Kunder står overfor en utfordring når de distribuerer skyressurser mellom ulike team som kjører arbeidsbelastninger som utvikling, testing eller produksjon. Ressursfordelingsutfordringen oppstår også når du har forskjellige bransjebrukere. Målet er ikke bare å sikre at tilstrekkelige ressurser konsekvent er tilgjengelige for produksjonsarbeidsbelastninger og kritiske team, men også å forhindre at adhoc-jobber bruker alle ressursene og forsinker andre kritiske arbeidsbelastninger på grunn av feilkonfigurert eller ikke-optimalisert kode. Kostnadskontroll og brukssporing på tvers av disse teamene er også en kritisk faktor.
I de eldre big data og Hadoop-klynger samt Amazon EMR klargjorte klynger, ble dette problemet overvunnet ved å administrere garnressurs og definere det som ble kalt garnkøer for forskjellige arbeidsmengder eller team. En annen tilnærming var å tildele uavhengige klynger for ulike team eller ulike arbeidsmengder.
Amazon EMR-serverløs er et serverløst alternativ i Amazon EMR som gjør det enkelt å kjøre big data-arbeidsmengdene dine ved å bruke åpen kildekode-analyserammeverk som Apache Spark og Hive uten å måtte konfigurere, administrere eller skalere klyngene. Med EMR Serverless trenger du ikke å konfigurere, optimalisere, sikre eller betjene klynger for å kjøre arbeidsbelastningene dine. Du fortsetter å få fordelene av Amazon EMR, for eksempel åpen kildekode-kompatibilitet, samtidighet og optimalisert kjøretidsytelse for populære bigdata-rammeverk. EMR Serverless gir kortere jobboppstartsforsinkelse, automatisk ressursstyring og effektiv kostnadskontroll.
I dette innlegget viser vi hvordan du definerer per-team ressursgrenser for big data-arbeidsbelastninger ved å bruke EMR-serverløs.
Løsningsoversikt
EMR-serverløs kommer med et konsept kalt an EMR Serverløs applikasjon, som er et isolert miljø med muligheten til å velge en av analyseapplikasjonene med åpen kildekode (Spark, Hive) for å sende inn arbeidsmengdene dine. Du kan inkludere dine egne tilpassede biblioteker, spesifisere EMR-utgivelsesversjonen, og viktigst av alt definere ressursgrensene for data- og minneressursene. For eksempel, hvis produksjons-Spark-jobbene dine kjører på Amazon EMR 6.9.0 og du må teste den samme arbeidsbelastningen på Amazon EMR 6.10.0, kan du bruke EMR Serverless til å definere EMR 6.10.0 som din versjon og teste arbeidsmengden din ved å bruke en forhåndsdefinert ressursgrense.
Følgende diagram illustrerer løsningsarkitekturen vår. Vi ser at to forskjellige team, nemlig Prod-teamet og Dev-teamet, sender inn jobbene sine uavhengig til to forskjellige EMR-applikasjoner (nemlig henholdsvis ProdApp og DevApp) som har dedikerte ressurser.
