Bilde fra Midjourney
Som dataforsker leter jeg alltid etter måter å maksimere effektiviteten og skape forretningsverdi med data.
Så da ChatGPT ga ut en av de kraftigste funksjonene til nå? Kodetolker-pluginen, måtte jeg rett og slett prøve å innlemme den i arbeidsflytene mine.
Hvis du ikke allerede har hørt om Code Interpreter, er dette en ny funksjon som lar deg laste opp kode, kjøre programmer og analysere data i ChatGPT-grensesnittet.
Det siste året, hver gang jeg har måttet feilsøke kode eller analysere et dokument, måtte jeg kopiere arbeidet mitt og lime det inn i ChatGPT for å få svar.
Dette viste seg å være tidkrevende og ChatGPT-grensesnittet har en tegngrense, noe som begrenset min evne til å analysere data og utføre arbeidsflyter for maskinlæring.
Kodetolken løser alle disse problemene ved å la deg laste opp dine egne datasett til ChatGPT-grensesnittet.
Og selv om det kalles «kodetolk», er denne funksjonen ikke begrenset til programmerere?—?pluginen kan hjelpe deg med å analysere tekstfiler, oppsummere PDF-dokumenter, bygge datavisualiseringer og til og med beskjære bilder i henhold til ønsket forhold.
Før vi kommer inn på applikasjonene, la oss raskt gå gjennom hvordan du kan begynne å bruke kodetolk-plugin.
For å få tilgang til denne plugin-en må du ha et betalt abonnement på Chat GPT Plus, som for tiden er på $20 i måneden.
Kodetolker har dessverre ikke blitt gjort tilgjengelig for brukere som ikke abonnerer på ChatGPT Plus.
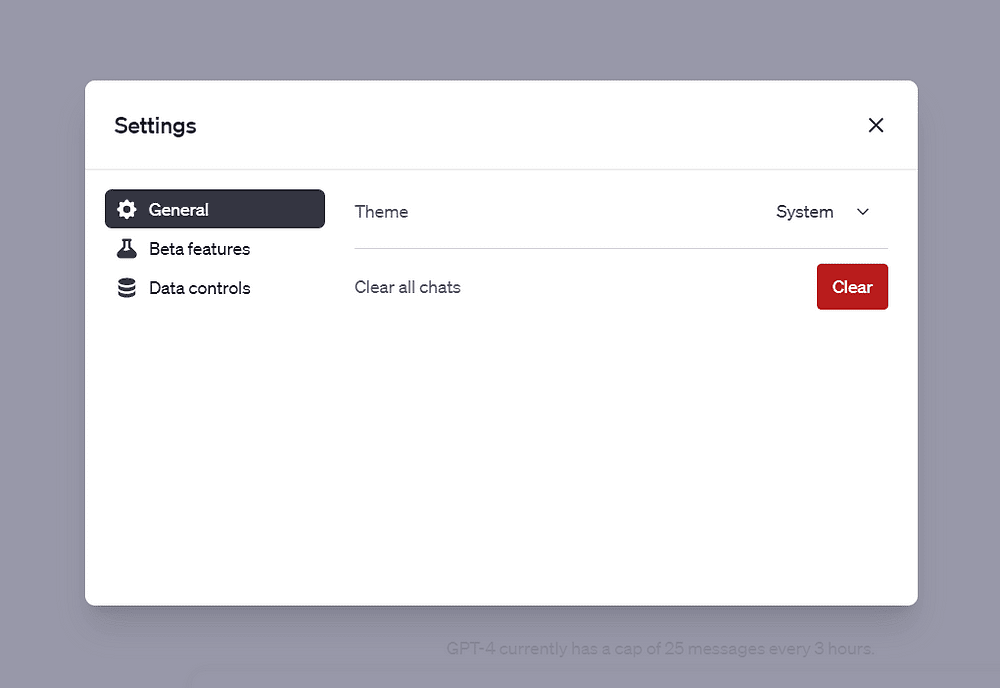
Når du har et betalt abonnement, er det bare å navigere til ChatGPT og klikk på de tre prikkene nederst til venstre i grensesnittet.
