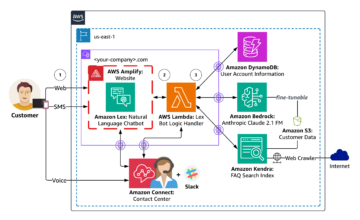
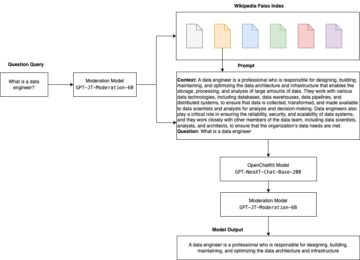
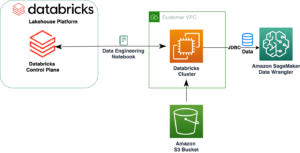
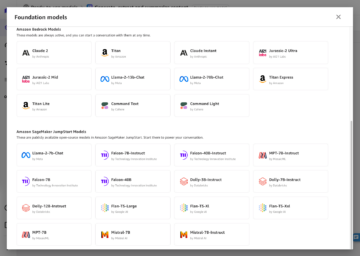
Amazon SageMaker er en fullstendig administrert maskinlæringstjeneste (ML). Med SageMaker kan dataforskere og utviklere raskt og enkelt bygge og trene ML-modeller, og deretter distribuere dem direkte i et produksjonsklart vertsmiljø. Den gir en integrert Jupyter-forfatternotatbok-instans for enkel tilgang til datakildene dine for utforskning og analyse, slik at du ikke trenger å administrere servere. Det gir også felles ML-algoritmer som er optimalisert for å kjøre effektivt mot ekstremt store data i et distribuert miljø.
SageMaker sanntidsslutning er ideell for arbeidsbelastninger som har sanntids, interaktive krav med lav latens. Med SageMaker sanntidsslutning kan du distribuere REST-endepunkter som støttes av en spesifikk forekomsttype med en viss mengde databehandling og minne. Å distribuere et SageMaker-endepunkt i sanntid er bare det første trinnet i veien til produksjon for mange kunder. Vi ønsker å være i stand til å maksimere ytelsen til endepunktet for å oppnå et mål for transaksjoner per sekund (TPS) mens vi overholder latenskrav. En stor del av ytelsesoptimalisering for slutninger er å sørge for at du velger riktig forekomsttype og teller for å gå tilbake til et endepunkt.
Dette innlegget beskriver de beste fremgangsmåtene for belastningsteste et SageMaker-endepunkt for å finne riktig konfigurasjon for antall forekomster og størrelse. Dette kan hjelpe oss med å forstå minimumskravene til klargjort forekomst for å oppfylle våre latens- og TPS-krav. Derfra dykker vi inn i hvordan du kan spore og forstå beregningene og ytelsen til SageMaker-endepunktet ved å bruke Amazon CloudWatch beregninger.
Vi måler først ytelsen til modellen vår på en enkelt forekomst for å identifisere TPS-en den kan håndtere i henhold til våre akseptable latenskrav. Deretter ekstrapolerer vi funnene for å bestemme antall instanser vi trenger for å håndtere produksjonstrafikken vår. Til slutt simulerer vi trafikk på produksjonsnivå og setter opp belastningstester for et sanntids SageMaker-endepunkt for å bekrefte at endepunktet vårt kan håndtere belastningen på produksjonsnivå. Hele settet med kode for eksempelet er tilgjengelig i det følgende GitHub repository.
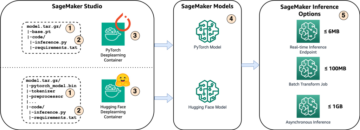
Oversikt over løsning
For dette innlegget distribuerer vi en forhåndsutdannet Hugging Face DistilBERT modell fra Klemmer Face Hub. Denne modellen kan utføre en rekke oppgaver, men vi sender en nyttelast spesielt for sentimentanalyse og tekstklassifisering. Med denne prøvelasten streber vi etter å oppnå 1000 TPS.