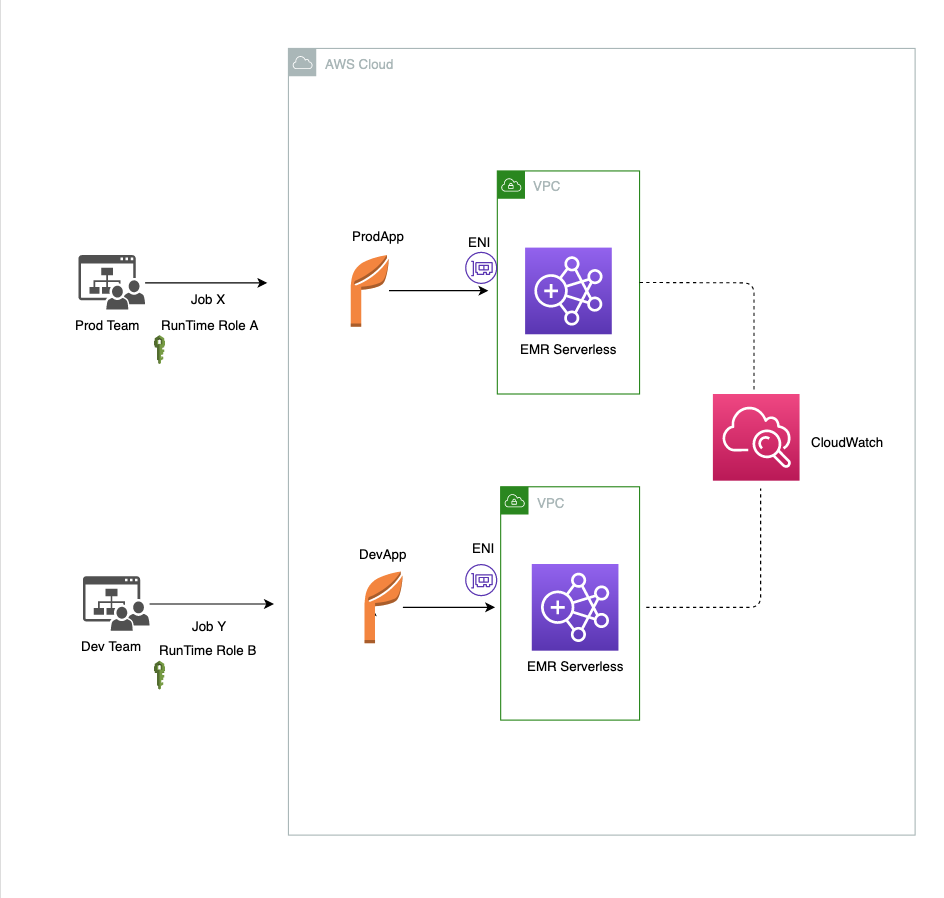
EMR Serverless gir kontroller på konto-, applikasjons- og jobbnivå for å begrense bruken av ressurser som CPU, minne eller disk. I de følgende avsnittene diskuterer vi noen av disse kontrollene.
Tjenestekvoter på kontonivå
Amazon EMR Serverless har en standardkvote på 16 for maksimale samtidige vCPUer per konto. Med andre ord kan en ny konto ha maksimalt 16 vCPUer som kjører på et gitt tidspunkt i en bestemt region på tvers av alle EMR-serverløse applikasjoner. Imidlertid kan denne kvoten automatisk justeres basert på bruksmønstrene, som overvåkes på konto- og regionnivå.
Ressursgrenser og kjøretidskonfigurasjoner på applikasjonsnivå
I tillegg til kvoter på kontonivå, kan administratorer begrense bruken av ressurser på applikasjonsnivå ved å bruke en funksjon kjent som "maks kapasitet” som definerer maksimal total vCPU, minne og diskkapasitet som kan forbrukes samlet av alle jobbene som kjører under denne applikasjonen.
Du har også en mulighet til å spesifisere vanlige kjøretids- og overvåkingskonfigurasjoner på applikasjonsnivå som du ellers ville lagt inn i de spesifikke jobbkonfigurasjonene. Dette bidrar til å skape et standardisert kjøretidsmiljø for alle jobbene som kjører under en applikasjon. Dette kan inkludere innstillinger som å definere vanlige tilkoblingsinnstillinger jobbene dine trenger tilgang til, loggkonfigurasjoner som alle jobbene dine vil arve som standard, eller Spark-ressursinnstillinger for å balansere ad-hoc-arbeidsbelastninger. Du kan overstyre disse konfigurasjonene på jobbnivå, men å definere dem i applikasjonen kan bidra til å redusere konfigurasjonen som er nødvendig for individuelle jobber.
For ytterligere detaljer, se Erklære konfigurasjoner på applikasjonsnivå.
