Apache isfjell er et åpent tabellformat for svært store analytiske datasett, som fanger opp metadatainformasjon om tilstanden til datasett etter hvert som de utvikler seg og endrer seg over tid. Den legger til tabeller til beregningsmotorer inkludert Spark, Trino, PrestoDB, Flink og Hive ved å bruke et tabellformat med høy ytelse som fungerer akkurat som en SQL-tabell. Iceberg har blitt veldig populært for sin støtte for ACID-transaksjoner i datainnsjøer og funksjoner som skjema- og partisjonsutvikling, tidsreiser og tilbakerulling.
Apache Iceberg-integrasjon støttes av AWS-analysetjenester inkludert Amazon EMR, Amazonas Athenaog AWS Lim. Amazon EMR kan levere klynger med Spark, Hive, Trino og Flink som kan kjøre Iceberg. Fra og med Amazon EMR versjon 6.5.0 kan du bruk Iceberg med EMR-klyngen uten å kreve en bootstrap-handling. Tidlig i 2022 kunngjorde AWS generell tilgjengelighet av Athena ACID-transaksjoner, drevet av Apache Iceberg. Den nylig utgitte Athena spørremotor versjon 3 gir bedre integrasjon med Iceberg-tabellformatet. AWS Glue 3.0 og nyere støtter Apache Iceberg-rammeverket for datainnsjøer.
I dette innlegget diskuterer vi hva kundene ønsker i moderne datainnsjøer og hvordan Apache Iceberg bidrar til å møte kundenes behov. Deretter går vi gjennom en løsning for å bygge en høyytelses og utviklende isfjell-datainnsjø på Amazon enkel lagringstjeneste (Amazon S3) og behandle inkrementelle data ved å kjøre inn, oppdater og slett SQL-setninger. Til slutt viser vi deg hvordan du ytelsesjusterer prosessen for å forbedre lese- og skriveytelsen.
Hvordan Apache Iceberg adresserer det kundene ønsker i moderne datainnsjøer
Flere og flere kunder bygger datainnsjøer, med strukturerte og ustrukturerte data, for å støtte mange brukere, applikasjoner og analyseverktøy. Det er et økt behov for datainnsjøer for å støtte database som funksjoner som ACID-transaksjoner, oppdateringer og slettinger på rekordnivå, tidsreiser og tilbakeføring. Apache Iceberg er designet for å støtte disse funksjonene på kostnadseffektive petabyte-skala datainnsjøer på Amazon S3.
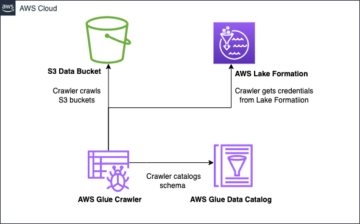
Apache Iceberg imøtekommer kundenes behov ved å fange opp rik metadatainformasjon om datasettet på det tidspunktet de individuelle datafilene opprettes. Det er tre lag i arkitekturen til en Iceberg-tabell: Iceberg-katalogen, metadatalaget og datalaget, som vist i følgende figur (kilde).

Iceberg-katalogen lagrer metadatapekeren til gjeldende tabellmetadatafil. Når en utvalgt spørring leser en Iceberg-tabell, går spørringsmotoren først til Iceberg-katalogen, og henter deretter plasseringen til gjeldende metadatafil. Hver gang det er en oppdatering av Iceberg-tabellen, opprettes et nytt øyeblikksbilde av tabellen, og metadatapekeren peker til gjeldende tabellmetadatafil.
Følgende er et eksempel på en isfjellkatalog med implementering av AWS Glue. Du kan se databasenavnet, plasseringen (S3-banen) til Iceberg-tabellen og metadataplasseringen.

