To jest post gościnny napisany wspólnie z zespołem kierowniczym Iambic Therapeutics.
Terapeutyka jambiczna to startup zajmujący się odkrywaniem leków, którego misją jest tworzenie innowacyjnych technologii opartych na sztucznej inteligencji, aby szybciej dostarczać lepsze leki pacjentom chorym na raka.
Nasze zaawansowane narzędzia sztucznej inteligencji generatywnej i predykcyjnej (AI) pozwalają nam szybciej i skuteczniej przeszukiwać ogromną przestrzeń możliwych cząsteczek leków. Nasze technologie są wszechstronne i mają zastosowanie w obszarach terapeutycznych, klasach białek i mechanizmach działania. Oprócz tworzenia zróżnicowanych narzędzi sztucznej inteligencji stworzyliśmy zintegrowaną platformę, która łączy oprogramowanie sztucznej inteligencji, dane w chmurze, skalowalną infrastrukturę obliczeniową oraz wysokoprzepustowe możliwości w zakresie chemii i biologii. Platforma zarówno umożliwia korzystanie z naszej sztucznej inteligencji – dostarczając dane w celu udoskonalenia naszych modeli – jak i umożliwia ją dzięki niej, wykorzystując możliwości zautomatyzowanego podejmowania decyzji i przetwarzania danych.
Miarą sukcesu jest nasza zdolność do tworzenia doskonałych kandydatów klinicznych, odpowiadających pilnym potrzebom pacjentów, z niespotykaną dotąd szybkością: od uruchomienia programu do kandydatów klinicznych przeszliśmy w zaledwie 24 miesiące, znacznie szybciej niż nasi konkurenci.
W tym poście skupiamy się na tym, jak używaliśmy Stolarz on Elastyczna usługa Amazon Kubernetes (Amazon EKS) w celu skalowania uczenia i wnioskowania AI, które są głównymi elementami platformy odkrywania Iambic.
Potrzeba skalowalnego szkolenia i wnioskowania w zakresie sztucznej inteligencji
Co tydzień Iambic przeprowadza wnioskowanie AI na dziesiątkach modeli i milionach cząsteczek, obsługując dwa główne przypadki użycia:
- Chemicy medyczni i inni naukowcy korzystają z naszej aplikacji internetowej Insight do badania przestrzeni chemicznej, uzyskiwania dostępu do danych eksperymentalnych i ich interpretacji oraz przewidywania właściwości nowo zaprojektowanych cząsteczek. Cała ta praca jest wykonywana interaktywnie w czasie rzeczywistym, co stwarza potrzebę wnioskowania przy małych opóźnieniach i średniej przepustowości.
- Jednocześnie nasze generatywne modele sztucznej inteligencji automatycznie projektują cząsteczki mające na celu ulepszenie wielu właściwości, wyszukujące miliony kandydatów i wymagające ogromnej przepustowości i średniego opóźnienia.
Kierując się technologiami sztucznej inteligencji i ekspertami w dziedzinie poszukiwania leków, nasza platforma eksperymentalna generuje co tydzień tysiące unikalnych cząsteczek, a każda z nich jest poddawana wielu testom biologicznym. Wygenerowane punkty danych są co tydzień automatycznie przetwarzane i wykorzystywane do dostrajania naszych modeli AI. Początkowo dostrajanie naszego modelu zajmowało wiele godzin czasu procesora, dlatego konieczne było stworzenie platformy do dostrajania modelu skalowania na procesorach graficznych.
Nasze modele głębokiego uczenia się mają nietrywialne wymagania: mają gigabajtowy rozmiar, są liczne i niejednorodne oraz wymagają procesorów graficznych do szybkiego wnioskowania i dostrajania. Jeśli chodzi o infrastrukturę chmurową, potrzebowaliśmy systemu, który umożliwiłby nam dostęp do procesorów graficznych, szybkie skalowanie w górę i w dół w celu obsługi gwałtownych, heterogenicznych obciążeń i uruchamianie dużych obrazów platformy Docker.
