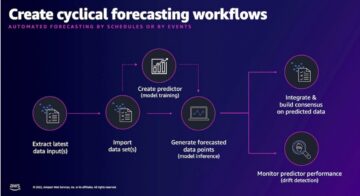
Dziś z radością ogłaszamy, że Strażnik Lamy model jest już dostępny dla klientów korzystających z niego Amazon SageMaker JumpStart. Llama Guard zapewnia zabezpieczenia danych wejściowych i wyjściowych we wdrażaniu modelu dużego języka (LLM). Jest to jeden z elementów inicjatywy Purple Llama, firmy Meta, obejmującej narzędzia i oceny otwartego zaufania i bezpieczeństwa, które pomagają programistom w odpowiedzialnym tworzeniu modeli sztucznej inteligencji. Purple Llama łączy narzędzia i oceny, które pomagają społeczności w odpowiedzialnym budowaniu dzięki generatywnym modelom sztucznej inteligencji. Pierwsza wersja skupia się na bezpieczeństwie cybernetycznym oraz zabezpieczeniach wejściowych i wyjściowych LLM. Komponenty projektu Purple Llama, w tym model Llama Guard, są licencjonowane w trybie permisywnym, co umożliwia wykorzystanie zarówno w celach badawczych, jak i komercyjnych.
Teraz możesz używać modelu Llama Guard w SageMaker JumpStart. SageMaker JumpStart to centrum uczenia maszynowego (ML). Amazon Sage Maker która zapewnia dostęp do modeli podstawowych, wbudowanych algorytmów i kompleksowych szablonów rozwiązań, które pomogą Ci szybko rozpocząć pracę z uczeniem maszynowym.
W tym poście opisujemy, jak wdrożyć model Llama Guard i zbudować odpowiedzialne, generatywne rozwiązania AI.
Model Strażnika Lamy
Llama Guard to nowy model firmy Meta, który zapewnia poręcze wejściowe i wyjściowe dla wdrożeń LLM. Llama Guard to ogólnodostępny model, który działa konkurencyjnie w popularnych otwartych testach porównawczych i zapewnia programistom wstępnie wyszkolony model, który pomaga chronić się przed generowaniem potencjalnie ryzykownych wyników. Model ten został przeszkolony na zestawie publicznie dostępnych zbiorów danych, aby umożliwić wykrywanie typowych typów potencjalnie ryzykownych lub naruszających treści treści, które mogą być istotne w wielu przypadkach użycia przez programistów. Ostatecznie wizja modelu polega na umożliwieniu programistom dostosowania tego modelu do obsługi odpowiednich przypadków użycia oraz ułatwienia przyjęcia najlepszych praktyk i ulepszenia otwartego ekosystemu.
Llama Guard może być używany przez programistów jako dodatkowe narzędzie do integracji z ich własnymi strategiami łagodzenia skutków, takimi jak chatboty, moderowanie treści, obsługa klienta, monitorowanie mediów społecznościowych i edukacja. Przekazując treści generowane przez użytkowników przez Llama Guard przed ich opublikowaniem lub udzieleniem odpowiedzi, programiści mogą oznaczyć niebezpieczny lub nieodpowiedni język i podjąć działania w celu utrzymania bezpiecznego i pełnego szacunku środowiska.
Przyjrzyjmy się, jak możemy wykorzystać model Llama Guard w SageMaker JumpStart.
Modele podstawowe w SageMaker
SageMaker JumpStart zapewnia dostęp do szeregu modeli z popularnych centrów modeli, w tym Hugging Face, PyTorch Hub i TensorFlow Hub, których możesz używać w toku prac programistycznych ML w SageMaker. Ostatnie postępy w uczeniu maszynowym dały początek nowej klasie modeli znanych jako modele fundamentów, które są zazwyczaj szkolone na miliardach parametrów i można je dostosować do szerokiej kategorii przypadków użycia, takich jak podsumowywanie tekstu, generowanie dzieł sztuki cyfrowej i tłumaczenie językowe. Ponieważ uczenie tych modeli jest drogie, klienci chcą korzystać z istniejących, wstępnie wytrenowanych modeli podstawowych i dostrajać je w razie potrzeby, zamiast samodzielnie szkolić te modele. SageMaker udostępnia wyselekcjonowaną listę modeli, spośród których możesz wybierać w konsoli SageMaker.