Deretter velger du Innstillinger:
Bilde av forfatter
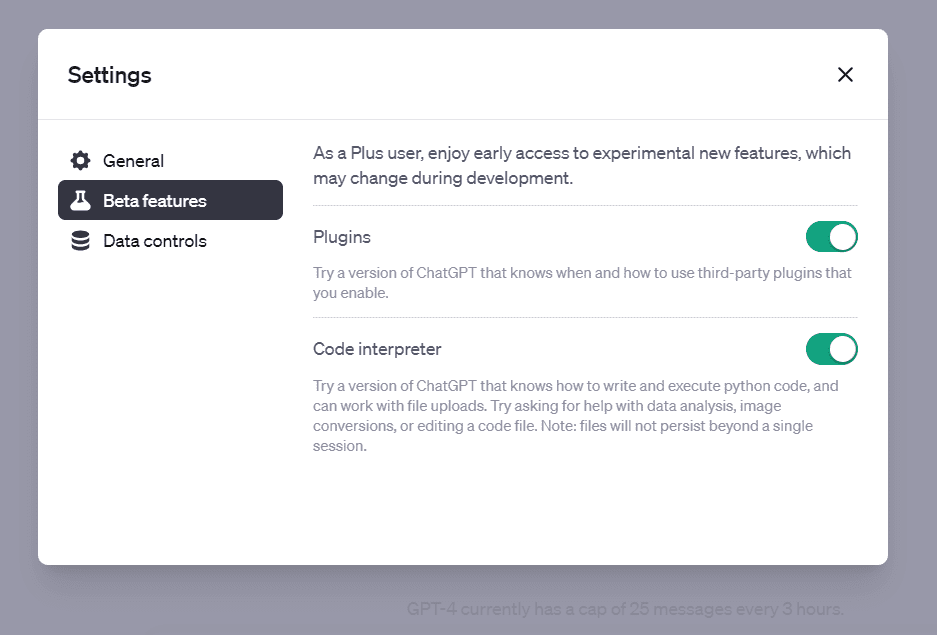
Klikk på "Betafunksjoner" og aktiver glidebryteren som sier Kodetolk:
Bilde av forfatter
Til slutt, klikk på "Ny chat", velg "GPT-4"-alternativet, og velg "Kodetolk" på rullegardinmenyen som vises:
Du vil se en skjerm som ser slik ut, med et "+"-symbol nær tekstboksen:

Bilde av forfatter
Flott! Du har nå aktivert ChatGPT Code Interpreter.
I denne artikkelen vil jeg vise deg fem måter du kan bruke Code Interpreter til å automatisere datavitenskapelige arbeidsflyter.
Som dataforsker bruker jeg mye tid på å bare prøve å forstå de forskjellige variablene som finnes i datasettet.
Code Interpreter gjør en god jobb med å bryte ned hvert datapunkt for deg.
Slik kan du få modellen til å hjelpe deg med å oppsummere data:
La oss bruke Titanic Survival Prediction datasett på Kaggle for dette eksemplet. Jeg kommer til å bruke "train.csv" filen.
Last ned datasettet og naviger til Kodetolk:
Bilde av forfatter
Klikk på "+"-symbolet og last opp filen du vil oppsummere.
Be deretter ChatGPT om å forklare alle variablene i denne filen på en enkel måte:
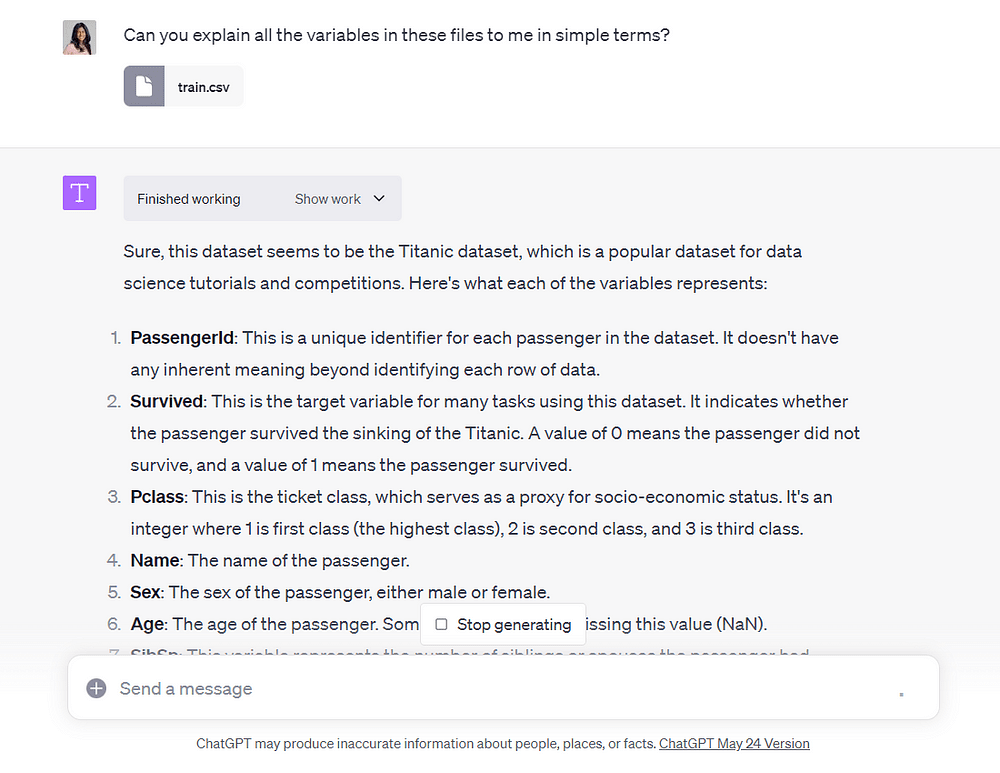
Bilde av forfatter
Voila!