Metadatalaget har tre typer filer: metadatafilen, manifestlisten og manifestfilen i et hierarki. Øverst i hierarkiet er metadatafilen, som lagrer informasjon om tabellens skjema, partisjonsinformasjon og øyeblikksbilder. Øyeblikksbildet peker til manifestlisten. Manifestlisten har informasjonen om hver manifestfil som utgjør øyeblikksbildet, for eksempel plasseringen av manifestfilen, partisjonene den tilhører, og de nedre og øvre grensene for partisjonskolonner for datafilene den sporer. Manifestfilen sporer datafiler samt ytterligere detaljer om hver fil, for eksempel filformatet. Alle tre filene fungerer i et hierarki for å spore øyeblikksbilder, skjema, partisjonering, egenskaper og datafiler i en Iceberg-tabell.
Datalaget har de individuelle datafilene til Iceberg-tabellen. Iceberg støtter et bredt spekter av filformater, inkludert Parkett, ORC og Avro. Fordi Iceberg-tabellen sporer de individuelle datafilene i stedet for bare å peke til partisjonsplasseringen med datafiler, isolerer den skriveoperasjonene fra leseoperasjoner. Du kan skrive datafilene når som helst, men bare forplikte endringen eksplisitt, noe som skaper en ny versjon av øyeblikksbildet og metadatafilene.
Løsningsoversikt
I dette innlegget leder vi deg gjennom en løsning for å bygge en høyytende Apache Iceberg-datainnsjø på Amazon S3; behandle inkrementelle data med å sette inn, oppdatere og slette SQL-setninger; og juster Iceberg-tabellen for å forbedre lese- og skriveytelsen. Følgende diagram illustrerer løsningsarkitekturen.

For å demonstrere denne løsningen bruker vi Amazon kundeanmeldelser datasett i en S3-bøtte (s3://amazon-reviews-pds/parquet/). I reell bruk vil det være rådata som er lagret i S3-bøtten din. Vi kan sjekke datastørrelsen med følgende kode i AWS kommandolinjegrensesnitt (AWS CLI):
Totalt antall objekter er 430, og total størrelse er 47.4 GiB.
For å konfigurere og teste denne løsningen, fullfører vi følgende trinn på høyt nivå:
- Sett opp en S3-bøtte i den kurerte sonen for å lagre konverterte data i Iceberg-tabellformat.
- Start en EMR-klynge med passende konfigurasjoner for Apache Iceberg.
- Lag en notatbok i EMR Studio.
- Konfigurer Spark-økten for Apache Iceberg.
- Konverter data til Iceberg-tabellformat og flytt data til den kurerte sonen.
- Kjør inn, oppdater og slett spørringer i Athena for å behandle inkrementelle data.
- Utfør ytelsesjustering.
Forutsetninger
For å følge med på denne gjennomgangen må du ha en AWS-konto med en AWS identitets- og tilgangsadministrasjon (IAM) rolle som har tilstrekkelig tilgang til å levere de nødvendige ressursene.
Sett opp S3-bøtten for isfjelldata i den kurerte sonen i datasjøen din
Velg regionen der du vil lage S3-bøtten og oppgi et unikt navn:
Start en EMR-klynge for å kjøre Iceberg-jobber med Spark
Du kan opprette en EMR-klynge fra AWS-administrasjonskonsoll, Amazon EMR CLI, eller AWS skyutviklingssett (AWS CDK). For dette innlegget viser vi deg hvordan du oppretter en EMR-klynge fra konsollen.
- På Amazon EMR-konsollen velger du Opprett klynge.
- Velg Avanserte alternativer.
- Til Programvarekonfigurasjon, velg den nyeste Amazon EMR-utgivelsen. Fra januar 2023 er den siste utgivelsen 6.9.0. Iceberg krever utgivelse 6.5.0 og nyere.
- Plukke ut JupyterEnterpriseGateway og Spark som programvaren som skal installeres.
- Til Rediger programvareinnstillinger, plukke ut Angi konfigurasjon og skriv inn
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - La andre innstillinger stå som standard og velg neste.

- Til maskinvare, bruk standardinnstillingen.
- Velg neste.
- Til Klyngens navn, skriv inn et navn. Vi bruker
iceberg-blog-cluster. - La de resterende innstillingene være uendret og velg neste.