Kjøretidskonfigurasjoner på jobbnivå
Etter at du har satt service, applikasjonskvoter og kjøretidskonfigurasjoner på applikasjonsnivå, har du også muligheten til å overstyre eller legge til nye konfigurasjoner på jobbnivå også. Du kan for eksempel bruke forskjellige Spark-jobbparametere for å definere hvor mange maksimale utførere som kan kjøres av den spesifikke jobben. En slik parameter er spark.dynamicAllocation.maxExecutors som definerer en øvre grense for antall executors i en jobb og derfor kontrollerer antall arbeidere i en EMR Serverless-applikasjon fordi hver executor kjører innenfor en enkelt arbeider. Denne parameteren er en del av dynamisk tildeling funksjon av Apache Spark, som lar deg dynamisk skalere antall utøvere (arbeidere) registrert med jobben opp og ned basert på arbeidsmengden. Dynamisk tildeling er aktivert som standard på EMR Serverless. For detaljerte trinn, se Erklære konfigurasjoner på applikasjonsnivå.
Med disse konfigurasjonene kan du kontrollere ressursene som brukes på tvers av kontoer, applikasjoner og jobber. Du kan for eksempel opprette applikasjoner med en forhåndsdefinert maksimal kapasitet for å begrense kostnader eller konfigurere jobber med ressursgrenser for å tillate flere ad hoc-jobber å kjøre samtidig uten å bruke for mange ressurser.
Beste praksis og hensyn
Ved å utvide disse bruksscenarioene ytterligere, tilbyr EMR Serverless funksjoner og muligheter for å implementere følgende designbetraktninger og beste praksis basert på arbeidsbelastningskravene dine:
- For å være sikker på at brukerne eller teamene bare sender jobbene sine til godkjente søknader, kan du bruke tag-basert AWS identitets- og tilgangsadministrasjon (IAM) forsikringsbetingelser. For flere detaljer, se Bruke tagger for tilgangskontroll.
- Du kan bruke tilpassede bilder som applikasjoner som tilhører forskjellige team som har forskjellige brukstilfeller og programvarekrav. Bruk av egendefinerte bilder er mulig EMR 6.9.0 og nyere. Egendefinerte bilder lar deg pakke ulike applikasjonsavhengigheter i en enkelt beholder. Noen av de viktige fordelene ved å bruke tilpassede bilder inkluderer muligheten til å bruke dine egne JDK- og Python-versjoner, bruke organisasjonsspesifikke sikkerhetspolicyer og integrere EMR Serverless i bygge-, test- og distribusjonsrørledningene dine. For mer informasjon, se Tilpasse et EMR-serverløst bilde.
- Hvis du trenger å anslå hvor mye en Spark-jobb vil koste når den kjøres på EMR Serverless, kan du bruke åpen kildekode-verktøyet EMR Serverless Estimator. Dette verktøyet analyserer Spark-hendelseslogger for å gi deg kostnadsestimatet. For flere detaljer, se Amazon EMR Serverless kostnadsberegning
- Vi anbefaler at du bestemmer din maksimale kapasitet i forhold til de støttede arbeiderstørrelsene ved å multiplisere antall arbeidere med deres størrelse. Hvis du for eksempel vil begrense programmet med 50 arbeidere til 2 vCPUer, 16 GB minne og 20 GB disk, setter du maksimal kapasitet til 100 vCPU, 800 GB minne og 1000 GB disk.
- Du kan bruke tagger når du oppretter EMR Serverless-applikasjonen for å hjelpe til med å søke og filtrere ressursene dine, eller spore AWS-kostnadene ved å bruke AWS Cost Explorer. Du kan også bruke tagger for å kontrollere hvem som kan sende jobber til en bestemt applikasjon eller endre konfigurasjonene. Referere til Merke ressursene dine for mer informasjon.
- Du kan konfigurere forhåndsinitialisert kapasitet på tidspunktet for søknadsoppretting, noe som holder ressursene klare til å bli forbrukt av de tidssensitive jobbene du sender inn.
- Antallet samtidige jobber du kan kjøre avhenger av viktige faktorer som maksimale kapasitetsgrenser, arbeidere som kreves for hver jobb, og tilgjengelig IP-adresse hvis du bruker en VPC.
- EMR Serverless vil konfigureres elastiske nettverksgrensesnitt (ENIs) for å kommunisere sikkert med ressurser i din VPC. Sørg for at du har nok IP-adresser i subnettet for jobben.
