Introductie
Op het gebied van AI zijn er twee verschillende uitdagingen aan het licht gekomen: het inzetten van grote modellen in cloudomgevingen, het maken van formidabele rekenkosten die de schaalbaarheid en winstgevendheid belemmeren, en het accommoderen van edge-apparaten met beperkte middelen die moeite hebben om complexe modellen te ondersteunen. De rode draad onder deze uitdagingen is de noodzaak om de modelgrootte te verkleinen zonder de nauwkeurigheid in gevaar te brengen. Modelkwantisering, een populaire techniek, biedt een mogelijke oplossing, maar roept zorgen op over mogelijke compromissen op het gebied van nauwkeurigheid.

Kwantiseringsbewuste training komt naar voren als een overtuigend antwoord. Het integreert kwantisering naadloos in het modeltrainingsproces, waardoor aanzienlijke verkleiningen van de modelgrootte mogelijk zijn, soms met twee tot vier keer of meer, terwijl de kritische nauwkeurigheid behouden blijft. Dit artikel gaat diep in op kwantisering, waarbij kwantisering na de training (PTQ) en kwantiseringsbewuste training (QAT) worden vergeleken. Bovendien bieden we praktische inzichten, die aantonen hoe beide methoden effectief kunnen worden geïmplementeerd met behulp van SuperGradients, een open-source trainingsbibliotheek ontwikkeld door Deci.
Daarnaast onderzoeken we de optimalisatie van Convolutional Neural Networks (CNN's) voor mobiele en embedded platforms, waarmee de unieke uitdagingen van omvang en computervereisten worden aangepakt. We richten ons op kwantisering en onderzoeken de rol van getalrepresentatie bij het optimaliseren van modellen voor mobiele en ingebedde platforms.
leerdoelen
- Begrijp het concept van modelkwantisering in AI.
- Leer meer over typische kwantiseringsniveaus en hun afwegingen.
- Maak onderscheid tussen Quantization-Aware Training (QAT) en Post-training Quantization (PTQ).
- Ontdek de voordelen van modelkwantisering, inclusief geheugenefficiëntie en energiebesparing.
- Ontdek hoe modelkwantisering een bredere implementatie van AI-modellen mogelijk maakt.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Inzicht in de noodzaak van modelkwantisering
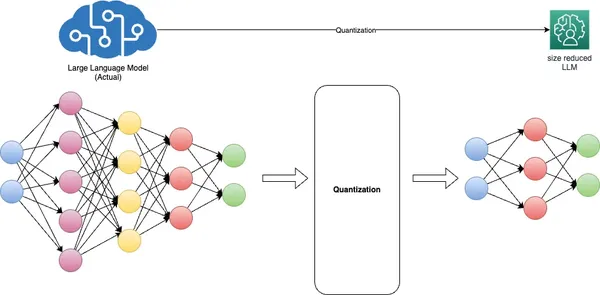
Modelkwantisering, een fundamentele techniek in deep learning, heeft tot doel kritische uitdagingen aan te pakken die verband houden met modelgrootte, inferentiesnelheid en geheugenefficiëntie. Dit wordt bereikt door modelgewichten om te zetten van uiterst nauwkeurige drijvende-komma-representaties, doorgaans 32-bits (FP32), naar formaten met drijvende komma (FP) of gehele getallen (INT), zoals 16-bits of 8-bits. .
De voordelen van kwantisering zijn tweeledig. Ten eerste verkleint het de geheugenvoetafdruk van het model aanzienlijk en verbetert het de inferentiesnelheid zonder substantiële verslechtering van de nauwkeurigheid te veroorzaken. Ten tweede optimaliseert het de modelprestaties door de vereisten voor geheugenbandbreedte te verminderen en het cachegebruik te verbeteren.
INT8-representatie wordt in de context van diepe neurale netwerken vaak ‘gekwantiseerd’ genoemd, maar andere formaten zoals UINT8 en INT16 worden ook gebruikt, afhankelijk van de hardware-architectuur. Verschillende modellen vereisen verschillende kwantiseringsbenaderingen, waarbij vaak voorkennis en nauwgezette afstemming nodig zijn om de nauwkeurigheid en de verkleining van de modelgrootte in evenwicht te brengen.
Kwantisering brengt uitdagingen met zich mee, vooral bij integer-formaten met lage precisie, zoals INT8, vanwege hun beperkte dynamische bereik. Het samenpersen van het uitgebreide dynamische bereik van FP32 in slechts 255 waarden van INT8 kan tot nauwkeurigheidsverlies leiden. Om deze uitdaging het hoofd te bieden, worden door schaling per kanaal of per laag de schaal- en nulpuntwaarden van gewichts- en activeringstensoren aangepast zodat ze beter bij het gekwantiseerde formaat passen.
Bovendien simuleert kwantiseringsbewuste training het kwantiseringsproces tijdens modeltraining, waardoor het model zich op een elegante manier kan aanpassen aan lagere precisie. De squeeze, of schatting van het bereik, is een essentieel aspect van dit proces, dat wordt bereikt door middel van kalibratie.
In wezen is modelkwantisering onmisbaar voor het inzetten van efficiënte AI-modellen, waarbij een delicaat evenwicht wordt gevonden tussen nauwkeurigheid en hulpbronnenefficiëntie, vooral op edge-apparaten met beperkte rekenbronnen.
