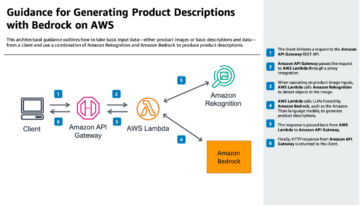
I varevisningen er elementer gitt i form av en tidsbestemt liste, der hvert element inneholder ytterligere metadatainformasjon:
{ "results": { "items": [ { "channel_label": "ch_0", "start_time": "1.509", "speaker_label": "spk_0", "end_time": "2.21", "alternatives": [ { "confidence": "0.999", "content": "Hi" } ], "type": "pronunciation" }, { "channel_label": "ch_0", "speaker_label": "spk_0", "alternatives": [ { "confidence": "0.0", "content": "," } ], "type": "punctuation" }, { "channel_label": "ch_0", "start_time": "2.22", "speaker_label": "spk_0", "end_time": "2.9", "alternatives": [ { "confidence": "0.999", "content": "welcome" } ], "type": "pronunciation" }, { "channel_label": "ch_0", "speaker_label": "spk_0", "alternatives": [ { "confidence": "0.0", "content": "." } ], "type": "punctuation" } ] }
}
Metadataene er som følger:
- typen – Typeverdien indikerer om det spesifikke elementet er en tegnsetting eller en uttale. Eksempler på støttede tegnsettinger er komma, punktum og spørsmålstegn.
- Alternatives – En rekke objekter som inneholder den faktiske transkripsjonen, sammen med konfidensnivå, sortert etter konfidensnivå. Når alternative resultatfunksjonen ikke er aktivert, har denne listen alltid bare ett element.
- Tillit – En indikasjon på hvor sikker Amazon Transcribe er på om transkripsjonen er korrekt. Den bruker verdier fra 0–1, med 1 som indikerer 100 % konfidens.
- Innhold – Det transkriberte ordet.
- Starttid – En tidspeker for lyd- eller videofilen som indikerer starten på elementet i ss.SSS-format.
- Sluttid – En tidspeker for lyd- eller videofilen som indikerer slutten av elementet i ss.SSS-format.
- Kanaletikett – Kanalidentifikatoren, som bare finnes i elementet når kanalidentifikasjonsfunksjonen var aktivert i jobbkonfigurasjonen.
- Høyttaleretikett – Høyttaleridentifikatoren, som bare finnes i elementet når funksjonen for høyttalerpartisjonering var aktivert i jobbkonfigurasjonen.
Identifiser avsnitt
Identifikasjon av avsnitt er avhengig av metadatainformasjon i elementvisningen. Spesielt bruker vi informasjon om start og sluttid sammen med transkripsjonstype og innhold for å identifisere setninger og deretter bestemme hvilke setninger som er de beste kandidatene for avsnittsinngang.
En setning anses å være en liste over transkripsjonselementer som eksisterer mellom tegnsettingselementer som indikerer punktum. Unntak fra dette er starten og slutten av transkripsjonen, som som standard er setningsgrenser. Følgende figur viser et eksempel på disse elementene.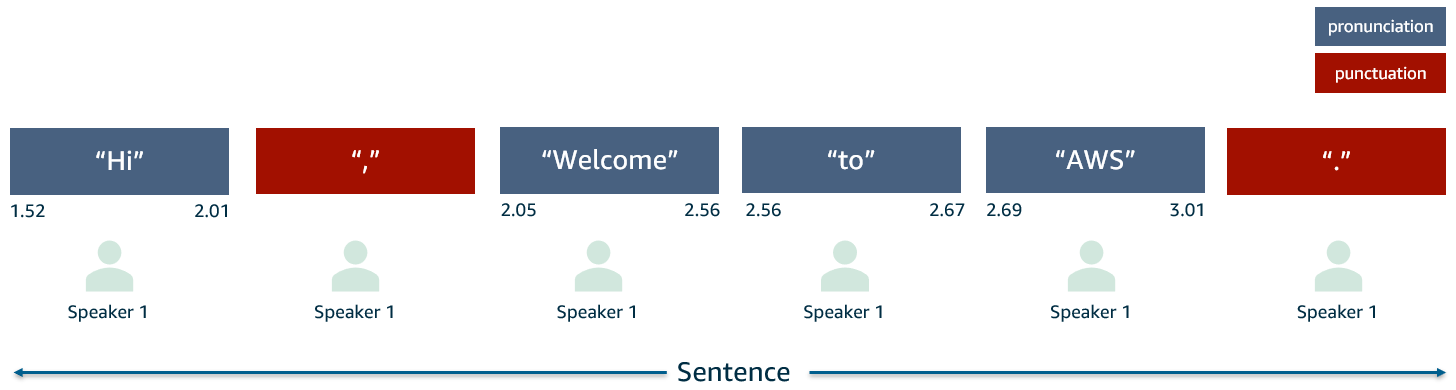
Setningsidentifikasjon er enkel med Amazon Transcribe fordi tegnsetting er en klar funksjon, sammen med tegnsettingstypene komma, punktum, spørsmålstegn. I dette konseptet bruker vi et punktum som setningsgrense.
