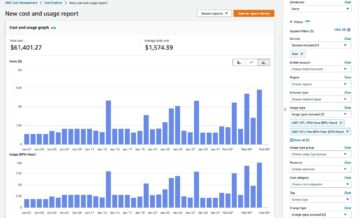
顧客についてもっと知ることは常に有益です。 AWSデータ交換 公開されている国勢調査データを簡単に使用して、顧客データセットを充実させることができます。
米国国勢調査局は 10 年ごとに米国の国勢調査を実施し、世帯調査データを収集します。このデータは匿名化され、集約され、一般公開されます。国勢調査局がデータを収集および集計する最小の地理的エリアは、道路、道路、鉄道、小川、その他の水域、その他の目に見える物理的および文化的特徴、および国勢調査局の地図に示される法的境界によって形成される国勢調査ブロックです。 。
顧客が住んでいる国勢調査区域がわかれば、その顧客の人口統計的特徴について一般的な推論を行うことができます。これらの新しい属性を使用すると、セグメンテーション モデルを構築して、パーソナライズされたメッセージングの対象となる個別の顧客グループを識別できます。このデータは AWS Data Exchange で購読できます。また、データ共有を使用すると、クエリを実行するためにアカウントにデータのコピーを保存するために料金を支払う必要はありません。
この投稿では、顧客の住所を使用して、米国国勢調査局のデータセットからの追加の人口統計の詳細でデータセットを強化する方法を示します。
ソリューションの概要
このソリューションには、次の高レベルの手順が含まれています。
- セットアップ AmazonRedshiftサーバーレス エンドポイントを設定して顧客データをロードします。
- 場所のインデックスを設定します Amazonロケーションサービス.
- 書く AWSラムダ 位置情報サービスを呼び出すためのユーザー定義関数 (UDF) Amazonレッドシフト.
- AWS Data Exchange で国勢調査データを購読します。
- 地理空間クエリを使用して、住所を国勢調査ブロックにタグ付けします。
- Amazon Redshift で新しい顧客データセットを作成します。
- 新規顧客データを評価する アマゾンクイックサイト.
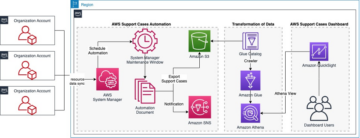
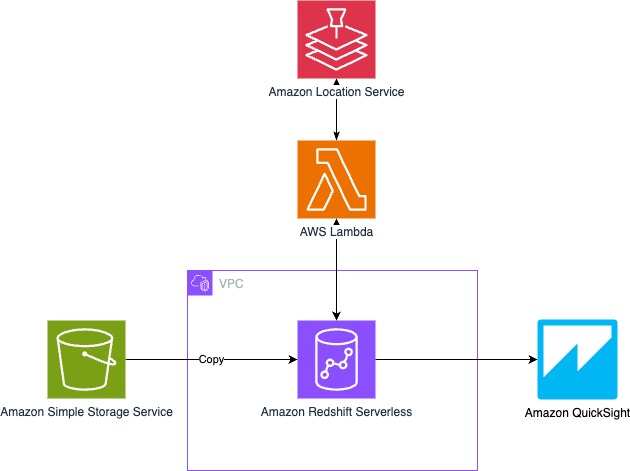
次の図は、ソリューションのアーキテクチャを示しています。
前提条件
次のものを使用できます AWS CloudFormation template 必要なインフラストラクチャを展開します。導入する前に、次の方法で QuickSight アクセスにサインアップする必要があります。 AWSマネジメントコンソール.
