Store oppmerksomhetsbaserte transformatormodeller har oppnådd enorme gevinster på naturlig språkbehandling (NLP). Men å trene disse gigantiske nettverkene fra bunnen av krever en enorm mengde data og databehandling. For mindre NLP-datasett er en enkel, men effektiv strategi å bruke en forhåndstrent transformator, vanligvis trent på en uovervåket måte på svært store datasett, og finjustere den på datasettet av interesse. Klemme ansiktet opprettholder en stor dyreparkmodell av disse ferdigtrente transformatorene og gjør dem lett tilgjengelige selv for nybegynnere.
Men finjustering av disse modellene krever fortsatt ekspertkunnskap, fordi de er ganske følsomme for hyperparametrene deres, for eksempel læringshastighet eller batchstørrelse. I dette innlegget viser vi hvordan du kan optimalisere disse hyperparametrene med åpen kildekode-rammeverket Syne Tune for distribuert hyperparameteroptimalisering (HPO). Syne Tune lar oss finne en bedre hyperparameterkonfigurasjon som oppnår en relativ forbedring mellom 1-4 % sammenlignet med standard hyperparametere på populære LIM referansedatasett. Selve valget av den forhåndstrente modellen kan også betraktes som en hyperparameter og velges derfor automatisk av Syne Tune. På et tekstklassifiseringsproblem fører dette til en ekstra økning i nøyaktighet på omtrent 5 % sammenlignet med standardmodellen. Vi kan imidlertid automatisere flere beslutninger en bruker må ta; vi demonstrerer dette ved også å eksponere typen instans som en hyperparameter som vi senere bruker for å distribuere modellen. Ved å velge riktig forekomsttype kan vi finne konfigurasjoner som optimalt avveier kostnader og ventetid.
For en introduksjon til Syne Tune, se Kjør distribuerte hyperparameter- og nevralarkitekturjusteringsjobber med Syne Tune.
Hyperparameteroptimalisering med Syne Tune
Vi vil bruke LIM benchmark suite, som består av ni datasett for naturlig språkforståelsesoppgaver, for eksempel gjenkjenning av tekst eller sentimentanalyse. Til det tilpasser vi Hugging Face's run_glue.py treningsmanus. GLUE-datasett kommer med et forhåndsdefinert trenings- og evalueringssett med etiketter samt et hold-out-testsett uten etiketter. Derfor deler vi opplæringssettet inn i et trenings- og valideringssett (70 %/30 % delt) og bruker evalueringssettet som vårt holdout-testdatasett. Videre legger vi til en annen tilbakeringingsfunksjon til Hugging Faces Trainer API som rapporterer valideringsytelsen etter hver epoke tilbake til Syne Tune. Se følgende kode:
Vi starter med å optimalisere typiske treningshyperparametre: læringshastigheten, oppvarmingsraten for å øke læringshastigheten og batchstørrelsen for finjustering av en forhåndstrent BERT (bert-base-hus) modell, som er standardmodellen i Hugging Face-eksemplet. Se følgende kode:
Som vår HPO-metode bruker vi ASHA, som sampler hyperparameterkonfigurasjoner jevnt tilfeldig og iterativt stopper evalueringen av konfigurasjoner med dårlig ytelse. Selv om mer sofistikerte metoder bruker en probabilistisk modell av den objektive funksjonen, slik som BO eller MoBster eksisterer, bruker vi ASHA for dette innlegget fordi det kommer uten noen forutsetninger om søkeområdet.
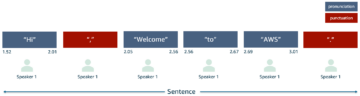
I den følgende figuren sammenligner vi den relative forbedringen i testfeil i forhold til Hugging Faces' standard hyperparameterkonfigurasjon.
![]()
For enkelhets skyld begrenser vi sammenligningen til MRPC, COLA og STSB, men vi observerer også lignende forbedringer også for andre GLUE-datasett. For hvert datasett kjører vi ASHA på en enkelt ml.g4dn.xlarge Amazon SageMaker forekomst med et kjøretidsbudsjett på 1,800 sekunder, som tilsvarer henholdsvis ca. 13, 7 og 9 fullfunksjonsevalueringer på disse datasettene. For å ta hensyn til den iboende tilfeldigheten i opplæringsprosessen, for eksempel forårsaket av mini-batch-sampling, kjører vi både ASHA og standardkonfigurasjonen for fem repetisjoner med et uavhengig frø for tilfeldig tallgeneratoren og rapporterer gjennomsnittet og standardavviket til relativ forbedring på tvers av repetisjonene. Vi kan se at vi på tvers av alle datasett faktisk kan forbedre prediktiv ytelse med 1-3 % i forhold til ytelsen til den nøye utvalgte standardkonfigurasjonen.
