Datavitenskap og dataingeniørteam bruker en betydelig del av tiden sin i dataforberedelsesfasen av en livssyklus for maskinlæring (ML) på å utføre datavalg, rengjøring og transformasjonstrinn. Det er et nødvendig og viktig skritt i enhver ML-arbeidsflyt for å generere meningsfull innsikt og spådommer, fordi data av dårlig eller lav kvalitet reduserer relevansen av den utledede innsikten i stor grad.
Dataingeniørteam er tradisjonelt ansvarlige for inntak, konsolidering og transformasjon av rådata for nedstrømsforbruk. Dataforskere trenger ofte å gjøre ytterligere behandling av data for domenespesifikke ML-brukstilfeller som naturlig språk og tidsserier. For eksempel kan visse ML-algoritmer være følsomme for manglende verdier, sparsomme funksjoner eller uteliggere og krever spesiell vurdering. Selv i tilfeller der datasettet er i god form, kan dataforskere ønske å transformere funksjonsdistribusjonene eller lage nye funksjoner for å maksimere innsikten som er oppnådd fra modellene. For å nå disse målene, må dataforskere stole på dataingeniørteam for å imøtekomme forespurte endringer, noe som resulterer i avhengighet og forsinkelser i modellutviklingsprosessen. Alternativt kan datavitenskapsteam velge å utføre dataforberedelse og funksjonsutvikling internt ved å bruke ulike programmeringsparadigmer. Det krever imidlertid en investering av tid og krefter i installasjon og konfigurasjon av biblioteker og rammeverk, noe som ikke er ideelt fordi den tiden kan brukes bedre til å optimalisere modellytelsen.
Amazon SageMaker Data Wrangler forenkler dataforberedelsen og funksjonsutviklingsprosessen, og reduserer tiden det tar å samle og forberede data for ML fra uker til minutter ved å tilby et enkelt visuelt grensesnitt for dataforskere til å velge, rense og utforske datasettene deres. Data Wrangler tilbyr over 300 innebygde datatransformasjoner for å hjelpe normalisere, transformere og kombinere funksjoner uten å skrive noen kode. Du kan importere data fra flere datakilder, som f.eks Amazon Simple Storage Service (Amazon S3), Amazonas Athena, Amazon RedShiftog Snowflake. Du kan nå også bruke Databaser som en datakilde i Data Wrangler for enkelt å klargjøre data for ML.
Databricks Lakehouse-plattformen kombinerer de beste elementene fra datainnsjøer og datavarehus for å levere pålitelighet, sterk styring og ytelse til datavarehus med åpenheten, fleksibiliteten og maskinlæringsstøtten til datainnsjøer. Med Databricks som datakilde for Data Wrangler kan du nå raskt og enkelt koble til Databricks, interaktivt spørre etter data som er lagret i Databricks ved hjelp av SQL, og forhåndsvise data før import. I tillegg kan du slå sammen dataene dine i Databricks med data som er lagret i Amazon S3, og data forespurt gjennom Amazon Athena, Amazon Redshift og Snowflake for å lage det riktige datasettet for ML-brukssaken.
I dette innlegget transformerer vi Lending Club Loan-datasettet ved å bruke Amazon SageMaker Data Wrangler for bruk i ML-modelltrening.
Løsningsoversikt
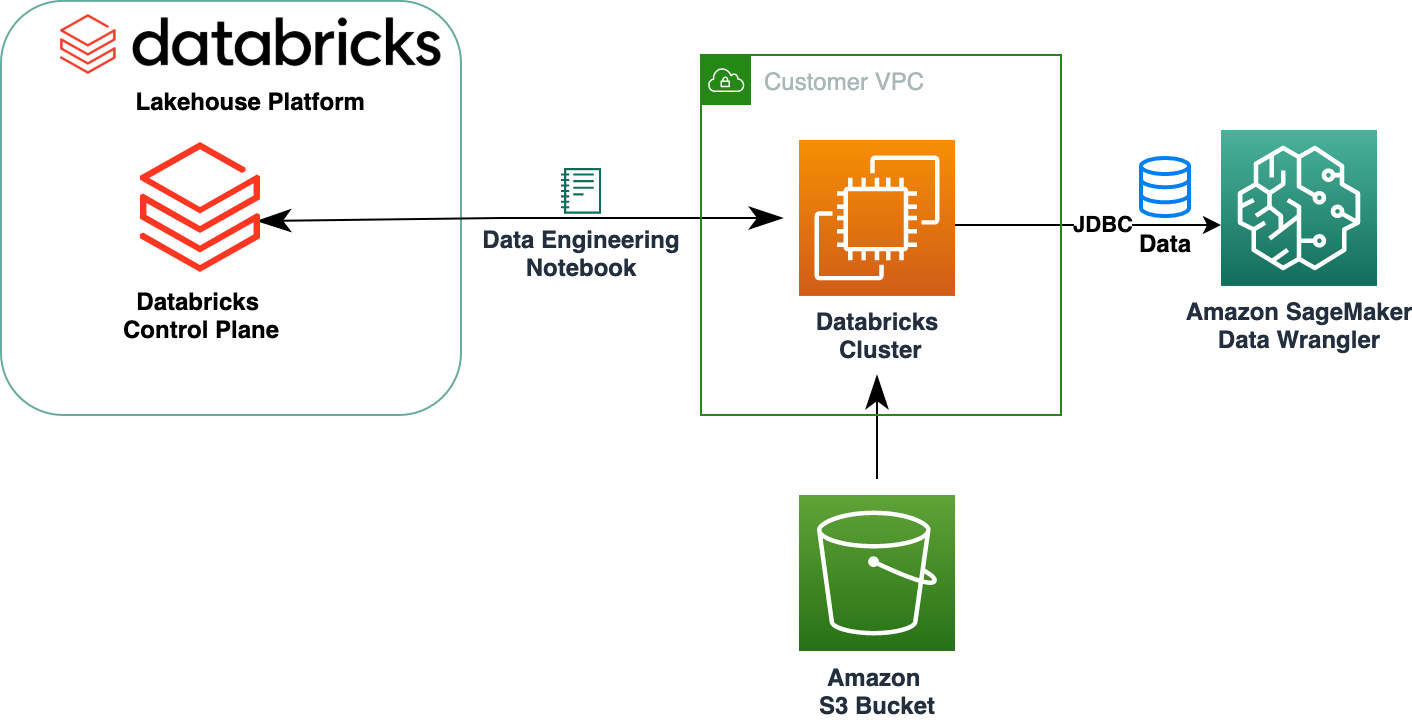
Følgende diagram illustrerer løsningsarkitekturen.
