Bilde opprettet på DALL-E
Vet du at valgresultater til en viss grad kan forutsies ved å gjøre sentimentanalyse? Datavitenskap kan være både morsomt og veldig nyttig når det brukes på virkelige situasjoner i stedet for å jobbe med falske datasett.
I denne artikkelen vil vi gjennomføre en kort casestudie ved å bruke Twitter-data. Til slutt vil du se en casestudie som har en betydelig innvirkning på det virkelige liv, som helt sikkert vil vekke interessen din. Men først, la oss starte med det grunnleggende.
Sentimentanalyse er en metode som brukes til å forutsi følelser, som digitale psykologer. Med denne, psykolog du opprettet, vil skjebnen til teksten du vil analysere være i dine hender. Du kan gjøre det som den berømte psykologen Freud, eller du kan bare være der som en psykolog, og belaste 10 dollar per økt.
Akkurat som psykologen din lytter og forstår følelsene dine, gjør sentimentanalyse de samme tingene på tekst, som anmeldelser, kommentarer eller tweets, som vi vil gjøre i neste avsnitt. For å gjøre det, la oss begynne å gjøre en casestudie på det klare datasettet.
For å gjøre sentimentanalyse vil vi bruke datasett fra Kaggle. Her ble dette datasettet samlet ved å bruke twitter api. Her er lenken til dette datasettet: https://www.kaggle.com/datasets/kazanova/sentiment140
La oss nå begynne å utforske datasettet.
Utforsk datasettet
Nå, før vi gjør sentimentanalyse, la oss utforske datasettet vårt. For å lese den, bruk koding. På grunn av dette vil vi legge til kolonnenavn etterpå. Du kan øke metodene for å gjøre datautforskning. Head, info og describe-metoden vil gi deg en god heads up; la oss se koden.
import pandas as pd data = pd.read_csv('training.csv', encoding='ISO-8859-1', header=None)
column_names = ['target', 'ids', 'date', 'flag', 'user', 'text']
data.columns = column_names
head = data.head()
info = data.info()
describe = data.describe()
head, info, describe
Her er utgangen.
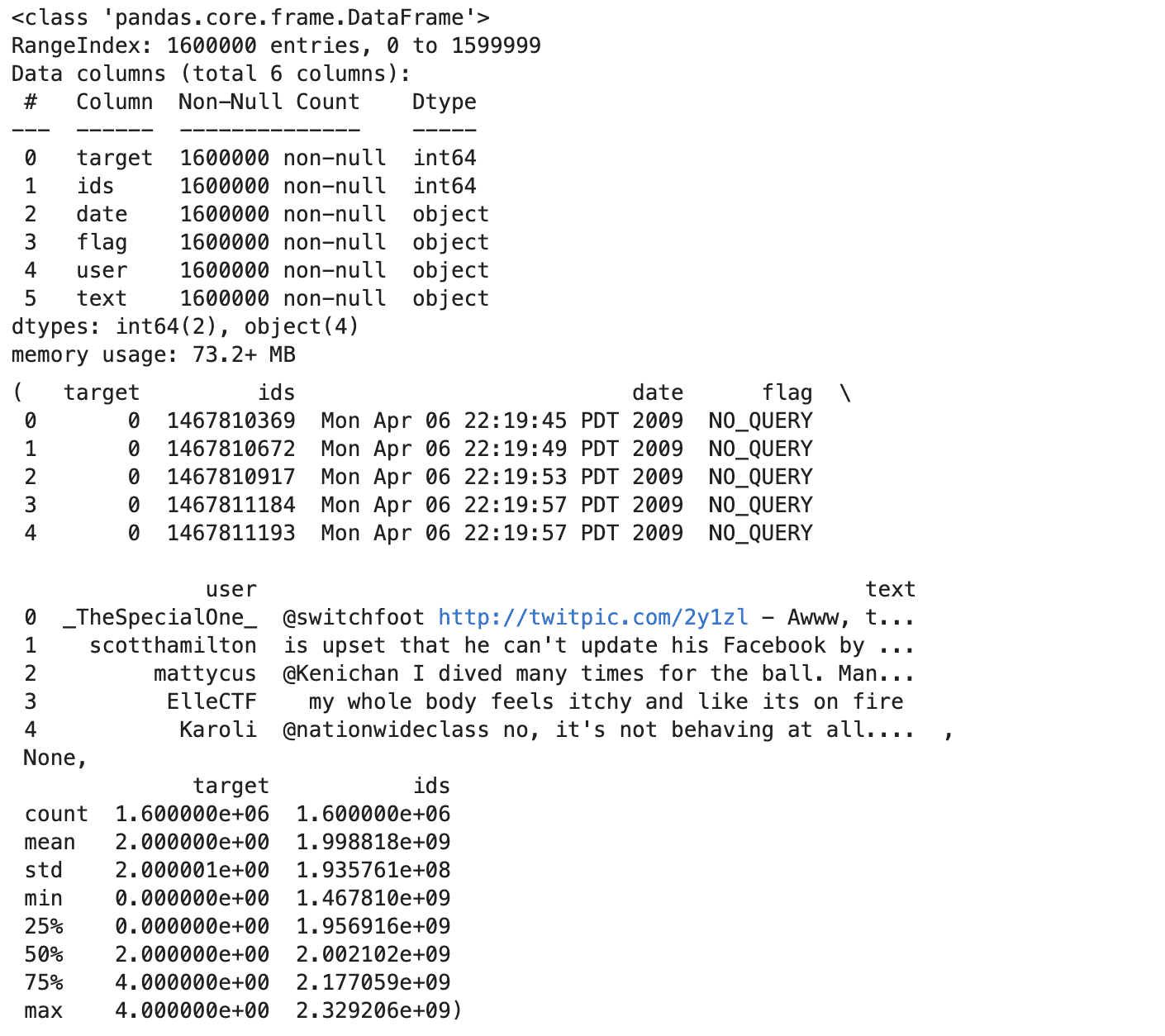
Selvfølgelig kan du kjøre disse metodene en etter en hvis du ikke har bildebegrensning på prosjektet ditt. La oss se innsikten vi samler inn fra disse utforskningsmetodene ovenfor.
Insights
