概要
最近のAIの進歩により、 ラングチェーン、ChatGPT ビルダー、Hugging Face の卓越性により、AI と LLM アプリ よりアクセスしやすくなりました。しかし、多くの人はこれらのツールを効果的に活用する方法がわかりません。
この記事では、ランダムな画像からストーリーを生成する AI ストーリーテラー アプリケーションの構築について説明します。オープンソース LLM モデルと業界標準のアプローチによるカスタム プロンプトを利用して、段階的なプロセスを見ていきます。
始める前に、この有益な情報への期待を明確にしておきましょう。
学習目標
- 独自の OpenAI および Hugging Face アカウントを作成し、API キーを生成します。
- API を使用してオープンソース LLM モデルの機能を活用します。
- プロジェクトの秘密を保護します。
- 複雑なプロジェクトを管理可能なタスクに分解し、プロジェクトのワークフローを作成します。
- Lang-Chain モジュールを使用して LLM にカスタム命令を与えます。
- デモンストレーション用に簡単な Web インターフェイスを作成します。
- 業界における LLM プロジェクトの開発における詳細レベルを高く評価する
前提条件
先に進む前に、満たす必要のあるいくつかの前提条件があります。
- Python – Python 3.8 以上をインストールすると、いくつかの手順で問題が発生する可能性があります。
- ミニコンダ – オプション。隔離された環境で作業したい場合のみ選択してください。
- VSコード – 複数の言語をサポートする軽量の IDE。
したがって、すべての前提条件を満たしていると仮定して、AI Storyteller アプリケーションのプロジェクト ワークフローを理解することから始めましょう。
目次
この記事は、の一部として公開されました データサイエンスブログ。
AI Storyteller アプリケーションのワークフロー
他のソフトウェア会社と同様に、プロジェクトの概要を作成することから始めましょう。
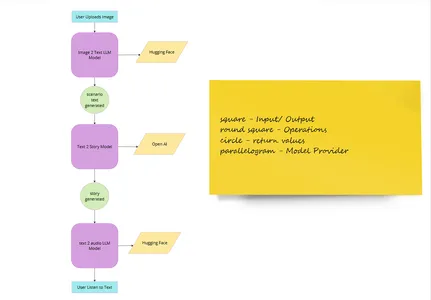
これは、アプローチとプロバイダーとともに行う必要があることの表です。
| セクション名 | アプローチ | プロバイダー |
| 画像アップロード | 画像アップロード Web インターフェイス | Python ライブラリ |
| 画像をテキストに変換 | LLM モデル (img2text) | ハグ顔 |
| テキストからストーリーを生成する | AI言語モデルを活用してコードのデバッグからデータの異常検出まで、 | オープンAI |
| ストーリーを音声に変換する | LLM モデル (text2speech) | ハグ顔 |
| ユーザーが音声を聞く | オーディオインターフェース | Python ライブラリ |
| ンを予約する(英語) | Webインターフェイス | Python ライブラリ |
まだ不明な場合は、ここに概要のユーザー フロー イメージを示します 👇
ワークフローを定義したら、プロジェクト ファイルを整理することから始めましょう。
従業員のセットアップ
作業ディレクトリのコマンド プロンプトに移動し、次のコマンドを 1 つずつ入力します。
mkdir ai-project
cd ai-project
code最後のコマンドを実行すると、VS コードが開き、ワークスペースが作成されます。このワークスペースで作業を進めていきます。
あるいは、ai-project フォルダーを作成し、vs code 内で開くこともできます。選択はあなた次第です😅。
次に、.env ファイル内に次のように 2 つの定数変数を作成します。
HUGGINGFACEHUB_API_TOKEN = YOUR HUGGINGFACE API KEY
OPENAI_API_KEY = YOUR OPEN AI API KEY次に、値を入力しましょう。
OpenAI APIキーを取得する
Open AI を使用すると、開発者は API キーを使用して製品を操作できるようになります。それでは、自分用に API キーを取得してみましょう。
- に行きます オープンアイ 公式ウェブサイトにアクセスし、「ログイン/サインアップ」をクリックします。
- 次に、資格情報を入力してログイン/サインアップします。サインアップした場合は、この手順をやり直してください。
- ログインすると、ChatGPT または API の 2 つのオプションが表示され、API を選択します。
- 次のページで、鍵 🔒 記号 (読んでいる時点では異なる場合があります) に移動し、サイドバーをクリックします (open-ai.png を参照)。