汎用住所データを Amazon Redshift にロードする
Amazon Redshift は、クラウド上のフルマネージド型のペタバイト規模のデータ ウェアハウス サービスです。 Redshift Serverless を使用すると、データ ウェアハウス インフラストラクチャを管理することなく、あらゆるサイズの分析ワークロードを簡単に実行できます。
住所データをロードするには、まず Redshift サーバーレス ワークグループを作成します。次に、Amazon Redshift Query Editor v2 を使用して顧客データをロードします。 Amazon シンプル ストレージ サービス (Amazon S3)。
Redshiftサーバーレスワークグループを作成する
Redshift サーバーレス アーキテクチャには 2 つの主要コンポーネントがあります。
- 名前空間 – データベース オブジェクトとユーザーのコレクション。ネームスペースは、スキーマ、テーブル、ユーザー、データ共有、スナップショットなど、Redshift Serverless で使用するすべてのリソースをグループ化します。
- ワークグループ – コンピューティング リソースのコレクション。ワークグループには、Redshift Serverless コンソールを使用して構成できるネットワークとセキュリティの設定があります。 AWSコマンドラインインターフェイス (AWS CLI)、または Redshift サーバーレス API。
ネームスペースとワークグループを作成するには、以下を参照してください。 Amazon Redshift Serverless を使用したデータ ウェアハウスの作成。この演習では、ワークグループ サンドボックスと名前空間に adx-demo という名前を付けます。
Query Editor v2 を使用して Amazon S3 から顧客データをロードする
Query Editor v2 を使用すると、Web インターフェイスを通じてクエリを送信し、データ ウェアハウスにデータをロードできます。 AWS アカウント用に Query Editor v2 を設定するには、以下を参照してください。 Query Editor V2 を使用して、Amazon Redshift でデータの読み込みを簡単かつ安全に。構成したら、次の手順を実行します。
- 次の SQL を使用して、
customer_dataデータ ウェアハウスの開発データベース内のスキーマ:
- 次の SQL DDL を使用して、顧客の住所データをロードするターゲット テーブルを作成します。
ファイルには列ヘッダーがなく、パイプ (|) で区切られています。 Amazon S3 またはローカル デスクトップからデータをロードする方法については、を参照してください。 データベースへのデータのロード.
位置情報サービスを使用して住所データをジオコーディングおよび強化する
位置情報サービスを使用すると、アプリケーションに位置データと機能を追加できます。これには、地図、名所、ジオコーディング、ルーティング、ジオフェンス、追跡などの機能が含まれます。
データは Amazon Redshift にあるため、SQL ステートメントを使用して位置情報サービス API にアクセスする必要があります。データの各行には、Location Service API を使用して情報を追加し、ジオタグを付けたい住所が含まれています。 Amazon Redshift を使用すると、開発者は SQL SELECT 句、Python、または Lambda を使用して UDF を作成できます。
Lambda は、サーバーのプロビジョニングや管理を行わずにコードを実行できるコンピューティング サービスです。 Lambda UDF を使用すると、複雑なロジックを使用してカスタム関数を作成し、サードパーティのコンポーネントと統合できます。スカラー Lambda UDF は、関数の呼び出しごとに 1 つの結果を返します。この場合、Lambda 関数は受信したデータの行ごとに 1 回実行されます。
この投稿では、Location Service API を使用して顧客の住所にジオタグを付け、検証する Lambda 関数を作成します。次に、この Lambda 関数を Redshift インスタンスに UDF として登録し、SQL コマンドから関数を呼び出せるようにします。
Location Service の場所インデックスを作成し、Lambda 関数とスカラー UDF を作成する手順については、を参照してください。 Amazon Redshift から Amazon Location Service にアクセスする。この投稿では、ESRI をプロバイダーとして使用し、場所インデックスに名前を付けます。 placeindex.redshift.
次のコードを使用して新しい関数をテストします。このコードは、ワシントン DC のホワイト ハウスの座標を返します。
AWS Data Exchange から人口統計データを購読する
AWS Data Exchange は、3,500 を超えるプロバイダーの 300 以上の製品が、ファイル、API、または Amazon Redshift クエリを通じて、それを使用するデータレイク、アプリケーション、分析、機械学習モデルに直接配信されるデータ マーケットプレイスです。
まず、Redshift 名前空間に許可を与える必要があります。 AWS IDおよびアクセス管理 (IAM) AWS Data Exchange のサブスクリプションにアクセスします。次に、サンプル人口統計データを購読できます。次の手順を実行します。
- IAM コンソールで、
AWSDataExchangeSubscriberFullAccess管理ポリシーを、名前空間の作成時に割り当てた Amazon Redshift コマンド アクセス ロールに適用します。 - AWS Data Exchange コンソールで、データセットに移動します。 ACS – 社会人口統計 (米国、国勢調査ブロックグループ、2019)、CARTOによって提供されます。
- 選択する 購読を続ける、を選択します ニュースレター登録.
