Dette innlegget er skrevet sammen av Jyoti Sharma og Sharmo Sarkar fra Vericast.
For ethvert maskinlæringsproblem (ML) begynner dataforskeren med å jobbe med data. Dette inkluderer å samle inn, utforske og forstå de forretningsmessige og tekniske aspektene ved dataene, sammen med evaluering av eventuelle manipulasjoner som kan være nødvendig for modellbyggingsprosessen. Et aspekt ved denne dataforberedelsen er funksjonsteknikk.
Funksjonsteknikk refererer til prosessen der relevante variabler identifiseres, velges og manipuleres for å transformere rådataene til mer nyttige og brukbare former for bruk med ML-algoritmen som brukes til å trene en modell og utføre slutninger mot den. Målet med denne prosessen er å øke ytelsen til algoritmen og den resulterende prediktive modellen. Funksjonsutviklingsprosessen omfatter flere stadier, inkludert funksjonsoppretting, datatransformasjon, funksjonsutvinning og funksjonsvalg.
Å bygge en plattform for generalisert funksjonsteknikk er en vanlig oppgave for kunder som trenger å produsere mange ML-modeller med forskjellige datasett. Denne typen plattform inkluderer opprettelsen av en programmatisk drevet prosess for å produsere ferdige, funksjonskonstruerte data klare for modelltrening med lite menneskelig innblanding. Imidlertid er det utfordrende å generalisere funksjonsteknikk. Hvert forretningsproblem er forskjellig, hvert datasett er forskjellig, datavolumer varierer voldsomt fra klient til klient, og datakvaliteten og ofte kardinaliteten til en bestemt kolonne (i tilfelle av strukturerte data) kan spille en betydelig rolle i kompleksiteten til funksjonsteknikken prosess. Videre kan den dynamiske naturen til en kundes data også resultere i en stor variasjon av behandlingstiden og ressursene som kreves for å fullføre funksjonsutviklingen optimalt.
AWS-kunde Vericast er et selskap for markedsføringsløsninger som tar datadrevne beslutninger for å øke markedsavkastningen for sine kunder. Vericasts interne skybaserte maskinlæringsplattform, bygget rundt CRISP-ML(Q)-prosessen, bruker ulike AWS-tjenester, bl.a. Amazon SageMaker, Amazon SageMaker-prosessering, AWS Lambdaog AWS trinnfunksjoner, for å produsere best mulig modeller som er skreddersydd til den spesifikke kundens data. Denne plattformen tar sikte på å fange opp repeterbarheten til trinnene som går til å bygge ulike ML-arbeidsflyter og samle dem inn i standard generaliserbare arbeidsflytmoduler i plattformen.
I dette innlegget deler vi hvordan Vericast optimaliserte funksjonsteknikk ved hjelp av SageMaker Processing.
Løsningsoversikt
Vericasts maskinlæringsplattform hjelper til med raskere distribusjon av nye forretningsmodeller basert på eksisterende arbeidsflyter eller raskere aktivering av eksisterende modeller for nye kunder. For eksempel er en modell som forutsier direktereklametilbøyelighet ganske forskjellig fra en modell som forutsier rabattkupongfølsomhet for kundene til en Vericast-klient. De løser ulike forretningsproblemer og har derfor ulike bruksscenarier i en markedsføringskampanjedesign. Men fra et ML-standpunkt kan begge tolkes som binære klassifiseringsmodeller, og kan derfor dele mange vanlige trinn fra et ML-arbeidsflytperspektiv, inkludert modelljustering og opplæring, evaluering, tolkning, distribusjon og slutning.
Fordi disse modellene er binære klassifiseringsproblemer (i ML-termer), deler vi kundene til et selskap i to klasser (binære): de som ville reagere positivt på kampanjen og de som ikke ville. Videre betraktes disse eksemplene som en ubalansert klassifisering fordi dataene som ble brukt til å trene modellen ikke ville inneholde like mange kunder som ville og ikke ville svare positivt.
Selve opprettelsen av en modell som denne følger det generaliserte mønsteret vist i følgende diagram.