- Det er en beste praksis å velge flere undernett fra flere tilgjengelighetssoner. Dette er fordi undernettene du velger bestemmer tilgjengelighetssonene som er tilgjengelige for å kjøre EMR Serverless-applikasjonen. Hver arbeider bruker en IP-adresse i undernettet der den startes. Sørg for at de konfigurerte undernettene har nok IP-adresser for antall arbeidere du planlegger å kjøre.
Sporing av ressursbruk
EMR Serverless lar ikke bare skyadministratorer begrense ressursene for hver applikasjon, den lar dem også overvåke applikasjonene og spore ressursbruken på tvers av disse applikasjonene. For flere detaljer, se EMR-serverløs bruksberegninger .
Du kan også distribuere en AWS CloudFormation-mal for å bygge en prøve CloudWatch Dashboard for EMR-serverløs som vil hjelpe med å visualisere ulike beregninger for applikasjonene og jobbene dine. For mer informasjon, se EMR Serverless CloudWatch Dashboard.
konklusjonen
I dette innlegget diskuterte vi hvordan EMR Serverless gir sky- og dataplattformadministratorer mulighet til å effektivt distribuere og begrense skyressursene på ulike nivåer, for ulike organisasjonsenheter, brukere og team, så vel som mellom kritiske og ikke-kritiske arbeidsbelastninger. EMR Serverless ressursbegrensende funksjoner sørger for at skykostnadene er under kontroll og ressursbruk spores effektivt.
For mer informasjon om EMR-serverløse applikasjoner og ressurskvoter, se EMR-serverløs brukerveiledning og Konfigurere en applikasjon.
Om forfatterne
 Gaurav Sharma er en spesialistløsningsarkitekt (Analytics) hos Amazon Web Services (AWS), og støtter amerikanske offentlige kunder på deres skyreise. Utenom jobben liker Gaurav å tilbringe tid med familien og lese bøker.
Gaurav Sharma er en spesialistløsningsarkitekt (Analytics) hos Amazon Web Services (AWS), og støtter amerikanske offentlige kunder på deres skyreise. Utenom jobben liker Gaurav å tilbringe tid med familien og lese bøker.
 Damon Cortesi er en ledende utvikleradvokat med Amazon Web Services. Han bygger verktøy og innhold for å gjøre livene til dataingeniører enklere. Når han ikke jobber hardt, bygger han fortsatt datapipelines og deler logger på fritiden.
Damon Cortesi er en ledende utvikleradvokat med Amazon Web Services. Han bygger verktøy og innhold for å gjøre livene til dataingeniører enklere. Når han ikke jobber hardt, bygger han fortsatt datapipelines og deler logger på fritiden.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/define-per-team-resource-limits-for-big-data-workloads-using-amazon-emr-serverless/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 10
- 100
- 16
- 20
- 50
- 9
- a
- evne
- adgang
- Logg inn
- kontoer
- tvers
- Ad
- legge til
- tillegg
- adresse
- adresser
- administratorer
- advokat
- Alle
- tildele
- allokering
- tillate
- tillater
- også
- Amazon
- Amazon EMR
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- analytics
- analyser
- og
- En annen
- Apache
- Apache Spark
- Søknad
- søknader
- Påfør
- tilnærming
- godkjent
- arkitektur
- ER
- AS
- At
- Automatisk
- tilgjengelighet
- tilgjengelig
- AWS
- AWS skyformasjon
- Balansere
- basert
- BE
- fordi
- tilhørighet
- Fordeler
- BEST
- beste praksis
- mellom
- Stor
- Store data
- bigdata
- bøker
- bundet
- bygge
- bygger
- men
- by
- som heter
- CAN
- evner
- Kapasitet
- utfordre
- Velg
- Cloud
- kode
- samlet sett
- kommer
- Felles
- kommunisere