サブスクリプションの構成には数分かかる場合があります。
- サブスクリプションが完了したら、Redshift Serverless コンソールに戻ります。
- ナビゲーションペインで、 データ共有.
- ソフトウェア設定ページで、下図のように プラン契約確認 タブで、サブスクライブしたばかりのデータ共有を選択します。
- データ共有の詳細ページで、 データ共有からデータベースを作成する.
- 前に作成した名前空間を選択し、サブスクライブしたデータセットの共有オブジェクトを保持する新しいデータベースの名前を指定します。
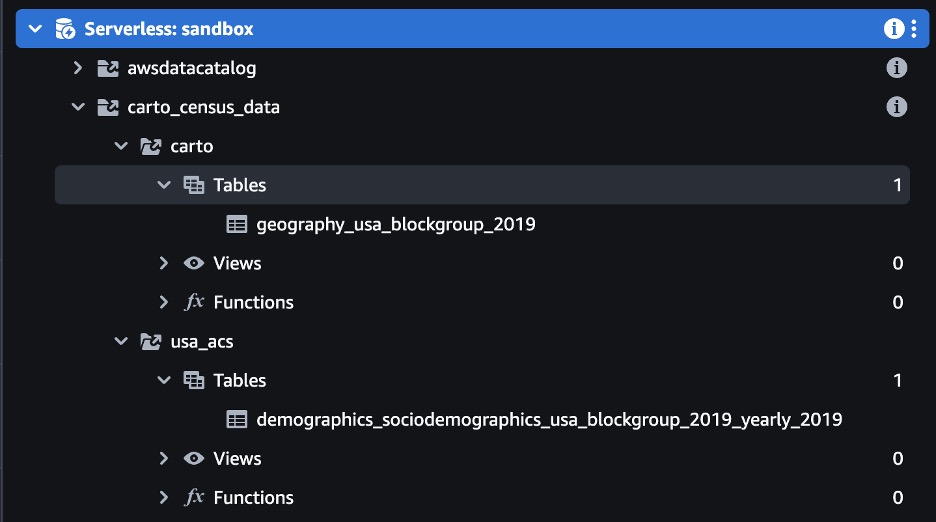
クエリ エディター v2 では、作成したばかりの新しいデータベースと XNUMX つの新しいテーブルが表示されます。XNUMX つはブロック グループのポリゴンを保持し、もう XNUMX つは各ブロック グループの人口統計情報を保持します。
地理空間クエリを使用して、ジオコーディングされた顧客データを国勢調査データに結合します
空間データには、ラスター データとベクター データという 2 つの主なタイプがあります。ラスター データはピクセルのグリッドとして表現されますが、この投稿の範囲外です。ベクター データは頂点、エッジ、ポリゴンで構成されます。地理空間データを使用すると、 頂点 緯度と経度の点として表され、 エッジ は頂点のペア間の接続です。地図上の 2 つの交差点を結ぶ道路を考えてください。あ ポリゴン は、連続的な形状を形成する一連の接続エッジを持つ頂点のセットです。オハイオ州の州境が多角形で表現できるのと同じように、単純な長方形は多角形です。サブスクライブした geography_usa_blockgroup_2019 データセットには 220,134 行があり、それぞれが単一の国勢調査ブロック グループとその地理的形状を表しています。
Amazon Redshift は、ベクトルベースの空間データのストレージとクエリをサポートしています。 GEOMETRY および GEOGRAPHY データ型。 Redshift SQL 関数を使用して、ポリゴン内のポイント操作などのクエリを実行して、特定の緯度/経度のポイントが特定のポリゴンの境界 (州や郡の境界など) 内にあるかどうかを判断できます。このデータセットでは、 geom の列 geography_usa_blockgroup_2019 タイプは GEOMETRY です。
私たちの目標は、ジオタグ付きの各住所がどの国勢調査ブロック (ポリゴン) に該当するかを判断し、国勢調査ブロックについて知っている詳細情報で顧客記録を充実させることです。次の手順を実行します。
- UDF からのジオコーディング結果を使用して新しいテーブルを作成します。
- 次のコードを使用して、JSON 列からさまざまな住所フィールドと緯度/経度の座標を抽出し、その結果を含む新しいテーブルを作成します。
このコードでは、 ST_POINT という緯度経度座標から新しい列を作成する関数 address_point タイプ GEOMETRY およびサブタイプ POINT の。それは、 ST_SetSRID geospatial 関数を使用して、新しい列の空間参照識別子 (SRID) を 4326 に設定します。
SRID は、ジオメトリ データを評価するときに使用される空間参照系を定義します。地理空間データを結合または比較する場合、一致する SRID があることが重要です。既存のジオメトリ列の SRID を確認するには、 ST_SRID 関数。 SRID と GEOMETRY データ型の詳細については、以下を参照してください。 Amazon Redshift での空間データのクエリ.