Code Interpreter ga oss enkle forklaringer av hver variabel i datasettet.
Nå som vi har en forståelse av de forskjellige variablene i datasettet, la oss be Code Interpreter om å gå et skritt videre og utføre litt EDA.
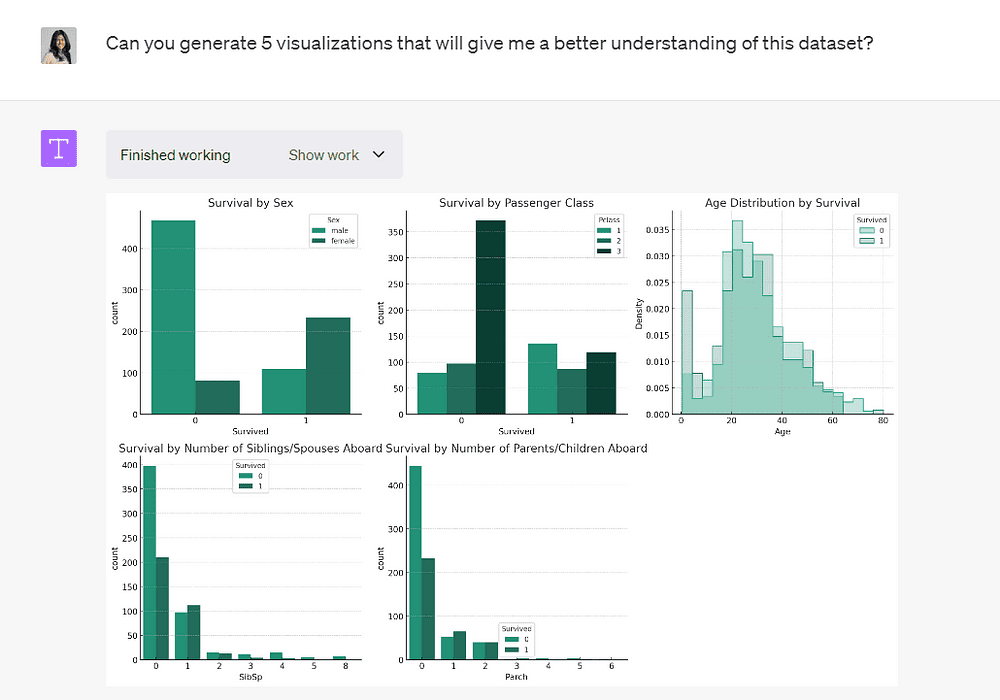
Bilde av forfatter
Modellen har generert 5 plott som gjør at vi bedre kan forstå de ulike variablene i dette datasettet.
Hvis du klikker på rullegardinmenyen "Vis arbeid", vil du legge merke til at Code Interpreter har skrevet og kjørt Python-kode for å hjelpe oss med å oppnå sluttresultatet:
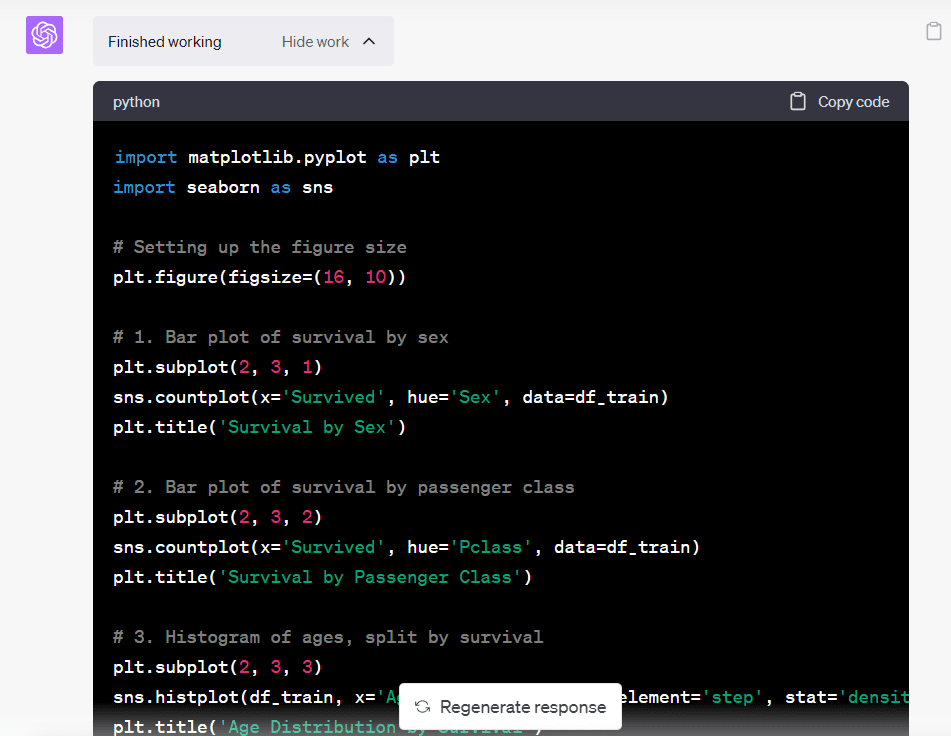
Bilde av forfatter
Du kan alltid kopiere og lime inn denne koden i din egen Jupyter Notebook hvis du ønsker å utføre ytterligere analyse.