Lending Club Loan-datasettet inneholder fullstendige lånedata for alle lån utstedt gjennom 2007–2011, inkludert gjeldende lånestatus og siste betalingsinformasjon. Den har 39,717 22 rader, 3 funksjonskolonner og XNUMX måletiketter.
For å transformere dataene våre ved hjelp av Data Wrangler, fullfører vi følgende trinn på høyt nivå:
- Last ned og del opp datasettet.
- Lag en Data Wrangler-flyt.
- Importer data fra Databricks til Data Wrangler.
- Importer data fra Amazon S3 til Data Wrangler.
- Bli med dataene.
- Bruk transformasjoner.
- Eksporter datasettet.
Forutsetninger
Innlegget forutsetter at du har en Databricks-klynge som kjører. Hvis klyngen din kjører på AWS, kontroller at du har følgende konfigurert:
Databricks oppsett
- An forekomstprofil med nødvendige tillatelser for å få tilgang til en S3-bøtte
- A bøttepolitikk med nødvendige tillatelser for mål S3-bøtten
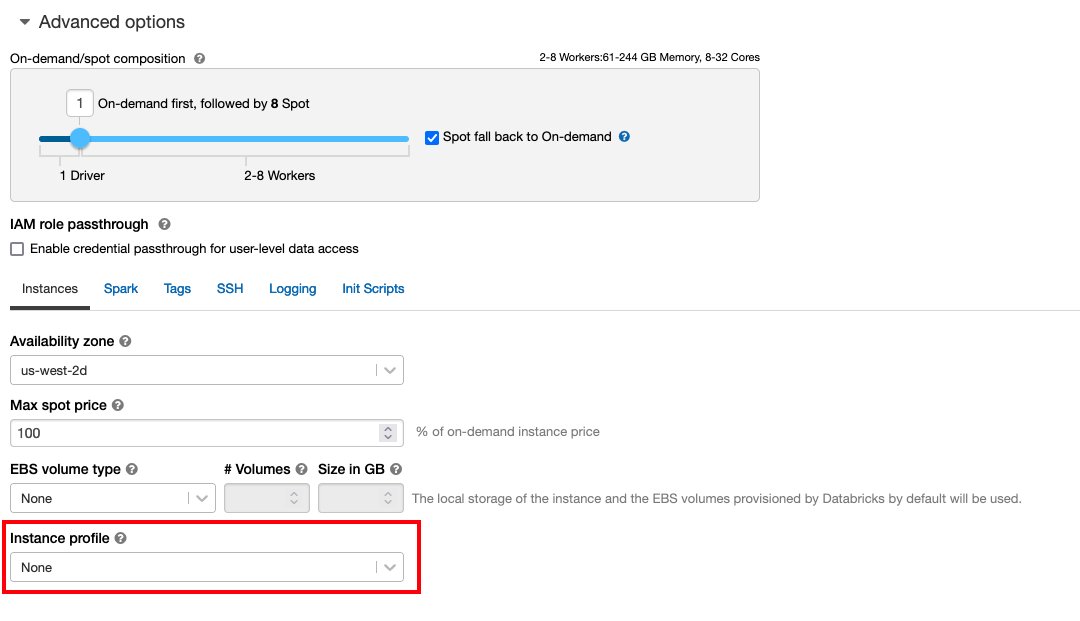
Følg Sikker tilgang til S3-bøtter ved hjelp av forekomstprofiler for det nødvendige AWS identitets- og tilgangsadministrasjon (IAM)-roller, S3-bøttepolicy og Databricks-klyngekonfigurasjon. Sørg for at Databricks-klyngen er konfigurert med riktig Instance Profile, valgt under de avanserte alternativene, for å få tilgang til ønsket S3-bøtte.
Etter at Databricks-klyngen er oppe og går med nødvendig tilgang til Amazon S3, kan du hente JDBC URL fra Databricks-klyngen din som skal brukes av Data Wrangler for å koble til den.
Hent JDBC URL
For å hente JDBC URL, fullfør følgende trinn:
- I Databricks, naviger til clusters UI.
- Velg klyngen din.
- På Konfigurasjon kategorien, velg Avanserte alternativer.
- Under Avanserte alternativer, Velg JDBC/ODBC fanen.
- Kopier JDBC URL.
