概要
人工ニューラル ネットワークは、その素晴らしさにもかかわらず、相変わらず不可解なままです。これらのネットワークが大きくなるにつれて、その能力は爆発的に増加しますが、その内部の仕組みを解読することは常に不可能に近いものでした。研究者は、これらのモデルに関して得られる洞察を常に探しています。
数年前、彼らは新しいものを発見しました。
2022 年 XNUMX 月、ChatGPT を開発した OpenAI の研究者は、 報告 これらのシステムは、誤って通常よりもはるかに長い時間データを読み込むことを許可された場合、問題を解決する独自の方法を開発したことがわかりました。通常、エンジニアがニューラル ネットワーク (人工ニューロンと呼ばれる計算単位で構成される) から機械学習モデルを構築する場合、過学習領域と呼ばれる特定の時点でトレーニングを停止する傾向があります。これは、ネットワークが基本的にそのトレーニング データの記憶を開始するときであり、多くの場合、新しいまだ見たことのない情報に一般化されません。しかし、OpenAI チームが誤ってこの時点をはるかに超えて小さなネットワークをトレーニングしたところ、単に暗記するだけではなく、問題に対する理解を深めたようで、突然あらゆるテスト データに匹敵する可能性がありました。
研究者らはこの現象を「グロッキング」と名付けた。これはSF作家ロバート・A・ハインラインが作った造語で、「観察者が観察されるプロセスの一部になるほど徹底的に」何かを理解することを意味する。特定の数学的演算を実行するように設計された過剰学習されたニューラル ネットワークは、数値の一般的な構造を学習し、その結果を内部化していました。それは問題を解決し、解決策になりました。
「これは非常に刺激的で、考えさせられるものでした」と氏は語った。 ミハイル・ベルキン カリフォルニア大学サンディエゴ校の博士号を取得し、ニューラル ネットワークの理論的および経験的特性を研究しています。 「それは多くのフォローアップ作業に拍車をかけました。」
実際、他の人はその結果を再現し、リバースエンジニアリングさえ行っています。最新の論文は、これらのニューラル ネットワークが理解するときに何をしているのかを明らかにしただけでなく、その内部を調べるための新しいレンズも提供しました。 「グロッキングのセットアップは、深層学習のさまざまな側面を理解するための優れたモデル生物のようなものです」と氏は述べています。 エリック・ミショー マサチューセッツ工科大学の。
この生物の内部を覗いてみると、非常に明らかになることがあります。 「美しい構造を見つけることができるだけでなく、その美しい構造は内部で何が起こっているのかを理解するために重要です」と彼は言いました。 ニール・ナンダ、現在はロンドンの Google DeepMind に勤務しています。
限界を超えて
基本的に、機械学習モデルの仕事は単純に思えます。与えられた入力を目的の出力に変換することです。それを実現できる最適な関数を探すのが学習アルゴリズムの仕事です。特定のモデルは限られた関数セットのみにアクセスでき、そのセットは多くの場合、モデル内のパラメーターの数によって決まります。ニューラル ネットワークの場合、これは人工ニューロン間の接続の数にほぼ相当します。
概要
ネットワークはトレーニングするにつれて、より複雑な機能を学習する傾向があり、トレーニング データでは、期待される出力と実際の出力との間に差異が生じ始めます。さらに良いことに、損失として知られるこの不一致は、トレーニングに使用されていない新しいデータであるテスト データでも減少し始めます。しかし、ある時点でモデルが過剰適合し始め、トレーニング データの損失が減少し続ける一方で、テスト データの損失が増加し始めます。したがって、通常、研究者がネットワークのトレーニングを停止するのはそのときです。
OpenAI のチームがニューラル ネットワークでどのように数学を実行できるかを検討し始めたとき、これが一般的な通念でした。彼らは小さなものを使っていました トランス — 最近大規模な言語モデルに革命を起こしたネットワーク アーキテクチャ — は、さまざまな種類のモジュラー演算を実行するためのもので、ループバックする限られたセットの数値を操作します。たとえば、モジュロ 12 は時計の文字盤で実行できます: 11 + 2 = 1。チームは、XNUMX つの数値を加算するネットワークの例を示しました。 a および b、出力を生成するには、 c, モジュロ 97 (数字が 97 の時計の文字盤に相当)。次に、彼らは、これまでにない組み合わせで変圧器をテストしました。 a および b 正しく予測できるかどうかを確認する c.