W SageMaker JumpStart można teraz znaleźć modele fundamentów od różnych dostawców modeli, co umożliwia szybkie rozpoczęcie pracy z modelami fundamentów. Możesz znaleźć modele podstawowe w oparciu o różne zadania lub dostawców modeli, a także łatwo przeglądać charakterystykę modelu i warunki użytkowania. Możesz także wypróbować te modele za pomocą widżetu testowego interfejsu użytkownika. Jeśli chcesz używać podstawowego modelu na dużą skalę, możesz to łatwo zrobić bez opuszczania programu SageMaker, korzystając z gotowych notatników od dostawców modeli. Ponieważ modele są hostowane i wdrażane w AWS, możesz mieć pewność, że Twoje dane, niezależnie od tego, czy zostaną użyte do oceny czy wykorzystania modelu na dużą skalę, nigdy nie zostaną udostępnione stronom trzecim.
Przyjrzyjmy się, jak możemy wykorzystać model Llama Guard w SageMaker JumpStart.
Odkryj model Llama Guard w SageMaker JumpStart
Dostęp do podstawowych modeli Code Lama można uzyskać poprzez SageMaker JumpStart w interfejsie użytkownika SageMaker Studio i w pakiecie SageMaker Python SDK. W tej sekcji omówimy, jak odkryć modele w Studio Amazon SageMaker.
SageMaker Studio to zintegrowane środowisko programistyczne (IDE) zapewniające pojedynczy internetowy interfejs wizualny, w którym można uzyskać dostęp do specjalnie zaprojektowanych narzędzi umożliwiających wykonanie wszystkich etapów programowania ML, od przygotowania danych po budowanie, trenowanie i wdrażanie modeli ML. Aby uzyskać więcej informacji na temat rozpoczęcia i konfiguracji SageMaker Studio, zobacz Studio Amazon SageMaker.
W SageMaker Studio możesz uzyskać dostęp do SageMaker JumpStart, który zawiera wstępnie przeszkolone modele, notatniki i gotowe rozwiązania, w zakładce Gotowe i zautomatyzowane rozwiązania.
Na stronie docelowej SageMaker JumpStart możesz znaleźć model Llama Guard, wybierając Meta Hub lub wyszukując Llama Guard.

Możesz wybierać spośród różnych wariantów modeli Lamy, w tym Llama Guard, Llama-2 i Code Llama.

Możesz wybrać kartę modelu, aby wyświetlić szczegółowe informacje na temat modelu, takie jak licencja, dane użyte do szkolenia i sposób korzystania. Znajdziesz tu także Rozmieścić opcję, która przeniesie Cię do strony docelowej, na której możesz przetestować wnioskowanie na przykładowym ładunku.

Wdróż model za pomocą pakietu SageMaker Python SDK
Kod pokazujący rozmieszczenie Llama Guard znajdziesz na Amazon JumpStart oraz przykład wykorzystania wdrożonego modelu w to Notatnik GitHuba.
W poniższym kodzie określamy identyfikator modelu centrum modelu SageMaker i wersję modelu do użycia podczas wdrażania Llama Guard:
Możesz teraz wdrożyć model za pomocą SageMaker JumpStart. Poniższy kod używa domyślnego wystąpienia ml.g5.2xlarge dla punktu końcowego wnioskowania. Możesz wdrożyć model na innych typach instancji, przekazując instance_type JumpStartModel klasa. Wdrożenie może potrwać kilka minut. Aby wdrożenie przebiegło pomyślnie, należy ręcznie zmienić plik accept_eula argument w metodzie wdrażania modelu do True.
