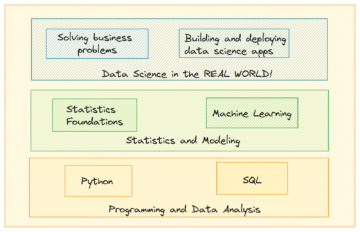
DALL・E 3 で生成された画像
データサイエンティストは刺激的な立場に置かれました。現代の仕事ではプログラミング言語を使用する必要がありますが、仕事上覚えておく必要のあるビジネスの側面は依然としてたくさんあります。データ サイエンティストが使用する Python コードには、通常、ビジネス上の問題を解決する方法に関するストーリーテリングが反映されているのはこのためです。データサイエンティストにとっての環境も注目に値します。 Jupyter Notebook IDE を使用すると、データ操作とモデル開発を実験するための優れた方法が可能になります。
コーディング活動の方法が異なると、データ サイエンティストはプログラミング活動中に異なる作業を行うことになります。これには、コードを説明するアクティビティであるコメント アクティビティが含まれます。要件の変更が常にあり、共同作業を行うデータ サイエンティストにとって、コメントを通じてコードの適切な説明を提供することが重要です。
この記事では、データ サイエンティストとして Python コードのコメント付けを実行する方法について説明します。あなたのアクティビティを改善し、あなたのコードを読む人に価値をもたらすさまざまな点について話し合います。それでは始めましょう。
先に進む前に、2 つの異なるタイプのコメントについて少し学びましょう。 1 つ目は ' を使用する単一行のコメントです。#コード内の ' 表記。通常、コードの簡単な説明に使用されます。たとえば、次のコードは、単一行のコメントの使用例を示しています。
# The code is to import the Pandas package and call it pd
import pandas as pd
コメントを作成するもう 1 つの方法は、三重引用符を使用する複数行の方法を使用することです。技術的には、これらはコメントではなく文字列オブジェクトですが、変数に代入しない場合、Python はそれらを無視します。次の例で実際の動作を確認できます。
"""
The code below would import the Pandas package, and we would call them pd throughout the whole working environment. """
import pandas as pdこのセクションでは、コメントに関する一般的なヒントについて説明します。これらのヒントはプログラマーにとってのベスト プラクティスであるため、必ずしもデータ サイエンティストに適用できるわけではありませんが、覚えておくと良いでしょう。ヒントは次のとおりです。
- 読みやすさを高めるために、説明するコードのすぐ上の別の行にコメントを配置することを検討してください。
- 作業中のコード全体でコメントのスタイルが一貫していること。
- 聴衆が理解できないことがわかっている場合は、理解しにくい専門用語や専門用語を使用しないでください。
- 明らかなことの説明を避けるために、価値を追加する場合にのみコメントします。
- コメントが関連性がなくなった場合は、コメントを維持および更新します。
これらは、より良いコメント エクスペリエンスを提供するための一般的なガイドラインです。ここで、データサイエンティスト向けのより具体的な話に移りましょう。
データ サイエンティストにとって、コーディング活動はソフトウェア エンジニアや Web 開発者のコーディング活動とは異なります。それが、コメント活動に違いが生じる理由です。ここでは、私たちデータサイエンティストに特有のヒントをいくつか紹介します。
1. コメントを使用して複雑なプロセスやアクティビティを明確にする
データ サイエンスの活動には多くの実験プロセスが含まれるため、説明しなければ読者や将来の私たちを混乱させる可能性があります。コードのコメントは、特に多くのステップが含まれる場合に、意図をより適切に説明するのに役立ちます。たとえば、以下のコードは、正規化とスケーリングによって外れ値を削除する方法を説明します。
# Perform data normalization (Min-Max scaling)
normalized_data = (data - np.min(data)) / (np.max(data) - np.min(data)) # Remove outliers by using the sigma rule (3 standard deviations removal)