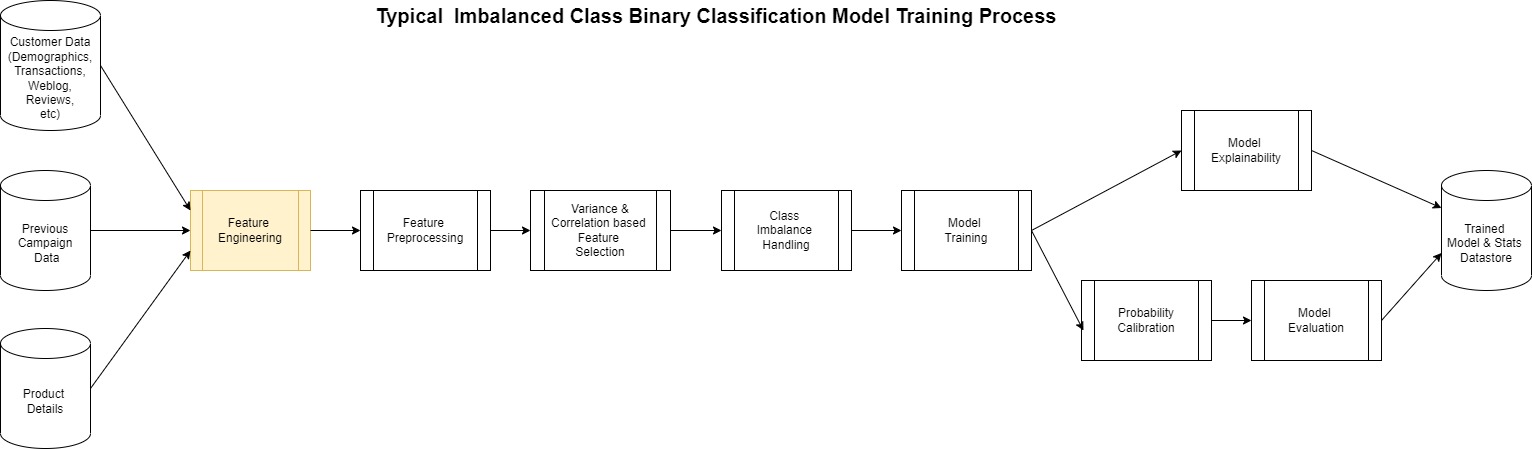
Det meste av denne prosessen er den samme for alle binære klassifiseringer bortsett fra funksjonsteknikktrinnet. Dette er kanskje det mest kompliserte, men til tider oversett trinnet i prosessen. ML-modeller er i stor grad avhengig av funksjonene som brukes til å lage den.
Vericasts skybaserte maskinlæringsplattform tar sikte på å generalisere og automatisere funksjonstrinnene for ulike ML-arbeidsflyter og optimalisere ytelsen deres på en kostnad vs. tid-beregning ved å bruke følgende funksjoner:
- Plattformens funksjonsingeniørbibliotek – Dette består av et stadig utviklende sett med transformasjoner som har blitt testet for å gi høykvalitets generaliserbare funksjoner basert på spesifikke klientkonsepter (for eksempel kundedemografi, produktdetaljer, transaksjonsdetaljer og så videre).
- Intelligente ressursoptimaliserere – Plattformen bruker AWSs on-demand-infrastrukturkapasitet til å spinne opp den mest optimale typen prosesseringsressurser for den spesielle funksjonsingeniørjobben basert på den forventede kompleksiteten til trinnet og mengden data den trenger for å churne gjennom.
- Dynamisk skalering av funksjonsingeniørjobber – En kombinasjon av ulike AWS-tjenester brukes til dette, men spesielt SageMaker Processing. Dette sikrer at plattformen produserer funksjoner av høy kvalitet på en kostnadseffektiv og tidsriktig måte.
Dette innlegget er fokusert rundt det tredje punktet i denne listen og viser hvordan man oppnår dynamisk skalering av SageMaker Processing-jobber for å oppnå et mer administrert, ytelsesrikt og kostnadseffektivt databehandlingsrammeverk for store datavolumer.
SageMaker Processing muliggjør arbeidsbelastninger som kjører trinn for dataforbehandling eller etterbehandling, funksjonsutvikling, datavalidering og modellevaluering på SageMaker. Det gir også et administrert miljø og fjerner kompleksiteten til udifferensierte tunge løft som kreves for å sette opp og vedlikeholde infrastrukturen som trengs for å kjøre arbeidsbelastningen. Videre gir SageMaker Processing et API-grensesnitt for kjøring, overvåking og evaluering av arbeidsmengden.
Kjøre SageMaker Behandlingsjobber foregår fullt ut i en administrert SageMaker-klynge, med individuelle jobber plassert i forekomstbeholdere under kjøring. Den administrerte klyngen, forekomstene og beholderne rapporterer beregninger til Amazon CloudWatch, inkludert bruk av GPU, CPU, minne, GPU-minne, diskberegninger og hendelseslogging.