予想通り、ネットワークが過剰適合状態に入ると、トレーニング データの損失はゼロに近づき (見たものを記憶し始めました)、テスト データの損失は増加し始めました。それは一般化されていませんでした。 「そしてある日、私たちは幸運に恵まれました」とチームリーダーのアレシア・パワーは語った。 2022年XNUMX月に講演 サンフランシスコでのカンファレンスにて。 「幸運とは、忘れっぽいという意味です。」
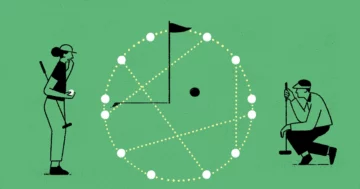
ネットワークをトレーニングしていたチーム メンバーが休暇に入り、トレーニングを中止するのを忘れていました。このバージョンのネットワークがトレーニングを続けると、突然、目に見えないデータの精度が向上しました。自動テストにより、この予想外の精度がチームの他のメンバーに明らかになり、すぐにネットワークが数値を配置する賢い方法を見つけたことに気づきました。 a および b。内部的には、ネットワークは高次元空間の数値を表しますが、研究者がこれらの数値を 2D 空間に投影してマッピングすると、数値は円を形成しました。
これは驚くべきことでした。チームはモデルにモジュロ 97 の計算を行っていることやモジュロの意味さえも伝えず、ただ算術の例を示しただけでした。モデルは、より深い分析的解決策、つまり、次のすべての組み合わせを一般化する方程式を見つけたようです。 a および bトレーニングデータを超えて。ネットワークに異常が発生し、テスト データの精度が 100% にまで上昇しました。 「これは奇妙だ」とパワーさんは聴衆に語った。
チームは、さまざまなタスクとさまざまなネットワークを使用して結果を検証しました。発見は続きました。
時計とピザの
しかし、ネットワークが見つけた方程式は何だったのでしょうか? OpenAIの論文には書かれていないが、その結果はナンダ氏の注目を集めた。 「ニューラル ネットワークに関する核心的な謎と厄介な点の 1 つは、ニューラル ネットワークの機能は非常に優れているのに、デフォルトではどのように機能するのかがまったく分からないということです」とナンダ氏は語ります。ネットワークを調べて、どのようなアルゴリズムを学習したかを調べます。
ナンダは OpenAI の発見に魅了され、おかしくなったニューラル ネットワークを分解することにしました。彼は、モジュラー演算を学習する際にモデルのパラメーターを詳細に検査できるように、OpenAI ニューラル ネットワークのさらに単純なバージョンを設計しました。彼は同じ動作、つまり一般化に取って代わられた過剰適合とテスト精度の急激な向上を観察しました。彼のネットワークでは、数字を円形に配置していました。多少の努力は必要だったが、ナンダさんは最終的にその理由を理解した。
ネットワークは円上に数字を表現していましたが、時計を見ている幼稚園児のように単純に数字を数えていたのではなく、高度な数学的操作を行っていました。ネットワークのパラメータの値を調べることで、 ナンダと同僚が明らかにした つまり、サインやコサインなどの三角関数を使用して数値を変換し、三角恒等式を使用してこれらの値を操作して解を導き出す「離散フーリエ変換」を実行することでクロック数値を加算していたのです。少なくとも、これは彼の特定のネットワークが行っていたことでした。
MIT のチームのとき フォローアップ ナンダの研究で、彼らは、グロッキング ニューラル ネットワークが常にこの「時計」アルゴリズムを発見するとは限らないことを示しました。時々、ネットワークは研究者が「ピザ」アルゴリズムと呼ぶものを代わりに見つけます。このアプローチは、ピザをスライスに分割し、順番に番号を付けることを想像します。 2 つの数値を加算するには、ピザの中心から問題の数値に矢印を描き、最初の 2 つの矢印によって形成される角度を二等分する線を計算することを想像してください。この線はピザのスライスの中央を通過します。スライスの番号は 2 つの数値の合計です。これらの操作は、次のサインとコサインの三角関数および代数操作の観点から書き留めることもできます。 a および b、理論的には時計のアプローチと同じくらい正確です。
