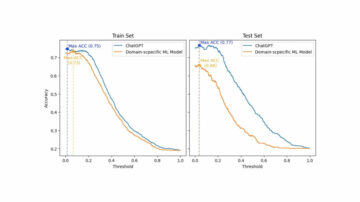
今年はプンタカナに行けませんでした  しかし、あらゆる移動制限にもかかわらずなんとかそこに到着した人々のことを(遠隔的に)嬉しく思います。プレミアムコンテンツが含まれています。
しかし、あらゆる移動制限にもかかわらずなんとかそこに到着した人々のことを(遠隔的に)嬉しく思います。プレミアムコンテンツが含まれています。
秋はとても忙しくなったので、より短い形式を試してみたいと思います: それぞれの大きなトピックに 1 つの「スポットライト」を当てる  私が特に興味深いと思うメインブロックの作品と、少し短い説明を持つ関連作品がいくつかあります。
私が特に興味深いと思うメインブロックの作品と、少し短い説明を持つ関連作品がいくつかあります。
今日の計画:
- KG拡張言語モデル:分類
- 会話型AI:幻覚をやめろ
- エンティティリンク: In the Shadow of Colossal (エンティティ)
- KG建設
- KG の質問への回答: いくつか追加
 SPARQL
SPARQL
この詳細な教育コンテンツがあなたに役立つ場合は、 AIリサーチメーリングリストに登録する 新しい素材がリリースされたときに警告が表示されます。
KG拡張言語モデル:分類
文脈言語モデルにおける関係世界知識表現:レビュー タラ・サファビとダナイ・コウトラ
あなたがそのようなダイジェスト(または以前の投稿)の経験豊富な読者であれば、あらゆるカンファレンスで公開され、毎週 arxiv にアップロードされる KG 拡張 LM が大量にあることをよくご存知でしょう。道に迷ったら  —あなただけではないと断言します。
—あなただけではないと断言します。
今年、ようやく サウンドフレームワーク およびさまざまな KG+LM アプローチの分類法!著者らは 3 つの大きなファミリーを定義しています。 1⃣ KG の監督なし、クローズ形式のプロンプトを使用して LM パラメータにエンコードされた知識を調査します。 2⃣ エンティティと ID による KG の監督。 3⃣ リレーションテンプレートとサーフェスフォームを使用した KG 監督。
各家族にはいくつかの支店があります  たとえば、以下に示す 4 つのエンティティ認識モデルを見てみましょう。から変わります 「あまり象徴的ではない」 〜へ 「より象徴的」、一部の LM は、言及スパン マスキング、対照学習、または既知の語彙からのエンティティ埋め込みの融合を実行します。著者らは、フレームワークに従って数十の既存のアーキテクチャを分類するという素晴らしい仕事をしました。今では、よりよく整理されているように見えます。とても必要な仕事です!
たとえば、以下に示す 4 つのエンティティ認識モデルを見てみましょう。から変わります 「あまり象徴的ではない」 〜へ 「より象徴的」、一部の LM は、言及スパン マスキング、対照学習、または既知の語彙からのエンティティ埋め込みの融合を実行します。著者らは、フレームワークに従って数十の既存のアーキテクチャを分類するという素晴らしい仕事をしました。今では、よりよく整理されているように見えます。とても必要な仕事です! 

いくつかの短い論文は、LMを生物医学KGで強化することに焦点を当てています。これは、LMにドメイン固有の生物医学を教えるための長期にわたる取り組みです。 スラング。 孟ら 提案する パーティションの混合物 (MoP)、に基づくLM アダプタフュージョン LMを最初から事前トレーニングする必要性を軽減する手法。 MoPは、一般的な生物医学用語とオントロジーUMLSおよびSNOMEDCTでトレーニングされました。 ソンら 頼む 「言語モデルは生物医学の知識ベースになることができますか?」 を参照して Petroniらによる有名なEMNLP'19論文。 答えは主に NO。 著者のデザイン バイオラマ、UMLS、CTD、Wikidata から構築された生物医学知識を調査するためのベンチマークです。彼らは、最新の LM がそれらのプローブで 10% 未満の精度しか得ていないことを発見しました。そのため、コミュニティは間違いなくより信頼性の高いものを必要としています。
孟ら 提案する パーティションの混合物 (MoP)、に基づくLM アダプタフュージョン LMを最初から事前トレーニングする必要性を軽減する手法。 MoPは、一般的な生物医学用語とオントロジーUMLSおよびSNOMEDCTでトレーニングされました。 ソンら 頼む 「言語モデルは生物医学の知識ベースになることができますか?」 を参照して Petroniらによる有名なEMNLP'19論文。 答えは主に NO。 著者のデザイン バイオラマ、UMLS、CTD、Wikidata から構築された生物医学知識を調査するためのベンチマークです。彼らは、最新の LM がそれらのプローブで 10% 未満の精度しか得ていないことを発見しました。そのため、コミュニティは間違いなくより信頼性の高いものを必要としています。  .
