「1 オンスの予防は 1 ポンドの治療に匹敵する」という古いことわざは、何かが起こってからダメージを修復するよりも、最初から何かが起こらないようにする方が簡単であることを私たちに思い出させます。
人工知能 (AI) の時代において、このことわざは、正則化などの技術を通じて過剰適合などの潜在的な落とし穴を回避することの重要性を強調しています。
この記事では、Sci-kit Learn (機械学習) と Tensorflow (深層学習) を使用してその基本原理から正則化を応用し、これらの結果を比較することでその変革力を実世界のデータセットで確認します。はじめましょう!
正則化は、モデルの過剰適合を防ぐことを目的とした機械学習と深層学習における重要な概念です。
過学習は、モデルがトレーニング データを学習しすぎると発生します。この状況は、あなたのモデルが真実であるにはあまりにも優れていることを示しています。
過剰適合がどのようなものかを見てみましょう。
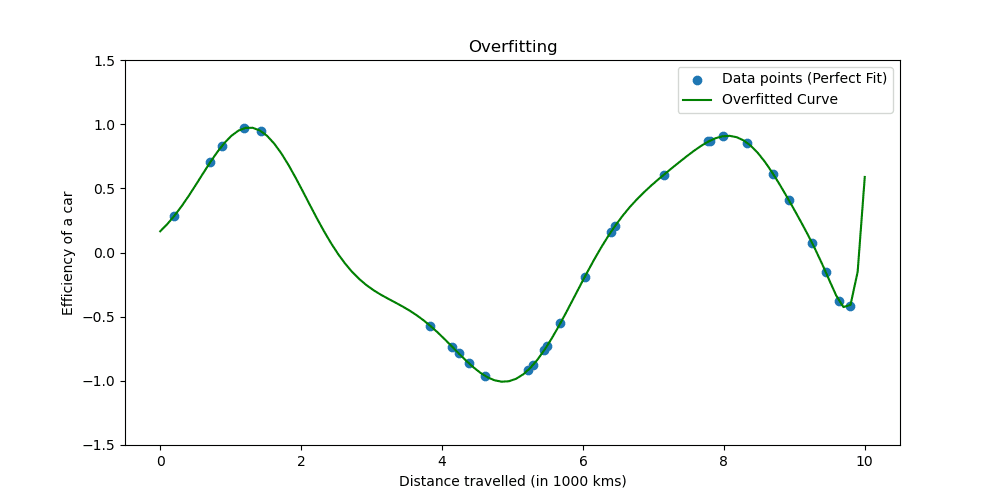
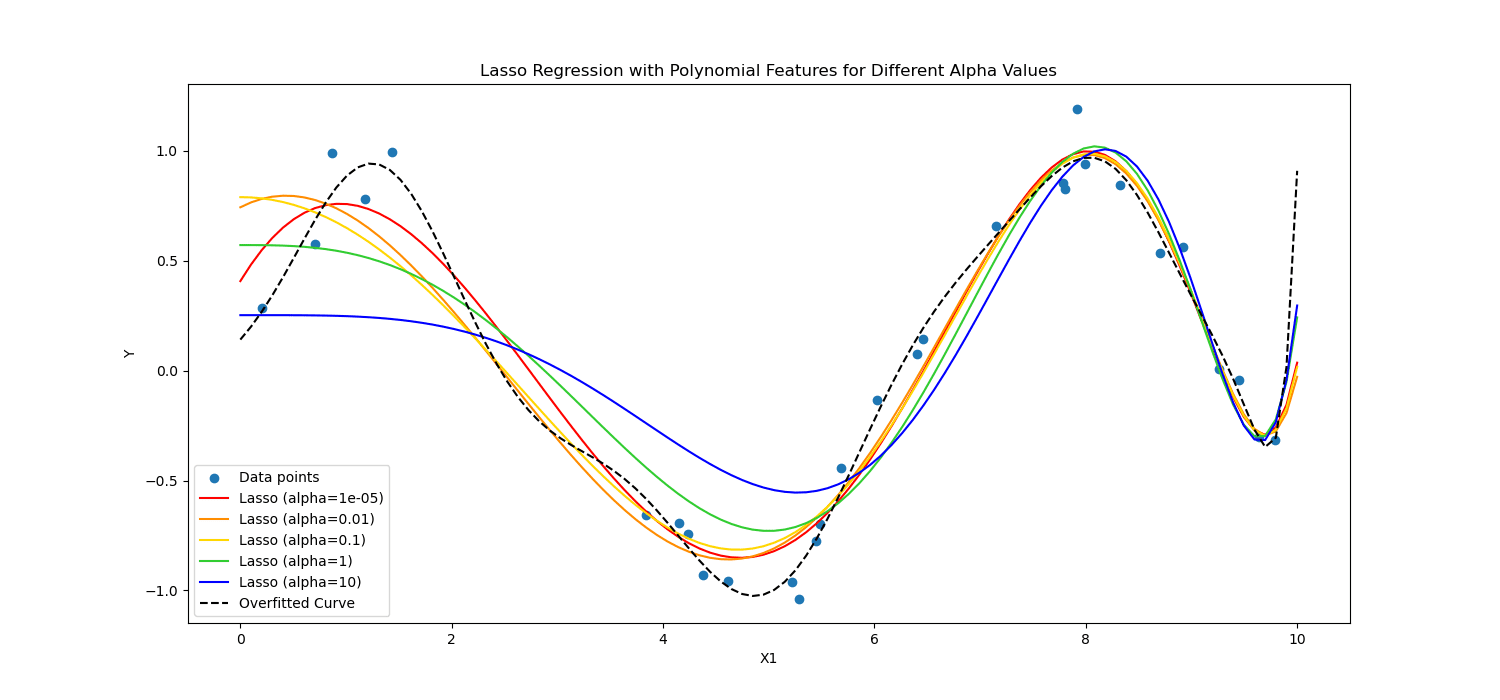
正則化手法は学習プロセスを調整してモデルを簡素化し、モデルがトレーニング データで適切に実行され、新しいデータに対して適切に一般化されるようにします。これを行う 2 つのよく知られた方法を検討します。
機械学習では、正則化は線形回帰やロジスティック回帰などの線形モデルに適用されることがよくあります。この文脈において、最も一般的な正規化形式は次のとおりです。
- L1 正則化 (Lasso 回帰)
- L2 正則化 (リッジ回帰)
ラッソ正則化 一部の係数値を正確にゼロにできるようにすることで、モデルが最も重要な特徴のみを使用するように促します。これは、特徴の選択に特に役立ちます。
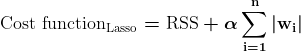
一方、 リッジの正則化 係数の値の 2 乗にペナルティを課すことで、有意な係数を妨げます。
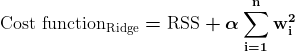
要するに、計算方法が違ったのです。
これらを心臓患者データに適用して、深層学習と機械学習におけるその威力を見てみましょう。
次に、正則化を適用して心臓患者データを分析し、正則化の力を確認します。データセットには次からアクセスできます。 こちら.
機械学習を適用するには、Scikit-learn を使用します。深層学習を適用するには、TensorFlow を使用します。はじめましょう!