概要
「時計アルゴリズムとピザアルゴリズムは両方ともこの循環表現を持っています」と彼は言いました 劉子明, MITチームのメンバー。 「しかし…これらのサインとコサインをどのように利用するかは異なります。だからこそ、私たちはそれらを異なるアルゴリズムと呼んでいます。」
しかし、それだけではありませんでした。 Liu 氏らは、モジュロ計算を行うように多数のネットワークをトレーニングした後、これらのネットワークで発見されたアルゴリズムの約 40% がピザや時計のアルゴリズムの一種であることを発見しました。チームは残りの時間、ネットワークが何をしているのかを解読できていない。ピザと時計のアルゴリズムについては、「人間が解釈できるものがたまたま見つかるだけです」とリュー氏は言う。
そして、ネットワークが問題を解決したときに学習するアルゴリズムが何であれ、一般化においては研究者が予想しているよりもさらに強力です。メリーランド大学のチームのとき 単純なニューラル ネットワークにデータを供給する ランダムなエラーを含むトレーニング データの場合、ネットワークは最初は期待どおりに動作します。トレーニング データ、エラー、その他すべてを過剰適合させ、破損していないテスト データではパフォーマンスが低下します。しかし、ネットワークが一旦理解してテスト質問に正しく答え始めると、間違ったエントリに対してさえ正しい答えを生成し、記憶されていた間違った答えを忘れて、トレーニング データにさえ一般化する可能性があります。 「この厄介なタスクは、実際にはこの種の破損に対して非常に堅牢です」と氏は言いました。 ダーシル・ドーシ、論文の著者の一人。
コントロールをめぐる戦い
その結果、研究者たちは現在、ネットワークがデータを収集するまでのプロセスを理解し始めています。ナンダ氏は、グロッキングの見かけの突然の外観は、ニューラル ネットワーク内で 2 つの異なるアルゴリズムを使用する、暗記から一般化への段階的な内部移行の結果であると考えています。同氏によると、ネットワークは学習を開始すると、まず記憶しやすいアルゴリズムを見つけ出す。ただし、アルゴリズムは単純ですが、ネットワークはトレーニング データの各インスタンスを記憶する必要があるため、かなりのリソースが必要になります。しかし、記憶している間でも、ニューラル ネットワークの一部は一般的な解決策を実装する回路を形成し始めます。 2 つのアルゴリズムはトレーニング中にリソースをめぐって競合しますが、正則化と呼ばれる追加の要素を使用してネットワークがトレーニングされると、最終的に一般化が勝ちます。
「正則化により、解決策はゆっくりと一般化解決策に向かって移動します」と Liu 氏は言います。これは、モデルの機能能力、つまりモデルが学習できる関数の複雑さを軽減するプロセスです。正則化によってモデルの複雑さが削減されると、より複雑ではない一般化アルゴリズムが最終的に勝利します。 「同じ(レベルの)パフォーマンスの場合、一般化する方が簡単です」とナンダ氏は言います。最後に、ニューラル ネットワークは記憶アルゴリズムを破棄します。
したがって、一般化の遅れた能力が突然現れたように見えますが、内部ではネットワークのパラメータが一般化アルゴリズムを着実に学習しています。理解できなくなるのは、ネットワークが一般化アルゴリズムを学習し、記憶アルゴリズムを完全に削除したときだけです。 「突然のように見える物事が、実は水面下では徐々に進行している可能性がある」とナンダ氏は語った。 その他の機械学習研究.