- kompatibilitet
- Beregn
- konsept
- samtidig
- forhold
- Konfigurasjon
- konfigurasjoner
- konfigurert
- tilkobling
- betraktninger
- konsekvent
- forbrukes
- Container
- innhold
- fortsette
- kontroll
- kontrollerende
- kontroller
- Kostnad
- Kostnader
- kunne
- prosessor
- skape
- skaperverket
- kritisk
- skikk
- Kunder
- dashbord
- dato
- Dataplattform
- dedikert
- Misligholde
- definere
- definerer
- definere
- avhengig
- avhenger
- utplassere
- utforming
- detaljert
- detaljer
- Bestem
- dev
- Utvikler
- Utvikling
- forskjellig
- diskutere
- diskutert
- distinkt
- distribuere
- distribusjon
- distribusjon
- ikke
- ned
- to
- dynamisk
- dynamisk
- hver enkelt
- enklere
- Effektiv
- effektivt
- effektivt
- bemyndiger
- aktivert
- muliggjør
- Ingeniører
- nok
- sikre
- Miljø
- anslag
- Eter (ETH)
- Event
- eksempel
- Face
- faktor
- faktorer
- familie
- Trekk
- Egenskaper
- filtrere
- etter
- Til
- rammer
- fra
- videre
- få
- gitt
- Hadoop
- Hard
- Ha
- å ha
- he
- hjelpe
- hjelper
- hans
- Hive
- Hvordan
- Hvordan
- Men
- HTML
- HTTPS
- IAM
- Identitet
- if
- illustrerer
- bilder
- iverksette
- viktig
- viktigere
- in
- I andre
- inkludere
- uavhengig
- uavhengig av hverandre
- individuelt
- informasjon
- f.eks
- integrere
- inn
- IP
- IP-adresse
- IP-adresser
- isolert
- IT
- DET ER
- Jobb
- Jobb
- reise
- jpg
- kjent
- Ventetid
- lansert
- Legacy
- Nivå
- nivåer
- bibliotekene
- i likhet med
- BEGRENSE
- begrense
- grenser
- Bor
- logg
- gjøre
- GJØR AT
- administrer
- ledelse
- mange
- maksimal
- Minne
- Metrics
- modifisere
- Overvåke
- overvåket
- overvåking
- mer
- mest
- mye
- flere
- multiplisere
- nemlig
- nødvendig
- Trenger
- nettverk
- Ny
- Antall
- Målet
- of
- on
- ONE
- bare
- utover
- åpen
- åpen kildekode
- betjene
- Optimalisere
- optimalisert
- Alternativ
- or
- rekkefølge
- organisasjons
- Annen
- ellers
- vår
- utenfor
- Overcome
- overstyring
- egen
- pakke
- parameter
- parametere
- del
- Spesielt
- mønstre
- for
- ytelse
- fly
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- Point
- Politikk
- politikk
- Populær
- mulig
- Post
- praksis
- praksis
- forebygge
- Principal
- Problem
- Produksjon
- gi
- gir
- offentlig
- sette
- Python
- Lesning
- klar
- anbefaler
- redusere
- referere
- region
- registrert
- slektning
- slipp
- påkrevd
- Krav
- ressurs
- Ressurser
- begrense
- Kjør
- rennende
- går
- samme
- Skala
- scenarier
- Søk
- seksjoner
- sektor
- sikre
- sikkert
- sikkerhet
- sikkerhetspolitikk
- se
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- innstilling
- innstillinger
- oppsett
- Vis
- samtidig
- enkelt
- Størrelse
- størrelser
- Software
- løsning
- Solutions
- noen
- kilde
- Spark
- spesialist
- spesifikk
- utgifter
- spagaten
- oppstart
- Steps
- Still
- rett fram
- send
- subnett
- subnett
- slik
- tilstrekkelig
- Støttes
- Støtte
- sikker
- TAG
- lag
- lag
- mal
- test
- Testing
- Det
- De
- deres
- Dem
- derfor
- Disse
- denne
- tid
- tidssensitiv
- til
- også
- verktøy
- verktøy
- Totalt
- spor
- Sporing
- to
- etter
- lomper
- us
- bruk
- bruke
- bruk-tilfeller
- brukt
- Bruker
- Brukere
- bruker
- ved hjelp av
- ulike
- versjon
- versjoner
- visualisere
- ønsker
- var
- we
- web
- webtjenester
- VI VIL
- var
- Hva
- når
- hvilken
- HVEM
- vil
- med
- innenfor
- uten
- ord
- Arbeid
- arbeidstaker
- arbeidere
- ville
- du
- Din
- zephyrnet
- soner