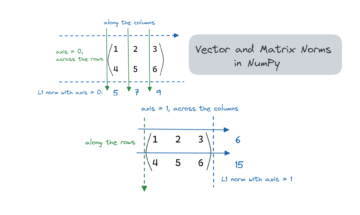
다음으로 생성된 이미지 Ideogram.ai
따라서 이러한 벡터 데이터베이스 용어를 모두 들어보셨을 것입니다. 어떤 사람들은 그것에 대해 이해할 수도 있고, 어떤 사람들은 그렇지 않을 수도 있습니다. 벡터 데이터베이스는 최근 몇 년간 더욱 주목받는 주제가 되었기 때문에 이에 대해 모르더라도 걱정하지 마십시오.
Generative AI가 대중, 특히 LLM에 도입되면서 벡터 데이터베이스의 인기가 높아졌습니다.
GPT-4 및 Gemini와 같은 많은 LLM 제품은 입력에 대한 텍스트 생성 기능을 제공하여 작업을 돕습니다. 음, 벡터 데이터베이스는 실제로 이러한 LLM 제품에서 중요한 역할을 합니다.
그런데 벡터 데이터베이스는 어떻게 작동했나요? 그리고 LLM과의 관련성은 무엇입니까?
위의 질문이 이 기사에서 답변할 내용입니다. 자, 함께 살펴보겠습니다.
벡터 데이터베이스는 벡터 데이터를 저장, 색인화, 쿼리하도록 설계된 특수 데이터베이스 저장소입니다. 일반적으로 기계 학습 모델, 특히 LLM의 출력이므로 고차원 벡터 데이터에 최적화되는 경우가 많습니다.
벡터 데이터베이스의 맥락에서 벡터는 데이터의 수학적 표현입니다. 각 벡터는 데이터 위치를 나타내는 숫자 점 배열로 구성됩니다. 벡터는 LLM에서 텍스트 데이터를 벡터로 표현하는 데 자주 사용되며 텍스트 데이터보다 처리하기 쉽습니다.
LLM 공간에서 모델은 텍스트 입력을 가질 수 있으며 텍스트를 텍스트의 의미론적 및 구문론적 특성을 나타내는 고차원 벡터로 변환할 수 있습니다. 이 프로세스를 우리는 임베딩(Embedding)이라고 부릅니다. 간단히 말해서 임베딩은 텍스트를 숫자 데이터가 포함된 벡터로 변환하는 프로세스입니다.
임베딩은 일반적으로 임베딩 모델(Embedding Model)이라는 신경망 모델을 사용하여 임베딩 공간의 텍스트를 나타냅니다.
"I Love Data Science"라는 예제 텍스트를 사용해 보겠습니다. 이를 OpenAI 모델 text-embedding-3-small로 표현하면 1536차원의 벡터가 생성됩니다.
[0.024739108979701996, -0.04105354845523834, 0.006121257785707712, -0.02210472710430622, 0.029098540544509888,...]
벡터 내의 숫자는 모델 임베딩 공간 내의 좌표입니다. 이들은 함께 모델에서 나오는 문장 의미의 고유한 표현을 형성합니다.
그런 다음 벡터 데이터베이스는 이러한 임베딩 모델 출력을 저장합니다. 그런 다음 사용자는 필요에 따라 벡터를 쿼리하고, 색인화하고, 검색할 수 있습니다.
소개는 이것으로 충분할 것입니다. 좀 더 기술적인 실습을 시작해 보겠습니다. 우리는 오픈 소스 벡터 데이터베이스를 사용하여 벡터를 설정하고 저장하려고 합니다. 위비하다.
Weaviate는 벡터를 저장하는 프레임워크 역할을 하는 확장 가능한 오픈 소스 벡터 데이터베이스입니다. Docker와 같은 인스턴스에서 Weaviate를 실행하거나 WCS(Weaviate Cloud Services)를 사용할 수 있습니다.
