ZOO Cyfrowy zapewnia kompleksowe usługi lokalizacyjne i medialne w celu dostosowania oryginalnych treści telewizyjnych i filmowych do różnych języków, regionów i kultur. Ułatwia globalizację najlepszym twórcom treści na świecie. Zaufana przez największe nazwiska branży rozrywkowej, ZOO Digital zapewnia wysokiej jakości usługi lokalizacyjne i medialne na dużą skalę, w tym dubbing, napisy, tworzenie scenariuszy i zgodność.
Typowe procesy lokalizacji wymagają ręcznej diaryzacji mówcy, podczas której strumień audio jest segmentowany na podstawie tożsamości mówcy. Zanim będzie można skopiować treść na inny język, należy zakończyć ten czasochłonny proces. W przypadku metod ręcznych zlokalizowanie 30-minutowego odcinka może zająć od 1 do 3 godzin. Dzięki automatyzacji ZOO Digital dąży do lokalizacji w czasie krótszym niż 30 minut.
W tym poście omawiamy wdrażanie skalowalnych modeli uczenia maszynowego (ML) do tworzenia dzienników treści multimedialnych Amazon Sage Maker, z naciskiem na SzeptX model.
Tło
Wizją ZOO Digital jest zapewnienie szybszego przetwarzania zlokalizowanych treści. Cel ten jest utrudniony ze względu na intensywną ręczną naturę ćwiczeń, którą dodatkowo potęguje niewielka liczba wykwalifikowanych pracowników, którzy potrafią ręcznie zlokalizować treść. ZOO Digital współpracuje z ponad 11,000 600 freelancerów i tylko w 2022 r. zlokalizowało ponad XNUMX milionów słów. Jednakże podaż wykwalifikowanych pracowników jest przewyższana przez rosnące zapotrzebowanie na treści, co wymaga automatyzacji w celu wsparcia procesów lokalizacji.
Aby przyspieszyć lokalizację przepływów pracy z treścią poprzez uczenie maszynowe, firma ZOO Digital zaangażowała się w AWS Prototyping, program inwestycyjny AWS mający na celu wspólne tworzenie obciążeń z klientami. Zaangażowanie skupiało się na dostarczeniu funkcjonalnego rozwiązania dla procesu lokalizacji, przy jednoczesnym zapewnieniu praktycznych szkoleń dla programistów ZOO Digital w zakresie SageMaker, Amazon Transcribe, Tłumacz Amazon.
Wyzwanie klienta
Po dokonaniu transkrypcji tytułu (filmu lub odcinka serialu telewizyjnego) do każdego segmentu mowy należy przypisać głośniki, aby można było je poprawnie przypisać do lektorów, którzy mają odgrywać postacie. Proces ten nazywany jest diaryzacją mówcy. ZOO Digital stoi przed wyzwaniem diaryzowania treści na dużą skalę, przy jednoczesnym zachowaniu opłacalności ekonomicznej.
Omówienie rozwiązania
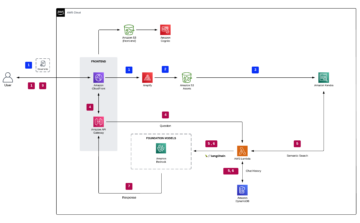
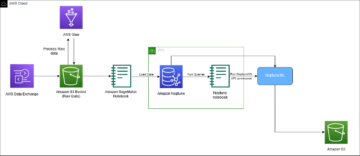
W tym prototypie oryginalne pliki multimedialne przechowywaliśmy w określonym formacie Usługa Amazon Simple Storage Łyżka (Amazon S3). Ten zasobnik S3 został skonfigurowany tak, aby emitował zdarzenie w przypadku wykrycia w nim nowych plików, wyzwalając błąd AWS Lambda funkcjonować. Instrukcje dotyczące konfigurowania tego wyzwalacza znajdują się w samouczku Użycie wyzwalacza Amazon S3 do wywołania funkcji Lambda. Następnie funkcja Lambda wywołała punkt końcowy SageMaker w celu wnioskowania za pomocą metody Klient wykonawczy Boto3 SageMaker.
