アパッチ氷山 は、非常に大規模な分析データセット用のオープン テーブル形式であり、データセットの状態に関するメタデータ情報を、データセットが時間の経過とともに進化および変化するにつれてキャプチャします。 SQL テーブルと同様に機能する高性能テーブル形式を使用して、Spark、Trino、PrestoDB、Flink、Hive などのコンピューティング エンジンにテーブルを追加します。 Iceberg は、データ レイクでの ACID トランザクションのサポートと、スキーマとパーティションの進化、タイム トラベル、ロールバックなどの機能で非常に人気があります。
Apache Iceberg の統合は、以下を含む AWS 分析サービスによってサポートされています。 アマゾンEMR, アマゾンアテナ, AWSグルー. Amazon EMR は、Iceberg を実行できる Spark、Hive、Trino、および Flink を使用してクラスターをプロビジョニングできます。 Amazon EMR バージョン 6.5.0 以降では、次のことができます。 EMR クラスターで Iceberg を使用する ブートストラップ アクションを必要とせずに。 2022 年初頭、AWS は Apache Iceberg を利用した Athena ACID トランザクションの一般提供を発表しました。 最近リリースされた Athena クエリ エンジン バージョン 3 Iceberg テーブル形式とのより良い統合を提供します。 AWS Glue 3.0 以降 Apache Iceberg フレームワークをサポート データレイク用。
この投稿では、お客様が最新のデータ レイクに何を求めているか、および Apache Iceberg がお客様のニーズに対応するのにどのように役立つかについて説明します。 次に、高性能で進化する Iceberg データ レイクを構築するためのソリューションについて説明します。 Amazon シンプル ストレージ サービス (Amazon S3) を挿入し、SQL ステートメントの挿入、更新、および削除を実行して増分データを処理します。 最後に、プロセスのパフォーマンスを調整して読み取りと書き込みのパフォーマンスを向上させる方法を示します。
Apache Iceberg が最新のデータ レイクで顧客が求めるものにどのように対処するか
多くのユーザー、アプリケーション、および分析ツールをサポートするために、構造化データと非構造化データを使用してデータ レイクを構築するお客様がますます増えています。 ACID トランザクション、レコード レベルの更新と削除、タイム トラベル、ロールバックなどのデータベースのような機能をサポートするデータ レイクの必要性が高まっています。 Apache Iceberg は、Amazon S3 の費用対効果の高いペタバイト規模のデータ レイクでこれらの機能をサポートするように設計されています。
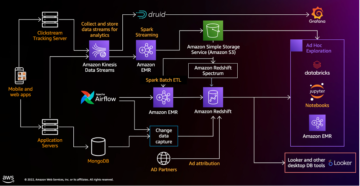
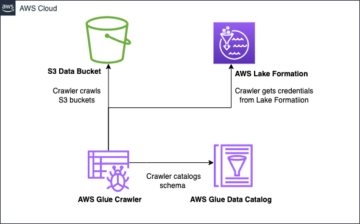
Apache Iceberg は、個々のデータ ファイルの作成時にデータセットに関する豊富なメタデータ情報を取得することで、顧客のニーズに対応します。 次の図に示すように、Iceberg テーブルのアーキテクチャには、Iceberg カタログ、メタデータ レイヤー、およびデータ レイヤーの XNUMX つのレイヤーがあります (source).