Technieken voor modelkwantisering
Kwantiseringsniveau
Kwantisering converteert de zeer nauwkeurige drijvende-kommagewichten en activeringen van een model naar vaste-kommawaarden met lagere precisie. Het “kwantiseringsniveau” verwijst naar het aantal bits dat deze vaste puntwaarden vertegenwoordigt. Typische kwantiseringsniveaus zijn 8-bits, 16-bits en zelfs binaire (1-bits) kwantisering. Het kiezen van een geschikt kwantiseringsniveau hangt af van de afweging tussen modelnauwkeurigheid en geheugen-, opslag- en rekenefficiëntie.
Kwantiseringsbewuste training (QAT) in detail
Quantization-aware training (QAT) is een techniek die wordt gebruikt tijdens de training van neurale netwerken om ze voor te bereiden op kwantisering. Het helpt het model effectief te leren werken met gegevens met een lagere nauwkeurigheid. Zo werkt QAT:
- Tijdens QAT wordt het model getraind met kwantiseringsbeperkingen. Deze beperkingen omvatten het simuleren van gegevenstypen met een lagere precisie (bijvoorbeeld 8-bit gehele getallen) tijdens voorwaartse en achterwaartse passages.
- Er wordt gebruik gemaakt van een kwantiseringsbewuste verliesfunctie, die rekening houdt met de kwantiseringsfout om afwijkingen van het gedrag van het model met volledige precisie te bestraffen.
- QAT helpt het model te leren omgaan met het door kwantisering veroorzaakte verlies aan precisie door de gewichten en activeringen dienovereenkomstig aan te passen.
Kwantisering na de training (PTQ) versus kwantiseringsbewuste training (QAT)
PTQ en QAT zijn twee verschillende benaderingen van modelkwantisering, elk met zijn voordelen en implicaties.
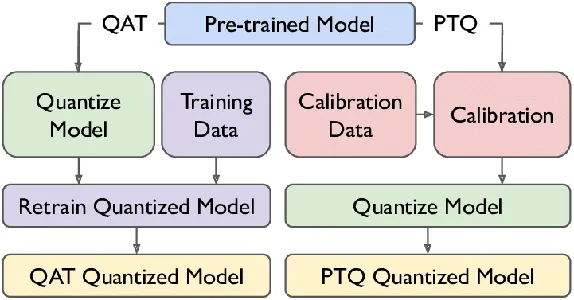
Kwantisering na de training (PTQ)
PTQ is een kwantiseringstechniek die wordt toegepast nadat een model een volledige training heeft ondergaan met standaardprecisie, meestal in drijvende-kommaweergave. In PTQ worden de gewichten en activeringen van het model gekwantiseerd in formaten met een lagere precisie, zoals 8-bit gehele getallen of 16-bit floats, om het geheugengebruik te verminderen en de inferentiesnelheid te verbeteren. Hoewel PTQ eenvoud en compatibiliteit biedt met reeds bestaande modellen, kan dit leiden tot een matig verlies aan nauwkeurigheid als gevolg van de conversie na de training.
Kwantiseringsbewuste training (QAT)
QAT daarentegen is een meer genuanceerde benadering van kwantisering. Het omvat het verfijnen van het PTQ-model met kwantisering in gedachten. Tijdens QAT wordt het kwantiseringsproces, dat schalen, knippen en afronden omvat, naadloos geïntegreerd in het trainingsproces. Hierdoor kan het model expliciet worden getraind om zijn nauwkeurigheid te behouden, zelfs na kwantisering. QAT optimaliseert de modelgewichten om de kwantisering van gevolgtrekkingstijd nauwkeurig te emuleren. Tijdens de training maakt het gebruik van ‘nep’-kwantiseringsmodules om het gedrag van de test- of inferentiefase na te bootsen, waarbij gewichten worden afgerond of vastgeklemd tot representaties met lage precisie. Deze aanpak leidt tot een hogere nauwkeurigheid tijdens gevolgtrekkingen in de echte wereld, omdat het model vanaf het begin op de hoogte is van kwantisering.
Kwantiseringsalgoritmen
Er zijn verschillende algoritmen en methoden voor het kwantiseren van neurale netwerken. Enkele standaard kwantiseringstechnieken zijn onder meer:
- Gewicht kwantificering omvat het kwantiseren van de gewichten van het model naar waarden met een lagere precisie (bijvoorbeeld 8-bit gehele getallen). Gewichtskwantisering kan de geheugenvoetafdruk van het model aanzienlijk verkleinen.
- Activeringskwantisering: Naast het kwantiseren van gewichten kunnen activeringen worden gekwantiseerd tijdens gevolgtrekking. Dit vermindert de rekenvereisten en het geheugengebruik verder.
- Dynamische kwantisering: In plaats van een vaste kwantiseringsschaal te gebruiken, maakt dynamische kwantisering een dynamische schaling van kwantiseringsbereiken tijdens gevolgtrekking mogelijk, waardoor het verlies aan nauwkeurigheid wordt beperkt.
- Kwantiseringsbewuste training (QAT): Zoals eerder vermeld is QAT een trainingsmethode die kwantiseringsbeperkingen omvat en het model in staat stelt te leren werken met gegevens met een lagere precisie.
