Med Amazon SageMaker, kan du administrere hele livssyklusen for ende-til-ende maskinlæring (ML). Den tilbyr mange innebygde funksjoner for å hjelpe til med å administrere ML-arbeidsflytaspekter, som eksperimentsporing og modellstyring via modellregisteret. Dette innlegget gir en løsning skreddersydd for kunder som allerede bruker MLflow, en åpen kildekode-plattform for å administrere ML-arbeidsflyter.
I en Forrige innlegg, diskuterte vi MLflow og hvordan det kan kjøres på AWS og integreres med SageMaker – spesielt når man sporer treningsjobber som eksperimenter og distribuerer en modell registrert i MLflow til SageMaker-administrerte infrastruktur. Imidlertid åpen kildekode-versjon of MLflow gir ikke innfødte brukertilgangskontrollmekanismer for flere leietakere på sporingsserveren. Dette betyr at enhver bruker med tilgang til serveren har administratorrettigheter og kan endre eksperimenter, modellversjoner og stadier. Dette kan være en utfordring for virksomheter i regulerte bransjer som har behov for å opprettholde en sterk modellstyring for revisjonsformål.
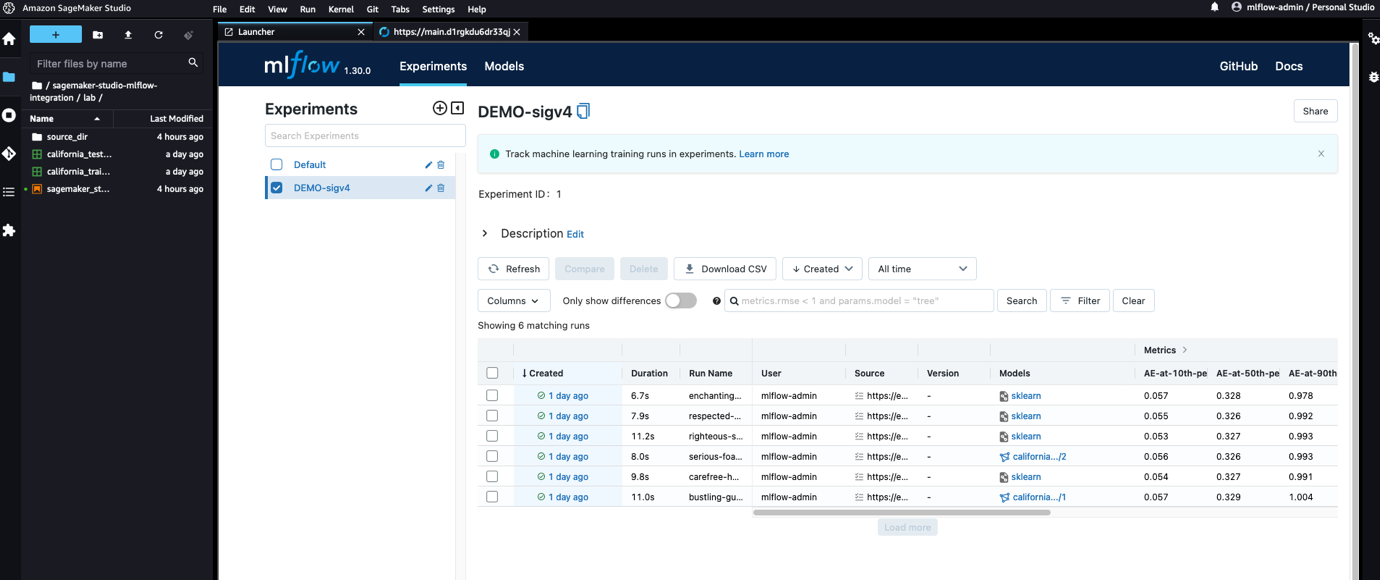
I dette innlegget adresserer vi disse begrensningene ved å implementere tilgangskontrollen utenfor MLflow-serveren og laste ned autentiserings- og autorisasjonsoppgaver til Amazon API-gateway, hvor vi implementerer finmaskede tilgangskontrollmekanismer på ressursnivå ved hjelp av Identitets- og tilgangsstyring (JEG ER). Ved å gjøre det kan vi oppnå robust og sikker tilgang til MLflow-serveren fra både SageMaker administrert infrastruktur og Amazon SageMaker Studio, uten å måtte bekymre deg for legitimasjon og all kompleksiteten bak legitimasjonsadministrasjon. Den modulære designen som er foreslått i denne arkitekturen gjør det enkelt å endre tilgangskontrolllogikken uten å påvirke selve MLflow-serveren. Til slutt, takket være SageMaker Studio-utvidbarhet, forbedrer vi dataforskeropplevelsen ytterligere ved å gjøre MLflow tilgjengelig i Studio, som vist i følgende skjermbilde.
MLflow har integrert funksjonen som muliggjør be om signering med AWS-legitimasjon inn i oppstrømsdepotet for Python SDK, noe som forbedrer integrasjonen med SageMaker. Endringene i MLflow Python SDK er tilgjengelig for alle siden MLflow versjon 1.30.0.
På et høyt nivå demonstrerer dette innlegget følgende:
- Hvordan distribuere en MLflow-server på en serverløs arkitektur som kjører på et privat subnett som ikke er tilgjengelig direkte fra utsiden. For denne oppgaven bygger vi på toppen av følgende GitHub-repo: Administrer livssyklusen for maskinlæring med MLflow og Amazon SageMaker.
- Hvordan eksponere MLflow-serveren via private integrasjoner til en API-gateway, og implementere en sikker tilgangskontroll for programmatisk tilgang via SDK og nettlesertilgang via MLflow-grensesnittet.
- Hvordan logge eksperimenter og kjøringer, og registrere modeller til en MLflow-server fra SageMaker ved å bruke de tilknyttede SageMaker-utførelsesrollene for å autentisere og autorisere forespørsler, og hvordan autentisere via Amazon Cognito til MLflow UI. Vi gir eksempler som demonstrerer eksperimentsporing og bruk av modellregisteret med MLflow fra henholdsvis SageMaker treningsjobber og Studio, i den medfølgende bærbare.
- Hvordan bruke MLflow som et sentralisert depot i et flerkontooppsett.
- Hvordan utvide Studio for å forbedre brukeropplevelsen ved å gjengi MLflow i Studio. For denne oppgaven viser vi hvordan du kan dra nytte av Studio-utvidbarhet ved å installere en JupyterLab-utvidelse.
La oss nå dykke dypere inn i detaljene.