Disse funksjonene gir fordeler til Vericast-dataingeniører og -forskere ved å hjelpe til med utviklingen av generaliserte forbehandlingsarbeidsflyter og abstrahere vanskelighetene med å opprettholde genererte miljøer for å kjøre dem. Tekniske problemer kan imidlertid oppstå, gitt den dynamiske karakteren til dataene og dens varierte funksjoner som kan mates inn i en slik generell løsning. Systemet må gjøre en utdannet innledende gjetning om størrelsen på klyngen og forekomster som utgjør den. Denne gjetningen må evaluere kriteriene for dataene og utlede CPU-, minne- og diskkravene. Denne gjetningen kan være helt passende og fungere tilstrekkelig for jobben, men i andre tilfeller er det kanskje ikke. For et gitt datasett og forbehandlingsjobb kan CPU-en være underdimensjonert, noe som resulterer i maksimal prosessytelse og lang tid å fullføre. Enda verre, minne kan bli et problem, noe som resulterer i enten dårlig ytelse eller mangel på minne som får hele jobben til å mislykkes.
Med disse tekniske hindringene i tankene, satte Vericast seg for å lage en løsning. De måtte forbli generelle og passe inn i det større bildet av forbehandlingsarbeidsflyten som var fleksibel i de involverte trinnene. Det var også viktig å løse både det potensielle behovet for å skalere opp miljøet i tilfeller der ytelsen ble kompromittert og å komme seg elegant etter en slik hendelse eller når en jobb ble avsluttet for tidlig av en eller annen grunn.
Løsningen bygget av Vericast for å løse dette problemet bruker flere AWS-tjenester som jobber sammen for å nå sine forretningsmål. Den ble designet for å starte på nytt og skalere opp SageMaker Processing-klyngen basert på ytelsesmålinger observert ved bruk av Lambda-funksjoner som overvåker jobbene. For ikke å miste arbeidet når en skaleringshendelse finner sted eller for å komme seg etter en jobb som uventet stopper, ble det satt på plass en sjekkpunktbasert tjeneste som bruker Amazon DynamoDB og lagrer de delvis behandlede dataene i Amazon enkel lagringstjeneste (Amazon S3) bøtter som trinn fullført. Det endelige resultatet er en automatisk skalering, robust og dynamisk overvåket løsning.
Følgende diagram viser en overordnet oversikt over hvordan systemet fungerer.
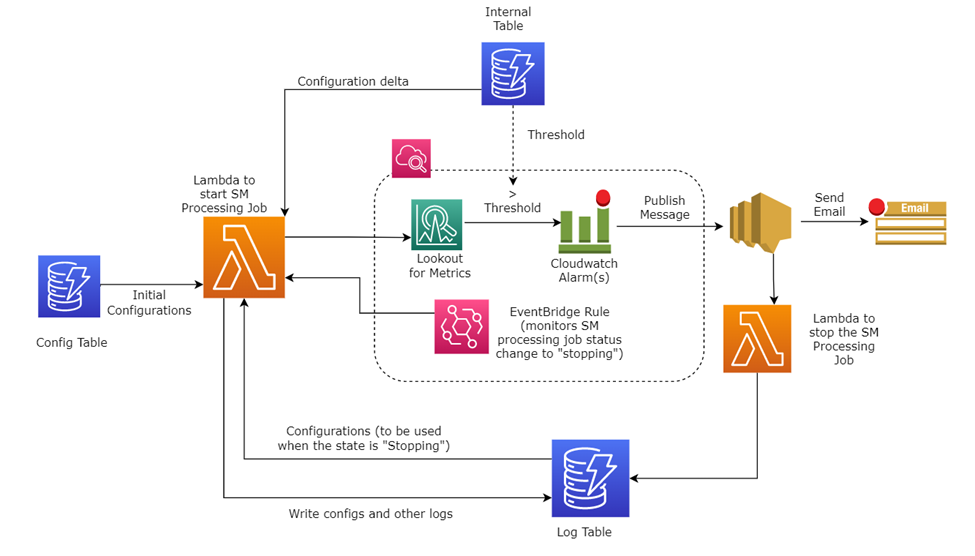
I de følgende avsnittene diskuterer vi løsningskomponentene mer detaljert.
Initialiserer løsningen
Systemet forutsetter at en egen prosess setter i gang løsningen. Motsatt er ikke dette designet designet for å fungere alene fordi det ikke vil gi noen artefakter eller utdata, men fungerer snarere som en sidevognimplementering til et av systemene som bruker SageMaker Processing-jobber. I Vericasts tilfelle initieres løsningen ved et anrop fra et Step Functions-trinn startet i en annen modul i det større systemet.