- Kwantisering met gemengde precisie: Deze techniek combineert verschillende precisiekwantiseringen voor gewichten en activeringen, waardoor nauwkeurigheid en efficiëntie worden geoptimaliseerd.
- Kwantisering na de training met kalibratie: Bij kwantisering na de training wordt kalibratie gebruikt om het kwantiseringsbereik van gewichten en activeringen te bepalen om het verlies aan nauwkeurigheid te minimaliseren.
Samenvattend hangt de keuze tussen kwantisering na de training en kwantiseringsbewuste training (QAT) af van de specifieke implementatiebehoeften en de balans tussen modelprestaties en efficiëntie. PTQ biedt een eenvoudigere benadering voor het verkleinen van de modelgrootte. Toch kan het nauwkeurigheidsverlies lijden als gevolg van de inherente mismatch tussen het oorspronkelijke model met volledige precisie en zijn gekwantiseerde tegenhanger. Aan de andere kant integreert QAT kwantiseringsbeperkingen rechtstreeks in het trainingsproces, waardoor het model vanaf het begin leert effectief te werken met gegevens met een lagere nauwkeurigheid.
Dit resulteert in een beter behoud van nauwkeurigheid en een fijnere controle over het kwantiseringsproces. Wanneer het handhaven van een hoge nauwkeurigheid van het grootste belang is, heeft QAT vaak de voorkeur. Het stelt deep learning-modellen in staat om het delicate evenwicht te vinden tussen optimale prestaties en efficiënt gebruik van hardwarebronnen. Het is met name geschikt voor inzet op apparaten met beperkte middelen waar de nauwkeurigheid niet in gevaar mag worden gebracht.
Voordelen van modelkwantisering
- Snellere gevolgtrekking: Gekwantiseerde modellen zijn sneller te implementeren en uit te voeren, waardoor ze ideaal zijn voor realtime toepassingen zoals stemherkenning, beeldverwerking en autonome voertuigen. Verminderde precisie zorgt voor snellere berekeningen, wat leidt tot een lagere latentie.
- Lagere implementatiekosten: Kleinere modelgroottes vertalen zich in verminderde opslag- en geheugenvereisten, waardoor de kosten van de implementatie van AI-oplossingen aanzienlijk worden verlaagd, vooral in cloudgebaseerde services waar opslag- en rekenkosten belangrijke overwegingen zijn.
- Verhoogde toegankelijkheid: Door kwantisering kan AI worden ingezet op apparaten met beperkte middelen, zoals smartphones, IoT-apparaten en edge computing-platforms. Dit breidt het bereik van AI uit naar een breder publiek en opent nieuwe mogelijkheden voor toepassingen in afgelegen of onderontwikkelde gebieden.
- Verbeterde privacy en beveiliging: Door de omvang van modellen te verkleinen, kan kwantisering de AI-verwerking op het apparaat vergemakkelijken, waardoor de noodzaak om gevoelige gegevens naar gecentraliseerde servers te sturen wordt verminderd. Dit verbetert de privacy en veiligheid door de blootstelling van gegevens aan externe bedreigingen te minimaliseren.
- Milieu-impact: Kleinere modelgroottes leiden tot een lager energieverbruik, waardoor datacenters en cloudinfrastructuur energiezuiniger worden. Dit helpt de milieueffecten van grootschalige AI-implementaties te verzachten.
- schaalbaarheid: Gekwantiseerde modellen zijn toegankelijker om te distribueren en in te zetten, waardoor AI-diensten efficiënt kunnen worden geschaald om tegemoet te komen aan de toenemende gebruikerseisen en het toenemende verkeer zonder aanzienlijke investeringen in de infrastructuur.
- Toepasbaar op: Gekwantiseerde modellen zijn vaak beter compatibel met een breder scala aan hardware, waardoor de inzet van AI-oplossingen op verschillende apparaten en platforms toegankelijker wordt.
- Realtime toepassingen: Door de kleinere modelgrootte en snellere gevolgtrekking zijn gekwantiseerde modellen geschikt voor realtime toepassingen zoals augmented reality, virtual reality en gaming, waarbij lage latentie cruciaal is voor een naadloze gebruikerservaring.
Deze voordelen samen maken modelkwantisering tot een essentiële techniek voor optimalisatie AI implementaties, waardoor zowel efficiëntie als toegankelijkheid voor een breed scala aan applicaties en apparaten wordt gegarandeerd.
Voorbeelden uit de echte wereld
- Gezondheidszorg: In de gezondheidszorgsector heeft modelkwantisering het mogelijk gemaakt om AI-aangedreven medische beeldvormingsoplossingen op edge-apparaten in te zetten. Draagbare echografiemachines en smartphone-apps maken nu gebruik van gekwantiseerde modellen voor het diagnosticeren van hartaandoeningen en het detecteren van tumoren. Dit vermindert de behoefte aan dure, gespecialiseerde apparatuur en stelt zorgprofessionals in staat tijdige en nauwkeurige diagnoses te stellen in afgelegen omgevingen of omgevingen met beperkte middelen.
- Autonome voertuigen: Gekwantiseerde modellen spelen een cruciale rol in autonome voertuigen, waar realtime besluitvorming absoluut noodzakelijk is. Zelfrijdende auto's kunnen efficiënt werken op ingebedde hardware door de omvang van deep learning-modellen voor perceptie- en controletaken te verkleinen. Dit verbetert de veiligheid, het reactievermogen en het vermogen om door complexe omgevingen te navigeren, waardoor autonoom rijden werkelijkheid wordt.