Iceberg カタログには、現在のテーブル メタデータ ファイルへのメタデータ ポインターが格納されます。 選択クエリが Iceberg テーブルを読み取る場合、クエリ エンジンは最初に Iceberg カタログに移動し、次に現在のメタデータ ファイルの場所を取得します。 Iceberg テーブルが更新されるたびに、テーブルの新しいスナップショットが作成され、メタデータ ポインターは現在のテーブル メタデータ ファイルを指します。
以下は、AWS Glue を実装した Iceberg カタログの例です。 データベース名、Iceberg テーブルの場所 (S3 パス)、およびメタデータの場所を確認できます。

メタデータ レイヤーには、階層内のメタデータ ファイル、マニフェスト リスト、マニフェスト ファイルの XNUMX 種類のファイルがあります。 階層の最上位にあるのは、テーブルのスキーマ、パーティション情報、およびスナップショットに関する情報を格納するメタデータ ファイルです。 スナップショットは、マニフェスト リストを指します。 マニフェスト リストには、マニフェスト ファイルの場所、マニフェスト ファイルが属するパーティション、追跡するデータ ファイルのパーティション列の下限と上限など、スナップショットを構成する各マニフェスト ファイルに関する情報が含まれています。 マニフェスト ファイルは、データ ファイルと、ファイル形式などの各ファイルに関する追加の詳細を追跡します。 XNUMX つのファイルはすべて階層内で機能し、Iceberg テーブル内のスナップショット、スキーマ、パーティション分割、プロパティ、およびデータ ファイルを追跡します。
データ層には、アイスバーグ テーブルの個々のデータ ファイルがあります。 Iceberg は、Parquet、ORC、Avro など、幅広いファイル形式をサポートしています。 Iceberg テーブルは、データ ファイルでパーティションの場所を指すだけでなく、個々のデータ ファイルを追跡するため、書き込み操作と読み取り操作を分離します。 データ ファイルはいつでも書き込むことができますが、変更を明示的にコミットするだけで、新しいバージョンのスナップショットとメタデータ ファイルが作成されます。
ソリューションの概要
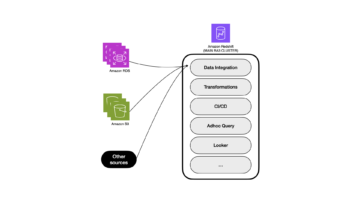
この投稿では、Amazon S3 で高性能の Apache Iceberg データ レイクを構築するためのソリューションについて説明します。 挿入、更新、および削除 SQL ステートメントを使用して増分データを処理します。 Iceberg テーブルを調整して、読み取りと書き込みのパフォーマンスを向上させます。 次の図は、ソリューション アーキテクチャを示しています。

このソリューションを実証するために、 アマゾンのカスタマーレビュー S3 バケット内のデータセット (s3://amazon-reviews-pds/parquet/)。 実際のユースケースでは、S3 バケットに保存された生データになります。 次のコードでデータサイズを確認できます AWSコマンドラインインターフェイス (AWS CLI):
合計オブジェクト数は 430 で、合計サイズは 47.4 GiB です。
このソリューションをセットアップしてテストするには、次の高レベルの手順を実行します。
- キュレートされたゾーンに S3 バケットをセットアップして、変換されたデータを Iceberg テーブル形式で保存します。
- Apache Iceberg の適切な構成で EMR クラスターを起動します。
- EMR Studio でノートブックを作成します。
- Apache Iceberg の Spark セッションを構成します。
- データを Iceberg テーブル形式に変換し、データをキュレーション ゾーンに移動します。
- Athena で挿入、更新、および削除クエリを実行して、増分データを処理します。
- パフォーマンスチューニングを実行します。
前提条件
このチュートリアルを進めるには、 AWSアカウント とともに AWS IDおよびアクセス管理 必要なリソースをプロビジョニングするための十分なアクセス権を持つ (IAM) ロール。
データレイクのキュレートされたゾーンに Iceberg データ用の S3 バケットを設定する
S3 バケットを作成するリージョンを選択し、一意の名前を付けます。
EMR クラスターを起動して、Spark を使用して Iceberg ジョブを実行する
から EMR クラスターを作成できます。 AWSマネジメントコンソール、Amazon EMR CLI、または AWSクラウド開発キット (AWS CDK)。 この投稿では、コンソールから EMR クラスターを作成する方法について説明します。
- Amazon EMRコンソールで、 クラスターを作成する.
- 選択する 詳細オプション.
