1. האתגר עבור מחסנית נתונים בלוקצ'יין מודרנית
ישנם מספר אתגרים שעומדים בפני סטארט-אפ מודרני לאינדקס בלוקצ'יין, כולל:
- כמויות אדירות של נתונים. ככל שכמות הנתונים בבלוקצ'יין תגדל, מדד הנתונים יצטרך להתרחב כדי להתמודד עם העומס המוגבר ולספק גישה יעילה לנתונים. כתוצאה מכך, זה מוביל לעלויות אחסון גבוהות יותר, חישוב מדדים איטי ועומס מוגבר על שרת מסד הנתונים.
- צינור עיבוד נתונים מורכב. טכנולוגיית הבלוקצ'יין מורכבת, ובניית אינדקס נתונים מקיף ואמין דורשת הבנה מעמיקה של מבני הנתונים והאלגוריתמים הבסיסיים. המגוון של יישומי בלוקצ'יין יורש אותו. בהינתן דוגמאות ספציפיות, NFTs ב-Ethereum נוצרים בדרך כלל במסגרת חוזים חכמים בעקבות הפורמטים ERC721 ו-ERC1155. לעומת זאת, היישום של אלה על Polkadot, למשל, נבנה בדרך כלל ישירות בתוך זמן ריצה של blockchain. אלה צריכים להיחשב NFTs ויש לשמור אותם.
- יכולות אינטגרציה. כדי לספק ערך מרבי למשתמשים, ייתכן שפתרון אינדקס בלוקצ'יין יצטרך לשלב את אינדקס הנתונים שלו עם מערכות אחרות, כגון פלטפורמות ניתוח או ממשקי API. זה מאתגר ודורש מאמץ משמעותי שהושקע בתכנון האדריכלות.
ככל שטכנולוגיית הבלוקצ'יין הפכה לנפוצה יותר, כמות הנתונים המאוחסנים בבלוקצ'יין גדלה. הסיבה לכך היא שיותר אנשים משתמשים בטכנולוגיה, וכל עסקה מוסיפה נתונים חדשים לבלוקצ'יין. בנוסף, טכנולוגיית הבלוקצ'יין התפתחה מיישומים פשוטים להעברת כספים, כגון אלה הכוללים שימוש בביטקוין, ליישומים מורכבים יותר הכוללים יישום של היגיון עסקי בתוך חוזים חכמים. חוזים חכמים אלה יכולים לייצר כמויות גדולות של נתונים, לתרום למורכבות ולגודל המוגבר של הבלוקצ'יין. עם הזמן זה הוביל לבלוקצ'יין גדול ומורכב יותר.
במאמר זה, אנו סוקרים את האבולוציה של ארכיטקטורת הטכנולוגיה של Footprint Analytics בשלבים כמחקר מקרה כדי לחקור כיצד ערימת הטכנולוגיה של Iceberg-Trino נותנת מענה לאתגרים של נתונים על השרשרת.
Footprint Analytics אינדקסה כ-22 נתוני בלוקצ'יין ציבוריים, ו-17 NFT Marketplace, 1900 פרויקט GameFi, ויותר מ-100,000 אוספי NFT לשכבת נתוני הפשטה סמנטית. זהו פתרון מחסני הנתונים הבלוקצ'יין המקיף ביותר בעולם.
ללא קשר לנתוני בלוקצ'יין, הכוללים למעלה מ-20 מיליארד שורות של רשומות של עסקאות פיננסיות, שאותן מנתחי נתונים שולטים לעתים קרובות. זה שונה מיומני כניסה במחסני נתונים מסורתיים.
חווינו 3 שדרוגים גדולים בחודשים האחרונים כדי לעמוד בדרישות העסקיות ההולכות וגדלות:
2. ארכיטקטורה 1.0 ביגקוורי
בתחילת Footprint Analytics, השתמשנו Google Bigquery כמנוע האחסון והשאילתות שלנו; Bigquery הוא מוצר נהדר. הוא מהיר להפליא, קל לשימוש ומספק כוח אריתמטי דינמי ותחביר UDF גמיש שעוזר לנו לבצע את העבודה במהירות.
