Bilde av forfatter
GitHub Actions er en kraftig funksjon i GitHub-plattformen som gjør det mulig å automatisere arbeidsflyter for programvareutvikling, for eksempel testing, bygging og distribusjon av kode. Dette effektiviserer ikke bare utviklingsprosessen, men gjør den også mer pålitelig og effektiv.
I denne opplæringen vil vi utforske hvordan du bruker GitHub Actions for et nybegynnerprosjekt for maskinlæring (ML). Fra å sette opp ML-prosjektet vårt på GitHub til å lage en GitHub Actions-arbeidsflyt som automatiserer ML-oppgavene dine, vi vil dekke alt du trenger å vite.
GitHub Actions er et kraftig verktøy som gir en kontinuerlig integrasjon og kontinuerlig levering (CI/CD) pipeline for alle GitHub-depoter gratis. Den automatiserer hele arbeidsflyten for programvareutvikling, fra å lage og teste til å distribuere kode, alt innenfor GitHub-plattformen. Du kan bruke den til å forbedre utviklings- og distribusjonseffektiviteten.
GitHub Actions nøkkelfunksjoner
Vi skal nå lære om nøkkelkomponenter i arbeidsflyten.
Arbeidsflyt
Arbeidsflyter er automatiserte prosesser som du definerer i GitHub-depotet ditt. De er sammensatt av en eller flere jobber og kan utløses av GitHub-hendelser som en push, pull-forespørsel, problemoppretting eller av arbeidsflyter. Arbeidsflyter er definert i en YML-fil i .github/workflows-katalogen i depotet ditt. Du kan redigere den og kjøre arbeidsflyten på nytt rett fra GitHub-depotet.
Jobber og trinn
Innenfor en arbeidsflyt definerer jobber et sett med trinn som utføres på samme løper. Hvert trinn i en jobb kan kjøre kommandoer eller handlinger, som er gjenbrukbare kodebiter som kan utføre en spesifikk oppgave, for eksempel formatering av koden eller opplæring av modellen.
hendelser
Arbeidsflyter kan utløses av forskjellige GitHub-hendelser, for eksempel push, pull-forespørsler, gafler, stjerner, utgivelser og mer. Du kan også planlegge arbeidsflyter til å kjøre på bestemte tidspunkter ved hjelp av cron-syntaks.
Løpere
Løpere er de virtuelle miljøene/maskinene der arbeidsflyter utføres. GitHub gir vertsbaserte løpere Linux-, Windows- og macOS-miljøer, eller du kan være vert for din egen løper for mer kontroll over miljøet.
handlinger
Handlinger er gjenbrukbare kodeenheter som du kan bruke som trinn i jobbene dine. Du kan lage dine egne handlinger eller bruke handlinger som deles av GitHub-fellesskapet i GitHub Marketplace.
GitHub Actions gjør det enkelt for utviklere å automatisere bygge-, test- og distribusjonsarbeidsflytene sine direkte i GitHub, noe som bidrar til å forbedre produktiviteten og strømlinjeforme utviklingsprosessen.
I dette prosjektet vil vi bruke to handlinger:
- actions/checkout@v3: for å sjekke ut depotet ditt slik at arbeidsflyten kan få tilgang til filen og dataene.
- iterative/setup-cml@v2: for å vise modellberegningene og forvirringsmatrisen under commit som en melding.
Vi vil jobbe med et enkelt maskinlæringsprosjekt ved å bruke Bank Churn datasett fra Kaggle for å trene og evaluere en Random Forest Classifier.
Setter opp
- Vi vil opprette GitHub-depotet ved å oppgi navn og beskrivelse, sjekke readme-filen og lisensen.
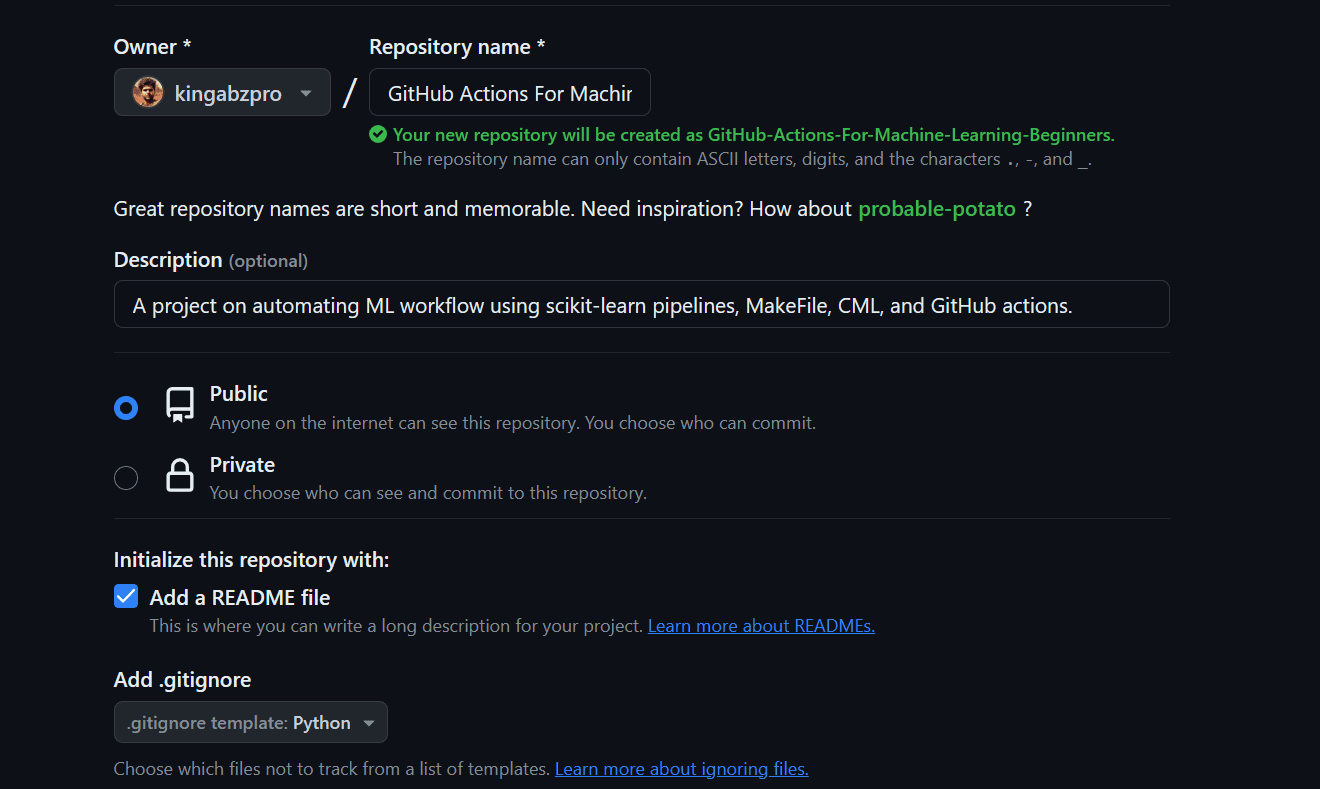
- Gå til prosjektdirektøren og klon depotet.
