お客様が採用している Apache Kafka 用の Amazon マネージドサービス (Amazon MSK) を、エンタープライズ データ ハブを構築するための高速で信頼性の高いストリーミング プラットフォームとして利用します。 ストリーミング機能に加えて、Amazon MSK を設定すると、組織は疎結合で独立したコンポーネントによるデータ配布にパブリッシュ/サブスクモデルを使用できるようになります。
Apache Kafka クラスターと、検索インデックス、データベース、ファイル システムなどの他の外部システムの間でデータを公開および配布するには、以下をセットアップする必要があります。 Apache Kafka コネクトのオープンソース コンポーネントです。 アパッチカフカ フレームワークを使用して、さまざまなシステム間でデータを移動するためのコネクタをホストおよび実行します。 アップストリームおよびダウンストリームのアプリケーションの数が増加するにつれて、Apache Kafka Connect クラスターの管理、拡張、管理も複雑になります。 これらのスケーラビリティと管理性の問題に対処するには、 アマゾンMSKコネクト は、Apache Kafka Connect 用に構築されたフルマネージド コネクタをデプロイする機能を提供します。また、ワークロードの変化に合わせて自動的にスケーリングし、消費したリソースに対してのみ支払いを行う機能を備えています。
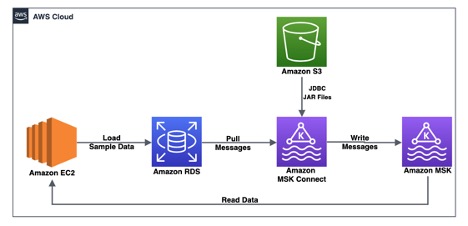
この投稿では、からデータをストリーミングするソリューションについて説明します。 MySQL 用 Amazon Relation Database Service (Amazon RDS) Amazon MSK Connect を使用してコネクタを設定およびデプロイすることで、リアルタイムで MSK クラスターに接続できます。
ソリューションの概要
私たちのユースケースでは、企業は複数のプロデューサー アプリケーションとコンシューマー アプリケーションを含む集中データ リポジトリを構築したいと考えています。 さまざまなツールやテクノロジーを使用してアプリケーションからのストリーミング データをサポートするために、ストリーミング プラットフォームとして Amazon MSK が選択されています。 現在、Amazon RDS for MySQL にデータを書き込んでいる主要なアプリケーションの XNUMX つでは、データを MSK トピックに公開し、同時にデータベースに書き込むために、大幅な設計変更が必要になります。 したがって、設計の変更を最小限に抑えるために、このアプリケーションは引き続き Amazon RDS for MySQL にデータを書き込みますが、このデータを集中ストリーミング プラットフォーム Amazon MSK と同期して、複数の下流消費者に対するリアルタイム分析を可能にするという追加要件も伴います。
このユースケースを解決するために、Amazon MSK の機能である Amazon MSK Connect を使用して、オープンソースの Amazon RDS for MySQL から MSK クラスターにデータを移動するためのフルマネージド Apache Kafka Connect コネクタをセットアップする次のアーキテクチャを提案します。 JDBC コネクタから ジャンクション.
AWS環境をセットアップする
このソリューションをセットアップするには、いくつかの AWS リソースを作成する必要があります。 の AWS CloudFormation この投稿で提供されているテンプレートは、前提条件として必要なすべての AWS リソースを作成します。
次の表に、テンプレートに指定する必要があるパラメータを示します。
| パラメータ名 | Description | キープ デフォルト値 |
| スタック名 | CloudFormation スタックの名前。 | いいえ |
| DBインスタンスID | RDS for MySQL インスタンスの名前。 | いいえ |
| DB名 | ストリーミング用のサンプル データを保存するデータベース名。 | はい |
| DBインスタンスクラス | RDS for MySQL インスタンスのインスタンス タイプ。 | いいえ |
| DB割り当てストレージ | DB インスタンスに割り当てられたサイズ (GiB)。 | いいえ |
| DBUユーザー名 | MySQL データベースにアクセスするためのデータベース ユーザー。 | いいえ |
| DBパスワード | MySQL データベースにアクセスするためのパスワード。 | いいえ |
| JDBCConnectorPluginBukcetName | MSK Connect コネクタの JAR ファイルとプラグインを保存するためのバケット。 | いいえ |
| クライアントIPCIDR | EC2 インスタンスに接続するクライアント マシンの IP アドレス。 | いいえ |
| EC2KeyPair | EC2 インスタンスで使用されるキーペア。 この EC2 インスタンスは、ローカル マシンから EC2 クライアント インスタンスに接続するためのプロキシとして使用されます。 | いいえ |
| EC2ClientImageId | Amazon Linux 2 の最新の AMI ID。この投稿ではデフォルト値をそのまま使用できます。 | はい |
| VpcCIDR | この VPC の IP 範囲 (CIDR 表記)。 | いいえ |
| PrivateSubnetOneCIDR | 最初のアベイラビリティーゾーンのプライベートサブネットの IP 範囲 (CIDR 表記)。 | いいえ |
| PrivateSubnetTwoCIDR | XNUMX 番目のアベイラビリティーゾーンのプライベートサブネットの IP 範囲 (CIDR 表記)。 | いいえ |
| PrivateSubnetThreeCIDR | XNUMX 番目のアベイラビリティーゾーンのプライベートサブネットの IP 範囲 (CIDR 表記)。 | いいえ |
| パブリックサブネットCIDR | パブリックサブネットのIP範囲(CIDR表記)。 | いいえ |
CloudFormation スタックを起動するには、次を選択します。 発射スタック:
![]()
CloudFormation テンプレートが完成し、リソースが作成されると、 出力 タブにはリソースの詳細が表示されます。