ChatGPT har også gitt oss litt innsikt i datasettet basert på visualiseringene som er generert:

Bilde av forfatter
Det forteller oss at kvinner, førsteklasses passasjerer og yngre passasjerer hadde høyere overlevelsesrater.
Dette er innsikt som vil ta tid å hente for hånd, spesielt hvis du ikke er godt kjent med Python og datavisualiseringsbiblioteker som Matplotlib.
Code Interpreter genererte dem i løpet av få sekunder, noe som reduserte tiden det tok å utføre EDA betydelig.
Jeg bruker mye tid på å rense datasett og forberede dem til modelleringsprosessen.
La oss be Code Interpreter hjelpe oss med å forhåndsbehandle dette datasettet:
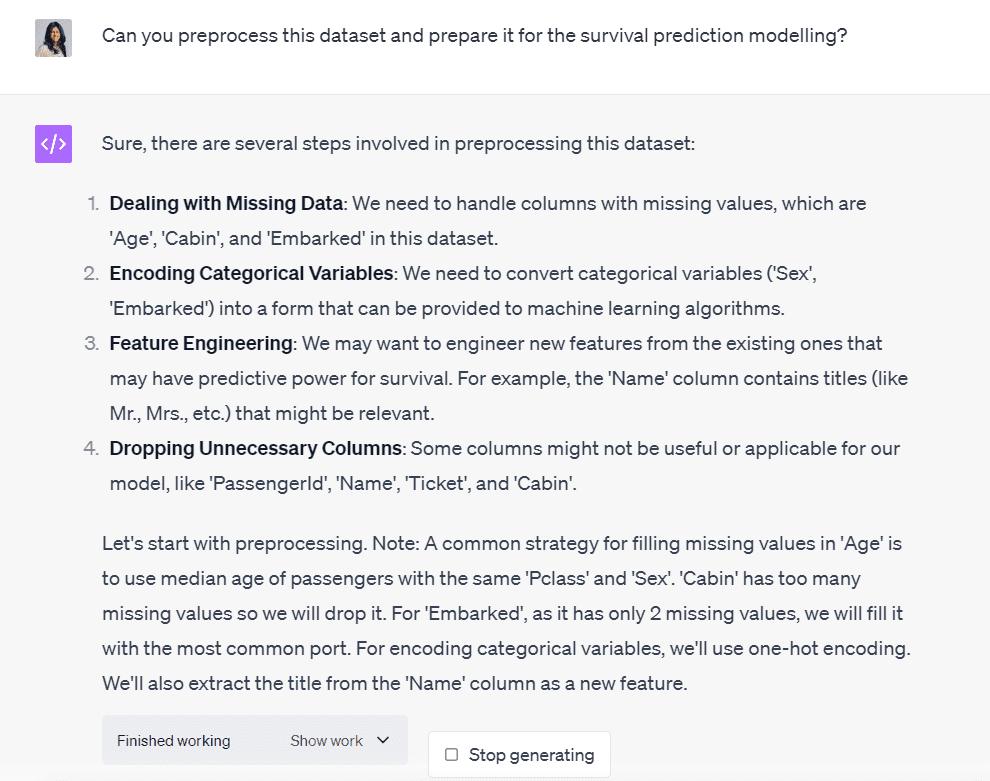
Bilde av forfatter
Code Interpreter har skissert alle trinnene som er involvert i prosessen med å rense dette datasettet.
Det forteller oss at vi må håndtere tre kolonner med manglende verdier, kode to kategoriske variabler, utføre noe funksjonsutvikling og slippe kolonner som er irrelevante for modelleringsprosessen.
Det fortsatte med å lage et Python-program som gjorde all forbehandlingen på bare sekunder.