Distribuer et endepunkt i sanntid
Dette innlegget forutsetter at du er kjent med hvordan du distribuerer en modell. Referere til Lag endepunktet ditt og distribuer modellen din for å forstå det interne bak å være vert for et endepunkt. Foreløpig kan vi raskt peke på denne modellen i Hugging Face Hub og distribuere et sanntidsendepunkt med følgende kodebit:
La oss raskt teste endepunktet vårt med prøvenyttelasten som vi vil bruke for lasttesting:

Merk at vi støtter endepunktet ved å bruke en singel Amazon Elastic Compute Cloud (Amazon EC2) forekomst av typen ml.m5.12xlarge, som inneholder 48 vCPU og 192 GiB minne. Antall vCPUer er en god indikasjon på samtidigheten instansen kan håndtere. Generelt anbefales det å teste ulike forekomsttyper for å sikre at vi har en forekomst som har ressurser som er riktig utnyttet. For å se en fullstendig liste over SageMaker-forekomster og deres tilsvarende datakraft for sanntidsinferens, se Amazon SageMaker-priser.
Beregninger å spore
Før vi kan gå inn i belastningstesting, er det viktig å forstå hvilke beregninger som skal spores for å forstå ytelsessammenbruddet til SageMaker-endepunktet. CloudWatch er det primære loggingsverktøyet som SageMaker bruker for å hjelpe deg med å forstå de forskjellige beregningene som beskriver endepunktets ytelse. Du kan bruke CloudWatch-logger til å feilsøke endepunktsoppfordringene dine; alle logg- og utskriftsoppgaver du har i slutningskoden din, fanges opp her. For mer informasjon, se Hvordan Amazon CloudWatch fungerer.
Det er to forskjellige typer beregninger CloudWatch dekker for SageMaker: forekomstnivå og invokasjonsberegninger.
Beregninger på forekomstnivå
Det første settet med parametere å vurdere er beregningene på forekomstnivå: CPUUtilization og MemoryUtilization (for GPU-baserte forekomster, GPUUtilization). Til CPUUtilization, kan du først se prosenter over 100 % i CloudWatch. Det er viktig å innse for CPUUtilization, vises summen av alle CPU-kjernene. For eksempel, hvis forekomsten bak endepunktet ditt inneholder 4 vCPUer, betyr dette at bruksområdet er opptil 400 %. MemoryUtilization, derimot, er i området 0–100 %.
Nærmere bestemt kan du bruke CPUUtilization for å få en dypere forståelse av om du har tilstrekkelig eller til og med en overflødig mengde maskinvare. Hvis du har en underutnyttet forekomst (mindre enn 30 %), kan du potensielt skalere ned forekomsttypen. Omvendt, hvis du er rundt 80–90 % utnyttelse, vil det være en fordel å velge en instans med større databehandling/minne. Fra våre tester foreslår vi rundt 60–70 % utnyttelse av maskinvaren din.
Påkallingsberegninger
Som antydet av navnet, er påkallingsberegninger der vi kan spore ende-til-ende-forsinkelsen til alle påkallinger til endepunktet ditt. Du kan bruke påkallingsberegningene til å fange opp feiltellinger og hvilken type feil (5xx, 4xx, og så videre) som endepunktet ditt kan oppleve. Enda viktigere, du kan forstå latenssammenbruddet til endepunktsamtalene dine. Mye av dette kan fanges med ModelLatency og OverheadLatency beregninger, som illustrert i følgende diagram.

De ModelLatency metrikk fanger opp tiden som inferens tar innenfor modellbeholderen bak et SageMaker-endepunkt. Merk at modellbeholderen også inkluderer egendefinert slutningskode eller skript som du har sendt for slutning. Denne enheten fanges opp i mikrosekunder som en invokasjonsberegning, og generelt kan du tegne en persentil på tvers av CloudWatch (p99, p90, og så videre) for å se om du når målforsinkelsen. Merk at flere faktorer kan påvirke modell- og beholderforsinkelse, for eksempel følgende:
- Egendefinert slutningsskript – Enten du har implementert din egen beholder eller brukt en SageMaker-basert beholder med tilpassede slutningsbehandlere, er det beste praksis å profilere skriptet ditt for å fange opp alle operasjoner som spesifikt legger mye tid til ventetiden din.
- Kommunikasjonsprotokoll – Vurder REST vs. gRPC-tilkoblinger til modellserveren i modellbeholderen.
- Modellrammeoptimaliseringer – Dette er rammebestemt, for eksempel med tensorflow, er det en rekke miljøvariabler du kan justere som er TF-serveringsspesifikke. Sørg for å sjekke hvilken beholder du bruker, og hvis det er noen rammespesifikke optimaliseringer du kan legge til i skriptet eller som miljøvariabler for å injisere i beholderen.
OverheadLatency måles fra det tidspunktet SageMaker mottar forespørselen til den returnerer et svar til klienten, minus modellforsinkelsen. Denne delen er stort sett utenfor din kontroll og faller inn under tiden som SageMaker-kostnader tar.
