Amazon Sage Maker biedt een aantal opties voor gebruikers die op zoek zijn naar een oplossing voor het hosten van hun machine learning (ML)-modellen. Van deze opties is een van de belangrijkste functies die SageMaker biedt realtime gevolgtrekking. Werkbelastingen voor real-time inferentie kunnen verschillende niveaus van vereisten en Service Level Agreements (SLA's) hebben in termen van latentie en doorvoer. Ongeacht de gebruikssituatie biedt SageMaker een aantal opties waarmee u de juiste balans tussen kosten en prestaties kunt vinden om aan uw bedrijfsdoelstellingen te voldoen.
Er zijn veel factoren waarmee u rekening moet houden bij het kiezen van de juiste optie voor realtime inferentie voor uw bedrijf. Uw bedrijf heeft bijvoorbeeld mogelijk een model dat moet voldoen aan de strengste SLA's voor latentie en doorvoer met zeer voorspelbare prestaties. Voor dat gebruik biedt SageMaker SageMaker-eindpunten met één model (SME's), waarmee u één ML-model tegen een logisch eindpunt kunt implementeren. Voor andere gebruiksscenario's kunt u ervoor kiezen om de kosten en prestaties te beheren met behulp van SageMaker-eindpunten voor meerdere modellen (MME's), waarmee u meerdere modellen kunt opgeven om achter een logisch eindpunt te hosten. Ongeacht de optie die u kiest, SageMaker-eindpunten bieden een schaalbaar mechanisme voor zelfs de meest veeleisende zakelijke gebruikers, terwijl ze waarde bieden in een overvloed aan functies, waaronder schaduw varianten, automatisch schalen, en native integratie met Amazon Cloud Watch (voor meer informatie, zie CloudWatch-statistieken voor implementaties van meerdere modellen van eindpunten).
Eén optie die wordt ondersteund door SageMaker-eindpunten met één en meerdere modellen is NVIDIA Triton Inference-server. Triton ondersteunt verschillende backends als motoren ter ondersteuning van het uitvoeren en aanbieden van verschillende ML-modellen voor gevolgtrekking. Voor elke Triton-implementatie is het van cruciaal belang om te weten hoe het backend-gedrag uw werklast beïnvloedt en wat u kunt verwachten, zodat u succesvol kunt zijn. In dit bericht helpen we u de Python-backend te begrijpen die door Triton op SageMaker wordt ondersteund, zodat u een weloverwogen beslissing kunt nemen over uw workloads en geweldige resultaten kunt behalen.
SageMaker levert Triton via het MKB en MME's
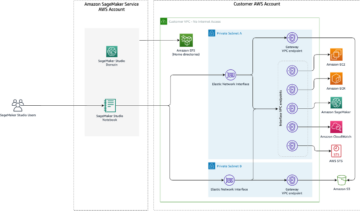
De Python-backend is beschikbaar via SageMaker, waarmee u kunt implementeren zowel single en multi-model eindpunten met NVIDIA Triton Inference Server. Triton ondersteunt instantietypen die GPU's, CPU's en AWS Inferentie chips, waarmee u de prestaties voor uw werklasten kunt maximaliseren. Het volgende diagram illustreert de NVIDIA Triton Inference Server-architectuur.
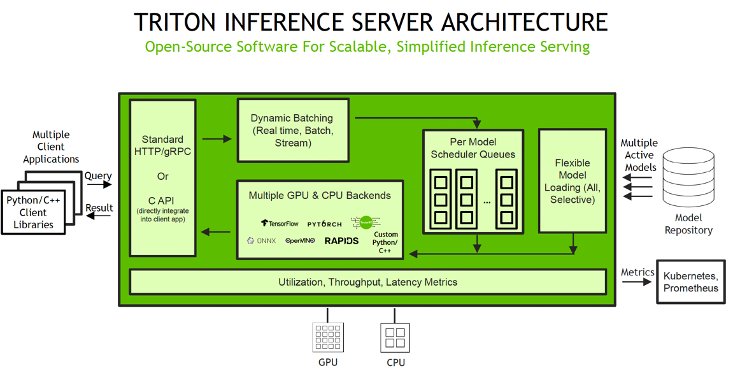
Inferentieverzoeken komen via beide bij de server aan HTTP / REST of door de C-API en worden vervolgens doorgestuurd naar de juiste planner per model. Triton-werktuigen meerdere plannings- en batchalgoritmen die per model kunnen worden geconfigureerd en kunnen helpen bij het afstemmen van de prestaties. De planner van elk model voert optioneel een batchverwerking van gevolgtrekkingsverzoeken uit en geeft de verzoeken vervolgens door aan de backend overeenkomend met het modeltype. De backend van het raamwerk voert gevolgtrekkingen uit met behulp van de invoer in de batchaanvragen om de gevraagde uitvoer te produceren. De uitvoer wordt vervolgens geformatteerd en geretourneerd in het antwoord. De model opslagplaats is een objectgebaseerde opslagplaats van de modellen aangedreven door Amazon eenvoudige opslagservice (Amazon S3) die Triton beschikbaar zal stellen voor gevolgtrekking.