- 新しいページがサイドバー (RHS) に表示されます。今すぐクリックしてください 新しい秘密鍵を作成します。
- キーに名前を付けて、「秘密キーの作成」をクリックします。
- 重要な! – このテキスト/値をメモし、安全に保管してください。ポップアップが閉じると、再度表示することはできません。
- 次に、.env ファイルに移動し、OPEN_AI_API_KEY の横に貼り付けます。引用符 ("") は入れないでください。
では、もう一方を修正してみましょう。
ハグフェイスAPIキーを取得
Hugging Face は、開発者のユースケースにオープンソースのモデル、データセット、タスク、さらにはコンピューティング スペースを提供する AI コミュニティです。唯一の問題は、モデルを使用するには API を使用する必要があることです。取得方法は次のとおりです (参考として ref.png を参照してください)。
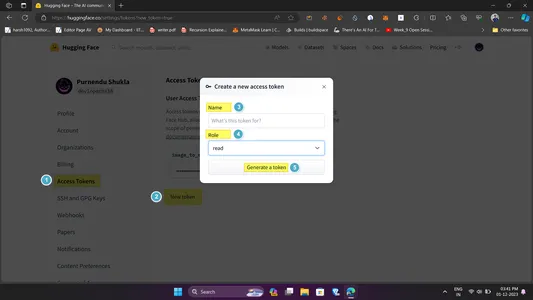
- 〜へ向かう 抱きしめる顔 ウェブサイトにアクセスし、アカウントを作成してログインします。
- 次に、左上のアバター (🧑🦲) に移動し、ドロップダウンの設定をクリックします
- 設定ページ内で、「アクセス トークン」をクリックし、次に「新しいトークン」をクリックします。
- 名前や権限などのトークン情報を入力します。わかりやすい名前と読み取り許可を付けてください。
- 「トークンの生成」をクリックすると、トークンが完成です。必ずコピーしてください。
- .env ファイルを開き、コピーした ID を HUGGGINGFACEHUB_API_TOKEN の横に貼り付けます。上記のガイドラインに従ってください。
Sああ、なぜこれが必要なのでしょうか? これは、開発者として、システム上の機密情報を誤って公開してしまうのは自然なことだからです。他の誰かがこのデータを入手すると、悲惨な結果になる可能性があるため、env ファイルを分離し、後で別のスクリプトでアクセスするのが標準的な方法です。
これでワークスペースのセットアップは完了しましたが、オプションの手順が 1 つあります。
環境の作成
このステップはオプションなのでスキップしても構いませんが、スキップしないことをお勧めします。
多くの場合、プロジェクトに必要なモジュールやファイルに集中するために、開発スペースを分離する必要があります。これは、仮想環境を作成することで行われます。
Mini-Conda は使いやすいため、v-env の作成に Mini-Conda を使用できます。したがって、コマンド プロンプトを開き、次のコマンドを順番に入力します。
conda create ai-storyteller
conda activate ai-storyteller1 番目のコマンドは新しい仮想環境を作成し、2 番目のコマンドはそれをアクティブにします。このアプローチは、後のプロジェクト展開段階でも役立ちます。それでは、メインのプロジェクト開発に移りましょう。
AI ストーリーテラー アプリケーション – バックエンド
前述したように、各コンポーネントを個別に作成してから、それらをすべてマージします。
依存関係と要件
vs-code または current-working-directory で、新しい Python ファイルを作成します。 main.py。これはプロジェクトのエントリ ポイントとして機能します。次に、必要なライブラリをすべてインポートしましょう。
from dotenv import find_dotenv, load_dotenv
from transformers import pipeline
from langchain import PromptTemplate, LLMChain, OpenAI
import requests
import os
import streamlit as stライブラリの詳細については触れないでください。使用しながら学習していきます。
load_dotenv(find_dotenv())
HUGGINGFACE_API_TOKEN = os.getenv("HUGGINGFACEHUB_API_TOKEN")ここに:
- 1 行目で、まず .env ファイルを作成し、そのコンテンツをロードします。このメソッドは OpenAI キーをロードするために使用されますが、その存在は妨げられます。良い習慣を呼びましょう 😅
- 2 行目では、 に保存されているハグ顔ハブ API トークンを読み込みます。env 使用してファイル os.getenv() 後で使用するために。