- Natuurlijke taalverwerking (NLP): Op het gebied van NLP hebben gekwantiseerde modellen de inzet van taalmodellen op slimme luidsprekers, chatbots en mobiele apparaten mogelijk gemaakt. Dit maakt real-time taalbegrip en -generatie mogelijk, waardoor stemassistenten en taalvertaalapps toegankelijker worden en beter kunnen reageren op vragen van gebruikers.
- Industriële automatie: Industriële automatisering maakt gebruik van gekwantiseerde modellen voor voorspellend onderhoud en kwaliteitscontrole. Edge-apparaten die zijn uitgerust met gekwantiseerde modellen kunnen de gezondheid van machines monitoren en defecten in realtime detecteren, waardoor de uitvaltijd wordt geminimaliseerd en de productie-efficiëntie in fabrieken wordt verbeterd.
- Detailhandel en e-commerce: Detailhandelaren gebruiken gekwantiseerde modellen voor voorraadbeheer en klantbetrokkenheid. Modellen voor realtime beeldherkenning die op camera's in de winkel worden ingezet, kunnen de beschikbaarheid van producten volgen en de winkelindeling optimaliseren. Op dezelfde manier bieden gekwantiseerde aanbevelingssystemen gepersonaliseerde winkelervaringen op e-commerceplatforms, waardoor de klanttevredenheid en de omzet worden verbeterd.
Deze praktijkvoorbeelden illustreren de veelzijdigheid en impact van modelkwantisering in verschillende sectoren, waardoor AI-oplossingen toegankelijker, efficiënter en kosteneffectiever worden.
Uitdagingen en overwegingen
Bij modelkwantisering bepalen verschillende cruciale uitdagingen en overwegingen het landschap van efficiënte AI-implementaties. Een fundamentele uitdaging ligt in het vinden van het delicate evenwicht tussen nauwkeurigheid en efficiëntie. Agressieve kwantisering kan weliswaar de hulpbronnenefficiëntie verbeteren, maar ook leiden tot aanzienlijk nauwkeurigheidsverlies, waardoor het absoluut noodzakelijk wordt om de kwantiseringsaanpak af te stemmen op de specifieke eisen van de toepassing.
Bovendien zijn niet alle AI-modellen even vatbaar voor kwantisering, waarbij de complexiteit van modellen een cruciale rol speelt in hun gevoeligheid voor nauwkeurigheidsverminderingen tijdens kwantisering. Dit vereist een zorgvuldige evaluatie of kwantisering past bij een bepaald model en gebruiksscenario. De keuze tussen kwantisering na de training (PTQ) en kwantiseringsbewuste training (QAT) is even cruciaal. Deze beslissing heeft een aanzienlijke invloed op de nauwkeurigheid, de complexiteit van het model en de ontwikkelingstijdlijnen, en onderstreept de noodzaak voor ontwikkelaars om goed geïnformeerde keuzes te maken die aansluiten bij de implementatievereisten van hun project en de beschikbare middelen. Deze overwegingen benadrukken gezamenlijk het belang van nauwgezette planning en beoordeling bij het implementeren van modelkwantisering, omdat ze rechtstreeks van invloed zijn op de ingewikkelde afwegingen tussen modelnauwkeurigheid en hulpbronnenefficiëntie in AI-toepassingen.
Nauwkeurigheidsafwegingen
- Een gedetailleerd onderzoek naar de afwegingen tussen modelnauwkeurigheid en kwantisering: In dit gedeelte wordt dieper ingegaan op de ingewikkelde balans tussen het handhaven van de modelnauwkeurigheid en het bereiken van hulpbronnenefficiëntie door middel van kwantisering. Het onderzoekt hoe agressieve kwantisering kan leiden tot nauwkeurigheidsverlies en de overwegingen die nodig zijn om weloverwogen beslissingen te nemen over het kwantiseringsniveau dat geschikt is voor specifieke toepassingen.
Kwantiseringsbewuste trainingsuitdagingen
- Veelvoorkomende uitdagingen bij het implementeren van QAT en strategieën om deze te overwinnen: We pakken de hindernissen aan die ontwikkelaars tegenkomen bij het integreren van kwantiseringsbewuste training (QAT) in het modeltrainingsproces. We bieden ook inzicht in strategieën en best practices om deze uitdagingen te overwinnen en een succesvolle QAT-implementatie te garanderen.
Hardwarebeperkingen
- Bespreken van de rol van hardwareversnellers bij de implementatie van gekwantiseerde modellen: in deze sectie wordt de rol onderzocht van hardwareversnellers, zoals GPU's, TPU's en speciale AI-hardware, bij de implementatie van gekwantiseerde modellen. Het benadrukt het belang van hardwarecompatibiliteit en -optimalisatie voor het bereiken van efficiënte en krachtige gevolgtrekkingen met gekwantiseerde modellen.
Realtime objectdetectie op een Raspberry Pi met Quantized MobileNetV2
1: Hardware-installatie

- Introduceer uw Raspberry Pi-model (bijvoorbeeld Raspberry Pi 4).
