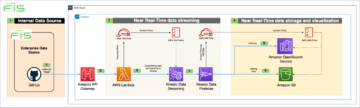
Amazon EMR ללא שרת מאפשר לך להפעיל מסגרות ביג דאטה בקוד פתוח כגון Apache Spark ו- Apache Hive מבלי לנהל אשכולות ושרתים. עם EMR Serverless, אתה יכול להפעיל עומסי עבודה אנליטיים בכל קנה מידה עם קנה מידה אוטומטי שמשנה את גודל המשאבים בשניות כדי לעמוד בנפחי הנתונים המשתנים ובדרישות העיבוד. EMR Serverless מרחיב את המשאבים באופן אוטומטי למעלה ולמטה כדי לספק בדיוק את הכמות הנכונה של קיבולת עבור היישום שלך.
אנו נרגשים להכריז כי EMR Serverless מציע כעת תצורות עובדים של 8 מעבדי vCPU עם עד 60 GB זיכרון ו-16 vCPUs עם עד 120 GB זיכרון, המאפשרים לך להפעיל עומסי עבודה עתירי מחשוב וזיכרון על EMR Serverless. יישום EMR Serverless משתמש באופן פנימי בעובדים לביצוע עומסי עבודה. ואתה יכול להגדיר תצורות עובדים שונות בהתבסס על דרישות עומס העבודה שלך. בעבר, תצורת העובד הגדולה ביותר הזמינה ב-EMR Serverless הייתה 4 מעבדי vCPU עם עד 30 GB זיכרון. יכולת זו מועילה במיוחד עבור התרחישים הנפוצים הבאים:
- עומסי עבודה כבדים
- עומסי עבודה עתירי זיכרון
בואו נסתכל על כל אחד ממקרי השימוש הללו ואת היתרונות של גדלים גדולים יותר של עובדים.
היתרונות של שימוש בעובדים גדולים לעומסי עבודה עתירי דשדוש
ב-Spark and Hive, ערבוב מתרחש כאשר יש צורך להפיץ נתונים מחדש על פני האשכול במהלך חישוב. כאשר האפליקציה שלך מבצעת טרנספורמציות רחבות או מפחיתה פעולות כגון join, groupBy, sortBy, או repartition, Spark and Hive מפעילים ערבוב. כמו כן, כל שלב Spark וקודקוד טז מוגבלים בפעולת דשדוש. אם ניקח את Spark כדוגמה, כברירת מחדל, יש 200 מחיצות עבור כל עבודת Spark שהוגדרה על ידי spark.sql.shuffle.partitions. עם זאת, Spark יחשב את מספר המשימות תוך כדי תנועה בהתבסס על גודל הנתונים והפעולה המתבצעת. כאשר מבוצעת טרנספורמציה רחבה על גבי מערך נתונים גדול, יכולים להיות GBs או אפילו TBs של נתונים שצריך להביא על ידי כל המשימות.
ערבובים הם בדרך כלל יקרים מבחינת זמן ומשאבים, ויכולים להוביל לצווארי בקבוק בביצועים. לכן, לאופטימיזציה של דשדושים יכולה להיות השפעה משמעותית על הביצועים והעלות של עבודת Spark. עם עובדים גדולים, ניתן להקצות יותר נתונים לזיכרון של כל מבצע, מה שממזער את הנתונים המעורבים בין המבצעים. זה בתורו מוביל להגברת ביצועי הקריאה בערבוביה מכיוון שיותר נתונים יובאו באופן מקומי מאותו עובד ופחות נתונים יובאו מרחוק מעובדים אחרים.
ניסויים
כדי להדגים את היתרונות של שימוש בעובדים גדולים עבור שאילתות עתירות ערבוב, בואו נשתמש q78 מ-TPC-DS, שהיא שאילתת Spark כבדה בערבוב 167 GB של נתונים על פני 12 שלבי Spark. בוא נבצע שתי איטרציות של אותה שאילתה עם תצורות שונות.