.
会話型AI:幻覚をやめろ
ニューラルパスハンター:パスグラウンディングによる対話システムの幻覚の低減 Nouha Dziri、Andrea Madotto、Osmar Zaiane、Avishek Joey Bose
KGバックグラウンドを持つConvAIシステムで応答を生成するのは難しいです。 多くのコンポーネントを含むパイプラインシステムでは、サーフェスフォーム(エンティティ名)を厳密に使用し、ほとんどの場合テンプレートを使用します。 テンプレートは退屈です そしてほとんど維持できません。 一方、GPT-2やGPT-2などのe3e生成モデルは、はるかにユニークな応答を生成しますが、多くの場合、幻覚を引き起こします。つまり、予期しないときに間違ったエンティティ名を挿入します。
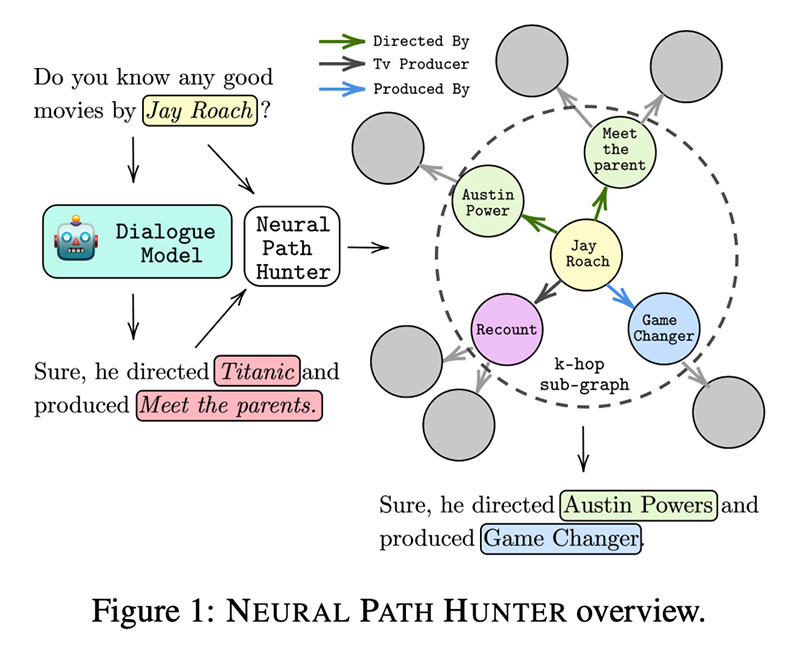
この作品の作者は、 狩り  KG監督による幻覚軽減の提案 ニューラルパスハンター。 まず、彼らはいくつかを研究します 幻覚の種類 、それらがどこから来たのか(主にトップkのサンプリングから)、そしてそれを定量化する方法。
KG監督による幻覚軽減の提案 ニューラルパスハンター。 まず、彼らはいくつかを研究します 幻覚の種類 、それらがどこから来たのか(主にトップkのサンプリングから)、そしてそれを定量化する方法。
NPH 自体は 1 つのモジュールで構成されます。2⃣ トークンに対してバイナリ分類を実行するクリティカル (非自己回帰 LM)。 XNUMX⃣ エンティティ エラーを修正するためのエンティティ取得ツール: これは本質的にエンティティ メモリであり、エンティティの埋め込みが GPT から取得され、グラフ構造を使用して CompGCN で更新されます。最も妥当な候補は、DistMult スコアリング関数を適用することで得られます。出来上がり!