- Endre katalogen til depotmappen.
- Start koderedigering. I vårt tilfelle er det VSCode.
$ git clone https://github.com/kingabzpro/GitHub-Actions-For-Machine-Learning-Beginners.git
$ cd .GitHub-Actions-For-Machine-Learning-Beginners
$ code .
- Opprett en `requirements.txt`-fil og legg til alle nødvendige pakker som kreves for å kjøre arbeidsflyten vellykket.
pandas
scikit-learn
numpy
matplotlib
skops
black
- Last ned dato fra Kaggle ved å bruke lenken og pakke den ut i hovedmappen.
- Datasettet er stort, så vi må installere GitLFS i vårt depot og spore tog-CSV-filen.
$ git lfs install
$ git lfs track train.csvOpplæring og evaluering av kode
I denne delen vil vi skrive koden som skal trene, evaluere og lagre modellrørledningene. Koden er fra min forrige opplæring, Strømlinjeform maskinlæringsarbeidsflyten din med Scikit-learn-pipelines. Hvis du vil vite hvordan scikit-learn-rørledningen fungerer, bør du lese den.
- Opprett en `train.py`-fil og kopier og lim inn følgende kode.
- Koden bruker ColumnTransformer og Pipeline for å forhåndsbehandle dataene og Pipeline for funksjonsvalg og modelltrening.
- Etter å ha evaluert modellytelsen, lagres både beregninger og forvirringsmatrisen i hovedmappen. Disse beregningene vil bli brukt senere av CML-handlingen.
- Til slutt lagres den siste pipelinen for scikit-learn for modellslutning.
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler, OrdinalEncoder
from sklearn.metrics import accuracy_score, f1_score
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
import skops.io as sio
# loading the data
bank_df = pd.read_csv("train.csv", index_col="id", nrows=1000)
bank_df = bank_df.drop(["CustomerId", "Surname"], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"], axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1, 2]
num_col = [0, 3, 4, 5, 6, 7, 8, 9]
# Transformers for numerical data
numerical_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="mean")), ("scaler", MinMaxScaler())]
)
# Transformers for categorical data
categorical_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OrdinalEncoder()),
]
)
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
("num", numerical_transformer, num_col),
("cat", categorical_transformer, cat_col),
],
remainder="passthrough",
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train, y_train)
## Model Evaluation
predictions = complete_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
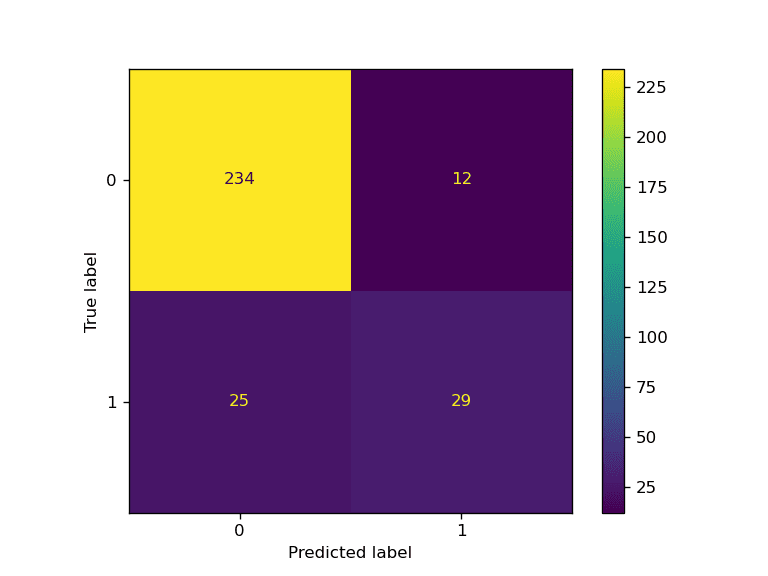
## Confusion Matrix Plot
predictions = complete_pipe.predict(X_test)
cm = confusion_matrix(y_test, predictions, labels=complete_pipe.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=complete_pipe.classes_)
disp.plot()
plt.savefig("model_results.png", dpi=120)
## Write metrics to file
with open("metrics.txt", "w") as outfile:
outfile.write(f"nAccuracy = {round(accuracy, 2)}, F1 Score = {round(f1, 2)}nn")
# saving the pipeline
sio.dump(complete_pipe, "bank_pipeline.skops")
Vi fikk et godt resultat.