- ソフトウェア構成で、最新の Amazon EMR リリースを選択します。 2023 年 6.9.0 月現在、最新リリースは 6.5.0 です。 Iceberg には、リリース XNUMX 以降が必要です。
- 選択 ジュピターエンタープライズゲートウェイ & スパーク インストールするソフトウェアとして。
- ソフトウェア設定の編集選択 構成を入力してください 入力してください
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - 他の設定はデフォルトのままにして、 Next.

- Hardware、デフォルト設定を使用します。
- 選択する Next.
- クラスター名、名前を入力します。 を使用しております
iceberg-blog-cluster. - 残りの設定は変更せずに、 Next.
- 選択する クラスターを作成する.
EMR Studio でノートブックを作成する
コンソールから EMR Studio でノートブックを作成する方法について説明します。
- IAMコンソールで、 EMR Studio サービスロールを作成する.
- Amazon EMRコンソールで、 EMR スタジオ.
- 選択する 始める.
始める ページが新しいタブに表示されます。
- 選択する スタジオを作成 新しいタブで。
- 名前を入力します。 アイスバーグスタジオを使用しています。
- EMR クラスターと同じ VPC とサブネット、およびデフォルトのセキュリティ グループを選択します。
- 選択する AWS Identity and Access Management(IAM) 認証のために、作成したばかりの EMR Studio サービスロールを選択します。
- の S3 パスを選択します ワークスペースのバックアップ.
- 選択する スタジオを作成.
- Studio が作成されたら、Studio アクセス URL を選択します。
- EMR Studio ダッシュボードで、 ワークスペースを作成する.
- ワークスペースの名前を入力します。 を使用しております
iceberg-workspace. - 詳細 高度な設定 選択して Workspace を EMR クラスターにアタッチする.
- 前に作成した EMR クラスターを選択します。
- 選択する ワークスペースを作成する.
- ワークスペース名を選択して、新しいタブを開きます。
ナビゲーション ウィンドウに、ワークスペースと同じ名前のノートブックがあります。 私たちの場合、それは iceberg-workspace です。
- ノートブックを開きます。
- カーネルを選択するように求められたら、選択します スパーク.
Apache Iceberg の Spark セッションを構成する
次のコードを使用して、独自の S3 バケット名を指定します。
これにより、次のSparkセッション構成が設定されます。
- スパーク.sql.カタログ.デモ – Iceberg Spark カタログ プラグインを使用する demo という名前の Spark カタログを登録します。
- スパーク.sql.catalog.demo.catalog-impl – デモ Spark カタログは、AWS Glue を物理カタログとして使用して、Iceberg データベースとテーブル情報を保存します。
- スパーク.sql.カタログ.デモ.ウェアハウス – デモ Spark カタログは、すべての Iceberg メタデータとデータ ファイルを、このプロパティで定義されたルート パスに格納します。
s3://iceberg-curated-blog-data. - スパーク.sql.extensions – Iceberg Spark SQL 拡張機能のサポートを追加します。これにより、Iceberg Spark プロシージャーおよび一部の Iceberg 専用 SQL コマンドを実行できます (これは後のステップで使用します)。
- スパーク.sql.catalog.demo.io-impl – Iceberg では、ユーザーは S3FileIO を介して Amazon S3 にデータを書き込むことができます。 AWS Glue データ カタログはデフォルトでこの FileIO を使用し、他のカタログは io-impl カタログ プロパティを使用してこの FileIO をロードできます。
データを Iceberg テーブル形式に変換する
Amazon EMR の Spark または Athena のいずれかを使用して、Iceberg テーブルをロードできます。 EMR Studio ワークスペース ノートブックの Spark セッションで、次のコマンドを実行してデータを読み込みます。