Chcieliśmy zbudować skalowalny system wspierający szkolenie i wnioskowanie AI. Korzystamy z Amazon EKS i szukaliśmy najlepszego rozwiązania do automatycznego skalowania naszych węzłów roboczych. Wybraliśmy Karpentera do automatycznego skalowania węzłów Kubernetes z kilku powodów:
- Łatwość integracji z Kubernetesem, wykorzystanie semantyki Kubernetes do definiowania wymagań węzłów i specyfikacji podów na potrzeby skalowania
- Skalowanie w poziomie węzłów z niskim opóźnieniem
- Łatwość integracji z naszą infrastrukturą w postaci narzędzi kodowych (Terraform)
Dostawcy węzłów obsługują bezproblemową integrację z Amazon EKS i innymi zasobami AWS, takimi jak Elastyczna chmura obliczeniowa Amazon (Amazon EC2) instancje i Sklep Amazon Elastic Block wolumeny. Semantyka Kubernetes używana przez dostawców usług obsługuje ukierunkowane planowanie przy użyciu konstrukcji Kubernetes, takich jak skażenia lub tolerancje oraz specyfikacje powinowactwa lub przeciwdziałania powinowactwu; ułatwiają także kontrolę nad liczbą i rodzajami instancji GPU, które Karpenter może zaplanować.
Omówienie rozwiązania
W tej sekcji przedstawiamy ogólną architekturę podobną do tej, której używamy w przypadku naszych własnych obciążeń, która umożliwia elastyczne wdrażanie modeli przy użyciu wydajnego automatycznego skalowania w oparciu o niestandardowe metryki.
Poniższy schemat ilustruje architekturę rozwiązania.
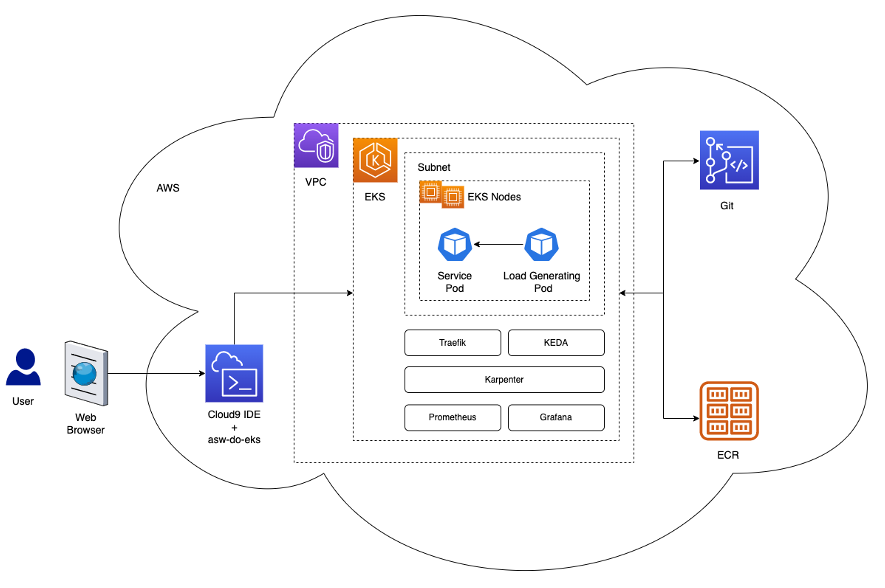
Architektura wdraża a prosta obsługa w pod Kubernetes w pliku Klaster EKS. Może to być wnioskowanie o modelu, symulacja danych lub dowolna inna usługa kontenerowa dostępna za pomocą żądania HTTP. Usługa jest udostępniana za pomocą odwrotnego proxy Traefik. Odwrotne proxy zbiera metryki dotyczące wywołań usługi i udostępnia je za pośrednictwem standardowego interfejsu API metryk Prometheus. Autoskaler sterowany zdarzeniami Kubernetes (KEDA) jest skonfigurowany tak, aby automatycznie skalować liczbę zasobników usług na podstawie niestandardowych metryk dostępnych w Prometheusie. Tutaj używamy liczby żądań na sekundę jako niestandardowej metryki. To samo podejście architektoniczne ma zastosowanie, jeśli wybierzesz inną metrykę dla swojego obciążenia.