Model ten jest wdrażany przy użyciu kontenera uczenia głębokiego Text Generation Inference (TGI). Żądania wnioskowania obsługują wiele parametrów, w tym następujące:
- maksymalna długość – Model generuje tekst do momentu osiągnięcia długości wyjściowej (w tym długości kontekstu wejściowego).
max_length. Jeśli jest określony, musi być dodatnią liczbą całkowitą. - max_new_tokens – Model generuje tekst aż do osiągnięcia długości wyjściowej (z wyłączeniem długości kontekstu wejściowego).
max_new_tokens. Jeśli jest określony, musi być dodatnią liczbą całkowitą. - liczba_wiązek – Wskazuje liczbę wiązek użytych w wyszukiwaniu zachłannym. Jeśli określono, musi to być liczba całkowita większa lub równa
num_return_sequences. - no_repeat_ngram_size – Model zapewnia, że sekwencja słów z
no_repeat_ngram_sizenie powtarza się w sekwencji wyjściowej. Jeśli jest określony, musi być dodatnią liczbą całkowitą większą niż 1. - temperatura – Ten parametr kontroluje losowość sygnału wyjściowego. Wyższy
temperatureskutkuje sekwencją wyjściową ze słowami o niskim prawdopodobieństwie i niższymtemperatureskutkuje sekwencją wyjściową zawierającą słowa o wysokim prawdopodobieństwie. Jeślitemperaturewynosi 0, powoduje to zachłanne dekodowanie. Jeśli jest określony, musi to być dodatnia liczba zmiennoprzecinkowa. - wcześnie_zatrzymanie - Jeśli
True, generowanie tekstu zakończy się, gdy wszystkie hipotezy dotyczące wiązek dotrą do końca żetonu zdania. Jeśli jest określony, musi to być wartość logiczna. - zrobić_próbkę - Jeśli
True, model próbkuje następne słowo zgodnie z prawdopodobieństwem. Jeśli jest określony, musi to być wartość logiczna. - góra_k – Na każdym etapie generowania tekstu model pobiera wyłącznie próbki z
top_knajbardziej prawdopodobne słowa. Jeśli jest określony, musi być dodatnią liczbą całkowitą. - góra_p – Na każdym etapie generowania tekstu model pobiera próbki z najmniejszego możliwego zestawu słów ze skumulowanym prawdopodobieństwem
top_p. Jeśli jest określony, musi to być liczba zmiennoprzecinkowa między 0 a 1. - return_full_text - Jeśli
True, tekst wejściowy będzie częścią tekstu wygenerowanego na wyjściu. Jeśli jest określony, musi to być wartość logiczna. Wartość domyślna toFalse. - Zatrzymaj się – Jeśli określono, musi to być lista ciągów. Generowanie tekstu zostaje zatrzymane, jeśli zostanie wygenerowany którykolwiek z określonych ciągów.
Wywołaj punkt końcowy SageMaker
Możesz programowo pobrać przykładowe ładunki z pliku JumpStartModel obiekt. Pomoże Ci to szybko rozpocząć pracę, przestrzegając wstępnie sformatowanych instrukcji, które Llama Guard może przyswoić. Zobacz następujący kod:
Po uruchomieniu poprzedniego przykładu możesz zobaczyć, jak dane wejściowe i wyjściowe zostaną sformatowane przez Llama Guard:
Podobnie jak Lama-2, Llama Guard używa specjalnych żetonów, aby wskazać modelowi instrukcje dotyczące bezpieczeństwa. Ogólnie rzecz biorąc, ładunek powinien mieć następujący format:
Monit użytkownika pokazany jako {user_prompt} powyżej, może dodatkowo zawierać sekcje definicji kategorii treści i rozmów, które wyglądają następująco:
W następnej sekcji omówimy zalecane wartości domyślne dla zadania, kategorii treści i definicji instrukcji. Rozmowa powinna odbywać się naprzemiennie User i Agent tekst w następujący sposób:
Moderuj rozmowę z Czatem Llama-2
Możesz teraz wdrożyć punkt końcowy modelu Llama-2 7B Chat na potrzeby czatu konwersacyjnego, a następnie używać Llama Guard do moderowania tekstu wejściowego i wyjściowego pochodzącego z czatu Llama-2 7B.