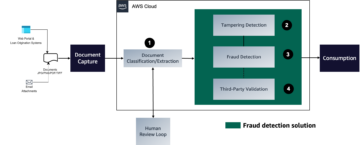
Ikke hver setning skal være et avsnittspunkt. For å identifisere avsnitt introduserer vi en ny innsikt på setningsnivå som kalles en startforsinkelse, som illustrert i følgende figur. Vi bruker en startforsinkelse for å definere tidsforsinkelsen taleren introduserer for uttalen av gjeldende setning i forhold til den forrige.
Beregning av startforsinkelse krever starttidspunkt for gjeldende setning og sluttid for forrige per taler. Fordi Amazon Transcribe gir start- og sluttider per element, krever beregningen bruk av de første og siste elementene i henholdsvis gjeldende og forrige setning.
Når vi kjenner startforsinkelsene for hver setning, kan vi bruke statistisk analyse og finne ut betydningen av hver forsinkelse sammenlignet med den totale populasjonen av forsinkelser. I vår sammenheng er betydelige forsinkelser de som er over befolkningens typiske varighet. Følgende graf viser et eksempel.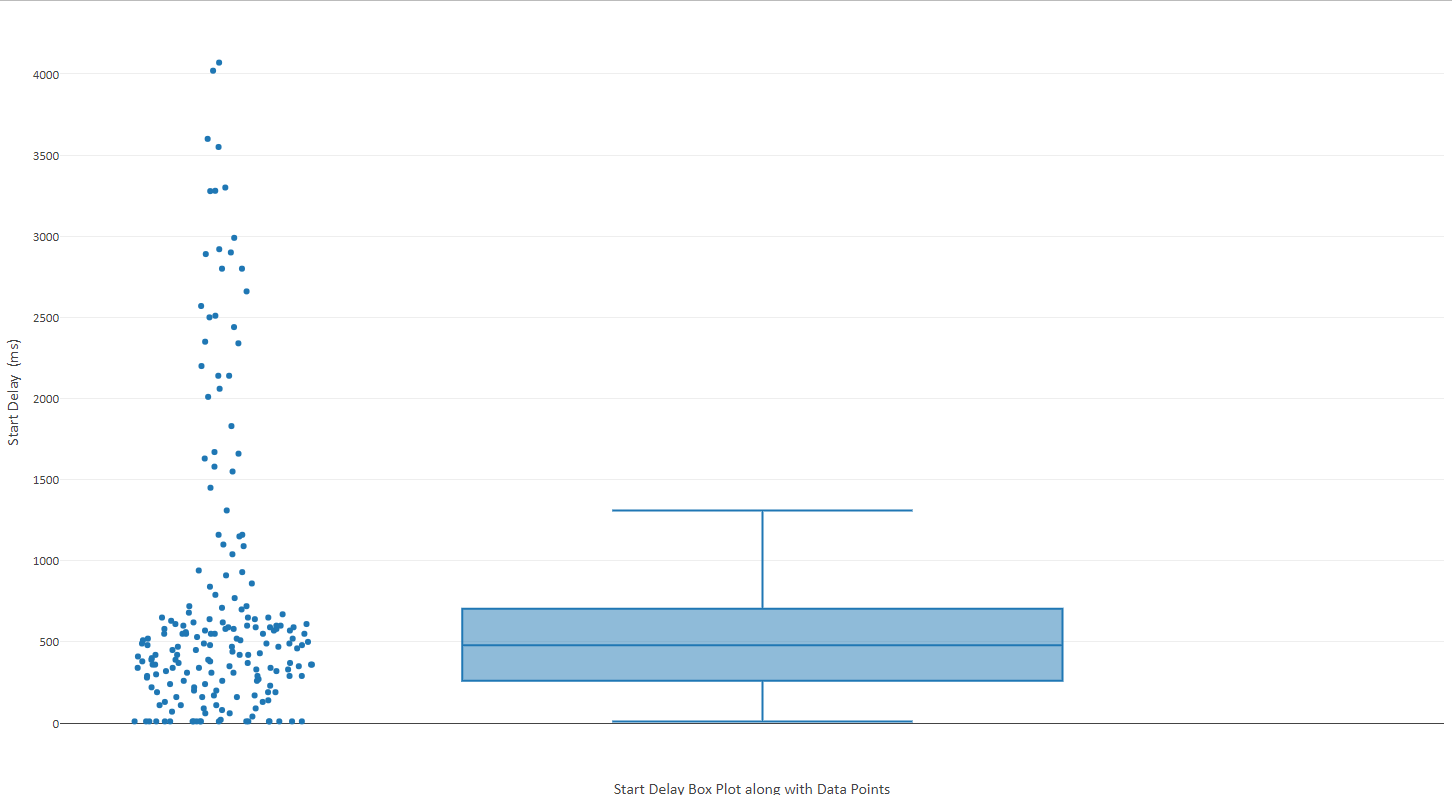
For dette konseptet bestemmer vi oss for å akseptere setninger med startforsinkelser større enn gjennomsnittsverdien som signifikante, og innføre et avsnittspunkt i begynnelsen av hver slik setning. Bortsett fra middelverdien, er det andre alternativer, som å akseptere alle startforsinkelser som er større enn medianen, eller tredje kvantil eller øvre gjerdeverdi for befolkningen.