Voor MME's zorgt SageMaker voor de verkeersvorming naar het eindpunt en onderhoudt optimale modelkopieën op GPU-instanties voor de beste prijs-kwaliteitverhouding. Het blijft verkeer routeren naar de instantie waar het model wordt geladen. Als de instancebronnen de capaciteit bereiken vanwege een hoog geheugengebruik, verwijdert SageMaker de minst populaire modellen uit de container om bronnen vrij te maken om vaker gebruikte modellen te laden. SageMaker MME's bieden mogelijkheden voor het tegelijkertijd uitvoeren van meerdere deep learning- of ML-modellen op de GPU met Triton Inference Server, die is uitgebreid om de MME API-contract. MME's maken het mogelijk om GPU-instanties achter een eindpunt over meerdere modellen te delen en modellen dynamisch te laden en te ontladen op basis van het binnenkomende verkeer. Hiermee kunt u eenvoudig een optimale prijs-prestatieverhouding realiseren.
Wanneer een SageMaker MME een HTTP-aanroepverzoek ontvangt voor een bepaald model met behulp van TargetModel in het verzoek, samen met de payload, wordt verkeer naar de juiste instantie achter het eindpunt geleid waar het doelmodel wordt geladen. SageMaker verzorgt het modelbeheer achter het endpoint. Het downloadt dynamisch modellen van Amazon S3 naar het opslagvolume van de instantie als het aangeroepen model niet beschikbaar is op het opslagvolume van de instantie. Vervolgens laadt SageMaker het model in het geheugen van de NVIDIA Triton-container op een GPU-versnelde instantie en dient het gevolgtrekkingsverzoek uit. De GPU-kern wordt gedeeld door alle modellen in een instantie. Zie voor meer informatie over SageMaker MME's op GPU's Voer meerdere deep learning-modellen uit op GPU met Amazon SageMaker multi-model endpoints.
SageMaker MME's kunnen horizontaal schalen met behulp van een automatisch schalingsbeleid en extra GPU-rekeninstanties leveren op basis van gespecificeerde statistieken. Bij het configureren van uw automatisch schalende groepen voor SageMaker-eindpunten, kunt u overwegen SageMakerVariantInvocationsPerInstance als het primaire criterium om de schaalkenmerken van uw automatische schaalgroep te bepalen. Afhankelijk van of uw modellen op GPU of CPU draaien, kunt u bovendien overwegen om CPUUtilization or GPUUtilization als aanvullende criteria. Houd er rekening mee dat het voor eindpunten met één model, omdat de geïmplementeerde modellen allemaal hetzelfde zijn, vrij eenvoudig is om het juiste beleid in te stellen om aan uw SLA's te voldoen. Voor eindpunten met meerdere modellen raden we aan vergelijkbare modellen achter een bepaald eindpunt te implementeren om stabielere, voorspelbare prestaties te verkrijgen. In gebruiksscenario's waarbij modellen van verschillende groottes en vereisten worden gebruikt, wilt u deze werklasten mogelijk verdelen over meerdere eindpunten met meerdere modellen of enige tijd besteden aan het verfijnen van uw groepsbeleid voor automatisch schalen om de beste balans tussen kosten en prestaties te verkrijgen.
Python-backend-runtime-architectuur
Zoals de naam al doet vermoeden, is de Python-backend bedoeld voor het uitvoeren van modellen die zijn geschreven en uitgevoerd in de Python-taal. Verschillende gebruiksscenario's vallen in deze categorie, zoals voor- of nabewerkingsstappen die een modellenensemble samenstellen. In andere gevallen kan de Python-backend worden gebruikt als wrapper om een op Python gebaseerd model of raamwerk aan te roepen. Verderop in dit bericht laten we een voorbeeld zien van hoe u de Python-backend kunt gebruiken om een PyTorch T5-model aan te roepen. Dit is misschien niet altijd de meest performante optie, maar het toont de flexibiliteit die de Python-backend biedt.
De Python-backend creëert een runtime-omgeving die Python-processen creëert met behulp van de CPU en het geheugen van de host. Je kunt nog steeds GPU-versnelling bereiken als deze wordt blootgesteld door een Python-front-end van het raamwerk dat de gevolgtrekking uitvoert. Er vindt geen extra GPU-versnelling plaats door de Python-backend zelf te gebruiken, maar er mogen geen compatibiliteitsfouten optreden voor welk Python-proces dan ook.
Op SageMaker wijst de standaard Triton Python-backend 16 MB toe, en groeit slechts met 1 MB. U kunt dit echter wijzigen door de SageMaker-omgevingsvariabelen in te stellen SAGEMAKER_TRITON_SHM_DEFAULT_BYTE_SIZE en SAGEMAKER_TRITON_SHM_GROWTH_BYTE_SIZE. Deze variabelen zijn belangrijk omdat de Python-backend via gedeeld geheugen tensoren zal uitwisselen.
Het volgende diagram toont de runtime-architectuur van de ensembleplanner, zodat u de geheugengebieden kunt verfijnen, inclusief CPU-adresseerbaar gedeeld geheugen, die worden gebruikt voor communicatie tussen processen tussen C++ en het Python-proces voor het uitwisselen van tensoren (invoer/uitvoer).