Du kan klikke på "Vis arbeid" hvis du vil forstå trinnene modellen har tatt for å utføre datarensingen:
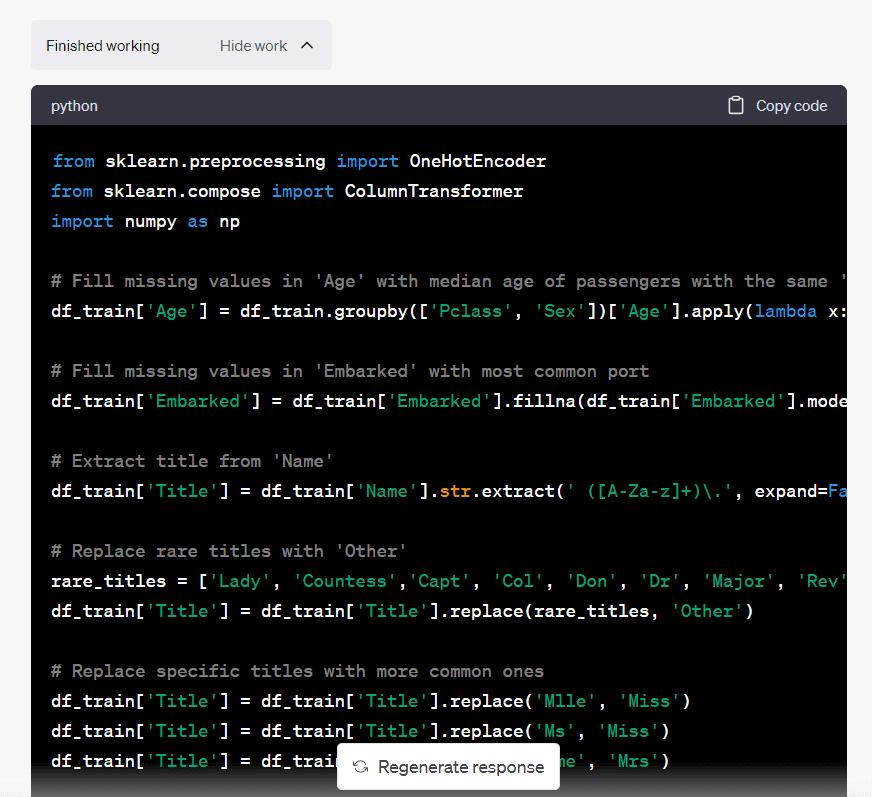
Bilde av forfatter
Så spurte jeg ChatGPT hvordan jeg kunne lagre utdatafilen, og den ga meg en nedlastbar CSV-fil:
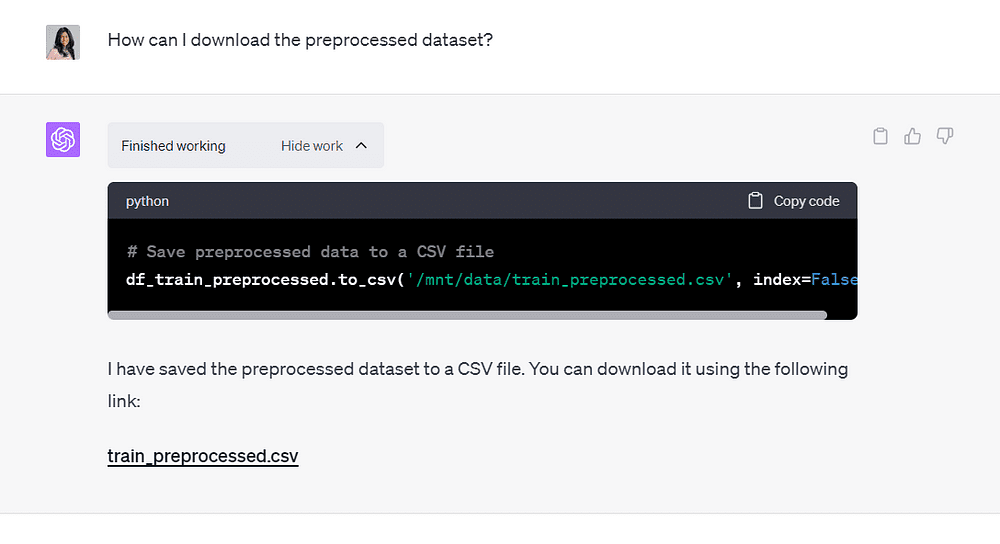
Bilde av forfatter
Legg merke til at jeg ikke en gang måtte kjøre en linje med kode gjennom denne prosessen.
Code Interpreter var i stand til å innta filen min, kjøre kode i grensesnittet og gi meg utdata på rekordtid.