NPHは、事前にトレーニングされたLMと組み合わせることができます。 オープンダイヤルKG GPT2-KGによるベンチマーク、 GPT2-KE, アダプターボット 大幅な削減を実証  幻覚と増加
幻覚と増加  忠実に。ユーザー調査では、人間が測定した幻覚が NPH モデルで約 2 倍減少したと報告されています
忠実に。ユーザー調査では、人間が測定した幻覚が NPH モデルで約 2 倍減少したと報告されています
この文脈に関連するもう 1 つの研究: ホノビッチら 対話システムで同じ問題を研究しますが、バックグラウンドKGを使用せず、新しいベンチマークを提案します Q² 質問の生成と質問応答の事実上の一貫性を測定します(質問した場合、両方のQが由来します)。
ConvAI と常識的な KG に興味がある場合は、CLUE (Conversational Multi-Hop Reasoner) を必ずチェックしてください。 アラブシャヒ、リー他の概念を組み込んだ if-(状態)、then-(アクション)、なぜなら-(目標) パターン論理ルールとシンボリック推論。
エンティティリンキング:ワンダと巨像
以前のプローブを使用したエンティティの曖昧性解消のロバスト性評価:エンティティのシャドウイングの場合 by Vera Provatorova、Svitlana Vakulenko、Samarth Bhargav、Evangelos Kanoulas
言語タスクに実際のKGを接続すると、必然的に遭遇します さまざまなエンティティ 正確に 同名  。残念ながら、人類は世界中のすべてのエンティティに一意のハッシュを使用しているわけではないため、エンティティの曖昧さの解消は依然としてエンティティ リンクの重要なステップです。
。残念ながら、人類は世界中のすべてのエンティティに一意のハッシュを使用しているわけではないため、エンティティの曖昧さの解消は依然としてエンティティ リンクの重要なステップです。

たとえば、ウィキデータには 「マイケルジョーダン」という名前の少なくとも18のエンティティ。 多くの場合、ELシステムは基本的な統計と人気スコアに依存しているため、最も人気のある「バスケットボール選手のマイケルジョーダン」は(少なくともポップカルチャーでは)あまり目立たない人々に影を落とします。
 著者らはこの問題に取り組み、新しいデータセットを導入しました。 シャドウリンク、最新のELシステムの混乱の程度を測定します。 最高のF1スコアが0.35に達することはほとんどありません(最近の生成 ジャンル 最も難しい部分で0.26)を生成します。 すべてのシステムは、ロングテールのまれなエンティティでスコアを飽和させ、より一般的なエンティティにも対処します。 主な課題は次のように定式化されています。タスクを困難にするのは、あいまいさと非共通性の組み合わせです」。 著者がデータセットをにアップロードすることをお勧めします HuggingFaceデータセット クールなプロジェクトの認知度を高めるため
著者らはこの問題に取り組み、新しいデータセットを導入しました。 シャドウリンク、最新のELシステムの混乱の程度を測定します。 最高のF1スコアが0.35に達することはほとんどありません(最近の生成 ジャンル 最も難しい部分で0.26)を生成します。 すべてのシステムは、ロングテールのまれなエンティティでスコアを飽和させ、より一般的なエンティティにも対処します。 主な課題は次のように定式化されています。タスクを困難にするのは、あいまいさと非共通性の組み合わせです」。 著者がデータセットをにアップロードすることをお勧めします HuggingFaceデータセット クールなプロジェクトの認知度を高めるため  .
.