עם זאת, ל-Bigquery יש גם כמה בעיות.
- הנתונים אינם דחוסים, מה שגורם לעלויות גבוהות, במיוחד בעת אחסון נתונים גולמיים של למעלה מ-22 בלוקצ'יין של Footprint Analytics.
- בו זמנית לא מספקת: Bigquery תומכת רק ב-100 שאילתות בו-זמנית, דבר שאינו מתאים לתרחישי בו-זיפות גבוהה עבור Footprint Analytics כאשר משרתים אנליסטים ומשתמשים רבים.
- היכנס ל-Google Bigquery, שהוא מוצר במקור סגור.
אז החלטנו לחקור ארכיטקטורות אלטרנטיביות אחרות.
3. ארכיטקטורה 2.0 OLAP
התעניינו מאוד בחלק ממוצרי OLAP שהפכו פופולריים מאוד. היתרון האטרקטיבי ביותר של OLAP הוא זמן התגובה לשאילתות שלו, שלוקח בדרך כלל תת-שניות כדי להחזיר תוצאות שאילתות עבור כמויות אדירות של נתונים, והוא יכול גם לתמוך באלפי שאילתות במקביל.
בחרנו באחד ממסדי הנתונים הטובים ביותר של OLAP, דוריס, כדי לנסות. מנוע זה מתפקד היטב. עם זאת, בשלב מסוים נתקלנו במהרה בכמה בעיות אחרות:
- סוגי נתונים כגון Array או JSON אינם נתמכים עדיין (נובמבר, 2022). מערכים הם סוג נפוץ של נתונים בבלוקצ'יין מסוימים. למשל, ה שדה נושא ביומני evm. אי יכולת לחשב ב-Array משפיע ישירות על היכולת שלנו לחשב מדדים עסקיים רבים.
- תמיכה מוגבלת ב-DBT ובהצהרות מיזוג. אלו הן דרישות נפוצות למהנדסי נתונים עבור תרחישי ETL/ELT שבהם אנחנו צריכים לעדכן כמה נתונים חדשים שנוספו לאינדקס.
עם זאת, לא יכולנו להשתמש ב-Doris עבור כל צנרת הנתונים שלנו בייצור, אז ניסינו להשתמש ב-Doris כמסד נתונים של OLAP כדי לפתור חלק מהבעיה שלנו בצינור ייצור הנתונים, לפעול כמנוע שאילתות ולספק במהירות וברמה גבוהה יכולות שאילתות במקביל.
למרבה הצער, לא יכולנו להחליף את Bigquery ב-Doris, ולכן נאלצנו לסנכרן מדי פעם נתונים מ-Bigquery ל-Doris תוך שימוש בו כמנוע שאילתות. לתהליך הסנכרון הזה היו מספר בעיות, אחת מהן הייתה שכתבי העדכון נערמו במהירות כאשר מנוע OLAP היה עסוק במתן שאילתות ללקוחות החזיתיים. לאחר מכן, מהירות תהליך הכתיבה נפגעה, והסנכרון לקח הרבה יותר זמן ולפעמים אף הפך לבלתי אפשרי לסיים.
הבנו שה-OLAP יכול לפתור מספר בעיות שעומדות בפנינו ולא יכול להפוך לפתרון המפתח של Footprint Analytics, במיוחד עבור צינור עיבוד הנתונים. הבעיה שלנו גדולה ומורכבת יותר, ואפשר לומר ש-OLAP כמנוע שאילתות בלבד לא הספיק לנו.