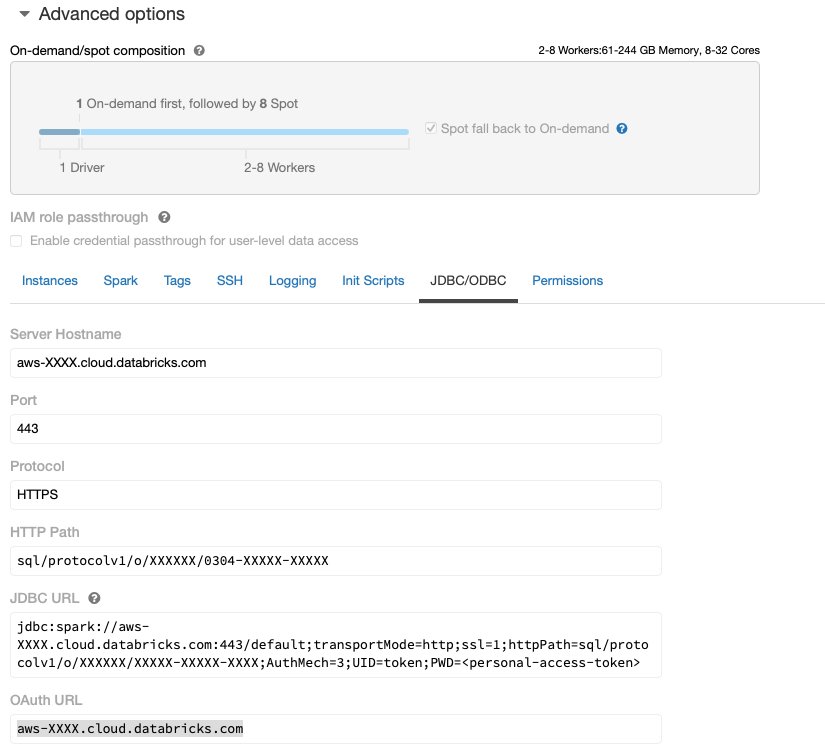
Sørg for å erstatte din personlige tilgang token i URL-en.
Data Wrangler-oppsett
Dette trinnet forutsetter at du har tilgang til Amazon SageMaker, en forekomst av Amazon SageMaker Studio, og en Studio-bruker.
For å tillate tilgang til Databricks JDBC-tilkoblingen fra Data Wrangler, krever Studio-brukeren følgende tillatelse:
secretsmanager:PutResourcePolicy
Følg trinnene nedenfor for å oppdatere IAM-utførelsesrollen som er tildelt Studio-brukeren med tillatelsen ovenfor, som administrativ IAM-bruker.
- Velg på IAM-konsollen Roller i navigasjonsruten.
- Velg rollen som er tildelt Studio-brukeren din.
- Velg Legg til tillatelser.
- Velg Lag inline policy.
- For Service, velg Secrets Manager.
- On handlinger, velg Tilgangsnivå.
- Velg Tillatelsesbehandling.
- Velg PutResourcePolicy.
- Til Ressurser, velg Spesifikk og velg Alle på denne kontoen.

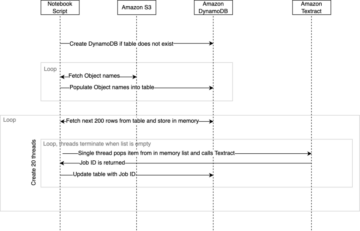
Last ned og del opp datasettet
Du kan starte med nedlasting av datasettet. For demonstrasjonsformål deler vi datasettet ved å kopiere funksjonskolonnene id, emp_title, emp_length, home_ownerog annual_inc å skape et sekund lån_2.csv fil. Vi fjerner de nevnte kolonnene fra den opprinnelige lånefilen bortsett fra id kolonne og gi nytt navn til den opprinnelige filen til lån_1.csv. Last opp lån_1.csv filen til Databaser å lage en tabell loans_1 og lån_2.csv i en S3 bøtte.
Lag en Data Wrangler-flyt
For informasjon om forutsetninger for Data Wrangler, se Kom i gang med Data Wrangler.
La oss komme i gang med å lage en ny dataflyt.
- På Studio-konsollen, på filet meny, velg Ny.
- Velg Data Wrangler flyt.
- Gi nytt navn til flyten som ønsket.
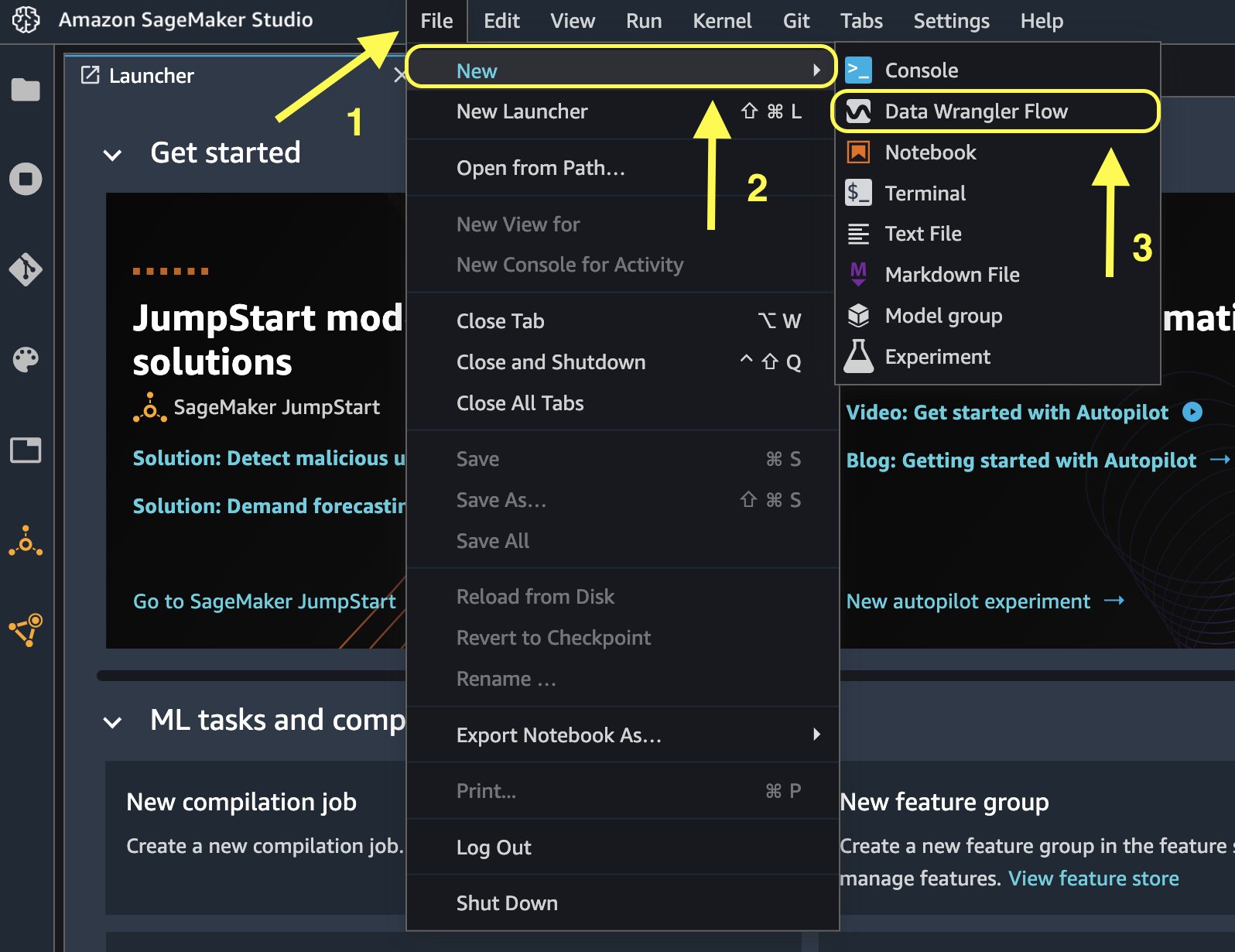
Alternativt kan du opprette en ny dataflyt fra startprogrammet.