Automatiser valg av forhåndsopplært modell
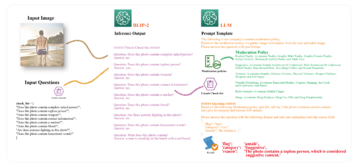
Vi kan bruke HPO til ikke bare å finne hyperparametere, men også automatisk velge riktig forhåndstrent modell. Hvorfor ønsker vi å gjøre dette? Fordi ingen enkelt modell overgår alle datasett, må vi velge riktig modell for et spesifikt datasett. For å demonstrere dette, vurderer vi en rekke populære transformatormodeller fra Hugging Face. For hvert datasett rangerer vi hver modell etter testytelsen. Rangeringen på tvers av datasett (se følgende figur) endres og ikke én enkelt modell som skårer høyest på hvert datasett. Som referanse viser vi også den absolutte testytelsen til hver modell og datasett i følgende figur.
For automatisk å velge riktig modell, kan vi kaste valget av modellen som kategoriske parametere og legge dette til vårt hyperparametersøkeområde:
Selv om søkeområdet nå er større, betyr ikke det nødvendigvis at det er vanskeligere å optimalisere. Følgende figur viser testfeilen for den best observerte konfigurasjonen (basert på valideringsfeilen) på MRPC-datasettet til ASHA over tid når vi søker i det opprinnelige rommet (blå linje) (med en BERT-basert, forhåndstrent modell ) eller i det nye utvidede søkefeltet (oransje linje). Gitt det samme budsjettet, er ASHA i stand til å finne en hyperparameterkonfigurasjon med mye bedre resultater i det utvidede søkeområdet enn i det mindre området.
![]()
Automatiser valg av forekomsttype
I praksis bryr vi oss kanskje ikke bare om å optimalisere prediktiv ytelse. Vi kan også bry oss om andre mål, for eksempel treningstid, (dollar) kostnader, ventetid eller rettferdighetsmålinger. Vi må også gjøre andre valg utover hyperparametrene til modellen, for eksempel å velge instanstype.
Selv om forekomsttypen ikke påvirker prediktiv ytelse, har den stor innvirkning på (dollar)kostnadene, treningstiden og ventetiden. Det siste blir spesielt viktig når modellen utplasseres. Vi kan formulere HPO som et multi-objektiv optimaliseringsproblem, der vi tar sikte på å optimalisere flere mål samtidig. Ingen enkelt løsning optimaliserer imidlertid alle beregninger samtidig. I stedet tar vi sikte på å finne et sett med konfigurasjoner som optimalt bytter det ene målet mot det andre. Dette kalles Pareto sett.
For å analysere denne innstillingen videre, legger vi til valget av forekomsttype som en ekstra kategorisk hyperparameter til søkeområdet vårt:
Vi bruker MO-ASHA, som tilpasser ASHA til multi-objektiv scenariet ved å bruke ikke-dominert sortering. I hver iterasjon velger MO-ASHA også for hver konfigurasjon også hvilken type forekomst vi ønsker å evaluere den på. For å kjøre HPO på et heterogent sett med forekomster, tilbyr Syne Tune SageMaker-backend. Med denne backend blir hver prøveversjon evaluert som en uavhengig SageMaker-treningsjobb på sin egen instans. Antall arbeidere definerer hvor mange SageMaker-jobber vi kjører parallelt på et gitt tidspunkt. Selve optimizeren, MO-ASHA i vårt tilfelle, kjører enten på den lokale maskinen, en Sagemaker-notisbok eller på en egen SageMaker-treningsjobb. Se følgende kode:
De følgende figurene viser latens vs testfeil til venstre og latens vs kostnad til høyre for tilfeldige konfigurasjoner samplet av MO-ASHA (vi begrenser aksen for synlighet) på MRPC-datasettet etter å ha kjørt det i 10,800 XNUMX sekunder på fire arbeidere. Farge angir forekomsttypen. Den stiplede svarte linjen representerer Pareto-settet, som betyr settet med punkter som dominerer alle andre punkter i minst ett mål.
Vi kan observere en avveining mellom latens og testfeil, noe som betyr at den beste konfigurasjonen med den laveste testfeilen ikke oppnår den laveste latensen. Basert på dine preferanser kan du velge en hyperparameterkonfigurasjon som ofrer testytelsen, men som kommer med en mindre ventetid. Vi ser også avveiningen mellom ventetid og kostnad. Ved å bruke en mindre ml.g4dn.xlarge-forekomst, for eksempel, øker vi bare marginalt latensen, men betaler en fjerdedel av kostnaden for en ml.g4dn.8xlarge-forekomst.
konklusjonen
I dette innlegget diskuterte vi hyperparameteroptimalisering for finjustering av ferdigtrente transformatormodeller fra Hugging Face basert på Syne Tune. Vi så at ved å optimalisere hyperparametre som læringshastighet, batchstørrelse og oppvarmingsforhold, kan vi forbedre den nøye valgte standardkonfigurasjonen. Vi kan også utvide dette ved automatisk å velge den forhåndstrente modellen via hyperparameteroptimalisering.