- Velg Opprett klynge.
Lag en notatbok i EMR Studio
Vi viser deg nå hvordan du lager en notatbok i EMR Studio fra konsollen.
- På IAM-konsollen, opprette en EMR Studio-tjenesterolle.
- På Amazon EMR-konsollen velger du EMR Studio.
- Velg KOM I GANG.
De KOM I GANG siden vises i en ny fane.
- Velg Lag Studio i den nye fanen.
- Skriv inn et navn. Vi bruker isfjell-studio.
- Velg samme VPC og subnett som for EMR-klyngen, og standard sikkerhetsgruppe.
- Velg AWS Identity and Access Management (IAM) for autentisering, og velg EMR Studio-tjenesterollen du nettopp opprettet.
- Velg en S3-bane for Sikkerhetskopiering av arbeidsområder.
- Velg Lag Studio.
- Etter at Studio er opprettet, velg Studio-tilgangs-URL.
- Velg på EMR Studio-dashbordet Lag arbeidsområde.
- Skriv inn et navn for arbeidsområdet ditt. Vi bruker
iceberg-workspace. - Expand Avansert konfigurasjon Og velg Koble Workspace til en EMR-klynge.
- Velg EMR-klyngen du opprettet tidligere.
- Velg Opprett arbeidsområde.
- Velg arbeidsområdenavnet for å åpne en ny fane.
I navigasjonsruten er det en notatbok som har samme navn som arbeidsområdet. I vårt tilfelle er det isfjell-arbeidsområde.
- Åpne notatboken.
- Når du blir bedt om å velge en kjerne, velg Spark.
Konfigurer en Spark-økt for Apache Iceberg
Bruk følgende kode, og oppgi ditt eget S3-bøttenavn:
Dette angir følgende Spark-øktkonfigurasjoner:
- spark.sql.catalog.demo – Registrerer en Spark-katalog kalt demo, som bruker Iceberg Spark-katalogplugin.
- spark.sql.catalog.demo.catalog-impl – Demo Spark-katalogen bruker AWS Glue som den fysiske katalogen for å lagre Iceberg-database- og tabellinformasjon.
- spark.sql.catalog.demo.warehouse – Demo Spark-katalogen lagrer alle Iceberg-metadata og datafiler under rotbanen definert av denne egenskapen:
s3://iceberg-curated-blog-data. - spark.sql.extensions – Legger til støtte for Iceberg Spark SQL-utvidelser, som lar deg kjøre Iceberg Spark-prosedyrer og noen SQL-kommandoer som kun er for Iceberg (du bruker dette i et senere trinn).
- spark.sql.catalog.demo.io-impl – Iceberg lar brukere skrive data til Amazon S3 gjennom S3FileIO. AWS Glue Data Catalog bruker som standard denne FileIO, og andre kataloger kan laste denne FileIO ved å bruke io-impl katalogegenskapen.
Konverter data til Iceberg-tabellformat
Du kan bruke enten Spark på Amazon EMR eller Athena for å laste Iceberg-bordet. I EMR Studio Workspace Notebook Spark-økten kjører du følgende kommandoer for å laste inn dataene:
Etter at du har kjørt koden, bør du finne to prefikser opprettet i datavarehusets S3-bane (s3://iceberg-curated-blog-data/reviews.db/all_reviews): data og metadata.
Behandle inkrementelle data ved å sette inn, oppdatere og slette SQL-setninger i Athena
Athena er en serverløs søkemotor som du kan bruke til å utføre lese-, skrive-, oppdaterings- og optimaliseringsoppgaver mot Iceberg-tabeller. For å demonstrere hvordan Apache Iceberg-datainnsjøformatet støtter inkrementell datainntak, kjører vi inn, oppdaterer og sletter SQL-setninger på datainnsjøen.