RDS for MySQL インスタンスのサンプル データを検証する
この使用例用のサンプル データを準備するには、次の手順を実行します。
- ローカル端末から次のコマンドを使用して、EC2 クライアント インスタンス MSKEC2Client に SSH 接続します。
- 次のコマンドを実行して、データが正常にロードされたことを検証します。

すべてのテーブルのデータを Amazon RDS から Amazon MSK に同期します
Amazon RDS から Amazon MSK にすべてのテーブルを同期するには、次の手順で Amazon MSK Connect マネージドコネクタを作成します。
- Amazon MSKコンソールで、 カスタムプラグイン 下のナビゲーションペインで MSKコネクト.
- 選択する カスタムプラグインを作成する.
- S3 URI – カスタム プラグイン オブジェクト、S3 バケット内の JDBC コネクタの confluentinc-kafka-connect-jdbc-plugin.zip (CloudFormation テンプレートによって作成された) という名前の ZIP ファイルを参照します。
bkt-msk-connect-plugins-<aws_account_id>. - カスタムプラグイン名、 入る
msk-confluent-jdbc-plugin-v1. - オプションの説明を入力します。
- 選択する カスタムプラグインを作成する.

カスタム プラグインが正常に作成されると、次の場所で使用できるようになります。 アクティブ status
- 選択する コネクタ 下のナビゲーションペインで MSKコネクト.
- 選択する コネクタを作成する.
- 選択 既存のカスタム プラグインを使用 と下 カスタムプラグイン、プラグインを選択します
msk-confluent-jdbc-plugin-v1以前に作成したもの。 - 選択する Next.

- コネクタ名、 入る
msk-jdbc-connector-rds-to-msk. - オプションの説明を入力します。
- クラスタータイプ選択 MSK クラスター.