Ved hjelp av Syne Tunes SageMaker-backend kan vi behandle instanstypen som en hyperparameter. Selv om forekomsttypen ikke påvirker ytelsen, har den en betydelig innvirkning på ventetiden og kostnadene. Derfor, ved å caste HPO som et multi-objektiv optimaliseringsproblem, er vi i stand til å finne et sett med konfigurasjoner som optimalt bytter det ene målet mot det andre. Hvis du vil prøve dette selv, sjekk ut vår eksempel notisbok.
Om forfatterne
![]() Aaron Klein er en Applied Scientist ved AWS.
Aaron Klein er en Applied Scientist ved AWS.
![]() Matthias Seeger er Principal Applied Scientist ved AWS.
Matthias Seeger er Principal Applied Scientist ved AWS.
![]() David Salinas er en Sr Applied Scientist ved AWS.
David Salinas er en Sr Applied Scientist ved AWS.
![]() Emily Webber ble med i AWS like etter at SageMaker ble lansert, og har prøvd å fortelle verden om det siden den gang! Utenom å bygge nye ML-opplevelser for kunder, liker Emily å meditere og studere tibetansk buddhisme.
Emily Webber ble med i AWS like etter at SageMaker ble lansert, og har prøvd å fortelle verden om det siden den gang! Utenom å bygge nye ML-opplevelser for kunder, liker Emily å meditere og studere tibetansk buddhisme.
![]() Cedric Archambeau er hovedforsker ved AWS og stipendiat ved European Lab for Learning and Intelligent Systems.
Cedric Archambeau er hovedforsker ved AWS og stipendiat ved European Lab for Learning and Intelligent Systems.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. FRI TILGANG.
- CryptoHawk. Altcoin Radar. Gratis prøveperiode.
- Kilde: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- Om oss
- Absolute
- tilgjengelig
- Logg inn
- Oppnå
- tvers
- Ytterligere
- påvirke
- Alle
- tillater
- Selv
- Amazon
- beløp
- analyse
- analysere
- En annen
- api
- anvendt
- ca
- arkitektur
- augmented
- automatisere
- automatisk
- gjennomsnittlig
- AWS
- Axis
- fordi
- benchmark
- BEST
- Bedre
- mellom
- Beyond
- Svart
- pin
- øke
- budsjett
- Bygning
- hvilken
- saken
- forårsaket
- valg
- valg
- valgt ut
- klasse
- klassifisering
- kode
- Kom
- sammenlignet
- Beregn
- Konfigurasjon
- kontroll
- Kunder
- dato
- avgjørelser
- demonstrere
- utplassere
- utplassert
- distribueres
- ikke
- Dollar
- hver enkelt
- lett
- Effektiv
- europeisk
- evaluere
- evaluering
- eksempel
- Erfaringer
- Expert
- utvide
- Face
- Mote
- Figur
- etter
- Rammeverk
- fra
- fullt
- funksjon
- videre
- Dess
- generator
- hjelpe
- her.
- Hvordan
- Hvordan
- Men
- HTTPS
- Påvirkning
- viktig
- forbedre
- forbedring
- Øke
- uavhengig
- påvirke
- f.eks
- Intelligent
- interesse
- IT
- selv
- Jobb
- Jobb
- ble med
- kunnskap
- lab
- etiketter
- Språk
- stor
- større
- lansert
- Fører
- læring
- BEGRENSE
- linje
- lokal
- maskin
- gjøre
- GJØR AT
- massive
- betyr
- metoder
- Metrics
- kunne
- ML
- modell
- modeller
- mer
- flere
- Naturlig
- nødvendigvis
- behov
- nettverk
- bærbare
- Antall
- mål
- innhentet
- optimalisering
- Optimalisere
- optimalisere
- original
- Annen
- egen
- spesielt
- Betale
- ytelse
- utfører
- vær så snill
- poeng
- Populær
- praksis
- Principal
- Problem
- prosess
- prosessering
- gir
- område
- Ranking
- rapporterer
- reporter
- Rapporter
- representerer
- Krever
- Resultater
- Kjør
- rennende
- samme
- Forsker
- Søk
- sekunder
- seed
- valgt
- sentiment
- sett
- innstilling
- Vis
- signifikant
- lignende
- Enkelt
- enkelt
- Størrelse
- løsning
- sofistikert
- Rom
- spesifikk
- splittet
- Standard
- Begynn
- Tilstand
- Still
- Strategi
- Systemer
- oppgaver
- test
- De
- verden
- derfor
- tid
- handel
- Kurs
- behandle
- enorm
- prøve
- forståelse
- us
- bruke
- Brukere
- vanligvis
- bruke
- validering
- synlighet
- Wikipedia
- uten
- arbeidere
- verden
- Din