Połączenia SzeptX model, na podstawie Szept OpenAI, wykonuje transkrypcje i diaryzację zasobów medialnych. Jest zbudowany na Szybszy szept ponowna implementacja, oferująca do czterech razy szybszą transkrypcję z poprawionym wyrównaniem znaczników czasu na poziomie słów w porównaniu do Whisper. Dodatkowo wprowadza diaryzację głośników, której nie było w oryginalnym modelu Whisper. WhisperX wykorzystuje model Whisper do transkrypcji, tzw Wav2Vec2 model poprawiający wyrównanie znaczników czasu (zapewniający synchronizację transkrybowanego tekstu ze znacznikami czasu dźwięku) oraz notatka model diaryzacji. FFmpeg służy do ładowania dźwięku z mediów źródłowych, obsługując różne formaty multimedialne. Przejrzysta i modułowa architektura modelu zapewnia elastyczność, ponieważ każdy element modelu można w przyszłości wymieniać w razie potrzeby. Należy jednak pamiętać, że WhisperX nie ma pełnych funkcji zarządzania i nie jest produktem na poziomie przedsiębiorstwa. Bez konserwacji i wsparcia może nie nadawać się do wdrożenia produkcyjnego.
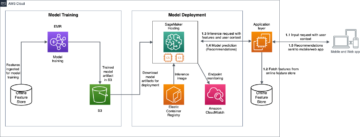
W ramach tej współpracy wdrożyliśmy i oceniliśmy WhisperX w SageMaker, używając asynchroniczny punkt końcowy wnioskowania gościć modelkę. Asynchroniczne punkty końcowe SageMaker obsługują przesyłanie plików o rozmiarze do 1 GB i zawierają funkcje automatycznego skalowania, które skutecznie łagodzą skoki ruchu i oszczędzają koszty poza godzinami szczytu. Asynchroniczne punkty końcowe szczególnie dobrze nadają się do przetwarzania dużych plików, takich jak filmy i seriale telewizyjne, w naszym przypadku.
Poniższy diagram ilustruje główne elementy eksperymentów, które przeprowadziliśmy w ramach tej współpracy.
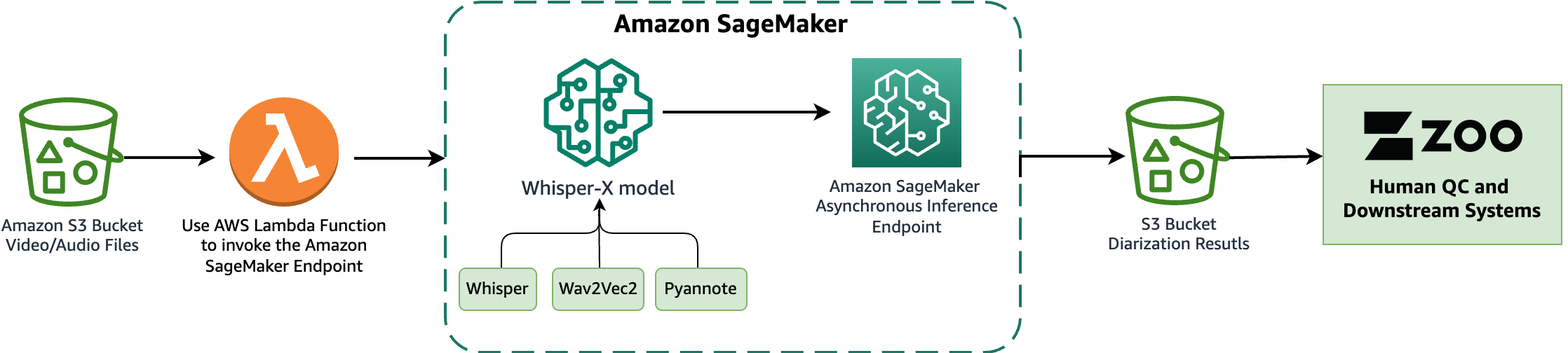
W kolejnych sekcjach zagłębiamy się w szczegóły wdrażania modelu WhisperX w SageMaker i oceniamy wydajność diaryzacji.
Pobierz model i jego komponenty
WhisperX to system zawierający wiele modeli transkrypcji, wymuszonego dopasowania i diaryzacji. Aby zapewnić płynne działanie programu SageMaker bez konieczności pobierania artefaktów modelu podczas wnioskowania, konieczne jest wstępne pobranie wszystkich artefaktów modelu. Artefakty te są następnie ładowane do kontenera obsługującego SageMaker podczas inicjacji. Ponieważ te modele nie są bezpośrednio dostępne, oferujemy opisy i przykładowy kod ze źródła WhisperX, dostarczając instrukcje dotyczące pobierania modelu i jego komponentów.