removed_outlier_data = normalized_data[np.abs(stats.zscore(normalized_data)) 3]上記のコメントは、各プロセスで何が行われたか、およびその背後にある概念を説明しています。コードで使用した概念を指定することは、私たちが行ったことを理解するために不可欠です。
これは前処理に限定されるものではなく、データ サイエンスのあらゆるステップでコメントすることができます。データの取得からモデルの監視に至るまで、誰でも理解できるようにコメントすることは良い習慣です。データ サイエンティストとして、私たちのコメントがコードと分析的洞察の間の架け橋になる可能性があることを忘れないでください。
2. コメントの基準を設ける
データ サイエンスの活動はコラボレーション プロセスであるため、誰もが理解できる標準的な構造を持つことが望ましいです。一人で作業する場合でも、知っているであろう基準があるので役立ちます。たとえば、作成した関数ごとにコメントを標準化できます。
# Function: name of the function
# Usage: description of how to use the function
# Parameters: list the parameters and explain them
# Output: explain the output上記は標準的な例であり、独自に何かを作成することもできます。このような標準がある場合は、同じスタイル、言語、略語を使用することを忘れないでください。
3. コメントを使用してワークフローを支援する
共同作業環境では、チームがワークフローを理解するためにコメントすることが不可欠です。コメントを使用すると、新しいコードがいつ更新されるか、または次に何を行う必要があるかを理解するのに役立ちます。たとえば、別の関数の更新によりプロセスにバグが発生するため、次にバグを修正する必要があります。
# TODO: Fix this function ASAP
some_function_to_fix()4. Markdown ノートブックのセルを実装する
実験にノートブックを使用するため、データ サイエンティスト IDE は非常に優れています。ノートブックのセルを使用すると、各コードを分離できるため、コード全体を実行する必要がなく、独立して実行できます。ノートブックのセルはコードに限定されず、Markdown セルに変換できます。
Markdown は、テキストがどのように見えるかを記述する書式設定言語です。セルでは、マークダウンによって以下のコードをさらに詳しく説明できます。マークダウンを使用する利点は、標準のコメント プロセスよりも詳細にコメントできることです。表、画像、LaTeX などを追加することもできます。
たとえば、以下の画像は、Markdown を使用してプロジェクト、目的、手順を説明する方法を示しています。
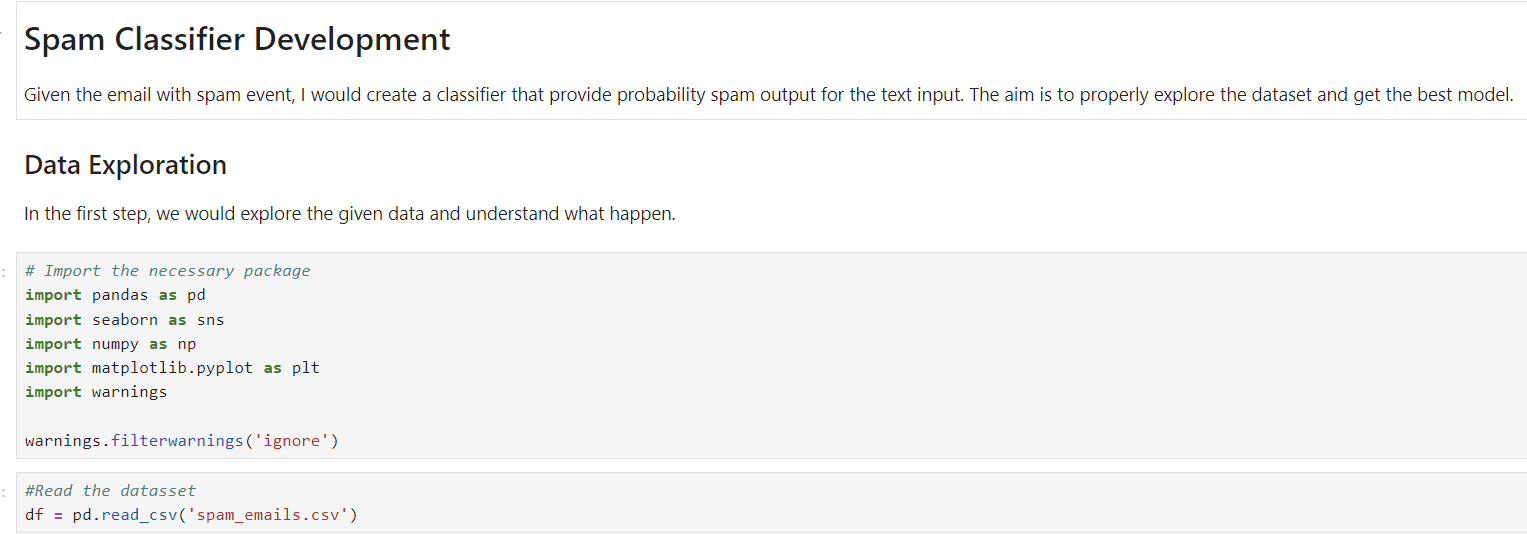
Jupyter Markdown Cell について詳しくは、 ドキュメント 自分に何ができるかをさらに理解するために。
コメントは、コードで何が起こったのかを読者が明確にするのに役立つため、データ サイエンティストの活動に不可欠な部分です。データ サイエンティストの場合、私たちの作業プロセスが異なるため、コメント プロセスはソフトウェア エンジニアや Web 開発者とは若干異なります。そのため、この記事では、データ サイエンティストとしてコメントする際に使用できるヒントをいくつか紹介します。ヒントは次のとおりです。
- コメントを使用して複雑なプロセスやアクティビティを明確にする
- コメントの基準があること
- コメントを使用してワークフローを支援する
- Markdown ノートブックのセルを実装する
私はそれが役に立てば幸いです。
コーネリアス・ユダ・ウィジャヤ は、データ サイエンス アシスタント マネージャー兼データ ライターです。 Allianz Indonesia でフルタイムで働いている間、彼はソーシャル メディアやライティング メディアを通じて Python とデータのヒントを共有するのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/how-to-comment-your-python-code-as-a-data-scientist?utm_source=rss&utm_medium=rss&utm_campaign=how-to-comment-your-python-code-as-a-data-scientist
- :は
- :not
- 7
- 8
- 9
- a
- 私たちについて
- 上記の.