コードを実行すると、データ ウェアハウスの S3 パスに作成された XNUMX つのプレフィックス (s3://iceberg-curated-blog-data/reviews.db/all_reviews): データとメタデータ。
Athena で SQL ステートメントの挿入、更新、削除を使用して増分データを処理する
Athena は、Iceberg テーブルに対して読み取り、書き込み、更新、および最適化タスクを実行するために使用できるサーバーレス クエリ エンジンです。 Apache Iceberg データ レイク形式が増分データ インジェストをサポートする方法を示すために、データ レイクで SQL ステートメントの挿入、更新、および削除を実行します。
Athenaコンソールに移動し、 クエリエディタ. 初めて Athena クエリ エディターを使用する場合は、次のことを行う必要があります。 クエリ結果の場所を構成する 前に作成した S3 バケットになります。 テーブル reviews.all_reviews がクエリに使用できることを確認できるはずです。 次のクエリを実行して、Iceberg テーブルが正常に読み込まれたことを確認します。
挿入、更新、および削除の SQL ステートメントを実行して、増分データを処理します。
パフォーマンスチューニング
このセクションでは、Apache Iceberg の読み取りと書き込みのパフォーマンスを向上させるさまざまな方法について説明します。
Apache Iceberg テーブルのプロパティを構成する
Apache Iceberg はテーブル形式であり、読み取り、書き込み、カタログなどのテーブルの動作を構成するテーブル プロパティをサポートしています。 テーブルのプロパティを調整することで、Iceberg テーブルの読み取りおよび書き込みのパフォーマンスを向上させることができます。
たとえば、Iceberg テーブルに対して小さなファイルを書きすぎることに気付いた場合は、書き込みファイル サイズを構成して、より少ないが大きなサイズのファイルを書き込むようにすると、クエリのパフォーマンスが向上します。
| プロパティ | デフォルト | 説明 |
| write.ターゲットファイルサイズバイト | 536870912(512 MB) | このバイト数についてターゲットに生成されるファイルのサイズを制御します |
テーブル形式を変更するには、次のコードを使用します。
パーティショニングとソート
クエリを高速に実行するには、読み取るデータが少ないほど効果的です。 Iceberg は、書き込み時にキャプチャする豊富なメタデータを利用して、スキャン計画、パーティショニング、プルーニング、最小/最大値などの列レベルの統計などの手法を促進し、一致するレコードがないデータ ファイルをスキップします。 Iceberg でクエリ スキャンの計画とパーティショニングがどのように機能するか、およびそれらを使用してクエリのパフォーマンスを向上させる方法について説明します。
クエリ スキャンの計画
特定のクエリの場合、クエリ エンジンの最初のステップはスキャン計画です。これは、クエリに必要なテーブル内のファイルを見つけるプロセスです。 Iceberg の豊富なメタデータを使用して、一致するデータを含まないデータ ファイルをフィルタリングするだけでなく、不要なメタデータ ファイルを削除できるため、Iceberg テーブルでの計画は非常に効率的です。 テストでは、Iceberg 形式に変換する前の元のデータと比較して、Athena が Iceberg テーブルの特定のクエリに対して 50% 以下のデータをスキャンしたことを確認しました。
フィルタリングには次の XNUMX 種類があります。
- メタデータのフィルタリング – Iceberg は、マニフェスト リストとマニフェスト ファイルの XNUMX つのレベルのメタデータを使用して、スナップショット内のファイルを追跡します。 まず、マニフェスト ファイルのインデックスとして機能するマニフェスト リストを使用します。 計画中、Iceberg はすべてのマニフェスト ファイルを読み取ることなく、マニフェスト リストのパーティション値の範囲を使用してマニフェストをフィルター処理します。 次に、選択したマニフェスト ファイルを使用してデータ ファイルを取得します。