WhisperX wykorzystuje sześć modeli:
Większość tych modeli można nabyć m.in Przytulanie Twarzy za pomocą biblioteki huggingface_hub. Używamy poniższych download_hf_model() funkcję pobierania artefaktów modelu. Wymagany jest token dostępu od Hugging Face, wygenerowany po zaakceptowaniu umów użytkownika dla następujących modeli pyannote:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization" def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str: """ Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to :param model_name: HuggingFace model name (and an optional version, appended with @[version]) :param hf_token: HuggingFace access token authorized to access the requested model :param local_model_dir: The local directory to download the model to :return: The subdirectory within local_modeL_dir that the model is downloaded to """ model_subdir = model_name.split('@')[0] huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False) return model_subdir
Model VAD jest pobierany z Amazon S3, a model Wav2Vec2 jest pobierany z modułu torchaudio.pipelines. Na podstawie poniższego kodu możemy pobrać wszystkie artefakty modeli, w tym te z Hugging Face, i zapisać je w określonym lokalnym katalogu modeli:
def fetch_models(hf_token: str, local_model_dir="./models"): """ Fetches all required models to run WhisperX locally without downloading models every time :param hf_token: A huggingface access token to download the models :param local_model_dir: The directory to download the models to """ # Fetch Faster Whisper's Large V2 model from HuggingFace download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir) # Fetch WhisperX's VAD Segmentation model from S3 vad_model_dir = "whisperx/vad" if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"): os.makedirs(f"{local_model_dir}/{vad_model_dir}") urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin") # Fetch the Wav2Vec2 alignment model torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"}) # Fetch pyannote's Speaker Diarization model from HuggingFace download_hf_model(model_name=DIARIZATION_MODEL, hf_token=hf_token, local_model_dir=local_model_dir) # Read in the Speaker Diarization model config to fetch models and update with their local paths with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file: diarization_config = yaml.safe_load(file) embedding_model = diarization_config['pipeline']['params']['embedding'] embedding_model_dir = download_hf_model(model_name=embedding_model, hf_token=hf_token, local_model_dir=local_model_dir) diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}" segmentation_model = diarization_config['pipeline']['params']['segmentation'] segmentation_model_dir = download_hf_model(model_name=segmentation_model, hf_token=hf_token, local_model_dir=local_model_dir) diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin" with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file: yaml.safe_dump(diarization_config, file) # Read in the Speaker Embedding model config to update it with its local path speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml" with open(speechbrain_hyperparams_path, 'r') as file: speechbrain_hyperparams = file.read() speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}") with open(speechbrain_hyperparams_path, 'w') as file: file.write(speechbrain_hyperparams)
Wybierz odpowiedni kontener głębokiego uczenia się AWS do obsługi modelu
Po zapisaniu artefaktów modelu przy użyciu powyższego przykładowego kodu można wybrać wersję gotową Kontenery AWS Deep Learning (DLC) z poniższych GitHub repo. Wybierając obraz platformy Docker, należy wziąć pod uwagę następujące ustawienia: framework (Przytulająca twarz), zadanie (wnioskowanie), wersja języka Python i sprzęt (na przykład procesor graficzny). Zalecamy użycie następującego obrazu: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Na tym obrazie są preinstalowane wszystkie niezbędne pakiety systemowe, takie jak ffmpeg. Pamiętaj, aby zastąpić [REGION] regionem AWS, którego używasz.