Pokazujemy przykład wejścia i wyjścia modelu czatu Llama-2 7B moderowanego przez Llama Guard, ale możesz używać Llama Guard do moderacji z dowolnym wybranym LLM.
Wdróż model za pomocą następującego kodu:
Możesz teraz zdefiniować szablon zadania Llama Guard. Kategorie niebezpiecznych treści można dostosować w zależności od konkretnego przypadku użycia. Możesz zdefiniować zwykłym tekstem znaczenie każdej kategorii treści, w tym, które treści powinny być oznaczone jako niebezpieczne, a które powinny być dozwolone jako bezpieczne. Zobacz następujący kod:
Następnie definiujemy funkcje pomocnicze format_chat_messages i format_guard_messages aby sformatować monit dla modelu czatu i modelu Llama Guard, który wymagał specjalnych tokenów:
Następnie możesz użyć tych funkcji pomocniczych w wierszu przykładowego komunikatu, aby uruchomić przykładowe dane wejściowe przez Llama Guard i sprawdzić, czy treść komunikatu jest bezpieczna:
Poniższe dane wyjściowe wskazują, że wiadomość jest bezpieczna. Możesz zauważyć, że podpowiedź zawiera słowa, które mogą wiązać się z przemocą, ale w tym przypadku Llama Guard jest w stanie zrozumieć kontekst w odniesieniu do instrukcji i definicji kategorii niebezpiecznych, które podaliśmy wcześniej i ustali, że jest to podpowiedź bezpieczna, a nie związane z przemocą.
Teraz, gdy już potwierdziłeś, że tekst wejściowy jest bezpieczny w odniesieniu do kategorii zawartości Llama Guard, możesz przekazać ten ładunek do wdrożonego modelu Llama-2 7B, aby wygenerować tekst:
Oto odpowiedź od modelki:
Na koniec możesz potwierdzić, że tekst odpowiedzi z modelu zawiera bezpieczną treść. Tutaj rozszerzasz odpowiedź wyjściową LLM na komunikaty wejściowe i przeprowadzasz całą rozmowę przez Llama Guard, aby upewnić się, że rozmowa jest bezpieczna dla Twojej aplikacji:
Możesz zobaczyć następujące dane wyjściowe wskazujące, że odpowiedź z modelu czatu jest bezpieczna:
Sprzątać
Po przetestowaniu punktów końcowych pamiętaj o usunięciu punktów końcowych wnioskowania SageMaker i modelu, aby uniknąć naliczania opłat.
Wnioski
W tym poście pokazaliśmy, jak można moderować wejścia i wyjścia za pomocą Llama Guard oraz umieszczać poręcze dla wejść i wyjść z LLM w SageMaker JumpStart.
W miarę ciągłego rozwoju sztucznej inteligencji niezwykle ważne jest nadanie priorytetu odpowiedzialnemu rozwojowi i wdrażaniu. Narzędzia takie jak CyberSecEval i Llama Guard firmy Purple Llama odgrywają zasadniczą rolę we wspieraniu bezpiecznych innowacji, oferując wczesną identyfikację ryzyka i wskazówki dotyczące jego łagodzenia w przypadku modeli językowych. Należy je uwzględnić w procesie projektowania sztucznej inteligencji, aby od pierwszego dnia wykorzystać jej pełny potencjał LLM w sposób etyczny.
Wypróbuj Llama Guard i inne modele podkładów w SageMaker JumpStart już dziś i daj nam znać, co myślisz!