- Datasettet har 1.6 millioner tweets, uten manglende verdier i noen kolonne.
- Hver tweet har en målfølelse (0 for negativ, 2 nøytral, 4 for positiv), en ID, et tidsstempel, et flagg (spørring eller 'NO_QUERY'), brukernavnet og teksten.
- Sentimentmålene er balanserte, med like mange positive og negative merker.
Visualiser datasettet
Fantastisk, vi har både statistisk og strukturell kunnskap om datasettet vårt. La oss nå lage noen visualiseringer for å avbilde det. Nå kjenner vi alle de skarpeste følelsene, positive og negative. For å se hvilke ord som skal brukes til det, bruker vi et av de python-biblioteker kalt wordcloud.
Dette biblioteket vil visualisere datasettene dine i henhold til frekvensen av ordene i det. Hvis ord brukes ofte, vil du forstå det ved å se på størrelsen på det, det er en positiv sammenheng, hvis ordet er større, bør det brukes mye.
Men først bør vi velge positive og negative tweets og kombinere dem ved å bruke python join-metoden etterpå. La oss se koden.
# Separate positive and negative tweets based on the 'target' column
positive_tweets = data[data['target'] == 4]['text']
negative_tweets = data[data['target'] == 0]['text'] # Sample some positive and negative tweets to create word clouds
sample_positive_text = " ".join(text for text in positive_tweets.sample(frac=0.1, random_state=23))
sample_negative_text = " ".join(text for text in negative_tweets.sample(frac=0.1, random_state=23)) # Generate word cloud images for both positive and negative sentiments
wordcloud_positive = WordCloud(width=800, height=400, max_words=200, background_color="white").generate(sample_positive_text)
wordcloud_negative = WordCloud(width=800, height=400, max_words=200, background_color="white").generate(sample_negative_text) # Display the generated image using matplotlib
plt.figure(figsize=(15, 7.5)) # Positive word cloud
plt.subplot(1, 2, 1)
plt.imshow(wordcloud_positive, interpolation='bilinear')
plt.title('Positive Tweets Word Cloud')
plt.axis("off") # Negative word cloud
plt.subplot(1, 2, 2)
plt.imshow(wordcloud_negative, interpolation='bilinear')
plt.title('Negative Tweets Word Cloud')
plt.axis("off") plt.show()
Her er utgangen.