W przypadku innych wymaganych pakietów Pythona utwórz plik requirements.txt plik z listą pakietów i ich wersjami. Pakiety te zostaną zainstalowane podczas kompilacji DLC AWS. Poniżej znajdują się dodatkowe pakiety potrzebne do hostowania modelu WhisperX w SageMaker:
Utwórz skrypt wnioskowania, aby załadować modele i uruchomić wnioskowanie
Następnie tworzymy niestandardowy inference.py skrypt opisujący sposób ładowania modelu WhisperX i jego komponentów do kontenera oraz sposobu uruchamiania procesu wnioskowania. Skrypt zawiera dwie funkcje: model_fn i transform_fn, model_fn funkcja jest wywoływana w celu załadowania modeli z ich odpowiednich lokalizacji. Następnie modele te są przekazywane do transform_fn funkcja podczas wnioskowania, podczas którego przeprowadzane są procesy transkrypcji, dopasowywania i diaryzacji. Poniżej znajduje się przykładowy kod dla inference.py:
import io
import json
import logging
import tempfile
import time import torch
import whisperx DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu' def model_fn(model_dir: str) -> dict: """ Deserialize and return the models """ logging.info("Loading WhisperX model") model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2", device=DEVICE, language="en", compute_type="float16", vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"}) logging.info("Loading alignment model") align_model, metadata = whisperx.load_align_model(language_code="en", device=DEVICE, model_name="WAV2VEC2_ASR_BASE_960H", model_dir=f"{model_dir}/wav2vec2") logging.info("Loading diarization model") diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml", device=DEVICE) return { 'model': model, 'align_model': align_model, 'metadata': metadata, 'diarization_model': diarization_model } def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str): """ Load in audio from the request, transcribe and diarize, and return JSON output """ # Start a timer so that we can log how long inference takes start_time = time.time() # Unpack the models whisperx_model = model['model'] align_model = model['align_model'] metadata = model['metadata'] diarization_model = model['diarization_model'] # Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it logging.info("Loading audio") with io.BytesIO(request_body) as file: tfile = tempfile.NamedTemporaryFile(delete=False) tfile.write(file.read()) audio = whisperx.load_audio(tfile.name) # Run transcription logging.info("Transcribing audio") result = whisperx_model.transcribe(audio, batch_size=16) # Align the outputs for better timings logging.info("Aligning outputs") result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False) # Run diarization logging.info("Running diarization") diarize_segments = diarization_model(audio) result = whisperx.assign_word_speakers(diarize_segments, result) # Calculate the time it took to perform the transcription and diarization end_time = time.time() elapsed_time = end_time - start_time logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds") # Return the results to be stored in S3 return json.dumps(result), response_content_type
W katalogu modelu, obok pliku requirements.txt plik, upewnij się, że jest obecny inference.py w podkatalogu kodu. The models katalog powinien wyglądać następująco:
Utwórz archiwum tar modeli
Po utworzeniu modeli i katalogów z kodem możesz użyć poniższych wierszy poleceń, aby skompresować model do pliku tar (plik .tar.gz) i przesłać go do Amazon S3. W chwili pisania tego tekstu, przy użyciu szybszego modelu Large V2, wynikowy plik tar reprezentujący model SageMaker ma rozmiar 3 GB. Aby uzyskać więcej informacji, zobacz Wzorce hostingu modeli w Amazon SageMaker, część 2: Pierwsze kroki z wdrażaniem modeli czasu rzeczywistego w SageMaker.
Utwórz model SageMaker i wdróż punkt końcowy z asynchronicznym predyktorem
Teraz możesz utworzyć model SageMaker, konfigurację punktu końcowego i asynchroniczny punkt końcowy za pomocą AsyncPredictor korzystając z modelu archiwum utworzonego w poprzednim kroku. Aby uzyskać instrukcje, zobacz Utwórz punkt końcowy wnioskowania asynchronicznego.
Oceń wydajność diaryzacji
Aby ocenić skuteczność diaryzacji modelu WhisperX w różnych scenariuszach, wybraliśmy po trzy odcinki każdy z dwóch angielskich tytułów: jeden tytuł dramatyczny składający się z 30-minutowych odcinków i jeden tytuł dokumentalny składający się z 45-minutowych odcinków. Wykorzystaliśmy zestaw narzędzi metrycznych pyannote, pyannote.metrics, aby obliczyć współczynnik błędów diaryzacji (DER). Za podstawową prawdę posłużyły w ocenie ręcznie przepisane i diarialne transkrypcje dostarczone przez ZOO.
Zdefiniowaliśmy DER w następujący sposób:

Kwota produktów: to długość filmu przedstawiającego prawdę. FA (Fałszywy alarm) to długość segmentów uznawanych za mowę w przewidywaniach, ale nie w oparciu o podstawową prawdę. Tęsknić to długość segmentów, które są uważane za mowę w podstawowej prawdzie, ale nie w przewidywaniu. Błąd, Zwany Zamieszanie, to długość segmentów przypisanych do różnych mówców w przewidywaniu i podstawowej prawdzie. Wszystkie jednostki są mierzone w sekundach. Typowe wartości DER mogą się różnić w zależności od konkretnego zastosowania, zbioru danych i jakości systemu diaryzacji. Należy pamiętać, że DER może być większy niż 1.0. Im niższy DER, tym lepiej.