Vi legger til ett ekstra trinn til avsnittsidentifikasjonsprosessen, og tar i betraktning antall ord som inneholder hvert avsnitt. Når avsnitt inneholder et betydelig antall ord, kjører vi en delt operasjon, og legger dermed til ett avsnitt til i sluttresultatet.
I sammenheng med ordtellinger definerer vi som signifikante ordtellinger som overstiger øvre gjerdeverdi. Vi tar denne avgjørelsen bevisst, slik at vi begrenser delte operasjoner til avsnittene som virkelig oppfører seg som uteliggere i resultatene våre. Følgende graf viser et eksempel.
Delingsoperasjonen velger det nye avsnittsinngangspunktet ved å vurdere maksimal innsikt i setningsstartforsinkelse. På denne måten introduseres det nye avsnittet ved setningen som viser den maksimale startforsinkelsen i gjeldende avsnitt. Splittinger kan gjentas inntil ingen ordtelling overskrider den valgte grensen, i vårt tilfelle den øvre gjerdeverdien. Følgende figur viser et eksempel.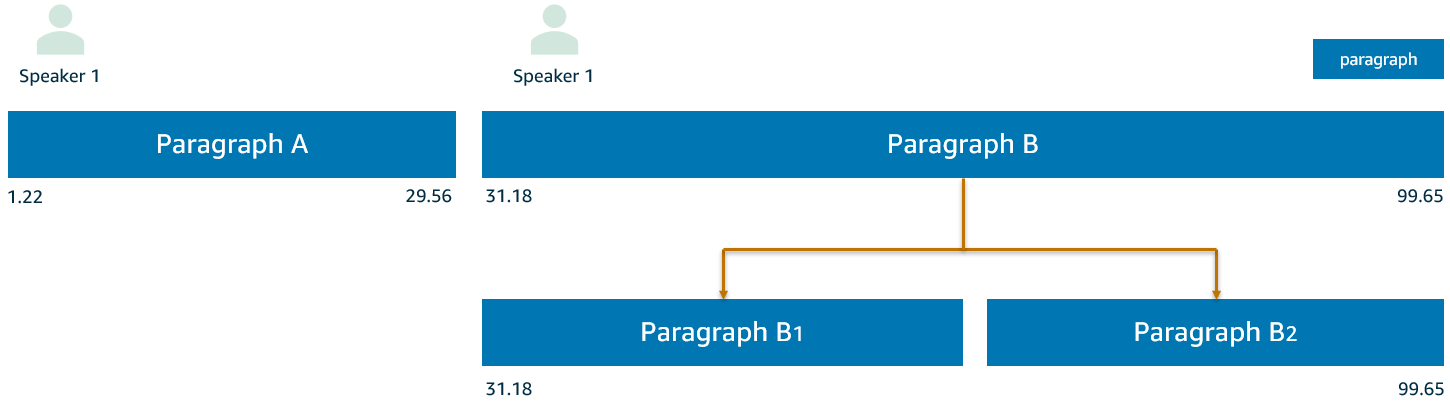
konklusjonen
I dette innlegget presenterte vi et konsept for automatisk å introdusere avsnitt til transkripsjonene dine, uten manuell inngripen, basert på metadataene Amazon Transcribe gir sammen med selve transkripsjonen.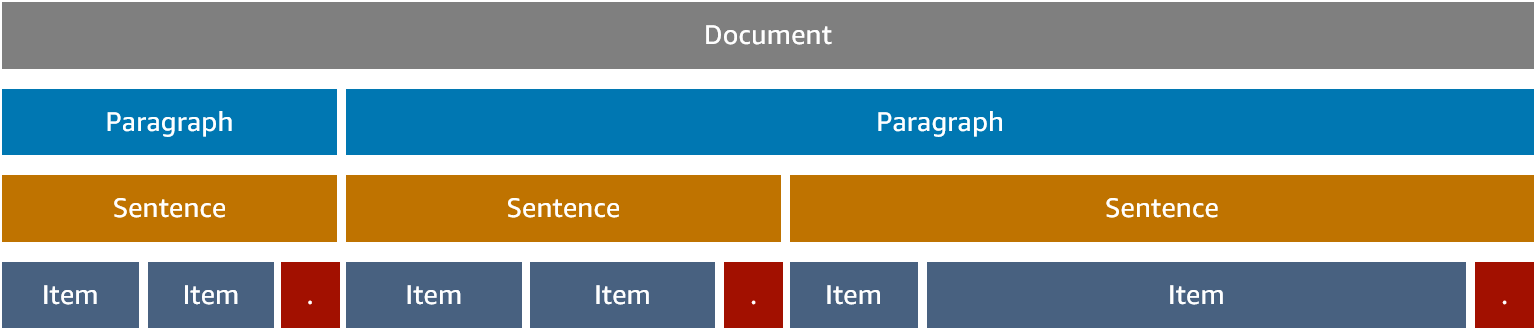
Dette konseptet er ikke språk- eller aksentspesifikt, fordi det er avhengig av ikke-språklige metadata for å foreslå avsnittsinngangspunkter. Fremtidige variasjoner kan inkludere grammatisk eller semantisk informasjon om en sak per språk, noe som ytterligere forbedrer avsnittsidentifikasjonslogikken.