アロラ他 別の方向からエンティティリンキングの問題にアプローチします。 主なアイデアは true 命名 エンティティ ドキュメント内(XNUMXつずつではなく共同で処理されます) スパン 低ランク 部分空間  候補を含むすべてのエンティティの空間内 (以下の視覚的な例を確認してください)。の 固有テーマ 事前にトレーニングされたエンティティの埋め込みがある場合、このアプローチは監視されません。作成者はWikidataの英語のサブセットに対してDeepWalkを使用します(または、単語の埋め込みを試みますが、うまく機能しません)。
候補を含むすべてのエンティティの空間内 (以下の視覚的な例を確認してください)。の 固有テーマ 事前にトレーニングされたエンティティの埋め込みがある場合、このアプローチは監視されません。作成者はWikidataの英語のサブセットに対してDeepWalkを使用します(または、単語の埋め込みを試みますが、うまく機能しません)。

概念的には似たような エンティティベースの競合の問題 によって研究されています ロングプレら、つまり、知識の置換 — 段落内の実際のエンティティをランダムなエンティティ(または矛盾するエンティティ)に反転した場合、モデルは答えを変更しますか?言い換えれば、QA モデルはコンテキストの読み取りや記憶された知識に依存するのでしょうか? このような置換を使用して QA モデルをトレーニングすると、OOD 一般化を大幅に向上させることができることがわかりました。
最後にアンケート調査を見てみましょう テデスキ他 on 「エンティティリンキングのNER:機能するものと次の機能」。 著者は、ELの主要な課題を特定し、NER関連の課題に対処しようとしています。 NER4EL 事前トレーニングされた大規模な LM と、特に低リソースのシナリオに関連する小規模なモデルとの間のパフォーマンスのギャップを減らすことを目的としています。 .

KG建設
私はここでキャッチーなラインを思い付くことができませんでした:/あなたがOpenIEとKG Constructionに興味があるなら、以下の論文が関連するかもしれません。
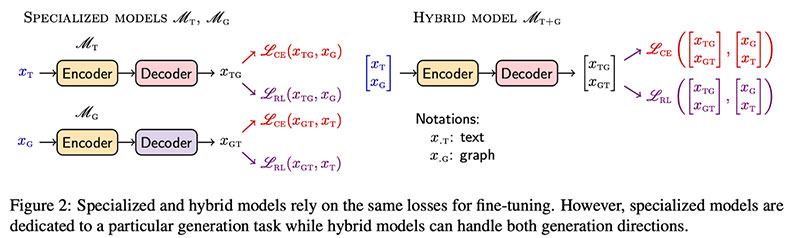
ドニンら 提案する リジェネ、Text2Graph タスクと Graph2Text タスクの両方を実行するように LM を微調整する (または特殊なモデルを微調整する) アプローチ。主要な成分  標準のクロスエントロピー (CE) に加えて、RL 損失 (セルフクリティカル シーケンス トレーニング) を追加しています。これは、事前にトレーニングされた LM に簡単に追加できます。著者は、T5-Large (770M パラメータ) と T5-base (220M パラメータ) で試しています。
標準のクロスエントロピー (CE) に加えて、RL 損失 (セルフクリティカル シーケンス トレーニング) を追加しています。これは、事前にトレーニングされた LM に簡単に追加できます。著者は、T5-Large (770M パラメータ) と T5-base (220M パラメータ) で試しています。  実験的には、 リジェネ Text2Graph WebNLGベースライン(メトリックに応じて3〜10絶対ポイント)を大幅に改善し、 ずっと より大きい TekGenデータセット (6Mトレーニングペア)。
実験的には、 リジェネ Text2Graph WebNLGベースライン(メトリックに応じて3〜10絶対ポイント)を大幅に改善し、 ずっと より大きい TekGenデータセット (6Mトレーニングペア)。
ダッシュ他 勉強する 正規化 OpenIEの問題—さまざまな表面形状を持つエンティティが (NYC、ニューヨーク市) 同じプロトタイプを参照してください。 教師なしの方法で、IEシステムがそれらの言及を自動的にクラスター化することを望んでいます。 方法、 クバ、クラスターを識別するために変分オートエンコーダー(VAE)に頼ります(エンティティと関係はガウス分布によってパラメーター化されます)。 VAEの標準に加えて 再建損失、CUVAは追加を採用しています リンク予測 損失 HolE スコアリング関数に基づいています。  さらに、著者は小説を紹介します カノニックネル データセット!
さらに、著者は小説を紹介します カノニックネル データセット!

KG の質問への回答: いくつか追加 SPARQL
中間質問分解からのSPARQLingデータベースクエリ by イリーナ・サパリナとアントン・オシン
残念ながら、*CL ドメインには SPARQL のアプリケーションはそれほど多くありません。これは NLP でさらに広く採用される価値があると思います。クールなアプリケーションでサポートされていれば、私はその気になれます  .
.
構造化されたQAデータセットの大部分、またはセマンティック解析ターゲットSQLをメインの出力形式として使用しているデータセット。 SQLパイプラインを超えた人生はありますか?
