この記事は、の一部として公開されました データサイエンスブログソン.
概要
レコメンデーションエンジンの使用に関する世界市場は、2.69年に2021億米ドルと評価されました。15.10年までに2026億米ドルを超えると予想され、37.79- 2022年のCAGRは2026%と報告されています。
企業が提供する推奨事項では、データ分析手法を使用して、好みや好みに一致するアイテムを特定することがあります。 インターネット上でデータが急速に増加しているため、Netflixは、次に見たい映画や、Twitterで読みたいトップニュース記事を知っていると言っても過言ではありません。
人工知能の最近の進歩と複数の企業間の競争の激化に伴い、消費者体験を改善し、デジタル化の傾向を高めるために、関連するデータのチャンクを検索、マッピング、および提供することが不可欠です。
そうは言っても、今日のガイドでは、レコメンデーションエンジン、その重要性、直面する課題、動作原理、さまざまな手法、アプリケーション、およびそれらを使用するトップ企業、そして最後に、Pythonで独自のレコメンデーションエンジンを構築する方法について説明します。
目次
- レコメンデーションエンジンとは何ですか?
- 機械学習でレコメンデーションエンジンが重要なのはなぜですか?
- レコメンダーエンジンのさまざまな手法
- レコメンデーションエンジンの動作
- レコメンデーションエンジンの課題
- レコメンデーションエンジンを構築する方法
- レコメンデーションエンジンを使用するアプリケーションとトップ企業
- まとめ
レコメンデーションエンジンとは何ですか?
レコメンデーションエンジンは、さまざまな機械学習アルゴリズムで動作するデータフィルタリングシステムであり、データ分析に基づいて製品、サービス、および情報をユーザーにレコメンデーションします。 これは、顧客の好み、過去の取引履歴、属性、状況コンテキストなどのさまざまな要因を使用して、顧客行動データのパターンを見つけるという原則に基づいて機能します。
インサイトを見つけるために使用されるデータは、暗黙的または明示的に収集できます。 企業は通常、レコメンデーションエンジンにペタバイトのデータを使用して、自分の意見を自分の経験、行動、好み、興味とともに提示します。
情報密度と製品の過負荷というこの進化し続ける市場では、各企業はわずかに異なる目的で推奨エンジンを使用しています。 それでも、売り上げを伸ばし、顧客エンゲージメントと顧客維持を促進し、消費者にパーソナライズされた知識とソリューションを提供するという同じ目標があります。
MLでレコメンデーションエンジンが重要なのはなぜですか?
レコメンデーションエンジンは、ユーザーエクスペリエンスの向上、需要の刺激、収益の増加、クリック率(CTR)の向上、ユーザーの積極的な関与、およびその他の重要な指標を実現するための優れた方法であることは間違いありません。 強力なデータフィルタリングツールとして、レコメンデーションエンジンはリアルタイムで機能します。 これらは、ユーザーにパーソナライズされた提案やアドバイスを提供する必要がある場合に役立ちます。
例としてNetflixを取り上げましょう。
何千もの映画と複数のカテゴリの番組を見ることができます。 それでも、Netflixは、あなたが最も楽しむ可能性が高い映画広告ショーのはるかに多くの意見のあるセレクションを提供します。 この戦略により、Netflixはより低いキャンセル率を達成し、年間XNUMX億ドルを節約し、時間を節約し、より優れたユーザーエクスペリエンスを提供します。
これが、レコメンデーションエンジンが不可欠であり、クロスセリングの機会をより多く提供することで、製品とのエンゲージメントの機会を促進している企業の数が正確に多い理由です。
レコメンデーションエンジンのさまざまな手法
機械学習で知られているレコメンダーエンジンにはXNUMXつの異なるタイプがあり、それらは次のとおりです。
1.協調フィルタリング
協調フィルタリング手法は、ユーザーの行動、オンラインアクティビティ、好みに関するデータを収集して分析し、他のユーザーとの類似性に基づいてユーザーが何を好むかを予測します。 マトリックススタイルの式を使用して、これらの類似性をプロットおよび計算します。
利点
協調フィルタリングの重要な利点のXNUMXつは、複雑なアイテムを正確に推奨するために、オブジェクト(製品、フィルム、本)を分析または理解する必要がないことです。 分析可能なマシンコンテンツに依存することはありません。つまり、ユーザーについて知っていることに基づいて推奨事項を選択します。
例
ユーザーXがブックA、ブックB、およびブックCを好み、ユーザーYがブックA、ブックB、およびブックDを好む場合、それらは同様の関心を持っています。 したがって、ユーザーXがBook Dを選択し、ユーザーYがBoodCを読むことを楽しむ可能性があります。これが協調フィルタリングの方法です。