End-to-end latens som helhet avhenger av en rekke faktorer og er ikke nødvendigvis summen av ModelLatency i tillegg til OverheadLatency. For eksempel, hvis klienten din lager InvokeEndpoint API-anrop over internett, fra klientens perspektiv, vil ende-til-ende-forsinkelsen være internett + ModelLatency + OverheadLatency. Som sådan, når du belastningstester endepunktet ditt for å nøyaktig benchmarke selve endepunktet, anbefales det å fokusere på endepunktberegningene (ModelLatency, OverheadLatencyog InvocationsPerInstance) for å nøyaktig benchmarke SageMaker-endepunktet. Eventuelle problemer knyttet til ende-til-ende-latens kan deretter isoleres separat.
Noen spørsmål å vurdere for ende-til-ende-forsinkelse:
- Hvor er klienten som påkaller endepunktet ditt?
- Er det noen mellomliggende lag mellom klienten din og SageMaker-kjøringen?
Automatisk skalering
Vi dekker ikke automatisk skalering spesifikt i dette innlegget, men det er en viktig vurdering for å kunne levere riktig antall forekomster basert på arbeidsmengden. Avhengig av trafikkmønsteret ditt kan du legge ved en retningslinjer for automatisk skalering til SageMaker-endepunktet. Det finnes ulike skaleringsalternativer, som f.eks TargetTrackingScaling, SimpleScalingog StepScaling. Dette gjør at endepunktet ditt kan skaleres inn og ut automatisk basert på trafikkmønsteret ditt.
Et vanlig alternativ er målsporing, hvor du kan spesifisere en CloudWatch-beregning eller tilpasset beregning som du har definert og skalere ut basert på det. En hyppig bruk av automatisk skalering er å spore InvocationsPerInstance metrisk. Etter at du har identifisert en flaskehals ved en bestemt TPS, kan du ofte bruke den som en beregning for å skalere ut til et større antall forekomster for å kunne håndtere toppbelastninger med trafikk. For å få en dypere oversikt over SageMaker-endepunkter for automatisk skalering, se Konfigurering av autoskalering av slutningsendepunkter i Amazon SageMaker.
Lasttesting
Selv om vi bruker Locust for å vise hvordan vi kan laste test i skala, hvis du prøver å rette størrelsen på forekomsten bak endepunktet ditt, SageMaker Inference Recommender er et mer effektivt alternativ. Med tredjeparts verktøy for belastningstesting må du manuelt distribuere endepunkter på tvers av forskjellige forekomster. Med Inference Recommender kan du ganske enkelt bestå en rekke av instanstypene du vil lastetest mot, og SageMaker vil spinne opp jobber for hvert av disse tilfellene.
Locust
For dette eksempelet bruker vi Locust, et åpen kildekode-lasttestingsverktøy som du kan implementere ved hjelp av Python. Locust ligner på mange andre åpen kildekode-lasttestverktøy, men har noen spesifikke fordeler:
- Enkel å sette opp – Som vi demonstrerer i dette innlegget, sender vi et enkelt Python-skript som enkelt kan refaktoreres for ditt spesifikke endepunkt og nyttelast.
- Distribuert og skalerbar – Locust er hendelsesbasert og bruker gavt under panseret. Dette er veldig nyttig for å teste svært samtidige arbeidsbelastninger og simulere tusenvis av samtidige brukere. Du kan oppnå høy TPS med en enkelt prosess som kjører Locust, men den har også en distribuert lastgenerering funksjon som lar deg skalere ut til flere prosesser og klientmaskiner, som vi vil utforske i dette innlegget.
- Locust-beregninger og brukergrensesnitt – Locust fanger også opp ende-til-ende-latens som en beregning. Dette kan bidra til å supplere CloudWatch-beregningene dine for å tegne et fullstendig bilde av testene dine. Alt dette fanges opp i Locust UI, der du kan spore samtidige brukere, arbeidere og mer.
For å forstå Locust ytterligere, sjekk ut deres dokumentasjon.