Til slutt ba jeg Code Interpreter om å bruke den forhåndsbehandlede filen til å bygge en maskinlæringsmodell for å forutsi om en person ville overleve Titanic-forliset:
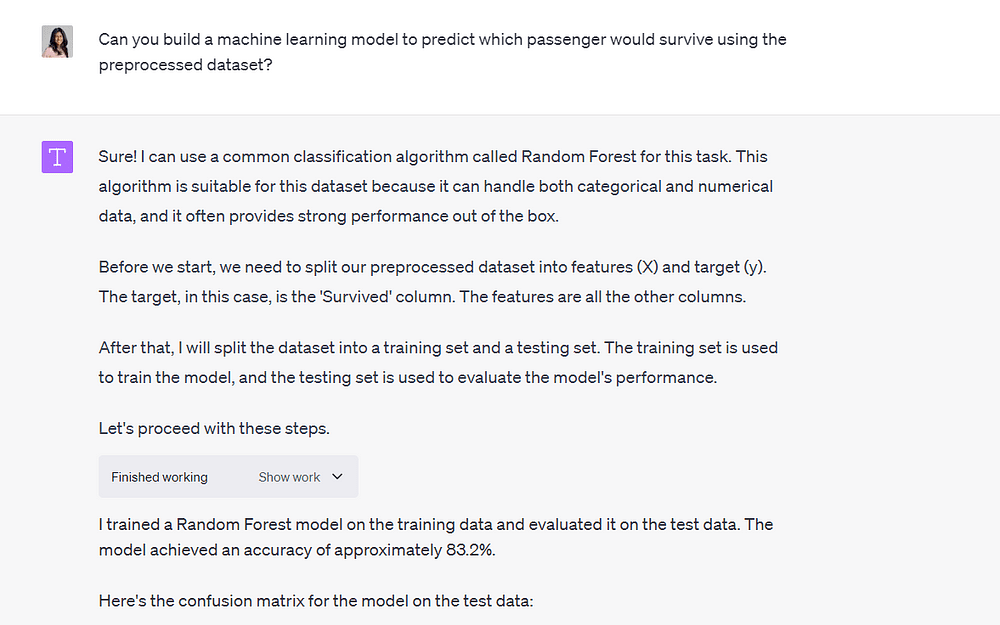
Bilde av forfatter
Den bygde modellen på under ett minutt og var i stand til å nå en nøyaktighet på 83.2 %.
Den ga meg også en forvirringsmatrise og klassifiseringsrapport som oppsummerer modellens ytelse, og forklarte hva alle beregningene representerte:

Bilde av forfatter
Jeg ba ChatGPT om å gi meg en utdatafil som kartla modellspådommene med passasjerdata.
Jeg ville også ha en nedlastbar fil av maskinlæringsmodellen den opprettet, siden vi alltid kan utføre ytterligere finjustering og trene på toppen av den i fremtiden:
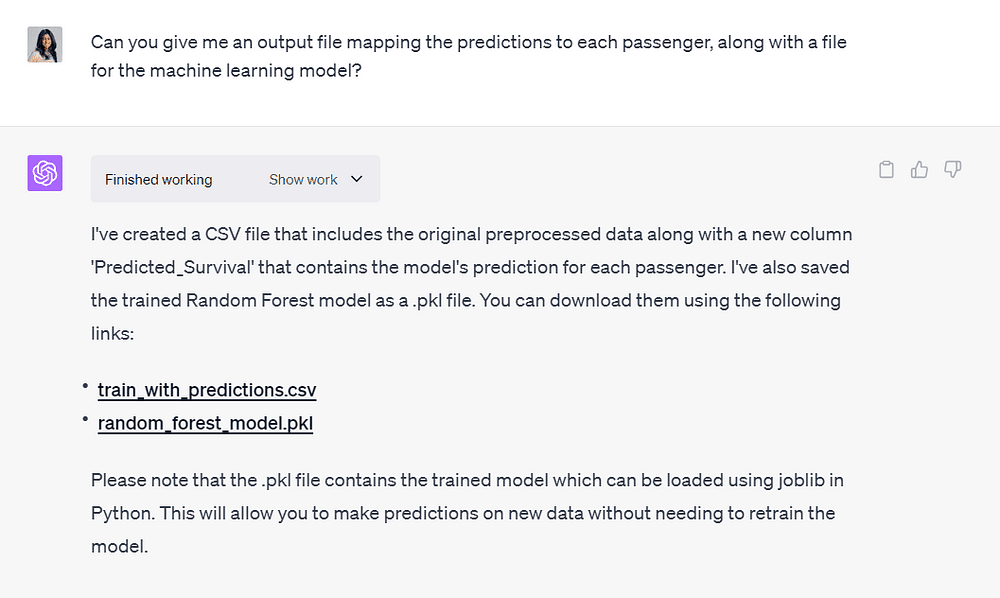
Bilde av forfatter
En annen applikasjon av Code Interpreter som jeg fant nyttig var dens evne til å komme opp med kodeforklaringer.
Bare her om dagen jobbet jeg med en sentimentanalysemodell og fant litt kode på GitHub som var relevant for min brukssituasjon.
Jeg forsto ikke hele koden, siden forfatteren hadde importert biblioteker jeg ikke var kjent med.
Med Code Interpreter kan du ganske enkelt laste opp en kodefil og be den forklare hver linje tydelig.
Du kan også be den om å feilsøke og optimalisere koden for bedre ytelse.
Her er et eksempel?—?Jeg lastet opp en fil som inneholder kode jeg skrev for år siden for å bygge et Python-dashbord:

Bilde av forfatter
Kodetolk brøt ned koden min og skisserte tydelig hva som ble gjort i hver del.

Bilde av forfatter
Den foreslo også å refaktorisere koden min for bedre lesbarhet og forklarte hvor jeg kunne inkludere nye seksjoner.