$ python train.py
Accuracy: 88.0% F1: 0.77
Du kan lære mer om den indre funksjonen til koden nevnt ovenfor ved å lese "Strømlinjeform maskinlæringsarbeidsflyten din med Scikit-learn-pipelines"
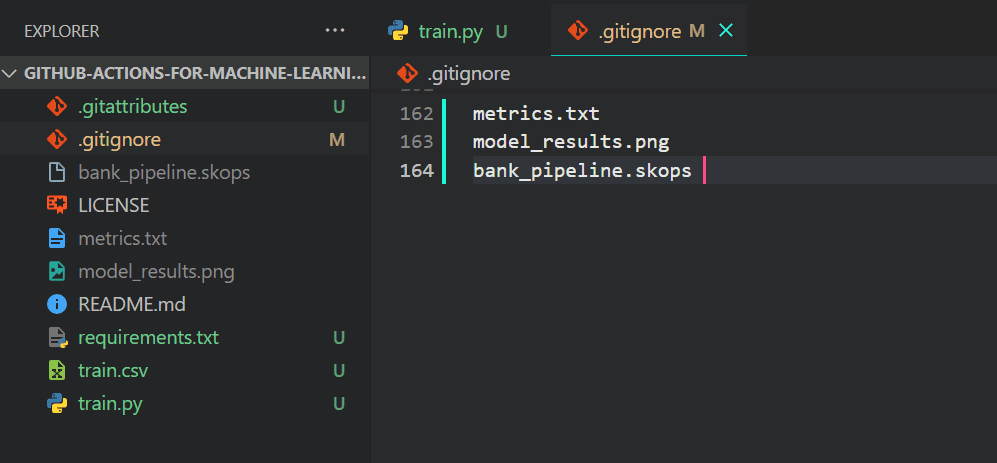
Vi vil ikke at Git skal pushe utdatafiler ettersom de alltid genereres på slutten av koden, så vi legger til .gitignore-filen.
Bare skriv '.gitignore' i terminalen for å starte filen.
$ .gitignore
Legg til følgende filnavn.
metrics.txt
model_results.png
bank_pipeline.skops
Slik skal det se ut på VSCode.
Vi vil nå iscenesette endringene, opprette en forpliktelse og skyve endringene til GitHub-hovedgrenen.
git add .
git commit -m "new changes"