Løsningsoversikt
Du kan tenke på MLflow som tre forskjellige kjernekomponenter som jobber side om side:
- En REST API for backend MLflow-sporingsserveren
- SDK-er slik at du kan samhandle programmatisk med API-ene for MLflow-sporingsserveren fra modelltreningskoden din
- Et React-grensesnitt for MLflow-grensesnittet for å visualisere eksperimentene, kjøringene og artefakterene dine
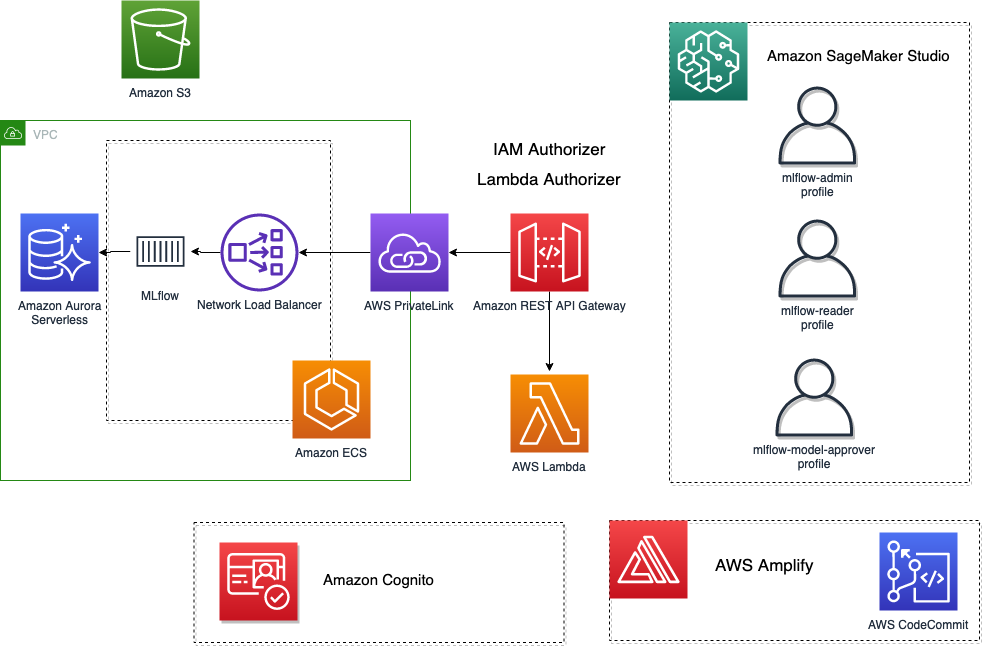
På et høyt nivå er arkitekturen vi har sett for oss og implementert vist i følgende figur.
Forutsetninger
Før du distribuerer løsningen, sørg for at du har tilgang til en AWS-konto med administratorrettigheter.
Distribuer løsningsinfrastrukturen
For å distribuere løsningen beskrevet i dette innlegget, følg de detaljerte instruksjonene i GitHub repository LES MIG. For å automatisere utrullingen av infrastrukturen bruker vi AWS skyutviklingssett (AWS CDK). AWS CDK er et programvareutviklingsrammeverk med åpen kildekode å lage AWS skyformasjon stabler gjennom automatisk CloudFormation-mal generasjon. En stabel er en samling av AWS-ressurser som kan oppdateres, flyttes eller slettes programmatisk. AWS CDK konstruerer er byggesteinene til AWS CDK-applikasjoner, som representerer planen for å definere skyarkitekturer.
Vi kombinerer fire stabler:
- De MLFlowVPCStack stack utfører følgende handlinger:
- De RestApiGatewayStack stack utfører følgende handlinger:
- Utsetter MLflow-serveren via AWS PrivateLink for en REST API-gateway.
- Distribuerer en Amazon Cognito-brukerpool for å administrere brukerne som får tilgang til brukergrensesnittet (fortsatt tomt etter distribusjonen).
- Utplasserer en AWS Lambda autorisator for å verifisere JWT-tokenet med Amazon Cognito-brukerpool-ID-nøklene og returnerer IAM-policyer for å tillate eller avslå en forespørsel. Denne autorisasjonsstrategien brukes på
<MLFlow-Tracking-Server-URI>/*. - Legger til en IAM-autorisator. Dette vil bli brukt på til
<MLFlow-Tracking-Server-URI>/api/*, som vil ha forrang over den forrige.
- De AmplifyMLFlowStack stack utfører følgende handling:
- Oppretter en app koblet til det lappede MLflow-depotet i AWS CodeCommit å bygge og distribuere MLflow UI.
- De SageMakerStudioUserStack stack utfører følgende handlinger:
- Distribuerer et Studio-domene (hvis et ikke eksisterer ennå).
- Legger til tre brukere, hver med en annen SageMaker-utførelsesrolle som implementerer et annet tilgangsnivå:
- mlflow-admin – Har administratorlignende tillatelse til alle MLflow-ressurser.
- mlflow-leser – Har skrivebeskyttede administratortillatelser til alle MLflow-ressurser.
- mlflow-modellgodkjenner – Har de samme tillatelsene som mlflow-reader, pluss kan registrere nye modeller fra eksisterende kjøringer i MLflow og fremme eksisterende registrerte modeller til nye stadier.
Distribuer MLflow-sporingsserveren på en serverløs arkitektur
Vårt mål er å ha en pålitelig, svært tilgjengelig, kostnadseffektiv og sikker distribusjon av MLflow-sporingsserveren. Serverløse teknologier er den perfekte kandidaten til å tilfredsstille alle disse kravene med minimale driftskostnader. For å oppnå det bygger vi et Docker-beholderbilde for MLflow-eksperimentsporingsserveren, og vi kjører det inn på AWS Fargate på Amazon ECS i dens dedikerte VPC som kjører på et privat undernett. MLflow er avhengig av to lagringskomponenter: backend-lageret og for artefaktlageret. For backend-butikken bruker vi Aurora Serverless, og for artefaktbutikken bruker vi Amazon S3. For arkitektur på høyt nivå, se Scenario 4: MLflow med ekstern sporingsserver, backend og artefaktbutikker. Omfattende detaljer om hvordan du gjør denne oppgaven finner du i følgende GitHub-repo: Administrer livssyklusen for maskinlæring med MLflow og Amazon SageMaker.
Sikker MLflow via API Gateway
På dette tidspunktet har vi fortsatt ikke en tilgangskontrollmekanisme på plass. Som et første skritt eksponerer vi MLflow for omverdenen ved hjelp av AWS PrivateLink, som etablerer en privat forbindelse mellom VPC og andre AWS-tjenester, i vårt tilfelle API Gateway. Innkommende forespørsler til MLflow blir deretter fullført via en REST API-gateway, noe som gir oss muligheten til å implementere flere mekanismer for å autorisere innkommende forespørsler. For våre formål fokuserer vi på kun to:
- Bruker IAM-autorisatorer - Med IAM-autorisatorer, må rekvirenten ha riktig IAM-policy tilordnet for å få tilgang til API-gateway-ressursene. Hver forespørsel må legge til autentiseringsinformasjon til forespørsler sendt via HTTP av AWS signaturversjon 4.
- Bruker Lambda-autorisatorer – Dette gir størst fleksibilitet fordi det gir full kontroll over hvordan en forespørsel kan godkjennes. Til slutt, den Lambda autorisator må returnere en IAM-policy, som igjen vil bli evaluert av API Gateway på om forespørselen skal tillates eller avvises.
For den fullstendige listen over støttede autentiserings- og autorisasjonsmekanismer i API Gateway, se Kontrollere og administrere tilgang til en REST API i API Gateway.
MLflow Python SDK-autentisering (IAM-autorisator)
MLflow-eksperimentsporingsserveren implementerer en REST API å samhandle på en programmatisk måte med ressursene og artefakter. MLflow Python SDK gir en praktisk måte å logge beregninger, kjøringer og artefakter på, og den har grensesnitt med API-ressursene som er vert under navneområdet <MLflow-Tracking-Server-URI>/api/. Vi konfigurerer API Gateway til å bruke IAM-autorisatoren for ressurstilgangskontroll på dette navneområdet, og krever dermed at hver forespørsel signeres med AWS Signature versjon 4.