こうした画期的な進歩にもかかわらず、グロッキング研究はまだ初期段階にあることを覚えておくことが重要です。これまでのところ、研究者は非常に小規模なネットワークのみを研究しており、これらの発見がより大規模で強力なネットワークにも当てはまるかどうかは不明です。 Belkin 氏はまた、モジュラー演算は、今日のニューラル ネットワークによって実行されるさまざまなタスクすべてに比べれば「大海の一滴」にすぎないと警告しています。このような数学に対するニューラル ネットワークのソリューションをリバース エンジニアリングするだけでは、これらのネットワークを一般化に導く一般原理を理解するのに十分ではない可能性があります。 「樹木を研究するのは素晴らしいことです」とベルキン氏は語った。 「しかし、私たちは森についても研究しなければなりません。」
それにもかかわらず、これらのネットワーク内を覗いて分析的に理解できることは、大きな意味を持ちます。私たちのほとんどにとって、フーリエ変換や円弧の二等分はモジュロ加算を行う非常に奇妙な方法です。人間のニューロンはそのように考えません。 「しかし、線形代数で構築されているのであれば、このようにすることは実際には非常に理にかなっています」とナンダ氏は言います。
「これらの奇妙な[人工]脳は、私たちのものとは異なる働きをします」と彼は言いました。 「[彼らには]独自のルールと構造があります。私たちはニューラルネットワークがどのように考えるかを学ぶ必要があります。」
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.quantamagazine.org/how-do-machines-grok-data-20240412/
- :持っている
- :は
- :not
- ][p
- $UP
- 1
- 11
- 12
- 2%
- 2022
- 2D
- 97
- a
- 能力
- 能力
- できる
- 私たちについて
- アクセス
- 誤って
- 精度
- 正確な
- エース
- 実際の
- 実際に
- 加えます
- 追加
- 添加
- NEW
- 後
- 前
- 代数
- 代数的
- アルゴリズム
- アルゴリズム
- すべて
- 許可されて
- また
- 常に
- an
- 分析的
- および
- 角度
- 応答
- 回答
- どれか
- 離れて
- 見かけ上
- アプローチ
- 建築
- です
- 算術
- 到着する
- 人工の
- 人工神経回路網
- AS
- 側面
- At
- 注意
- 聴衆
- 著者
- 著者
- オートマチック
- バック
- 基本的に
- BE
- 美しい
- になりました
- になる
- になる
- き
- 始まった
- 開始
- 始まります
- 始め
- 行動
- 背後に
- さ
- BEST
- より良いです
- の間に
- 越えて
- より大きい
- 両言語で
- 脳
- ブレークスルー
- ビルド
- 内蔵
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算
- カリフォルニア州
- コール
- 呼ばれます
- came
- 缶
- 容量
- 場合
- キャッチ
- 注意
- センター
- 一定
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- サークル
- 円
- 回路
- 円形の
- 明確化
- クリア
- 賢い
- クライミング
- 時計
- 時計
- 閉じる
- 密接に
- 造られた
- 同僚
- 組み合わせ
- 来ます
- 会社
- 比べ
- 競争する
- 完全に
- 複雑な
- 複雑さ
- 構成
- 計算
- 講演
- Connections
- かなりの
- 絶えず
- 継続します
- 基本
- 正しい
- 可能性
- カウント
- データ
- 中
- 決定しました
- 解読
- 深いです
- 深い学習
- より深い
- ディープマインド
- デフォルト
- 遅延
- 設計
- 希望
- 開発する
- 発展した
- 口述
- ディエゴ
- 異なります
- 異なって
- 数字
- 発見する
- 発見
- 発見
- 不一致
- 分割された
- do
- すること
- 行われ
- ドント
- ダウン
- 描画
- ドライブ
- Drop
- 間に
- 各
- 容易
- 努力
- 出てくる
- エンジニア
- 十分な
- 入力されました
- 方程式
- 同等の
- エラー
- さらに
- 最終的に
- EVER
- 調べる
- 例
- 例
- エキサイティング
- 予想される
- 探る
- 非常に
- 顔
- 落下
- 遠く
- 少数の
- フィギュア
- 考え出した
- フィギュア
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- 調査結果
- 発見
- 名
- 焦点を当てて
- 森林
- 形成
- 形成
- 発見
- フーリエ
- フランシスコ
- から
- function
- 機能的な
- 機能
- 与えた
- 一般化
- 取得する
- GitHubの
- 与えられた
- 行く
- 良い
- でログイン
- だ
- 緩やかな
- 素晴らしい
- 持っていました
- 起こります
- 持ってる
- he
- ヒーロー
- 彼女の
- 彼の
- 認定条件
- しかしながら
- HTML
- HTTP
- HTTPS
- 巨大な
- 人間
- 人間
- i
- アイデア
- アイデンティティ
- if
- 絵
- 想像します
- 実装する
- 意義
- 重要
- 不可能
- 改善
- in
- 誤った
- 情報
- 成分
- 内側の
- 内部
- 洞察
- を取得する必要がある者
- 機関
- 内部
- 内部で
- 解釈する
- に
- 問題
- IT
- ITS
- 1月
- ジョブ
- ただ
- 種類
- 既知の
- 言語
- 大
- リーダー
- リード
- LEARN
- 学んだ
- 学習
- 学ぶ
- 最低
- レンズ
- less
- レベル
- 活用します
- ような
- 限定的
- LINE
- 線形
- ロンドン
- より長いです
- 見て
- 探して
- 損失
- たくさん
- たくさん
- ラッキー
- 機械
- 機械学習
- マシン
- マガジン
- 作る
- 操作する
- 操作
- メリーランド
- マサチューセッツ州
- マサチューセッツ工科大学
- math
- 数学的
- 意味する
- 意味した
- メンバー
- 真ん中
- かもしれない
- マサチューセッツ工科大学(MIT)
- モデル
- モジュラー
- モジュロ
- 他には?