Weaviate 사용을 시작하려면 다음 코드를 사용하여 패키지를 설치해야 합니다.
pip install weaviate-client
작업을 더 쉽게 하기 위해 WCS의 샌드박스 클러스터를 벡터 데이터베이스로 사용하겠습니다. Weaviate는 결제 수단을 등록하지 않고도 벡터를 저장하는 데 사용할 수 있는 14일 무료 클러스터를 제공합니다. 그렇게 하려면 해당 회사에 등록해야 합니다. WCS 콘솔 처음에는
WCS 플랫폼 내에서 클러스터 생성을 선택하고 샌드박스 이름을 입력합니다. UI는 아래 이미지와 같아야 합니다.

작성자 별 이미지
WCS API 키를 통해 이 클러스터에 액세스하려고 하므로 인증을 활성화하는 것을 잊지 마십시오. 클러스터가 준비되면 벡터 데이터베이스에 액세스하는 데 사용할 API 키와 클러스터 URL을 찾으세요.
준비가 완료되면 첫 번째 벡터를 벡터 데이터베이스에 저장하는 것을 시뮬레이션합니다.
벡터 데이터베이스 저장 예제의 경우 도서 컬렉션 Kaggle의 예제 데이터세트 저는 상위 100개 행과 3개 열(제목, 설명, 소개)만 사용하겠습니다.
import pandas as pd
data = pd.read_csv('commonlit_texts.csv', nrows = 100, usecols=['title', 'description', 'intro'])
데이터를 따로 보관하고 벡터 데이터베이스에 연결해 보겠습니다. 먼저 API 키와 클러스터 URL을 사용하여 원격 연결을 설정해야 합니다.
import weaviate
import os
import requests
import json
cluster_url = "Your Cluster URL"
wcs_api_key = "Your WCS API Key"
Openai_api_key ="Your OpenAI API Key"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
클라이언트 변수를 설정하면 Weaviate 클라우드 서비스에 연결하고 벡터를 저장할 클래스를 생성합니다. Weaviate의 클래스는 데이터 컬렉션이거나 관계형 데이터베이스의 테이블 이름과 유사합니다.
import weaviate.classes as wvc
client.connect()
book_collection = client.collections.create(
name="BookCollection",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
위 코드에서는 Weaviate Cluster에 연결하고 BookCollection 클래스를 생성합니다. 또한 클래스 객체는 OpenAI text2vec 임베딩 모델을 사용하여 텍스트 데이터와 OpenAI 생성 모듈을 벡터화합니다.
벡터 데이터베이스에 텍스트 데이터를 저장해 보겠습니다. 그렇게 하려면 다음 코드를 사용할 수 있습니다.
sent_to_vdb = data.to_dict(orient='records')
book_collection.data.insert_many(sent_to_vdb)
작성자 별 이미지
방금 벡터 데이터베이스에 데이터세트를 성공적으로 저장했습니다! 그게 얼마나 쉽나요?
이제 LLM과 함께 벡터 데이터베이스를 사용하는 사용 사례가 궁금할 것입니다. 이것이 우리가 다음에 논의할 내용입니다.
벡터 데이터베이스에 LLM을 적용할 수 있는 몇 가지 사용 사례입니다. 함께 살펴보겠습니다.
의미 검색
의미 검색(Semantic Search)은 기존의 키워드 기반 검색에만 의존하지 않고 질의어의 의미를 이용하여 관련성 있는 결과를 검색함으로써 데이터를 검색하는 프로세스입니다.
이 프로세스에는 LLM 모델 쿼리 임베딩을 활용하고 벡터 데이터베이스에 저장된 저장된 임베딩 유사성 검색을 수행하는 작업이 포함됩니다.
Weaviate를 사용하여 특정 쿼리를 기반으로 의미 검색을 수행해 보겠습니다.
book_collection = client.collections.get("BookCollection")
client.connect()
response = book_collection.query.near_text(
query="childhood story,
limit=2
)
위의 코드에서는 Weaviate를 사용하여 의미론적 검색을 수행하여 쿼리 어린 시절 이야기와 밀접하게 관련된 상위 2권의 책을 찾으려고 합니다. 의미 검색은 이전에 설정한 OpenAI 임베딩 모델을 사용합니다. 그 결과는 아래에서 볼 수 있습니다.