サパリナとオソキン まず 1⃣ を使用して、その問題に対する新しい見方を提案します。 質問分解意味表現(QDMR) 質問を構文に依存しない論理形式に変換するフレームワーク。 2⃣ このフォームは任意の構造化フォーマットに変換できます。ここで著者は SPARQL を利用して、グラフ形式でデータベースをクエリする方がはるかに簡単であることを示しています。入力テーブルを RDF に変換する必要がありますが、 クモ スケーリングは非常に簡単に実行できます。
トレーニング可能なモジュールには次のものが含まれます RATトランス QDMRトークンを生成するLSTMデコーダーを備えたエンコーダー。 QDMR-> SPARQLは、いくつかのルールに基づくストレートトランスパイルです。 SOTA と同等の結果。 コードが利用可能です ; SPARQL は SQL よりもうまく機能します。
SOTA と同等の結果。 コードが利用可能です ; SPARQL は SQL よりもうまく機能します。
良い紙を作るために他に何が必要ですか?

もう一つの刺激的な作品 Dasetalによる「知識ベースを介した自然言語クエリの事例ベース推論」 SPARQLと 事例ベースの推論 (CBR)。 CBRは、80年代にエキスパートシステムに深く根ざしていますが、最近、表現学習の力で復活しました。 2021年のCBRのTLDRの説明:これは、概念的には構成の一般化に近いものです。つまり、いくつかの基本的な例を見て、以前は見られなかったエンティティに関するより複雑なクエリを作成できます。
以下の例をご覧ください。 入力クエリがあります 「ホビットのギムリの父親の兄弟は誰ですか?」。 トレーニングデータでは、GimliやHobbitについては何もわかっていない可能性がありますが、「比較的類似している」可能性があります。 例 クエリに役立つと思われる関係について、たとえば、 「チャーリーシーンのお父さんは誰ですか?」 Freebase関係で people.person_parents および 「リアーナの兄弟は誰ですか?」 関係と people.person.sibling_s 。 私たちの質問のためにそれらを構成し、データベースへのSPARQLクエリを構築します。
提案 CBR-KBQA このアプローチは、1⃣ DPR スタイルのトレーニング可能なニューラル レトリーバー (監視は重複関係に基づいています)、2⃣ 連結された関連する質問とクエリは非常に長いため、線形トランスフォーマー (BigBird を使用)、3⃣ をクリーンアップするためのいくつかの再ランキング メカニズムを組み合わせています。予測。既製の NER およびエンティティ リンク モジュールを使用し、再ランキング用に事前トレーニングされた TransE リレーション エンベディングも採用しています。 CBR-KBQA は、以下を含むいくつかの KBQA データセットで優れたパフォーマンスを示します。 CFQ。 ちょっとしたメモ:利用可能な最高のSOTAモデル(67.3 MCD-Mean)が78.1までのマージンを上回り、ベンチマークに提出されていないのではないかと少し疑っています。コードもまだ利用できません。

シら マルチホップQAを研究し、エンティティ/関係ID(ラベル形式)とその自然言語の説明(テキスト形式)の両方をメッセージ伝播フレームワークに統合することを提案します トランスファーネット。 評価は、標準のMetaQA、WebQuestionsSP、およびComplexWebQuestionsデータセットで行われます。
同じタスク (前の作業と同じデータセット) で、 オリヤ他 ほとんどのSOTAQAモデルは、すでにKGエンティティにリンクされているテキストスパンを必要とし、KGエンティティのノード近傍の機能とテキストスパンの機能を使用して動的エンティティの再ランク付けでこの要件を回避しようとしていることに気付きました。
それはすべての人々です
この短い「プレママ」が気に入ったら教えてください  以前のレビューのような長いテキストの壁よりも優れたフォーマットです。ここに時間を割いていただきありがとうございます。何か役立つものをお持ち帰っていただければ幸いです
以前のレビューのような長いテキストの壁よりも優れたフォーマットです。ここに時間を割いていただきありがとうございます。何か役立つものをお持ち帰っていただければ幸いです

この記事は、最初に公開された M 著者の許可を得てTOPBOTSに再公開しました。
この記事をお楽しみください? その他のAIアップデートにサインアップしてください。
技術教育が追加されましたらお知らせします。
ポスト EMNLP2021の知識グラフ 最初に登場した トップボット.