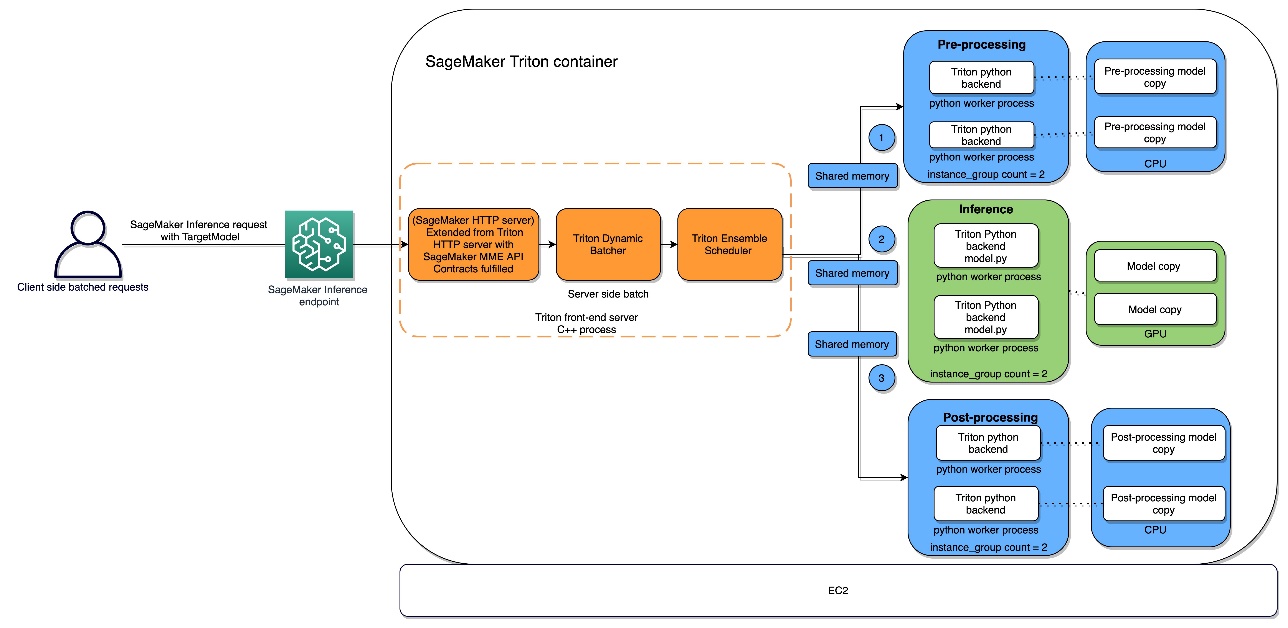
U kunt het resourcegebruik volgen met behulp van CloudWatch, dat een native integratie heeft met SageMaker.
Om aan de slag te gaan met de Python-backend, moet je een Python-bestand maken met een structuur die lijkt op de volgende code, die de structuur dicteert en ook de interactie met parameters en retourwaarden. Let op het punt in de levenscyclus waarop de methoden worden aangeroepen.
Door gebruik te maken van de model.py Met methoden kunt u de verantwoordelijkheid op u nemen om modellen op een specifiek apparaat (CPU of GPU) te laden door de code in het model.py expliciet indienen. Hoewel u met andere backends die Triton biedt, een KIND attribuut in het config.pbtxt bestand om te bepalen of de backend op CPU of GPU draait, is niet van toepassing op de Python-backend omdat het model in het betreffende apparaat wordt geladen, afhankelijk van de code die erin is geschreven model.py, zoals .to(device) in fakkel. Het is belangrijk op te merken dat als u expliciet artefacten in het geheugen laadt of tijdelijke bestanden maakt, u uw bronnen terugwint door op te ruimen, wat meestal gebeurt in de finalize methode. Anders kunt u ongewenste situaties ervaren, zoals geheugenlekken.
SageMaker-notebook-walkthrough
Met de NVIDIA Triton containerimage op SageMaker, kunt u nu de Python-backend van Triton gebruiken, waarmee u uw modellogica in Python kunt schrijven. U kunt deze backend bijvoorbeeld gebruiken om voor- en nabewerkingscode uit te voeren die in Python is geschreven, of om rechtstreeks een PyTorch Python-script uit te voeren (in plaats van dit eerst naar TorchScript te converteren en vervolgens de PyTorch-backend te gebruiken). De python_backend GitHub-repository bevat de documentatie en broncode voor de backend.
In dit gedeelte leiden we u door de voorbeeld notebook, die laat zien hoe u NVIDIA Triton Inference Server op een Amazon SageMaker MME met de GPU-functie kunt gebruiken om een T5 NLP-model voor vertaling te implementeren.