4. אדריכלות 3.0 אייסברג + טרינו
ברוכים הבאים לארכיטקטורת Footprint Analytics 3.0, שיפוץ מלא של הארכיטקטורה הבסיסית. עיצבנו מחדש את כל הארכיטקטורה מהיסוד כדי להפריד את האחסון, החישוב והשאילתה של נתונים לשלושה חלקים שונים. לוקחים לקחים משתי הארכיטקטורות המוקדמות יותר של Footprint Analytics ולומדים מהניסיון של פרויקטי ביג דאטה מצליחים אחרים כמו Uber, Netflix ו-Databricks.
4.1. הקדמה של אגם הנתונים
ראשית הפנינו את תשומת ליבנו ל-data lake, סוג חדש של אחסון נתונים עבור נתונים מובנים ובלתי מובנים כאחד. Data Lake מושלם לאחסון נתונים על השרשרת, שכן הפורמטים של נתונים על השרשרת נעים בטווח רחב, מנתונים גולמיים לא מובנים ועד לנתוני הפשטה מובנים, ידועה בשל Footprint Analytics. ציפינו להשתמש ב-Data Lake כדי לפתור את בעיית אחסון הנתונים, ובאופן אידיאלי זה יתמוך גם במנועי מחשוב מיינסטרים כמו Spark ו-Flink, כך שלא יהיה כאב להשתלב עם סוגים שונים של מנועי עיבוד ככל שה-Footprint Analytics מתפתח .
Iceberg משתלב היטב עם Spark, Flink, Trino ומנועי חישוב אחרים, ואנחנו יכולים לבחור את החישוב המתאים ביותר עבור כל אחד מהמדדים שלנו. לדוגמה:
- עבור אלה שדורשים לוגיקה חישובית מורכבת, Spark תהיה הבחירה.
- Flink עבור חישוב בזמן אמת.
- למשימות ETL פשוטות שניתן לבצע באמצעות SQL, אנו משתמשים בטרינו.
4.2. מנוע שאילתות
עם אייסברג פותר את בעיות האחסון והחישוב, היינו צריכים לחשוב על בחירת מנוע שאילתות. אין הרבה אפשרויות זמינות. החלופות ששקלנו היו
הדבר החשוב ביותר שחשבנו לפני שנעמיק היה שמנוע השאילתות העתידי חייב להיות תואם לארכיטקטורה הנוכחית שלנו.
- כדי לתמוך ב-Bigquery כמקור נתונים
- כדי לתמוך ב-DBT, שעליו אנו מסתמכים להפקת מדדים רבים
- לתמיכה במטא-בסיס כלי ה-BI
בהתבסס על האמור לעיל, בחרנו ב-Trino, שיש לה תמיכה טובה מאוד באייסברג והצוות היה כל כך מגיב שהעלינו באג, שתוקן למחרת ושוחרר לגרסה האחרונה בשבוע שלאחר מכן. זו הייתה הבחירה הטובה ביותר עבור צוות Footprint, שגם דורש היענות גבוהה ליישום.
4.3. בדיקת ביצועים
לאחר שהחלטנו על הכיוון שלנו, עשינו מבחן ביצועים על השילוב של Trino + Iceberg כדי לראות אם הוא יכול לענות על הצרכים שלנו ולהפתעתנו, השאילתות היו מהירות להפליא.
בידיעה ש-Presto + Hive היה המשווה הגרוע ביותר מזה שנים בכל ההייפ של OLAP, השילוב של Trino + Iceberg הוציא את דעתנו לחלוטין.
להלן תוצאות הבדיקות שלנו.
מקרה 1: הצטרף למערך נתונים גדול
שולחן בנפח 800 ג'יגה-בייט1 מצטרף לשולחן נוסף של 50 ג'יגה-בייט2 ועושה חישובים עסקיים מורכבים
מקרה 2: השתמש בטבלה בודדת גדולה כדי לבצע שאילתה ברורה
Test sql: בחר distinct(address) מקבוצת הטבלה לפי יום

השילוב של טרינו+אייסברג מהיר בערך פי 3 מדוריס באותה תצורה.