機械学習における正則化
Scikit-learn は最も人気のあるものの 1 つです Pythonライブラリ シンプルで効率的なデータ分析およびモデリング ツールを提供する機械学習向け。
これには、特に線形モデル向けのさまざまな正則化手法の実装が含まれています。
ここでは、L1 (なげなわ) と L2 (リッジ) の正則化を適用する方法を検討します。
次のコードでは、Ridge(L2) および Lasso 正則化 (L1) 手法を使用してロジスティック回帰をトレーニングします。最後に詳細なレポートを見ていきます。コードを見てみましょう。
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
これが出力です。
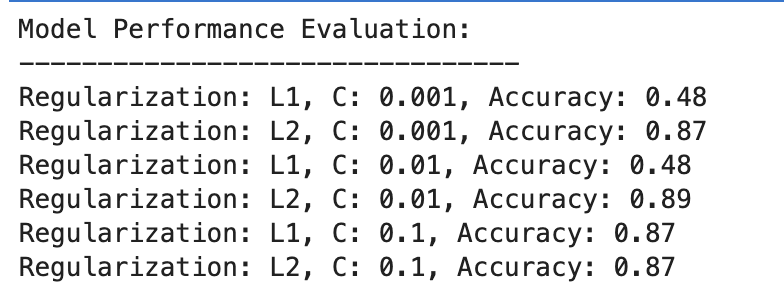
結果を評価してみましょう。
L1正則化
- C=0.001 では、精度が著しく低くなります (48%)。これは、モデルがアンダーフィッティングであることを示しています。正則化が多すぎることがわかります。
- C が 0.01 に増加しても、L1 の精度は変化せず、モデルが依然としてアンダーフィッティングに苦しんでいるか、正則化が強すぎることを示唆しています。
- C=0.1 では、精度が 87% に大幅に向上し、正則化強度を下げることでモデルがデータからより適切に学習できることがわかります。
L2正則化
全体として、L2 正則化は一貫して良好なパフォーマンスを示し、C=87 の場合は 0.001% の精度、C=89 の場合は 0.01% とわずかに高く、C=87 の場合は 0.1% で安定します。
これは、潜在的にその性質により、ロジスティック回帰モデルにおけるこのデータセットに対して、L2 正則化が一般的により寛容で効果的であることを示唆しています。
深層学習における正則化
深層学習では、L1 (Lasso) および L2 (Ridge) 正則化、ドロップアウト、早期停止など、いくつかの正則化手法が使用されます。
この例では、前の機械学習の例で行ったことを繰り返すために、L1 と L2 の正則化を適用します。今回はL1とL2の正則化値のリストを定義してみましょう。
次に、これらすべての値について深層学習モデルをトレーニングして評価し、最後に結果を評価します。
コードを見てみましょう。
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
これが出力です。
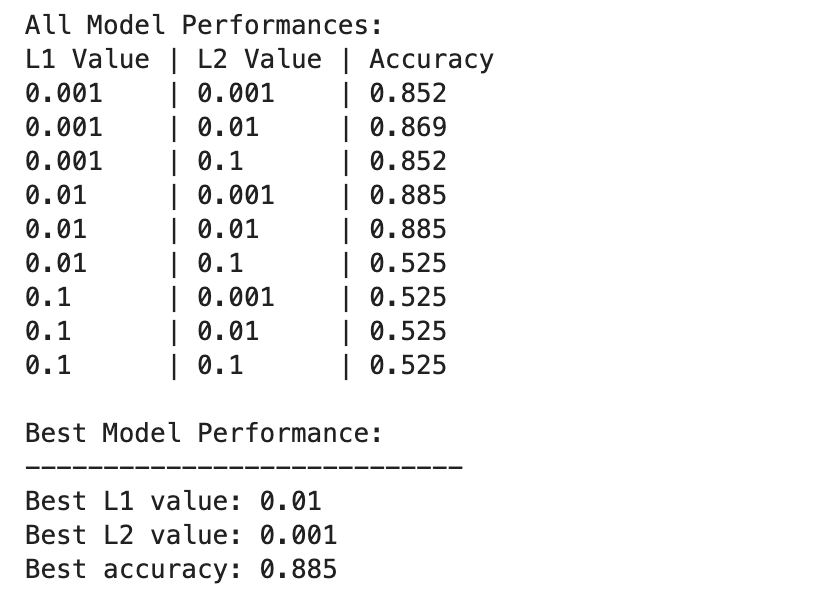
深層学習モデルのパフォーマンスは、L1 正則化値と L2 正則化値の組み合わせが異なるとさらに大きく異なります。
L1=0.01 および L2=0.001 で最高のパフォーマンスが観察され、精度は 88.5% です。これは、モデルがデータ内の基礎となるパターンをキャプチャできるようにしながら、過学習を防止するバランスの取れた正則化を示しています。
正則化値が高くなると、特に L1=0.1 または L2=0.1 では、モデルの精度が 52.5% まで大幅に低下します。これは、正則化が多すぎるとモデルの学習能力が大幅に制限されることを示唆しています。
正則化における機械学習と深層学習
機械学習と深層学習の結果を比較してみましょう。
正則化の効果: 機械学習と深層学習の両方のコンテキストにおいて、適切な正則化は過剰適合の軽減に役立ちますが、過剰な正則化は過小適合につながります。最適な正則化の強度は異なりますが、深層学習モデルは複雑であるため、より微妙なバランスが必要になる可能性があります。