התצורות עבור מבחן 1 הן כדלקמן:
- גודל ה-executor המבוקש בעת יצירת יישום EMR Serverless = 4 vCPUs, 8 GB זיכרון, 200 GB דיסק
- תצורת Spark Job:
spark.executor.cores= 4spark.executor.memory= 8spark.executor.instances= 48- מקביליות = 192 (
spark.executor.instances*spark.executor.cores)
התצורות עבור מבחן 2 הן כדלקמן:
- גודל ה-executor המבוקש בעת יצירת יישום EMR Serverless = 8 vCPUs, 16 GB זיכרון, 200 GB דיסק
- תצורת Spark Job:
spark.executor.cores= 8spark.executor.memory= 16spark.executor.instances= 24- מקביליות = 192 (
spark.executor.instances*spark.executor.cores)
בואו נשבית גם הקצאה דינמית על ידי הגדרה spark.dynamicAllocation.enabled ל false עבור שתי הבדיקות כדי למנוע רעש פוטנציאלי עקב זמני השקת מבצעים משתנים ולשמור על ניצול המשאבים עקבי עבור שתי הבדיקות. אנו משתמשים מידה ניצוץ, שהוא כלי קוד פתוח המפשט את האיסוף והניתוח של מדדי ביצועים של Spark. מכיוון שאנו משתמשים במספר קבוע של מבצעים, המספר הכולל של מעבדי vCPU והזיכרון המבוקשים זהים עבור שתי הבדיקות. הטבלה הבאה מסכמת את התצפיות מהמדדים שנאספו עם Spark Measure.
| . | הזמן הכולל שנלקח עבור שאילתה באלפיות שניות | ערבבLocalBlocksFetched | ערבבRemoteBlocks Fetched | shuffleLocalBytesRead | shuffleRemoteBytesRead | shuffleFetchWaitTime | shuffleWriteTime |
| מבחן 1 | 153244 | 114175 | 5291825 | 3.5 GB | 163.1 GB | 1.9 שעות | 4.7 דקות |
| מבחן 2 | 108136 | 225448 | 5185552 | 6.9 GB | 159.7 GB | 3.2 דקות | 5.2 דקות |
כפי שניתן לראות מהטבלה, יש הבדל משמעותי בביצועים עקב שיפורי דשדוש. מבחן 2, עם מחצית ממספר המבצעים הגדולים פי שניים מבדיקה 1, פעל מהר יותר ב-29.44%, עם פי 1.97 יותר נתוני ערבוב שנאספו באופן מקומי בהשוואה למבחן 1 עבור אותה שאילתה, אותה מקביליות, ואותם משאבי vCPU וזיכרון מצטברים . לכן, תוכלו להפיק תועלת מביצועים משופרים מבלי להתפשר על עלות או מקבילות לעבודה בעזרת מבצעים גדולים. ראינו יתרונות ביצועים דומים עבור שאילתות TPC-DS עתירות ערבוב אחרות כגון ש 23 א ו ש 23 ב.
המלצות
כדי לקבוע אם העובדים הגדולים יועילו ליישומי Spark עתירי הדשדוש שלך, שקול את הדברים הבאים:
- בדקו התמחות הכרטיסייה ממשק המשתמש של Spark History Server של היישום ללא שרת EMR שלך. לדוגמה, מצילום המסך הבא של Spark History Server, אנו יכולים לקבוע שעבודת Spark זו כתבה וקראה 167 GB של נתוני ערבוב המצטברים על פני 12 שלבים, תוך הסתכלות על ערבב לקרוא ו ערבב כתוב עמודות. אם העבודה שלך מערבבת מעל 50 GB של נתונים, אתה עשוי להפיק תועלת משימוש בעובדים גדולים יותר עם 8 או 16 vCPUs או
spark.executor.cores.

- בדקו SQL / DataFrame הכרטיסייה מממשק ה-Spark History Server של האפליקציה ללא שרת EMR (רק עבור ממשקי API של Dataframe ו-Dataset). כשאתה בוחר בפעולת Spark שבוצעה, כגון איסוף, קח, showString או שמירה, תראה DAG מצטבר עבור כל השלבים המופרדים על ידי החילופים. כל החלפה ב-DAG תואמת לפעולת ערבוב, והיא תכיל את הבתים והבלוקים המקומיים והמרוחקים ערבובים, כפי שניתן לראות בצילום המסך הבא. אם בלוקים או בתים של ערבוב מקומיים שאוחזרו הרבה פחות בהשוואה לבלוקים או בתים מרוחקים שאוחזרו, אתה יכול להפעיל מחדש את היישום שלך עם עובדים גדולים יותר (עם 8 או 16 vCPUs או spark.executor.cores) ולסקור את מדדי החלפה האלה ב-DAG כדי לראות אם יש שיפור.