Når løsningen er startet og en første kjøring er utløst, leses en standard standardkonfigurasjon fra en DynamoDB-tabell. Denne konfigurasjonen brukes til å angi parametere for SageMaker Processing-jobben og har de første antakelsene om infrastrukturbehov. SageMaker Processing-jobben er nå startet.
Overvåking av metadata og output
Når jobben starter, skriver en Lambda-funksjon jobbbehandlingsmetadataene (gjeldende jobbkonfigurasjon og annen logginformasjon) inn i DynamoDB-loggtabellen. Disse metadataene og logginformasjonen opprettholder en historikk for jobben, dens innledende og pågående konfigurasjon og andre viktige data.
På visse punkter, etter hvert som trinnene er fullført i jobben, legges sjekkpunktdata til DynamoDB-loggtabellen. Behandlede utdata blir flyttet til Amazon S3 for rask gjenoppretting om nødvendig.
Denne Lambda-funksjonen setter også opp en Amazon EventBridge regel som overvåker den løpende jobben for sin tilstand. Nærmere bestemt ser denne regelen på jobben for å observere om jobbstatusen endres til stopping eller er i en stopped stat. Denne EventBridge-regelen spiller en viktig rolle i å starte en jobb på nytt hvis det er en feil eller en planlagt automatisk skaleringshendelse oppstår.
Overvåking av CloudWatch-beregninger
Lambda-funksjonen setter også en CloudWatch-alarm basert på et metrisk matematisk uttrykk på behandlingsjobben, som overvåker beregningene for alle forekomstene for CPU-utnyttelse, minneutnyttelse og diskutnyttelse. Denne typen alarm (beregning) bruker CloudWatch-alarmterskler. Alarmen genererer hendelser basert på verdien av metrikken eller uttrykket i forhold til tersklene over en rekke tidsperioder.
I Vericasts brukstilfelle er terskeluttrykket designet for å betrakte driver- og eksekveringsinstansene som separate, med beregninger overvåket individuelt for hver. Ved å ha dem adskilt, vet Vericast hva som forårsaker alarmen. Dette er viktig for å bestemme hvordan du skal skalere tilsvarende:
- Hvis eksekveringsberegningene passerer terskelen, er det greit å skalere horisontalt
- Hvis sjåførberegningene krysser terskelen, vil det sannsynligvis ikke hjelpe å skalere horisontalt, så vi må skalere vertikalt
Uttrykk for alarmberegninger
Vericast kan få tilgang til følgende beregninger i sin evaluering for skalering og feil:
- CPUUtilization – Summen av hver enkelt CPU-kjernes utnyttelse
- Minneutnyttelse – Prosentandelen av minne som brukes av beholderne på en forekomst
- DiskUtilization – Prosentandelen av diskplass som brukes av beholderne på en forekomst
- GPUUtilization – Prosentandelen av GPU-enheter som brukes av beholderne på en forekomst
- GPUMemoryUtilization – Prosentandelen av GPU-minne som brukes av beholderne på en forekomst
Når dette skrives, vurderer Vericast bare CPUUtilization, MemoryUtilizationog DiskUtilization. I fremtiden har de tenkt å vurdere GPUUtilization og GPUMemoryUtilization også.
Følgende kode er et eksempel på en CloudWatch-alarm basert på et metrisk matematisk uttrykk for Vericast automatisk skalering:
Dette uttrykket illustrerer at CloudWatch-alarmen vurderer DriverMemoryUtilization (memoryDriver), CPUUtilization (cpuDriver), DiskUtilization (diskDriver), ExecutorMemoryUtilization (memoryExec), CPUUtilization (cpuExec)og DiskUtilization (diskExec) som overvåkingsmål. Tallet 80 i det foregående uttrykket står for terskelverdien.
Her IF((cpuDriver) > 80, 1, 0 innebærer at hvis driverens CPU-utnyttelse går utover 80 %, blir 1 tildelt som terskelen ellers 0. IF(AVG(METRICS("memoryExec")) > 80, 1, 0 innebærer at alle beregningene med streng memoryExec i den vurderes og det beregnes et gjennomsnitt på det. Hvis den gjennomsnittlige minneutnyttelsesprosenten går utover 80, blir 1 tildelt som terskelen ellers 0.
Den logiske operatoren OR brukes i uttrykket for å forene alle brukene i uttrykket – hvis noen av bruken når terskelen, utløs alarmen.