git push origin main
Dette er hvordan din GitHub Repository skal se ut.
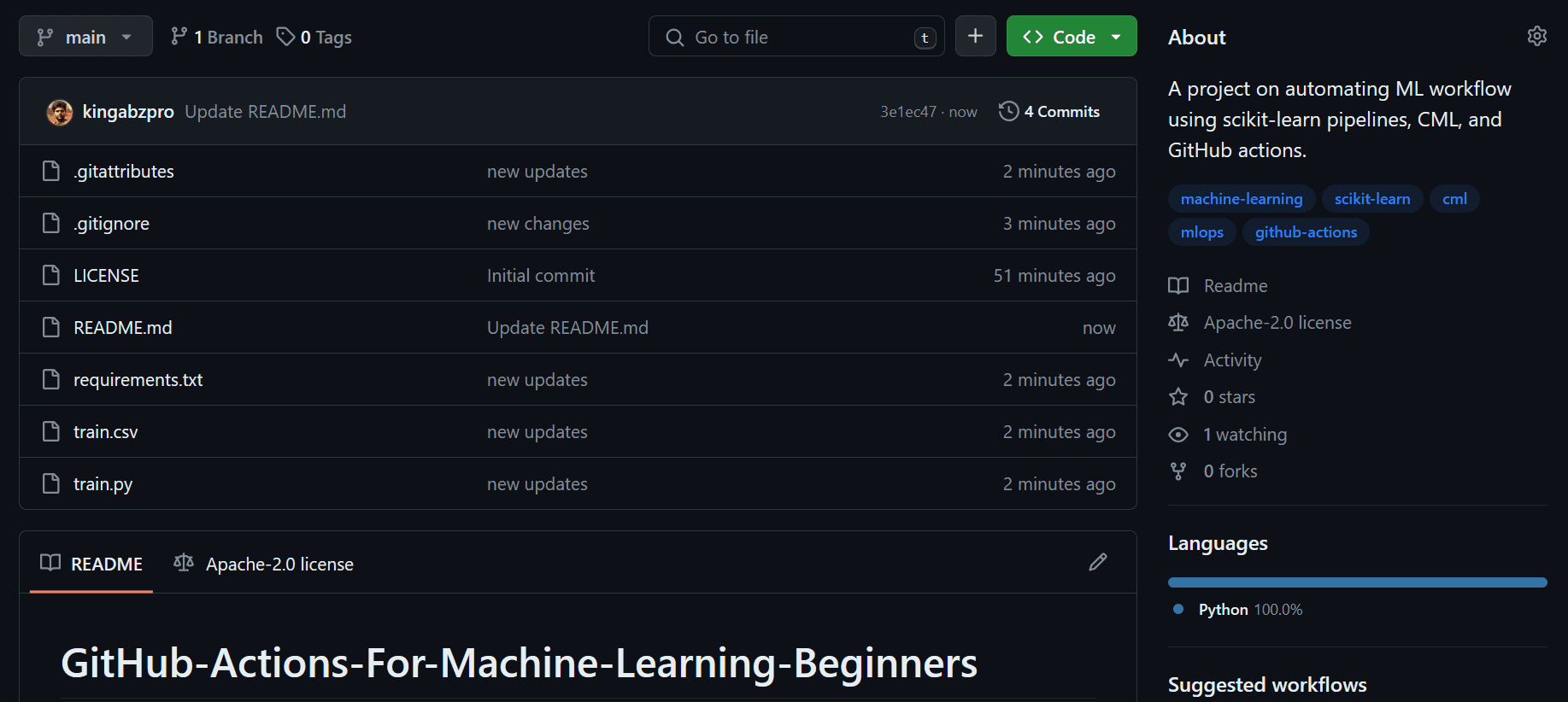
CML
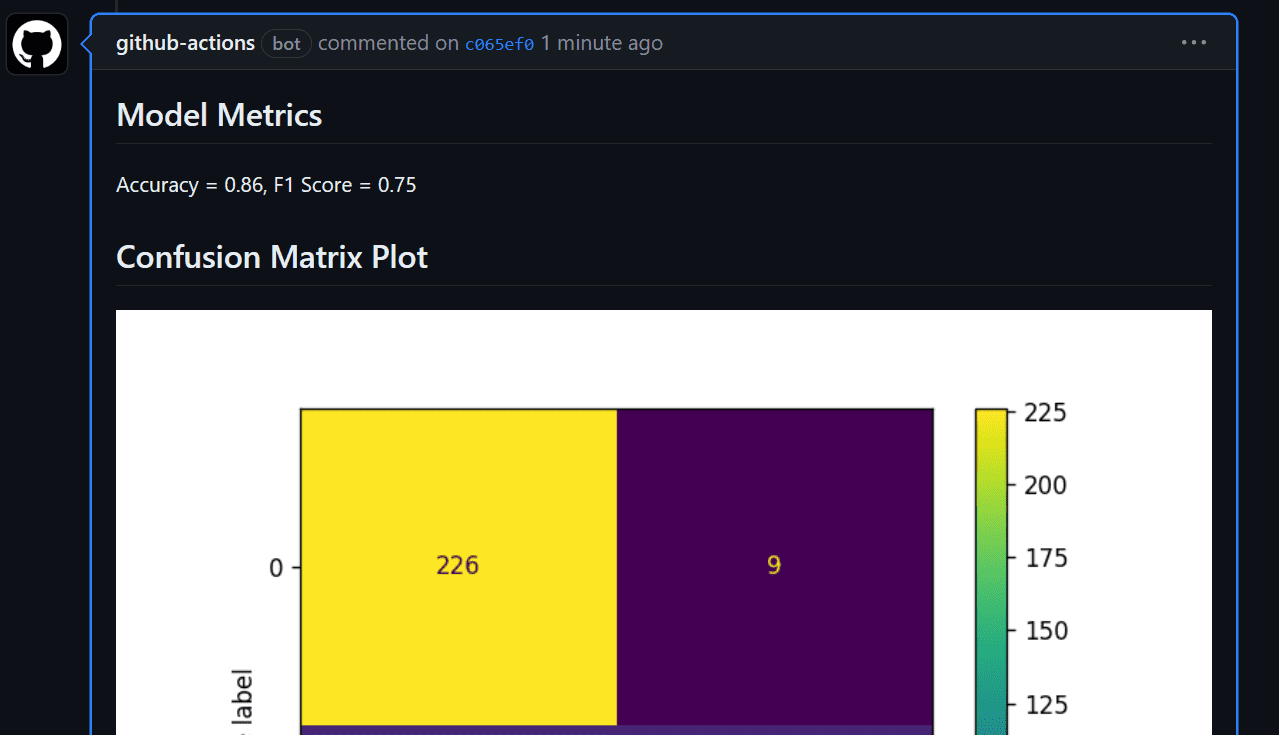
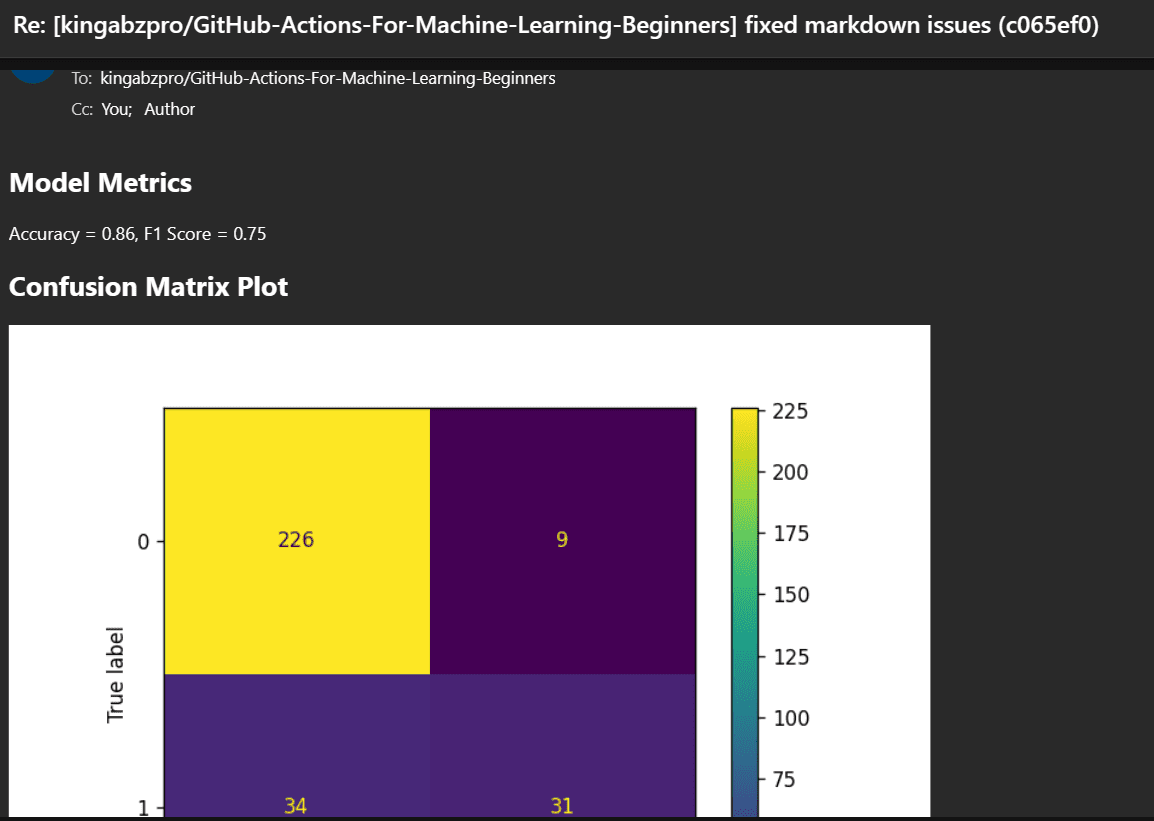
Før vi begynner å jobbe med arbeidsflyten, er det viktig å forstå formålet med Kontinuerlig maskinlæring (CML) handlinger. CML-funksjoner brukes i arbeidsflyten for å automatisere prosessen med å generere en modellevalueringsrapport. Hva betyr dette? Vel, når vi pusher endringer til GitHub, vil en rapport automatisk bli generert under commit. Denne rapporten vil inneholde resultatmålinger og en forvirringsmatrise, og vi vil også motta en e-post med all denne informasjonen.