- MSKクラスターで、前に作成したクラスターを選択します。
- 認証、選択する わたし。
- コネクタ構成、次の設定を入力します。
次の表は、前述のすべての構成オプションの簡単な概要を示しています。
| 設定オプション | Description |
| コネクタ.クラス | コネクタの JAVA クラス |
| 接続.ユーザー | MySQL エンドポイントで認証するためのユーザー名 |
| 接続.url | MySQL エンドポイントのホスト名とポート番号を識別する JDBC URL |
| 接続.パスワード | MySQL エンドポイントで認証するためのパスワード |
| タスク.最大 | このコネクタに対して起動されるタスクの最大数 |
| ポーリング間隔.ms | 各テーブルが新しいデータを取得するための後続のポーリング間の時間間隔 (ミリ秒) |
| トピック.プレフィックス | MSK クラスターでトピックを作成するときに各テーブル名に追加するカスタム プレフィックス値 |
| モード | 各ポーリングの動作モード (バルク、タイムスタンプ、増分、またはタイムスタンプ+増分など) |
| 接続の試行 | JDBC接続の最大リトライ回数 |
| セキュリティ.プロトコル | 暗号化用に TLS を設定します |
| sasl.メカニズム | 使用する SASL メカニズムを識別します |
| ssl.truststore.location | 信頼できる証明書を保存する場所 |
| ssl.keystore.location | 秘密鍵を保管する場所 |
| sasl.client.callback.handler.class | 抽出された資格情報に基づいて SigV4 署名の構築をカプセル化します。 |
| sasl.jaas.config | SASL クライアント実装をバインドします。 |

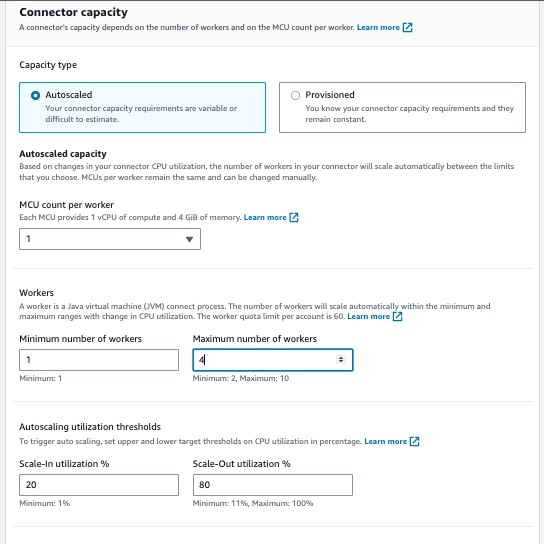
- コネクタ容量 セクション、選択 自動スケール for 容量タイプ デフォルト値の 1 をそのまま使用します。 ワーカーあたりの MCU 数.
- セット4 最大ワーカー数 他のすべてのデフォルト値を維持します 労働者 および 自動スケーリング使用率のしきい値.
- ワーカー構成選択 MSK のデフォルト構成を使用する.
- アクセス許可、カスタム IAM ロールを選択します
msk-connect-rds-jdbc-MSKConnectServiceIAMRole-*以前に作成されました。
- ログ配信選択 Amazon CloudWatch Logs に配信する.
- ロググループ、ロググループを選択します
msk-jdbc-source-connector以前に作成されました。
- 選択する Next.
- レビューと作成、すべての設定を検証し、選択します コネクタを作成する.
コネクタが移行した後、 ランニング ステータスが変化すると、RDS インスタンスから MSK クラスターへのデータのフローが開始されるはずです。
データを検証する
データを検証して比較するには、次の手順を実行します。
- EC2 クライアント インスタンスへの SSH 接続
MSKEC2Clientローカル端末から次のコマンドを使用します。 - IAM 認証を使用して MSK クラスターに接続するには、最新バージョンの aws-msk-iam-認証 クラスパス内の JAR ファイル:
- Amazon MSKコンソールで、 クラスター ナビゲーションペインでクラスタを選択します
MSKConnect-msk-connect-rds-jdbc. - ソフトウェア設定ページで、下図のように クラスタの概要 ページ、選択 クライアント情報を見る.