Amazon EC2 oppsett
Du kan sette opp Locust uansett hvilket miljø som er kompatibelt for deg. For dette innlegget setter vi opp en EC2-forekomst og installerer Locust der for å utføre testene våre. Vi bruker en c5.18xlarge EC2-instans. Beregningskraften på klientsiden er også noe å vurdere. Til tider når du går tom for datakraft på klientsiden, blir dette ofte ikke fanget opp, og blir forvekslet som en SageMaker-endepunktfeil. Det er viktig å plassere klienten på et sted med tilstrekkelig datakraft som kan håndtere belastningen du tester på. For vår EC2-forekomst bruker vi en Ubuntu Deep Learning AMI, men du kan bruke hvilken som helst AMI så lenge du kan sette opp Locust på maskinen riktig. For å forstå hvordan du starter og kobler til EC2-forekomsten din, se veiledningen Kom i gang med Amazon EC2 Linux-forekomster.
Locust UI er tilgjengelig via port 8089. Vi kan åpne dette ved å justere våre innkommende sikkerhetsgrupperegler for EC2-forekomsten. Vi åpner også port 22 slik at vi kan SSH inn i EC2-forekomsten. Vurder å begrense kilden til den spesifikke IP-adressen du får tilgang til EC2-forekomsten fra.

Etter at du er koblet til EC2-forekomsten, setter vi opp et virtuelt Python-miljø og installerer åpen kildekode Locust API via CLI:
Vi er nå klare til å jobbe med Locust for lasttesting av endepunktet vårt.
Græshopptesting
Alle Locust-belastningstester er utført basert på en Locust fil som du gir. Denne Locust-filen definerer en oppgave for belastningstesten; det er her vi definerer vår Boto3 invoke_endpoint API-kall. Se følgende kode:
I den foregående koden, juster parametrene for påkalling av endepunktanrop for å passe til din spesifikke modellanrop. Vi bruker InvokeEndpoint API som bruker følgende kodebit i Locust-filen; dette er vårt lastetestkjøringspunkt. Locust-filen vi bruker er locust_script.py.
Nå som vi har Locust-skriptet vårt klart, ønsker vi å kjøre distribuerte Locust-tester for å stressteste vår enkeltforekomst for å finne ut hvor mye trafikk forekomsten vår kan håndtere.
Locust-distribuert modus er litt mer nyansert enn en enkelt-prosess Locust-test. I distribuert modus har vi én primær og flere arbeidere. Den primære arbeideren instruerer arbeiderne om hvordan de skal spawn og kontrollere de samtidige brukerne som sender en forespørsel. I vår distributed.sh skript, ser vi som standard at 240 brukere vil bli fordelt på de 60 arbeiderne. Merk at --headless flagget i Locust CLI fjerner UI-funksjonen til Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
Vi kjører først den distribuerte testen på en enkelt forekomst som støtter endepunktet. Tanken her er at vi ønsker å fullt ut maksimere en enkelt forekomst for å forstå antall forekomster vi trenger for å oppnå vårt mål-TPS samtidig som vi holder oss innenfor latenskravene våre. Merk at hvis du vil ha tilgang til brukergrensesnittet, endrer du Locust_UI miljøvariabelen til True og ta den offentlige IP-en til EC2-forekomsten din og tilordne port 8089 til URL-en.
Følgende skjermbilde viser CloudWatch-beregningene våre.

Etter hvert legger vi merke til at selv om vi i utgangspunktet oppnår en TPS på 200, begynner vi å legge merke til 5xx-feil i våre EC2-klientsidelogger, som vist i følgende skjermbilde.
Vi kan også verifisere dette ved å se nærmere på beregningene våre på forekomstnivå CPUUtilization.
 Her merker vi
Her merker vi CPUUtilization på nesten 4,800 %. Vår ml.m5.12x.large-instans har 48 vCPUer (48 * 100 = 4800~). Dette metter hele forekomsten, noe som også bidrar til å forklare 5xx-feilene våre. Vi ser også en økning i ModelLatency.
Det virker som om enkeltforekomsten vår blir veltet og ikke har data til å opprettholde en last forbi de 200 TPS som vi observerer. Målet vårt for TPS er 1000, så la oss prøve å øke antallet forekomster til 5. Dette må kanskje være enda mer i en produksjonsinnstilling, fordi vi observerte feil ved 200 TPS etter et visst tidspunkt.

Vi ser i både Locust UI- og CloudWatch-loggene at vi har en TPS på nesten 1000 med fem forekomster som støtter endepunktet.