Niniejsze wytyczne służą wyłącznie celom informacyjnym. Nadal powinieneś przeprowadzić własną niezależną ocenę i podjąć kroki, aby upewnić się, że przestrzegasz własnych, konkretnych praktyk i standardów kontroli jakości, a także lokalnych zasad, przepisów ustawowych, wykonawczych, licencji i warunków użytkowania, które mają zastosowanie do Ciebie, Twoich treści, oraz model strony trzeciej, do którego odwołuje się niniejszy poradnik. AWS nie ma kontroli ani uprawnień nad modelem strony trzeciej, o którym mowa w niniejszych wytycznych, i nie składa żadnych oświadczeń ani gwarancji, że model strony trzeciej jest bezpieczny, wolny od wirusów, operacyjny lub zgodny ze środowiskiem produkcyjnym i standardami użytkownika. AWS nie składa żadnych oświadczeń, zapewnień ani gwarancji, że jakiekolwiek informacje zawarte w niniejszych wytycznych spowodują określony wynik lub rezultat.
O autorach
 dr Kyle Ulrich jest naukowcem z Wbudowane algorytmy Amazon SageMaker zespół. Jego zainteresowania badawcze obejmują skalowalne algorytmy uczenia maszynowego, wizję komputerową, szeregi czasowe, nieparametryczne Bayesa i procesy Gaussa. Jego doktorat uzyskał na Uniwersytecie Duke'a i publikował artykuły w czasopismach NeurIPS, Cell i Neuron.
dr Kyle Ulrich jest naukowcem z Wbudowane algorytmy Amazon SageMaker zespół. Jego zainteresowania badawcze obejmują skalowalne algorytmy uczenia maszynowego, wizję komputerową, szeregi czasowe, nieparametryczne Bayesa i procesy Gaussa. Jego doktorat uzyskał na Uniwersytecie Duke'a i publikował artykuły w czasopismach NeurIPS, Cell i Neuron.
 Evana Kravitza jest inżynierem oprogramowania w Amazon Web Services i pracuje nad SageMaker JumpStart. Interesuje go zbieżność uczenia maszynowego z przetwarzaniem w chmurze. Evan uzyskał tytuł licencjata na Uniwersytecie Cornell i tytuł magistra na Uniwersytecie Kalifornijskim w Berkeley. W 2021 roku na konferencji ICLR wygłosił referat na temat kontradyktoryjnych sieci neuronowych. W wolnym czasie Evan lubi gotować, podróżować i biegać po Nowym Jorku.
Evana Kravitza jest inżynierem oprogramowania w Amazon Web Services i pracuje nad SageMaker JumpStart. Interesuje go zbieżność uczenia maszynowego z przetwarzaniem w chmurze. Evan uzyskał tytuł licencjata na Uniwersytecie Cornell i tytuł magistra na Uniwersytecie Kalifornijskim w Berkeley. W 2021 roku na konferencji ICLR wygłosił referat na temat kontradyktoryjnych sieci neuronowych. W wolnym czasie Evan lubi gotować, podróżować i biegać po Nowym Jorku.
 Rachna Czadha jest głównym architektem rozwiązań AI/ML w obszarze kont strategicznych w AWS. Rachna jest optymistą, który wierzy, że etyczne i odpowiedzialne korzystanie z AI może w przyszłości poprawić społeczeństwo i przynieść dobrobyt gospodarczy i społeczny. W wolnym czasie Rachna lubi spędzać czas z rodziną, spacerować i słuchać muzyki.
Rachna Czadha jest głównym architektem rozwiązań AI/ML w obszarze kont strategicznych w AWS. Rachna jest optymistą, który wierzy, że etyczne i odpowiedzialne korzystanie z AI może w przyszłości poprawić społeczeństwo i przynieść dobrobyt gospodarczy i społeczny. W wolnym czasie Rachna lubi spędzać czas z rodziną, spacerować i słuchać muzyki.
 Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana-Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana-Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
 Karola Albertsena kieruje produktem, inżynierią i nauką w Amazon SageMaker Algorithms i JumpStart, centrum uczenia maszynowego SageMaker. Pasjonuje się stosowaniem uczenia maszynowego w celu odblokowania wartości biznesowej.