- 注: どちらの変数も定数であるため、大文字のままにします。
すべての要件と依存関係をロードしたら、最初のコンポーネントの構築に進みましょう。画像からテキストへのジェネレーター。
画像からテキストへのジェネレータ モデル
#img-to-text def img2text(path): img_to_text = pipeline( "image-to-text", model="Salesforce/blip-image-captioning-base") text = img_to_text(path)[0]['generated_text'] return text次に、コードを分析してみましょう。
- 3 行目では、画像パスを取得する img2text 関数を定義します。
- 4 行目では、タスク (img_to_text) とモデル名を受け取るハグフェイスからのパイプライン コンストラクターを使用して、モデル オブジェクトを img_to_text としてインスタンス化します。
- 6 行目では、API 呼び出しを介して画像パスをモデルに送信し、生成されたテキスト (キー: 値) を返し、テキスト変数に保存します。
- 最後にテキストを返却しました。
とてもシンプルですよね?
次に、テキストをストーリー ジェネレーターに渡しましょう。
テキストからストーリーへのジェネレータ モデル
テキストからストーリーへの生成には ChatGPT を使用しますが、お好みの他のモデルを自由に使用してください。
さらに、Lang-chain を使用してモデルにカスタム プロンプト テンプレートを提供し、あらゆる年齢層が安全に使用できるようにします。これは次のようにして実現できます。
def story_generator(scenario): template = """ You are an expert kids story teller; You can generate short stories based on a simple narrative Your story should be more than 50 words. CONTEXT: {scenario} STORY: """ prompt = PromptTemplate(template=template, input_variables = ["scenario"]) story_llm = LLMChain(llm = OpenAI( model_name= 'gpt-3.5-turbo', temperature = 1), prompt=prompt, verbose=True) story = story_llm.predict(scenario=scenario) return storyコードの説明
コードを理解しましょう:
- 1 行目では、シナリオを引数として受け取るストーリー ジェネレーター関数を定義します。ここでのシナリオは、以前にモデルによって生成されたストーリーを参照していることに注意してください。
- 2 行目から 9 行目までは、シナリオとしてコンテキストを使用して変数テンプレートの下にカスタム命令を定義します。これは、このセクションで前述したカスタム命令です。
- 次に、10 行目で、ハグ顔を使用してプロンプトを生成します。 プロンプトテンプレート クラス。テンプレート (テキスト全体) とカスタム コンテキスト (このシナリオ) を取り込みます。
- 11 行目では、次を使用して chat-gpt-3.5-turbo モデルのインスタンスを作成します。 LLMチェーン lang-chain のラッパー。モデルには、モデル名、温度 (応答のランダム性)、プロンプト (カスタム プロンプト)、および詳細 (ログを表示するため) が必要です。
- ここで、次を使用してモデルを呼び出します。 予測する メソッドを作成し、14 行目にシナリオを渡します。これにより、ストーリー変数に格納されたコンテキストに基づいてストーリーが返されます。
- 最終的には話を戻して最終モデルに引き継ぎます。
使用されている Lang-Chain クラスに興味がある人のために:
- プロンプトテンプレート は、提供されたテンプレート/コンテキストに基づいてプロンプトを作成するために使用されます。この場合、追加のコンテキスト - シナリオがあることを指定します。
- LLM チェーン LLM モデルのチェーンを表すために使用されます。この例では、GPT 3.5 Turbo モデルを使用した OpenAI 言語モデルを表します。簡単に言えば、複数の LLM を連鎖させることができます。
Lang-chain とその機能の詳細については、以下を参照してください。 こちら.