For mer informasjon om bruk av CloudWatch metriske alarmer basert på metriske matematiske uttrykk, se Opprette en CloudWatch-alarm basert på et metrisk matematisk uttrykk.
CloudWatch alarmbegrensninger
CloudWatch begrenser antall beregninger per alarm til 10. Dette kan forårsake begrensninger hvis du må vurdere flere beregninger enn dette.
For å overvinne denne begrensningen har Vericast satt alarmer basert på den totale klyngestørrelsen. Én alarm opprettes per tre forekomster (for tre forekomster vil det være én alarm fordi det vil utgjøre ni beregninger). Forutsatt at sjåførforekomsten skal vurderes separat, opprettes en annen separat alarm for sjåførforekomsten. Derfor tilsvarer det totale antallet alarmer som opprettes omtrent en tredjedel av antall eksekutørnoder og en ekstra for driverforekomsten. I hvert tilfelle er antall beregninger per alarm under grensen på 10 metriske.
Hva skjer når du er i alarmtilstand
Hvis en forhåndsbestemt terskel er nådd, går alarmen til en alarm stat, som bruker Amazon enkel varslingstjeneste (Amazon SNS) for å sende ut varsler. I dette tilfellet sender den ut et e-postvarsel til alle abonnenter med detaljene om alarmen i meldingen.
Amazon SNS brukes også som en trigger til en Lambda-funksjon som stopper den for tiden kjørende SageMaker Processing-jobben fordi vi vet at jobben sannsynligvis vil mislykkes. Denne funksjonen registrerer også logger til loggtabellen relatert til hendelsen.
EventBridge-regelen satt opp ved jobbstart vil merke at jobben har gått inn i en stopping oppgi noen sekunder senere. Denne regelen kjører deretter den første Lambda-funksjonen på nytt for å starte jobben på nytt.
Den dynamiske skaleringsprosessen
Den første Lambda-funksjonen etter å ha kjørt to eller flere ganger vil vite at en tidligere jobb allerede hadde startet og nå har stoppet. Funksjonen vil gå gjennom en lignende prosess for å hente basiskonfigurasjonen fra den opprinnelige jobben i loggen DynamoDB-tabellen og vil også hente oppdatert konfigurasjon fra den interne tabellen. Denne oppdaterte konfigurasjonen er en ressursdelta-konfigurasjon som er satt basert på skaleringstypen. Skaleringstypen bestemmes fra alarmmetadataene som beskrevet tidligere.
Den opprinnelige konfigurasjonen pluss ressursdelta brukes fordi en ny konfigurasjon og en ny SageMaker Processing-jobb startes med de økte ressursene.
Denne prosessen fortsetter til jobben er fullført og kan resultere i flere omstarter etter behov, og legge til flere ressurser hver gang.
Vericasts utfall
Denne tilpassede automatiske skaleringsløsningen har vært med på å gjøre Vericasts maskinlæringsplattform mer robust og feiltolerant. Plattformen kan nå grasiøst håndtere arbeidsmengder av forskjellige datavolumer med minimal menneskelig innblanding.
Før du implementerte denne løsningen, var estimering av ressurskravene for alle de Spark-baserte modulene i pipelinen en av de største flaskehalsene i den nye klienten onboarding-prosessen. Arbeidsflyter ville mislykkes hvis klientdatavolumet økte, eller kostnaden ville være uforsvarlig hvis datavolumet gikk ned i produksjonen.
Med denne nye modulen på plass, har arbeidsflytfeil på grunn av ressursbegrensninger blitt redusert med nesten 80 %. De få gjenværende feilene skyldes for det meste AWS-kontobegrensninger og utover den automatiske skaleringsprosessen. Vericasts største gevinst med denne løsningen er den enkle de kan ta med seg nye klienter og arbeidsflyter. Vericast forventer å fremskynde prosessen med minst 60–70 %, med data som fortsatt skal samles inn for et endelig antall.
Selv om dette blir sett på som en suksess av Vericast, er det en kostnad som følger med det. Basert på naturen til denne modulen og konseptet med dynamisk skalering som helhet, har arbeidsflytene en tendens til å ta rundt 30 % lengre tid (gjennomsnittlig tilfelle) enn en arbeidsflyt med en tilpasset klynge for hver modul i arbeidsflyten. Vericast fortsetter å optimalisere på dette området, og ser etter å forbedre løsningen ved å inkludere heuristikk-basert ressursinitialisering for hver klientmodul.