Aby móc obliczyć DER dla fragmentu nośnika, wymagana jest diaryzacja prawdy podstawowej, a także transkrybowane i diaryzowane dane wyjściowe WhisperX. Muszą one zostać przeanalizowane i skutkować powstaniem list krotek zawierających etykietę mówiącego, czas rozpoczęcia segmentu mowy i czas zakończenia segmentu mowy dla każdego segmentu mowy w mediach. Etykiety głośników nie muszą pasować do diaryzacji WhisperX i podstawowej prawdy. Wyniki opierają się głównie na czasie segmentów. pyannote.metrics pobiera te krotki diaryzacji prawdy podstawowej i diaryzacji wyjściowej (określane w dokumentacji pyannote.metrics jako odniesienie i hipoteza) w celu obliczenia DER. Poniższa tabela podsumowuje nasze wyniki.
| Typ wideo | DER | Poprawny | Tęsknić | Błąd | Fałszywy alarm |
| Dramat | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Dokumentalny | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Średni | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Wyniki te ujawniają znaczną różnicę w wydajności między tytułami dramatu i filmów dokumentalnych, przy czym model osiągnął znacznie lepsze wyniki (stosując DER jako metrykę zbiorczą) dla odcinków dramatu w porównaniu z tytułem dokumentalnym. Bliższa analiza tytułów pozwala uzyskać wgląd w potencjalne czynniki przyczyniające się do tej luki w wydajności. Jednym z kluczowych czynników może być częste występowanie muzyki w tle nakładającej się na mowę w tytule dokumentu. Chociaż wstępne przetwarzanie multimediów w celu zwiększenia dokładności diaryzacji, np. usuwanie szumu tła w celu izolowania mowy, wykraczało poza zakres tego prototypu, otwiera ono możliwości przyszłych prac, które mogłyby potencjalnie zwiększyć wydajność WhisperX.
Wnioski
W tym poście omawialiśmy współpracę między AWS i ZOO Digital, wykorzystując techniki uczenia maszynowego z SageMaker i modelem WhisperX w celu usprawnienia przepływu pracy w diaryzacji. Zespół AWS odegrał kluczową rolę, pomagając ZOO w prototypowaniu, ocenie i zrozumieniu skutecznego wdrażania niestandardowych modeli ML, specjalnie zaprojektowanych do diaryzacji. Obejmowało to włączenie automatycznego skalowania w celu zapewnienia skalowalności za pomocą SageMaker.
Wykorzystanie sztucznej inteligencji do diaryzacji doprowadzi do znacznych oszczędności zarówno pod względem kosztów, jak i czasu podczas generowania zlokalizowanych treści dla ZOO. Pomagając osobom transkrybującym w szybkim i precyzyjnym tworzeniu i identyfikowaniu mówców, technologia ta rozwiązuje tradycyjnie czasochłonny i podatny na błędy charakter zadania. Konwencjonalny proces często obejmuje wielokrotne przejścia przez wideo i dodatkowe etapy kontroli jakości w celu zminimalizowania błędów. Zastosowanie sztucznej inteligencji do diaryzacji umożliwia bardziej ukierunkowane i wydajne podejście, zwiększając w ten sposób produktywność w krótszym czasie.
Opisaliśmy kluczowe kroki wdrażania modelu WhisperX na asynchronicznym punkcie końcowym SageMaker i zachęcamy do samodzielnego wypróbowania go przy użyciu dostarczonego kodu. Więcej informacji na temat usług i technologii ZOO Digital można znaleźć na stronie Oficjalna strona ZOO Digital. Aby uzyskać szczegółowe informacje na temat wdrażania modelu OpenAI Whisper w SageMaker i różnych opcjach wnioskowania, zobacz Hostuj model Whisper na Amazon SageMaker: odkrywanie opcji wnioskowania. Zachęcamy do dzielenia się swoimi przemyśleniami w komentarzach.
O autorach
 Doktor Ying Hou, jest architektem prototypowania opartym na uczeniu maszynowym w AWS. Jej główne obszary zainteresowań obejmują głębokie uczenie się, ze szczególnym uwzględnieniem GenAI, widzenia komputerowego, NLP i przewidywania danych szeregów czasowych. W wolnym czasie lubi spędzać wartościowe chwile z rodziną, zagłębiając się w powieściach i spacerując po parkach narodowych Wielkiej Brytanii.