For å forenkle forespørselssigneringsprosessen, fra MLflow 1.30.0, kan denne funksjonen aktiveres sømløst. Sørg for at requests_auth_aws_sigv4 biblioteket er installert i systemet og angi MLFLOW_TRACKING_AWS_SIGV4 miljøvariabel til True. Mer informasjon finner du i offisiell MLflow-dokumentasjon.
På dette tidspunktet trenger MLflow SDK bare AWS-legitimasjon. Fordi request_auth_aws_sigv4 bruker Boto3 for å hente legitimasjon, vet vi at det kan last inn legitimasjon fra forekomstens metadata når en IAM-rolle er knyttet til en Amazon Elastic Compute Cloud (Amazon EC2)-forekomst (for andre måter å levere legitimasjon til Boto3, se Credentials). Dette betyr at den også kan laste inn AWS-legitimasjon når den kjøres fra en SageMaker-administrert instans fra den tilknyttede utførelsesrollen, som diskutert senere i dette innlegget.
Konfigurer IAM-policyer for å få tilgang til MLflow APIer via API-gateway
Du kan bruke IAM-roller og -policyer for å kontrollere hvem som kan påkalle ressurser på API-gateway. For flere detaljer og IAM-policyreferanseerklæringer, se Kontroller tilgang for å påkalle en API.
Følgende kode viser et eksempel på en IAM-policy som gir den som ringer tillatelser til alle metoder på alle ressurser på API-gatewayen som skjermer MLflow, og gir praktisk talt administratortilgang til MLflow-serveren:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/*/*",
"Effect": "Allow"
}
]
}Hvis vi vil ha en policy som tillater en bruker skrivebeskyttet tilgang til alle ressurser, vil IAM-policyen se ut som følgende kode:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": [
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search",
],
"Effect": "Allow"
}
]
}Et annet eksempel kan være en policy for å gi spesifikke brukere tillatelse til å registrere modeller i modellregisteret og fremme dem senere til bestemte stadier (oppsetning, produksjon og så videre):
{ "Version": "2012-10-17", "Statement": [ { "Action": "execute-api:Invoke", "Resource": [ "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/model-versions/*", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/registered-models/*" ], "Effect": "Allow" } ]
}MLflow UI-autentisering (Lambda-autorisator)
Nettlesertilgang til MLflow-serveren håndteres av MLflow UI implementert med React. MLflow-grensesnittet er ikke utviklet for å støtte autentiserte brukere. Å implementere en robust påloggingsflyt kan virke som en skremmende oppgave, men heldigvis kan vi stole på Forsterk UI React-komponenter for autentisering, noe som i stor grad reduserer innsatsen for å opprette en påloggingsflyt i en React-applikasjon, ved å bruke Amazon Cognito for identitetsbutikken.
Amazon Cognito lar oss administrere vår egen brukerbase og også støtte tredjeparts identitetsføderasjon, noe som gjør det mulig å bygge for eksempel ADFS-føderasjon (se Bygg ADFS Federation for webappen din ved å bruke Amazon Cognito User Pools for flere detaljer). Tokens utstedt av Amazon Cognito må verifiseres på API Gateway. Bare å verifisere tokenet er ikke nok for finmasket tilgangskontroll, derfor gir Lambda-autorisatoren oss fleksibiliteten til å implementere logikken vi trenger. Vi kan deretter bygge vår egen Lambda-autorisator for å verifisere JWT-tokenet og generere IAM-policyene for å la API-gatewayen avslå eller tillate forespørselen. Følgende diagram illustrerer MLflow-påloggingsflyten.
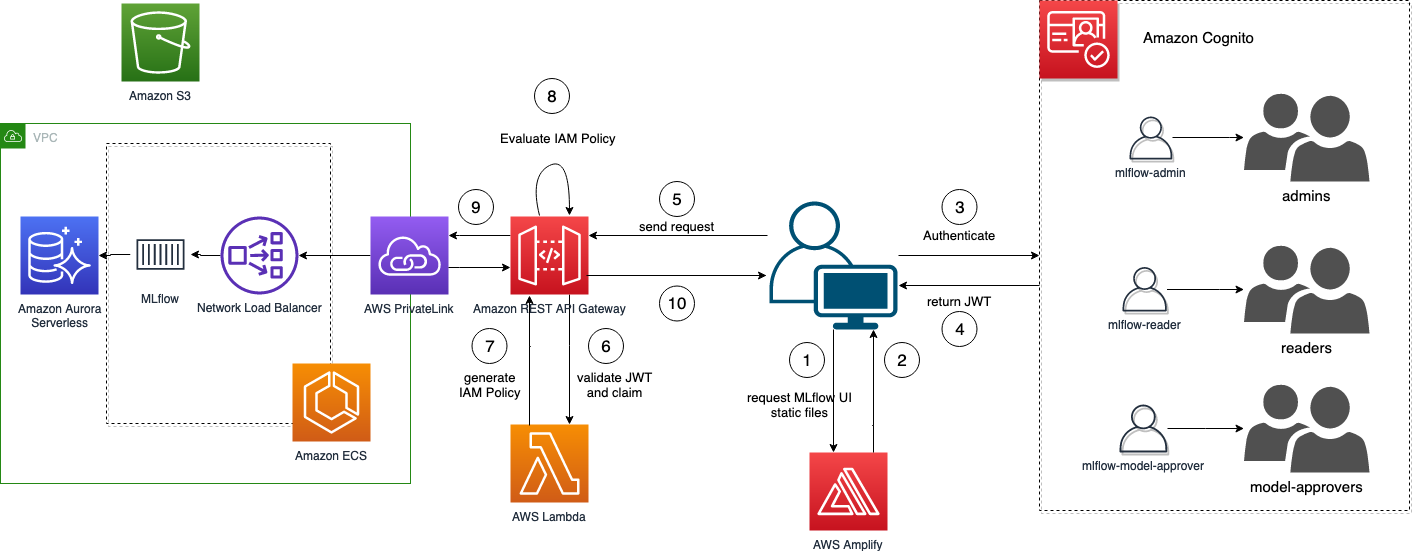
For mer informasjon om de faktiske kodeendringene, se oppdateringsfilen cognito.patch, gjelder for MLflow versjon 2.3.1.
Denne oppdateringen introduserer to funksjoner:
- Legg til Amplify UI-komponentene og konfigurer Amazon Cognito-detaljene via miljøvariabler som implementerer påloggingsflyten
- Trekk ut JWT fra økten og lag en autorisasjonsoverskrift med et bærertoken for hvor du skal sende JWT
Selv om å opprettholde divergerende kode fra oppstrøms alltid gir mer kompleksitet enn å stole på oppstrøms, er det verdt å merke seg at endringene er minimale fordi vi er avhengige av Amplify React UI-komponentene.