- これで、顧客の住所がジオメトリ列の緯度/経度ポイントとしてジオコーディングされたので、結合を使用して、新しいポイントがどの国勢調査ブロック形状に含まれるかを特定できます。
前述のコードは、という新しいテーブルを作成します。 customer_addresses_with_censusこれにより、顧客の住所が、その顧客が属する国勢調査ブロックと、その国勢調査ブロックに関連付けられた人口統計データに結合されます。
これを行うには、 ST_CONTAINS この関数は 2 つのジオメトリ データ タイプを入力として受け入れ、最初の入力ジオメトリの XNUMXD 投影に XNUMX 番目の入力ジオメトリが含まれる場合に TRUE を返します。この例では、国勢調査ブロックが多角形で表現され、住所が点で表現されています。 SQL ステートメント内の結合は、点が多角形の境界内にある場合に成功します。
QuickSight で新しい人口統計データを視覚化する
QuickSight は、どこにいても一緒に働く人々にわかりやすい洞察を提供するために使用できるクラウド スケールのビジネス インテリジェンス (BI) サービスです。 QuickSight はクラウド内のデータに接続し、さまざまなソースからのデータを結合します。
まず、顧客ベースの人口統計をより深く理解するのに役立つ新しい計算フィールドをいくつか構築しましょう。これは QuickSight で行うことも、SQL を使用して Redshift ビューで列を構築することもできます。以下は Redshift ビューのコードです。
QuickSight が Redshift サーバーレス エンドポイントと通信できるようにするには、次の手順を実行します。
これで、QuickSight で新しいデータセットを作成できるようになりました。
- QuickSightコンソールで、 データセット ナビゲーションペインに表示されます。
- 選択する 新しいデータセット.
- 新しいデータ ソースからデータセットを作成し、 Redshift: 手動接続 オプションを選択します。
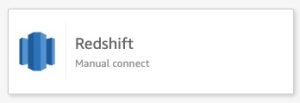
- Redshift Serverless ワークグループの接続情報を指定します。
ワークグループのエンドポイントと、ワークグループの設定時に作成したユーザー名とパスワードが必要になります。 Redshift Serverless コンソールでワークグループ設定に移動すると、ワークグループのエンドポイントを見つけることができます。次のスクリーンショットは、必要な接続設定の例です。接続タイプが、QuickSight で以前に構成した VPC 接続の名前であることに注意してください。 Redshift コンソールからエンドポイントをコピーする場合は、フィールドに入力する前に、URL の末尾からデータベースとポート番号を必ず削除してください。
- 新しいデータ ソース構成を保存します。
データセットに使用するテーブルを選択するように求められます。
- 新しい派生フィールドを含む、作成した新しいビューを選択します。
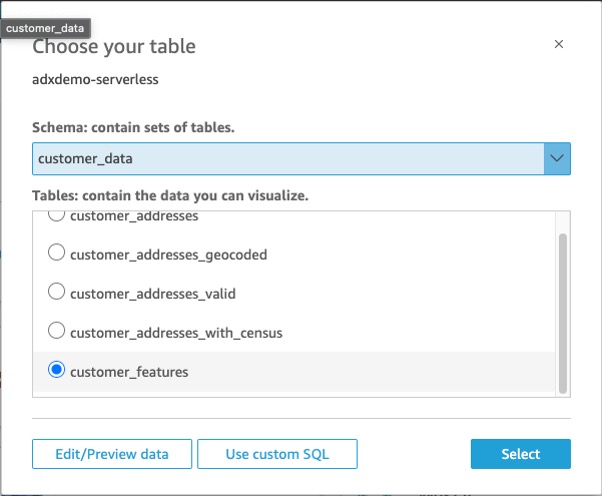
- 選択 データを直接クエリする.