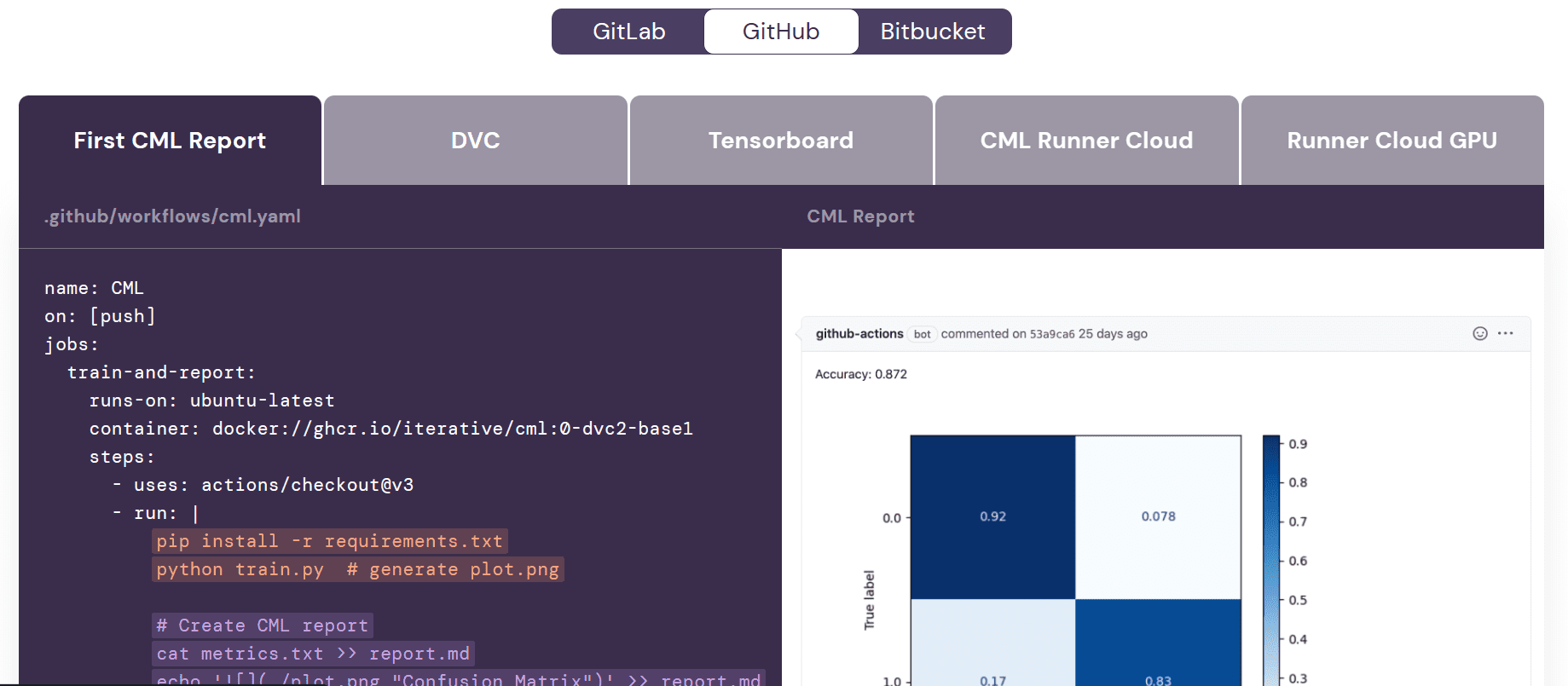
GitHub-handlinger
Det er tid for hoveddelen. Vi vil utvikle en arbeidsflyt for maskinlæring for opplæring og evaluering av modellen vår. Denne arbeidsflyten vil bli aktivert hver gang vi skyver koden vår til hovedgrenen eller når noen sender en pull-forespørsel til hovedgrenen.
For å lage vår første arbeidsflyt, naviger til "Handlinger"-fanen på Repository og klikk på den blå teksten "sett opp en arbeidsflyt selv." Den vil opprette en YML-fil i .github/workflows-katalogen og gi oss den interaktive kodeeditoren for å legge til koden.
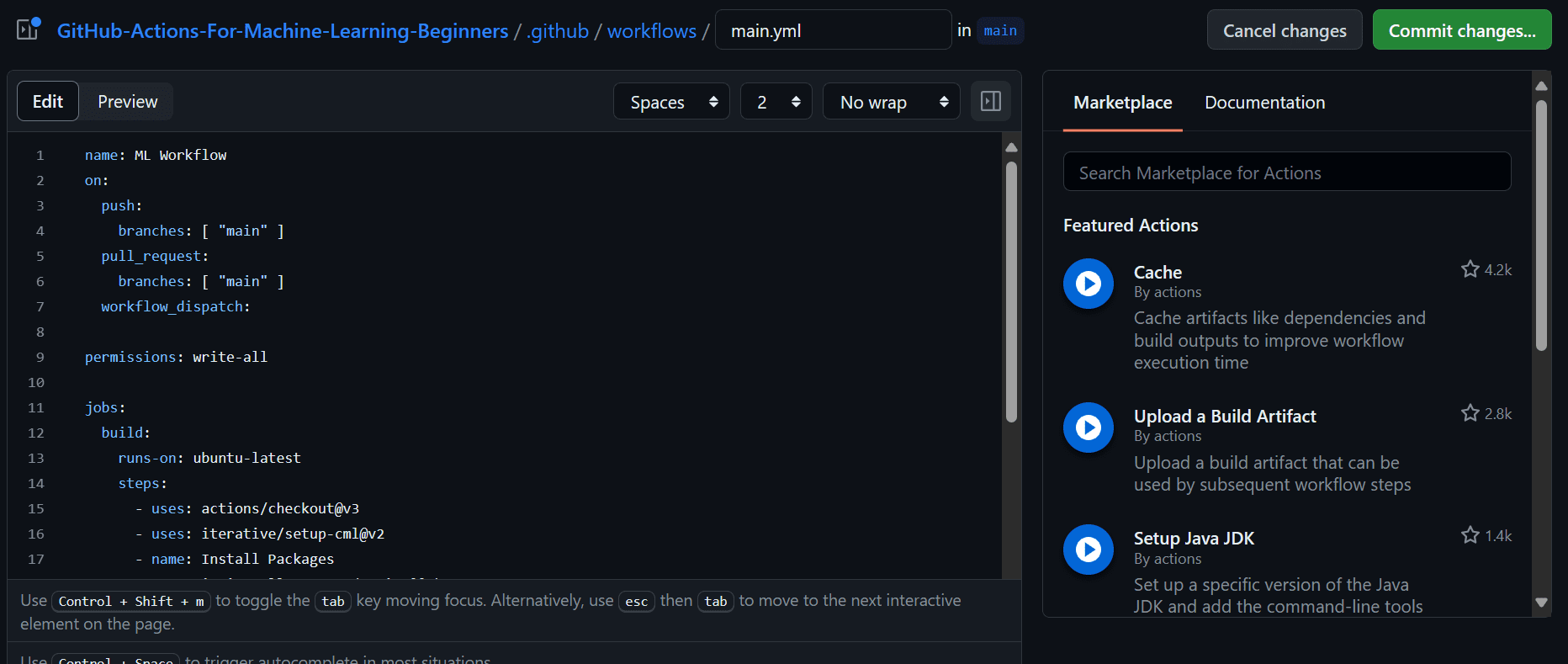
Legg til følgende kode i arbeidsflytfilen. I denne koden er vi:
- Navngi arbeidsflyten vår.