Sharmo Sarkar, Senior Manager, Machine Learning Platform hos Vericast, sier: "Når vi fortsetter å utvide bruken av AWS og SageMaker, ønsket jeg å bruke et øyeblikk på å fremheve det utrolige arbeidet til vårt AWS Client Services Team, dedikerte AWS Solutions Architects, og AWS Professional Services som vi jobber med. Deres dype forståelse av AWS og SageMaker tillot oss å designe en løsning som dekket alle våre behov og ga oss fleksibiliteten og skalerbarheten vi trengte. Vi er så takknemlige for å ha et så dyktig og kunnskapsrikt støtteteam på vår side.»
konklusjonen
I dette innlegget delte vi hvordan SageMaker og SageMaker Processing har gjort det mulig for Vericast å bygge et administrert, effektivt og kostnadseffektivt databehandlingsrammeverk for store datavolumer. Ved å kombinere kraften og fleksibiliteten til SageMaker Processing med andre AWS-tjenester, kan de enkelt overvåke den generaliserte funksjonsutviklingsprosessen. De kan automatisk oppdage potensielle problemer generert fra mangel på databehandling, minne og andre faktorer, og automatisk implementere vertikal og horisontal skalering etter behov.
SageMaker og dets verktøy kan hjelpe teamet ditt med å nå sine ML-mål også. For å lære mer om SageMaker Processing og hvordan det kan hjelpe deg med databehandlingsarbeidsmengdene dine, se Behandle data. Hvis du akkurat har begynt med ML og ser etter eksempler og veiledning, Amazon SageMaker JumpStart kan komme i gang. JumpStart er en ML-hub hvorfra du kan få tilgang til innebygde algoritmer med forhåndstrente grunnmodeller for å hjelpe deg med å utføre oppgaver som artikkeloppsummering og bildegenerering og forhåndsbygde løsninger for å løse vanlige brukstilfeller.
Til slutt, hvis dette innlegget hjelper deg eller inspirerer deg til å løse et problem, vil vi gjerne høre om det! Del gjerne dine kommentarer og tilbakemeldinger.
Om forfatterne
 Anthony McClure er Senior Partner Solutions Architect med AWS SaaS Factory-teamet. Anthony har også en sterk interesse for maskinlæring og kunstig intelligens i samarbeid med AWS ML/AI Technical Field Community for å hjelpe kunder med å bringe maskinlæringsløsningene deres til virkelighet.
Anthony McClure er Senior Partner Solutions Architect med AWS SaaS Factory-teamet. Anthony har også en sterk interesse for maskinlæring og kunstig intelligens i samarbeid med AWS ML/AI Technical Field Community for å hjelpe kunder med å bringe maskinlæringsløsningene deres til virkelighet.
 Jyoti Sharma er en datavitenskapsingeniør med maskinlæringsplattformteamet hos Vericast. Hun er lidenskapelig opptatt av alle aspekter av datavitenskap og fokusert på å designe og implementere en svært skalerbar og distribuert maskinlæringsplattform.
Jyoti Sharma er en datavitenskapsingeniør med maskinlæringsplattformteamet hos Vericast. Hun er lidenskapelig opptatt av alle aspekter av datavitenskap og fokusert på å designe og implementere en svært skalerbar og distribuert maskinlæringsplattform.
 Sharmo Sarkar er Senior Manager hos Vericast. Han leder Cloud Machine Learning Platform og Marketing Platform ML R&D-teamene hos Vericast. Han har lang erfaring innen Big Data Analytics, Distributed Computing og Natural Language Processing. Utenfor jobben liker han motorsykkel, fotturer og sykling på fjellstier.