Naviger til Athena-konsollen og velg Spørringsredaktør. Hvis dette er første gang du bruker Athena spørringsredigering, må du konfigurere søkeresultatplasseringen å være S3-bøtten du opprettet tidligere. Du bør kunne se at tabellen reviews.all_reviews er tilgjengelig for spørring. Kjør følgende spørring for å bekrefte at du har lastet inn Iceberg-tabellen:
Behandle inkrementelle data ved å kjøre inn, oppdater og slett SQL-setninger:
Ytelsestuning
I denne delen går vi gjennom ulike måter å forbedre Apache Iceberg lese- og skriveytelse på.
Konfigurer Apache Iceberg-tabellegenskaper
Apache Iceberg er et tabellformat, og det støtter tabellegenskaper for å konfigurere tabellatferd som les, skriv og katalog. Du kan forbedre lese- og skriveytelsen på Iceberg-tabeller ved å justere tabellegenskapene.
For eksempel, hvis du legger merke til at du skriver for mange små filer for en Iceberg-tabell, kan du konfigurere skrivefilstørrelsen til å skrive færre, men større filer, for å forbedre søkeytelsen.
| Eiendom | Misligholde | Beskrivelse |
| write.target-file-size-bytes | 536870912 (512 MB) | Kontrollerer størrelsen på filer som genereres for å målrette rundt så mange byte |
Bruk følgende kode for å endre tabellformatet:
Oppdeling og sortering
For å få et søk til å kjøre raskt, jo mindre data som leses, jo bedre. Iceberg drar nytte av de rike metadataene den fanger opp ved skrivetidspunkt og letter teknikker som skanneplanlegging, partisjonering, beskjæring og statistikk på kolonnenivå som min/maks-verdier for å hoppe over datafiler som ikke har samsvarsposter. Vi leder deg gjennom hvordan planlegging og partisjonering av spørringsskanning fungerer i Iceberg og hvordan vi bruker dem til å forbedre søkeytelsen.
Planlegging av søkeskanning
For en gitt spørring er det første trinnet i en spørringsmotor skanneplanlegging, som er prosessen for å finne filene i en tabell som trengs for en spørring. Planlegging i en Iceberg-tabell er svært effektiv, fordi Icebergs rike metadata kan brukes til å beskjære metadatafiler som ikke er nødvendige, i tillegg til å filtrere datafiler som ikke inneholder samsvarende data. I testene våre observerte vi at Athena skannet 50 % eller mindre data for en gitt spørring på en Iceberg-tabell sammenlignet med originaldata før konvertering til Iceberg-format.
Det finnes to typer filtrering:
- Metadatafiltrering – Iceberg bruker to nivåer av metadata for å spore filene i et øyeblikksbilde: manifestlisten og manifestfilene. Den bruker først manifestlisten, som fungerer som en indeks over manifestfilene. Under planlegging filtrerer Iceberg manifester ved å bruke partisjonsverdiområdet i manifestlisten uten å lese alle manifestfilene. Deretter bruker den utvalgte manifestfiler for å hente datafiler.
- Datafiltrering – Etter å ha valgt listen over manifestfiler, bruker Iceberg partisjonsdata og statistikk på kolonnenivå for hver datafil som er lagret i manifestfiler for å filtrere datafiler. Under planleggingen konverteres spørringspredikater til predikater på partisjonsdataene og brukes først for å filtrere datafiler. Deretter brukes kolonnestatistikken som verditellinger på kolonnenivå, nulltellinger, nedre grenser og øvre grenser for å filtrere ut datafiler som ikke kan samsvare med spørringspredikatet. Ved å bruke øvre og nedre grenser for å filtrere datafiler på planleggingstidspunktet, forbedrer Iceberg søkeytelsen betraktelig.
Oppdeling og sortering
Partisjonering er en måte å gruppere poster med de samme nøkkelkolonneverdiene skriftlig. Fordelen med partisjonering er raskere spørringer som bare får tilgang til deler av dataene, som forklart tidligere i planlegging av spørringsskanning: datafiltrering. Iceberg gjør partisjonering enkel ved å støtte skjult partisjonering, på den måten som Iceberg produserer partisjonsverdier ved å ta en kolonneverdi og eventuelt transformere den.