- Stille inn utløsere på push and pull-forespørsel ved å bruke "på"-tastene.
- Å gi handlingene skriftlig tillatelse slik at CML-handlingen kan lage meldingen under commit.
- Bruk Ubuntu Linux runner.
- Bruk handlingen `actions/checkout@v3` for å få tilgang til alle depotfilene, inkludert datasettet.
- Bruker `iterative/setup-cml@v2` handling for å installere CML-pakken.
- Opprett kjøringen for å installere alle Python-pakkene.
- Opprett kjøringen for formatering av Python-filene.
- Lag løpet for trening og evaluering av modellen.
- Opprett kjøringen med GITHUB_TOKEN for å flytte modellberegninger og forvirringsmatriseplott til report.md-filen. Deretter bruker du CML-kommandoen til å lage rapporten under commit-kommentaren.
name: ML Workflow
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
workflow_dispatch:
permissions: write-all
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
lfs: true
- uses: iterative/setup-cml@v2
- name: Install Packages
run: pip install --upgrade pip && pip install -r requirements.txt
- name: Format
run: black *.py
- name: Train
run: python train.py
- name: Evaluation
env:
REPO_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
echo "## Model Metrics" > report.md
cat metrics.txt >> report.md
echo '## Confusion Matrix Plot' >> report.md
echo '' >> report.md
cml comment create report.md
Slik skal det se ut på din GitHub-arbeidsflyt.
Etter å ha begått endringene. Arbeidsflyten vil begynne å utføre kommandoen sekvensielt.
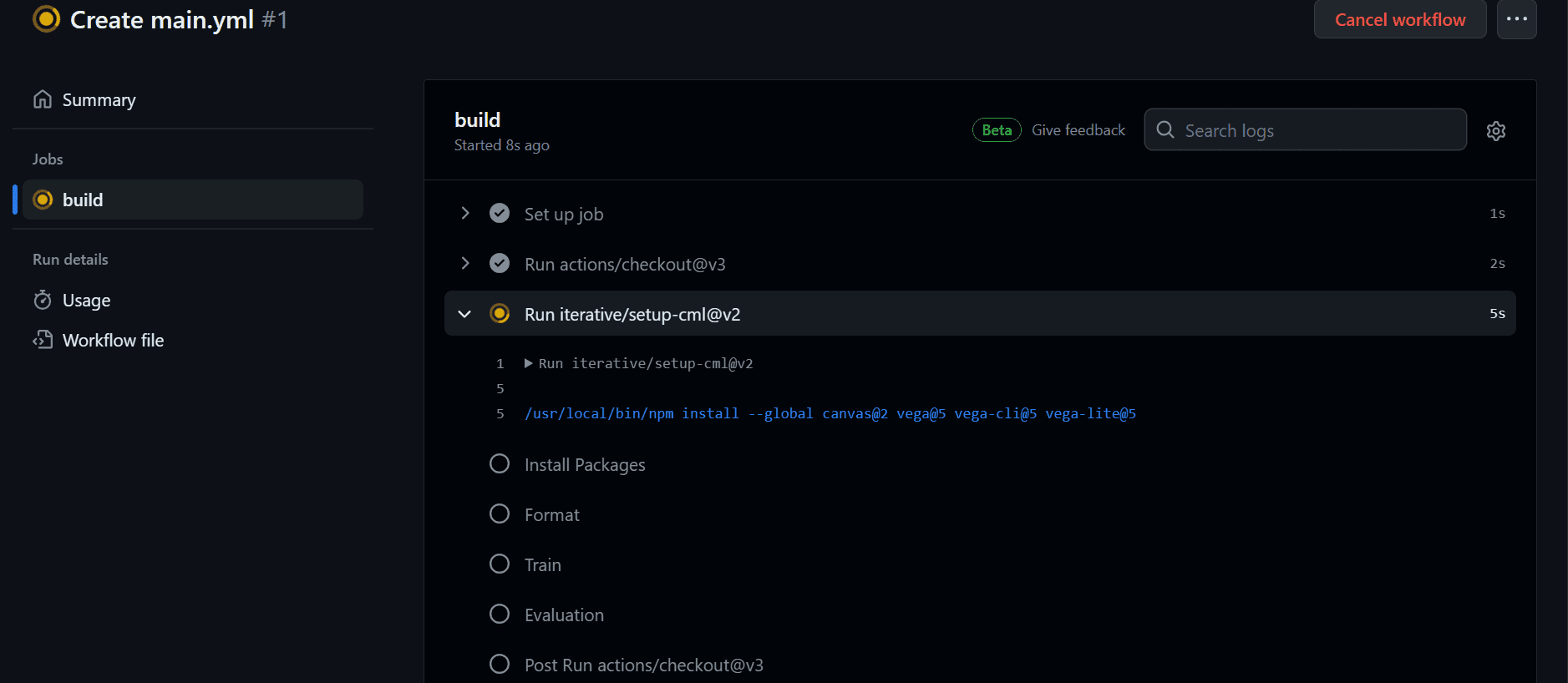
Etter å ha fullført arbeidsflyten, kan vi se loggene ved å klikke på den nylige arbeidsflyten i fanen "Handlinger", åpne bygget og gjennomgå loggene for hver oppgave.