{'title': 'Act Your Age', 'description': 'A young girl is told over and over again to act her age.', 'intro': 'Colleen Archer has written for nHighlightsn. In this short story, a young girl is told over and over again to act her age.nAs you read, take notes on what Frances is doing when she is told to act her age. '}
{'title': 'The Anklet', 'description': 'A young woman must deal with unkind and spiteful treatment from her two older sisters.', 'intro': "Neil Philip is a writer and poet who has retold the best-known stories from nThe Arabian Nightsn for a modern day audience. nThe Arabian Nightsn is the English-language nickname frequently given to nOne Thousand and One Arabian Nightsn, a collection of folk tales written and collected in the Middle East during the Islamic Golden Age of the 8th to 13th centuries. In this tale, a poor young woman must deal with mistreatment by members of her own family.nAs you read, take notes on the youngest sister's actions and feelings."}
보시다시피 위의 결과에는 어린 시절 이야기에 대한 직접적인 단어가 없습니다. 그러나 그 결과는 여전히 어린이를 대상으로 한 이야기와 밀접한 관련이 있다.
생성 검색
생성 검색은 의미 검색을 위한 확장 응용 프로그램으로 정의될 수 있습니다. 생성 검색 또는 RAG(Retrieval Augmented Generation)는 벡터 데이터베이스에서 데이터를 검색하는 의미 검색과 함께 LLM 프롬프트를 활용합니다.
RAG를 사용하면 쿼리 검색 결과가 LLM으로 처리되므로 원시 데이터 대신 원하는 형식으로 가져옵니다. 벡터 데이터베이스를 사용하여 RAG를 간단하게 구현해 보겠습니다.
response = book_collection.generate.near_text(
query="childhood story",
limit=2,
grouped_task="Write a short LinkedIn post about these books."
)
print(response.generated)
그 결과는 아래 텍스트에서 확인할 수 있습니다.
Excited to share two captivating short stories that explore themes of age and mistreatment. "Act Your Age" by Colleen Archer follows a young girl who is constantly told to act her age, while "The Anklet" by Neil Philip delves into the unkind treatment faced by a young woman from her older sisters. These thought-provoking tales will leave you reflecting on societal expectations and family dynamics. #ShortStories #Literature #BookRecommendations 📚
보시다시피 데이터 내용은 이전과 동일하지만 이제 OpenAI LLM으로 처리되어 짧은 LinkedIn 게시물을 제공합니다. 이런 방식으로 RAG는 데이터의 특정 형식 출력을 원할 때 유용합니다.
RAG를 사용한 질문 답변
이전 예에서는 쿼리를 사용하여 원하는 데이터를 얻었고 RAG는 해당 데이터를 의도한 출력으로 처리했습니다.
그러나 RAG 기능을 질문 답변 도구로 전환할 수 있습니다. 이를 LangChain 프레임워크와 결합하여 달성할 수 있습니다.
먼저 필요한 패키지를 설치해 보겠습니다.
pip install langchain
pip install langchain_community
pip install langchain_openai
그런 다음 패키지를 가져오고 RAG를 사용하여 QA를 수행하는 데 필요한 변수를 시작해 보겠습니다.
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Weaviate
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_openai.llms.base import OpenAI
llm = OpenAI(openai_api_key = openai_api_key, model_name = 'gpt-3.5-turbo-instruct', temperature = 1)
embeddings = OpenAIEmbeddings(openai_api_key = openai_api_key )
client = weaviate.Client(
url=cluster_url, auth_client_secret=weaviate.AuthApiKey(wcs_api_key)
)
위 코드에서는 텍스트 생성, 임베딩 모델 및 Weaviate 클라이언트 연결을 위한 LLM을 설정했습니다.
다음으로 벡터 데이터베이스에 대한 Weaviate 연결을 설정합니다.
weaviate_vectorstore = Weaviate(client=client, index_name='BookCollection', text_key='intro',by_text = False, embedding=embeddings)
retriever = weaviate_vectorstore.as_retriever()
위 코드에서 메시지가 표시되면 '소개' 기능을 검색하는 RAG 도구로 Weaviate Database BookCollection을 만듭니다.