I vårt brukstilfelle kjører vi først følgende spørring på Iceberg-tabellen som ikke er partisjonert. Deretter deler vi Iceberg-tabellen etter kategorien vurderinger, som vil bli brukt i spørringen WHERE-tilstand for å filtrere ut poster. Med partisjonering kan spørringen skanne mye mindre data. Se følgende kode:
Kjør følgende select-setning på den ikke-partisjonerte all_reviews-tabellen kontra den partisjonerte tabellen for å se ytelsesforskjellen:
Tabellen nedenfor viser ytelsesforbedringen til datapartisjonering, med omtrent 50 % ytelsesforbedring og 70 % mindre skannet data.
| Datasettnavn | Ikke-partisjonert datasett | Partisjonert datasett |
| Kjøretid (sekunder) | 8.20 | 4.25 |
| Data skannet (MB) | 131.55 | 33.79 |
Merk at kjøretiden er gjennomsnittlig kjøretid med flere kjøringer i testen vår.
Vi så god ytelsesforbedring etter partisjonering. Dette kan imidlertid forbedres ytterligere ved å bruke statistikk på kolonnenivå fra Iceberg-manifestfiler. For å bruke statistikken på kolonnenivå effektivt, ønsker du å sortere postene dine ytterligere basert på spørringsmønstrene. Sortering av hele datasettet ved hjelp av kolonnene som ofte brukes i spørringer vil omorganisere dataene på en slik måte at hver datafil ender opp med et unikt verdiområde for de spesifikke kolonnene. Hvis disse kolonnene brukes i spørringstilstanden, lar det søkemotorer hoppe over datafiler ytterligere, og dermed muliggjøre enda raskere spørringer.
Kopier-på-skriv vs. les-på-fletting
Når du implementerer oppdatering og sletting på Iceberg-tabeller i datasjøen, er det to tilnærminger definert av Iceberg-tabellegenskapene:
- Kopier-on-write – Med denne tilnærmingen, når det er endringer i Iceberg-tabellen, enten oppdateringer eller slettinger, vil datafilene knyttet til de berørte postene bli duplisert og oppdatert. Postene vil enten bli oppdatert eller slettet fra de dupliserte datafilene. Et nytt øyeblikksbilde av Iceberg-tabellen vil bli opprettet og peker til den nyere versjonen av datafiler. Dette gjør den generelle skrivingen tregere. Det kan være situasjoner hvor samtidig skriving er nødvendig med konflikter, så et nytt forsøk må skje, noe som øker skrivetiden enda mer. På den annen side, når du leser dataene, er det ingen ekstra prosess nødvendig. Spørringen vil hente data fra den nyeste versjonen av datafiler.
- Slå sammen ved lesing – Med denne tilnærmingen, når det er oppdateringer eller slettinger på Iceberg-tabellen, vil de eksisterende datafilene ikke bli skrevet om; i stedet opprettes nye slettefiler for å spore endringene. For slettinger vil det opprettes en ny slettefil med de slettede postene. Når du leser Iceberg-tabellen, vil slettefilen bli brukt på de hentede dataene for å filtrere ut slettepostene. For oppdateringer vil det opprettes en ny slettefil for å merke de oppdaterte postene som slettet. Deretter opprettes en ny fil for disse postene, men med oppdaterte verdier. Når du leser Iceberg-tabellen, vil både slette- og nye filer bli brukt på de hentede dataene for å gjenspeile de siste endringene og gi de riktige resultatene. Så for alle påfølgende søk vil et ekstra trinn for å slå sammen datafilene med slette- og nye filer skje, noe som vanligvis vil øke spørringstiden. På den annen side kan skrivingene være raskere fordi det ikke er behov for å omskrive de eksisterende datafilene.