- På Studio-konsollen velger du Amazon SageMaker Studio i navigasjonsruten.
- Velg Ny dataflyt.

Det kan ta noen minutter å opprette en ny flyt. Etter at flyten er opprettet, ser du Import datoer side.
Importer data fra Databricks til Data Wrangler
Deretter setter vi opp Databricks (JDBC) som en datakilde i Data Wrangler. For å importere data fra Databricks, må vi først legge til Databricks som en datakilde.
- På Import datoer fanen i Data Wrangler-flyten, velg Legg til datakilde.
- Velg på rullegardinmenyen Databricks (JDBC).
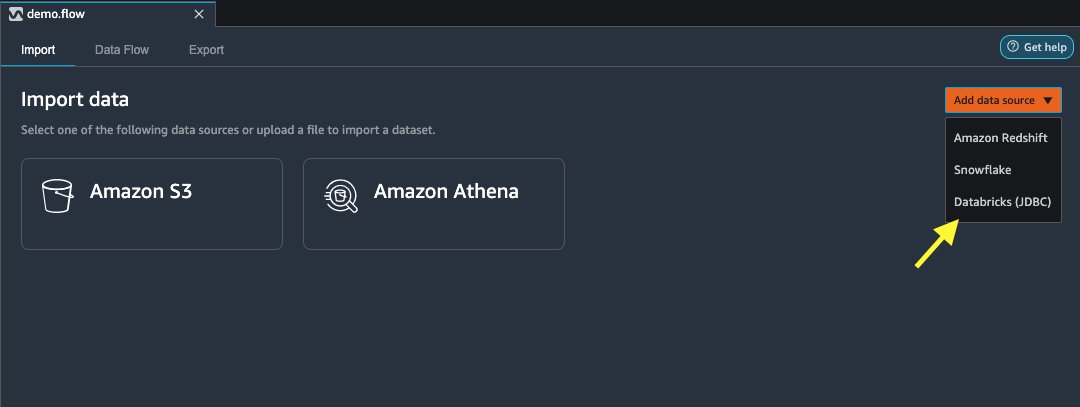
På Importer data fra Databricks side, angir du klyngedetaljene dine.
- Til Datasettnavn, skriv inn et navn du vil bruke i flytfilen.
- Til Driver, velg driveren
com.simba.spark.jdbc.Driver. - Til JDBC URL, skriv inn URL-en til Databricks-klyngen du har fått tidligere.
URL-en skal ligne følgende format jdbc:spark://<serve- hostname>:443/default;transportMode=http;ssl=1;httpPath=<http- path>;AuthMech=3;UID=token;PWD=<personal-access-token>.
- Angi følgende SQL SELECT-setning i SQL-spørringseditoren:
Hvis du valgte et annet tabellnavn mens du laster opp data til Databricks, erstatter du lån_1 i SQL-spørringen ovenfor.
på SQL-spørring i Data Wrangler, kan du spørre hvilken som helst tabell som er koblet til JDBC Databricks-databasen. De forhåndsvalgte Aktiver prøvetaking innstillingen henter de første 50,000 XNUMX radene i datasettet som standard. Avhengig av størrelsen på datasettet, fjerner du valget Aktiver prøvetaking kan føre til lengre importtid.
- Velg Kjør.
Å kjøre spørringen gir en forhåndsvisning av Databricks-datasettet ditt direkte i Data Wrangler.

- Velg Import.

Data Wrangler gir fleksibiliteten til å sette opp flere samtidige tilkoblinger til den ene Databricks-klyngen eller flere klynger om nødvendig, noe som muliggjør analyse og forberedelse på kombinerte datasett.
Importer dataene fra Amazon S3 til Data Wrangler
La oss deretter importere loan_2.csv fil fra Amazon S3.
- På Importer-fanen velger du Amazon S3 som datakilde.

- Naviger til S3-bøtten for
loan_2.csvfilen.
Når du velger CSV-filen, kan du forhåndsvise dataene.
- på Detaljer ruten, velg Avansert konfigurasjon å sørge for at Aktiver prøvetaking er valgt og AVSNITT er valgt for delimiter.