Karola Albertsena kieruje produktem, inżynierią i nauką w Amazon SageMaker Algorithms i JumpStart, centrum uczenia maszynowego SageMaker. Pasjonuje się stosowaniem uczenia maszynowego w celu odblokowania wartości biznesowej.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- Zdolny
- O nas
- powyżej
- Akceptuj
- dostęp
- Stosownie
- Konta
- działać
- Działania
- działania
- aktywny
- zajęcia
- rzeczywisty
- dodatek
- Skorygowana
- przyjąć
- awansować
- zaliczki
- przeciwny
- Rada
- przed
- Agent
- AI
- Modele AI
- AI / ML
- Alkohol
- Algorytmy
- Wszystkie kategorie
- również
- Amazonka
- Amazon Sage Maker
- Amazon SageMaker JumpStart
- Amazon Web Services
- an
- i
- Ogłosić
- odpowiedź
- każdy
- Zastosowanie
- stosowany
- Aplikuj
- Stosowanie
- właściwy
- SĄ
- argument
- argumenty
- Sztuka
- AS
- oszacowanie
- pomagać
- Asystent
- powiązany
- zapewniony
- At
- władza
- zautomatyzowane
- dostępny
- uniknąć
- AWS
- na podstawie
- podstawowy
- Bayesian
- BE
- Belka
- bo
- być
- zanim
- rozpocząć
- zachowanie
- uważa,
- poniżej
- Benchmarki
- Berkeley
- BEST
- Najlepsze praktyki
- pomiędzy
- miliardy
- ciało
- obie
- przynieść
- Przynosi
- budować
- Budowanie
- wbudowany
- biznes
- ale
- by
- California
- CAN
- konopie indyjskie
- karta
- walizka
- Etui
- kategorie
- Kategoria
- komórka
- wyzwania
- szansa
- zmiana
- Charakterystyka
- Opłaty
- nasze chatboty
- ZOBACZ
- chemiczny
- wybór
- Dodaj
- Wybierając
- Miasto
- klasa
- kleń
- Chmura
- cloud computing
- kod
- kolor
- przyjście
- handlowy
- zobowiązany
- wspólny
- społeczność
- zgodny
- wykonania
- składniki
- skład
- komputer
- Wizja komputerowa
- computing
- Konferencja
- konferencje
- Potwierdzać
- ZATWARDZIAŁY
- zbieg
- Konsola
- konsumpcja
- zawierać
- Pojemnik
- zawiera
- zawartość
- moderacja treści
- kontekst
- ciągły
- kontrola
- kontrolowanych
- kontroli
- Rozmowa
- konwersacyjny
- rozmowy
- gotowanie
- Cornell
- mógłby
- Stwórz
- tworzenie
- Zbrodnie
- Karny
- krytyczny
- kurator
- klient
- Obsługa klienta
- Klientów
- dostosować
- cyber
- bezpieczeństwo cybernetyczne
- cykl
- dane
- zbiory danych
- dzień
- Rozszyfrowanie
- głęboko
- głęboka nauka
- Domyślnie
- określić
- definicje
- Stopień
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- wdrożenia
- Wnętrze
- proces projektowania
- pragnienie
- życzenia
- szczegółowe
- detale
- Wykrywanie
- Ustalać
- ustalona
- rozwijać
- Deweloper
- deweloperzy
- oprogramowania
- DICT
- różne
- cyfrowy
- Sztuka cyfrowa
- Inwalidztwo
- odkryj
- dyskryminacja
- dyskutować
- do
- robi
- Narkotyki
- Książę
- uniwersytet książęcy
- e
- każdy
- Wcześniej
- Wcześnie
- z łatwością