Doktor Ying Hou, jest architektem prototypowania opartym na uczeniu maszynowym w AWS. Jej główne obszary zainteresowań obejmują głębokie uczenie się, ze szczególnym uwzględnieniem GenAI, widzenia komputerowego, NLP i przewidywania danych szeregów czasowych. W wolnym czasie lubi spędzać wartościowe chwile z rodziną, zagłębiając się w powieściach i spacerując po parkach narodowych Wielkiej Brytanii.
 Ethana Cumberlanda jest inżynierem ds. badań nad sztuczną inteligencją w ZOO Digital, gdzie pracuje nad wykorzystaniem sztucznej inteligencji i uczenia maszynowego jako technologii wspomagających w celu usprawnienia przepływów pracy w zakresie mowy, języka i lokalizacji. Ma doświadczenie w inżynierii oprogramowania i badaniach w dziedzinie bezpieczeństwa i policji, koncentrując się na wydobywaniu ustrukturyzowanych informacji z Internetu i wykorzystywaniu modeli uczenia maszynowego typu open source do analizowania i wzbogacania zebranych danych.
Ethana Cumberlanda jest inżynierem ds. badań nad sztuczną inteligencją w ZOO Digital, gdzie pracuje nad wykorzystaniem sztucznej inteligencji i uczenia maszynowego jako technologii wspomagających w celu usprawnienia przepływów pracy w zakresie mowy, języka i lokalizacji. Ma doświadczenie w inżynierii oprogramowania i badaniach w dziedzinie bezpieczeństwa i policji, koncentrując się na wydobywaniu ustrukturyzowanych informacji z Internetu i wykorzystywaniu modeli uczenia maszynowego typu open source do analizowania i wzbogacania zebranych danych.
 Gaurav Kaila kieruje zespołem AWS Prototyping dla Wielkiej Brytanii i Irlandii. Jego zespół współpracuje z klientami z różnych branż, aby opracowywać i współtworzyć obciążenia krytyczne dla biznesu, mając na celu przyspieszenie wdrażania usług AWS.
Gaurav Kaila kieruje zespołem AWS Prototyping dla Wielkiej Brytanii i Irlandii. Jego zespół współpracuje z klientami z różnych branż, aby opracowywać i współtworzyć obciążenia krytyczne dla biznesu, mając na celu przyspieszenie wdrażania usług AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 000
- 1
- 10
- 100
- 11
- 2%
- 2022
- 220
- 28
- 30
- 350
- 7
- 8
- a
- Zdolny
- przyśpieszyć
- akceptując
- dostęp
- dostępny
- precyzja
- Osiągać
- osiągnięcia
- w poprzek
- przystosować
- Dodatkowy
- do tego
- Adresy
- Przyjęcie
- Po
- agregat
- umowy
- AI
- ai badania
- zmierzać
- Cele
- alarm
- wyrównać
- justowanie
- wyrównanie
- Wszystkie kategorie
- pozwala
- sam
- wzdłuż
- również
- Chociaż
- Amazonka
- Amazon Sage Maker
- Amazon Web Services
- an
- analizowanie
- analiza
- i
- Inne
- Zastosowanie
- podejście
- właściwy
- architektura
- SĄ
- obszary
- Artyści
- AS
- oszacować
- Aktywa
- przydzielony
- pomagać
- pomoc
- At
- audio
- upoważniony
- samochód
- Automatyzacja
- aleje
- AWS
- tło
- na podstawie
- BE
- bo
- być
- zanim
- jest
- BEST
- Ulepsz Swój
- pomiędzy
- Poza
- Najwyższa
- BIN
- obie
- wybudowany
- biznes
- ale
- by
- bajtów
- obliczać
- nazywa
- CAN
- walizka
- wyzwanie
- znaków
- Dodaj
- bliższy
- kod