Sharmo Sarkar er Senior Manager hos Vericast. Han leder Cloud Machine Learning Platform og Marketing Platform ML R&D-teamene hos Vericast. Han har lang erfaring innen Big Data Analytics, Distributed Computing og Natural Language Processing. Utenfor jobben liker han motorsykkel, fotturer og sykling på fjellstier.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/how-vericast-optimized-feature-engineering-using-amazon-sagemaker-processing/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 15%
- a
- Om oss
- adgang
- tilsvar
- Logg inn
- Oppnå
- Aktivering
- handlinger
- legge til
- la til
- legge
- Ytterligere
- tilstrekkelig
- Etter
- mot
- hjelpemidler
- mål
- alarm
- algoritme
- algoritmer
- Alle
- alene
- langs
- allerede
- også
- Amazon
- Amazon SageMaker
- beløp
- an
- analytics
- og
- En annen
- Anthony
- noen
- api
- hensiktsmessig
- arkitektur
- ER
- AREA
- rundt
- Artikkel
- kunstig
- kunstig intelligens
- AS
- aspektet
- aspekter
- tildelt
- bistå
- At
- auto
- automatisere
- automatisk
- gjennomsnittlig
- AWS
- AWS profesjonelle tjenester
- basen
- basert
- BE
- fordi
- bli
- vært
- være
- Fordeler
- BEST
- Beyond
- Stor
- Store data
- Biggest
- øke
- både
- flaskehalser
- Bringe
- bygge
- Bygning
- bygget
- innebygd
- virksomhet
- men
- by
- beregnet
- ring
- Kampanje
- CAN
- Kan få
- fange
- saken
- saker
- Årsak
- forårsaker
- viss
- utfordrende
- Endringer
- klasse
- klasser
- klassifisering
- kunde
- klient onboarding
- klienter
- Cloud
- Cluster
- kode
- Kolonne
- kombinasjon
- kombinere
- kommer
- kommentarer
- Felles
- samfunnet
- Selskapet
- fullføre
- Fullfører
- kompleksitet
- komplisert
- komponenter
- kompromittert
- Beregn
- databehandling
- konsept
- konsepter
- Konfigurasjon
- Vurder
- ansett
- vurderer
- anser
- begrensninger
- Containere
- fortsette
- fortsetter
- Kostnad
- kostnadseffektiv
- kunne
- kupong
- prosessor
- skape
- opprettet
- skaperverket
- kriterier
- Kryss
- Gjeldende
- I dag
- skikk
- kunde
- Kunder
- dato
- Data Analytics
- Dataklargjøring
- databehandling
- datakvalitet
- datavitenskap
- dataforsker
- data-drevet
- datasett
- bestemme
- avgjørelser
- dedikert
- dyp
- Delta
- Demografi
- avhengig
- distribusjon
- beskrevet
- utforming
- designet
- utforme
- detalj
- detaljer
- bestemmes
- Utvikling
- forskjellig
- ulik
- Vanskelighetsgrad
- direkte
- Rabatt
- diskutere
- distribueres
- distribuert databehandling
- drevet
- sjåfør
- to
- dynamisk
- dynamisk
- hver enkelt
- Tidligere
- lette
- lett
- enten
- emalje
- aktivert
- muliggjør
- ingeniør
- Ingeniørarbeid
- Ingeniører
- sikrer
- Hele
- Miljø
- miljøer
- lik
- Tilsvarende
- Eter (ETH)
- evaluere
- evaluere
- evaluering
- Event
- hendelser
- eksempel
- eksempler
- Unntatt
- eksisterende
- Expand
- forventet
- forventer
- erfaring
- Utforske
- uttrykkene
- omfattende
- Omfattende erfaring
- utdrag
- faktorer
- fabrikk
- FAIL
- Failure
- Trekk
- Egenskaper
- Fed
- tilbakemelding
- Noen få
- felt
- slutt~~POS=TRUNC
- avsluttet
- Først
- passer
- fleksibilitet
- fleksibel
- fokuserte
- etter
- følger
- Til
- skjemaer
- Fundament
- Rammeverk
- fra
- fullt
- funksjon
- funksjoner
- Dess
- framtid
- samle
- general
- generert
- genererer
- generasjonen
- få
- få
- gitt
- Go
- mål
- Mål
- Går
- god
- GPU
- takknemlig
- veiledning
- HAD
- håndtere
- skjer
- Ha
- å ha
- he
- høre
- tung
- tung løfting
- hjelpe
- hjelper
- høyt nivå
- høykvalitets
- Uthev
- svært
- vandreturer
- historie
- Horisontal
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- Hub
- menneskelig
- hekk
- i
- identifisert
- if
- illustrerer
- bilde
- bildegenerering
- iverksette
- gjennomføring
- implementere
- viktig
- forbedre
- in
- I andre
- inkluderer
- Inkludert
- innlemme
- Øke
- økt
- utrolig
- individuelt
- individuelt
- informasjon
- Infrastruktur
- innledende
- Starter
- f.eks
- instrumental
- Intelligens
- hensikt
- interesse
- Interface
- intern
- intervensjon
- inn
- involvert
- utstedelse
- saker
- IT
- DET ER
- Jobb
- Jobb
- jpg
- bare
- Type
- Vet
- maling
- Språk
- stor
- i stor grad
- større
- seinere
- Fører
- LÆRE
- læring
- minst
- Bibliotek
- løfte
- begrensning
- begrensninger
- grenser
- Liste
- lite
- logg
- logging
- logisk
- lenger
- ser
- taper
- elsker
- maskin
- maskinlæring
- vedlikeholde
- opprettholder
- gjøre
- GJØR AT
- Making
- fikk til
- leder
- manipulert
- måte
- mange
- Marketing
- math
- Kan..