次に、生成された出力をオーディオに変換する必要があります。みてみましょう。
テキストからオーディオへのモデル
ただし、今回はモデルをロードするのではなく、ハグ顔推論 API を使用して結果を取得します。これにより、ストレージとコンピューティングのコストが節約されます。コードは次のとおりです。
#text-to-speech (Hugging Face)
def text2speech(msg): API_URL = "https://api-inference.huggingface.co/models/espnet/kan-bayashi_ljspeech_vits" headers = {"Authorization": f"Bearer {HUGGINGFACE_API_TOKEN}"} payloads = { "inputs" : msg } response = requests.post(API_URL, headers=headers, json=payloads) with open('audio.flac','wb') as f: f.write(response.content)コードの説明
上記のコードの説明は次のとおりです。
- 1行目で関数を定義します テキスト2スピーチ その仕事は、メッセージ (以前のモデルから生成されたストーリー) を受け取り、音声ファイルを返すことです。
- 行 2 は、呼び出す API エンドポイントを保持する API_URL で構成されます。
- 次に、ヘッダーに認証とベアラー トークンを指定します。これは、モデルを呼び出すときにヘッダー (認証データ) として提供されます。
- 5 行目では、変換する必要があるメッセージ (msg) を含むペイロード ディクショナリ (JSON 形式) を定義します。
- 後続の行では、モデルへのリクエストがヘッダーと JSON データとともに送信されます。返された応答は応答変数に格納されます。
注: モデル推論の形式はモデルによって異なる場合があるため、セクションの最後を参照してください。
- 最後に、必要な応答を記述して、オーディオ ファイルのコンテンツ (response.content) をローカル システムに保存します。 オーディオ.flac。これはコンテンツの安全性を確保するために行われ、オプションです。
オプション
別の text-to-audio モデルを選択する予定の場合は、モデル ページにアクセスして、デプロイの横にあるドロップダウン矢印をクリックし、 推論 API オプションを選択します。

おめでとうございます。バックエンド部分が完了しました。動作をテストしてみましょう。
バックエンドの動作を確認する
今度はモデルをテストします。このために、画像を渡し、すべてのモデル関数を呼び出します。以下のコードをコピーして貼り付けます。
scenario = img2text("img.jpeg") #text2image
story = story_generator(scenario) # create a story
text2speech(story) # convert generated text to audioここに img.jpeg はイメージ ファイルで、main.py と同じディレクトリに存在します。
次に、ターミナルに移動し、次のように main.py を実行します。
python main.pyすべてがうまくいけば、 オーディオファイル 以下と同じディレクトリにあります。

audio.flac ファイルが見つからない場合は、API キーが追加されていること、十分なトークンがあること、FFmpeg を含む必要なライブラリがすべてインストールされていることを確認してください。
バックエンドの作成が完了し、機能するようになったので、次はフロントエンド Web サイトを作成します。移動しましょう。
AI ストーリーテラー アプリケーション – フロントエンド
フロントエンドを作成するには、Python スクリプトから Web ページを構築し、専用の CLI を備え、ホスティングするための使いやすい再利用可能なコンポーネントを提供する streamlit ライブラリを使用します。小規模なプロジェクトをホストするために必要なものがすべて揃っています。
まず、Streamlit にアクセスしてアカウントを作成してください。無料です。
次に、ターミナルに移動し、以下を使用して streamlit cli をインストールします。
pip install streamlit完了したら、準備は完了です。
次のコードをコピーして貼り付けます。
def main(): st.set_page_config(page_title = "AI story Teller", page_icon ="🤖") st.header("We turn images to story!") upload_file = st.file_uploader("Choose an image...", type = 'jpg') #uploads image if upload_file is not None: print(upload_file) binary_data = upload_file.getvalue() # save image with open (upload_file.name, 'wb') as f: f.write(binary_data) st.image(upload_file, caption = "Image Uploaded", use_column_width = True) # display image scenario = img2text(upload_file.name) #text2image story = story_generator(scenario) # create a story text2speech(story) # convert generated text to audio # display scenario and story with st.expander("scenario"): st.write(scenario) with st.expander("story"): st.write(story) # display the audio - people can listen st.audio("audio.flac") # the main
if __name__ == "__main__": main()コードの説明
- st.set_page_config:ページ構成を設定します。ここでタイトルとアイコンを設定します
- セントヘッダー: ページヘッダーコンポーネントを設定します。
- st.file_uploader: 提供されたテキストとともにアップロード コンポーネントを Web ページに追加します。ここではユーザーから画像を取得するために使用されます。
- 画像:画像を表示します。推測どおり、ユーザーがアップロードした画像が表示されます。
- セントエキスパンダー: エキスパンダー (展開して表示) コンポーネントを Web ページに追加します。ここでは、シナリオ (画像のキャプション) とストーリー (ストーリーへのキャプション) を保存するために使用します。ユーザーがエキスパンダーをクリックすると、生成されたテキストが表示されます。また、優れた UI エクスペリエンスも提供します。
- st.write: 複数の目的に使用されます。ここでは展開テキストを記述します。
- セントオーディオ: Web ページにオーディオ コンポーネントを追加します。ユーザーはこれを使用して、生成されたオーディオを聞くことができます
私たちの関数が何をするのかを簡単に説明すると、次のようになります。
本サイトの メイン 関数は、ユーザーが画像をアップロードし、それをモデルに渡し、画像をキャプションに変換し、それに基づいてストーリーを生成し、そのストーリーをユーザーが聞くことができる音声に変換できる Web ページを作成します。それとは別に、生成されたキャプションとストーリーを表示することもでき、オーディオ ファイルはローカル/ホスト システムに保存されます。
アプリケーションを実行するには、ターミナルに移動して次のコマンドを実行します。
streamlit run app.pyすべてが成功すると、以下の応答が得られます。

次に、ローカル URL に移動すると、アプリをテストできます。
アプリの使用方法を紹介するビデオは次のとおりです。
[埋め込まれたコンテンツ]
Hugging Face、OpenAI、Lang チェーンを利用した LLM アプリケーションの構築おめでとうございます。それでは、この記事で学んだことをまとめてみましょう。
まとめ
以上で、AI Storyteller アプリケーションのフロントエンドとバックエンドを構築する方法を学習しました。
私たちはプロジェクトの基礎を築くことから始め、次に、顔を抱きしめる力を活用して、目の前にあるタスクにオープンソース LLM モデルを使用し、オープン AI とラングチェーンを組み合わせてカスタム コンテキストを提供し、その後アプリケーション全体をインタラクティブなアプリケーションにラップしました。 streamlit を使用した Web アプリ。また、プロジェクトに沿ってセキュリティ原則ガイドも適用しました。
主要な取り組み
- を使用してユーザー情報を保護します。 env を作成し、Python を使用して同じものをロードします ドテンフ パッケージ。
- プロジェクトを実行可能なコンポーネントに分割し、それに応じて環境を設定します。
- 複数のモデルを上付き文字として組み合わせて作業を完了します。
- Lang チェーンを使用してモデルにカスタム命令を提供し、幻覚を軽減し、PromptTemplate を使用して反応を保護します。
- Lang-Chain LLMChain クラスを使用して、複数のモデルを結合します。
- 推論 API を使用して、抱き顔モデルを推論し、結果を保存します。
- Streamlit の宣言構文を使用して Web ページを構築します。
この AI ストーリーテラー アプリケーションの構築を楽しんでいただければ幸いです。さあ、それを実践してみましょう。皆さんが何を思いつくか楽しみです。最後までお付き合いいただきありがとうございました。開始するためのリソースをいくつか紹介します。
リソース
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/12/building-an-ai-storyteller-application-using-langchain-openai-and-hugging-face/
- :持っている
- :は
- :not
- $UP
- 1
- 10
- 11
- 14
- 1
- 50
- 8
- 9
- a
- できる
- 私たちについて
- 上記の.