Med den nye påloggingsflyten på plass, la oss lage produksjonsbygget for vårt oppdaterte MLflow-grensesnitt. AWS Amplify Hosting er en AWS-tjeneste som gir en git-basert arbeidsflyt for CI/CD og hosting av nettapper. Byggetrinnet i rørledningen er definert av buildspec.yaml, der vi som miljøvariabler kan injisere detaljer om Amazon Cognito-brukerpool-IDen, Amazon Cognito-identitetspool-IDen og brukerpool-klient-IDen som kreves av Amplify UI React-komponenten for å konfigurere autentiseringsflyten. Følgende kode er et eksempel på buildspec.yaml file:
version: "1.0"
applications: - frontend: phases: preBuild: commands: - fallocate -l 4G /swapfile - chmod 600 /swapfile - mkswap /swapfile - swapon /swapfile - swapon -s - yarn install build: commands: - echo "REACT_APP_REGION=$REACT_APP_REGION" >> .env - echo "REACT_APP_COGNITO_USER_POOL_ID=$REACT_APP_COGNITO_USER_POOL_ID" >> .env - echo "REACT_APP_COGNITO_IDENTITY_POOL_ID=$REACT_APP_COGNITO_IDENTITY_POOL_ID" >> .env - echo "REACT_APP_COGNITO_USER_POOL_CLIENT_ID=$REACT_APP_COGNITO_USER_POOL_CLIENT_ID" >> .env - yarn run build artifacts: baseDirectory: build files: - "**/*"Logg eksperimenter og kjører sikkert ved å bruke SageMaker-utførelsesrollen
Et av nøkkelaspektene ved løsningen som diskuteres her, er den sikre integrasjonen med SageMaker. SageMaker er en administrert tjeneste, og som sådan utfører den operasjoner på dine vegne. Hva SageMaker har lov til å gjøre er definert av IAM-policyene knyttet til utførelsesrollen som du knytter til en SageMaker-treningsjobb, eller som du knytter til en brukerprofil som jobber fra Studio. For mer informasjon om SageMaker-utførelsesrollen, se SageMaker-roller.
Ved å konfigurere API-gatewayen til å bruke IAM-autentisering på <MLFlow-Tracking-Server-URI>/api/* ressurser, kan vi definere et sett med IAM-policyer på SageMaker-utførelsesrollen som vil tillate SageMaker å samhandle med MLflow i henhold til tilgangsnivået som er spesifisert.
Når du stiller inn MLFLOW_TRACKING_AWS_SIGV4 miljøvariabel til True mens du jobber i Studio eller i en SageMaker-treningsjobb, vil MLflow Python SDK automatisk signere alle forespørsler, som vil bli validert av API-gatewayen:
os.environ['MLFLOW_TRACKING_AWS_SIGV4'] = "True"
mlflow.set_tracking_uri(tracking_uri)
mlflow.set_experiment(experiment_name)Test SageMaker-utførelsesrollen med MLflow SDK
Hvis du får tilgang til Studio-domenet som ble generert, vil du finne tre brukere:
- mlflow-admin – Tilknyttet en utførelsesrolle med lignende tillatelser som brukeren i Amazon Cognito-gruppens administratorer
- mlflow-leser – Tilknyttet en utførelsesrolle med lignende tillatelser som brukeren i Amazon Cognito-gruppeleserne
- mlflow-modellgodkjenner – Tilknyttet en utførelsesrolle med lignende tillatelser som brukeren i Amazon Cognito-gruppens modellgodkjennere
For å teste de tre forskjellige rollene, se laboratoriene gitt som en del av denne prøven på hver brukerprofil.
Følgende diagram illustrerer arbeidsflyten for Studio-brukerprofiler og SageMaker jobbautentisering med MLflow.
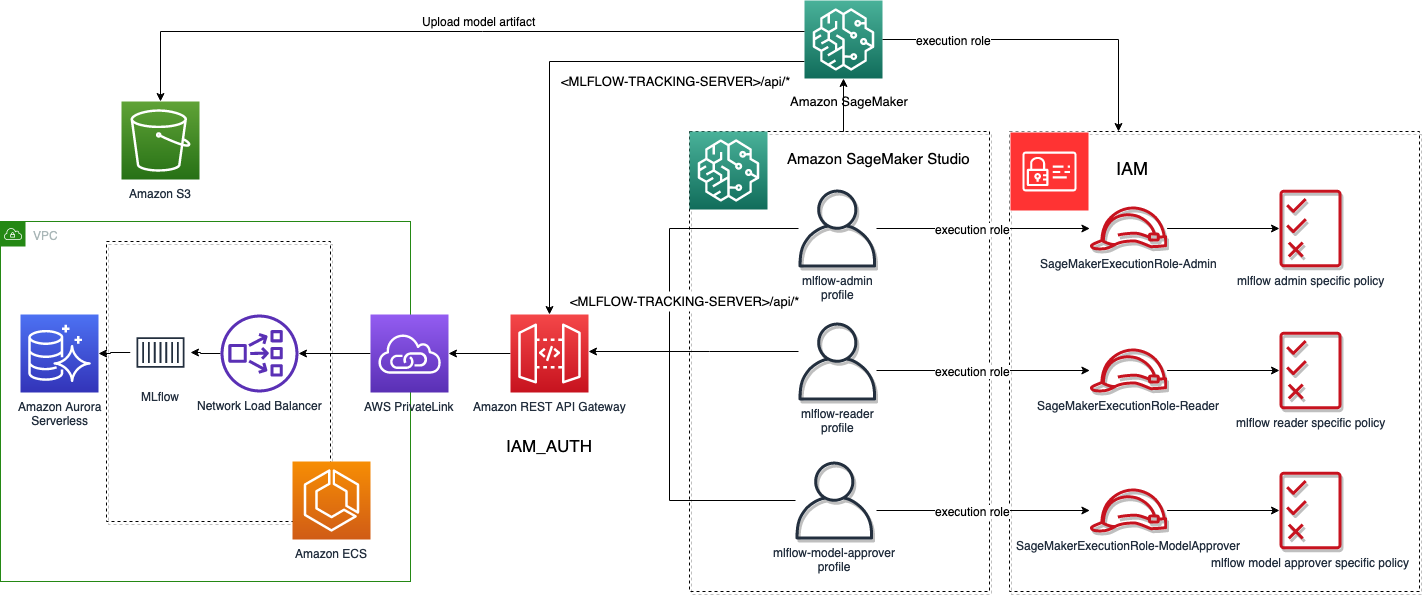
På samme måte, når du kjører SageMaker-jobber på SageMaker-administrerte infrastruktur, hvis du angir miljøvariabelen MLFLOW_TRACKING_AWS_SIGV4 til True, og SageMaker-utførelsesrollen som overføres til jobbene har riktig IAM-policy for å få tilgang til API-gatewayen, kan du trygt samhandle med MLflow-sporingsserveren din uten å måtte administrere legitimasjonen selv. Når du kjører SageMaker-treningsjobber og initialiserer en estimatorklasse, kan du sende miljøvariabler som SageMaker vil injisere og gjøre det tilgjengelig for opplæringsskriptet, som vist i følgende kode:
environment={ "AWS_DEFAULT_REGION": region, "MLFLOW_EXPERIMENT_NAME": experiment_name, "MLFLOW_TRACKING_URI": tracking_uri, "MLFLOW_AMPLIFY_UI_URI": mlflow_amplify_ui, "MLFLOW_TRACKING_AWS_SIGV4": "true", "MLFLOW_USER": user
} estimator = SKLearn( entry_point='train.py', source_dir='source_dir', role=role, metric_definitions=metric_definitions, hyperparameters=hyperparameters, instance_count=1, instance_type='ml.m5.large', framework_version='1.0-1', base_job_name='mlflow', environment=environment
)Visualiser kjøringer og eksperimenter fra MLflow-grensesnittet
Etter at den første distribusjonen er fullført, la oss fylle Amazon Cognito-brukerpoolen med tre brukere, som hver tilhører en annen gruppe, for å teste tillatelsene vi har implementert. Du kan bruke dette skriptet add_users_and_groups.py å seede brukerpoolen. Etter å ha kjørt skriptet, hvis du sjekker Amazon Cognito-brukerpoolen på Amazon Cognito-konsollen, bør du se de tre brukerne som er opprettet.