- השתמש מידה ניצוץ כלי עם שאילתת Spark שלך כדי להשיג את מדדי הערבוב ב-Spark Driver
stdoutיומנים, כפי שמוצג ביומן הבא עבור עבודת Spark. סקור את הזמן שלוקח לקריאה בערבוביה (shuffleFetchWaitTime) וערבב כותב (shuffleWriteTime), והיחס בין הבתים המקומיים שנלקחו לבייטים המרוחקים שנלקחו. אם פעולת הערבוב נמשכת יותר מ-2 דקות, הפעל מחדש את היישום שלך עם עובדים גדולים יותר (עם 8 או 16 vCPUs אוspark.executor.cores) עם Spark Measure כדי לעקוב אחר השיפור בביצועי ערבוב וזמן הריצה הכולל של העבודה.
היתרונות של שימוש בעובדים גדולים לעומסי עבודה עתירי זיכרון
סוגים מסוימים של עומסי עבודה הם עתירי זיכרון ועשויים להפיק תועלת מיותר זיכרון המוגדר לכל עובד. בסעיף זה, אנו דנים בתרחישים נפוצים שבהם עובדים גדולים יכולים להועיל להפעלת עומסי עבודה עתירי זיכרון.
הטיית נתונים
הטיית נתונים מתרחשת בדרך כלל במספר סוגים של מערכי נתונים. כמה דוגמאות נפוצות הן גילוי הונאה, ניתוח אוכלוסיה וחלוקת הכנסה. לדוגמה, כאשר אתה רוצה לזהות חריגות בנתונים שלך, צפוי שרק פחות מ-1% מהנתונים הם חריגים. אם ברצונך לבצע צבירה מסוימת על גבי רשומות רגילות לעומת חריגות, 99% מהנתונים יעובדו על ידי עובד בודד, מה שעלול להוביל לאותו עובד שיגמר הזיכרון. ניתן להבחין בהטיות נתונים עבור טרנספורמציות עתירות זיכרון כמו groupBy, orderBy, join, פונקציות חלון, collect_list, collect_set, וכולי. הצטרפו סוגים כגון BroadcastNestedLoopJoin ומוצר Cartesan הם גם מטבעם עתירי זיכרון ורגישים להטיות נתונים. באופן דומה, אם נתוני הקלט שלך דחוסים Gzip, לא ניתן לקרוא קובץ Gzip בודד על ידי יותר ממשימה אחת מכיוון שסוג הדחיסה של Gzip אינו ניתן לפיצול. כאשר יש כמה קבצי Gzip גדולים מאוד בקלט, ייתכן שהזיכרון שלך ייגמר במשימה מכיוון שמשימה בודדת תצטרך לקרוא קובץ Gzip ענק שלא מתאים לזיכרון המבצע.
ניתן לצמצם כשלים עקב הטיית נתונים על ידי יישום אסטרטגיות כגון המלחה. עם זאת, לעתים קרובות זה מצריך שינויים נרחבים בקוד, אשר עשוי להיות בלתי אפשרי עבור עומס עבודה בייצור שנכשל עקב הטיית נתונים חסר תקדים שנגרם על ידי עלייה פתאומית בנפח הנתונים הנכנסים. לפתרון פשוט יותר, ייתכן שתרצה להגדיל את זיכרון העובד. שימוש בעובדים גדולים יותר עם יותר spark.executor.memory מאפשר לך להתמודד עם הטיית נתונים מבלי לבצע שינויים כלשהם בקוד היישום שלך.
מטמון
על מנת לשפר את הביצועים, Spark מאפשר לך לשמור במטמון את מסגרות הנתונים, מערכי הנתונים ו-RDD בזיכרון. זה מאפשר לך לעשות שימוש חוזר במסגרת נתונים מספר פעמים ביישום שלך מבלי שתצטרך לחשב אותה מחדש. כברירת מחדל, עד 50% מה-JVM של המבצע שלך משמש לשמירה במטמון של מסגרות הנתונים בהתבסס על property spark.memory.storageFraction. לדוגמא, אם שלך spark.executor.memory מוגדר ל-30 GB, ולאחר מכן 15 GB משמש לאחסון מטמון חסין מפני פינוי.
רמת האחסון המוגדרת כברירת מחדל של פעולת המטמון היא DISK_AND_MEMORY. אם גודל מסגרת הנתונים שאתה מנסה לאחסן במטמון אינו מתאים לזיכרון של המבצע, חלק מהמטמון נשפך לדיסק. אם אין מספיק מקום כדי לכתוב את הנתונים המאוחסנים בדיסק, הבלוקים מסולקים ואתה לא מקבל את היתרונות של שמירה במטמון. שימוש בעובדים גדולים יותר מאפשר לך לשמור יותר נתונים בזיכרון, ולהגביר את ביצועי העבודה על ידי אחזור בלוקים מאוחסנים במטמון מהזיכרון ולא מהאחסון הבסיסי.