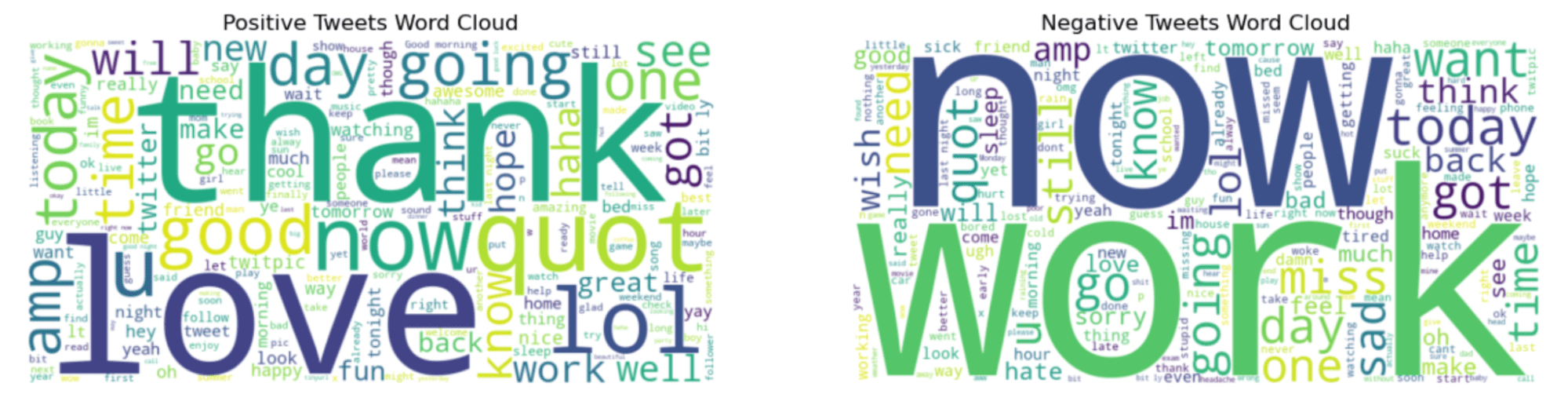
"Takk" og "nå"-ord i grafen til venstre høres mer positivt ut. Imidlertid ser "jobb" og "nå" interessant ut fordi disse ordene ser ut som om de ofte er i negative tweets.
Sentiment Analyse
For å utføre sentimentanalyse, her er trinnene vi vil følge;
- Forbehandle tekstdataene
- Del datasettet
- Vektoriser datasettet
- Datakonvertering
- Etikettkoding
- Tren et nevrale nettverk
- Tren modellen
- Evaluer modellen (med plotting)
Nå kan det å jobbe med 1.6 millioner tweets være en stor arbeidsbelastning for datamaskinen eller plattformen din; det er derfor jeg valgte 50K positive og 50K negative tweets først.
# Since we need to use a smaller dataset due to resource constraints, let's sample 100k tweets
# Balanced sampling: 50k positive and 50k negative
sample_size_per_class = 50000 positive_sample = data[data['target'] == 4].sample(n=sample_size_per_class, random_state=23)
negative_sample = data[data['target'] == 0].sample(n=sample_size_per_class, random_state=23) # Combine the samples into one dataset
balanced_sample = pd.concat([positive_sample, negative_sample]) # Check the balance of the sampled data
balanced_sample['target'].value_counts()
Deretter, la oss bygge våre nevrale nett.