- Møt
- Minne
- melding
- metadata
- metrisk
- Metrics
- kunne
- tankene
- minimal
- ML
- modell
- modeller
- moduler
- Moduler
- øyeblikk
- Overvåke
- overvåket
- overvåking
- skjermer
- mer
- mest
- for det meste
- fjell
- flere
- må
- Naturlig
- Naturlig språk
- Natural Language Processing
- Natur
- Trenger
- nødvendig
- trenger
- behov
- Ny
- noder
- spesielt
- Legge merke til..
- varsling
- varslinger
- nå
- Antall
- mål
- observere
- of
- ofte
- on
- På etterspørsel
- Ombord
- onboarding
- ONE
- pågående
- bare
- operatør
- optimal
- Optimalisere
- optimalisert
- or
- original
- Annen
- vår
- ut
- Utfallet
- produksjon
- utenfor
- enn
- samlet
- Overcome
- oversikt
- parametere
- del
- Spesielt
- partner
- Passerer
- lidenskapelig
- Mønster
- prosent
- utføre
- ytelse
- kanskje
- perioder
- perspektiv
- bilde
- rørledning
- Sted
- planlagt
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- Spille
- spiller
- vær så snill
- i tillegg til
- Point
- poeng
- dårlig
- mulig
- Post
- potensiell
- makt
- forutsi
- forrige
- sannsynligvis
- Problem
- problemer
- prosess
- prosessering
- produsere
- Produkt
- Produksjon
- profesjonell
- gi
- forutsatt
- gir
- sette
- kvalitet
- Rask
- raskere
- FoU
- heller
- Raw
- rådata
- å nå
- Lese
- klar
- Reality
- grunnen til
- poster
- Gjenopprette
- utvinning
- Redusert
- refererer
- i slekt
- relevant
- forbli
- gjenværende
- rapporterer
- påkrevd
- Krav
- ressurs
- Ressurser
- Svare
- resultere
- resulterende
- robust
- Rolle
- omtrent
- Regel
- Kjør
- rennende
- SaaS
- sagemaker
- samme
- sier
- skalerbarhet
- skalerbar
- Skala
- skalering
- Skaleringsløsning
- scenarier
- Vitenskap
- Forsker
- forskere
- sekunder
- seksjoner
- valgt
- utvalg
- send
- sender
- senior
- Følsomhet
- separat
- hver for seg
- separering
- tjeneste
- Tjenester
- sett
- sett
- flere
- Del
- delt
- Sharma
- hun
- vist
- Viser
- side
- signifikant
- lignende
- Enkelt
- Størrelse
- So
- løsning
- Solutions
- LØSE
- Rom
- spesifikk
- spesielt
- fart
- Snurre rundt
- stadier
- Standard
- står
- Begynn
- startet
- starter
- Tilstand
- status
- Trinn
- Steps
- Still
- stoppet
- stoppe
- Stopper
- lagring
- butikker
- String
- sterk
- strukturert
- abonnenter
- suksess
- vellykket
- slik
- støtte
- system
- Systemer
- bord
- skreddersydd
- Ta
- tar
- talentfull
- Oppgave
- oppgaver
- lag
- lag
- Teknisk
- vilkår
- enn
- Det
- De
- Fremtiden
- deres
- Dem
- deretter
- Der.
- derfor
- Disse
- de
- Tredje
- denne
- De
- tre
- terskel
- Gjennom
- tid
- ganger
- til
- sammen
- verktøy
- Totalt
- Tog
- Kurs
- Transaksjonen
- Transaksjonsdetaljer
- Transform
- Transformation
- transformasjoner
- utløse
- utløst
- to
- typen
- typisk
- etter
- forståelse
- lomper
- til
- oppdatert
- us
- bruk
- bruk
- bruke
- bruk sak
- brukt
- ved hjelp av
- validering
- verdi
- variabler
- ulike
- vertikal
- volum
- volumer
- vs
- ønsket
- var
- se
- Vei..
- we
- VI VIL
- når
- hvilken
- HVEM
- hele
- helt
- vil
- vinne
- med
- innenfor
- Arbeid
- arbeidsflyt
- arbeidsflyt
- arbeid
- virker
- verre
- ville
- skriving
- ennå
- Utbytte
- du
- Din
- zephyrnet