ניסויים
לדוגמא, הדברים הבאים עבודת PySpark מוביל להטיה, כאשר מבצע אחד מעבד 99.95% מהנתונים עם אגרגטים עתירי זיכרון כמו collect_list. העבודה גם מאחסנת מסגרת נתונים גדולה מאוד (2.2 TB). בואו נריץ שתי איטרציות של אותה עבודה ב-EMR Serverless עם תצורות ה-vCPU והזיכרון הבאות.
הבה נריץ את מבחן 3 עם תצורות העובד הגדולות ביותר שהיו בעבר:
- גודל ה-executor מוגדר בעת יצירת יישום EMR Serverless = 4 vCPUs, 30 GB זיכרון, 200 GB דיסק
- תצורת Spark Job:
spark.executor.cores= 4spark.executor.memory= 27 גרם
הבה נריץ את מבחן 4 עם תצורות העובד הגדולות ששוחררו לאחרונה:
- גודל המבצע שהוגדר בעת יצירת יישום EMR ללא שרת = 8 vCPUs, 60 GB זיכרון, 200 GB דיסק
- תצורת Spark Job:
spark.executor.cores= 8spark.executor.memory= 54 גרם
מבחן 3 נכשל עם FetchFailedException, שנבע מכך שזיכרון המבצע לא הספיק לעבודה.

כמו כן, מממשק המשתמש של Spark של מבחן 3, אנו רואים שזיכרון האחסון השמור של המבצעים נוצל במלואו לשמירה במטמון של מסגרות הנתונים.

הבלוקים הנותרים למטמון נשפכו לדיסק, כפי שניתן לראות ב-executor stderr יומנים:
בסביבות 33% ממסגרת הנתונים המתמשכת נשמרה במטמון בדיסק, כפי שניתן לראות ב- אחסון לשונית של ממשק המשתמש של Spark.

מבחן 4 עם מבצעים גדולים יותר ו-vCores רץ בהצלחה מבלי לזרוק שגיאות הקשורות לזיכרון. כמו כן, רק כ-2.2% ממסגרת הנתונים נשמרה לדיסק. לכן, בלוקים מאוחסנים במטמון של מסגרת נתונים יאוחזרו מהזיכרון ולא מהדיסק, ומציעים ביצועים טובים יותר.

המלצות
כדי לקבוע אם העובדים הגדולים יועילו ליישומי Spark עתירי הזיכרון שלך, שקול את הדברים הבאים:
- קבע אם לאפליקציית Spark שלך יש הטיות נתונים כלשהן על ידי התבוננות בממשק המשתמש של Spark. צילום המסך הבא של ממשק המשתמש של Spark מציג דוגמה לתרחיש של הטיית נתונים שבו משימה אחת מעבדת את רוב הנתונים (145.2 GB), תוך הסתכלות על ערבב לקרוא גודל. אם משימה אחת או פחות מעבדת יותר נתונים באופן משמעותי ממשימות אחרות, הפעל מחדש את היישום שלך עם עובדים גדולים יותר עם 60-120 G של זיכרון (
spark.executor.memoryמוגדר בכל מקום בין 54-109 GB תוך התחשבות ב-10% מהspark.executor.memoryOverhead).

- בדקו אחסון לשונית של Spark History Server כדי לסקור את היחס בין הנתונים המאוחסנים בזיכרון לדיסק מה- גודל בזיכרון ו גודל בדיסק עמודות. אם יותר מ-10% מהנתונים שלך מאוחסנים בדיסק, הפעל מחדש את היישום שלך עם עובדים גדולים יותר כדי להגדיל את כמות הנתונים המאוחסנים בזיכרון.
- דרך נוספת לקבוע מראש אם העבודה שלך זקוקה ליותר זיכרון היא על ידי ניטור שיא זיכרון JVM על ממשק המשתמש של Spark מוציאים לפועל לשונית. אם זיכרון השיא של JVM בשימוש קרוב לזיכרון המבצע או מנהל ההתקן, אתה יכול ליצור יישום עם עובד גדול יותר ולהגדיר ערך גבוה יותר עבור
spark.executor.memoryorspark.driver.memory. לדוגמה, בצילום המסך הבא, הערך המרבי של שימוש שיא בזיכרון JVM הוא 26 GB וspark.executor.memoryמוגדר ל-27 G. במקרה זה, ייתכן שיהיה מועיל להשתמש בעובדים גדולים יותר עם זיכרון של 60 GB וspark.executor.memoryמוגדר ל-54 G.