그런 다음 아래 코드를 사용하여 LangChain에서 질문 응답 체인을 생성합니다.
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever = retriever
)
이제 모든 것이 준비되었습니다. 다음 코드 예제를 사용하여 RAG로 QA를 시도해 보겠습니다.
response = qa_chain.invoke(
"Who is the writer who write about love between two goldfish?")
print(response)
결과는 아래 텍스트에 나와 있습니다.
{'query': 'Who is the writer who write about love between two goldfish?', 'result': ' The writer is Grace Chua.'}
벡터 데이터베이스를 모든 텍스트 데이터를 저장하는 장소로 사용하면 RAG를 구현하여 LangChain으로 QA를 수행할 수 있습니다. 얼마나 깔끔합니까?
벡터 데이터베이스는 벡터 데이터를 저장, 색인화, 쿼리하도록 설계된 특수 스토리지 솔루션입니다. 텍스트 데이터를 저장하는 데 자주 사용되며 LLM(대형 언어 모델)과 함께 구현됩니다. 이 기사에서는 의미 체계 검색, RAG(Retrieval-Augmented Generation) 및 RAG를 사용한 질문 응답과 같은 사용 사례 예시를 포함하여 Vector Database Weaviate의 실습 설정을 시도합니다.
코넬리우스 유다 위자야 데이터 과학 보조 관리자이자 데이터 작성자입니다. Allianz Indonesia에서 풀타임으로 일하는 동안 그는 소셜 미디어와 글쓰기 미디어를 통해 Python과 데이터 팁을 공유하는 것을 좋아합니다. Cornellius는 다양한 AI 및 기계 학습 주제에 대해 글을 씁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/vector-databases-in-ai-and-llm-use-cases?utm_source=rss&utm_medium=rss&utm_campaign=vector-databases-in-ai-and-llm-use-cases
- :있다
- :이다
- :아니
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 19
- 7
- 8
- 8 위
- 9
- a
- 소개
- IT에 대해
- 위의
- ACCESS
- 달성
- 행동
- 행위
- 실제로
- 후
- 다시
- 나이
- AI
- 목표
- All
- 알리안츠
- 또한
- an
- 유사체
- 및
- 답변
- 응답
- 어떤
- API를
- 어플리케이션
- 적용된
- 아라비아 사람
- 궁수
- 있군요
- 배열
- 기사
- AS
- 산
- 조수
- At
- 청중
- 증강 된
- 인증
- 인증
- 기지
- 기반으로
- BE
- 가
- 된
- 전에
- 이하
- 사이에
- 도서
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- 전화
- 라는
- CAN
- 능력
- 매혹적인
- 가지 경우
- 수세기
- 체인
- 쇠사슬
- 특성
- 어린이
- 수업
- 수업
- 클라이언트
- 면밀히
- 클라우드
- 클라우드 서비스
- 클러스터
- 암호
- 모은
- 수집
- 컬렉션
- 열
- 결합
- 오는
- 결합
- 연결하기
- 연결
- 구성
- 끊임없이
- 함유량
- 문맥
- 좌표의
- 수
- 만들
- 이상한
- 데이터
- 데이터 과학
- 데이터베이스
- 데이터베이스
- 일
- 거래
- 한정된
- 탐구하다
- 설명
- 설계
- DID
- 치수
- 곧장
- 토론
- do
- 도커
- 하기
- 말라
- ...동안
- 역학
- 마다
- 쉽게
- 동쪽
- 쉽게
- 임베디드
- 임베딩
- 가능
- 충분히
- 특히
- 세우다
- 에테르 (ETH)
- 예
- 기대