2.コンテンツベースのフィルタリング
コンテンツベースのフィルタリングは、製品とユーザーの希望する選択肢のプロファイルを記述するという原則に基づいて機能します。 特定のアイテムが好きな場合は、この他のアイテムも好きになることを前提としています。 製品は、キーワード(ジャンル、製品タイプ、色、単語の長さ)を使用して定義され、推奨事項を作成します。 ユーザープロファイルは、このユーザーが楽しんでいるアイテムの種類を説明するために作成されます。 次に、アルゴリズムは、正弦距離とユークリッド距離を使用してアイテムの類似性を評価します。
利点
このレコメンダーエンジン手法の重要な利点のXNUMXつは、レコメンデーションがこのユーザーに固有であるため、他のユーザーに関する追加データを必要としないことです。 また、このモデルは、ユーザーの特定の関心を捉え、他のユーザーがほとんど関心を持っていないニッチなオブジェクトを提案することができます。
例
ユーザーXがスパイダーマンのようなアクション映画を見るのが好きだとします。 その場合、このレコメンダーエンジンの手法では、アクションジャンルの映画またはトムホランドを説明する映画のみが推奨されます。
3.ハイブリッドモデル
ハイブリッドレコメンデーションシステムでは、メタ(コラボレーション)データとトランザクション(コンテンツベース)データの両方が同時に使用され、ユーザーに幅広いアイテムを提案します。 この手法では、オブジェクト(映画、歌)ごとに自然言語処理タグを割り当てることができ、ベクトル方程式によって類似度が計算されます。 協調フィルタリングマトリックスは、ユーザーの行動、行動、意図に応じて、ユーザーに物事を提案することができます。
Advantages
このレコメンデーションシステムは新進気鋭であり、精度の点で上記の両方の方法よりも優れていると言われています。
例
Netflixはハイブリッドレコメンデーションエンジンを使用しています。 ユーザーの興味を分析し(共同)、ユーザーが高く評価したもの(コンテンツベース)と同様の属性を共有するような番組/映画を推奨することにより、推奨を行います。
レコメンデーションエンジンの動作
データは、レコメンデーションエンジンを構築する上で最も重要な要素です。 これは、アルゴリズムによってパターンが導出される構成要素です。 詳細が多ければ多いほど、より正確かつ実用的に、適切な収益を生み出す推奨事項が提供されます。 基本的に、レコメンデーションエンジンは、データと機械学習アルゴリズムの組み合わせをXNUMXつのフェーズで使用して機能します。 今、それらを詳細に理解しましょう:
1。 データ収集
レコメンデーションエンジンを作成するための最初の最も重要なステップは、すべてのユーザーに適切なデータを収集することです。 データにはXNUMXつのタイプがあります。 明白な から収集された情報を含むデータ 製品に対する評価、レビュー、いいね、嫌い、コメントなどのユーザー入力.
対照的に、 暗黙 次のようなユーザーアクティビティから収集された情報を含むデータ Web検索履歴、クリック、カートアクション、検索ログ、および注文履歴。
各ユーザーのデータプロファイルは、時間の経過とともにより特徴的になります。 したがって、次のような顧客属性データを収集することも重要です。
- 人口統計(年齢、性別)
- 類似の顧客を特定するためのサイコグラフィック(関心、価値観)
- 類似の製品の類似性を判断するための機能データ(ジャンル、オブジェクトタイプ)。
2.データストレージ
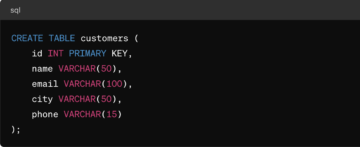
データを収集したら、次のステップはデータを効率的に保存することです。 より多くのデータを収集するにつれて、十分でスケーラブルなストレージが利用可能である必要があります。 収集するデータのタイプに応じて、NoSQL、標準SQLデータベース、MongoDB、AWSなどのいくつかのストレージオプションを利用できます。
最適なストレージオプションを選択するときは、実装の容易さ、データストレージのサイズ、統合、移植性など、いくつかの要素を考慮する必要があります。
3.データを分析します
データを収集した後、データを分析する必要があります。 次に、データをドリルして分析し、すぐに推奨事項を提供する必要があります。 データを分析できる最も一般的な方法は次のとおりです。
- リアルタイム分析、 システムは、作成時にイベントを評価および分析するツールを使用します。 この手法は、主に、即時の推奨事項を提供する場合に実装されます。
- バッチ分析、データの処理と分析が定期的に行われます。 この手法は主に、推奨事項を記載したメールを送信する場合に実装されます。