 Hvis du begynner å oppleve feil selv med dette maskinvareoppsettet, sørg for å overvåke
Hvis du begynner å oppleve feil selv med dette maskinvareoppsettet, sørg for å overvåke CPUUtilization for å forstå hele bildet bak endepunktverten din. Det er avgjørende å forstå maskinvarebruken din for å se om du trenger å skalere opp eller til og med ned. Noen ganger fører problemer på beholdernivå til 5xx-feil, men hvis CPUUtilization er lav, indikerer det at det ikke er maskinvaren din, men noe på beholder- eller modellnivå som kan føre til disse problemene (riktig miljøvariabel for antall arbeidere som ikke er angitt, for eksempel). På den annen side, hvis du merker at forekomsten din blir fullstendig mettet, er det et tegn på at du enten må øke gjeldende forekomstflåte eller prøve ut en større forekomst med en mindre flåte.
Selv om vi økte antall forekomster til 5 for å håndtere 100 TPS, kan vi se at ModelLatency metrikken er fortsatt høy. Dette skyldes at forekomstene er mettet. Generelt foreslår vi å ta sikte på å utnytte instansens ressurser mellom 60–70 %.
Rydd opp
Etter lasttesting, sørg for å rydde opp i alle ressurser du ikke vil bruke via SageMaker-konsollen eller gjennom delete_endpoint Boto3 API-kall. Sørg i tillegg for å stoppe EC2-forekomsten din eller hvilket klientoppsett du måtte ha for å ikke pådra deg ytterligere kostnader der også.
Oppsummering
I dette innlegget beskrev vi hvordan du kan lastetest ditt SageMaker-endepunkt i sanntid. Vi diskuterte også hvilke beregninger du bør evaluere når du laster endepunktet for å forstå ytelsessammenbruddet. Sørg for å sjekke ut SageMaker Inference Recommender for ytterligere å forstå forekomster av riktig størrelse og flere teknikker for ytelsesoptimalisering.
Om forfatterne
 Marc Karp er en ML-arkitekt med SageMaker Service-teamet. Han fokuserer på å hjelpe kunder med å designe, distribuere og administrere ML-arbeidsmengder i stor skala. På fritiden liker han å reise og utforske nye steder.
Marc Karp er en ML-arkitekt med SageMaker Service-teamet. Han fokuserer på å hjelpe kunder med å designe, distribuere og administrere ML-arbeidsmengder i stor skala. På fritiden liker han å reise og utforske nye steder.
 Ram Vegiraju er en ML-arkitekt med SageMaker Service-teamet. Han fokuserer på å hjelpe kunder med å bygge og optimalisere sine AI/ML-løsninger på Amazon SageMaker. På fritiden elsker han å reise og skrive.
Ram Vegiraju er en ML-arkitekt med SageMaker Service-teamet. Han fokuserer på å hjelpe kunder med å bygge og optimalisere sine AI/ML-løsninger på Amazon SageMaker. På fritiden elsker han å reise og skrive.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- I stand
- ovenfor
- akseptabelt
- adgang
- tilgjengelig
- Tilgang
- nøyaktig
- Oppnå
- tvers
- tillegg
- adresse
- Etter
- mot
- AI / ML
- Sikter
- Alle
- tillater
- Selv
- Amazon
- Amazon EC2
- Amazon SageMaker
- beløp
- analyse
- og
- api
- rundt
- Array
- feste
- forfatter
- auto
- automatisk
- tilgjengelig
- AWS
- tilbake
- Backed
- backing
- basert
- fordi
- bak
- være
- benchmark
- nytte
- Fordeler
- BEST
- beste praksis
- mellom
- kroppen
- Breakdown
- bygge
- C + +
- ring
- Samtaler
- Kan få
- fangst
- fanger
- Catch
- viss
- endring
- avgifter
- sjekk
- klasse
- klassifisering
- kunde
- kode
- Felles
- kompatibel
- Beregn
- samtidig
- Gjennomføre
- Konfigurasjon
- Bekrefte
- Koble
- tilkoblet
- Tilkoblinger
- Vurder
- hensyn
- Konsoll
- Container
- inneholder
- kontekst
- kontroll
- Tilsvarende
- kunne
- dekke
- dekker
- prosessor
- skape
- avgjørende
- Gjeldende
- skikk
- Kunder
- dato
- dyp
- dyp læring
- dypere
- Misligholde
- definerer
- demonstrere
- avhengig
- avhenger
- utplassere
- utplasserings
- beskrive
- beskrevet
- utforming
- utviklere
- forskjellig
- direkte
- diskutert
- Vise
- distribueres
- ikke
- ikke
- ned
- hver enkelt
- lett
- effektiv
- effektivt
- enten
- muliggjør
- ende til ende
- Endpoint
- Hele
- Miljø
- feil
- feil
- avgjørende
- Eter (ETH)
- Selv
- eksempel
- unntak
- henrette
- opplever
- Forklar
- leting
- utforske
- Utforske
- eksportere
- ekstremt
- Face
- faktorer
- Falls
- kjent
- Trekk
- Noen få
- filet
- Endelig
- Finn
- Først
- FLÅTE
- Fokus
- fokuserer
- etter
- format
- Rammeverk
- hyppig
- fra
- fullt
- fullt
- videre
- general
- generelt
- få
- få
- god
- graf
- større
- Gruppe
- Gruppens
- håndtere
- lykkelig
- maskinvare
- hjelpe
- hjelpe
- hjelper
- her.