- データフィルタリング – マニフェスト ファイルのリストを選択した後、Iceberg は、マニフェスト ファイルに格納されている各データ ファイルのパーティション データと列レベルの統計情報を使用して、データ ファイルをフィルター処理します。 計画中に、クエリ述語はパーティション データの述語に変換され、最初にデータ ファイルをフィルター処理するために適用されます。 次に、列レベルの値のカウント、null カウント、下限、上限などの列統計を使用して、クエリ述語に一致しないデータ ファイルを除外します。 計画時に上限と下限を使用してデータ ファイルをフィルター処理することにより、Iceberg はクエリのパフォーマンスを大幅に向上させます。
パーティショニングとソート
パーティショニングは、キー列の値が同じレコードをグループ化して書き込みます。 パーティショニングの利点は、クエリ スキャンの計画: データ フィルタリングで説明したように、データの一部のみにアクセスするクエリが高速になることです。 Iceberg は、非表示のパーティショニングをサポートすることでパーティショニングを簡素化します。これは、Iceberg が列の値を取得し、必要に応じてそれを変換することによってパーティション値を生成する方法です。
このユース ケースでは、まず、パーティション分割されていない Iceberg テーブルに対して次のクエリを実行します。 次に、レコードを除外するクエリの WHERE 条件で使用されるレビューのカテゴリで Iceberg テーブルを分割します。 パーティショニングを使用すると、クエリでスキャンできるデータが大幅に少なくなります。 次のコードを参照してください。
パーティション化されていない all_reviews テーブルとパーティション化されたテーブルで次の select ステートメントを実行して、パフォーマンスの違いを確認します。
次の表は、データのパーティショニングによるパフォーマンスの向上を示しています。パフォーマンスが約 50% 向上し、スキャンされるデータが 70% 減少しています。
| データセット名 | 分割されていないデータセット | 分割されたデータセット |
| 実行時間 (秒) | 8.20 | 4.25 |
| スキャンされたデータ (MB) | 131.55 | 33.79 |
実行時間は、テストで複数回実行した平均実行時間であることに注意してください。
パーティショニング後、パフォーマンスが向上しました。 ただし、これは、Iceberg マニフェスト ファイルの列レベルの統計を使用することでさらに改善できます。 列レベルの統計を効果的に使用するには、クエリ パターンに基づいてレコードをさらに並べ替える必要があります。 クエリでよく使用される列を使用してデータセット全体を並べ替えると、各データ ファイルが特定の列の一意の範囲の値になるようにデータが並べ替えられます。 これらの列がクエリ条件で使用されている場合、クエリ エンジンはデータ ファイルをさらにスキップできるため、さらに高速なクエリが可能になります。
コピーオンライトとリードオンマージ
データ レイクの Iceberg テーブルに更新と削除を実装する場合、Iceberg テーブル プロパティによって定義される XNUMX つのアプローチがあります。
- コピーオンライト – このアプローチでは、Iceberg テーブルに変更 (更新または削除) がある場合、影響を受けるレコードに関連付けられたデータ ファイルが複製および更新されます。 レコードは、複製されたデータ ファイルから更新または削除されます。 Iceberg テーブルの新しいスナップショットが作成され、新しいバージョンのデータ ファイルが参照されます。 これにより、全体的な書き込みが遅くなります。 競合を伴う同時書き込みが必要な場合は、再試行が必要になるため、書き込み時間がさらに長くなります。 一方、データを読み取るときは、余分なプロセスは必要ありません。 クエリは、最新バージョンのデータ ファイルからデータを取得します。
- マージオンリード – このアプローチでは、Iceberg テーブルに更新または削除があった場合、既存のデータ ファイルは書き換えられません。 代わりに、変更を追跡するために新しい削除ファイルが作成されます。 削除の場合、削除されたレコードを含む新しい削除ファイルが作成されます。 Iceberg テーブルを読み取る場合、取得したデータに削除ファイルが適用され、削除レコードが除外されます。 更新の場合、更新されたレコードを削除済みとしてマークするために、新しい削除ファイルが作成されます。 次に、それらのレコード用に新しいファイルが作成されますが、値は更新されます。 Iceberg テーブルを読み取る場合、取得したデータに削除ファイルと新しいファイルの両方が適用され、最新の変更が反映され、正しい結果が生成されます。 そのため、後続のクエリでは、データ ファイルを削除ファイルと新しいファイルにマージするための追加の手順が発生し、通常はクエリ時間が長くなります。 一方、既存のデータ ファイルを書き換える必要がないため、書き込みは高速になる可能性があります。