- クライアント情報を見る セクション ブートストラップ サーバーのプライベート エンドポイントをコピーします。 認証タイプ わたし。

- 最新バージョンの Apache Kafka インストールを操作し、Amazon MSK ブートストラップ サーバーに接続するための追加の環境変数を設定します。
<bootstrap servers>IAM 認証を使用して MSK クラスターに接続できるブートストラップ サーバーのリストです。 - という名前の構成ファイルをセットアップします
client/properties認証に使用されます: - MSK クラスターで作成されたトピックのリストを検証します。

- データが MSK クラスター内のトピックにロードされたことを検証します。
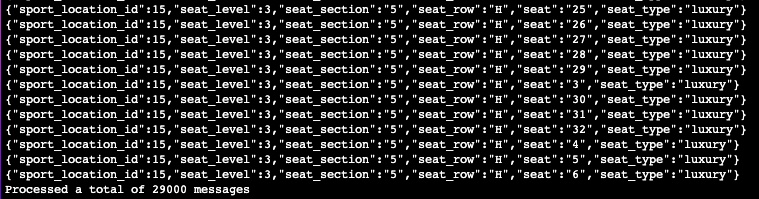
Amazon RDS へのクエリを使用してデータを同期し、Amazon MSK に書き込む
Amazon RDS for MySQL の複数のテーブルを結合してデータを平坦化するクエリの結果を同期するには、次の手順で Amazon MSK Connect マネージドコネクタを作成します。
- Amazon MSK コンソールで、選択します コネクタ 下のナビゲーションペインで MSKコネクト.
- 選択する コネクタを作成する.
- 選択 既存のカスタム プラグインを使用 と下 カスタムプラグイン、選択
pluginmsk-confluent-jdbc-plugin-v1. - コネクタ名、 入る
msk-jdbc-connector-rds-to-msk-query. - オプションの説明を入力します。
- クラスタータイプ選択 MSK クラスター.
- MSKクラスターで、前に作成したクラスターを選択します。
- 認証、選択する わたし。
- コネクタ構成、次の設定を入力します。
- コネクタ容量 セクション、選択 自動スケール for 容量タイプ デフォルト値の 1 をそのまま使用します。 ワーカーあたりの MCU 数.
- セット4 最大ワーカー数 他のすべてのデフォルト値を維持します 労働者 および 自動スケーリング使用率のしきい値.
- ワーカー構成選択 MSK のデフォルト構成を使用する.
- アクセス許可、カスタム IAM ロールを選択します
role_msk_connect_serivce_exec_custom. - ログ配信選択 Amazon CloudWatch Logs に配信する.
- ロググループ、前に作成したログ グループを選択します。
- 選択する Next.
- レビューと作成、すべての設定を検証し、選択します コネクタを作成する.
コネクタが移行すると、 ランニング ステータスが変化すると、RDS インスタンスから MSK クラスターへのデータのフローが開始されるはずです。
- データを検証するには、EC2 クライアント インスタンス MSKEC2Client に SSH で接続し、次のコマンドを実行してトピック内のデータを確認します。

クリーンアップ
リソースをクリーンアップして継続的な料金を回避するには、次の手順を実行します。
- Amazon MSKコンソールで、 コネクタ 下のナビゲーションペインで MSKコネクト.
- 作成したコネクタを選択し、 削除.