- Gospodarczy
- Ekosystem
- Edukacja
- ruchomości
- łatwy
- umożliwiać
- umożliwiając
- zachęcać
- zakończenia
- koniec końców
- Punkt końcowy
- Punkty końcowe
- zobowiązany
- inżynier
- Inżynieria
- zapewnić
- zapewnia
- Środowisko
- równy
- szczególnie
- Eter (ETH)
- etyczny
- oceny
- oceny
- evan
- wydarzenia
- przykład
- Z wyjątkiem
- wyjątek
- podniecony
- z pominięciem
- egzekucja
- Przede wszystkim system został opracowany
- drogi
- odkryj
- ekspresowy
- rozciągać się
- Twarz
- w obliczu
- fałszywy
- członków Twojej rodziny
- Wyposażony w
- kilka
- budżetowy
- przestępstwa finansowe
- Znajdź
- broń palna
- i terminów, a
- taflowy
- pływak
- Skupiać
- obserwuj
- następnie
- następujący
- następujący sposób
- W razie zamówieenia projektu
- format
- wychowanie
- Fundacja
- Darmowy
- od
- pełny
- Funkcje
- dalej
- przyszłość
- Płeć
- Ogólne
- Generować
- wygenerowane
- generuje
- generujący
- generacja
- generatywny
- generatywna sztuczna inteligencja
- otrzymać
- GitHub
- dany
- Dający
- Go
- będzie
- got
- większy
- Chciwy
- gwarancji
- osłona
- poradnictwo
- PISTOLETY
- zaszkodzić
- uprząż
- nienawidzić
- Have
- he
- Zdrowie
- pomoc
- pomaga
- jej
- tutaj
- wyższy
- turystyka
- jego
- historyczny
- hostowane
- W jaki sposób
- How To
- HTML
- HTTPS
- Piasta
- koncentratory
- i
- ICLR
- ID
- Identyfikacja
- tożsamość
- if
- Nielegalny
- Illinois
- natychmiast
- importować
- podnieść
- in
- zawierać
- obejmuje
- Włącznie z
- niezależny
- wskazać
- wskazuje
- wskazując,
- Informacja
- Informacyjna
- zakorzeniony
- początkowy
- inicjatywa
- Innowacja
- wkład
- Wejścia
- przykład
- instrukcje
- instrumentalny
- integrować
- zintegrowany
- zainteresowany
- zainteresowania
- Interfejs
- najnowszych
- z udziałem
- IT
- JEGO
- jpg
- Zabić
- Wiedzieć
- znany
- Kyle
- lądowanie
- strona docelowa
- język
- duży
- Nazwisko
- Laws
- Wyprowadzenia
- nauka
- pozostawiając
- Długość
- niech
- Licencja
- Upoważniony
- licencje
- lubić
- prawdopodobieństwo
- Prawdopodobnie
- lubi
- Ograniczony
- Linia
- linux
- Lista
- Słuchanie
- Lama
- miejscowy
- WYGLĄD
- niższy
- maszyna
- uczenie maszynowe
- utrzymać
- robić
- ręcznie
- zrobiony fabrycznie
- wiele
- mistrzowski
- Może..
- znaczenie
- środków
- Media
- psychika
- Zdrowie psychiczne
- wiadomość
- wiadomości
- Meta
- metoda
- metody
- może
- minuty
- łagodzenie
- mieszać
- ML
- model
- modele
- umiarkowanego
- umiar
- monitorowanie
- jeszcze
- większość
- Muzyka
- musi
- Musisz przeczytać
- narodowy
- potrzebne
- sieci
- Nerwowy
- sieci neuronowe
- NeuroIPS
- nigdy
- Nowości
- I Love New York
- nowy jork
- Następny
- Nie
- notatnik
- laptopy
- Zauważyć..