- współpraca
- współpracy
- gromadzone
- komentarze
- w porównaniu
- Zakończony
- spełnienie
- składnik
- składniki
- spotęgowane
- kompresować
- komputer
- Wizja komputerowa
- przeprowadzone
- skonfigurowany
- konfigurowanie
- Rozważać
- za
- Składający się
- Pojemnik
- zawierające
- zawiera
- zawartość
- twórcy treści
- przyczyniając
- kontrola
- Konwencjonalny
- rdzeń
- prawidłowo
- Koszty:
- Koszty:
- mógłby
- CPU
- Stwórz
- stworzony
- Tworzenie
- twórcy
- krytyczny
- Hodowle
- zwyczaj
- Klientów
- dane
- głęboko
- głęboka nauka
- def
- zdefiniowane
- dostarczanie
- dostarcza
- sięgać
- Kreowanie
- W zależności
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- zaprojektowany
- detale
- wykryte
- deweloperzy
- urządzenie
- schemat
- DICT
- różnica
- różne
- cyfrowy
- Cyfrowe
- bezpośrednio
- katalogi
- katalog
- dyskutować
- inny
- Doker
- dokumentalny
- dokumentacja
- domena
- nie
- pobieranie
- ściąganie
- Dramat
- dubbingowane
- podczas
- każdy
- łatwiej
- ekonomicznie
- Efektywne
- wydajny
- skutecznie
- Elementy
- więcej
- osadzanie
- zatrudniający
- Umożliwia
- objąć
- zachęcać
- zakończenia
- koniec końców
- Punkt końcowy
- Punkty końcowe
- zaangażowany
- zaręczynowy
- inżynier
- Inżynieria
- Angielski
- wzmacniać
- wzbogacanie
- zapewnić
- zapewnienie
- na poziomie przedsiębiorstwa
- rozrywka
- epizod
- Odcinki
- błąd
- Błędy
- niezbędny
- Eter (ETH)
- oceniać
- oceniane
- oceny
- ewaluację
- wydarzenie
- Każdy
- przykład
- Ćwiczenie
- eksperymenty
- zbadane
- Exploring
- Twarz
- twarze
- czynnik
- Czynniki
- fałszywy
- członków Twojej rodziny
- szybciej
- Korzyści
- czuć
- Pobrano
- filet
- Akta
- Elastyczność
- Skupiać
- koncentruje
- skupienie
- następujący
- następujący sposób
- W razie zamówieenia projektu
- wymuszony
- Formaty
- cztery
- Framework
- Darmowy
- częsty
- od
- pełny
- funkcjonować
- funkcjonalny
- Funkcje
- dalej
- przyszłość
- szczelina
- genialne
- wygenerowane
- generujący
- miejsce
- GitHub
- globalizacja
- cel
- GPU
- Ziemia
- hands-on
- sprzęt komputerowy
- he
- jej
- wysokiej jakości
- turystyka
- jego
- gospodarz
- Hosting
- GODZINY
- W jaki sposób
- Jednak
- HTML
- http
- HTTPS
- Przytulanie twarzy
- identyfikacja
- tożsamość
- if
- ilustruje
- obraz
- importować
- podnieść
- ulepszony
- in
- włączony
- obejmuje
- Włącznie z
- włączać
- włączenie
- wzrastający
- przemysłowa
- Informacja
- inicjacja
- spostrzeżenia
- zainstalowany
- instrukcje
- intensywny
- odsetki
- najnowszych
- Przedstawia
- inwestycja
- przywołany
- dotyczy
- Irlandia
- IT
- JEGO
- jpg
- json
- Klawisz
- kluczowy czynnik
- Etykieta
- Etykiety
- brak
- język
- Języki
- duży
- większe
- prowadzić
- Wyprowadzenia
- nauka
- Długość
- lewarowanie
- Biblioteka
- linie
- Lista
- wykazy
- załadować
- załadunek
- miejscowy
- Localization
- lokalnie
- lokalizacji
- log
- zalogowaniu
- długo
- niższy
- maszyna
- uczenie maszynowe
- Techniki uczenia maszynowego
- konserwacja
- WYKONUJE
- i konserwacjami
- Mandat
- podręcznik
- ręcznie
- Mecz
- Może..