שיקולים
למרות שמעבדי vCPU גדולים עוזרים להגדיל את המקום של בלוקי הדשדוש, ישנם גורמים נוספים המעורבים כגון תפוקת דיסק, IOPS של דיסק (פעולות קלט/פלט בשנייה) ורוחב פס רשת. במקרים מסוימים, יותר עובדים קטנים עם יותר דיסקים יכולים להציע IOPS, תפוקה ורוחב פס רשת גבוהים יותר בדיסק בהשוואה למספר עובדים גדולים יותר. אנו ממליצים לך למדוד את עומסי העבודה שלך מול תצורות vCPU מתאימות כדי לבחור את התצורה הטובה ביותר עבור עומס העבודה שלך.
עבור עבודות כבדות ערבוב, מומלץ להשתמש בדיסקים גדולים. אתה יכול לצרף עד 200 GB דיסק לכל עובד בעת יצירת היישום שלך. שימוש במעבדי vCPU גדולים (spark.executor.cores) לכל מבצע עשוי להגדיל את ניצול הדיסק על כל עובד. אם האפליקציה שלך נכשלת עם "לא נותר מקום במכשיר" בגלל חוסר היכולת להתאים נתוני ערבוב בדיסק, השתמש בעוד עובדים קטנים יותר עם דיסק של 200 GB.
סיכום
בפוסט זה, למדת על היתרונות של שימוש במנהלים גדולים עבור העבודות שלך ללא שרת EMR. למידע נוסף על תצורות עובדים שונות, עיין ב תצורות עובדים. תצורות עובדים גדולות זמינות בכל האזורים שבהם נמצא EMR Serverless זמין.
על המחבר
 וינה וסודוואן הוא אדריכל פתרונות שותפים בכיר ומומחה אמזון EMR ב-AWS המתמקד בביג דאטה ואנליטיקה. היא עוזרת ללקוחות ולשותפים לבנות פתרונות אופטימליים, ניתנים להרחבה ומאובטחים; לחדש את הארכיטקטורות שלהם; ולהעביר את עומסי העבודה ב-Big Data שלהם ל-AWS.
וינה וסודוואן הוא אדריכל פתרונות שותפים בכיר ומומחה אמזון EMR ב-AWS המתמקד בביג דאטה ואנליטיקה. היא עוזרת ללקוחות ולשותפים לבנות פתרונות אופטימליים, ניתנים להרחבה ומאובטחים; לחדש את הארכיטקטורות שלהם; ולהעביר את עומסי העבודה ב-Big Data שלהם ל-AWS.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/amazon-emr-serverless-supports-larger-worker-sizes-to-run-more-compute-and-memory-intensive-workloads/
- 1
- 10
- 100
- 11
- 2%
- 7
- 70
- 9
- 95%
- a
- אודות
- לרוחב
- פעולה
- נגד
- - צבירה
- תעשיות
- מוּקצֶה
- הַקצָאָה
- מאפשר
- מאפשר
- אמזון בעברית
- אמזון EMR
- כמות
- אנליזה
- ניתוח
- ו
- להכריז
- בְּכָל מָקוֹם
- אַפָּשׁ
- אפאצ 'י ספארק
- ממשקי API
- בקשה
- יישומים
- מריחה
- לצרף
- מכני עם סלילה אוטומטית
- באופן אוטומטי
- זמין
- לְהִמָנַע
- AWS
- רוחב פס
- מבוסס
- כי
- להיות
- בנצ 'מרק
- מועיל
- תועלת
- הטבות
- הטוב ביותר
- מוטב
- גָדוֹל
- נתונים גדולים
- לחסום
- אבני
- חיזוק
- צווארי בקבוק
- לִבנוֹת
- מטמון
- קיבולת
- מקרה
- מקרים
- גרם
- שינויים
- משתנה
- בחרו
- סְגוֹר
- אשכול
- קוד
- לגבות
- אוסף
- עמודות
- Common
- בדרך כלל
- לעומת
- מתפשר
- חישוב
- לחשב
- תְצוּרָה
- תצורות
- לשקול
- עִקבִי
- הקשר
- מתכתב
- עלות
- יכול
- לִיצוֹר