Hvis du har tilbakemeldinger om dette innlegget, send inn kommentarene dine i kommentarfeltet. Vi ser frem til å høre fra deg. Sjekk ut Amazon-transkriberingsfunksjoner for tilleggsfunksjoner som vil hjelpe deg å få mest mulig ut av transkripsjonene dine.
Om forfatterne
![]() Kostas Tzouvanas er en Enterprise Solution Architect hos Amazon Web Services. Han hjelper kunder med å bygge skybaserte løsninger for å oppnå forretningspotensialet deres. Hans hovedfokus er handelsplattformer og høyytelses datasystemer. Han er også lidenskapelig opptatt av genomikk og bioinformatikk.
Kostas Tzouvanas er en Enterprise Solution Architect hos Amazon Web Services. Han hjelper kunder med å bygge skybaserte løsninger for å oppnå forretningspotensialet deres. Hans hovedfokus er handelsplattformer og høyytelses datasystemer. Han er også lidenskapelig opptatt av genomikk og bioinformatikk.
![]() Pavlos Kaimakis er en Enterprise Solutions Architect som tar vare på Enterprise-kunder i GR/CY/MT og støtter dem med sin erfaring med å designe og implementere løsninger som skaper verdi for dem. Pavlos har brukt mest tid i sin karriere i produkt- og kundestøttesektoren – både fra et ingeniør- og et ledelsesperspektiv. Pavlos elsker å reise, og han er alltid klar for å utforske nye steder i verden.