Karpenter monitoruje wszystkie oczekujące pody, które nie mogą działać z powodu braku wystarczających zasobów w klastrze. W przypadku wykrycia takich podów Karpenter dodaje do klastra więcej węzłów, aby zapewnić niezbędne zasoby. I odwrotnie, jeśli w klastrze jest więcej węzłów niż potrzeba zaplanowanych podów, Karpenter usuwa niektóre węzły robocze, a harmonogram podów zostaje zmieniony, konsolidując je w mniejszej liczbie instancji. Liczbę żądań HTTP na sekundę i liczbę węzłów można wizualizować za pomocą a grafana panel. Aby zademonstrować automatyczne skalowanie, uruchamiamy jeden lub więcej proste kapsuły generujące obciążenie, które wysyłają żądania HTTP do usługi za pomocą curl.
Wdrożenie rozwiązania
W opis krok po kroku, Używamy Chmura AWS9 jako środowisko do wdrożenia architektury. Dzięki temu wszystkie kroki można wykonać z poziomu przeglądarki internetowej. Rozwiązanie można także wdrożyć z komputera lokalnego lub instancji EC2.
Aby uprościć wdrażanie i poprawić powtarzalność, przestrzegamy zasad framework do zrobienia i strukturę szablon zależności od okna dokowanego. Klonujemy aws-do-eks projekt i użycie Doker, budujemy obraz kontenera, który jest wyposażony w niezbędne narzędzia i skrypty. W kontenerze przechodzimy przez wszystkie etapy kompleksowego przewodnika, od utworzenia klastra EKS za pomocą Karpentera po skalowanie Instancje EC2.
W przykładzie w tym poście używamy następującego Manifest klastra EKS:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: do-eks-yaml-karpenter
version: '1.28'
region: us-west-2
tags:
karpenter.sh/discovery: do-eks-yaml-karpenter
iam:
withOIDC: true
addons:
- name: aws-ebs-csi-driver
version: v1.26.0-eksbuild.1
wellKnownPolicies:
ebsCSIController: true
managedNodeGroups:
- name: c5-xl-do-eks-karpenter-ng
instanceType: c5.xlarge
instancePrefix: c5-xl
privateNetworking: true
minSize: 0
desiredCapacity: 2
maxSize: 10
volumeSize: 300
iam:
withAddonPolicies:
cloudWatch: true
ebs: trueTen manifest definiuje klaster o nazwie do-eks-yaml-karpenter ze sterownikiem EBS CSI zainstalowanym jako dodatek. Zarządzana grupa węzłów z dwoma c5.xlarge nodes jest dołączony do uruchamiania zasobników systemowych potrzebnych w klastrze. Węzły robocze są hostowane w podsieciach prywatnych, a punkt końcowy interfejsu API klastra jest domyślnie publiczny.
Zamiast tworzyć klaster, możesz także użyć istniejącego klastra EKS. Wdrażamy Karpentera, postępując zgodnie z instrukcje w dokumentacji Karpentera lub uruchamiając poniższe polecenie scenariusz, co automatyzuje instrukcje wdrażania.
Poniższy kod przedstawia konfigurację Karpentera, której używamy w tym przykładzie:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
metadata: null
labels:
cluster-name: do-eks-yaml-karpenter
annotations:
purpose: karpenter-example
spec:
nodeClassRef:
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
name: default
requirements:
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
- on-demand
- key: karpenter.k8s.aws/instance-category
operator: In
values:
- c
- m
- r
- g
- p
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values:
- '2'
disruption:
consolidationPolicy: WhenUnderutilized
#consolidationPolicy: WhenEmpty
#consolidateAfter: 30s
expireAfter: 720h
---
apiVersion: karpenter.k8s.aws/v1beta1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "do-eks-yaml-karpenter"
role: "KarpenterNodeRole-do-eks-yaml-karpenter"
tags:
app: autoscaling-test
blockDeviceMappings:
- deviceName: /dev/xvda
ebs:
volumeSize: 80Gi
volumeType: gp3
iops: 10000
deleteOnTermination: true
throughput: 125
detailedMonitoring: trueDefiniujemy domyślny Karpenter NodePool z następującymi wymaganiami:
- Karpenter może uruchamiać instancje z obu
spotion-demandpule pojemności - Instancje muszą pochodzić z „
c” (zoptymalizowany pod kątem obliczeń), „m" (ogólny cel), "r” (zoptymalizowana pod kątem pamięci) lub „g"I"p” (akcelerowane przez GPU) rodziny obliczeniowe - Generowanie instancji musi być większe niż 2; Na przykład,
g3jest do przyjęcia, aleg2nie jest
Domyślna pula NodePool definiuje również zasady dotyczące zakłóceń. Niewykorzystane węzły zostaną usunięte, aby można było skonsolidować pody tak, aby działały na mniejszej liczbie lub mniejszych węzłach. Alternatywnie możemy skonfigurować usuwanie pustych węzłów po określonym czasie. The expireAfter ustawienie określa maksymalny czas życia dowolnego węzła, zanim zostanie on zatrzymany i wymieniony, jeśli to konieczne. Pomaga to zmniejszyć luki w zabezpieczeniach, a także uniknąć problemów typowych dla węzłów o długim czasie pracy, takich jak fragmentacja plików lub wycieki pamięci.