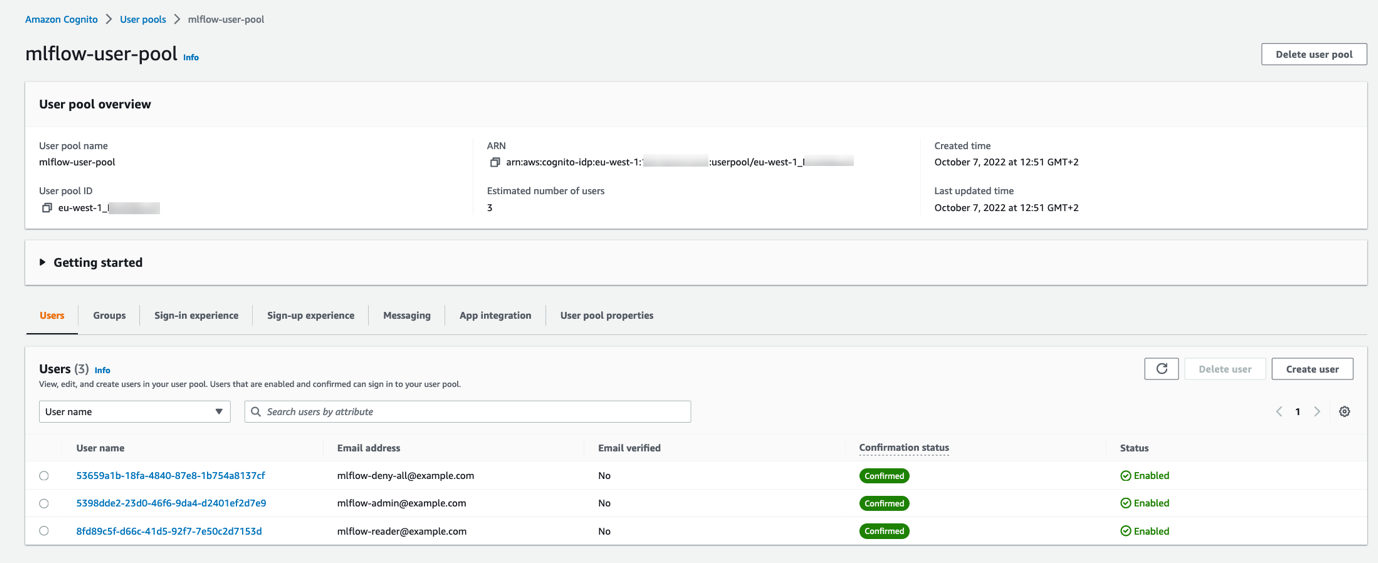
På REST API Gateway-siden vil Lambda-autorisatoren først verifisere signaturen til tokenet ved å bruke Amazon Cognito-brukerpoolnøkkelen og verifisere påstandene. Først etter det vil den trekke ut Amazon Cognito-gruppen brukeren tilhører fra kravet i JWT-tokenet (cognito:groups) og bruk forskjellige tillatelser basert på gruppen vi har programmert.
For vårt spesifikke tilfelle har vi tre grupper:
- admins – Kan se og kan redigere alt
- lesere – Kan bare se alt
- modellgodkjennere – Det samme som lesere, pluss kan registrere modeller, lage versjoner og fremme modellversjoner til neste trinn
Avhengig av gruppen vil Lambda-autorisatoren generere forskjellige IAM-policyer. Dette er bare et eksempel på hvordan autorisasjon kan oppnås; med en Lambda-autorisator kan du implementere hvilken som helst logikk du trenger. Vi har valgt å bygge IAM-policyen på kjøretid i selve Lambda-funksjonen; Du kan imidlertid forhåndsgenerere passende IAM-policyer, lagre dem i Amazon DynamoDB, og hente dem på kjøretid i henhold til din egen forretningslogikk. Men hvis du bare vil begrense et delsett av handlinger, må du være klar over MLflow REST API-definisjon.
Du kan utforske koden for Lambda-autorisatoren på GitHub repo.
Flerkontohensyn
Datavitenskapelige arbeidsflyter må passere flere stadier når de går fra eksperimentering til produksjon. En vanlig tilnærming innebærer separate kontoer dedikert til ulike faser av AI/ML-arbeidsflyten (eksperimentering, utvikling og produksjon). Noen ganger er det imidlertid ønskelig å ha en dedikert konto som fungerer som sentralt oppbevaringssted for modeller. Selv om arkitekturen og prøven vår refererer til en enkelt konto, kan den enkelt utvides til å implementere dette siste scenariet, takket være IAM evne til å bytte roller selv på tvers av kontoer.
Følgende diagram illustrerer en arkitektur som bruker MLflow som et sentralt depot i en isolert AWS-konto.
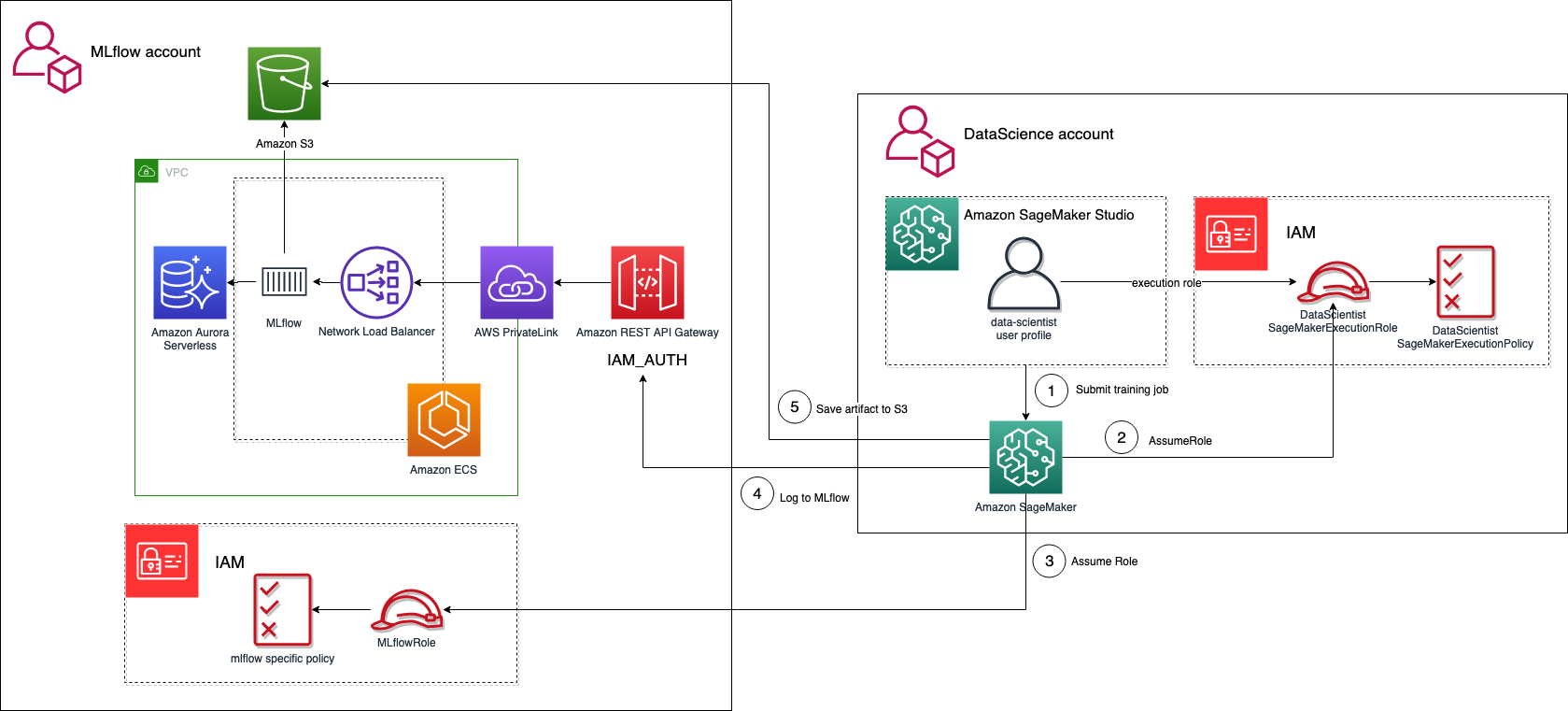
For denne brukssaken har vi to kontoer: én for MLflow-serveren og én for eksperimenteringen som er tilgjengelig for datavitenskapsteamet. For å aktivere tilgang på tvers av kontoer fra en SageMaker-opplæringsjobb som kjører i datavitenskapskontoen, trenger vi følgende elementer:
- En SageMaker-utførelsesrolle i AWS-kontoen for datavitenskap med vedlagt en IAM-policy som gjør det mulig å påta seg en annen rolle i MLflow-kontoen:
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "<ARN-ROLE-IN-MLFLOW-ACCOUNT>" }
}- En IAM-rolle i MLflow-kontoen med den riktige IAM-policyen vedlagt som gir tilgang til MLflow-sporingsserveren, og lar SageMaker-utførelsesrollen i datavitenskapskontoen overta den:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "<ARN-SAGEMAKER-EXECUTION-ROLE-IN-DATASCIENCE-ACCOUNT>" }, "Action": "sts:AssumeRole" } ]