- Raspberry Pi-cameramodule (of USB-webcam voor oudere modellen)
- Stroomvoorziening
- MicroSD-kaart met Raspberry Pi OS
- HDMI-kabel, monitor, toetsenbord en muis (voor eerste installatie)
- Benadruk de noodzaak van het inzetten van een lichtgewicht model op de Raspberry Pi vanwege de beperkte middelen.
2: Software-installatie
- Stel de Raspberry Pi in met Raspberry Pi OS (voorheen Raspbian).
- Installeer Python en de vereiste bibliotheken:
sudo apt update
sudo apt install python3-pip
pip3 install opencv-python-headless
pip3 install opencv-python
pip3 install numpy
pip3 install tensorflow==2.73: Gegevensverzameling en voorverwerking
- Verzamel of open een dataset voor objectdetectie (bijvoorbeeld COCO-dataset).
- Het labelen van interessante objecten in afbeeldingen met behulp van tools zoals LabelImg.
- Annotaties converteren naar het vereiste formaat (bijvoorbeeld TFRecord) voor TensorFlow.
4: Importeer de benodigde bibliotheken
import argparse # For command-line argument parsing
import cv2 # OpenCV library for computer vision tasks
import imutils # Utility functions for working with images and video
import numpy as np # NumPy for numerical operations
import tensorflow as tf # TensorFlow for machine learning and deep learning5: Modelkwantisering
- Kwantificeer een vooraf getraind MobileNetV2-model met TensorFlow:
import tensorflow as tf # Load the pre-trained model
model = tf.keras.applications.MobileNetV2(weights='imagenet', input_shape=(224, 224, 3)) # Quantize the model
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quantized_model = converter.convert() # Save the quantized model
with open('quantized_mobilenetv2.tflite', 'wb') as f: f.write(tflite_quantized_model)Step 5: Deployment and Real-time Inference6: Parseren van argumenten
- “argparse” wordt gebruikt om opdrachtregelargumenten te ontleden. Hier is het geconfigureerd om het pad naar het op maat getrainde model, het labelsbestand en een betrouwbaarheidsdrempel te accepteren.
# Parse command-line arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True, help="path to your custom trained model")
ap.add_argument("-l", "--labels", required=True, help="path to your class labels file")
ap.add_argument("-c", "--confidence", type=float, default=0.2, help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
7: Model laden en label laden
- De code laadt het op maat getrainde objectdetectiemodel en klasselabels.
# Load your custom-trained model and labels
print("[INFO] loading model...")
model = tf.saved_model.load(args["model"]) # Load the custom-trained TensorFlow model
with open(args["labels"], "r") as f: CLASSES = f.read().strip().split("n") # Load class labels from a file
8: Initialisatie van videostreams
- Het stelt de videostream in, die frames van de standaardcamera vastlegt.
# Initialize video stream
print("[INFO] starting video stream...")
cap = cv2.VideoCapture(0) # Initialize the video stream (0 for the default camera)
fps = cv2.getTickFrequency()
start_time = cv2.getTickCount()
9: Realtime objectdetectielus
- De hoofdlus legt frames vast uit de videostream, voert objectdetectie uit met behulp van het aangepaste model en geeft de resultaten op het frame weer.
- Gedetecteerde objecten worden getekend als selectiekaders met labels en betrouwbaarheidsscores.
while True: # Read a frame from the video stream ret, frame = cap.read() frame = imutils.resize(frame, width=800) # Resize the frame for better processing speed # Perform object detection using the custom model detections = model(frame) # Loop over detected objects for detection in detections['detection_boxes']: # Extract bounding box coordinates startY, startX, endY, endX = detection[0], detection[1], detection[2], detection[3] # Draw bounding box and label on the frame label = CLASSES[0] # Replace with your class label logic confidence = 1.0 # Replace with your confidence score logic color = (0, 255, 0) # Green color for bounding box (you can change this) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2) text = "{}: {:.2f}%".format(label, confidence * 100) cv2.putText(frame, text, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # Display the frame with object detection results cv2.imshow("Custom Object Detection", frame) key = cv2.waitKey(1) & 0xFF if key == ord("q"): break # Break the loop if 'q' key is pressed # Clean up
cap.release() # Release the video stream
cv2.destroyAllWindows() # Close OpenCV windows
10: Prestatie-evaluatie
- Meet de gevolgtrekkingssnelheid en het gebruik van bronnen op de Raspberry Pi met behulp van tijd- en systeemmonitoringtools (htop).
- Bespreek eventuele afwegingen tussen nauwkeurigheid en efficiëntie die tijdens het project zijn waargenomen.
11: Conclusie en inzichten
- Vat de essentiële bevindingen samen en benadruk hoe modelkwantisering real-time objectdetectie mogelijk maakte op een apparaat met beperkte middelen zoals de Raspberry Pi.
- Benadruk de praktische bruikbaarheid en praktische toepassingen van dit project, zoals het inzetten van objectdetectie in beveiligingscamera's of robotica.
Door deze stappen te volgen en de meegeleverde Python-code te gebruiken, kunnen leerlingen een real-time objectdetectiesysteem op een Raspberry Pi bouwen, waarmee de voordelen van modelkwantisering voor efficiënte AI-toepassingen op edge-apparaten worden gedemonstreerd.