Domyślnie Karpenter udostępnia węzłom mały wolumin główny, który może być niewystarczający do obsługi obciążeń AI lub uczenia maszynowego (ML). Niektóre obrazy kontenerów uczenia głębokiego mogą mieć rozmiar kilkudziesięciu GB i musimy się upewnić, że w węzłach jest wystarczająca ilość miejsca, aby uruchomić pody przy użyciu tych obrazów. Aby to zrobić, definiujemy EC2NodeClass w blockDeviceMappings, jak pokazano w poprzednim kodzie.
Karpenter odpowiada za automatyczne skalowanie na poziomie klastra. Aby skonfigurować automatyczne skalowanie na poziomie poda, używamy KEDA do zdefiniowania niestandardowego zasobu o nazwie ScaledObject, jak pokazano w następującym kodzie:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: keda-prometheus-hpa
namespace: hpa-example
spec:
scaleTargetRef:
name: php-apache
minReplicaCount: 1
cooldownPeriod: 30
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus- server.prometheus.svc.cluster.local:80
metricName: http_requests_total
threshold: '1'
query: rate(traefik_service_requests_total{service="hpa-example-php-apache-80@kubernetes",code="200"}[2m])Powyższy manifest definiuje a ScaledObject o imieniu keda-prometheus-hpa, który jest odpowiedzialny za skalowanie wdrożenia php-apache i zawsze utrzymuje działającą co najmniej jedną replikę. Skaluje zasobniki tego wdrożenia na podstawie metryki http_requests_total dostępne w Prometheusie uzyskane przez określone zapytanie i cele skalowania podów, tak aby każdy pod obsługiwał nie więcej niż jedno żądanie na sekundę. Skaluje repliki w dół, gdy obciążenie żądania znajduje się poniżej progu przez dłużej niż 30 sekund.
Połączenia specyfikacja wdrożenia w naszym przykładzie usługa zawiera następujące elementy żądania zasobów i limity:
resources:
limits:
cpu: 500m
nvidia.com/gpu: 1
requests:
cpu: 200m
nvidia.com/gpu: 1W tej konfiguracji każdy z podów usługowych będzie korzystał z dokładnie jednego procesora graficznego NVIDIA. Po utworzeniu nowych podów będą one w stanie Oczekujące, dopóki procesor graficzny nie będzie dostępny. Karpenter dodaje węzły GPU do klastra w miarę potrzeb, aby pomieścić oczekujące zasobniki.
A kapsuła generująca obciążenie wysyła do usługi żądania HTTP z ustaloną częstotliwością. Zwiększamy liczbę żądań zwiększając liczbę replik w pliku wdrożenie generatora obciążenia.
Pełny cykl skalowania z konsolidacją węzłów opartą na wykorzystaniu jest wizualizowany na pulpicie nawigacyjnym Grafana. Poniższy pulpit nawigacyjny przedstawia liczbę węzłów w klastrze według typu instancji (na górze), liczbę żądań na sekundę (na dole po lewej) i liczbę zasobników (na dole po prawej).