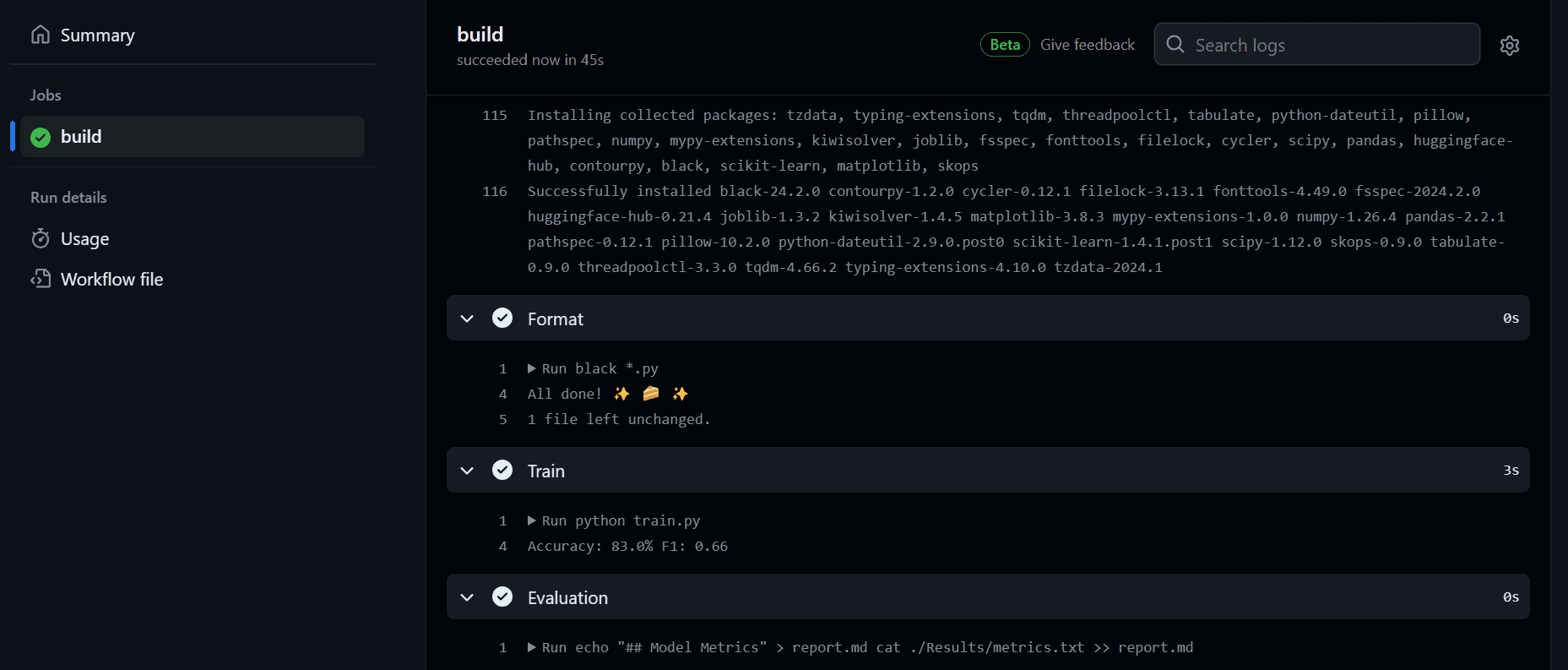
Vi kan nå se modellevalueringen under commit messages-delen. Vi kan få tilgang til den ved å klikke på commit-lenken: fast plassering i arbeidsflyten · kingabzpro/GitHub-Actions-For-Machine-Learning-Beginners@44c74fa
Du vil også motta en e-post fra GitHub
Kodekilden er tilgjengelig på GitHub-depotet mitt: kingabzpro/GitHub-Actions-For-Machine-Learning-Beginners. Du kan klone det og prøve det selv.
Maskinlæringsoperasjon (MLOps) er et stort felt som krever kunnskap om ulike verktøy og plattformer for å kunne bygge og distribuere modeller i produksjon. For å komme i gang med MLOps, anbefales det å følge en omfattende opplæring, "En nybegynnerveiledning til CI/CD for maskinlæring«. Det vil gi deg et solid grunnlag for å effektivt implementere MLOps-teknikker.
I denne opplæringen dekket vi hva GitHub-handlinger er og hvordan de kan brukes til å automatisere arbeidsflyten for maskinlæring. Vi lærte også om CML-handlinger og hvordan man skriver skript i YML-format for å kjøre jobber vellykket. Hvis du fortsatt er forvirret om hvor du skal begynne, foreslår jeg at du tar en titt på Det eneste gratis kurset du trenger for å bli MLOps-ingeniør.