- Velg Import.

Etter loans_2.csv datasettet er vellykket importert, dataflytgrensesnittet viser både Databricks JDBC- og Amazon S3-datakildene.

Bli med dataene
Nå som vi har importert data fra Databricks og Amazon S3, la oss slå sammen datasettene ved å bruke en felles unik identifikatorkolonne.
- På Dataflyt fanen, for Datatyper, velg plusstegnet for
loans_1. - Velg Bli med.
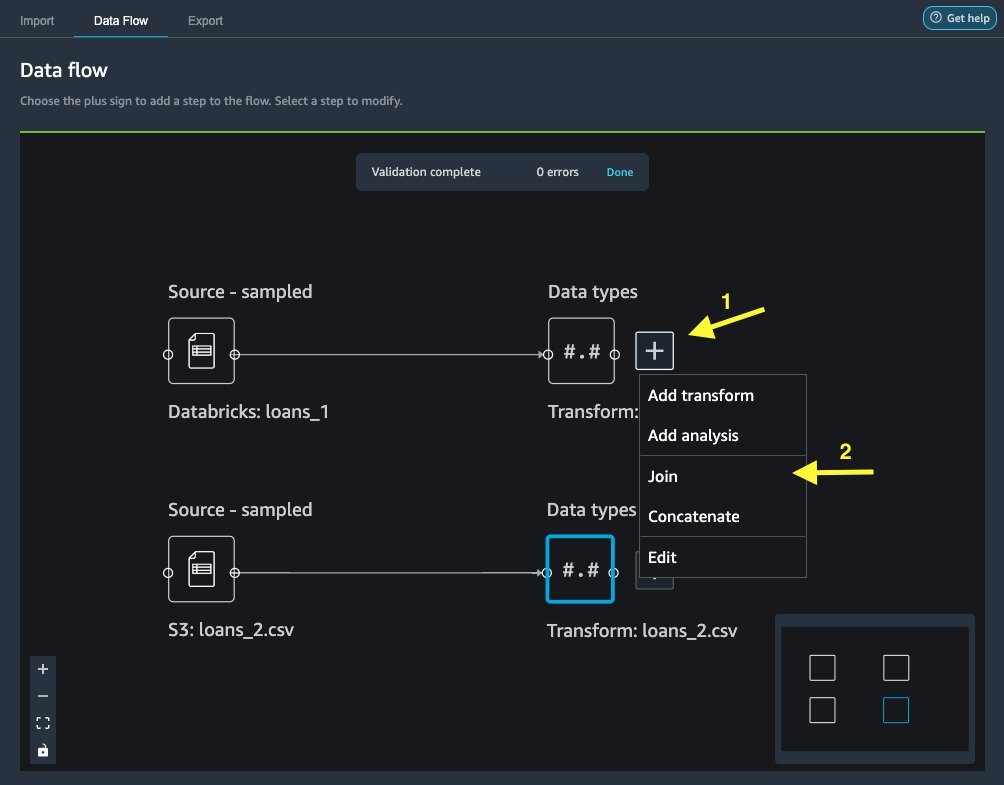
- Velg
loans_2.csvfil som Ikke sant datasett. - Velg Konfigurer for å sette opp sammenføyningskriteriene.
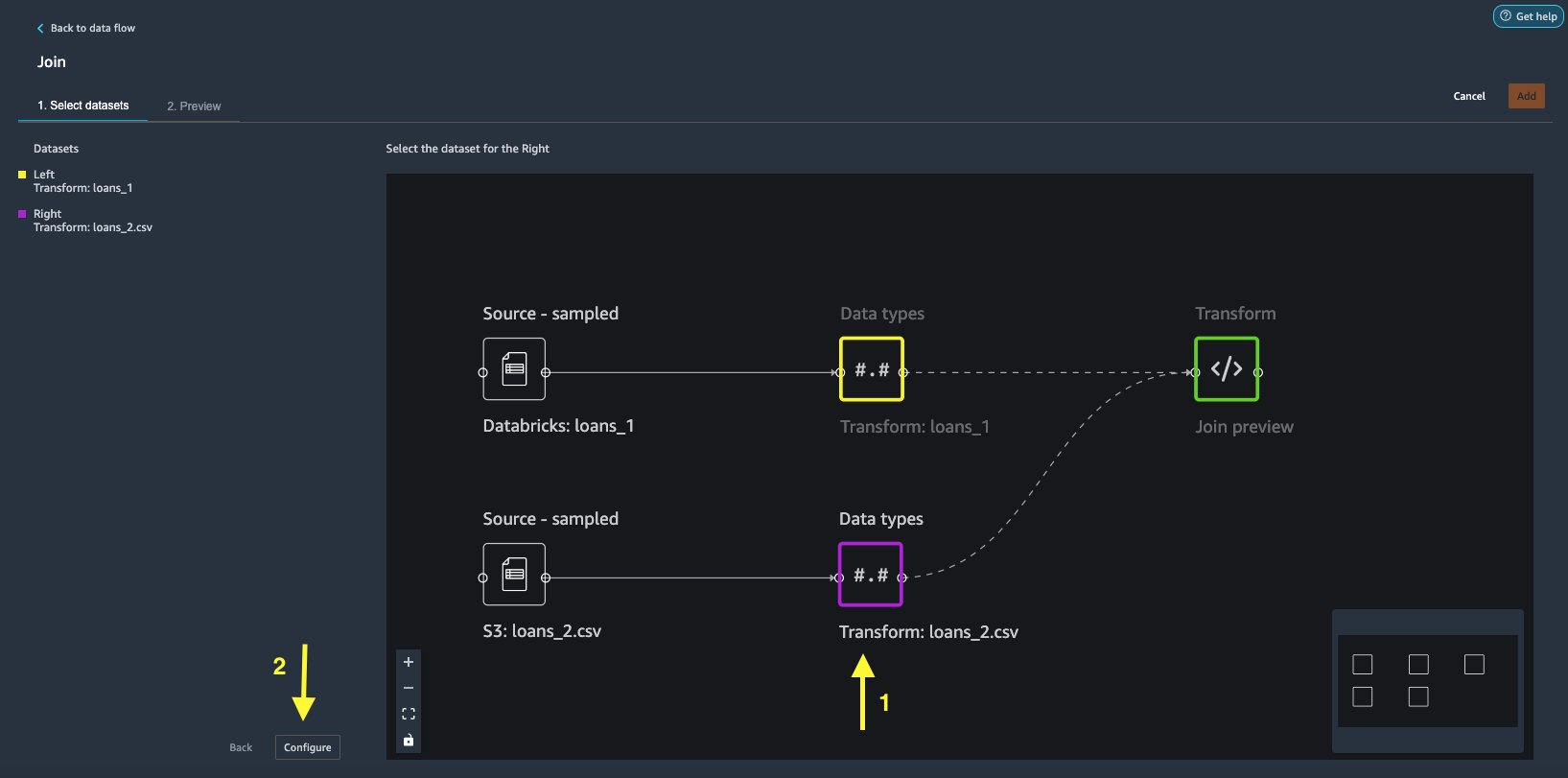
- Til Navn, skriv inn et navn for sammenføyningen.