Conclusie
Modelkwantisering is een cruciale techniek die het landschap van AI-implementatie diepgaand beïnvloedt. Het maakt mobiele en edge-apparaten met beperkte middelen mogelijk door hen in staat te stellen AI-applicaties efficiënt uit te voeren en verbetert de schaalbaarheid en kosteneffectiviteit van cloudgebaseerde AI-diensten. De impact van kwantisering weerklinkt in het AI-ecosysteem, waardoor AI toegankelijker, responsiever en milieuvriendelijker wordt.
Bovendien sluit kwantisering aan bij opkomende AI-trends, zoals federatief leren en AI aan de rand, waardoor nieuwe grenzen voor innovatie worden geopend. Nu we getuige zijn van de voortdurende evolutie van AI, is modelkwantisering een essentieel instrument dat ervoor zorgt dat AI een breder publiek kan bereiken, realtime inzichten kan leveren en zich kan aanpassen aan de veranderende eisen van diverse industrieën. In dit dynamische landschap dient modelkwantisering als brug tussen de kracht van AI en de praktische toepasbaarheid ervan, waardoor een pad wordt gebaand naar efficiëntere, toegankelijkere en duurzamere AI-oplossingen.
Key Takeaways
- Modelkwantisering is van cruciaal belang voor de inzet van grote AI-modellen op apparaten met beperkte middelen.
- Kwantiseringsniveaus, zoals 8-bit of 16-bit, verkleinen de modelgrootte en verbeteren de efficiëntie.
- Quantization-Aware Training (QAT) presser Kwantisatie-bewuste training kwantificeert training tijdens de training.
- Post-training kwantisering (PTQ) vereenvoudigt maar kan de nauwkeurigheid verminderen, waardoor fijnafstemming nodig is.
- De keuze hangt af van specifieke implementatiebehoeften en de balans tussen nauwkeurigheid en efficiëntie, wat cruciaal is voor apparaten met beperkte middelen.
Veelgestelde Vragen / FAQ
A: Modelkwantisering in AI is een techniek waarbij de precisie van de gewichten en activeringen van een neuraal netwerkmodel wordt verminderd. Het converteert drijvende-kommawaarden met hoge precisie naar vaste-komma- of gehele getallenrepresentaties met lagere precisie, waardoor het model geheugenefficiënter wordt en sneller kan worden uitgevoerd.
A: Algemene kwantiseringsniveaus omvatten 8-bits, 16-bits en binaire (1-bits) kwantisering. De keuze van het kwantiseringsniveau hangt af van de balans tussen modelnauwkeurigheid en geheugen/opslag/rekenefficiëntie die vereist is voor een specifieke toepassing.
A: QAT neemt kwantiseringsbeperkingen op tijdens de training, waardoor het model zich kan aanpassen aan berekeningen met lagere precisie. PTQ daarentegen kwantiseert een vooraf getraind model na standaardtraining, waardoor mogelijk fijnafstemming nodig is om de verloren nauwkeurigheid terug te winnen.
A: Modelkwantisering biedt voordelen zoals een kleinere geheugenvoetafdruk, verbeterde inferentiesnelheid, energie-efficiëntie, bredere inzet op apparaten met beperkte middelen, kostenbesparingen en verbeterde privacy en beveiliging dankzij kleinere modelgroottes.
A: Het kiezen van QAT bij het behouden van de modelnauwkeurigheid is een prioriteit. QAT zorgt voor een beter behoud van nauwkeurigheid door kwantiseringsbeperkingen te integreren tijdens de training, waardoor het ideaal is wanneer nauwkeurigheid van het grootste belang is. PTQ is eenvoudiger, maar vereist mogelijk aanvullende verfijning om de nauwkeurigheid te herstellen. De keuze hangt af van specifieke implementatiebehoeften.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/11/model-quantization-for-large-scale-deployment/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 10
- 100
- 11
- 13
- 14
- 22
- 224
- 300
- a
- vermogen
- Over
- versnellers
- ACCEPTEREN
- toegang
- de toegankelijkheid
- beschikbaar
- accommoderen
- meegaand
- dienovereenkomstig
- nauwkeurigheid
- accuraat
- nauwkeurig
- bereikt
- het bereiken van
- over
- Activering
- activaties
- aanpassen
- Extra
- adres
- aanpakken
- het aanpassen van
- voordelen
- Na
- agressief
- AI
- AI-modellen
- AI-diensten
- AI Trends
- AI-powered
- wil
- algoritmen
- richten
- Lijnt uit
- Alles
- Het toestaan
- toestaat
- ook
- onder
- an
- analytics
- Analytics Vidhya
- en
- beantwoorden
- elke
- Aanvraag
- toepassingen
- toegepast
- nadering
- benaderingen
- passend
- apps
- APT
- architectuur
- ZIJN
- gebieden
- argument
- argumenten
- dit artikel
- AS
- gevraagd
- verschijning
- beoordeling
- assistenten
- At
- gehoor
- aangevuld
- Augmented Reality
- Automatisering
- autonoom