- Amazon S3コンソールで、 バケット ナビゲーションペインに表示されます。
- 命名規則に従ってバケットを検索する
bkt-msk-connect-plugins-<aws_account_id>. - このバケット内のすべてのフォルダーとオブジェクトを削除します。
- すべての内容を削除した後、バケットを削除します。
- CloudFormation スタックを使用して作成された他のすべてのリソースを削除するには、AWS CloudFormation コンソールからスタックを削除します。
まとめ
Amazon MSK Connect は、必要なリソースをプロビジョニングし、コネクタの健全性と配信状態を監視し、基盤となるハードウェアを維持し、コネクタを自動スケールしてワークロードのバランスを整えるフルマネージド型サービスです。 この投稿では、RDS for MySQL インスタンスと MSK クラスターの間でデータをストリーミングするために、Confluent からオープンソース JDBC コネクタをセットアップする方法を説明しました。 また、すべてのテーブルを同期するためのさまざまなオプションや、クエリベースのアプローチを使用して非正規化データを MSK トピックにストリーミングするためのさまざまなオプションも検討しました。
Amazon MSK Connect の詳細については、以下を参照してください。 MSK Connect の使用を開始する.
著者について
 マニッシュ・ヴィルワニ AWS のシニア ソリューション アーキテクトです。 彼は、大規模なビッグデータおよび分析ソリューションの設計と実装に XNUMX 年以上の経験があります。 彼は、一部の主要な AWS 顧客およびパートナーに技術指導、設計アドバイス、思想的リーダーシップを提供しています。
マニッシュ・ヴィルワニ AWS のシニア ソリューション アーキテクトです。 彼は、大規模なビッグデータおよび分析ソリューションの設計と実装に XNUMX 年以上の経験があります。 彼は、一部の主要な AWS 顧客およびパートナーに技術指導、設計アドバイス、思想的リーダーシップを提供しています。
 インディラ・バラクリシュナン AWS アナリティクス スペシャリスト SA チームのプリンシパル ソリューション アーキテクトです。 彼女は、顧客がクラウドベースの分析ソリューションを構築して、データ主導の意思決定を使用してビジネス上の問題を解決できるよう支援することに情熱を注いでいます。 仕事以外では、子供たちの活動にボランティアとして参加し、家族との時間を過ごしています。
インディラ・バラクリシュナン AWS アナリティクス スペシャリスト SA チームのプリンシパル ソリューション アーキテクトです。 彼女は、顧客がクラウドベースの分析ソリューションを構築して、データ主導の意思決定を使用してビジネス上の問題を解決できるよう支援することに情熱を注いでいます。 仕事以外では、子供たちの活動にボランティアとして参加し、家族との時間を過ごしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/stream-data-with-amazon-msk-connect-using-an-open-source-jdbc-connector/
- :持っている
- :は
- :どこ
- $UP
- 1
- 10
- 100
- 13
- 14
- 視聴者の38%が
- 17
- 195
- 27
- 7
- 8
- 9
- a
- 私たちについて
- アクセス
- 活動
- 添加
- NEW
- 住所
- 管理する
- 採用
- アドバイス
- 後
- すべて
- 許す
- また
- Amazon
- アマゾンRDS
- Amazon Webサービス
- an
- 分析論
- および
- アパッチ
- アパッチカフカ
- 申し込み
- アプローチ
- 建築
- です
- AS
- At
- 認証
- 認証
- 認証
- オート
- 自動的に
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- 避ける
- AWS
- AWS CloudFormation
- ベース
- コウモリ
- BE
- き
- の間に
- ビッグ
- ビッグデータ
- ブートストラップ
- 結合した
- ビルド
- 内蔵
- ビジネス
- by
- 缶
- 機能
- 場合
- CD
- 集中型の
- 変更
- 課金
- 選択する
- class
- クライアント
- クラスタ
- 比較します
- コンプリート
- 複雑さ
- コンポーネント
- コンポーネント
- 懸念事項
- ジャンクション
- お問合せ
- 接続する
- 接続
- 領事
- 構築
- 消費
- consumer
- 消費者
- 中身
- 続ける
- 大会
