
- תמונה
- תמונה
- ליישם
- הפעלה
- יישומים
- לייבא
- לשפר
- שיפור
- in
- כולל
- יותר ויותר
- בנפרד
- תעשיות
- בתחילה
- קלט
- תובנות
- במקום
- אינטגרלי
- אל תוך
- מבוא
- אינטואיציה
- כרוך
- IT
- איטרציה
- שֶׁלָה
- להצטרף
- הצטרף אלינו
- KDnuggets
- לדעת
- ידע
- ידוע
- לִלמוֹד
- למידה
- לתת
- מינוף
- החיים
- לינקדין
- לִטעוֹן
- נראה
- הסתכלות
- מגרש
- מכונה
- למידת מכונה
- הרוב
- לעשות
- עושה
- רב
- שיווק
- דבר
- מקסימום
- אומר
- התכוון
- meta
- שיטה
- לצמצם
- מודל
- מודלים
- יותר
- רוב
- הכי פופולארי
- מספר
- חדש
- לא
- מספר
- מטרה
- תצפיות
- להשיג
- of
- לעתים קרובות
- on
- פעם
- ONE
- יחידות
- אופטימיזציה
- or
- להזמין
- מְקוֹרִי
- אחר
- שלנו
- תוֹצָאָה
- יותר
- מקיף
- חבילה
- מקביל
- פרמטרים
- מסוים
- לבצע
- ביצועים
- לְחַבֵּר
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- לְשַׂחֵק
- פופולרי
- פופולריות
- כּוֹחַ
- חזק
- מעשי
- תרגול
- חזה
- נבואה
- התחזיות
- מנבא
- מתעדף
- הסתברות
- בעיה
- בעיות
- תהליך
- לייצר
- מספק
- למטרות
- פיתון
- אקראי
- זמן אמת
- מפחית
- נסיגה
- תַחֲלִיף
- מחקר
- חוקר
- תוצאות
- חָסוֹן
- הפעלה
- ריצה
- s
- אותו
- מַדְעָן
- מדענים
- סקיקיט-לימוד
- ציון
- לִרְאוֹת
- לראות
- בחירה
- סט
- סטים
- כמה
- קצר
- בפשטות
- יחיד
- So
- משהו
- לפצל
- יציב
- מְגוּבָּב
- הערימה
- צעדים
- אסטרטגי
- אסטרטגיות
- אִסטרָטֶגִיָה
- חזק
- חזק יותר
- מַתְאִים
- לקחת
- לוקח
- יעד
- משימות
- טכניקות
- עשר
- מבחן
- בדיקות
- מֵאֲשֶׁר
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- שם.
- אלה
- הֵם
- זֶה
- שְׁלוֹשָׁה
- דרך
- זמן
- ל
- יַחַד
- ארגז כלים
- רכבת
- מְאוּמָן
- הדרכה
- עץ
- פנייה
- שתיים
- האולטימטיבי
- ייחודי
- בניגוד
- עד
- us
- נוֹהָג
- להשתמש
- מְשׁוּמָשׁ
- שימושים
- באמצעות
- אימות
- רב צדדי
- מאוד
- חזון
- הַצבָּעָה
- קולות
- הצבעה
- בהדרכה
- דרכים
- we
- מִשׁקָל
- מה
- מתי
- אם
- אשר
- בזמן
- כל
- יצטרך
- עם
- תיק עבודות
- עבד
- X
- XGBoost
- שנים
- עוד
- תְשׁוּאָה
- אתה
- זפירנט