Stel de omgeving in
We beginnen met het opzetten van de gewenste omgeving. We installeren de afhankelijkheden die nodig zijn om onze modelpijplijn te verpakken en inferenties uit te voeren met behulp van Triton Inference Server. We definiëren ook de AWS Identiteits- en toegangsbeheer (IAM) rol die SageMaker toegang geeft tot de modelartefacten en de NVIDIA Triton Amazon Elastic Container-register (Amazon ECR) afbeelding. U kunt het volgende codevoorbeeld gebruiken om de vooraf gemaakte Triton ECR-image op te halen:
Genereer modelartefacten
In dit voorbeeld hosten we een vooraf getrainde T5-klein knuffelgezicht PyTorch-model met behulp van Triton Python-backend. Hier hebben we het Python-script model.py, dat alle logica implementeert om het T5-model te initialiseren en gevolgtrekkingen uit te voeren voor de vertaaltaak. Er zijn drie hoofdfuncties in het script:
- initialiseren – De initialisatiefunctie wordt eenmalig aangeroepen wanneer het model wordt geladen. Implementeren
initializeis optioneel.initializeHiermee kunt u alle noodzakelijke initialisaties uitvoeren voordat u het model uitvoert. Met deze functie kan het model elke status initialiseren die aan dit model is gekoppeld. - uitvoeren - The
executefunctie wordt aangeroepen wanneer een deductieverzoek wordt gedaan. Elk Python-model moet deexecutefunctie. In deexecutefunctie, je krijgt een lijst metInferenceRequestvoorwerpen. Er zijn twee manieren om deze functie te implementeren: de standaardmodus en de ontkoppelde modus. De standaardmodus is de meest algemene manier waarop u uw model wilt implementeren en vereist dat de execute-functie precies één antwoord per aanvraag retourneert. In de ontkoppelde modus kunt u meerdere antwoorden op een verzoek verzenden of geen antwoorden op een verzoek verzenden. De modus die u kiest, moet afhangen van uw gebruiksscenario, dat wil zeggen of u wel of niet ontkoppelde antwoorden uit dit model wilt retourneren. In dit voorbeeldnotebook gebruiken we de standaardmodus. - afronden – Implementeren
finalizeis optioneel. Met deze functie kunt u alle noodzakelijke opschoningen uitvoeren voordat het model van de Triton Inference Server wordt verwijderd.
Bouw de modelrepository
Het gebruik van Triton op SageMaker vereist dat we eerst een model opslagplaats map met daarin de modellen die wij willen serveren. Voor elk model moeten we een modelmap maken die bestaat uit het modelartefact en het bestand config.pbtxt definiëren om de modelconfiguratie op te geven die Triton gebruikt om het model te laden en te bedienen. Voor meer informatie over de configuratie-instellingen raadpleegt u Modelconfiguratie. De modelrepositorystructuur voor het T5-model is als volgt:

Houd er rekening mee dat Triton specifieke vereisten heeft voor de lay-out van de modelrepository. Binnen de modelopslagmap op het hoogste niveau heeft elk model zijn eigen submap met de informatie voor het overeenkomstige model. Elke modelmap in Triton moet ten minste één numerieke submap hebben die een versie van het model vertegenwoordigt. Hier is dat 1, die versie 1 van ons T5 PyTorch-model vertegenwoordigt. Elk model wordt beheerd door een specifieke backend, dus elke versiesubmap moet het modelartefact bevatten dat door die backend is vereist. Hier gebruiken we de Python-backend en hiervoor is het Python-bestand vereist dat wordt gebruikt voor het serveren (model.py). Als we een PyTorch-backend zouden gebruiken, zou een model.pt-bestand vereist zijn. Voor meer details over naamgevingsconventies voor modelbestanden, zie Modelbestanden.
Elk Python Triton-model moet een config.pbtxt file beschrijft de modelconfiguratie. Om deze backend te gebruiken, moet u de backend veld van uw model config.pbtxt bestand naar python. De volgende code laat zien hoe u het configuratiebestand definieert voor het T5 PyTorch-model dat wordt aangeboden via de Python-backend van Triton:
In deze configuratie hebben we de parametersectie gedefinieerd om een omgevingspad te bieden. Dit komt omdat we, om het Hugging Face T5 PyTorch-model te bedienen met behulp van de Python-backend van Triton, PyTorch- en Hugging Face-transformatoren als afhankelijkheden hebben. U moet een aangepaste uitvoeringsomgeving maken in de Python-backend om alle afhankelijkheden in dit voorbeeld op te nemen. Het alternatief is om Python en alle afhankelijkheden in de lokale omgeving te installeren. De aangepaste uitvoeringsomgeving is alleen nodig als u portabiliteit wilt tussen verschillende systemen die mogelijk niet over de Python-omgeving beschikken om de gevolgtrekking uit te voeren. Als een aangepaste uitvoeringsomgeving vereist is voor SageMaker, moet dit duidelijk worden aangegeven. Momenteel ondersteunt de Python-backend alleen conda-pakket Voor dit doeleinde. conda-pakket zorgt ervoor dat uw Conda-omgeving draagbaar is. Wij volgen de instructies van de Triton-documentatie voor verpakkingsafhankelijkheden te gebruiken in de Python-backend als het TAR-bestand van de Conda-omgeving. Het bash-script uitvoeren create_hf_env.sh creëert de Conda-omgeving met PyTorch- en Hugging Face-transformatoren en verpakt deze als een TAR-bestand, en vervolgens verplaatsen we deze naar de t5-pytorch-modelmap:
Nadat we het TAR-bestand vanuit de Conda-omgeving hebben aangemaakt, plaatsen we dit in de modelmap. De volgende code in het model config.pbtxt bestand vertelt de Python-backend om deze aangepaste omgeving voor uw model te gebruiken:
parameters: { key: "EXECUTION_ENV_PATH", value: {string_value: "$$TRITON_MODEL_DIRECTORY/hf_env.tar.gz"}
}
Hier $$TRITON_MODEL_DIRECTORY helpt bij het verschaffen van het omgevingspad relatief aan de modelmap in de modelrepository, en is opgelost $pwd/model_repository/t5_pytorch. Tenslotte, hf_env.tar.gz is de naam die we aan ons Conda-omgevingsbestand hebben gegeven.