これにより、QuickSight インメモリ データ ストアにデータが取り込まれるのではなく、ビジュアライゼーションがデータベース内のデータに直接接続されます。
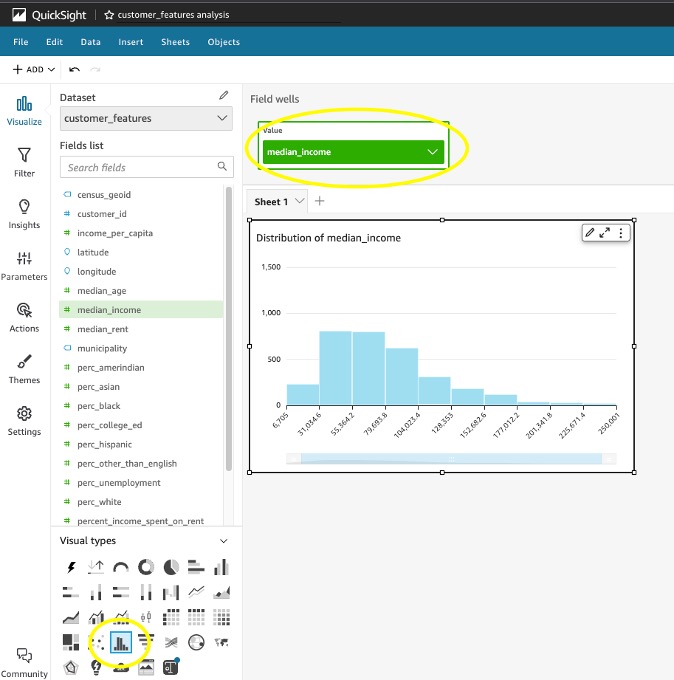
- 収入レベルの中央値のヒストグラムを作成するには、Sheet1 の空白のビジュアルを選択し、その下のヒストグラム ビジュアル アイコンを選択します。 ビジュアルタイプ.
- 選択する
median_income下 フィールドリスト それをドラッグして、 値 よくフィールド。
これにより、次の分布を示すヒストグラムが作成されます。 median_income お客様が住んでいる国勢調査ブロック グループに基づいて、お客様を対象としています。
まとめ
この投稿では、企業が AWS Data Exchange で利用可能なオープン国勢調査データを使用して、人口統計の観点から顧客ベースの高度な理解を容易に得る方法を実証しました。顧客の居住地に基づいた顧客の基本的な理解は、よりターゲットを絞ったマーケティング キャンペーンの基盤として機能し、製品開発やサービス提供に影響を与えることもあります。
いつものように、AWS は皆様からのフィードバックをお待ちしております。ご意見やご質問をコメント欄に残してください。
著者について
 トニー・ストリッカー AWS のデータ戦略チームの主任技術者であり、上級幹部がデータドリブンの考え方を採用し、イノベーションを促進し、具体的で具体的なビジネス成果に向けて推進できる方法で人材、プロセス、テクノロジーを調整するのを支援しています。彼はデータ ウェアハウス アーキテクトおよびデータ サイエンティストとしての経歴を持ち、石油とガス、金融サービス、公共部門、製造を含む複数の業界の生産にソリューションを提供してきました。トニーは余暇には、犬や猫と遊んだり、家の改善プロジェクトに取り組んだり、ビンテージのエアストリーム キャンピングカーをレストアしたりすることが好きです。
トニー・ストリッカー AWS のデータ戦略チームの主任技術者であり、上級幹部がデータドリブンの考え方を採用し、イノベーションを促進し、具体的で具体的なビジネス成果に向けて推進できる方法で人材、プロセス、テクノロジーを調整するのを支援しています。彼はデータ ウェアハウス アーキテクトおよびデータ サイエンティストとしての経歴を持ち、石油とガス、金融サービス、公共部門、製造を含む複数の業界の生産にソリューションを提供してきました。トニーは余暇には、犬や猫と遊んだり、家の改善プロジェクトに取り組んだり、ビンテージのエアストリーム キャンピングカーをレストアしたりすることが好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/enrich-your-customer-data-with-geospatial-insights-using-amazon-redshift-aws-data-exchange-and-amazon-quicksight/
- :持っている
- :は
- :どこ
- $UP
- 10
- 100
- 11
- 13
- 16
- 20
- 2019
- 220
- 2D
- 30
- 300
- 500
- 7
- a
- できる
- 私たちについて
- 受け入れる
- アクセス
- 越えて
- 加えます
- NEW
- 住所
- アドレス
- 採用
- 後
- 集約された
- 骨材
- 整列する
- すべて
- 許可
- ことができます
- 常に
- Amazon
- アマゾンクイックサイト
- Amazon Webサービス
- an
- 分析論
- および
- 別の
- どれか
- API
- API
- 建築
- です
- AREA
- AS
- 割り当てられた
- 関連する
- At
- 属性
- オート
- 利用できます
- 鳥
- AWS
- バック
- 背景
- ベース
- ベース
- 基本
- BE
- より良いです