}Innenfor opplæringsskriptet som kjører i datavitenskapskontoen, kan du bruke dette eksemplet før du initialiserer MLflow-klienten. Du må påta deg rollen i MLflow-kontoen og lagre den midlertidige legitimasjonen som miljøvariabler, fordi dette nye settet med legitimasjon vil bli plukket opp av en ny Boto3-sesjon initialisert i MLflow-klienten.
import boto3 # Session using the SageMaker Execution Role in the Data Science Account
session = boto3.Session()
sts = session.client("sts") response = sts.assume_role( RoleArn="<ARN-ROLE-IN-MLFLOW-ACCOUNT>", RoleSessionName="AssumedMLflowAdmin"
) credentials = response['Credentials']
os.environ['AWS_ACCESS_KEY_ID'] = credentials['AccessKeyId']
os.environ['AWS_SECRET_ACCESS_KEY'] = credentials['SecretAccessKey']
os.environ['AWS_SESSION_TOKEN'] = credentials['SessionToken'] # set remote mlflow server and initialize a new boto3 session in the context
# of the assumed role
mlflow.set_tracking_uri(tracking_uri)
experiment = mlflow.set_experiment(experiment_name)I dette eksemplet, RoleArn er ARN for rollen du ønsker å påta deg, og RoleSessionName er navnet du velger for den antatte økten. De sts.assume_role metoden returnerer midlertidig sikkerhetslegitimasjon som MLflow-klienten vil bruke for å opprette en ny klient for den antatte rollen. MLflow-klienten vil deretter sende signerte forespørsler til API Gateway i sammenheng med den antatte rollen.
Gjengi MLflow i SageMaker Studio
SageMaker Studio er basert på JupyterLab, og akkurat som i JupyterLab kan du installere utvidelser for å øke produktiviteten. Takket være denne fleksibiliteten kan dataforskere som jobber med MLflow og SageMaker forbedre integreringen deres ytterligere ved å få tilgang til MLflow UI fra Studio-miljøet og umiddelbart visualisere eksperimentene og kjøringene som er logget. Følgende skjermbilde viser et eksempel på MLflow gjengitt i Studio.
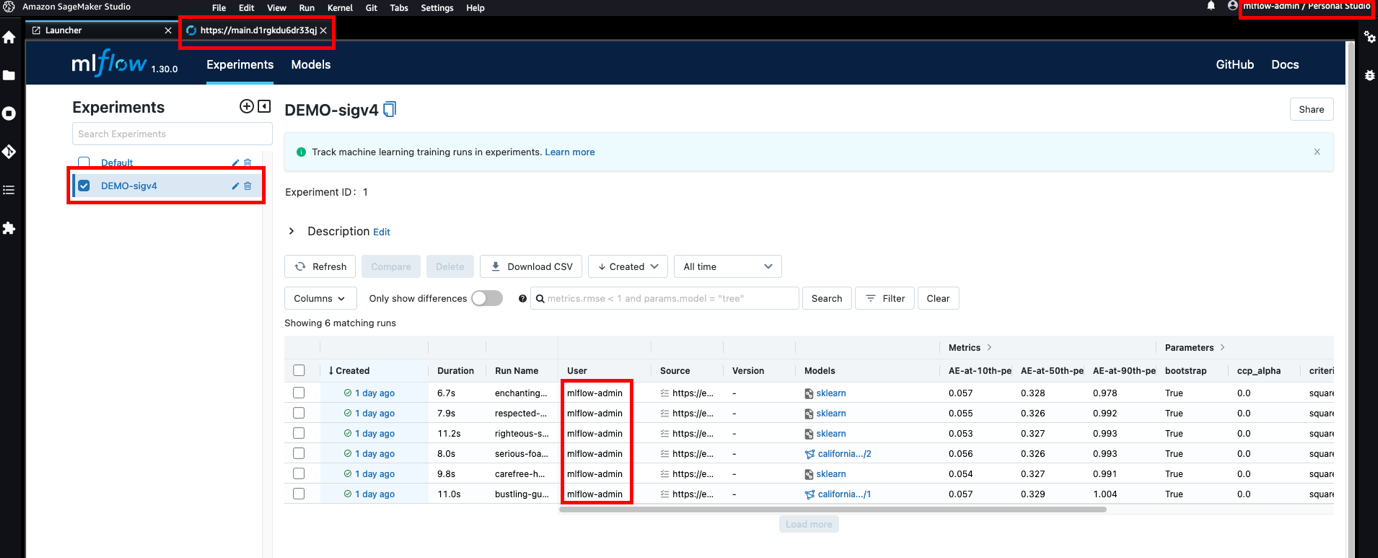
For informasjon om installasjon av JupyterLab-utvidelser i Studio, se Amazon SageMaker Studio og SageMaker Notebook Instance kommer nå med JupyterLab 3 bærbare PC-er for å øke utviklerproduktiviteten. For detaljer om å legge til automatisering via livssykluskonfigurasjoner, se Tilpass Amazon SageMaker Studio ved å bruke livssykluskonfigurasjoner.
I prøvelageret som støtter dette innlegget, tilbyr vi instruksjoner om hvordan du installerer jupyterlab-iframe Utvidelse. Etter at utvidelsen er installert, kan du få tilgang til MLflow-grensesnittet uten å forlate Studio ved å bruke det samme settet med legitimasjon som du har lagret i Amazon Cognito-brukerpoolen.