Vervolgens verpakken we ons model als *.tar.gz bestanden voor uploaden naar Amazon S3:
Een SageMaker-eindpunt maken
Nu we de modelartefacten naar Amazon S3 hebben geüpload, kunnen we een SageMaker-eindpunt met meerdere modellen maken. Om een SageMaker-eindpunt te maken, moeten we eerst het SageMaker-modelobject en de eindpuntconfiguratie maken.
Eerst moeten we de dienende container definiëren. Definieer in de containerdefinitie de ModelDataUrl om de S3-directory op te geven die alle modellen bevat die het SageMaker-eindpunt met meerdere modellen zal gebruiken om voorspellingen te laden en te leveren. Set Mode naar MultiModel om aan te geven dat SageMaker het eindpunt zou creëren met MME-containerspecificaties. Zie de volgende code:
Vervolgens maken we het SageMaker-modelobject met behulp van de create_model boto3 API door de ModelName en containerdefinitie op te geven:
We gebruiken dit model om een eindpunt configuratie waar we het type en aantal instanties kunnen specificeren dat we in het eindpunt willen hebben. Hier implementeren we een g5.2xlarge NVIDIA GPU-instantie:
We gebruiken deze configuratie om een nieuw SageMaker-eindpunt te maken en te wachten tot de implementatie is voltooid:
De status verandert in InService nadat de implementatie succesvol is verlopen.
Roep uw model aan dat wordt gehost op het SageMaker-eindpunt
Nadat het eindpunt is uitgevoerd, kunnen we een aantal onbewerkte voorbeeldgegevens gebruiken om gevolgtrekkingen uit te voeren met JSON als payload-indeling. Voor het formaat van het gevolgtrekkingsverzoek gebruikt Triton de KFServing-gemeenschapsstandaard inferentie protocollen. We kunnen gevolgtrekkingsverzoeken naar het multi-modeleindpunt sturen met behulp van de invoke_enpoint API. We specificeren de TargetModel in de aanroepoproep en geef de payload voor elk modeltype door. Zie de volgende code:
Het notitieboek is te vinden in de GitHub-repository.
Beste praktijken
Bij het gebruik van de Python-backend kan het soms ingewikkeld zijn om de werklast te optimaliseren voor doorvoer en latentie. U moet rekening houden met de opties die beschikbaar zijn via de omgevingsvariabelen van SageMaker en Triton die we eerder hebben besproken met betrekking tot batchgroottes, maximale vertraging en andere factoren. Daarnaast moet u op de hoogte zijn van de Python backend-specifieke configuratie en de configuratie van het onderliggende raamwerk. Hier volgen enkele best practices:
- Als u de PyTorch-module (of een ander deep learning-framework) in de Python-backend gebruikt, overweeg dan om te experimenteren met verschillende waarden van de intra/inter op-threadpoolgrootte. Omdat elke Python-backend-modelinstantie in een afzonderlijk proces wordt uitgevoerd, voorkomt het beperken van het aantal threads per proces dat de systeembronnen worden overbelast bij het opschalen van het aantal instanties.
- Hoewel de Python-backend zeer flexibel is, voert deze een aantal extra gegevenskopieën uit die van invloed kunnen zijn op de gevolgtrekkingsprestaties. Voor de beste prestaties op GPU kunt u overwegen om indien mogelijk de TensorRT-backend van Triton te gebruiken.
- Wanneer u Python-backend-modellen in een ensemble gebruikt, raadpleegt u Interoperabiliteit en GPU-ondersteuning voor een mogelijke zero-copy-overdracht van Python-backend-tensoren naar andere frameworks.
- U kunt ook gebruik maken van de
instance_group_countvariabele in deconfig.pbtxtbestand om een werkproces toe te voegen en de doorvoer te verhogen. Houd er rekening mee dat het verhogen van deze variabele het resourceverbruik zal vergroten, inclusief het CPU- en GPU-gebruik.
U kunt deze opties en parameters verkennen om de gewenste prestatiekenmerken te verkrijgen die u zoekt. Houd er zoals altijd rekening mee dat bronnen zoals processor- of geheugengebruik kunnen veranderen en moeten worden gemonitord, zodat u de inferentieprestaties kunt verfijnen en optimaliseren.