- autonome voertuigen
- beschikbaarheid
- Beschikbaar
- bewust
- Balance
- bandbreedte
- BE
- gedrag
- betekent
- BEST
- 'best practices'
- Betere
- tussen
- blogathon
- zowel
- Box camera's
- dozen
- Breken
- BRUG
- bredere
- bouw
- maar
- by
- kabel
- cache
- camera
- camera's
- CAN
- kan niet
- pet
- captures
- kaart
- voorzichtig
- auto's
- geval
- veroorzakend
- Centra
- gecentraliseerde
- uitdagen
- uitdagingen
- verandering
- chatbots
- keuze
- keuzes
- Kies
- het kiezen van
- klasse
- klassen
- schoon
- Sluiten
- Cloud
- cloud infrastructuur
- kokosnoot
- code
- Collectie
- collectief
- kleur
- combines
- Gemeen
- vergelijken
- verenigbaarheid
- verenigbaar
- dwingende
- complex
- ingewikkeldheid
- Aangetast
- afbreuk te doen aan
- berekening
- computationeel
- berekeningen
- Berekenen
- computer
- Computer visie
- computergebruik
- concept
- Zorgen
- conclusie
- voorwaarden
- vertrouwen
- geconfigureerd
- overwegingen
- beschouwt
- beperkingen
- consumptie
- verband
- voortgezet
- onder controle te houden
- Camper ombouw
- het omzetten van
- Kosten
- kostenbesparingen
- kostenefficient
- Kosten
- Tegenhanger
- kritisch
- cruciaal
- gewoonte
- klant
- Klantbinding
- Klanttevredenheid
- gegevens
- datacenters
- beslissing
- Besluitvorming
- beslissingen
- toegewijd aan
- deep
- diepe duik
- diepgaand leren
- diepe neurale netwerken
- Standaard
- leveren
- veeleisende
- eisen
- demonstrating
- Afhankelijk
- afhankelijk
- implementeren
- ingezet
- het inzetten
- inzet
- implementaties
- gedetailleerd
- opsporen
- gedetecteerd
- Opsporing
- Bepalen
- ontwikkelde
- ontwikkelaars
- Ontwikkeling
- apparaat
- systemen
- diagnoses
- diagnose stellen
- verschillen
- anders
- direct
- goeddunken
- Display
- displays
- onderscheiden
- verdelen
- duiken
- diversen
- doet
- uitvaltijd
- trekken
- getrokken
- aandrijving
- twee
- gedurende
- dynamisch
- e
- e-commerce
- e-commerce platforms
- elk
- Vroeger
- ecosysteem
- rand
- edge computing
- effectief
- doeltreffendheid
- doeltreffend
- efficiënt
- ingebed
- voorschijn
- opkomende
- benadrukken
- benadrukt
- telt
- machtigt
- ingeschakeld
- maakt
- waardoor
- allesomvattende
- ontmoeting
- energie-niveau
- energie-efficiëntie
- engagement
- verbeterde
- Verbetert
- verbeteren
- waarborgt
- zorgen
- milieu
- milieuvriendelijke
- milieuvriendelijk
- omgevingen
- even
- uitrusting
- uitgerust
- fout
- vooral
- essentie
- essentieel
- Ether (ETH)
- evalueren
- Zelfs
- Evolutie
- evoluerende
- onderzoek
- Onderzoeken
- voorbeelden
- uitvoeren
- expansieve
- duur
- ervaring
- Ervaringen
- uitdrukkelijk
- Verken
- verkent
- Media
- strekt
- extern
- extract
- geconfronteerd
- vergemakkelijken
- sneller
- veld-
- Dien in
- filter
- bevindingen
- in de eerste plaats
- geschikt
- vast
- Focus
- volgend
- Footprint
- Voor
- Smeden
- formaat
- formaten
- vroeger
- geducht
- Naar voren
- vier
- fps
- FRAME
- vriendelijk
- oppompen van
- Frontiers
- vol
- functie
- functies
- fundamenteel
- verder
- Bovendien
- gaming
- generatie
- gegeven
- GPU's
- Groen
- hand
- Hardware
- Hebben
- Gezondheid
- gezondheidszorg
- zorgsector
- Hart
- het helpen van
- helpt
- hier
- Hoge
- hoge performantie
- hoger
- scharnieren
- Hoe
- HTTPS
- Horden
- i
- ideaal
- if
- illustreren
- beeld
- Beeldherkenning
- IMAGEnet
- afbeeldingen
- Imaging
- Impact
- Effecten
- gebiedende wijs
- uitvoering
- geïmplementeerd
- uitvoering
- implicaties
- importeren
- belang
- verbeteren
- verbeterd
- verbetert
- het verbeteren van
- in
- in de winkel
- omvatten
- Inclusief
- omvat
- meer
- industrieel
- industriële automatisering
- industrieën
- beïnvloeden
- info
- op de hoogte
- Infrastructuur
- inherent
- eerste
- Innovatie
- inzichten
- installeren
- geïntegreerde
- integreert
- Integreren
- belang
- in
- ingewikkeld
- Introduceert
- inventaris
- Voorraadbeheer
- Investeringen
- gaat
- iot
- iot apparaten
- IT
- HAAR
- jpg
- voor slechts
- Keras
- sleutel
- kennis
- label
- labels
- Landschap
- taal
- Groot
- grootschalig
- Wachttijd
- leiden
- leidend
- Leads
- LEARN
- leerlingen
- leren
- leert
- Niveau
- niveaus
- hefbomen
- bibliotheken
- Bibliotheek
- ligt
- lichtgewicht
- als
- Beperkt
- laden
- het laden
- ladingen
- logica
- uit
- verloren
- Laag
- te verlagen
- het verlagen van
- machine
- machine learning
- machinerie
- Machines
- Hoofd
- behoud van
- onderhoud
- maken
- maken
- management
- productie
- max-width
- Mei..