- ほぼリアルタイムの分析、 すぐには必要ないため、データを数秒ではなく数分で分析および処理します。 この手法は主に、ユーザーがサイトにいる間に推奨事項を提供するときに実装されます。
4.データのフィルタリング
データを分析したら、最後のステップは、データを正確にフィルタリングして、価値のある推奨事項を提供することです。 さまざまな行列、数学的規則、および数式がデータに適用され、正しい提案を提供します。 適切なアルゴリズムを選択する必要があり、このフィルタリングの結果が推奨事項になります。
レコメンデーションエンジンの課題
完璧は単に存在しません。 英国の理論物理学者「スティーブンホーキング」はかつて次のように述べています。
「宇宙の基本的なルールのXNUMXつは、完璧なものは何もないということです。」
同様に、効果的なレコメンダーシステムを構築するために企業が克服しなければならないいくつかの課題があります。 それらのいくつかを次に示します。
1.コールドスタートの問題
この問題は、新しいユーザーがシステムに参加したとき、またはレコードに新しいアイテムを追加したときに発生します。 レコメンダーシステムは、評価やレビューがないため、この新しいアイテムやユーザーを最初に提案することはできません。 したがって、エンジンが新しいユーザーの好みや優先順位、または新しいアイテムの評価を予測することは困難になり、推奨の精度が低下します。
たとえば、Netflixの新しい映画は、視聴回数と評価が上がるまでお勧めできません。
ただし、ディープラーニングベースのモデルは、予測を行うためにユーザーの行動に大きく依存しないため、コールドスタートの問題を解決できます。 製品のコンテキストや、製品の説明、画像、ユーザーの行動などのユーザーの詳細を調べることで、ユーザーとアイテム間の相関関係を最適化できます。
2.データの希薄性の問題
ご存知のとおり、レコメンデーションエンジンはデータに大きく依存しています。 いくつかの状況では、一部のユーザーは購入したアイテムの評価やレビューを提供しません。 高品質のデータがない場合、評価モデルは非常にまばらになり、データのスパース性の問題が発生します。
この問題により、アルゴリズムが同様の評価または関心を持つユーザーを見つけることが困難になります。
最高品質のデータを確保し、レコメンデーションエンジンを最大限に活用できるようにするには、次のXNUMXつの質問を自問してください。
- データはどのくらい最近ですか?
- 情報はどれくらいうるさいですか?
- 情報はどのくらい多様ですか?
- レコメンダーシステムモデルに新しいデータをどれだけ迅速にフィードできますか?
上記の質問により、ビジネスが複雑なデータ分析要件を確実に満たすようになります。
3.ユーザー設定の変更問題
評価とレビューでのユーザーアイテムの相互作用は、大規模な変化するデータを生成する可能性があります。
たとえば、今日はガールフレンドと一緒にロマンチックな映画を見るためにNetflixにいるかもしれません。 でも明日は気分が違うかもしれませんし、古典的なサイコスリラーが見たいです。
ユーザー設定の問題に関して、レコメンダーエンジンはユーザーに誤ったラベルを付ける可能性があり、これにより大規模なデータセットの結果が非効率的に解釈されます。 したがって、スケーラビリティはこれらのデータセットにとって大きな課題であり、この問題に対処するには、いくつかの高度な大規模な方法が必要です。
Pythonでレコメンデーションエンジンを構築する方法は?
このガイドセクションは、Pythonで基本的なレコメンデーションシステムを構築するのに役立ちます。 特定のアイテム(この場合は映画)に最も類似したアイテムを推奨することにより、基本的な推奨システムの構築に焦点を当てます。 これは正確で堅牢なレコメンデーションエンジンではないことに注意してください。 それは、どの映画/アイテムがあなたの映画の好みに最も類似しているかを示唆しているだけです。
このセクションの最後にコードとデータファイルがあります。 それでは始めましょう:
注: このコードを実行するには、GoogleCollabまたはJupyterNotebookで操作することを強くお勧めします。
#1。 必要なライブラリをインポートします。
numpyとpandasの機械学習ライブラリをインポートします。これは、データフレームと相関関係の評価に使用するためです。
Code
npとしてnumpyをインポートする パンダをpdとしてインポート
#2。 データを取得する
列名を定義し、映画とレビューのデータセットのcsvファイルを読み取り、最初の5行を印刷します。
Code
column_names = ['user_id'、 'item_id'、 'rating'、 'timestamp'] df = pd.read_csv( 'u.data'、sep = 't'、names = column_names) df.head()
出力