Conclusie
In dit bericht zijn we diep ingegaan op de Python-backend die Triton Inference Server ondersteunt op SageMaker. Deze backend zorgt voor zowel CPU- als GPU-versnelling van uw modellen die zijn geschreven en uitgevoerd in de Python-taal. Er zijn veel opties waarmee u rekening moet houden om de beste prestaties voor inferentie te krijgen, zoals batchgroottes, gegevensinvoerformaten en andere factoren die kunnen worden afgestemd op uw behoeften. Met SageMaker kunt u eindpunten met één model gebruiken voor gegarandeerde prestaties en eindpunten met meerdere modellen voor een beter evenwicht tussen prestaties en kostenbesparingen. Zie om aan de slag te gaan met MME-ondersteuning voor GPU Ondersteunde algoritmen, frameworks en instances.
We nodigen u uit om Triton Inference Server-containers in SageMaker te proberen en uw feedback en vragen in de opmerkingen te delen.
Over de auteurs
 James Park is een oplossingsarchitect bij Amazon Web Services. Hij werkt samen met Amazon aan het ontwerpen, bouwen en implementeren van technologische oplossingen op AWS, en heeft een bijzondere interesse in AI en machine learning. In zijn vrije tijd gaat hij graag op zoek naar nieuwe culturen, nieuwe ervaringen en op de hoogte blijven van de nieuwste technologische trends.
James Park is een oplossingsarchitect bij Amazon Web Services. Hij werkt samen met Amazon aan het ontwerpen, bouwen en implementeren van technologische oplossingen op AWS, en heeft een bijzondere interesse in AI en machine learning. In zijn vrije tijd gaat hij graag op zoek naar nieuwe culturen, nieuwe ervaringen en op de hoogte blijven van de nieuwste technologische trends.
 Dhawal Patel is Principal Machine Learning Architect bij AWS. Hij heeft met organisaties, variërend van grote ondernemingen tot middelgrote startups, gewerkt aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op deep learning, inclusief NLP en computer vision domeinen. Hij helpt klanten om hoogwaardige modelinferentie te bereiken op Amazon SageMaker.
Dhawal Patel is Principal Machine Learning Architect bij AWS. Hij heeft met organisaties, variërend van grote ondernemingen tot middelgrote startups, gewerkt aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op deep learning, inclusief NLP en computer vision domeinen. Hij helpt klanten om hoogwaardige modelinferentie te bereiken op Amazon SageMaker.
 Melanie Li is een Senior AI/ML Specialist TAM bij AWS in Sydney, Australië. Ze helpt zakelijke klanten om oplossingen te bouwen die gebruikmaken van de allernieuwste AI/ML-tools op AWS en biedt begeleiding bij het ontwerpen en implementeren van machine learning-oplossingen met best practices. In haar vrije tijd houdt ze ervan om buiten de natuur te verkennen en tijd door te brengen met familie en vrienden.
Melanie Li is een Senior AI/ML Specialist TAM bij AWS in Sydney, Australië. Ze helpt zakelijke klanten om oplossingen te bouwen die gebruikmaken van de allernieuwste AI/ML-tools op AWS en biedt begeleiding bij het ontwerpen en implementeren van machine learning-oplossingen met best practices. In haar vrije tijd houdt ze ervan om buiten de natuur te verkennen en tijd door te brengen met familie en vrienden.
 Jiahong Liu is Solution Architect in het Cloud Service Provider-team van NVIDIA. Hij helpt klanten bij het adopteren van machine learning en AI-oplossingen die gebruikmaken van NVIDIA Accelerated Computing om hun trainings- en inferentie-uitdagingen aan te pakken. In zijn vrije tijd houdt hij van origami, doe-het-zelfprojecten en basketbal.
Jiahong Liu is Solution Architect in het Cloud Service Provider-team van NVIDIA. Hij helpt klanten bij het adopteren van machine learning en AI-oplossingen die gebruikmaken van NVIDIA Accelerated Computing om hun trainings- en inferentie-uitdagingen aan te pakken. In zijn vrije tijd houdt hij van origami, doe-het-zelfprojecten en basketbal.
 Kshitiz Gupta is Solutions Architect bij NVIDIA. Hij vindt het leuk om cloudklanten te informeren over de GPU AI-technologieën die NVIDIA te bieden heeft en hen te helpen bij het versnellen van hun machine learning en deep learning-applicaties. Naast zijn werk houdt hij van hardlopen, wandelen en het spotten van dieren in het wild.