パフォーマンス: 最もパフォーマンスの高い機械学習モデル (L2、C=0.01、精度 89%) と最もパフォーマンスの高い深層学習モデル (L1=0.01、L2=0.001、精度 88.5%) は同等の精度を達成しており、両方のアプローチが効果的に利用できることを示しています。このデータセットで高いパフォーマンスを達成するために正規化されています。
正則化戦略: L2 正則化はより効果的で、ロジスティック回帰モデルにおける C の選択の影響を受けにくいように見えますが、L1 正則化と L2 正則化を組み合わせるとディープ ラーニングで最良の結果が得られ、特徴選択と重みペナルティのバランスが取れます。
正則化の選択と強度は、学習の複雑さと過学習または過小学習のリスクのバランスを保つために慎重に調整する必要があります。
この探索を通じて、私たちは正則化の謎を解き明かし、過学習を防止し、モデルが目に見えないデータに対して適切に一般化できるようにするその役割を示しました。
正則化手法を適用すると、機械学習と深層学習の熟練度に近づき、データ サイエンティストのツールセットが強化されます。
データ プロジェクトに進み、次のようなさまざまなシナリオでデータを正規化してみてください。 配信期間の予測。このデータ プロジェクトでは、機械学習モデルと深層学習モデルの両方を使用しました。ただし、最終的には改善の余地があるかもしれないとも述べました。それで、そこで正則化を試してみて、それが役立つかどうかを確認してみてはいかがでしょうか?
ネイト・ロシディ データサイエンティストであり、製品戦略に携わっています。 彼はまた、分析を教える非常勤教授であり、 ストラタスクラッチ、データサイエンティストがトップ企業からの実際の面接の質問で面接の準備をするのを支援するプラットフォーム。 彼とつながる Twitter:StrataScratch or LinkedIn.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for
- :持っている
- :は
- 001
- 01
- 1
- 2%
- 5
- 52
- a
- 精度
- 達成する
- 越えて
- アダム
- 付属
- 調整します
- 後
- AI
- 目指して
- すべて
- 許可
- ことができます
- 沿って
- 既に
- また
- an
- 分析
- 分析論
- 分析します
- および
- 登場する
- 申し込み
- 適用された
- 申し込む
- アプローチ
- 適切な
- です
- 記事
- 人工の
- 人工知能
- 人工知能(AI)
- AS
- 評価する
- At
- 回避
- BE
- BEST
- より良いです
- の間に
- ボード
- 両言語で
- 持って来る
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算された
- 缶
- 容量
- キャプチャー
- 慎重に
- 選択
- クローザー
- コード
- 係数
- 組み合わせ
- 組み合わせ
- コマンドと
- 企業
- 匹敵します
- 比較します
- 比較
- 複雑さ
- コンセプト
- お問合せ
- 一貫して
- コンテキスト
- 文脈
- 重大な
- ケア
- 電流プローブ
- 損傷
- データ
- データ分析
- データサイエンティスト
- データセット
- 深いです
- 深い学習
- 定義します
- デモ
- 詳細な
- 細部
- DID
- 異なります
- 異なって
- 発見する
- すること
- ドント
- 劇的に
- 原因
- デュレーション
- 早い
- 容易
- 効果的な
- 効果的に
- 効率的な
- 励ます
- end
- 確保する
- 方程式
- 時代
- 特に
- 本質的な
- エーテル(ETH)
- 評価する
- 評価
- 正確に
- 例
- 過度の
- 探査