XNUMX つのアプローチの影響をテストするには、次のコードを実行して Iceberg テーブルのプロパティを設定します。
Athena で update、delete、および select SQL ステートメントを実行して、コピー オン ライトとマージ オン リードの実行時の違いを示します。
次の表は、クエリの実行時間をまとめたものです。
| クエリー | コピーオンライト | マージオンリード | ||||
| UPDATE | DELETE | SELECT | UPDATE | DELETE | SELECT | |
| 実行時間 (秒) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| スキャンしたデータ (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
実行時間は、テストで複数回実行した平均実行時間であることに注意してください。
テスト結果が示すように、XNUMX つのアプローチには常にトレードオフがあります。 どのアプローチを使用するかは、ユース ケースによって異なります。 要約すると、考慮事項は読み取りと書き込みのレイテンシに帰着します。 次の表を参照して、正しい選択を行うことができます。
| . | コピーオンライト | マージオンリード |
| メリット | 読み取りの高速化 | より高速な書き込み |
| デメリット | 高価な書き込み | 読み取りのレイテンシが高い |
| 使用する場合 | 頻繁な読み取り、まれな更新と削除、または大規模なバッチ更新に適しています | 更新と削除が頻繁に行われるテーブルに適しています |
データ圧縮
データ ファイルのサイズが小さい場合、Iceberg テーブルに数千または数百万のファイルが含まれる可能性があります。 これにより、I/O 操作が大幅に増加し、クエリが遅くなります。 さらに、Iceberg はデータセット内の各データ ファイルを追跡します。 データ ファイルが増えると、メタデータも増えます。 これにより、メタデータ ファイルを読み取る際のオーバーヘッドと I/O 操作が増加します。 クエリのパフォーマンスを向上させるために、小さなデータ ファイルを大きなデータ ファイルに圧縮することをお勧めします。
Iceberg テーブルのレコードを更新および削除するときに、読み取りオン マージ アプローチを使用すると、多くの小さな削除または新しいデータ ファイルが発生する可能性があります。 圧縮を実行すると、これらすべてのファイルが結合され、新しいバージョンのデータ ファイルが作成されます。 これにより、読み取り中にそれらを調整する必要がなくなります。 より高速な書き込み速度を維持しながら、読み取りへの影響を最小限に抑えるために、定期的な圧縮ジョブを実行することをお勧めします。
次のデータ圧縮コマンドを実行してから、Athena から選択クエリを実行します。
次の表は、データ圧縮前と圧縮後の実行時間を比較しています。 約 40% のパフォーマンスの向上が見られます。
| クエリー | データ圧縮前 | データ圧縮後 |
| 実行時間 (秒) | 97.75 | 32.676 seconds |
| スキャンしたデータ (MB) | 137.16 M | 189.19 M |
選択クエリが実行されたことに注意してください all_reviews 更新操作と削除操作の後、データ圧縮の前後のテーブル。 実行時間は、テストで複数回実行した場合の平均実行時間です。
クリーンアップ
ソリューションのチュートリアルに従ってユース ケースを実行したら、次の手順を実行してリソースをクリーンアップし、それ以上のコストを回避します。
- Athena から AWS Glue テーブルとデータベースをドロップするか、ノートブックで次のコードを実行します。
- EMR Studio コンソールで、 ワークスペース ナビゲーションペインに表示されます。
- 作成したワークスペースを選択し、 削除.
- EMR コンソールで、 ·スタジオ ページで見やすくするために変数を解析したりすることができます。
- 作成した Studio を選択し、 削除.
- EMR コンソールで、 クラスター ナビゲーションペインに表示されます。
- クラスタを選択して選択します Terminate.