בנוסף, יש עוד הפתעה מכיוון שאייסברג יכול להשתמש בפורמטים של נתונים כמו פרקט, ORC וכו', שידחסו ויאחסנו את הנתונים. אחסון הטבלה של אייסברג לוקח רק כ-1/5 מהשטח של מחסני נתונים אחרים גודל האחסון של אותה טבלה בשלושת מסדי הנתונים הוא כדלקמן:
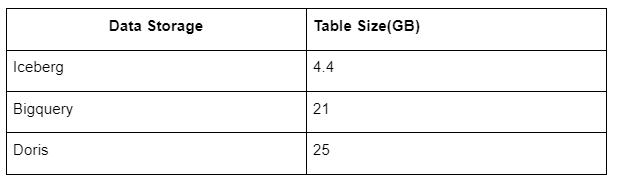
הערה: הבדיקות לעיל הן דוגמאות שנתקלנו בהן בייצור בפועל והן להתייחסות בלבד.
4.4. אפקט השדרוג
דוחות בדיקת הביצועים העניקו לנו מספיק ביצועים שלקח לצוות שלנו כחודשיים להשלים את ההעברה, וזהו דיאגרמה של הארכיטקטורה שלנו לאחר השדרוג.
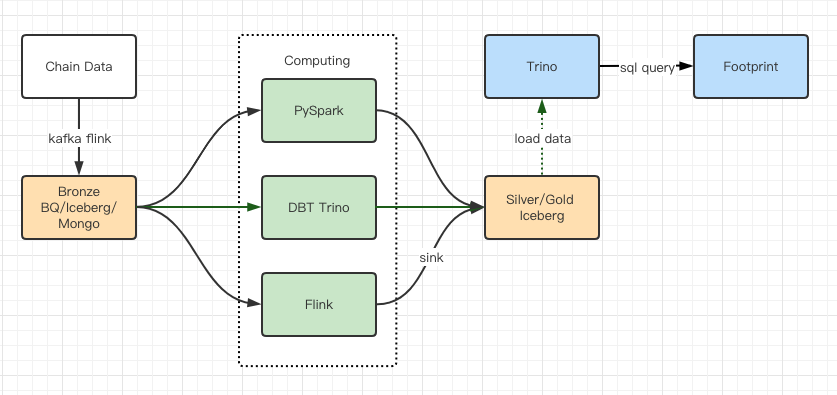
- מנועי מחשב מרובים מתאימים לצרכים השונים שלנו.
- טרינו תומך ב-DBT, ויכול לבצע שאילתות ישירות על Iceberg, כך שלא נצטרך להתעסק יותר בסנכרון נתונים.
- הביצועים המדהימים של Trino + Iceberg מאפשרים לנו לפתוח את כל נתוני הברונזה (נתונים גולמיים) למשתמשים שלנו.
5. תקציר
מאז השקתו באוגוסט 2021, צוות Footprint Analytics השלים שלושה שדרוגים ארכיטקטוניים תוך פחות משנה וחצי, הודות לרצונו העז ולנחישותו להביא את היתרונות של טכנולוגיית מסד הנתונים הטובה ביותר למשתמשי הקריפטו שלו וביצוע מוצק ביישום שדרוג התשתית והארכיטקטורה הבסיסית שלה.
שדרוג ארכיטקטורת Footprint Analytics 3.0 קנה חוויה חדשה למשתמשים שלו, המאפשר למשתמשים מרקעים שונים לקבל תובנות בשימוש ויישומים מגוונים יותר:
- נבנה עם הכלי Metabase BI, Footprint מאפשרת לאנליסטים לקבל גישה לנתונים מפוענחים על השרשרת, לחקור עם חופש בחירה מוחלט של כלים (ללא קוד או כבל קשיח), לבצע שאילתות בהיסטוריה שלמה ולחקור מערכי נתונים כדי לקבל תובנות לגבי אין זמן.