- 変換
- 結合しました
- 作ります
- 作成した
- 作成します。
- 作成
- Credentials
- 現在
- カスタム
- Customers
- データ
- データ駆動型の
- データベース
- データベースを追加しました
- 十年
- 決定
- デフォルト
- 配達
- 展開します
- 展開する
- 説明
- 設計
- 設計
- デスティネーション
- 細部
- 異なります
- 分配します
- ディストリビューション
- ドキュメント
- ありません
- 各
- 前
- enable
- 可能
- 暗号化
- エンドポイント
- 入力します
- Enterprise
- 環境
- エーテル(ETH)
- 既存の
- 体験
- 調査済み
- export
- 外部
- 家族
- スピーディー
- 特徴
- 少数の
- File
- 名
- 流れる
- フォロー中
- フレームワーク
- から
- 完全に
- 機能性
- グループ
- 成長する
- ガイダンス
- Hardware
- 持ってる
- he
- 健康
- 助け
- 彼女の
- host
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- ハブ
- IAM
- ID
- 識別する
- 識別
- 実装
- 実装
- in
- 含めて
- 独立しました
- インデックス
- 情報
- インストール
- に
- 呼び出す
- IT
- join
- 参加
- JPG
- JSON
- カフカ
- キープ
- キー
- 大規模
- 最新の
- 起動する
- 打ち上げ
- リーダーシップ
- LIMIT
- linuxの
- リスト
- リスト
- ローカル
- ログ
- 機械
- 維持
- 主要な
- 管理します
- マネージド
- 多くの
- メカニズム
- メッセージ
- 最小限に抑えます
- モード
- モニター
- 他には?
- 移動する
- の試合に
- しなければなりません
- MySQL
- 名
- 名前付き
- 名
- 命名
- ナビゲーション
- 必要
- 新作
- 数
- オブジェクト
- オブジェクト
- of
- on
- ONE
- 継続
- の
- オープンソース
- 操作
- オプション
- or
- 組織
- その他
- 私たちの
- 外側
- ページ
- ペア
- ペイン
- パラメータ
- パートナー
- 情熱的な
- path
- 支払う
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイヤー
- お願いします
- プラグイン
- 世論調査
- ポスト
- 準備
- 前提条件
- 主要な
- 校長
- プライベート
- 問題
- プロデューサー
- プロパティ
- 提案する
- 提供します
- 提供
- は、大阪で
- 代理
- 公共
- パブリッシュ
- 範囲
- リアル
- への
- 関係
- 信頼性のある
- 削除済み
- 倉庫
- 必要とする
- の提出が必要です
- 要件
- リソースを追加する。
- リソース
- 結果
- レビュー
- 職種
- ラン
- SA
- 同じ
- スケーラビリティ
- 規模
- 秤
- を検索
- 二番
- セクション
- セキュリティ
- 選択
- サーバー
- サービス
- サービス
- セッションに
- セット
- 設定
- 設定
- 彼女
- すべき
- 作品
- 署名
- サイズ
- So
- ソフトウェア
- 溶液
- ソリューション
- 解決する
- 一部
- ソース
- 専門家
- 特定の
- SSL
- スタック
- start
- 開始
- 都道府県
- Status:
- ステップ
- ストレージ利用料
- 店舗
- 流れ
- ストリーミング
- サブネット
- それに続きます
- 首尾よく
- そのような
- 概要
- サポート
- システム
- テーブル
- 仕事
- タスク
- チーム
- 技術的
- テクノロジー
- template
- ターミナル
- より
- それ
- アプリ環境に合わせて
- したがって、
- ボーマン
- 三番
- この
- 考え
- 思考リーダーシップ
- 介して
- 時間
- タイムスタンプ
- TLS
- 〜へ
- 豊富なツール群
- トピック
- トピック
- 転送
- 信頼されている
- type
- 下
- 根本的な
- URI
- URL
- つかいます
- 使用事例
- 中古
- ユーザー
- 検証
- 値
- 価値観
- variables
- さまざまな
- バージョン
- 、
- ボランティア
- 望んでいる
- we
- ウェブ
- Webサービス
- WELL
- いつ
- which
- 意志
- 仕事
- ワーキング
- でしょう
- 書きます
- 書き込み
- 貴社
- あなたの
- ゼファーネット
- 〒