- この投稿の前提条件の一部として作成した S3 バケットとその他のリソースを削除します。
まとめ
この投稿では、Apache Iceberg フレームワークと、それが最新のデータ レイクで抱えているいくつかの課題の解決にどのように役立つかを紹介しました。 次に、Apache Iceberg を使用してデータ レイクで増分データを処理するソリューションについて説明しました。 最後に、ユース ケースの読み取りと書き込みのパフォーマンスを向上させるためのパフォーマンス チューニングについて深く掘り下げました。
この投稿が、データ レイク ソリューションに Apache Iceberg を採用するかどうかを決定するのに役立つ情報を提供することを願っています。
著者について
 フローラ・ウー AWS Data Lab のシニア レジデント アーキテクトです。 彼女は、企業顧客がデータ分析戦略を作成し、ビジネスの成果を加速するソリューションを構築するのを支援しています。 余暇には、テニス、サルサのダンス、旅行を楽しんでいます。
フローラ・ウー AWS Data Lab のシニア レジデント アーキテクトです。 彼女は、企業顧客がデータ分析戦略を作成し、ビジネスの成果を加速するソリューションを構築するのを支援しています。 余暇には、テニス、サルサのダンス、旅行を楽しんでいます。
 ダニエル・リー アマゾン ウェブ サービスのシニア ソリューション アーキテクトです。 彼は、顧客がクラウド サービスと戦略を開発、採用、実装するのを支援することに重点を置いています。 仕事をしていないときは、家族と屋外で過ごすのが好きです。
ダニエル・リー アマゾン ウェブ サービスのシニア ソリューション アーキテクトです。 彼は、顧客がクラウド サービスと戦略を開発、採用、実装するのを支援することに重点を置いています。 仕事をしていないときは、家族と屋外で過ごすのが好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- できる
- 私たちについて
- 上記の.
- 加速する
- アクセス
- アクセス管理
- Action
- 使徒行伝
- 添加
- NEW
- 住所
- アドレス
- 追加
- 採用
- 利点
- 後
- に対して
- すべて
- ことができます
- 常に
- Amazon
- アマゾンEMR
- Amazon Webサービス
- 分析的
- 分析論
- &
- 発表の
- アパッチ
- 適用された
- アプローチ
- アプローチ
- 適切な
- 建築
- 関連する
- 認証
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- 平均
- 避ける
- AWS
- AWSグルー
- ベース
- なぜなら
- になる
- 恩恵
- より良いです
- の間に
- より大きい
- ブートストラップ
- ビルド
- 建物
- ビジネス
- キャプチャ
- キャプチャ
- 場合
- 例
- カタログ
- カタログ
- カテゴリー
- 課題
- 変化する
- 変更
- チェック
- 選択
- 選択する
- 分類
- クラウド
- クラウドサービス
- クラスタ
- コード
- コラム
- コラム
- 組み合わせる
- 来ます
- コミット
- 比べ
- コンプリート
- 計算
- 同時
- 条件
- 構成
- 検討事項
- 領事
- 変換
- 変換
- コスト効率の良い
- コスト
- 可能性
- 作ります
- 作成した
- 作成します。
- キュレーション
- 電流プローブ
- 顧客
- Customers
- ダンシング
- ダッシュボード
- データ
- データ分析
- データレイク
- データ処理
- データウェアハウス
- データベース
- データセット
- 深いです
- ディープダイブ
- デフォルト
- 定義済みの
- デモ
- 実証します
- 依存
- 設計
- 細部
- 開発する
- 開発
- 違い
- 異なります
- 話し合います
- ドント
- ダウン
- 劇的に
- Drop
- 間に
- 各
- 前
- 早い
- エディタ
- 効果的に
- 効率的な
- どちら
- 排除
- 使用可能
- 有効にする
- 終了
- エンジン
- エンジン
- 入力します
- Enterprise
- 企業顧客
- エーテル(ETH)
- さらに
- 進化
- 進化
- 進化
- 例
- 既存の
- 存在
- 説明
- エクステンション
- 余分な
- 促進する
- 家族
- スピーディー
- 速いです
- 特徴
- フィギュア
- File
- filter
- フィルタリング
- フィルター
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- 初回
- 焦点を当てて
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- フレームワーク
- 頻繁な
- から
- さらに
- さらに
- 生成された
- 取得する
- 与えられた
- ゴエス
- 良い
- 大いに
- グループ
- ハンド
- 起こる
- 助けます
- 助け
- ことができます
- 隠されました
- 階層
- ハイレベル
- ハイパフォーマンス
- 高性能
- ハイブ
- 希望
- 認定条件
- How To
- しかしながら
- HTML
- HTTPS
- IAM
- アイデンティティ
- アイデンティティとアクセス管理
- 影響
- 影響を受けた
- 実装する
- 実装
- 実装
- 改善します
- 改善されました
- 改善
- 向上させる
- in
- 含めて
- 増える
- 増加した
- 増加
- index
- 個人
- 情報
- install
- を取得する必要がある者
- 統合
- 導入
- 分離する
- IT
- 1月
- Jobs > Create New Job
- キー
- ラボ
- 湖
- 大
- より大きい
- レイテンシ
- 最新の
- 最新のリリース
- 層
- 層
- つながる
- レベル
- LIMIT
- LINE
- リスト
- 少し
- 負荷
- 場所
- make
- 作る
- 管理
- 多くの
- マーク
- 市場
- 一致
- マッチング
- マージ
- かもしれない
- 何百万
- モダン
- 他には?