I stedet for å gjøre dette selv, ba jeg bare Code Interpreter om å refaktorisere koden og gi meg en forbedret versjon:
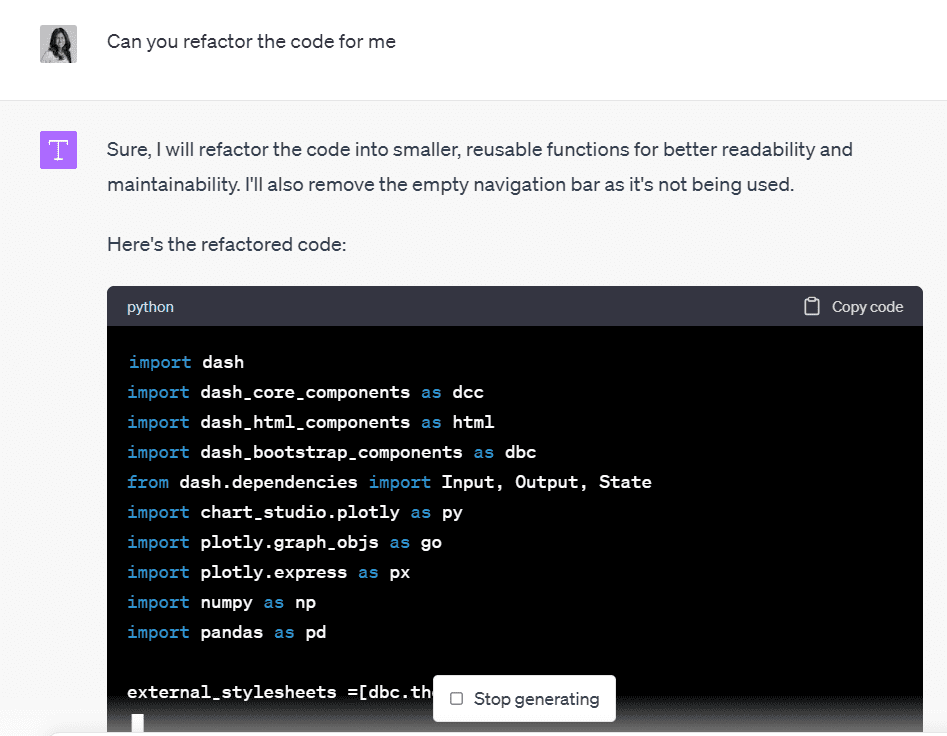
Bilde av forfatter
Code Interpreter skrev om koden min for å kapsle inn hver visualisering i separate funksjoner, noe som gjorde det lettere å forstå og oppdatere.
Det er mye hype rundt Code Interpreter akkurat nå, siden dette er første gang vi er vitne til et verktøy som kan innta kode, forstå naturlig språk og utføre ende-til-ende datavitenskapelige arbeidsflyter.
Det er imidlertid viktig å huske på at dette bare er nok et verktøy som skal hjelpe oss å gjøre datavitenskap mer effektivt.
Så langt har jeg brukt det til å bygge grunnmodeller på dummy-data, siden jeg ikke har lov til å laste opp sensitiv bedriftsinformasjon til ChatGPT-grensesnittet.
Kodetolk har dessuten ikke domenespesifikk kunnskap. Jeg bruker vanligvis spådommene den genererer som basisprognoser?—?Jeg må ofte justere utdataene den genererer for å matche organisasjonens brukstilfelle.
Jeg kan ikke presentere tallene generert av en algoritme som ikke har noen innsyn i selskapets indre.
Til slutt bruker jeg ikke kodetolk for hvert prosjekt, siden noen av dataene jeg jobber med består av millioner av rader og ligger i SQL-databaser.
Dette betyr at jeg fortsatt må utføre mye av spørringen, datautvinningen og transformasjonen selv.
Hvis du er en dataforsker på inngangsnivå eller ønsker å bli det, vil jeg foreslå å lære hvordan du kan utnytte verktøy som Code Interpreter for å få de verdslige delene av jobben din gjort mer effektivt.
Det var alt for denne artikkelen, takk for at du leste!