- 最も
- ずっと
- 名前付き
- 近く
- 必要
- ニーズ
- ネットワーク
- ネットワーク
- ニューラル
- ニューラルネットワーク
- ニューラルネットワーク
- ニューロン
- 決して
- 新作
- いいえ
- 今
- 数
- 数の
- 番号
- 多数の
- 観測された
- of
- オフ
- 頻繁に
- on
- かつて
- ONE
- の
- OpenAI
- 業務執行統括
- or
- 注文
- その他
- 私たちの
- でる
- 結果
- 出力
- 自分の
- 紙素材
- 論文
- パラメータ
- 部
- 特定の
- 部品
- パス
- ピア
- 実行する
- パフォーマンス
- 実行
- 現象
- 選ぶ
- ピザ
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- 可能
- 電力
- 強力な
- 予測する
- 一般の
- 原則
- 問題
- 問題
- プロセス
- 作り出す
- 投影
- プロパティ
- 提供
- クアンタマガジン
- 質問
- 質問
- 非常に
- ランダム
- 実現
- 最近
- 最近
- 軽減
- 政権
- 残る
- 覚えています
- 削除済み
- 複製された
- 表現
- 表します
- 表し
- 必要
- 研究
- 研究者
- リソース
- REST
- 結果
- 結果
- 明らかに
- 明らかにする
- 革命を起こした
- 上昇
- ROBERT
- 堅牢な
- 大体
- ルール
- 前記
- 同じ
- サン
- サンディエゴ
- サンフランシスコ
- 見ました
- 言う
- 思われる
- 見えた
- と思われる
- 見て
- 見て
- センス
- 9月
- セッションに
- ショット
- 示されました
- 簡単な拡張で
- 簡単な
- 単に
- スライス
- ゆっくり
- 小さい
- So
- これまでのところ
- 溶液
- 解決
- 一部
- 何か
- 時々
- すぐに
- 洗練された
- スペース
- start
- 開始
- 着実に
- まだ
- Force Stop
- 構造
- 研究
- 研究
- 勉強
- 勉強
- そのような
- 突然の
- 合計
- 表面
- 疑わしいです
- システム
- 仕事
- タスク
- チーム
- テクノロジー
- 傾向があります
- 傾向がある
- 期間
- 条件
- test
- テスト
- テスト
- より
- それ
- アプリ環境に合わせて
- それら
- 自分自身
- その後
- 理論的な
- 理論的には
- ボーマン
- 彼ら
- 物事
- 考える
- 考え
- この
- 徹底的に
- しかし?
- 考え
- 介して
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 今日の
- 言われ
- 取った
- に向かって
- トレーニング
- 訓練された
- トレーニング
- 列車
- 最適化の適用
- トランス
- 変換
- トランスフォーム
- 遷移
- 樹木類
- 勝利
- 2
- 一般的に
- 下
- わかる
- 理解する
- 予期しない
- ユニーク
- ユニット
- 大学
- カリフォルニア大学
- メリーランド大学
- に
- us
- つかいます
- 中古
- いつもの
- 休暇
- 価値観
- 検証
- バージョン
- 非常に
- ました
- 見ている
- 仕方..
- 方法
- we
- webp
- 奇妙な
- went
- した
- この試験は
- どのような
- いつ
- which
- while
- 誰
- その
- なぜ
- 意志
- 勝
- 知恵
- 仕事
- 仕組み
- 書かれた
- 間違った
- 年
- 貴社
- ゼファーネット
- ゼロ