- '
- "
- 10
- 11
- 2021
- 67
- 7
- 9
- a
- 私たちについて
- 豊富
- 従った
- Action
- 追加されました
- 添加
- 住所
- 管理
- 養子縁組
- AI
- 愛の研究
- 目指す
- すべて
- 既に
- 曖昧さ
- 分析論
- 別の
- 回答
- 申し込み
- 適用された
- 適用
- アプローチ
- 記事
- 著者
- 自動的に
- 利用できます
- 背景
- バスケットボール
- 以下
- ベンチマーク
- BEST
- の間に
- 越えて
- 最大の
- ビット
- ブロック
- ビジネス
- コール
- 候補
- 場合
- 例
- 挑戦する
- 課題
- 挑戦
- 変化する
- 市町村
- 分類
- コード
- 組み合わせ
- 来ます
- コマンドと
- コミュニティ
- 複雑な
- コンポーネント
- 講演
- 混乱
- 建設
- コンテンツ
- 可能性
- 文化
- 顧客
- カスタマーサービス
- データ
- データベース
- データベースを追加しました
- 深いです
- 実証します
- によっては
- 説明する
- DID
- 異なります
- そうではありません
- ドメイン
- ダイナミック
- 各
- 簡単に
- 教育
- 教育の
- 努力
- 従業員
- 英語
- エンティティ
- エンティティ
- 特に
- 本質的に
- 評価
- イベント
- 例
- 例
- エキサイティング
- 既存の
- 期待する
- エキスパート
- 家族
- 家族
- 特徴
- 最後に
- ファイナンス
- 名
- フォーカス
- フォロー中
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- フォーム
- フレームワーク
- から
- function
- ギャップ
- 世代
- 生々しい
- GitHubの
- 目標
- 良い
- 素晴らしい
- ハッピー
- 持って
- 高さ
- こちら
- ホーム
- 希望
- 認定条件
- How To
- hr
- HTTPS
- 人類
- アイデア
- 識別する
- 重要
- 印象的
- その他の
- 含めて
- 増える
- 統合する
- 投資
- IT
- 自体
- ジョブ
- キー
- 知っている
- 知識
- 既知の
- ラベル
- 言語
- 大
- 学習
- リーガルポリシー
- LINE
- 連結
- ロンドン
- 長い
- 見て
- 大多数
- make
- 作る
- 管理します
- マネージド
- 方法
- マーケティング
- 材料
- 意味
- だけど
- ミディアム
- メモリ
- 言及
- かもしれない
- モデル
- 他には?
- 最も
- 一番人気
- すなわち
- 名
- ナチュラル
- ニーズ
- ニューヨーク
- ニューヨーク市
- 概念
- NYC
- オンタリオ
- 業務執行統括
- 整理
- その他
- 紙素材
- 部
- 特に
- パフォーマンス
- 人
- お願いします
- ポイント
- 人気
- 人気
- 投稿
- 電力
- 予測
- プレミアム
- かなり
- 前
- 問題
- 作り出す
- プロダクト
- プロジェクト
- 著名な
- 提案する
- 質問
- リーダー
- リーディング
- 最近
- 最近
- 推奨する
- 減らします
- 電話代などの費用を削減
- 縮小
- 関係
- リリース
- 関連した
- 信頼性のある
- 残っている
- レポート
- 表現
- 必要とする
- 研究
- リゾート
- 結果
- ルール
- セールス
- 同じ
- 規模
- 得点
- いくつかの
- Shadow
- ショート
- 符号
- 重要
- 小さい
- So
- 一部
- 何か
- スペース
- 専門の
- 標準
- 都道府県
- 統計情報
- 構造化された
- 勉強
- 提出された
- 監督
- サポート
- サポート
- 表面
- Survey
- システム
- ターゲット
- タスク
- 技術的
- テンプレート
- 世界
- 時間
- 今日
- 一緒に
- トークン
- トピック
- トレーニング
- 変換
- 旅行
- Uk
- ユニーク
- 更新版
- つかいます
- さまざまな
- 視認性
- W
- ウェブ
- weekly
- この試験は
- 誰
- より広い
- 言葉
- 仕事
- 作品
- 世界
- でしょう
- 年
- あなたの