Natassha Selvaraj er en selvlært dataforsker med en lidenskap for skriving. Du kan få kontakt med henne Linkedin.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Bil / elbiler, Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- BlockOffsets. Modernisering av eierskap for miljøkompensasjon. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/07/chatgpt-code-interpreter-data-science-minutes.html?utm_source=rss&utm_medium=rss&utm_campaign=chatgpt-code-interpreter-do-data-science-in-minutes
- : har
- :er
- :ikke
- :hvor
- $OPP
- 2%
- a
- evne
- I stand
- Om oss
- adgang
- Ifølge
- nøyaktighet
- Oppnå
- siden
- algoritme
- Alle
- tillate
- tillatt
- tillate
- tillater
- allerede
- også
- Selv
- alltid
- am
- beløp
- an
- analyse
- analysere
- og
- En annen
- Søknad
- søknader
- ER
- rundt
- Artikkel
- AS
- spurte
- strebe
- At
- forfatter
- automatisere
- tilgjengelig
- basert
- Baseline
- BE
- bli
- vært
- Bedre
- Eske
- Breaking
- Broke
- bygge
- bygget
- virksomhet
- by
- som heter
- CAN
- Kan få
- kan ikke
- saken
- karakter
- ChatGPT
- klassifisering
- Rengjøring
- klart
- klikk
- kode
- kolonner
- Kom
- Selskapet
- forvirring
- Koble
- forbrukes
- kunne
- skape
- opprettet
- avling
- I dag
- dashbord
- dato
- datavitenskap
- dataforsker
- datavisualisering
- databaser
- datasett
- dag
- ønsket
- gJORDE
- forskjellig
- do
- dokument
- dokumenter
- gjør
- gjør
- gjort
- ikke
- ned
- stasjonen
- Drop
- hver enkelt
- enklere
- effektivitet
- effektivt
- muliggjøre
- aktivert
- slutt
- ende til ende
- Ingeniørarbeid
- Hele
- entry-level
- spesielt
- Selv
- Hver
- eksempel
- henrette
- Forklar
- forklarte
- utdrag
- kjent
- langt
- Trekk
- Egenskaper
- hunner
- filet
- Filer
- Først
- første gang
- fem
- Til
- prognoser
- funnet
- fra
- funksjoner
- videre
- framtid
- generelt
- generert
- genererer
- få
- GitHub
- Go
- skal
- flott
- HAD
- hånd
- håndtere
- Ha
- hørt
- hjelpe
- her
- høyere
- Hvordan
- Hvordan
- HTTPS
- Hype
- i
- if
- bilder
- viktig
- forbedret
- in
- inkludere
- innlemme
- informasjon
- innsikt
- innsikt
- Interface
- inn
- involvert
- saker
- IT
- DET ER
- Jobb
- jpg
- Jupyter Notebook
- bare
- KDnuggets
- Hold
- kunnskap
- Språk
- læring
- Leverage
- bibliotekene
- i likhet med
- BEGRENSE
- Begrenset
- linje
- ser
- UTSEENDE
- Lot
- maskin
- maskinlæring
- laget
- Making
- kartlegging
- Match
- matplotlib
- Matrix
- Maksimer
- me
- midler
- bare
- Metrics
- millioner
- tankene
- minutt
- minutter
- mangler
- modell
- modellering
- modeller
- Måned
- mer
- mest
- mye
- my
- Naturlig
- Naturlig språk
- Naviger
- Nær
- Trenger
- Ny
- ny funksjon
- Nei.
- bærbare
- Legge merke til..
- nå
- tall
- of
- ofte
- on
- ONE
- videre til
- OpenAI
- Optimalisere
- Alternativ
- or
- Annen
- skissert
- produksjon
- egen
- betalt
- deler
- lidenskap
- Past
- utføre
- ytelse
- person
- plato
- Platon Data Intelligence
- PlatonData
- plugg inn
- i tillegg til
- Point
- kraftig
- forutsi
- Spådommer
- forbereder
- presentere
- prosess
- program
- programmerere
- programmer
- prosjekt
- beviste
- gi
- forutsatt
- Python
- raskt
- priser
- ratio
- å nå
- rekord
- redusere
- Refaktor
- utgitt
- relevant
- rapporterer
- representert
- svar
- begrenset
- resultere
- ikke sant
- Kjør
- Spar
- sier
- Vitenskap
- Forsker
- Skjerm
- sekunder
- Seksjon
- seksjoner
- se
- sensitive
- sentiment
- separat
- innstillinger
- Vis
- betydelig
- Enkelt
- ganske enkelt
- siden
- glidebryter
- løser
- noen
- bruke
- SQL
- Begynn
- Trinn
- Steps
- Still
- abonnement
- vellykket
- foreslår
- oppsummere
- overlevelse
- overleve
- symbol
- Ta
- tatt
- vilkår
- Takk
- Det
- De
- Fremtiden
- Dem
- Disse
- denne
- tre
- Gjennom
- hele
- tid
- tidkrevende
- til
- verktøy
- verktøy
- topp
- Tog
- Transformation
- prøve
- to
- etter
- forstå
- forståelse
- Oppdater
- lastet opp
- us
- bruke
- bruk sak
- Brukere
- ved hjelp av
- verdi
- Verdier
- variabler
- versjon
- synlighet
- visualisering
- ønsker
- ønsket
- var
- måter
- we
- Hva
- når
- om
- hvilken
- HVEM
- vil
- med
- innenfor
- vitne
- Arbeid
- arbeidsflyt
- arbeid
- hjemkomsten
- ville
- skriving
- skrevet
- skrev
- år
- år
- ennå
- du
- Younger
- Din
- zephyrnet