- 탐험
- 확장자
- 직면
- 그릇된
- 가족
- 특색
- 감정
- 를
- Find
- 먼저,
- 수행원
- 다음
- 럭셔리
- 형태
- 뼈대
- 무료
- 자주
- 에
- 쌍둥이 자리
- 일반적으로
- 생성
- 생성
- 세대
- 생성적인
- 제너레이티브 AI
- 얻을
- 소녀
- 주어진
- 가는
- 골든
- 은혜
- 손 -에
- 있다
- he
- 듣다
- 도움
- 그녀의
- 방법
- 그러나
- HTTP
- HTTPS
- i
- if
- 영상
- 구현
- 이행
- 구현
- import
- in
- 포함
- 색인
- 인도네시아 공화국
- 처음에는
- 시작
- 입력
- 설치
- 인스턴스
- 를 받아야 하는 미국 여행자
- 예정된
- 으로
- 개요
- 포함
- 이슬람교의
- IT
- JSON
- 다만
- 너 겟츠
- 키
- 알아
- 언어
- 넓은
- 배우기
- 휴가
- 처럼
- 링크드인
- llm
- 보기
- 같이
- 애정
- loves
- 기계
- 기계 학습
- 확인
- 매니저
- 수학의
- 의미
- 미디어
- 회원
- 방법
- 중간
- 중동
- 수도
- 모델
- 모델
- 현대
- 모듈
- 배우기
- 절대로 필요한 것
- name
- 코
- 산뜻한
- 필요한
- 필요
- 네트워크
- 신경
- 신경망
- 다음 것
- 아니
- 없음
- 노트
- 지금
- 번호
- 수치의
- 대상
- of
- 자주
- 이전
- on
- ONE
- 만
- 오픈 소스
- OpenAI
- 최적화
- or
- OS
- 우리의
- 아웃
- 출력
- 출력
- 위에
- 자신의
- 패키지
- 팬더
- 부품
- 지불
- 결제 방법
- 수행
- 실행할 수 있는
- 장소
- 플랫폼
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 연극
- 시인
- 전철기
- 가난한
- 인기
- 위치
- 게시하다
- 너무 이른
- 이전에
- 방법
- 처리
- 제품
- 현저한
- 제공
- 제공
- 제공
- 공개
- Python
- 질문 게시판
- 질문
- 문제
- 조각
- 차라리
- 살갗이 벗어 진
- 원시 데이터
- 읽기
- 준비
- 최근
- 기록
- 반영
- 회원가입
- 등록
- 관련
- 관련된
- 의지
- 먼
- 대표
- 대표
- 대표
- 요청
- 필요
- 응답
- 책임
- 결과
- 결과
- 검색
- 부활
- 행
- 달리기
- s
- 같은
- 모래 상자
- 확장성
- 과학
- 검색
- 수색
- 참조
- 본
- 고르다
- 시맨틱
- 문장
- 봉사하다
- 서비스
- 서비스
- 세트
- 설치
- 공유
- 그녀
- 짧은
- 영상을
- 표시
- 단순, 간단, 편리
- 간단
- 시뮬레이션하다
- 언니
- 자매
- So
- 사회적
- 소셜 미디어
- 사회적
- 혼자서
- 해결책
- 일부
- 스페이스 버튼
- 전문
- 구체적인
- 스타트
- 아직도
- 저장
- 저장
- 저장
- 이야기
- 저장
- 이야기
- 물건
- 성공적으로
- 이러한
- 테이블
- 받아
- 이야기
- 이야기
- 테크니컬
- 조건
- 본문
- 텍스트 생성
- 보다
- 감사
- 그
- XNUMXD덴탈의
- 그들의
- 그들
- 테마
- 그때
- Bowman의
- 그들
- 일
- 이
- 생각을 자극하는
- 천
- 도움말
- Title
- 에
- 함께
- 이야기
- 수단
- 상단
- 화제
- 이상의 주제
- 전통적인
- 변환
- 변환
- 치료
- 시도
- 회전
- 두
- ui
- 이해
- 유일한
- URL
- 사용
- 익숙한
- 유용
- 사용자
- 사용
- 사용
- 보통
- 이용
- 이용하다
- 변수
- 변수
- 종류
- 벡터
- 벡터
- 를 통해
- 필요
- 원
- 방법..
- we
- 잘
- 뭐
- 언제
- 어느
- 동안
- 누구
- 의지
- 과
- 이내
- 없이
- 여자
- 말
- 작업
- 일하는
- 겠지
- 쓰다
- 작가
- 쓰기
- 쓴
- 년
- 당신
- 젊은
- 최연소자
- 너의
- 제퍼 넷