Neste trinn
Det er flere alternativer for å utvide dette arbeidet. En idé er å konsolidere identitetsbutikken for både SageMaker Studio og MLflow UI. Et annet alternativ ville være å bruke en tredjeparts identitetsføderasjonstjeneste med Amazon Cognito, og deretter bruke AWS IAM Identity Center (etterfølger til AWS Single Sign-On) for å gi tilgang til Studio ved å bruke samme tredjepartsidentitet. En annen er å introdusere full automatisering ved hjelp av Amazon SageMaker-rørledninger for CI/CD-delen av modellbyggingen, og bruk av MLflow som en sentralisert eksperimentsporingsserver og modellregister med sterke styringsevner, samt automatisering for automatisk å distribuere godkjente modeller til et SageMaker-vertsendepunkt.
konklusjonen
Målet med dette innlegget var å gi tilgangskontroll på bedriftsnivå for MLflow. For å oppnå dette skilte vi autentiserings- og autorisasjonsprosessene fra MLflow-serveren og overførte dem til API Gateway. Vi brukte to autorisasjonsmetoder som tilbys av API Gateway, IAM-autorisatorer og Lambda-autorisatorer, for å imøtekomme kravene til både MLflow Python SDK og MLflow UI. Det er viktig å forstå at brukere er eksterne i forhold til MLflow, derfor krever en konsistent styring opprettholdelse av IAM-policyene, spesielt i tilfelle svært detaljerte tillatelser. Til slutt demonstrerte vi hvordan vi kan forbedre opplevelsen til dataforskere ved å integrere MLflow i Studio gjennom enkle utvidelser.
Prøv løsningen på egen hånd ved å gå til GitHub repo og gi oss beskjed hvis du har spørsmål i kommentarene!
Tilleggsressurser
For mer informasjon om SageMaker og MLflow, se følgende:
Om forfatterne
 Paolo Di Francesco er Senior Solutions Architect hos Amazon Web Services (AWS). Han har en doktorgrad i telekommunikasjonsteknikk og har erfaring innen programvareteknikk. Han er lidenskapelig opptatt av maskinlæring og fokuserer for tiden på å bruke sin erfaring til å hjelpe kundene med å nå sine mål på AWS, spesielt i diskusjoner rundt MLOps. Utenom jobben liker han å spille fotball og lese.
Paolo Di Francesco er Senior Solutions Architect hos Amazon Web Services (AWS). Han har en doktorgrad i telekommunikasjonsteknikk og har erfaring innen programvareteknikk. Han er lidenskapelig opptatt av maskinlæring og fokuserer for tiden på å bruke sin erfaring til å hjelpe kundene med å nå sine mål på AWS, spesielt i diskusjoner rundt MLOps. Utenom jobben liker han å spille fotball og lese.
 Chris Fregly er en hovedspesialistløsningsarkitekt for AI og maskinlæring ved Amazon Web Services (AWS) med base i San Francisco, California. Han er medforfatter av O'Reilly Book, "Data Science on AWS." Chris er også grunnleggeren av mange globale møter med fokus på Apache Spark, TensorFlow, Ray og KubeFlow. Han snakker regelmessig på AI- og maskinlæringskonferanser over hele verden, inkludert O'Reilly AI, Open Data Science Conference og Big Data Spain.
Chris Fregly er en hovedspesialistløsningsarkitekt for AI og maskinlæring ved Amazon Web Services (AWS) med base i San Francisco, California. Han er medforfatter av O'Reilly Book, "Data Science on AWS." Chris er også grunnleggeren av mange globale møter med fokus på Apache Spark, TensorFlow, Ray og KubeFlow. Han snakker regelmessig på AI- og maskinlæringskonferanser over hele verden, inkludert O'Reilly AI, Open Data Science Conference og Big Data Spain.
 Irshad Buchh er en hovedløsningsarkitekt hos Amazon Web Services (AWS). Irshad samarbeider med store AWS Global ISV- og SI-partnere og hjelper dem med å bygge deres skystrategi og brede bruk av Amazons cloud computing-plattform. Irshad samhandler med CIOer, CTOer og deres arkitekter og hjelper dem og deres sluttkunder med å implementere skyvisjonen deres. Irshad eier de strategiske og tekniske engasjementene og den ultimate suksessen rundt spesifikke implementeringsprosjekter, og utvikler en dyp ekspertise innen Amazon Web Services-teknologier samt bred kunnskap rundt hvordan applikasjoner og tjenester er konstruert ved hjelp av Amazon Web Services-plattformen.
Irshad Buchh er en hovedløsningsarkitekt hos Amazon Web Services (AWS). Irshad samarbeider med store AWS Global ISV- og SI-partnere og hjelper dem med å bygge deres skystrategi og brede bruk av Amazons cloud computing-plattform. Irshad samhandler med CIOer, CTOer og deres arkitekter og hjelper dem og deres sluttkunder med å implementere skyvisjonen deres. Irshad eier de strategiske og tekniske engasjementene og den ultimate suksessen rundt spesifikke implementeringsprosjekter, og utvikler en dyp ekspertise innen Amazon Web Services-teknologier samt bred kunnskap rundt hvordan applikasjoner og tjenester er konstruert ved hjelp av Amazon Web Services-plattformen.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- Minting the Future med Adryenn Ashley. Tilgang her.
- Kjøp og selg aksjer i PRE-IPO-selskaper med PREIPO®. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/securing-mlflow-in-aws-fine-grained-access-control-with-aws-native-services/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 100
- 30
- a
- Om oss
- adgang
- tilgjengelig
- Tilgang
- Ifølge
- Logg inn
- kontoer
- Oppnå
- oppnådd
- tvers
- Handling
- handlinger
- handlinger
- legge til
- legge
- adresse
- Legger
- admin
- Adopsjon
- Fordel
- Etter
- AI
- AI / ML
- sikte
- Alle
- tillate
- tillater
- allerede
- også
- Selv
- alltid
- Amazon
- Amazon Cognito
- Amazon EC2
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- og
- En annen
- noen
- Apache
- Apache Spark
- api
- APIer
- app
- vises
- aktuelt
- Søknad
- søknader
- anvendt
- Påfør
- tilnærming
- hensiktsmessig
- godkjent
- apps
- arkitektur
- ER
- rundt
- AS
- aspekter
- tildelt
- Førsteamanuensis
- assosiert
- antatt
- At
- vedlagte
- revisjon
- Aurora
- Auth
- godkjenne
- autentisert
- Autentisering
- autorisasjon
- autorisere
- autorisert
- automatisere
- automatisk
- Automatisering
- tilgjengelig
- AWS
- Backend
- basen
- basert
- BE
- bærer
- fordi
- vært
- før du
- bak
- tilhører
- mellom
- Stor
- Store data
- Blocks
- bok
- øke
- både
- bred
- nett~~POS=TRUNC leseren~~POS=HEADCOMP
- bygge
- Bygning
- virksomhet
- men
- by
- california
- Caller
- CAN
- kandidat
- evner
- saken
- imøtekomme
- sentral
- sentralisert
- utfordre
- Endringer
- sjekk
- Velg
- chris
- hevder
- krav
- klasse
- kunde
- Cloud
- cloud computing
- Medforfatter
- kode
- samling
- kombinere
- Kom
- Felles
- fullføre
- kompleksitet
- komponent
- komponenter
- Beregn
- databehandling
- Konferanse
- konferanser
- konfigurasjoner
- tilkobling
- konsistent
- Konsoll
- konsolidere
- Container
- kontekst
- kontroll
- Praktisk
- Kjerne
- korrigere
- kostnadseffektiv
- skape
- opprettet
- KREDENSISJON
- Credentials
- I dag
- Kunder
- dato
- datavitenskap
- dataforsker
- dedikert
- dyp
- dyp ekspertise
- dypere
- definert
- demonstrert
- demonstrerer
- demonstrere
- utplassere
- utplasserings
- distribusjon
- beskrevet
- utforming
- designet
- detaljert
- detaljer
- Utvikler
- utvikle
- Utvikling
- forskjellig
- direkte
- diskutert
- diskusjoner
- do
- Docker
- Docker-beholder
- ikke
- gjør
- domene
- ikke
- hver enkelt
- lett
- savner
- effekt
- innsats
- elementer
- muliggjøre
- aktivert
- muliggjør
- slutt
- ende til ende
- Endpoint
- Ingeniørarbeid
- forbedre
- nok
- bedriftsnivå
- bedrifter
- Miljø
- spesielt
- etablerer
- Eter (ETH)
- evaluert
- Selv
- etter hvert
- Hver
- alle
- eksempel
- eksempler
- gjennomføring
- eksisterer
- eksisterende
- ekspanderende
- erfaring
- eksperiment
- eksperimenter
- ekspertise
- utforske
- utvide
- forlengelse
- utvidelser
- omfattende
- utvendig
- trekke ut
- legge til rette
- gjennomførbart
- Trekk
- Føderasjon
- Figur
- filet
- Filer
- Endelig
- Finn
- Først
- fleksibilitet
- flyten
- Fokus
- fokuserte
- fokusering
- følge
- etter
- fotball
- Til
- funnet
- Grunnleggeren
- fire
- Rammeverk
- Francisco
- fra
- foran
- Front end
- Frontend
- fullt
- funksjon
- videre
- gateway
- generere
- generert
- generasjonen
- GitHub
- Gi
- Giving
- Global
- Mål
- styresett
- innvilge
- tilskudd
- størst
- sterkt
- Gruppe
- Gruppens
- håndteres
- Ha
- å ha
- he
- hjelpe
- hjelper
- her.