- Media
- medisch
- medische beeldvorming
- Geheugen
- vermeld
- methode
- methoden
- nauwkeurig
- denken
- verkleinen
- minimaliseren
- minimum
- Verzachten
- Mobile
- mobiele toestellen
- model
- modellen
- matig
- module
- Modules
- monitor
- Grensverkeer
- meer
- efficiënter
- muis
- OP DEZE WEBSITE VIND JE
- noodzakelijk
- vereist
- Noodzaak
- behoeften
- netwerk
- netwerken
- Neural
- neuraal netwerk
- neurale netwerken
- New
- nlp
- nu
- aantal
- numeriek
- numpy
- object
- Objectdetectie
- objecten
- opgemerkt
- of
- Aanbod
- vaak
- ouder
- on
- open source
- OpenCV
- opening
- opent
- besturen
- Operations
- Kansen
- optimale
- optimalisatie
- Optimaliseer
- Optimaliseert
- optimaliseren
- or
- origineel
- OS
- Overige
- over
- Overwinnen
- eigendom
- Hoogste
- deel
- vooral
- passes
- pad
- perceptie
- uitvoeren
- prestatie
- presteert
- Gepersonaliseerde
- fase
- centraal
- planning
- planten
- platforms
- Plato
- Plato gegevensintelligentie
- PlatoData
- Spelen
- spelen
- Populair
- draagbare
- potentieel
- mogelijk
- energie
- PRAKTISCH
- praktijken
- precisie
- voorspellend
- bij voorkeur
- Voorbereiden
- het behoud van
- Voorafgaand
- prioriteit
- privacy
- Privacy en Beveiliging
- waarschijnlijkheid
- verwerking
- Product
- productie
- professionals
- winstgevendheid
- diep
- project
- projecten
- zorgen voor
- mits
- gepubliceerde
- Python
- kwaliteit
- kwantificeert
- queries
- sneller
- R
- verhoogt
- reeks
- ranges
- Framboos
- Raspberry Pi
- bereiken
- Lees
- echte wereld
- real-time
- Realiteit
- erkenning
- Aanbeveling
- Herstellen
- verminderen
- Gereduceerd
- vermindert
- vermindering
- reductie
- reducties
- verwezen
- verwijst
- herwinnen
- met betrekking tot
- verwant
- los
- vanop
- vervangen
- vertegenwoordiging
- vertegenwoordigen
- vereisen
- nodig
- Voorwaarden
- hulpbron
- Resources
- responsive
- resultaat
- Resultaten
- verkooppunten
- behouden
- behoud
- robotica
- Rol
- ronding
- lopen
- Veiligheid
- verkoop
- tevredenheid
- Bespaar
- Bespaar geld
- Schaalbaarheid
- Scale
- scaling
- Wetenschap
- partituur
- scores
- naadloos
- naadloos
- sectie
- sector
- veiligheid
- zelfrijdende
- sturen
- gevoelig
- Gevoeligheid
- Servers
- bedient
- Diensten
- Sets
- settings
- setup
- verscheidene
- Vorm
- Winkelen
- moet
- getoond
- betekenis
- aanzienlijke
- aanzienlijk
- evenzo
- eenvoud
- simuleert
- Maat
- maten
- kleinere
- slim
- Slimme luidsprekers
- smartphone
- smartphones
- Software
- oplossing
- Oplossingen
- sommige
- soms
- speakers
- gespecialiseerde
- specifiek
- snelheid
- Persen
- standaard
- staat
- Start
- Stappen
- Still
- mediaopslag
- shop
- eenvoudig
- strategieën
- stream
- slaan
- Worstelen
- wezenlijk
- geslaagd
- dergelijk
- sudo
- geschikt
- past
- OVERZICHT
- ondersteuning
- duurzaam
- system
- Systems
- taken
- techniek
- technieken
- tensorflow
- Testen
- tekst
- dat
- De
- Het landschap
- hun
- Ze
- Deze
- ze
- dit
- bedreigingen
- drempel
- Door
- niet de tijd of
- tijdlijnen
- actuele
- keer
- naar
- tools
- tools
- in de richting van
- spoor
- verkeer
- getraind
- Trainingen
- vertalen
- Vertaling
- Trends
- waar
- tumoren
- twee
- types
- typisch
- typisch
- ultrageluid
- ondergaan
- begrip
- unieke
- bijwerken
- Gebruik
- usb
- .
- use case
- gebruikt
- Gebruiker
- Gebruikerservaring
- gebruik
- utility
- gebruik maken van
- gebruikt
- Values
- divers
- Voertuigen
- veelzijdigheid
- Video
- Virtueel
- Virtuele realiteit
- visie
- vitaal
- Stem
- spraakherkenning
- vs
- was
- we
- webcam
- webp
- gewicht
- Wat
- Wat is
- wanneer
- of
- welke
- en
- breed
- Grote range
- ruiten
- Met
- zonder
- Getuige
- werkzaam
- Bedrijven
- u
- Your
- zephyrnet