- アクセス
- アクセス可能な
- それに応じて
- 達成
- 加えます
- 追加されました
- 追加
- 進歩
- 後
- 再び
- 年齢
- 先んじて
- AI
- すべて
- ことができます
- 沿って
- また
- an
- 分析論
- 分析Vidhya
- および
- 別の
- どれか
- 離れて
- API
- アプリ
- 現れる
- 申し込み
- 適用された
- アプローチ
- です
- 引数
- 記事
- AS
- At
- オーディオ
- 承認
- アバター
- バックエンド
- ベース
- BE
- 無記名
- なぜなら
- になる
- 始まる
- 以下
- ブログソン
- 両言語で
- ビルド
- ビルダー
- 建物
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- コール
- 缶
- 取得することができます
- 資本
- 場合
- レスリング
- CD
- チェーン
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- 選択
- 選択する
- class
- クラス
- クリック
- 閉じ
- コード
- 組み合わせる
- 組み合わせた
- 来ます
- コミュニティ
- 会社
- コンプリート
- 複雑な
- コンポーネント
- コンポーネント
- 計算
- コンピューティング
- からなる
- 定数
- 含まれています
- コンテンツ
- コンテキスト
- 変換
- コスト
- 作ります
- 作成します。
- 作成
- Credentials
- 興味深い
- カスタム
- データ
- データセット
- 専用の
- 定義します
- 定義済みの
- 依存関係
- 展開します
- 展開
- 詳細
- 細部
- Developer
- 開発者
- 開発
- 異なる
- 異なります
- 悲惨な
- 裁量
- ディスプレイ
- ディスプレイ
- do
- ありません
- 行われ
- ドント
- ダウン
- 原因
- 各
- 前
- 緩和する
- 使いやすさ
- 使いやすい
- 効果的に
- ほかに
- 埋め込まれた
- end
- 楽しんだ
- 確保
- 入力します
- 全体
- エントリ
- 環境
- 確立する
- エーテル(ETH)
- さらに
- あらゆる
- すべてのもの
- 存在
- 詳細
- 期待
- エキスパート
- 説明
- 探る
- 余分な
- 顔
- 特徴
- 少数の
- File
- 埋める
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- 修正する
- フォーカス
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- Foundation
- 無料版
- から
- フロント
- フロントエンド
- フロントエンド
- function
- 機能
- 生成する
- 生成された
- 生成
- 世代
- ジェネレータ
- 取得する
- 与える
- Go
- ゴエス
- 行く
- 良い
- グラブ
- 挨拶
- 推測された
- ガイド
- ガイドライン
- ハンド
- 持ってる
- 持って
- ヘッダーの
- ことができます
- こちら
- ハイレベル
- ヒット
- 保持している
- 希望
- host
- 主催
- ホスティング
- 認定条件
- How To
- しかしながら
- HTTPS
- ハブ
- 抱き合う顔
- i
- 私は
- ID
- if
- 画像
- 画像
- import
- in
- 含めて
- info
- 有益な
- 入力
- 内部
- install
- インストール
- 説明書
- 相互作用
- 相互作用的
- インタフェース
- に
- 分離された
- 問題
- IT
- ITS
- ジョブ
- 旅
- JPG
- JSON
- ただ
- キープ
- 保管
- キー
- キー
- 子供たち
- 言語
- 言語
- 姓
- 後で
- 敷設
- LEARN
- 学んだ
- 学習
- 左
- レベル
- 活用します
- レバレッジ
- ライブラリ
- 図書館
- 軽量
- ような
- LINE
- ライン
- 聞く
- 聞く
- 負荷
- ローディング
- ローカル
- ログ
- ログインして
- ログイン
- 見て
- メイン
- make
- 扱いやすいです
- 多くの
- 五月..