- Høy
- høyt nivå
- svært
- hans
- holder
- vert
- Hosting
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- ID
- Tanken
- identiteter
- Identitet
- if
- illustrerer
- bilde
- umiddelbart
- slag
- iverksette
- gjennomføring
- implementert
- implementere
- redskaper
- viktig
- forbedre
- bedre
- in
- Inkludert
- Innkommende
- bransjer
- informasjon
- Infrastruktur
- installere
- installerte
- installere
- f.eks
- instruksjoner
- integrert
- Integrering
- integrering
- integrasjoner
- samhandle
- interaktiv
- grensesnitt
- inn
- introdusere
- Introduserer
- innebærer
- isolert
- Utstedt
- IT
- DET ER
- selv
- Jobb
- Jobb
- bare
- Jwt
- Hold
- nøkkel
- nøkler
- Vet
- KubeFlow
- stor
- Siste
- seinere
- læring
- forlater
- Nivå
- Bibliotek
- Livssyklus
- i likhet med
- begrensninger
- knyttet
- Liste
- laste
- logg
- logget
- logging
- logikk
- Logg inn
- Se
- ser ut som
- maskin
- maskinlæring
- gjøre
- GJØR AT
- Making
- administrer
- fikk til
- ledelse
- administrerende
- mange
- midler
- mekanisme
- mekanismer
- Meetups
- metode
- metoder
- Metrics
- kunne
- minimal
- ML
- MLOps
- modell
- modeller
- modifisere
- modulære
- mer
- multi
- flere
- må
- navn
- innfødt
- Trenger
- nødvendig
- trenger
- behov
- Ny
- neste
- bærbare
- notatbøker
- nå
- of
- tilbudt
- Tilbud
- on
- ONE
- bare
- åpen
- åpne data
- åpen kildekode
- Programvare med åpen kildekode
- operasjonell
- Drift
- Alternativ
- alternativer
- or
- OS
- Annen
- vår
- ut
- utenfor
- enn
- egen
- eier
- del
- Spesielt
- partnere
- passere
- bestått
- lidenskapelig
- patch
- perfekt
- utfører
- tillatelse
- tillatelser
- plukket
- rørledning
- Sted
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- i tillegg til
- Point
- Politikk
- politikk
- basseng
- mulighet
- Post
- praktisk talt
- forrige
- Principal
- privat
- prosess
- Prosesser
- Produksjon
- produktivitet
- Profil
- Profiler
- programma
- programmert
- Progress
- prosjekter
- fremme
- foreslått
- gi
- forutsatt
- gir
- formål
- Python
- spørsmål
- RAY
- å nå
- Reager
- lesere
- Lesning
- reduserer
- region
- registrere
- registrert
- registret
- regelmessig
- regulert
- regulerte næringer
- pålitelig
- avhengige
- fjernkontroll
- gjengivelse
- Repository
- representerer
- anmode
- forespørsler
- Krav
- Krever
- ressurs
- Ressurser
- svar
- REST
- begrense
- retur
- avkastning
- ikke sant
- rettigheter
- robust
- Rolle
- roller
- Kjør
- rennende
- går
- sagemaker
- samme
- San
- San Fransisco
- scenario
- Vitenskap
- Forsker
- forskere
- SDK
- sømløst
- sikre
- sikkert
- sikring
- sikkerhet
- se
- seed
- send
- senior
- separat
- server~~POS=TRUNC
- tjeneste
- Tjenester
- Session
- sett
- innstilling
- oppsett
- flere
- bør
- Vis
- vist
- Viser
- side
- undertegne
- signatur
- signert
- signering
- lignende
- Enkelt
- ganske enkelt
- siden
- enkelt
- So
- Software
- programvareutvikling
- software engineering
- løsning
- Solutions
- Spania
- Spark
- Snakker
- spesialist
- spesifikk
- spesifisert
- stable
- Stabler
- stadier
- iscenesettelse
- Start
- Uttalelse
- uttalelser
- Trinn
- Steps
- Still
- lagring
- oppbevare
- lagret
- rett fram
- Strategisk
- Strategi
- sterk
- studio
- subnett
- suksess
- slik
- levere
- støtte
- Støttes
- Støtte
- sikker
- Bytte om
- system
- skreddersydd
- Ta
- Oppgave
- oppgaver
- lag
- Teknisk
- Technologies
- telekommunikasjon
- midlertidig
- tensorflow
- test
- enn
- Takk
- Det
- De
- verden
- deres
- Dem
- deretter
- derved
- derfor
- Disse
- de
- Tenk
- tredjeparts
- denne
- tre
- Gjennom
- tid
- til
- token
- tokens
- topp
- Sporing
- Tog
- Kurs
- overføres
- sant
- SVING
- to
- ui
- ultimate
- etter
- forstå
- oppdatert
- upon
- us
- bruke
- bruk sak
- Bruker
- Brukererfaring
- Brukere
- ved hjelp av
- bruke
- benyttes
- validert
- variabler
- verifisert
- verifisere
- verifisere
- versjon
- veldig
- av
- syn
- visualisere
- ønsker
- var
- Vei..
- måter
- we
- web
- webtjenester
- VI VIL
- Hva
- når
- om
- hvilken
- mens
- HVEM
- hele
- vil
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- arbeidsflyt
- arbeid
- virker
- verden
- bekymring
- verdt
- ville
- ennå
- du
- Din
- deg selv
- zephyrnet