- już dziś
- numer
- przedmiot
- obserwując
- of
- oferuje
- on
- ONE
- tylko
- koncepcja
- otwarcie
- operacyjny
- Option
- Opcje
- or
- Origin
- Inne
- ludzkiej,
- na zewnątrz
- Wynik
- wydajność
- Wyjścia
- koniec
- własny
- własność
- strona
- Papier
- Papiery
- parametr
- parametry
- część
- szczególny
- strony
- przechodzić
- Przechodzący
- namiętny
- Ludzie
- dla
- wykonać
- wykonuje
- osoba
- osobisty
- PhD
- Równina
- krok po kroku
- planowanie
- plato
- Analiza danych Platona
- PlatoDane
- polityka
- Popularny
- pozytywny
- możliwy
- Post
- potencjał
- potencjalnie
- praktyki
- Urządzenie prognozujące
- przygotowanie
- przedstawione
- zapobiec
- Główny
- Priorytet
- prawdopodobieństwo
- wygląda tak
- procesów
- Produkt
- Produkcja
- projekt
- monity
- dobrobyt
- zapewniać
- pod warunkiem,
- dostawców
- zapewnia
- publicznie
- opublikowany
- Wydawniczy
- cele
- położyć
- Python
- płomień
- jakość
- szybko
- Wyścig
- przypadkowość
- zasięg
- raczej
- dosięgnąć
- Osiąga
- Czytaj
- Odebrane
- niedawny
- Zalecana
- odnosić się
- w sprawie
- regulowane
- regulamin
- związane z
- zwolnić
- religia
- powtórzony
- obsługi produkcji rolnej, która zastąpiła
- wywołań
- wymagany
- Badania naukowe
- badacz
- Zasoby
- poszanowanie
- odpowiadanie
- odpowiedź
- odpowiedzialny
- odpowiedzialnie
- REST
- dalsze
- Efekt
- powrót
- przeglądu
- Rosnąć
- Ryzyko
- ryzykowny
- mapa drogowa
- Rola
- role
- reguły
- run
- działa
- "bezpiecznym"
- zabezpieczenia
- Bezpieczeństwo
- sagemaker
- Wnioskowanie SageMakera
- skalowalny
- Skala
- nauka
- Naukowiec
- Sdk
- Szukaj
- poszukiwania
- druga
- Sekcja
- działy
- bezpieczne
- bezpieczeństwo
- widzieć
- wybierać
- senior
- wrażliwy
- wyrok
- uczucia
- Sekwencja
- Serie
- usługa
- Usługi
- zestaw
- Seksualny
- shared
- powinien
- pokazać
- pokazał
- seans
- pokazane
- pojedynczy
- najmniejszy
- So
- Obserwuj Nas
- Media społecznościowe
- Społeczeństwo
- Tworzenie
- Software Engineer
- rozwiązanie
- Rozwiązania
- specjalny
- specyficzny
- określony
- Spędzanie
- standardy
- rozpoczęty
- Startowy
- statystyczny
- statystyka
- Ewolucja krok po kroku
- Cel
- Nadal
- Zatrzymuje
- Strategiczny
- strategie
- studio
- udany
- taki
- Samobójstwa
- wsparcie
- podpory
- pewnie
- składnia
- system
- systemy
- Brać
- Zadanie
- zadania
- zespół
- szablon
- Szablony
- tensorflow
- REGULAMIN
- test
- przetestowany
- XNUMX
- generowanie tekstu
- niż
- że
- Połączenia
- Przyszłość
- Informacje
- kradzież
- ich
- Im
- sami
- następnie
- Tam.
- Te
- one
- Trzeci
- osoby trzecie
- innych firm
- to
- tych
- Przez
- czas
- Szereg czasowy
- do
- tytoń
- już dziś
- razem
- żeton
- Żetony
- narzędzie
- narzędzia
- tematy
- handel
- Pociąg
- przeszkolony
- Trening
- Tłumaczenie
- Podróżowanie
- prawdziwy
- Zaufaj
- próbować
- SKRĘCAĆ
- typy
- zazwyczaj
- ui
- Ostatecznie
- dla
- zrozumieć
- uniwersytet
- University of California
- odblokować
- aż do
- us
- Stosowanie
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- zastosowania
- za pomocą
- wartość
- Wartości
- różnorodność
- wersja
- Zobacz i wysłuchaj
- łamane
- Naruszać
- przemoc
- wizja
- wizualny
- spacer
- chcieć
- Droga..
- we
- Bronie
- sieć
- usługi internetowe
- Web-based
- Co
- jeśli chodzi o komunikację i motywację
- czy
- który
- KIM
- cały
- szeroki
- widget
- będzie
- chcieć
- w
- w ciągu
- bez
- słowo
- słowa
- Praca
- workflow
- pracujący
- by
- york
- ty
- Twój
- zefirnet