- の間に
- 越えて
- ブロック
- ブロック
- ボディ
- 国境
- 境界
- ビルド
- 構築します
- オフィス
- ビジネス
- ビジネス・インテリジェンス
- by
- 計算された
- コール
- 呼ばれます
- キャンペーン
- 缶
- 機能
- 場合
- CAT
- 国勢調査
- 国勢調査局
- 国勢調査データ
- 文字
- 特性
- チェック
- 選択する
- クリ
- クラウド
- コード
- コレクション
- 集める
- コラム
- コラム
- 組み合わせ
- 注釈
- 企業
- 比較
- コンプリート
- 複雑な
- コンポーネント
- 構成
- 計算
- 行動する
- 設定された
- お問合せ
- 接続する
- 接続
- Connections
- コネクト
- 領事
- 含まれています
- 連続的な
- 座標
- copy
- 国
- 郡
- 作ります
- 作成した
- 作成します。
- 作成
- 文化的な
- カスタム
- 顧客
- 顧客データ
- Customers
- データ
- データ交換
- データサイエンティスト
- データ共有
- データ戦略
- データウェアハウス
- データ駆動型の
- データベース
- dc
- 定義する
- 配信する
- 配信
- デモ
- 人口動態
- 人口動態
- 実証
- 展開します
- 展開
- 派生
- デスクトップ
- 細部
- 決定する
- デベロッパー
- 開発者
- 開発
- ダイアグラム
- 異なります
- 直接に
- 明確な
- ディストリビューション
- do
- 犬
- ドント
- ドライブ
- 各
- 前
- 簡単に
- エッジ
- エディタ
- 楽
- どちら
- end
- エンドポイント
- 豊かにする
- 入る
- エーテル(ETH)
- 評価します
- さらに
- あらゆる
- 例
- 交換
- 幹部
- 運動
- 既存の
- エクスプローラ
- エキス
- フォールズ
- 特徴
- フィードバック
- 少数の
- フィールド
- フィールズ
- File
- ファイナンシャル
- 金融業務
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- フロート
- フォロー中
- フォーム
- 形成
- 育てる
- Foundation
- から
- 完全に
- function
- 機能性
- 機能
- 利得
- GAS
- 地理的
- 地理
- 取得する
- 与える
- 与えられた
- 目標
- グリッド
- グループ
- グループの
- ハング
- 持ってる
- 持って
- he
- ヘッダーの
- 助けます
- ことができます
- ハイレベル
- 彼の
- 保持している
- ホーム
- お家の掃除
- 家庭
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ICON
- 識別子
- 識別する
- アイデンティティ
- if
- 説明する
- 重要
- 改善
- in
- 含ま
- 含めて
- 所得
- index
- 産業
- 影響
- 情報
- インフラ関連事業
- 内側の
- 革新的手法
- 洞察
- 説明書
- 整数
- 統合する
- インテリジェンス
- 関心
- インタフェース
- 交差点
- に
- IT
- ITS
- join
- 参加
- ジョイン
- JPG
- JSON
- ただ
- 知っている
- ラベル
- 湖
- 緯度
- 学習
- コメントを残す
- リーガルポリシー
- ことができます
- レベル
- 好き
- LINE
- ライブ
- 命
- 負荷
- ローカル
- 場所
- ロジック
- 機械
- 機械学習
- 製
- 簡単に
- make
- 作る
- 管理します
- マネージド
- 管理
- 管理する
- マニュアル
- 製造業
- 多くの
- 地図
- ゲレンデマップ
- マーケティング
- マーケティングキャンペーン
- 市場
- マッチング
- 五月..