- Action
- 活動
- アクティビティ
- 加えます
- 追加
- 十分な
- 利点
- 目指す
- アリアンツ
- ことができます
- また
- an
- 分析的
- および
- 別の
- どれか
- もはや
- 誰も
- 適用可能な
- です
- 記事
- AS
- 側面
- アシスタント
- At
- 聴衆
- 避ける
- BE
- になる
- 背後に
- 以下
- BEST
- より良いです
- の間に
- BRIDGE
- 持って来る
- バグ
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- コール
- 缶
- 原因
- セル
- 細胞
- 変更
- コード
- コード
- コーディング
- 環境、テクノロジーを推奨
- 共同
- コメント
- コメントアウト
- コメント
- 注釈
- 複雑な
- コンセプト
- コンセプト
- 検討
- 整合性のある
- 絶えず
- 可能性
- 作ります
- 重大な
- データ
- データサイエンス
- データサイエンティスト
- 説明する
- 説明
- 詳細
- Developer
- 開発
- の違い
- 異なります
- 異なって
- 直接に
- 話し合います
- do
- 行われ
- ドント
- 間に
- 各
- 従業員
- エンジニア
- 環境
- 時代
- 特に
- 本質的な
- エーテル(ETH)
- さらに
- あらゆる
- 誰も
- 例
- 優れた
- エキサイティング
- 例示する
- 体験
- 実験
- 実験的
- 説明する
- 説明
- 説明
- 説明
- 名
- 修正する
- フォロー中
- から
- function
- さらに
- 未来
- 生成された
- 取得する
- 与える
- Go
- 良い
- ガイドライン
- が起こった
- 持ってる
- 持って
- he
- 助けます
- 役立つ
- ことができます
- こちら
- 希望
- 認定条件
- How To
- HTML
- HTTPS
- if
- 無視する
- 画像
- 画像
- 実装する
- import
- 改善します
- in
- 含ま
- 増える
- 単独で
- インドネシア
- 洞察力
- インテグラル
- 意図
- に
- 巻き込む
- 関係する
- IT
- 専門用語
- ジョブ
- ジュピターノート
- KDナゲット
- 知っている
- 言語
- LEARN
- ような
- 限定的
- LINE
- リスト
- 少し
- 見て
- のように見える
- で
- 製
- 維持する
- マネージャー
- 操作
- 多くの
- メディア
- 方法
- かもしれない
- モダン
- モニタリング
- 他には?
- 名
- 必ずしも
- 必要
- ニーズ
- 新作
- 次の
- ノート
- 今
- オブジェクト
- 明白
- of
- on
- ONE
- の
- or
- その他
- 私たちの
- 出力
- パッケージ
- パンダ
- パラメータ
- 部
- 実行する
- 配置
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- 位置
- 練習
- 問題
- プロセス
- ラボレーション
- プログラマ
- プログラミング
- プロジェクト
- 提供します
- Python
- 非常に
- 引用
- 読む
- リーダー
- 読者
- 反映
- 関連した
- 顕著
- 覚えています
- 除去
- 削除します
- 要件
- 必要
- 検索
- ルール
- ラン
- 同じ
- スケーリング
- 科学
- 科学者
- 科学者たち
- セクション
- 別
- シェアする
- すべき
- 作品
- シグマ
- 簡単な拡張で
- わずかに
- So
- 社会
- ソーシャルメディア
- ソフトウェア
- ソフトウェアエンジニア
- のみ
- 解決する
- 一部
- 何か
- 特定の
- 指定する
- 標準
- 統計情報
- ステップ
- まだ
- ストーリーテリング
- 文字列
- 構造
- チーム
- 技術的
- 技術的に
- 条件
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- より
- それ
- アプリ環境に合わせて
- それら
- そこ。
- ボーマン
- 彼ら
- 物事
- この
- 全体
- ヒント
- 〜へ
- 変換
- トリプル
- 2
- わかる
- 理解する
- アップデイト
- 更新版
- us
- 使用法
- つかいます
- 中古
- 使用されます
- 通常
- 値
- 変数
- さまざまな
- 、
- 欲しいです
- ました
- 仕方..
- we
- ウェブ
- した
- この試験は
- いつ
- which
- while
- 誰
- 全体
- なぜ
- 意志
- 無し
- 仕事
- ワークフロー
- ワーキング
- でしょう
- 作家
- 書き込み
- 貴社
- あなたの
- ゼファーネット