- Til Bli med type, velg Indre for dette innlegget.
- Velg
idkolonne å bli med på. - Velg Påfør for å forhåndsvise det sammenføyde datasettet.
- Velg Legg til for å legge den til dataflyten.

Bruk transformasjoner
Data Wrangler kommer med over 300 innebygde transformasjoner, som ikke krever noen koding. La oss bruke innebygde transformasjoner for å forberede datasettet.
Slipp kolonne
Først slipper vi den redundante ID-kolonnen.
- Velg plusstegnet på den sammenføyde noden.
- Velg Legg til transform.

- Under Forvandler, velge + Legg til trinn.
- Velg Administrer kolonner.
- Til Transform, velg Slipp kolonne.
- Til Kolonner å slippe, velg kolonnen
id_0. - Velg Forhåndsvisning.
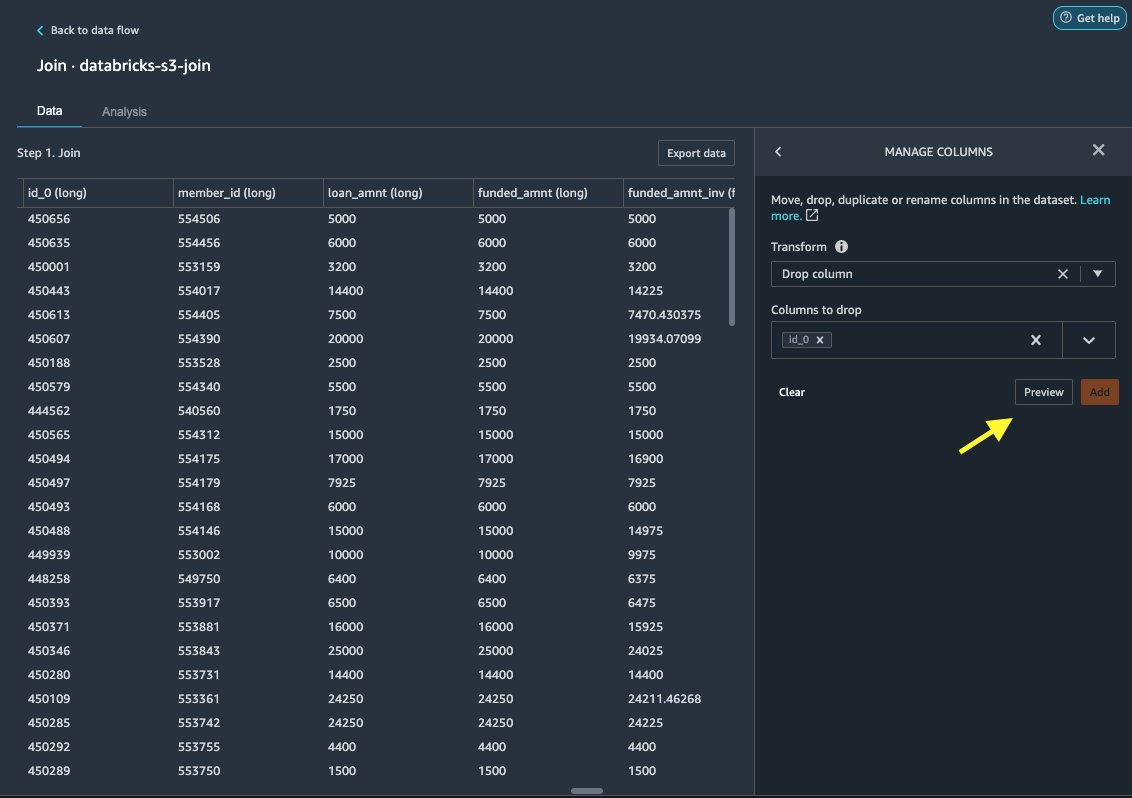
- Velg Legg til.
Formater streng
La oss bruke strengformatering for å fjerne prosentsymbolet fra int_rate og revol_util kolonner.
- På Data under fanen Transforms, velg + Legg til trinn.

- Velg Formater streng.
- Til Transform, velg Fjern tegn fra høyre.
Data Wrangler lar deg bruke den valgte transformasjonen på flere kolonner samtidig.
- Til Inndatakolonner, velg
int_rateogrevol_util. - Til Tegn å fjerne, Tast inn
%. - Velg Forhåndsvisning.