上記のように、XNUMXつの列があります。各ユーザーに固有のユーザーIDです。 アイテムIDは、各映画、映画の評価、およびそれらのタイムスタンプに固有です。
それでは、映画のタイトルを取得しましょう。
Code
movie_titles = pd.read_csv( "Movie_Id_Titles") movie_titles.head()
出力

パンダのライブラリを使用してデータを読み取り、データセットの上位5行を印刷します。 各映画のIDとタイトルがあります。
これで、XNUMXつの列を結合できます。
Code
df = pd.merge(df、movie_titles、on = 'item_id') df.head()
出力

これで結合されたデータフレームができました。これを次に探索的データ分析(EDA)に使用します。
#3。 探索的データ分析
データを少し調べて、最も評価の高い映画のいくつかを覗いてみましょう。
視覚化のインポートは、EDAの最初のステップになります。
Code
matplotlib.pyplotをpltとしてインポートする snsとしてseabornをインポートする sns.set_style( 'white') %matplotlibインライン
次に、XNUMXつの列として平均評価と評価数を使用して評価データフレームを作成します。
Code
df.groupby( 'title')['rating']。mean()。sort_values(ascending = False).head()
出力

Code
df.groupby( 'title')['rating']。count()。sort_values(ascending = False).head()
出力

Code
評価= pd.DataFrame(df.groupby( 'title')['rating']。mean()) ratings.head()
出力

次に、平均評価のすぐ隣に評価列の数を設定します。
Code
評価['評価の数'] = pd.DataFrame(df.groupby( 'title')['rating']。count()) ratings.head()
出力

いくつかのヒストグラムをプロットして、いくつかの評価を視覚的に確認します。
Code
plt.figure(figsize =(10,4)) 評価['評価の数']。hist(bins = 70)
出力

Code
plt.figure(figsize =(10,4)) ratings ['rating']。hist(bins = 70)
出力

Code
sns.jointplot(x = 'レーティング'、y = 'レーティング数'、data =レーティング、alpha = 0.5)
出力

わかった! データがどのように見えるかを包括的に把握できたので、Pythonでの簡単なレコメンデーションシステムの構築に移りましょう。
#4。 類似の映画を推薦する
次に、ユーザーIDと映画のタイトルを使用してマトリックスを作成しましょう。 各セルは、その映画のユーザーの評価で構成されます。
注: たくさんあります NaN ほとんどの人が映画のほとんどを見たことがないので、価値観。
Code
moviemat = df.pivot_table(index = 'user_id'、columns = 'title'、values = 'rating') moviemat.head()
出力

最も評価の高い映画を印刷する:
Code
ratings.sort_values( '評価の数'、ascending = False).head(10)
出力

XNUMXつの映画を選びましょう:スターウォーズ、SF映画。 もうXNUMXつはコメディーのLiarLiarです。 次のステップは、これらXNUMXつの映画のユーザー評価を取得することです。
Code
starwars_user_ratings = moviemat ['スターウォーズ(1977)'] liarliar_user_ratings = moviemat ['Liar Liar(1997)'] starwars_user_ratings.head()
出力

次に、corrwith()メソッドを使用して、XNUMXつのパンダシリーズ間の相関関係を取得できます。
Code
類似_to_starwars = moviemat.corrwith(starwars_user_ratings) like_to_liarliar = moviemat.corrwith(liarliar_user_ratings)
出力

NaN値を削除することでクリーンアップできるnull値はまだたくさんあります。 したがって、シリーズの代わりにDataFrameを使用します。
Code
corr_starwars = pd.DataFrame(similar_to_starwars、columns = ['Correlation']) corr_starwars.dropna(inplace = True) corr_starwars.head()
出力

ここで、相関によってデータフレームをソートするとします。 その場合、最も類似した映画を入手する必要がありますが、実際には意味をなさない映画がいくつかあることに注意してください。
これは、スターウォーズも見たユーザーが一度だけ見た映画がたくさんあるからです。
Code
corr_starwars.sort_values( 'Correlation'、ascending = False).head(10)
出力