- שלב נתונים על השרשרת והן מחוץ לשרשרת לניתוח על פני web2 + web3;
- על ידי בנייה/שאילתה של מדדים על גבי ההפשטה העסקית של Footprint, אנליסטים או מפתחים חוסכים זמן על 80% מעבודת עיבוד הנתונים החוזרת ונשנית ומתמקדים במדדים משמעותיים, מחקר ופתרונות מוצר המבוססים על העסק שלהם.
- חוויה חלקה מ-Footprint Web ועד קריאות API של REST, הכל מבוסס על SQL
- התראות בזמן אמת והתראות ניתנות לפעולה על אותות מפתח לתמיכה בהחלטות השקעה
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://cryptoslate.com/iceberg-spark-trino-a-modern-open-source-data-stack-for-blockchain/
- 000
- 1
- 100
- 2021
- 2022
- a
- יכולת
- אודות
- מֵעַל
- גישה
- תוספת
- בנוסף
- כתובת
- כתובות
- מוסיף
- יתרון
- לאחר
- אלגוריתמים
- תעשיות
- מאפשר
- מאפשר
- לבד
- חלופה
- חלופות
- מדהים
- כמות
- כמויות
- אנליסטים
- ניתוח
- ו
- אחר
- אַפָּשׁ
- API
- ממשקי API
- יישומים
- מתאים
- אדריכלי
- ארכיטקטורה
- מערך
- מאמר
- תשומת לב
- מושך
- אוגוסט
- זמין
- רקע
- מבוסס
- כי
- להיות
- לפני
- ההתחלה
- להיות
- הטבות
- הטוב ביותר
- גָדוֹל
- נתונים גדולים
- גדול
- מיליארדים
- ביטקוין
- blockchain
- נתוני
- טכנולוגיה
- blockchains
- קנה
- להביא
- חרק
- בִּניָן
- נבנה
- עסקים
- שיחות
- יכולות
- מקרה
- מקרה מבחן
- לאתגר
- האתגרים
- אתגר
- בחירה
- בחרו
- בחירה
- לקוחות
- אוספים
- שילוב
- Common
- תואם
- להשלים
- השלמת
- לחלוטין
- מורכב
- מורכבות
- מַקִיף
- חישוב
- לחשב
- המחשב
- במקביל
- תְצוּרָה
- כתוצאה מכך
- נחשב
- חוזים
- לעומת זאת
- תורם
- עלויות
- יכול
- נוצר
- קריפטו
- משתמשי הצפנה
- CryptoSlate
- נוֹכְחִי
- נתונים
- אגם דאטה
- עיבוד נתונים
- אחסון נתונים
- מסד נתונים
- מאגרי מידע
- מערכי נתונים
- יְוֹם
- עסקה
- החליט
- עמוק
- עמוק יותר
- עיצוב
- נחישות
- מפתחים
- DID
- אחר
- כיוון
- ישירות
- מובהק
- שונה
- גיוון
- דינמי
- כל אחד
- מוקדם יותר
- יעיל
- מאמץ
- מנוע
- מהנדסים
- מנועים
- מספיק
- שלם
- ERC721
- במיוחד
- וכו '
- ethereum
- אֲפִילוּ
- EVM
- אבולוציה
- התפתח
- דוגמאות
- הוצאת להורג
- צפוי
- ניסיון
- מנוסה
- לחקור
- פָּנִים
- מקל
- מול
- מהר
- מהר יותר
- כספי
- ראשון
- קבוע
- גמיש
- להתמקד
- הבא
- כדלקמן
- עָקֵב
- ניתוח רגליים
- חופש
- בתדירות גבוהה
- החל מ-
- עתיד
- לְהַשִׂיג
- משחק fi
- ליצור
- לקבל
- לתת
- נתן
- הולך
- טוב
- גדול