For å teste virkningen av de to tilnærmingene, kan du kjøre følgende kode for å angi Iceberg-tabellegenskapene:
Kjør oppdateringen, slett og velg SQL-setninger i Athena for å vise kjøretidsforskjellen for kopi-på-skriv vs. flette-på-les:
Følgende tabell oppsummerer spørringskjøringene.
| Query | Kopier-på-skriv | Merge-on-Read | ||||
| OPPDATERING | SLETT | VELG | OPPDATERING | SLETT | VELG | |
| Kjøretid (sekunder) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| Data skannet (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
Merk at kjøretiden er gjennomsnittlig kjøretid med flere kjøringer i testen vår.
Som våre testresultater viser, er det alltid avveininger i de to tilnærmingene. Hvilken tilnærming du skal bruke avhenger av dine brukstilfeller. Oppsummert kommer hensynene til latens på lesing versus skriving. Du kan referere til følgende tabell og gjøre det riktige valget.
| . | Kopier-på-skriv | Merge-on-Read |
| Pros | Raskere lesing | Raskere skriver |
| Ulemper | Dyrt skriver | Høyere ventetid på lesinger |
| Når skal brukes | Bra for hyppige lesinger, sjeldne oppdateringer og slettinger eller store batchoppdateringer | Bra for tabeller med hyppige oppdateringer og slettinger |
Datakomprimering
Hvis datafilstørrelsen din er liten, kan du ende opp med tusenvis eller millioner av filer i et isfjell-tabell. Dette øker I/O-operasjonen dramatisk og senker spørringene. I tillegg sporer Iceberg hver datafil i et datasett. Flere datafiler fører til mer metadata. Dette øker igjen overhead- og I/O-operasjonen ved lesing av metadatafiler. For å forbedre søkeytelsen, anbefales det å komprimere små datafiler til større datafiler.
Når du oppdaterer og sletter poster i Iceberg-tabellen, hvis les-på-flett-tilnærmingen brukes, kan du ende opp med mange små slettinger eller nye datafiler. Å kjøre komprimering vil kombinere alle disse filene og lage en nyere versjon av datafilen. Dette eliminerer behovet for å avstemme dem under lesing. Det anbefales å ha vanlige komprimeringsjobber for å påvirke lesingen så lite som mulig mens du fortsatt opprettholder raskere skrivehastighet.
Kjør følgende datakomprimeringskommando, og kjør deretter select-spørringen fra Athena:
Tabellen nedenfor sammenligner kjøretiden før og etter datakomprimering. Du kan se omtrent 40 % ytelsesforbedring.
| Query | Før datakomprimering | Etter datakomprimering |
| Kjøretid (sekunder) | 97.75 | 32.676 sekunder |
| Data skannet (MB) | 137.16 M | 189.19 M |
Merk at utvalgsspørringene kjørte på all_reviews tabell etter oppdatering og sletting, før og etter datakomprimering. Kjøretiden er gjennomsnittlig kjøretid med flere kjøringer i testen vår.
Rydd opp
Etter at du har fulgt løsningsgjennomgangen for å utføre brukstilfellene, fullfør følgende trinn for å rydde opp i ressursene dine og unngå ytterligere kostnader:
- Slipp AWS Glue-tabellene og databasen fra Athena eller kjør følgende kode i notatboken din:
- På EMR Studio-konsollen velger du arbeidsområder i navigasjonsruten.
- Velg arbeidsområdet du opprettet og velg Delete.
- På EMR-konsollen, naviger til Studios side.
- Velg studioet du opprettet og velg Delete.
- På EMR-konsollen velger du klynger i navigasjonsruten.
- Velg klyngen og velg Terminere.
- Slett S3-bøtta og eventuelle andre ressurser du opprettet som en del av forutsetningene for dette innlegget.
konklusjonen
I dette innlegget introduserte vi Apache Iceberg-rammeverket og hvordan det hjelper til med å løse noen av utfordringene vi har i en moderne datainnsjø. Så ledet vi deg gjennom en løsning for å behandle inkrementelle data i en datainnsjø ved hjelp av Apache Iceberg. Til slutt hadde vi et dypdykk i ytelsesjustering for å forbedre lese- og skriveytelsen for våre brukstilfeller.