- יוצרים
- לקוחות
- DAG
- נתונים
- מערכי נתונים
- בְּרִירַת מֶחדָל
- מוגדר
- תואר
- להפגין
- איתור
- לקבוע
- הבדל
- אחר
- לדון
- הפצה
- לא
- לא
- מטה
- נהג
- בְּמַהֲלָך
- דינמי
- כל אחד
- מאפשר
- לעודד
- מספיק
- שגיאות
- במיוחד
- Ether (ETH)
- אֲפִילוּ
- כל
- דוגמה
- דוגמאות
- חליפין
- בורסות
- נרגש
- לבצע
- צפוי
- יקר
- נרחב
- גורמים
- נכשל
- נכשל
- רחוק
- מהר יותר
- אפשרי
- הושג
- מעטים
- שלח
- קבצים
- מתאים
- קבוע
- התמקדות
- הבא
- כדלקמן
- מסגרת
- מסגרות
- הונאה
- גילוי הונאה
- החל מ-
- לגמרי
- פונקציות
- לקבל
- חצי
- לטפל
- יש
- לעזור
- עוזר
- גבוה יותר
- מאוד
- היסטוריה
- כוורת
- אולם
- HTML
- HTTPS
- עצום
- פְּגִיעָה
- לשפר
- משופר
- השבחה
- שיפורים
- in
- חוסר יכולת
- הַכנָסָה
- נכנס
- להגדיל
- גדל
- מידע
- מידע
- קלט
- במקום
- מעורב
- IT
- איטרציות
- עבודה
- מקומות תעסוקה
- להצטרף
- שמור
- גָדוֹל
- גדול יותר
- הגדול ביותר
- לשגר
- עוֹפֶרֶת
- מוביל
- למד
- רמה
- להגביל
- מקומי
- באופן מקומי
- נראה
- הסתכלות
- עשייה
- ניהול
- מקסימום
- למדוד
- לִפְגוֹשׁ
- זכרון
- מדדים
- נודד
- דקות
- מצב
- לְחַדֵשׁ
- ניטור
- יותר
- רוב
- MS
- מספר
- צורך
- צרכי
- רשת
- רעש
- נוֹרמָלִי
- מספר
- להשיג
- הַצָעָה
- הצעה
- המיוחדות שלנו
- ONE
- קוד פתוח
- מבצע
- תפעול
- אופטימיזציה
- מיטוב
- להזמין
- אחר
- מקיף
- שותף
- שותפים
- שִׂיא
- לבצע
- ביצועים
- מבצע
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- אוכלוסייה
- אפשרי
- הודעה
- פוטנציאל
- פוטנציאל
- קוֹדֶם
- תהליך
- תהליכים
- תהליך
- המוצר
- הפקה
- לספק
- יחס
- חומר עיוני
- מוּמלָץ
- רשום
- להפחית
- אזורים
- שוחרר
- נותר
- מרחוק
- בקשתי
- דרישות
- דורש
- שמור
- משאב
- משאבים
- סקירה
- הפעלה
- ריצה
- אותו
- שמור
- להרחבה
- סולם
- מאזניים
- דרוג
- תרחיש
- תרחישים
- שְׁנִיָה
- שניות
- סעיף
- לבטח
- לחצני מצוקה לפנסיונרים
- ללא שרת
- שרתים
- סט
- הצבה
- כמה
- משותף
- הראה
- הופעות
- לערבב
- משמעותי
- באופן משמעותי
- דומה
- באופן דומה
- יחיד
- מידה
- גדל
- מוטה
- קטן
- קטן יותר
- So
- עד כה
- פתרונות
- כמה
- מֶרחָב
- לעורר
- מומחה
- SQL
- התמחות
- שלבים
- אחסון
- חנות
- אסטרטגיות
- בהצלחה
- כזה
- פתאומי
- מספיק
- מַתְאִים
- תומך
- לְהִתְנַחְשֵׁל
- apt
- שולחן
- לקחת
- לוקח
- נטילת
- המשימות
- משימות
- מונחים
- מבחן
- בדיקות
- השמיים
- שֶׁלָהֶם
- לכן
- תפוקה
- זורק
- זמן
- פִּי
- ל
- כלי
- חלק עליון
- סה"כ
- לעקוב
- טרנספורמציה
- טרנספורמציות
- תור
- סוגים
- בדרך כלל
- ui
- בְּסִיסִי
- חסר תקדים
- נוֹהָג
- להשתמש
- מנוצל
- ערך
- כֶּרֶך
- כרכים
- אשר
- בזמן
- רָחָב
- יצטרך
- לְלֹא
- עובד
- עובדים
- לכתוב
- זפירנט