- 探る
- 特徴
- 特徴
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- 名
- フォロー中
- フォーム
- AIとMoku
- から
- 基本的な
- 一般に
- ゴエス
- 良い
- ハンド
- が起こった
- 出来事
- 起こります
- he
- 助け
- ことができます
- ハイ
- より高い
- 彼に
- history
- 認定条件
- How To
- しかしながら
- HTTPS
- if
- 実装
- import
- 重要性
- 改善
- 向上させる
- in
- 含ま
- 含めて
- 増加
- を示し
- インテリジェンス
- インタビュー
- 面接の質問
- 記事執筆
- に
- IT
- ITS
- KDナゲット
- keras
- l2
- リード
- LEARN
- 学習
- 学ぶ
- less
- う
- ような
- 制限
- 線形
- リスト
- ll
- LOOKS
- 損失
- ロー
- 機械
- 機械学習
- 言及した
- メトリック
- メトリック
- かもしれない
- 軽減する
- モデリング
- モデル
- 他には?
- 最も
- 一番人気
- ずっと
- 自然
- 新作
- 特に
- 微妙
- numpy
- 観測された
- of
- 提供すること
- 頻繁に
- 古い
- on
- ONE
- の
- 最適な
- or
- その他
- 私たちの
- 出力
- が
- 特に
- 患者
- 患者データ
- パターン
- パフォーマンス
- 公演
- 実行
- 実行する
- 場所
- プレースホルダー
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人気
- 潜在的な
- :
- ポンド
- 電力
- 準備
- 防ぐ
- 予防
- 防止
- を防止
- 原則
- 印刷物
- プロセス
- プロダクト
- 東京大学大学院海洋学研究室教授
- プロジェクト
- プロジェクト(実績作品)
- ことわざ
- は、大阪で
- 質問
- リーチ
- リアル
- 現実の世界
- 減らします
- 縮小
- 回帰
- relu
- 残っている
- 思い出させます
- 修理
- 繰り返す
- レポート
- 結果
- 結果
- リスク
- 職種
- ルーム
- s
- 格言
- シナリオ
- 科学者
- 科学者たち
- scikit-学ぶ
- 選択
- 敏感な
- セット
- ひどく
- ショート
- すべき
- 表示
- 作品
- 重要
- 著しく
- 簡単な拡張で
- 簡素化する
- 状況
- わずかに
- So
- 固まる
- 一部
- 何か
- split
- 広場
- 起動
- まだ
- Force Stop
- 停止
- 店舗
- 保存
- 戦略
- 力
- 強い
- そのような
- 苦しみ
- 提案する
- ターゲット
- ティーチング
- テクニック
- テンソルフロー
- テスト
- より
- それ
- アプリ環境に合わせて
- その後
- そこ。
- ボーマン
- 彼ら
- この
- 介して
- 時間
- 〜へ
- あまりに
- 豊富なツール群
- top
- トレーニング
- トレーニング
- 変形させる
- true
- 試します
- 調整された
- 2
- 根本的な
- アンダースコア
- us
- つかいます
- 中古
- 便利
- 値
- 価値観
- さまざまな
- 変わります
- Ve
- 方法
- we
- 重量
- WELL
- 周知
- この試験は
- 何ですか
- いつ
- which
- while
- なぜ
- 広く
- 意志
- 目撃者
- 価値
- X
- 貴社
- あなたの
- ゼファーネット
- ゼロ