これは、100件未満のレビューでフィルムを除外することで修正できます。 この値は、前にEDAセクションでプロットしたヒストグラムに基づいて決定できます。
Code
corr_starwars = corr_starwars.join(ratings ['num ofratings']) corr_starwars.head()
出力

次に、値を並べ替えて、タイトルがどのように理解を深めるかを確認します。
Code
corr_starwars [corr_starwars ['評価数']> 100] .sort_values( 'Correlation'、ascending = False).head()
出力

コメディーのライアーライアー映画でも同じことが進行します。
Code
corr_liarliar = pd.DataFrame(similar_to_liarliar、columns = ['Correlation']) corr_liarliar.dropna(inplace = True) corr_liarliar = corr_liarliar.join(ratings ['num ofratings']) corr_liarliar [corr_liarliar ['評価数']> 100] .sort_values( 'Correlation'、ascending = False).head()
出力

お疲れ様でした。あなたはあなた自身の映画推薦エンジンを作りました。
レコメンデーションエンジンを使用するアプリケーションとトップ企業
多くの業界では、ユーザーインタラクションを促進し、ショッピングの見通しを高めるためにレコメンデーションエンジンを採用しています。 誰もが見てきたように、レコメンデーションエンジンは、企業がユーザーと通信する方法を変更し、ユーザーが収集できる情報に基づいて投資収益率(ROI)を最大化することができます。
ほぼすべての企業がどのようにレコメンデーションエンジンを使用して利益を得るチャンスがあるかを見ていきます。
1。 Eコマース
Eコマースは、レコメンデーションエンジンが最初に広く採用された業界です。 Eコマースビジネスは、数百万の顧客とオンラインデータベース上のデータに正確な推奨事項を提供するのに最適です。
2 小売
ショッピングデータは、機械学習アルゴリズムにとって最も価値のある情報です。 これは、ユーザーの意図に関する最も正確なデータポイントです。 ショッピングデータの山を持っている小売業者は、顧客に具体的な推奨事項を生成する企業の最前線にいます。
3。 メディア
電子商取引のように、メディア企業は推奨エンジン技術に飛び乗った最初の人です。 レコメンデーションエンジンが機能していないニュースサイトに気付くのは難しいです。
4。 銀行業
銀行業は、何百万人もの人々がデジタルで利用しているマスマーケット業界であり、推奨事項の第一人者です。 何千もの同等のユーザーのデータと相関する、顧客の正確な財務状況と過去の選択を理解することは非常に重要です。
5。 テレコム
この業界は、銀行業界と同様のダイナミクスを共有しています。 通信事業者は、すべてのアクションが文書化されている何百万もの顧客の資格を持っています。 また、製品範囲は他のセクターに比べて適度に狭く、テレコムでの推奨事項をより管理しやすいソリューションにしています。
6。 公益事業
テレコムと同様のダイナミクスですが、ユーティリティの製品範囲はさらに限定されているため、推奨事項は比較的使いやすくなっています。
レコメンデーションエンジンを使用しているトップ企業には
- Amazon
- Netflix
- Spotifyは
- YouTube
- TikTok
- 火口
- Quora
- でログイン
- Yahoo
最終的な考え
レコメンデーションエンジンは、アップセル、クロスセル、ビジネスの促進に役立つ強力なマーケティングツールです。 レコメンデーションエンジンの分野では多くのことが起こっています。 すべての企業は、すべてのユーザーに最高の満足度の推奨事項を提供するために、テクノロジーを最新の状態に保つ必要があります。
ここで、このガイドの最後に到達します。 すべてのトピックと説明が、機械学習の推奨エンジンでの旅を始めるのに役立つことを願っています。
についての私たちのブログでより多くの記事を読む 推奨エンジン.
それでも疑問がある場合は、私のソーシャルメディアプロファイルで私に連絡してください。喜んでお手伝いします。 あなたは私について以下でもっと読むことができます:
私は、機械学習、人工知能、コンピュータービジョンを専門とするコンピューターサイエンスの学士号を取得したデータサイエンティストです。 Mrinalは、フリーランスのブロガー、作家、オタクでもあり、XNUMX年の経験があります。 私は現在、コンピュータサイエンスのほとんどの分野で働いている経歴を持ち、ウィンザー大学でAIを専門とする応用コンピューティングの修士号を取得しており、フリーランスのコンテンツライターおよびコンテンツアナリストです。