Kshitiz Gupta is Solutions Architect bij NVIDIA. Hij vindt het leuk om cloudklanten te informeren over de GPU AI-technologieën die NVIDIA te bieden heeft en hen te helpen bij het versnellen van hun machine learning en deep learning-applicaties. Naast zijn werk houdt hij van hardlopen, wandelen en het spotten van dieren in het wild.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/host-ml-models-on-amazon-sagemaker-using-triton-python-backend/
- : heeft
- :is
- :niet
- :waar
- $UP
- 1
- 10
- 100
- 11
- 12
- 23
- 7
- 8
- 9
- a
- Over
- versneld
- versnellen
- versnelling
- toegang
- Account
- Bereiken
- over
- toevoegen
- toevoeging
- Extra
- adres
- adresseerbaar
- De goedkeuring van
- Na
- tegen
- overeenkomsten
- AI
- AI / ML
- algoritmen
- Alles
- ken toe
- toelaten
- toestaat
- langs
- ook
- alternatief
- Hoewel
- altijd
- Amazone
- Amazon Sage Maker
- Amazon Web Services
- bedragen
- an
- en
- elke
- api
- toepasselijk
- toepassingen
- passend
- architectuur
- ZIJN
- gebieden
- argument
- kunstmatig
- kunstmatige intelligentie
- AS
- helpt
- geassocieerd
- At
- Australië
- auto
- Beschikbaar
- bewust
- AWS
- backend
- Balance
- baseren
- gebaseerde
- slaan
- basis
- Basketbal
- BE
- omdat
- geweest
- vaardigheden
- beginnen
- achter
- wezen
- BEST
- 'best practices'
- Betere
- tussen
- lichaam
- zowel
- bouw
- bedrijfsdeskundigen
- maar
- by
- C + +
- Bellen
- Dit betekent dat we onszelf en onze geliefden praktisch vergiftigen.
- CAN
- mogelijkheden
- Inhoud
- verzorging
- geval
- gevallen
- Categorie
- uitdagingen
- verandering
- kenmerken
- chips
- Kies
- het kiezen van
- klasse
- Schoonmaak
- duidelijk
- klanten
- Cloud
- code
- COM
- opmerkingen
- Communicatie
- gemeenschap
- verenigbaarheid
- ingewikkeld
- Berekenen
- computer
- Computer visie
- computergebruik
- Configuratie
- Overwegen
- bestaande uit
- consumptie
- Containers
- containers
- bevat
- blijft
- conventies
- het omzetten van
- Kern
- Overeenkomend
- Kosten
- kostenbesparingen
- CPU
- en je merk te creëren
- aangemaakt
- creëert
- criteria
- cruciaal
- Op dit moment
- gewoonte
- Klanten
- gegevens
- Datum
- beslissing
- ontkoppelde
- deep
- diepgaand leren
- Standaard
- gedefinieerd
- vertraging
- veeleisende
- demonstreert
- Afhankelijk
- implementeren
- ingezet
- het inzetten
- inzet
- Design
- gewenste
- gegevens
- Bepalen
- apparaat
- DICT
- dicteert
- anders
- direct
- besproken
- verdeeld
- distributed computing
- diy
- do
- documentatie
- domeinen
- duif
- downloads
- twee
- dynamisch
- elk
- gemakkelijk
- opleiden
- beide
- anders
- in staat stellen
- maakt
- einde
- Endpoint
- Motoren
- Engels
- waarborgt
- Enterprise
- zakelijke klanten
- bedrijven
- Milieu
- fouten
- Ether (ETH)
- Zelfs
- Alle
- precies
- voorbeeld
- uitwisseling
- uitwisselen
- uitvoeren
- uitvoering
- bestaand
- afrit
- verwachten
- ervaring
- Ervaringen
- Verken
- blootgestelde
- extra
- Gezicht
- factoren
- tamelijk
- Vallen
- vals
- familie
- Kenmerk
- Voordelen
- feedback
- veld-
- Dien in
- Bestanden
- Tot slot
- VIND DE PLEK DIE PERFECT VOOR JOU IS
- afmaken
- Voornaam*
- Flexibiliteit
- flexibel
- richt
- volgen
- volgend
- volgt
- Voor
- formaat
- gevonden
- Achtergrond
- frameworks
- Gratis
- vaak
- vrienden
- oppompen van
- voor
- Voorkant
- functie
- functioneel
- functies
- gaf
- Duits
- krijgen
- GitHub
- gegeven
- geeft
- GPU
- GPU's
- groot
- Groep
- Groep
- Groeit
- gegarandeerde
- leiding
- Hebben
- he
- hulp
- helpt
- haar
- hier
- Hoge
- hoge performantie
- zeer
- wandelen
- zijn
- gastheer
- gehost
- Huis
- Hoe
- How To
- Echter
- HTML
- http
- HTTPS
- IAM
- ID
- Identiteit
- if
- illustreert
- beeld
- Impact
- Effecten
- uitvoeren
- geïmplementeerd
- uitvoering
- gereedschap
- importeren
- belangrijk
- in
- Anders
- omvatten
- Inclusief
- Inkomend
- Laat uw omzet
- meer
- aangeven
- informatie
- op de hoogte
- invoer
- ingangen
- installeren
- instantie
- verkrijgen in plaats daarvan
- instructies
- integratie
- Intelligentie
- interactie
- belang
- in
- uitnodigt
- ingeroepen
- IT
- HAAR
- zelf
- jpg
- json
- sleutel
- toetsen
- Soort
- blijven
- taal
- Groot
- Grote ondernemingen
- Wachttijd
- later
- laatste
- Layout
- Lekken
- LEARN
- leren
- minst
- Lengte
- Niveau
- niveaus
- Hefboomwerking
- leveraging
- levenscyclus van uw product
- als
- Lijst
- laden
- ladingen
- lokaal
- logica
- logisch
- op zoek
- houdt
- machine
- machine learning
- gemaakt
- Hoofd
- onderhoudt
- maken
- beheer
- management
- veel
- in kaart brengen
- max
- Maximaliseren
- Mei..