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(max_features=10000, ngram_range=(1, 2)) # Train and test split
X_train, X_val, y_train, y_val = train_test_split(balanced_sample['text'], balanced_sample['target'], test_size=0.2, random_state=23) # After vectorizing the text data using TF-IDF
X_train_vectorized = vectorizer.fit_transform(X_train)
X_val_vectorized = vectorizer.transform(X_val) # Convert the sparse matrix to a dense matrix
X_train_vectorized = X_train_vectorized.todense()
X_val_vectorized = X_val_vectorized.todense() # Convert labels to one-hot encoding
encoder = LabelEncoder()
y_train_encoded = to_categorical(encoder.fit_transform(y_train))
y_val_encoded = to_categorical(encoder.transform(y_val)) # Define a simple neural network model
model = Sequential()
model.add(Dense(512, input_shape=(X_train_vectorized.shape[1],), activation='relu'))
model.add(Dense(2, activation='softmax')) # 2 because we have two classes # Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # Train the model over epochs
history = model.fit(X_train_vectorized, y_train_encoded, epochs=10, batch_size=128, validation_data=(X_val_vectorized, y_val_encoded), verbose=1) # Plotting the model accuracy over epochs
plt.figure(figsize=(10, 6))
plt.plot(history.history['accuracy'], label='Train Accuracy', marker='o')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy', marker='o')
plt.title('Model Accuracy over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show()
Her er utgangen.
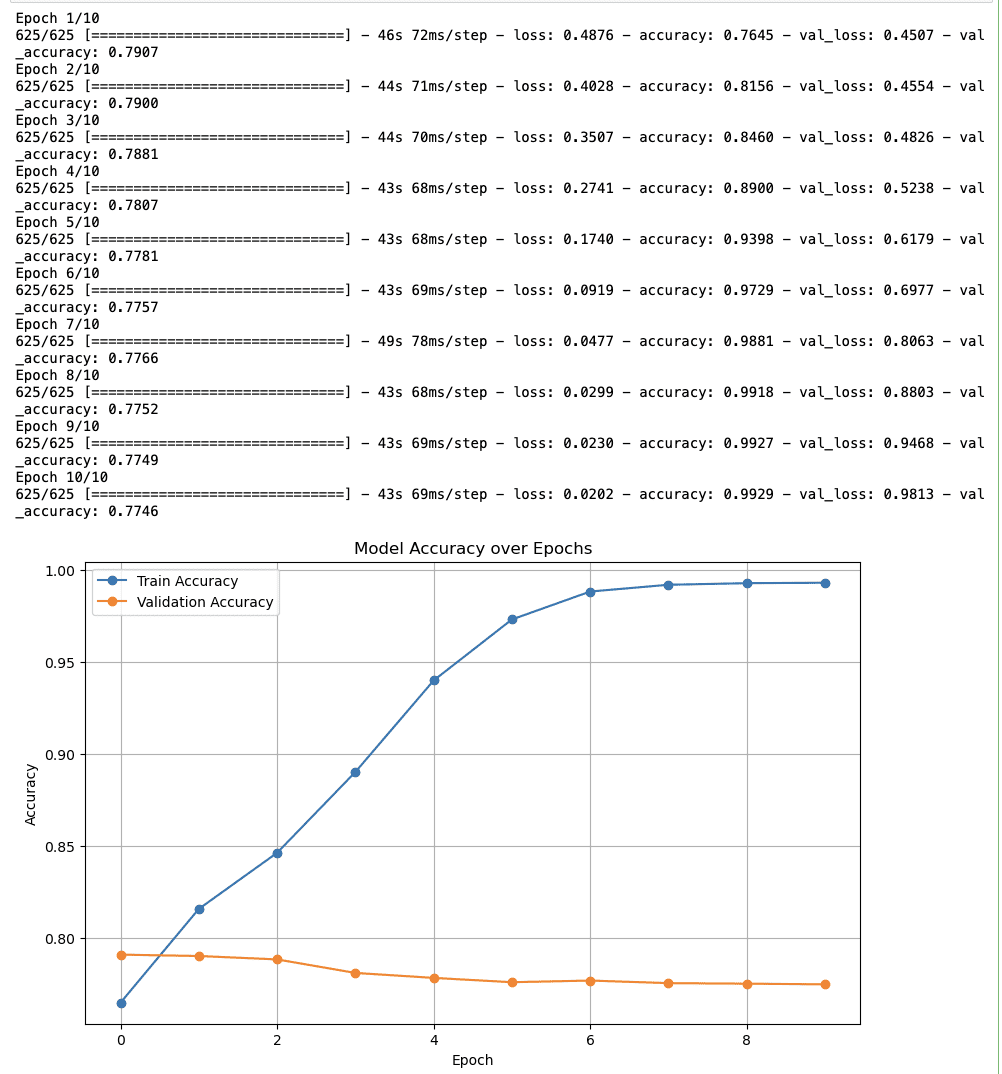
Endelig innsikt om sentimentanalyse
- Treningsnøyaktighet: Nøyaktigheten starter på nesten 80 % og øker konstant til nær 100 % innen den tiende epoken. Så det ser ut til at modellen lærer effektivt.