- の試合に
- 名
- 名前付き
- ナビゲート
- ナビゲーション
- 必要
- 必要とされる
- ニーズ
- 新作
- ノート
- オブジェクト
- 開いた
- 操作
- 業務執行統括
- 最適化
- 最適化
- 注文
- オリジナル
- その他
- 屋外で
- 全体
- 自分の
- ペイン
- 部
- path
- パターン
- 実行する
- パフォーマンス
- 物理的な
- 計画
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 再生
- プラグイン
- ポイント
- 人気
- 可能
- ポスト
- パワード
- 前提条件
- 手続き
- プロセス
- 処理
- 作り出す
- プロパティ
- 財産
- 提供します
- は、大阪で
- 提供
- 準備
- 範囲
- Raw
- 生データ
- 読む
- リーディング
- リアル
- 最近
- 推奨される
- 記録
- 反映する
- 地域
- レジスタ
- レギュラー
- リリース
- リリース
- 残り
- の提出が必要です
- 必要
- リソース
- 結果
- 結果
- レビュー
- 富裕層
- 職種
- ルート
- ラン
- ランニング
- 同じ
- スキャン
- 秒
- セクション
- セキュリティ
- 選択
- 選択
- サーバレス
- サービス
- サービス
- セッション
- セッションに
- セット
- 設定
- 設定
- すべき
- 表示する
- 作品
- 簡単な拡張で
- 状況
- サイズ
- 遅くなります
- 小さい
- Snapshot
- So
- ソフトウェア
- 溶液
- ソリューション
- 一部
- スパーク
- 特定の
- スピード
- 支出
- SQL
- 起動
- 都道府県
- ステートメント
- 文
- 統計情報
- 手順
- ステップ
- まだ
- ストレージ利用料
- 店舗
- 保存され
- 店舗
- 作戦
- 戦略
- 構造化された
- 構造化データと非構造化データ
- 研究
- サブネット
- それに続きます
- 首尾よく
- そのような
- 十分な
- 概要
- サポート
- サポート
- 支援する
- サポート
- テーブル
- 取り
- 取得
- ターゲット
- タスク
- テクニック
- テニス
- test
- テスト
- テスト
- 情報
- ステート
- アプリ環境に合わせて
- それによって
- 数千
- 三
- 介して
- 時間
- タイムトラベル
- 〜へ
- 一緒に
- あまりに
- 豊富なツール群
- top
- トータル
- 追跡する
- 取引
- 変換
- 旅行
- 旅行
- 順番
- 下
- ユニーク
- アップデイト
- 更新しました
- 更新版
- 更新
- URL
- つかいます
- 使用事例
- users
- 通常
- VAL
- 値
- 価値観
- 確認する
- バージョン
- 歩いた
- ウォークスルー
- 倉庫
- ウオッチ
- 方法
- ウェブ
- Webサービス
- この試験は
- かどうか
- which
- while
- ワイド
- 広い範囲
- 意志
- 無し
- 仕事
- ワーキング
- 作品
- でしょう
- 書きます
- 書き込み
- あなたの
- ゼファーネット