Vi håper dette innlegget gir deg nyttig informasjon for å bestemme om du vil ta i bruk Apache Iceberg i datainnsjøløsningen din.
Om forfatterne
 Flora Wu er Sr. Resident Architect ved AWS Data Lab. Hun hjelper bedriftskunder med å lage dataanalysestrategier og bygge løsninger for å akselerere bedriftens resultater. På fritiden liker hun å spille tennis, danse salsa og reise.
Flora Wu er Sr. Resident Architect ved AWS Data Lab. Hun hjelper bedriftskunder med å lage dataanalysestrategier og bygge løsninger for å akselerere bedriftens resultater. På fritiden liker hun å spille tennis, danse salsa og reise.
 Daniel Li er senior løsningsarkitekt hos Amazon Web Services. Han fokuserer på å hjelpe kunder med å utvikle, ta i bruk og implementere skytjenester og strategi. Når han ikke jobber, liker han å tilbringe tid utendørs med familien.
Daniel Li er senior løsningsarkitekt hos Amazon Web Services. Han fokuserer på å hjelpe kunder med å utvikle, ta i bruk og implementere skytjenester og strategi. Når han ikke jobber, liker han å tilbringe tid utendørs med familien.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- I stand
- Om oss
- ovenfor
- akselerere
- adgang
- tilgangsstyring
- Handling
- handlinger
- tillegg
- Ytterligere
- adresse
- adresser
- Legger
- adoptere
- Fordel
- Etter
- mot
- Alle
- tillater
- alltid
- Amazon
- Amazon EMR
- Amazon Web Services
- analytisk
- analytics
- og
- annonsert
- Apache
- søknader
- anvendt
- tilnærming
- tilnærminger
- hensiktsmessig
- arkitektur
- assosiert
- Autentisering
- tilgjengelighet
- tilgjengelig
- gjennomsnittlig
- unngå
- AWS
- AWS Lim
- basert
- fordi
- bli
- før du
- nytte
- Bedre
- mellom
- større
- Bootstrap
- bygge
- Bygning
- bedrifter
- fanger
- fange
- saken
- saker
- katalog
- kataloger
- Kategori
- utfordringer
- endring
- Endringer
- sjekk
- valg
- Velg
- klassifisering
- Cloud
- skytjenester
- Cluster
- kode
- Kolonne
- kolonner
- kombinere
- Kom
- forplikte
- sammenlignet
- fullføre
- Beregn
- samtidig
- tilstand
- konfigurasjoner
- betraktninger
- Konsoll
- Konvertering
- konvertert
- kostnadseffektiv
- Kostnader
- kunne
- skape
- opprettet
- skaper
- kuratert
- Gjeldende
- kunde
- Kunder
- Dans
- dashbord
- dato
- Data Analytics
- Data Lake
- databehandling
- datalager
- Database
- datasett
- dyp
- dypdykk
- Misligholde
- definert
- Demo
- demonstrere
- avhenger
- designet
- detaljer
- utvikle
- Utvikling
- forskjell
- forskjellig
- diskutere
- ikke
- ned
- dramatisk
- Drop
- under
- hver enkelt
- Tidligere
- Tidlig
- redaktør
- effektivt
- effektiv
- enten
- eliminerer
- aktivert
- muliggjør
- slutter
- Motor
- Motorer
- Enter
- Enterprise
- bedriftskunder
- Eter (ETH)
- Selv
- evolusjon
- utvikle seg
- utvikling
- eksempel
- eksisterende
- finnes
- forklarte
- utvidelser
- ekstra
- forenkler
- familie
- FAST
- raskere
- Egenskaper
- Figur
- filet
- Filer
- filtrere
- filtrering
- filtre
- Endelig
- Finn
- Først
- første gang
- fokuserer
- følge
- etter
- format
- Rammeverk