- Valideringsnøyaktighet: Valideringsnøyaktigheten starter igjen rundt 80 % og fortsetter jevnt og trutt, noe som kan indikere at modellen ikke generaliserer til usynlige data.
I begynnelsen av denne artikkelen ble interessen din vekket. Og la oss nå forklare den virkelige historien bak dette.
Oppgaven fra Forutsi valgresultater fra Twitter ved å bruke maskinlæringsalgoritmer,
publisert i "Recent Advances in Computer Science and Communications", presenterer en maskinlæringsbasert metode for å forutsi valgresultater. Her du kan lese hele.
Oppsummert gjorde de sentimentanalyse, og oppnådde 94.2 % nøyaktighet, på AP-forsamlingsvalget 2019. Det ser ut til at de virkelig kom nærmere.
Hvis du planlegger å gjøre et porteføljeprosjekt, forskning som dette, eller har tenkt å gå videre fra denne casestudien, kan du bruke Twitter API eller x API. Her er planene: https://developer.twitter.com/en/products/twitter-api

Du kan gjøre hashtag-sentimentanalyse på Twitter etter store sports- eller politiske begivenheter. I 2024 vil det være valg i en rekke land som USA, hvor du kan sjekke nyheter.
Kraften til Data Science kan virkelig sees i dette eksemplet. I år vil vi være vitne til en rekke valg over hele verden, så hvis du har som mål å trekke oppmerksomhet til prosjektet ditt, kan dette være en god idé. Hvis du er en nybegynner som søker etter måter å lære datavitenskap på, kan du finne mange virkelige prosjekter, datavitenskapelige intervjuspørsmål, og blogginnlegg med datavitenskapelige prosjekter som dette på StrataScratch.
Nate Rosidi er dataviter og innen produktstrategi. Han er også adjungert professor som underviser i analyse, og er grunnleggeren av StrataScratch, en plattform som hjelper dataforskere med å forberede seg til intervjuene sine med ekte intervjuspørsmål fra toppbedrifter. Ta kontakt med ham Twitter: StrataScratch or Linkedin.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/sentiment-analysis-in-python-going-beyond-bag-of-words?utm_source=rss&utm_medium=rss&utm_campaign=sentiment-analysis-in-python-going-beyond-bag-of-words
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100k
- 14
- 15%
- 2%
- 2019
- 2024
- 25
- 35%
- 4
- 5
- 50000
- 6
- 7
- a
- Om oss
- ovenfor
- Ifølge
- nøyaktighet
- oppnådd
- Adam
- legge til
- adjunkt
- fremskritt
- Etter
- etterpå
- en gang til
- sikte
- algoritmer
- Alle
- også
- an
- analyse
- analytics
- analysere
- og
- noen
- api
- anvendt
- ER
- rundt
- Artikkel
- AS
- Montering
- At
- oppmerksomhet
- veske
- Veske med ord
- Balansere
- balanserte
- basert
- Grunnleggende
- BE
- fordi
- før du
- Nybegynner
- Begynnelsen
- bak
- Beyond
- større
- bilineær
- Blogg
- Blogginnlegg
- både
- bygge
- Bunch
- men
- by
- som heter
- CAN
- saken
- case study
- lading
- sjekk
- klasser
- Lukke
- Cloud
- kode
- samle
- samlet
- Kolonne
- kolonner
- kombinere
- kommentarer
- kommunikasjon
- Selskaper
- datamaskin
- informatikk
- Gjennomføre
- Koble
- stadig
- begrensninger
- fortsetter
- Konvertering
- konvertere
- kunne
- land
- kurs
- skape
- opprettet
- dato
- datavitenskap
- dataforsker
- datasett
- Dato
- definere
- tett
- beskrive
- gJORDE
- digitalt
- Vise
- do
- gjør
- gjør
- dollar
- ikke
- tegne
- to
- effektivt
- Valg
- Valg
- følelser
- koding
- slutt
- epoke
- epoker
- lik
- Eter (ETH)
- hendelser
- eksempel
- Forklar
- leting
- utforske
- Utforske
- grad
- berømt
- Featuring
- følelser
- Finn
- Først
- følge
- Til
- Grunnleggeren
- Frekvens
- ofte
- fra
- videre
- generere
- generert
- Gi
- Go
- skal
- god
- fikk
- graf
- flott
- hender
- hashtag
- Ha
- he
- hode
- .