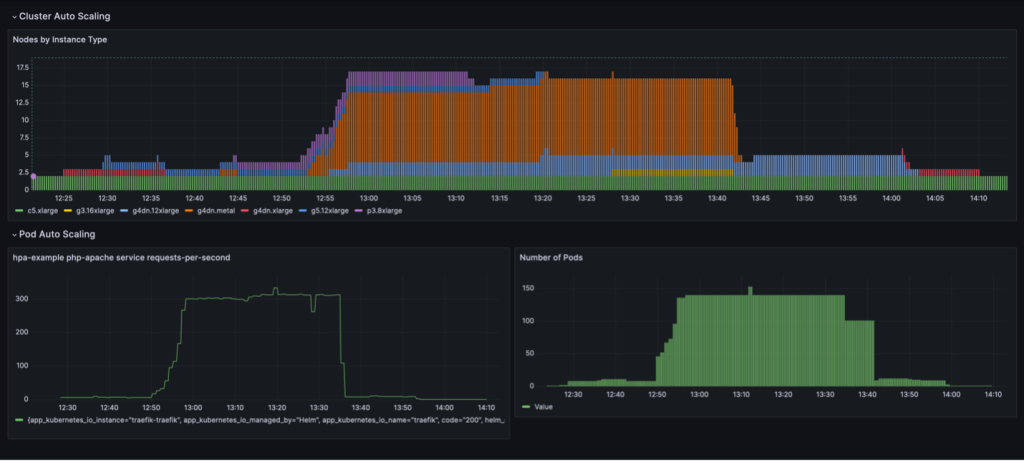
Zaczynamy od dwóch instancji procesora c5.xlarge, z którymi utworzono klaster. Następnie wdrażamy jedną instancję usługi, która wymaga pojedynczego procesora graficznego. Aby sprostać tym potrzebom, Karpenter dodaje instancję g4dn.xlarge. Następnie wdrażamy generator obciążenia, co powoduje, że KEDA dodaje więcej podów usług, a Karpenter dodaje więcej instancji GPU. Po optymalizacji stan ustala się na jednej instancji p3.8xlarge z 8 procesorami graficznymi i jednej instancji g5.12xlarge z 4 procesorami graficznymi.
Kiedy skalujemy wdrożenie generujące obciążenie do 40 replik, KEDA tworzy dodatkowe zasobniki usług, aby utrzymać wymagane obciążenie żądań na pod. Karpenter dodaje do klastra węzły g4dn.metal i g4dn.12xlarge, aby zapewnić procesory graficzne potrzebne dla dodatkowych podów. W stanie skalowanym klaster zawiera 16 węzłów GPU i obsługuje około 300 żądań na sekundę. Kiedy skalujemy generator obciążenia do 1 repliki, zachodzi proces odwrotny. Po okresie przestoju KEDA zmniejsza liczbę kapsuł serwisowych. Następnie, gdy działa mniej podów, Karpenter usuwa z klastra niewykorzystane węzły, a pody usług są konsolidowane, aby działać na mniejszej liczbie węzłów. Po usunięciu modułu generatora obciążenia pojedynczy moduł usługi w pojedynczej instancji g4dn.xlarge z 1 procesorem graficznym pozostaje uruchomiony. Gdy usuniemy również moduł serwisowy, klaster pozostanie w stanie początkowym z tylko dwoma węzłami procesora.
Możemy zaobserwować to zachowanie, gdy NodePool ma ustawienie consolidationPolicy: WhenUnderutilized.
Dzięki temu ustawieniu Karpenter dynamicznie konfiguruje klaster z jak najmniejszą liczbą węzłów, zapewniając jednocześnie wystarczające zasoby do działania wszystkich podów, a także minimalizując koszty.
Zachowanie skalowania pokazane na poniższym pulpicie nawigacyjnym jest obserwowane, gdy NodePool zasada konsolidacji jest ustawiona na WhenEmptyWraz z consolidateAfter: 30s.
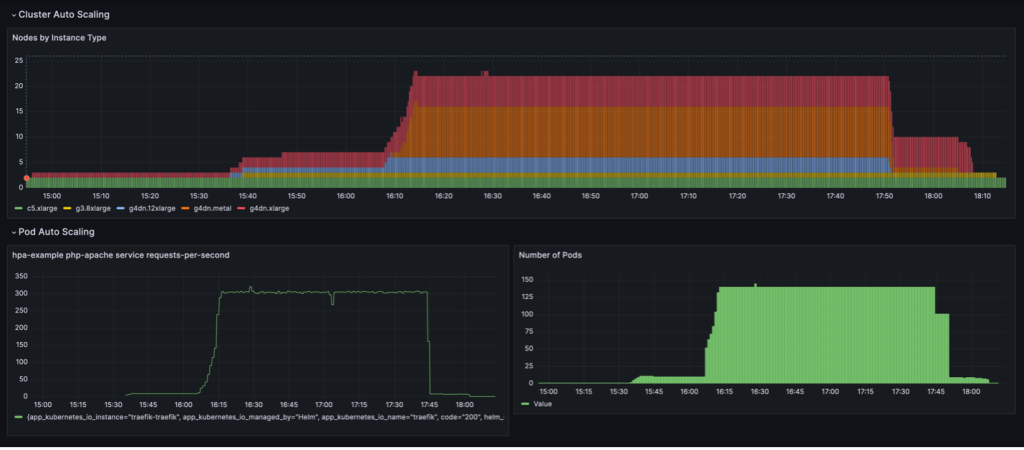
W tym scenariuszu węzły są zatrzymywane tylko wtedy, gdy po okresie przestoju nie działają na nich żadne zasobniki. Krzywa skalowania wydaje się gładka w porównaniu z polityką konsolidacji opartej na wykorzystaniu; można jednak zauważyć, że w stanie skalowanym wykorzystuje się więcej węzłów (22 vs. 16).