- Høy
- svært
- panser
- vert
- vert
- Hosting
- Hvordan
- Hvordan
- HTML
- HTTPS
- Hub
- Tanken
- ideell
- identifisert
- identifisere
- Påvirkning
- iverksette
- implementert
- importere
- viktig
- in
- inkluderer
- Øke
- økt
- indikerer
- indikasjon
- informasjon
- i utgangspunktet
- installere
- f.eks
- integrert
- interaktiv
- Internet
- påkaller
- IP
- IP-adresse
- isolert
- saker
- IT
- selv
- JSON
- stor
- i stor grad
- større
- Ventetid
- lansere
- lag
- føre
- ledende
- læring
- Nivå
- linux
- Liste
- lite
- laste
- laster
- plassering
- Lang
- ser
- Lot
- Lav
- maskin
- maskinlæring
- maskiner
- gjøre
- Making
- administrer
- fikk til
- manuelt
- mange
- kart
- Maksimer
- midler
- Møt
- møte
- Minne
- metrisk
- Metrics
- kunne
- minimum
- ML
- Mote
- modell
- modeller
- Overvåke
- mer
- mer effektivt
- flere
- navn
- nesten
- nødvendigvis
- Trenger
- Ny
- bærbare
- Antall
- ONE
- åpen
- åpen kildekode
- Drift
- optimalisering
- Optimalisere
- optimalisert
- Alternativ
- alternativer
- rekkefølge
- Annen
- utenfor
- egen
- maling
- parametere
- del
- bestått
- Past
- banen
- Mønster
- mønstre
- Topp
- utføre
- ytelse
- perspektiv
- plukke
- bilde
- brikke
- Sted
- steder
- plato
- Platon Data Intelligence
- PlatonData
- i tillegg til
- Point
- Post
- potensielt
- makt
- praksis
- praksis
- Predictor
- primære
- Skrive ut
- problemer
- prosess
- Prosesser
- Produksjon
- Profil
- ordentlig
- riktig
- gi
- gir
- forsyning
- offentlig
- Python
- spørsmål
- raskt
- område
- klar
- sanntids
- realisere
- mottar
- anbefales
- region
- i slekt
- anmode
- Krav
- Ressurser
- svar
- REST
- resultere
- Resultater
- avkastning
- regler
- Kjør
- rennende
- sagemaker
- SageMaker Inference
- Skala
- skalering
- forskere
- Omfang
- skript
- Sekund
- sikkerhet
- synes
- SELV
- sending
- sentiment
- tjeneste
- servering
- sett
- innstilling
- innstillinger
- oppsett
- flere
- bør
- vist
- Viser
- undertegne
- lignende
- Enkelt
- ganske enkelt
- enkelt
- Størrelse
- mindre
- So
- Solutions
- noe
- kilde
- Kilder
- Gyte
- spesifikk
- spesielt
- Snurre rundt
- Standard
- Begynn
- startet
- uttalelser
- Trinn
- Still
- Stopp
- stresset
- streber
- slik
- tilstrekkelig
- Dress
- Super
- supplere
- Ta
- tar
- Target
- Oppgave
- oppgaver
- lag
- teknikker
- test
- Prøvekjøring
- Testing
- tester
- Tekstklassifisering
- De
- Kilden
- deres
- tredjeparts
- tusener
- Gjennom
- tid
- ganger
- til
- verktøy
- verktøy
- tps
- spor
- Sporing
- trafikk
- Tog
- Transaksjoner
- Traveling
- sant
- tutorial
- typer
- Ubuntu
- ui
- etter
- forstå
- forståelse
- enhet
- URL
- us
- bruke
- Brukere
- bruke
- benyttes
- bruker
- utnytte
- variasjon
- verifisere
- av
- virtuelle
- Hva
- om
- hvilken
- mens
- vil
- innenfor
- Arbeid
- arbeidstaker
- arbeidere
- ville
- skriving
- Din
- zephyrnet