- hjelpe
- her.
- ham
- historie
- Men
- HTTPS
- i
- ID
- Tanken
- ids
- if
- bilde
- bilder
- Påvirkning
- importere
- in
- Øke
- øker
- indikerer
- info
- innsikt
- hensikt
- interesse
- interessant
- Intervju
- intervju spørsmål
- intervjuer
- inn
- IT
- bli medlem
- bare
- KDnuggets
- hard
- Vet
- kunnskap
- etiketter
- lag
- LÆRE
- læring
- venstre
- la
- Bibliotek
- Life
- i likhet med
- BEGRENSE
- LINK
- lytter
- Se
- ser ut som
- ser
- UTSEENDE
- Lot
- maskin
- maskinlæring
- større
- mange
- matplotlib
- Matrix
- metode
- metoder
- kunne
- millioner
- mangler
- modell
- modeller
- mer
- navn
- Nær
- nesten
- Trenger
- negativ
- Nets
- nettverk
- nettverk
- neural
- nevrale nettverket
- nevrale nettverk
- Nøytral
- neste
- Nei.
- nå
- Antall
- mange
- of
- off
- ofte
- on
- ONE
- or
- vår
- produksjon
- enn
- pandaer
- Papir
- for
- utføre
- bilde
- fly
- planer
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- politisk
- portefølje
- positiv
- innlegg
- makt
- forutsi
- spådd
- forutsi
- Forbered
- gaver
- Produkt
- Professor
- prosjekt
- prosjekter
- Python
- spørring
- spørsmål
- raskt
- heller
- Lese
- klar
- ekte
- ekte liv
- virkelig
- nylig
- forhold
- gjenopptakelse
- forskning
- ressurs
- Resultater
- Anmeldelser
- Kjør
- s
- samme
- sample
- Vitenskap
- Forsker
- forskere
- søker
- Seksjon
- se
- sett
- velg
- valgt
- sentiment
- følelser
- separat
- Session
- Skarpest
- bør
- signifikant
- Enkelt
- siden
- situasjoner
- Størrelse
- mindre
- So
- noen
- Lyd
- sparsom
- sparsom matrise
- splittet
- Sports
- Begynn
- starter
- Stater
- statistisk
- stadig
- Steps
- Story
- Strategi
- strukturell
- Studer
- SAMMENDRAG
- sikkert
- Target
- mål
- Undervisning
- tensorflow
- tiende
- test
- tekst
- enn
- Det
- De
- Grunnleggende
- Grafen
- deres
- Dem
- Der.
- Disse
- de
- ting
- denne
- dette året
- tidsstempel
- til
- sammen
- topp
- Tog
- Kurs
- sant
- tweet
- tweets
- to
- forstå
- forstår
- forent
- Forente Stater
- bruke
- brukt
- nyttig
- Bruker
- brukernavn
- ved hjelp av
- validering
- Verdier
- veldig
- visualisere
- var
- måter
- we
- når
- hvilken
- hvit
- hele
- hvorfor
- vil
- med
- Vitne
- ord
- ord
- arbeid
- verdensomspennende
- X
- år
- du
- Din
- zephyrnet