- メディア
- 言及した
- マージ
- メッセージ
- 会った
- 方法
- かもしれない
- モデル
- モジュール
- モジュール
- 他には?
- 移動する
- の試合に
- 名
- ナレラティブ
- ナチュラル
- ナビゲート
- 必要
- 必要
- 必要とされる
- ニーズ
- 新作
- 次の
- なし
- 注意
- 知らせ..
- 今
- 簡単
- オブジェクト
- 客観
- of
- 公式
- 公式ウェブサイト
- on
- かつて
- ONE
- の
- 開いた
- オープンソース
- OpenAI
- オプション
- オプション
- or
- 整理する
- OS
- その他
- 私たちの
- 自分自身
- でる
- アウトライン
- 出力
- が
- 自分の
- 所有している
- ページ
- 部
- パス
- path
- のワークプ
- 許可
- パイプライン
- 計画
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- ポイント
- 投稿
- 電力
- パワード
- 練習
- 好む
- 優先
- 現在
- 前
- 前に
- 原則
- プロセス
- 製品
- プロジェクト
- プロジェクト(実績作品)
- 目立つ
- プロンプト
- 提供します
- 提供
- は、大阪で
- 公表
- 目的
- 置きます
- Python
- 引用
- ランダム
- ランダム
- むしろ
- 読む
- リーディング
- 最近
- 減らします
- 参照する
- 参照
- 指し
- 表す
- 表し
- 要求
- リクエスト
- 必要とする
- の提出が必要です
- 要件
- 必要
- リソース
- 応答
- 結果
- return
- 収益
- 再利用可能な
- 明らかにする
- 右
- ラン
- 安全な
- 保護
- 安全性
- 同じ
- Save
- シナリオ
- 科学
- スクリプト
- スクリプト
- 秘密
- 秘密
- セクション
- セキュリティ
- select
- 選択
- 送る
- 送信
- 別
- 別々
- 役立つ
- セッションに
- セット
- 設定
- ショート
- すべき
- 示す
- 作品
- 署名されました
- 簡単な拡張で
- 小さい
- So
- ソフトウェア
- 誰か
- ソース
- スペース
- スペース
- st
- ステージ
- 標準
- start
- 開始
- 手順
- ステップ
- 粘着
- まだ
- ストレージ利用料
- 店舗
- 保存され
- ストーリー
- ストーリー
- それに続きます
- 成功した
- そのような
- 十分な
- まとめる
- サポート
- 確か
- シンボル
- 構文
- テーブル
- 取る
- 取り
- 仕事
- タスク
- template
- ターミナル
- 条件
- test
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- より
- 感謝
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- 物事
- この
- それらの
- 介して
- 時間
- 役職
- 〜へ
- 一緒に
- トークン
- トークン
- あまりに
- 豊富なツール群
- top
- トランスフォーマー
- true
- 順番
- type
- 不明
- 下
- わかる
- 理解する
- アップロード
- URL
- つかいます
- 使用事例
- 中古
- ユーザー
- 活用
- 値
- 価値観
- 変数
- variables
- 変わります
- 、
- ビデオ
- 詳しく見る
- バーチャル
- 訪問
- vs
- vsコード
- wait
- ました
- we
- ウェブ
- webp
- ウェブサイト
- WELL
- この試験は
- いつ
- which
- while
- 誰
- なぜ
- 意志
- 言葉
- 仕事
- いい結果になる
- ワークフロー
- 労働人口
- ワーキング
- 作品
- 包まれました
- 書きます
- 書き込み
- 貴社
- あなたの
- ユーチューブ
- ゼファーネット