- קרקע
- קְבוּצָה
- גדל
- חצי
- לטפל
- עוזר
- גָבוֹהַ
- גבוה יותר
- מאוד
- היסטוריה
- כוורת
- איך
- אולם
- HTTPS
- התלהבות
- הפעלה
- יישום
- חשוב
- בלתי אפשרי
- in
- כולל
- כולל
- גדל
- עליות
- בצורה מדהימה
- מדד
- תשתית
- תובנות
- למשל
- לשלב
- משלב
- מעוניין
- מבוא
- להשקיע
- השקעה
- בעיות
- IT
- עבודה
- להצטרף
- מצטרף
- ג'סון
- מפתח
- אגם
- גָדוֹל
- גדול יותר
- האחרון
- לשגר
- שכבה
- מוביל
- למידה
- הוביל
- שיעורים
- לִטעוֹן
- עוד
- זרם מרכזי
- גדול
- רב
- שוק
- מסיבי
- להתאים
- max-width
- מקסימום
- משמעותי
- לִפְגוֹשׁ
- למזג
- מדדים
- הֲגִירָה
- מוחות
- מודרני
- חודשים
- יותר
- רוב
- צורך
- צרכי
- נטפליקס
- חדש
- הבא
- NFT
- אוספי NFT
- שוק nft
- NFTs
- הודעות
- על השרשרת
- נתונים על שרשרת
- ONE
- לפתוח
- קוד פתוח
- אפשרויות
- אחר
- לְשַׁפֵּץ
- כְּאֵב
- חלק
- עבר
- אֲנָשִׁים
- ביצועים
- מבצע
- הרים
- חתיכות
- צינור
- פלטפורמות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- מנוקד
- פופולרי
- כּוֹחַ
- בעיה
- בעיות
- תהליך
- תהליך
- המוצר
- הפקה
- מוצרים
- פּרוֹיֶקט
- פרויקטים
- לספק
- מספק
- מתן
- ציבורי
- -
- מהירות
- מורם
- רכס
- חי
- זמן אמת
- הבין
- רשום
- שוחרר
- אָמִין
- להחליף
- דוחות לדוגמא
- דרישות
- דורש
- מחקר
- תגובה
- תגובה
- REST
- וכתוצאה מכך
- תוצאות
- לַחֲזוֹר
- סקירה
- אמר
- אותו
- שמור
- סולם
- תרחישים
- הגשה
- כמה
- צריך
- אותות
- משמעותי
- פָּשׁוּט
- יחיד
- מידה
- להאט
- חכם
- חוזים חכמים
- So
- מוצק
- פִּתָרוֹן
- פתרונות
- לפתור
- פותר
- כמה
- מָקוֹר
- מֶרחָב
- לעורר
- ספציפי
- מְהִירוּת
- לערום
- שלבים
- סטארט - אפ
- הצהרות
- אחסון
- חנות
- אחסן את הנתונים
- מאוחסן
- חזק
- מובנה
- לימוד
- כתוצאה מכך
- מוצלח
- כזה
- תמיכה
- נתמך
- תומך
- הפתעה
- סִנכְּרוּן
- תחביר
- מערכות
- שולחן
- לוקח
- נטילת
- משימות
- נבחרת
- טכנולוגיה
- מבחן
- בדיקות
- השמיים
- העולם
- שֶׁלָהֶם
- דבר
- אלפים
- שְׁלוֹשָׁה
- זמן
- פִּי
- ל
- כלי
- כלים
- חלק עליון
- מסורתי
- עסקה
- עסקות
- הסתובב
- סוגים
- בדרך כלל
- סופר
- בְּסִיסִי
- הבנה
- עדכון
- שדרוג
- שדרוגים
- us
- נוֹהָג
- להשתמש
- משתמשים
- בְּדֶרֶך כְּלַל
- ערך
- שונים
- גרסה
- אינטרנט
- Web2
- Web3
- שבוע
- מוכר
- אשר
- מי
- באופן נרחב
- נָפוֹץ
- יצטרך
- בתוך
- תיק עבודות
- עוֹלָם
- גרוע
- היה
- כתיבה
- שנה
- שנים
- זפירנט