- Velg Legg til.
Fremhev tekst
La oss nå vektorisere verification_status, en tekstfunksjonskolonne. Vi konverterer tekstkolonnen til vektorer for termfrekvens–invers dokumentfrekvens (TF-IDF) ved å bruke tellevektoriseringen og en standard tokenizer som beskrevet nedenfor. Data Wrangler gir også muligheten til å ta med din egen tokenizer, hvis ønskelig.
- Under transformers, velg + Legg til trinn.
- Velg Fremhev tekst.
- Til Transform, velg Vektorer.
- Til Inndatakolonner, velg
verification_status. - Velg Forhåndsvisning.

- Velg Legg til.
Eksporter datasettet
Etter at vi har brukt flere transformasjoner på forskjellige kolonnetyper, inkludert tekst, kategorisk og numerisk, er vi klare til å bruke det transformerte datasettet for opplæring i ML-modeller. Det siste trinnet er å eksportere det transformerte datasettet til Amazon S3. I Data Wrangler har du flere alternativer å velge mellom for nedstrømsforbruk av transformasjonene:
- Velg Eksporter trinn å automatisk generere en Jupyter-notisbok med SageMaker Processing-kode for behandling og eksportere det transformerte datasettet til en S3-bøtte. For mer informasjon, se Start behandlingsjobber med noen få klikk ved hjelp av Amazon SageMaker Data Wrangler.
- Eksporter en Studio-notatbok som lager en SageMaker rørledning med dataflyten din, eller en notatbok som lager en Amazon SageMaker Feature Store funksjonsgruppe og legger til funksjoner i en offline eller nettbasert funksjonsbutikk.
- Velg Eksporter data for å eksportere direkte til Amazon S3.
I dette innlegget drar vi nytte av Eksporter data alternativet i Transform view for å eksportere det transformerte datasettet direkte til Amazon S3.
- Velg Eksporter data.

- Til S3 beliggenhet, velg Søk og velg din S3-bøtte.
- Velg Eksporter data.
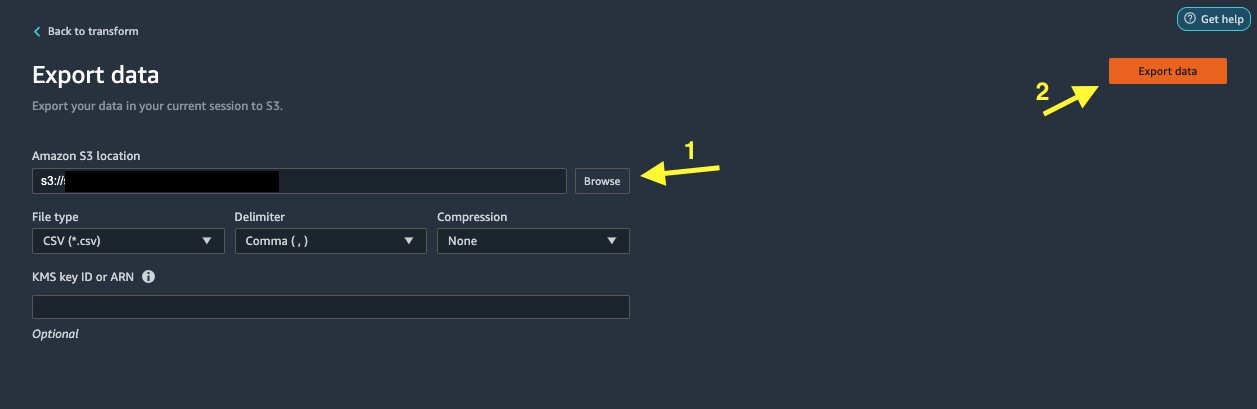
Rydd opp
Hvis arbeidet ditt med Data Wrangler er fullført, slå av Data Wrangler-forekomsten for å unngå å pådra seg ekstra avgifter.
konklusjonen
I dette innlegget dekket vi hvordan du raskt og enkelt kan sette opp og koble til Databricks som en datakilde i Data Wrangler, interaktivt spørre data lagret i Databricks ved hjelp av SQL, og forhåndsvise data før import. I tillegg har vi sett på hvordan du kan slå sammen dataene dine i Databricks med data lagret i Amazon S3. Vi brukte deretter datatransformasjoner på det kombinerte datasettet for å lage en dataforberedelsespipeline. For å utforske flere data Wranglers analysefunksjoner, inkludert mållekkasje og generering av skjevhetsrapporter, se følgende blogginnlegg Akselerer dataforberedelsen ved å bruke Amazon SageMaker Data Wrangler for gjeninnleggelse av diabetikere.
For å komme i gang med Data Wrangler, se Forbered ML-data med Amazon SageMaker Data Wrangler, og se den nyeste informasjonen om Data Wrangler produktside.
Om forfatterne
 Roop Bains er en løsningsarkitekt hos AWS med fokus på AI/ML. Han brenner for å hjelpe kunder med å innovere og nå forretningsmålene sine ved å bruke kunstig intelligens og maskinlæring. På fritiden liker Roop å lese og gå på tur.
Roop Bains er en løsningsarkitekt hos AWS med fokus på AI/ML. Han brenner for å hjelpe kunder med å innovere og nå forretningsmålene sine ved å bruke kunstig intelligens og maskinlæring. På fritiden liker Roop å lese og gå på tur.
 Igor Alekseev er partnerløsningsarkitekt hos AWS i data og analyse. Igor jobber med strategiske partnere som hjelper dem med å bygge komplekse, AWS-optimaliserte arkitekturer. Før han begynte i AWS, som Data/Solution Architect, implementerte han mange prosjekter i Big Data, inkludert flere datainnsjøer i Hadoop-økosystemet. Som dataingeniør var han involvert i å bruke AI/ML til svindeloppdagelse og kontorautomatisering. Igors prosjekter var i en rekke bransjer, inkludert kommunikasjon, finans, offentlig sikkerhet, produksjon og helsevesen. Tidligere jobbet Igor som fullstack-ingeniør/teknologisk leder.