- mechanisme
- Maak kennis met
- Geheugen
- methode
- methoden
- Metriek
- macht
- ML
- Mode
- model
- modellen
- modi
- module
- monitor
- bewaakt
- meer
- meest
- beweging
- Eindpunt voor meerdere modellen
- meervoudig
- Dan moet je
- naam
- naamgeving
- inheemse
- NATUUR
- noodzakelijk
- Noodzaak
- nodig
- behoeften
- New
- nlp
- geen
- nota
- notitieboekje
- nu
- aantal
- numpy
- Nvidia
- object
- doelstellingen
- objecten
- verkrijgen
- of
- bieden
- Aanbod
- on
- eens
- EEN
- Slechts
- OP
- optimale
- Optimaliseer
- Keuze
- Opties
- or
- organisaties
- OS
- Overige
- anders-
- onze
- uit
- buiten
- uitgang
- buiten
- het te bezitten.
- pakket
- Paketten
- verpakking
- parameters
- bijzonder
- passeren
- passes
- pad
- uitvoeren
- prestatie
- presteert
- pijpleiding
- plaats
- Plato
- Plato gegevensintelligentie
- PlatoData
- spelen
- overvloed
- punt
- beleidsmaatregelen door te lezen.
- beleidsmaatregelen
- zwembad
- Populair
- mogelijk
- Post
- aangedreven
- praktijken
- Voorspelbaar
- Voorspellingen
- voorkomt
- die eerder
- prijs
- primair
- Principal
- problemen
- processen
- Gegevensverwerker
- produceren
- projecten
- gepast
- vastgoed
- zorgen voor
- mits
- leverancier
- biedt
- het verstrekken van
- voorziening
- doel
- Python
- pytorch
- Contact
- verhogen
- variërend
- Rauw
- ruwe data
- bereiken
- real-time
- ontvangt
- adviseren
- achteloos
- betreft de
- regio
- verwant
- bewaarplaats
- vertegenwoordigen
- te vragen
- aangevraagd
- verzoeken
- nodig
- Voorwaarden
- vereist
- opgelost
- hulpbron
- Resources
- degenen
- antwoord
- reacties
- verantwoordelijkheid
- Resultaten
- terugkeer
- Retourneren
- rechts
- Rol
- weg
- wegen
- lopen
- lopend
- loopt
- sagemaker
- dezelfde
- Bespaar geld
- schaalbare
- Scale
- scaling
- scheduling
- sectie
- zien
- Zoeken
- op zoek naar
- ZELF
- sturen
- senior
- apart
- dienen
- bedient
- service
- Service Provider
- Diensten
- serveer-
- reeks
- het instellen van
- settings
- vorming
- Delen
- gedeeld
- delen
- ze
- moet
- tonen
- Shows
- gelijk
- Eenvoudig
- single
- situaties
- Maat
- maten
- MKB
- So
- oplossing
- Oplossingen
- sommige
- bron
- specialist
- specifiek
- specificaties
- gespecificeerd
- besteden
- standaard
- gestart
- Startups
- Land
- state-of-the-art
- Status
- vast
- Stappen
- Still
- mediaopslag
- eenvoudig
- Draad
- structuur
- geslaagd
- dergelijk
- Stelt voor
- ondersteuning
- ondersteunde
- steunen
- sydney
- system
- Systems
- Nemen
- neemt
- TAM
- doelwit
- Taak
- team
- Technologies
- Technologie
- vertelt
- tijdelijk
- termen
- dat
- De
- de informatie
- hun
- Ze
- harte
- Er.
- Deze
- dit
- die
- toch?
- drie
- Door
- doorvoer
- niet de tijd of
- naar
- tools
- hoogste niveau
- fakkel
- verkeer
- Trainingen
- overdracht
- transformers
- vertalen
- Vertaling
- Trends
- Triton
- proberen
- twee
- type dan:
- types
- die ten grondslag liggen
- begrijpen
- ongewenste
- geüpload
- Uploaden
- op
- UPS
- us
- .
- use case
- gebruikt
- gebruikers
- gebruik
- doorgaans
- Gebruik makend
- waarde
- Values
- variabelen
- divers
- versie
- zeer
- via
- visie
- volume
- wachten
- willen
- kijken
- Manier..
- we
- web
- webservices
- GOED
- waren
- Wat
- wanneer
- telkens als
- of
- welke
- en
- WIE
- wildlife
- wil
- Met
- binnen
- prachtig
- Mijn werk
- werkte
- werker
- Bedrijven
- zou
- schrijven
- het schrijven van
- geschreven
- u
- Your
- zephyrnet