Abid Ali Awan (@1abidaliawan) er en sertifisert dataforsker som elsker å bygge maskinlæringsmodeller. For tiden fokuserer han på innholdsskaping og skriver tekniske blogger om maskinlæring og datavitenskapsteknologier. Abid har en mastergrad i teknologiledelse og en bachelorgrad i telekommunikasjonsteknikk. Hans visjon er å bygge et AI-produkt ved å bruke et grafisk nevralt nettverk for studenter som sliter med psykiske lidelser.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/github-actions-for-machine-learning-beginners?utm_source=rss&utm_medium=rss&utm_campaign=github-actions-for-machine-learning-beginners
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 2%
- 4
- 5
- 6
- 7
- 8
- 9
- a
- Om oss
- ovenfor
- adgang
- nøyaktighet
- Handling
- handlinger
- aktivert
- legge til
- legge
- Etter
- AI
- Alle
- tillater
- også
- alltid
- an
- og
- ER
- AS
- At
- automatisere
- Automatisert
- automatiserer
- automatisk
- Automatisere
- tilgjengelig
- BE
- bli
- begynne
- Nybegynner
- nybegynnere
- BEST
- Stor
- Svart
- blogger
- Blå
- både
- Branch
- grener
- bygge
- Bygning
- men
- by
- CAN
- saken
- CAT
- CD
- Sertifisert
- endring
- Endringer
- kontroll
- klassifikator
- klikk
- klikke
- kode
- kolonner
- kombinere
- kombinere
- kommentere
- forplikte
- begå
- samfunnet
- fullføre
- fullført
- komponenter
- komponert
- omfattende
- forvirret
- forvirring
- innhold
- innholdsskaping
- kontinuerlig
- kontroll
- kopiere
- kurs
- dekke
- dekket
- skape
- Opprette
- skaperverket
- I dag
- dato
- datavitenskap
- dataforsker
- definere
- definert
- Grad
- levering
- utplassere
- utplasserings
- distribusjon
- beskrivelse
- utvikle
- utviklere
- Utvikling
- direkte
- Regissør
- katalog
- visning
- gjør
- Don
- nedlasting
- hver enkelt
- savner
- redaktør
- effektivt
- effektivitet
- effektiv
- emalje
- slutt
- Ingeniørarbeid
- Hele
- Miljø
- miljøer
- Eter (ETH)
- evaluere
- evaluere
- evaluering
- hendelser
- alt
- henrette
- henrettet
- utførende
- utforske
- trekke ut
- f1
- Trekk
- Egenskaper
- felt
- filet
- Filer
- slutt~~POS=TRUNC
- Først
- fokusering
- følge
- etter
- Til
- skog
- Forks
- format
- Fundament
- Gratis
- fra
- funksjoner
- generert
- genererer
- få
- gå
- GitHub
- Go
- god
- fikk
- graf
- Graf Neural Network
- veilede
- Ha
- he
- hjelpe
- hans
- holder
- vert
- vert
- Hvordan
- Hvordan
- HTTPS
- i
- ID
- identifisere
- if
- sykdom
- iverksette
- importere
- viktig
- forbedre
- in
- inkludere
- Inkludert
- informasjon
- indre
- installere
- installere
- integrering
- interaktiv
- inn
- utstedelse
- IT
- Jobb
- Jobb
- KDnuggets
- nøkkel
- Vet
- kunnskap
- seinere
- lansere
- LÆRE
- lært
- læring
- Tillatelse
- i likhet med
- LINK
- linux
- lasting
- plassering
- Se
- ser ut som
- elsker
- maskin
- maskinlæring
- MacOS
- Makro
- Hoved
- GJØR AT
- ledelse
- markedsplass
- Master
- matplotlib
- Matrix
- bety
- mental
- Mentalt syk
- nevnt
- melding
- meldinger
- Metrics
- ML
- MLOps
- modell
- modeller
- mer
- flytting
- my
- navn
- navn
- Naviger
- nødvendig
- Trenger
- nettverk
- neural
- nevrale nettverket
- Ny
- nå
- numerisk
- følelsesløs
- of
- on
- ONE
- bare
- åpning
- drift
- or
- Origin
- vår
- ut
- produksjon
- enn
- egen
- pakke
- pakker
- pandaer
- del
- komme igjennom
- utføre
- ytelse
- tillatelse
- tillatelser
- stykker
- rørledning
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- plott
- kraftig
- Spådommer
- forrige
- prosess
- Prosesser
- Produkt
- Produksjon
- produktivitet
- profesjonell
- prosjekt
- gi
- gir
- gi
- formål
- Skyv
- Python
- tilfeldig
- RE
- Lese
- Lesning
- motta
- nylig
- anbefales
- Utgivelser
- pålitelig
- rapporterer
- Repository
- anmode
- forespørsler
- påkrevd
- Krav
- Krever
- resultere
- gjenbruk
- gjennomgå
- ikke sant
- Kjør
- runner
- rennende
- s
- samme
- Spar
- lagret
- besparende
- planlegge
- Vitenskap
- Forsker
- scikit lære
- Resultat
- skript
- hemmeligheter
- Seksjon
- velge
- utvalg
- sett
- sett
- innstilling
- delt
- bør
- Enkelt
- So
- Software
- programvareutvikling
- solid
- Noen
- kilde
- spesifikk
- Scene
- Stjerner
- Begynn
- startet
- Trinn
- Steps
- Still
- rett fram
- effektivisere
- effektiviserer
- Sliter
- Studenter
- sender inn
- vellykket
- slik
- foreslår
- syntaks
- T
- ta
- Oppgave
- oppgaver
- Teknisk
- teknikker
- Technologies
- Teknologi
- telekommunikasjon
- terminal
- test
- Testing
- tekst
- Det
- De
- deres
- deretter
- Disse
- de
- denne
- tid
- ganger
- til
- verktøy
- verktøy
- spor
- Tog
- Kurs
- transformers
- utløst
- sant
- prøve
- tutorial
- to
- typen
- Ubuntu
- etter
- forstå
- lomper
- us
- bruke
- brukt
- bruker
- ved hjelp av
- ulike
- enorme
- Se
- virtuelle
- syn
- W
- ønsker
- we
- VI VIL
- Hva
- når
- når som helst
- hvilken
- HVEM
- vil
- vinduer
- med
- innenfor
- Arbeid
- arbeidsflyt
- arbeidsflyt
- arbeid
- hjemkomsten
- virker
- skrive
- skriving
- skrevet
- X
- du
- Din
- deg selv
- zephyrnet