Igor Alekseev er partnerløsningsarkitekt hos AWS i data og analyse. Igor jobber med strategiske partnere som hjelper dem med å bygge komplekse, AWS-optimaliserte arkitekturer. Før han begynte i AWS, som Data/Solution Architect, implementerte han mange prosjekter i Big Data, inkludert flere datainnsjøer i Hadoop-økosystemet. Som dataingeniør var han involvert i å bruke AI/ML til svindeloppdagelse og kontorautomatisering. Igors prosjekter var i en rekke bransjer, inkludert kommunikasjon, finans, offentlig sikkerhet, produksjon og helsevesen. Tidligere jobbet Igor som fullstack-ingeniør/teknologisk leder.
 Huong Nguyen er Sr. Product Manager i AWS. Hun leder brukeropplevelsen for SageMaker Studio. Hun har 13 års erfaring med å skape kunde-besatte og datadrevne produkter for både bedrifts- og forbrukerlokaler. På fritiden liker hun å lese, være i naturen og tilbringe tid med familien.
Huong Nguyen er Sr. Product Manager i AWS. Hun leder brukeropplevelsen for SageMaker Studio. Hun har 13 års erfaring med å skape kunde-besatte og datadrevne produkter for både bedrifts- og forbrukerlokaler. På fritiden liker hun å lese, være i naturen og tilbringe tid med familien.
 Henry Wang er en programvareutviklingsingeniør ved AWS. Han begynte nylig i Data Wrangler-teamet etter endt utdanning fra UC Davis. Han har en interesse for datavitenskap og maskinlæring og driver med 3D-printing som en hobby.
Henry Wang er en programvareutviklingsingeniør ved AWS. Han begynte nylig i Data Wrangler-teamet etter endt utdanning fra UC Davis. Han har en interesse for datavitenskap og maskinlæring og driver med 3D-printing som en hobby.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. FRI TILGANG.
- CryptoHawk. Altcoin Radar. Gratis prøveperiode.
- Kilde: https://aws.amazon.com/blogs/machine-learning/prepare-data-from-databricks-for-machine-learning-using-amazon-sagemaker-data-wrangler/
- "
- 000
- 100
- 39
- 3d
- Om oss
- adgang
- imøtekomme
- Ytterligere
- avansert
- Fordel
- algoritmer
- Alle
- Amazon
- analyse
- analytics
- påføring
- arkitektur
- kunstig
- kunstig intelligens
- Kunstig intelligens og maskinlæring
- tildelt
- Automatisering
- AWS
- være
- BEST
- Store data
- Blogg
- grensen
- bygge
- innebygd
- virksomhet
- evner
- saker
- Velg
- Rengjøring
- klubb
- kode
- Koding
- Kolonne
- kombinert
- Felles
- kommunikasjon
- komplekse
- Konfigurasjon
- tilkoblet
- tilkobling
- Tilkoblinger
- hensyn
- Konsoll
- konsolidering
- forbruker
- forbruk
- inneholder
- opprettet
- skaper
- Opprette
- Gjeldende
- Kunder
- dato
- datavitenskap
- Database
- forsinkelse
- avhengig
- Gjenkjenning
- Utvikling
- forskjellig
- direkte
- skjermer
- ned
- sjåfør
- Drop
- lett
- økosystem
- redaktør
- muliggjøre
- muliggjør
- ingeniør
- Ingeniørarbeid
- Enter
- Enterprise
- eksempel
- Unntatt
- gjennomføring
- erfaring
- utforske
- familie
- Trekk
- Egenskaper
- avgifter
- finansiere
- Først
- fleksibilitet
- flyten
- etter
- format
- svindel
- fullt
- generere
- generasjonen
- god
- styresett
- Gruppe
- helsetjenester
- hjelpe
- Hvordan
- HTTPS
- Identitet
- implementert
- viktig
- importere
- Inkludert
- bransjer
- informasjon
- innsikt
- Intelligens
- interesse
- Interface
- investering
- involvert
- IT
- Jobb
- bli medlem
- ble med
- etiketter
- Språk
- siste
- føre
- ledende
- læring
- utlån
- Lån
- så
- maskin
- maskinlæring
- leder
- produksjon
- ML
- modell
- modeller
- mer
- flere
- Naturlig
- Natur
- Navigasjon
- Nye funksjoner
- bærbare
- Tilbud
- offline
- på nett
- Alternativ
- alternativer
- rekkefølge
- egen
- partner
- partnere
- lidenskapelig
- betaling
- prosent
- ytelse
- personlig
- fase
- plattform
- politikk
- Spådommer
- Forhåndsvisning
- prosess
- Produkt
- Produkter
- Programmering
- prosjekter
- gir
- gi
- offentlig
- formål
- raskt
- Raw
- Lesning
- redusere
- rapporterer
- krever
- påkrevd
- ansvarlig
- rennende
- Sikkerhet
- Vitenskap
- forskere
- valgt
- Serien
- tjeneste
- sett
- innstilling
- signifikant
- Enkelt
- Størrelse
- Software
- programvareutvikling
- løsning
- Solutions
- mellomrom
- bruke
- utgifter
- splittet
- stable
- Standard
- Begynn
- startet
- Uttalelse
- status
- lagring
- oppbevare
- Strategisk
- sterk
- studio
- vellykket
- støtte
- Target
- lag
- Gjennom
- tid
- Kurs
- Transform
- Transformation
- ui
- unik
- Oppdater
- bruke
- variasjon
- ulike
- mens
- uten
- Arbeid
- arbeidet
- virker
- skriving