- hyppig
- fra
- videre
- Dess
- general
- generert
- få
- gitt
- Går
- god
- sterkt
- Gruppe
- hånd
- skje
- hjelpe
- hjelpe
- hjelper
- skjult
- hierarki
- høyt nivå
- høy ytelse
- høytytende
- Hive
- håp
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- IAM
- Identitet
- styring av identitet og tilgang
- Påvirkning
- påvirket
- iverksette
- gjennomføring
- implementere
- forbedre
- forbedret
- forbedring
- forbedrer
- in
- Inkludert
- Øke
- økt
- øker
- indeks
- individuelt
- informasjon
- installere
- i stedet
- integrering
- introdusert
- isolater
- IT
- Januar
- Jobb
- nøkkel
- lab
- innsjø
- stor
- større
- Ventetid
- siste
- siste utgivelsen
- lag
- lag
- føre
- nivåer
- BEGRENSE
- linje
- Liste
- lite
- laste
- plassering
- gjøre
- GJØR AT
- ledelse
- mange
- merke
- markedsplass
- Match
- matchende
- Flett
- metadata
- kunne
- millioner
- Moderne
- mer
- flytte
- flere
- navn
- oppkalt
- Naviger
- Navigasjon
- Trenger
- nødvendig
- behov
- Ny
- bærbare
- objekt
- åpen
- drift
- Drift
- optimalisering
- Optimalisere
- rekkefølge
- original
- Annen
- utendørs
- samlet
- egen
- brød
- del
- banen
- mønstre
- utføre
- ytelse
- fysisk
- planlegging
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- plugg inn
- poeng
- Populær
- mulig
- Post
- powered
- forutsetninger
- prosedyrer
- prosess
- prosessering
- produsere
- egenskaper
- eiendom
- gi
- gir
- gi
- forsyning
- område
- Raw
- rådata
- Lese
- Lesning
- ekte
- nylig
- anbefales
- poster
- reflektere
- region
- registre
- regelmessig
- slipp
- utgitt
- gjenværende
- påkrevd
- Krever
- Ressurser
- resultere
- Resultater
- Anmeldelser
- Rich
- Rolle
- root
- Kjør
- rennende
- samme
- skanne
- sekunder
- Seksjon
- sikkerhet
- valgt
- velge
- server~~POS=TRUNC
- tjeneste
- Tjenester
- Session
- sett
- sett
- innstilling
- innstillinger
- bør
- Vis
- Viser
- Enkelt
- situasjoner
- Størrelse
- bremser
- liten
- Snapshot
- So
- Software
- løsning
- Solutions
- noen
- Spark
- spesifikk
- fart
- utgifter
- SQL
- Start
- Tilstand
- Uttalelse
- uttalelser
- stats
- Trinn
- Steps
- Still
- lagring
- oppbevare
- lagret
- butikker
- strategier
- Strategi
- strukturert
- strukturerte og ustrukturerte data
- studio
- subnett
- senere
- vellykket
- slik
- tilstrekkelig
- SAMMENDRAG
- støtte
- Støttes
- Støtte
- Støtter
- bord
- tar
- ta
- Target
- oppgaver
- teknikker
- tennis
- test
- Testing
- tester
- De
- informasjonen
- Staten
- deres
- derved
- tusener
- tre
- Gjennom
- tid
- tidsreiser
- til
- sammen
- også
- verktøy
- topp
- Totalt
- spor
- Transaksjoner
- transformere
- reiser
- Traveling
- SVING
- typer
- etter
- unik
- Oppdater
- oppdatert
- oppdateringer
- oppdatering
- URL
- bruke
- bruk sak
- Brukere
- vanligvis
- VAL
- verdi
- Verdier
- verifisere
- versjon
- gikk
- walkthrough
- Warehouse
- klokker
- måter
- web
- webtjenester
- Hva
- om
- hvilken
- mens
- bred
- Bred rekkevidde
- vil
- uten
- Arbeid
- arbeid
- virker
- ville
- skrive
- skriving
- Din
- zephyrnet