Pavlos Kaimakis er en Enterprise Solutions Architect som tar vare på Enterprise-kunder i GR/CY/MT og støtter dem med sin erfaring med å designe og implementere løsninger som skaper verdi for dem. Pavlos har brukt mest tid i sin karriere i produkt- og kundestøttesektoren – både fra et ingeniør- og et ledelsesperspektiv. Pavlos elsker å reise, og han er alltid klar for å utforske nye steder i verden.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/arrange-your-transcripts-into-paragraphs-with-amazon-transcribe/
- : har
- :er
- :ikke
- $OPP
- 1
- 100
- 22
- 9
- a
- Om oss
- Aksepterer
- akseptere
- Oppnå
- faktiske
- legge til
- legge
- Ytterligere
- Etter
- Alle
- langs
- også
- alternativ
- alternativer
- alltid
- Amazon
- Amazon Transcribe
- Amazon Web Services
- beløp
- an
- analyse
- og
- hverandre
- Påfør
- ER
- Array
- AS
- At
- lyd
- automatisk
- basert
- BE
- fordi
- Begynnelsen
- BEST
- mellom
- Biggest
- både
- grenser
- Eske
- virksomhet
- by
- som heter
- CAN
- kandidater
- Karriere
- saken
- Kanal
- sjekk
- kommentarer
- sammenligning
- databehandling
- konsept
- selvtillit
- trygg
- Konfigurasjon
- hensyn
- ansett
- vurderer
- inneholdt
- innhold
- kontekst
- Gjeldende
- kunde
- Kundeservice
- Kunder
- bestemme
- avgjørelse
- Misligholde
- forsinkelse
- forsinkelser
- utforming
- dokument
- stasjonen
- varighet
- hver enkelt
- aktivert
- slutt
- Ingeniørarbeid
- styrke
- Enterprise
- bedriftskunder
- Enterprise Solutions
- entry
- Eter (ETH)
- Hver
- eksempel
- eksempler
- stige
- stiger
- utstillinger
- finnes
- erfaring
- Utforske
- Trekk
- Egenskaper
- tilbakemelding
- Figur
- filet
- slutt~~POS=TRUNC
- Først
- Fokus
- etter
- følger
- Til
- skjema
- format
- Forward
- fra
- fullt
- videre
- framtid
- genomikk
- få
- graf
- større
- Ha
- he
- hørsel
- hjelpe
- hjelper
- hi
- Høy
- High Performance Computing
- hans
- Hvordan
- HTTPS
- Identifikasjon
- identifikator
- identifisere
- if
- iverksette
- in
- inkludere
- indikerer
- indikerer
- indikasjon
- informasjon
- innsikt
- intervensjon
- inn
- introdusere
- introdusert
- Introduserer
- IT
- varer
- Jobb
- jpg
- Språk
- Siste
- Nivå
- i likhet med
- Liste
- logikk
- Se
- ser
- elsker
- Hoved
- gjøre
- ledelse
- håndbok
- merke
- max
- maksimal
- bety
- metadata
- mer
- mest
- Ny
- Nei.
- Antall
- gjenstander
- of
- on
- ONE
- bare
- drift
- Drift
- alternativer
- or
- Annen
- vår
- ut
- enn
- Spesielt
- lidenskapelig
- ytelse
- perspektiv
- steder
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Point
- poeng
- befolkningen
- Post
- potensiell
- presentere
- presentert
- forrige
- prosess
- Produkt
- forutsatt
- gir
- spørsmål
- gjentatt
- Krever
- begrense
- resultere
- Resultater
- Kjør
- Seksjon
- sektor
- valgt
- dømme
- Tjenester
- bør
- Viser
- betydning
- signifikant
- So
- løsning
- Solutions
- Høyttaler
- spesifikk
- brukt
- splittet
- spagaten
- Begynn
- statistisk
- Trinn
- Stopp
- rett fram
- send
- slik
- foreslår
- støtte
- Støttes
- Støtte
- Systemer
- ta
- enn
- Det
- De
- verden
- deres
- Dem
- deretter
- Der.
- derved
- Disse
- Tredje
- denne
- De
- tid
- ganger
- til
- Totalt
- trading
- Handelsplattformer
- Transcript
- virkelig
- typen
- typer
- typisk
- til
- bruk
- bruke
- bruker
- bruke
- verdi
- Verdier
- video
- Se
- var
- Vei..
- we
- web
- webtjenester
- velkommen
- når
- hvilken
- vil
- med
- uten
- ord
- ord
- verden
- du
- Din
- zephyrnet