Mrinal Waliaによるレコメンダーエンジンの詳細:
1. リソースを使用したトップ5のオープンソース機械学習レコメンダーシステムプロジェクト
2. コンピュータサイエンスの学生のためのオープンソースのディープラーニングプロジェクトを試してみる必要があります
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- "
- &
- 100
- 2021
- 2022
- 私たちについて
- アクセス
- Action
- 行動
- 活動
- Ad
- NEW
- 住所
- 利点
- アドバイス
- AI
- アルゴリズム
- アルゴリズム
- すべて
- 間で
- 分析
- アナリスト
- 分析論
- 記事
- 物品
- 人工の
- 人工知能
- 利用できます
- 平均
- AWS
- バンキング
- 基本的に
- さ
- BEST
- 10億
- ビット
- ブログ
- 本
- 後押し
- ビルド
- 建物
- ビジネス
- ビジネス
- CAGR
- 挑戦する
- 課題
- 変化する
- クラシック
- コード
- 共同
- 収集
- 集める
- コラム
- 組み合わせ
- コメディ
- 注釈
- 企業
- 会社
- コンペ
- 複雑な
- コンピュータサイエンス
- Computer Vision
- コンピューティング
- consumer
- 消費者体験
- 消費者
- コンテンツ
- 作成
- Credentials
- 顧客エンゲージメント
- Customers
- データ
- データ分析
- データ分析
- データサイエンティスト
- データストレージ
- データベース
- 深い学習
- 需要
- 詳細
- 異なります
- 話し合います
- そうではありません
- ドル
- 運転
- 間に
- eコマース
- 効果的な
- 婚約
- 英語
- イベント
- 例
- 体験
- エクスペリエンス
- 直面して
- フィクション
- 膜
- ファイナンシャル
- 名
- 修正する
- フォーカス
- フリーランス
- ゲーム&オタク
- 性別
- 生成する
- グローバル
- 行く
- でログイン
- グラブ
- 成長
- ガイド
- 助けます
- こちら
- history
- 認定条件
- How To
- HTTPS
- ハイブリッド
- 識別する
- 直ちに
- 実装
- 重要
- 増える
- 産業
- 産業を変えます
- 情報
- 洞察
- 統合
- インテリジェンス
- 意図
- 相互作用
- 利益
- インターネット
- IT
- ジョブ
- join
- 旅
- ジュピターノート
- 知識
- 言語
- 大
- 主要な
- 学習
- 図書館
- 限定的
- 機械学習
- 作成
- 地図
- 市場
- マーケティング
- 一致
- マトリックス
- メディア
- Meta
- メトリック
- マインド
- ML
- MongoDBの
- 気分
- 他には?
- 映画
- 動画
- 名
- 自然言語
- 自然言語処理
- 必要とされる
- Netflix
- ニュース
- 提供
- 提供すること
- オファー
- オンライン
- 機会
- オプション
- 注文
- その他
- のワークプ
- プレイ
- 強力な
- 予測
- 現在
- 問題
- プロセス
- プロダクト
- 製品
- プロフィール
- 対応プロファイル
- 利益
- プロジェクト(実績作品)
- 提供します
- Python
- 品質
- 品質データ
- 範囲
- 価格表
- 評価
- リーディング
- への
- 記録
- 要件
- 結果
- 小売業者
- 収入
- レビュー
- ROI
- ルール
- ランニング
- セールス
- 満足
- スケーラビリティ
- 科学
- サイエンスフィクション
- を検索
- セクター
- センス
- シリーズ
- サービス
- セッションに
- シェアする
- 株式
- ショッピング
- 同様の
- 簡単な拡張で
- サイズ
- So
- 社会
- ソーシャルメディア
- ソリューション
- 解決する
- SQL
- スターウォーズ
- start
- 開始
- ストレージ利用料
- 店舗
- 戦略
- 驚き
- システム
- テクニック
- テクノロジー
- 通信会社?」
- 電気通信
- 介して
- 時間
- 今日
- ツール
- 豊富なツール群
- top
- トップ5
- トピック
- トランザクション
- さえずり
- 大学
- us
- USD
- users
- 通常
- 公益事業
- 貴重な情報
- 値
- 評価
- 詳しく見る
- ビジョン
- よく見る
- この試験は
- 誰
- 広く
- ウィンザー
- 無し
- 仕事
- ワーキング
- 作品
- でしょう
- 作家
- X
- 年
- 年