- メッセージング
- 考え方
- 分
- モデル
- 他には?
- の試合に
- 名
- ナビゲート
- ナビゲート
- ナビゲーション
- 必要
- 必要とされる
- ネットワーク
- 新作
- いいえ
- 知らせ..
- 数
- オブジェクト
- 観察する
- of
- オファリング
- オハイオ
- 油
- 石油とガス
- on
- ONE
- 開いた
- 操作
- オプション
- or
- 注文
- その他
- 私たちの
- でる
- 成果
- が
- ページ
- 足
- ペイン
- パスワード
- 支払う
- 国
- ペンシルベニア州
- のワークプ
- 以下のために
- 実行する
- 許可
- カスタマイズ
- 物理的な
- パイプ
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- ポイント
- ポイント
- 方針
- ポリゴン
- ポスト
- 前に
- 主要な
- 校長
- プロダクト
- 製品開発
- 生産
- 製品
- 投影
- プロジェクト(実績作品)
- 提供します
- 提供
- プロバイダー
- プロバイダ
- 公共
- 公然と
- Python
- クエリ
- クエリー
- 質問
- むしろ
- 受け取り
- 記録
- 参照する
- 参照
- 地域
- 登録
- 削除します
- で表さ
- 表します
- の提出が必要です
- リソース
- リストア
- 結果
- 結果
- return
- 収益
- ロード
- 道路
- 職種
- ルーティング
- 行
- 行
- ラン
- runs
- サンプル
- サンドボックス
- 科学者
- スコープ
- 二番
- セクション
- セクター
- 安全に
- セキュリティ
- セグメンテーション
- select
- シニア
- シリーズ
- 役立つ
- サーバレス
- サーバー
- サービス
- サービス
- セッションに
- 設定
- 形状
- シェイプ
- shared
- シェアリング
- すべき
- 表示する
- 表示
- 示す
- 符号
- 簡単な拡張で
- サイズ
- 最小
- So
- 溶液
- ソリューション
- 一部
- ソース
- ソース
- 空間の
- 特定の
- SQL
- 立場
- 都道府県
- ステートメント
- 文
- 米国
- ステップ
- ストレージ利用料
- 店舗
- 簡単な
- 戦略
- ストリーム
- ストリート
- 提出する
- 申し込む
- 購読
- サブスクリプション
- 成功する
- そのような
- サポート
- 確か
- Survey
- T
- テーブル
- TAG
- 取る
- Talk
- 有形
- ターゲット
- 対象となります
- チーム
- 技術者
- より
- それ
- ブロック
- ステート
- アプリ環境に合わせて
- その後
- ボーマン
- 彼ら
- 考える
- サードパーティ
- この
- 介して
- 時間
- 〜へ
- 一緒に
- トニー
- に向かって
- 追跡
- true
- 2
- type
- 下
- わかる
- 理解する
- ユナイテッド
- 米国
- URL
- us
- 米国国勢調査
- USA
- つかいます
- 中古
- ユーザー
- users
- 使用されます
- 検証
- ベクトル
- 、
- 詳しく見る
- ヴィンテージ
- 目に見える
- ビジュアル
- 欲しいです
- 倉庫
- ワシントン
- 水
- 方法
- we
- ウェブ
- Webサービス
- ようこそ
- WELL
- いつ
- どこにでも
- which
- 白
- ホワイトハウス
- 誰
- 意志
- 以内
- 無し
- 仕事
- ワークグループ
- 書きます
- ヤムル
- 年
- 貴社
- あなたの
- ゼファーネット