- mierzona
- Media
- Metadane
- metody
- metryczny
- Metryka
- milion
- zminimalizować
- minuty
- Złagodzić
- ML
- model
- modele
- Modułowa
- moduł
- Chwile
- jeszcze
- przeważnie
- film
- Kino
- wielokrotność
- Muzyka
- musi
- Nazwa
- Nazwy
- narodowy
- parki narodowe
- Natura
- niezbędny
- Potrzebować
- potrzebne
- Nowości
- nlp
- Hałas
- szczególnie
- noty
- uzyskane
- of
- oferta
- oferuje
- urzędnik
- często
- on
- ONE
- open source
- OpenAI
- otwiera
- działanie
- Opcje
- or
- oryginalny
- OS
- Inne
- ludzkiej,
- na zewnątrz
- zarys
- opisane
- wydajność
- Wyjścia
- koniec
- Pakiety
- parki
- część
- szczególnie
- Współpraca
- minęło
- przebiegi
- ścieżka
- ścieżki
- wzory
- Ludzie
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywane
- wykonuje
- kawałek
- rurociąg
- kluczowy
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- grał
- policja
- Post
- potencjał
- potencjalnie
- precyzyjnie
- przepowiednia
- Przewidywania
- obecność
- teraźniejszość
- poprzedni
- pierwotny
- wygląda tak
- procesów
- przetwarzanie
- Produkt
- Produkcja
- wydajność
- Program
- prototyp
- prototypowanie
- zapewniać
- pod warunkiem,
- zapewnia
- że
- Python
- jakość
- R
- Kurs
- Czytaj
- real
- w czasie rzeczywistym
- polecić
- odnosić się
- , o którym mowa
- region
- regiony
- pamiętać
- usuwanie
- obsługi produkcji rolnej, która zastąpiła
- reprezentowanie
- zażądać
- wniosek
- wymagać
- wymagany
- wymagania
- Badania naukowe
- osób
- dalsze
- wynikły
- Efekt
- powrót
- powraca
- ujawniać
- Rola
- run
- bieganie
- Czas
- s
- sagemaker
- próba
- Zapisz
- zapisywane
- Oszczędności
- Skalowalność
- skalowalny
- Skala
- skalowaniem
- scenariusze
- zakres
- scenariusz
- sekund
- działy
- bezpieczeństwo
- segment
- segmentacja
- Segmenty
- wybrany
- wybierając
- Serie
- służył
- Usługi
- służąc
- w panelu ustawień
- Share
- ona
- powinien
- znaczący
- Prosty
- SIX
- Rozmiar
- rozmiary
- wykwalifikowany
- mały
- gładki
- So
- Tworzenie
- Inżynieria oprogramowania
- rozwiązanie
- Źródło
- Głośnik
- Głośniki
- specyficzny
- swoiście
- określony
- przemówienie
- Spędzanie
- kolce
- początek
- rozpoczęty
- Ewolucja krok po kroku
- Cel
- przechowywanie
- przechowywany
- Historia
- strumień
- opływowy
- zbudowany
- Następnie
- znaczny
- taki
- odpowiedni
- Dostawa
- wsparcie
- Wspierający
- zamienione
- szybko
- synchronizacja
- system
- stół
- Brać
- trwa
- ukierunkowane
- Zadanie
- zespół
- Techniki
- Technologies
- Technologia
- tymczasowy
- XNUMX
- niż
- że
- Połączenia
- Przyszłość
- bezpieczeństwa
- UK
- ich
- Im
- następnie
- a tym samym
- Te
- one
- to
- tych
- trzy
- Przez
- czas
- Szereg czasowy
- czasochłonne
- ramy czasowe
- czasy
- znak czasu
- czasy
- Tytuł
- tytuły
- do
- żeton
- wziął
- Zestaw narzędzi
- pochodnia
- tradycyjnie
- ruch drogowy
- Trening
- przezroczysty
- wyzwalać
- wyzwalanie
- zaufany
- Prawda
- próbować
- Tutorial
- tv
- Seriale TV
- drugiej
- typowy
- Uk
- dla
- pod 30
- zrozumienie
- jednostek
- Aktualizacja
- na
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- zastosowania
- za pomocą
- wykorzystany
- wykorzystuje
- Wartości
- różnorodny
- różnią się
- wersja
- Wersje
- wykonalne
- Wideo
- wizja
- Odwiedzić
- Głos
- W
- była
- we
- sieć
- usługi internetowe
- DOBRZE
- jeśli chodzi o komunikację i motywację
- Podczas
- Szept
- będzie
- w
- w ciągu
- bez
- słowa
- Praca
- workflow
- przepływów pracy
- Siła robocza
- działa
- świat
- pisanie
- jamla
- ty
- Twój
- siebie
- zefirnet
- ZOO