Ogólnie rzecz biorąc, połączenie automatycznego skalowania podów i klastrów zapewnia dynamiczne skalowanie klastra w zależności od obciążenia, alokując zasoby w razie potrzeby i usuwając je, gdy nie są używane, maksymalizując w ten sposób wykorzystanie i minimalizując koszty.
Wyniki
Iambic wykorzystał tę architekturę, aby umożliwić efektywne wykorzystanie procesorów graficznych w AWS i migrację obciążeń z procesora na procesor graficzny. Korzystając z instancji zasilanych procesorem graficznym EC2, Amazon EKS i Karpenter, mogliśmy umożliwić szybsze wnioskowanie dla naszych modeli opartych na fizyce i krótsze czasy iteracji eksperymentów dla naukowców stosowanych, którzy polegają na szkoleniu jako usłudze.
W poniższej tabeli podsumowano niektóre metryki czasu tej migracji.
| Zadanie | procesory | GPU |
| Wnioskowanie z wykorzystaniem modeli dyfuzyjnych dla modeli ML opartych na fizyce | 3,600 sekund |
100 sekund (ze względu na nieodłączne grupowanie procesorów graficznych) |
| Szkolenie modelowe ML jako usługa | 180 minut | 4 minut |
W poniższej tabeli podsumowano niektóre nasze wskaźniki czasu i kosztów.
| Zadanie | Wydajność/koszt | |
| procesory | GPU | |
| Trening modelu ML |
240 minut średnio 0.70 USD za zadanie szkoleniowe |
20 minut średnio 0.38 USD za zadanie szkoleniowe |
Podsumowanie
W tym poście pokazaliśmy, jak Iambic wykorzystał Karpenter i KEDA do skalowania naszej infrastruktury Amazon EKS, aby spełnić wymagania dotyczące opóźnień naszych obciążeń wnioskowania i szkolenia AI. Karpenter i KEDA to potężne narzędzia typu open source, które pomagają w automatycznym skalowaniu klastrów EKS i działających na nich obciążeń. Pomaga to zoptymalizować koszty obliczeń przy jednoczesnym spełnieniu wymagań dotyczących wydajności. Możesz sprawdzić kod i wdrożyć tę samą architekturę we własnym środowisku, postępując zgodnie z pełnym przewodnikiem w tym temacie GitHub repo.
O autorach
 Mateusz Welborn jest dyrektorem ds. uczenia maszynowego w Iambic Therapeutics. On i jego zespół wykorzystują sztuczną inteligencję do przyspieszenia identyfikacji i opracowywania nowatorskich terapii, dzięki czemu szybciej dostarczają pacjentom leki ratujące życie.
Mateusz Welborn jest dyrektorem ds. uczenia maszynowego w Iambic Therapeutics. On i jego zespół wykorzystują sztuczną inteligencję do przyspieszenia identyfikacji i opracowywania nowatorskich terapii, dzięki czemu szybciej dostarczają pacjentom leki ratujące życie.
 Paula Whitemore’a jest głównym inżynierem w Iambic Therapeutics. Wspiera dostawę infrastruktury dla platformy odkrywania leków opartej na sztucznej inteligencji Iambic.
Paula Whitemore’a jest głównym inżynierem w Iambic Therapeutics. Wspiera dostawę infrastruktury dla platformy odkrywania leków opartej na sztucznej inteligencji Iambic.
 Aleks Iankoulski jest głównym architektem rozwiązań w ML/AI Frameworks, który koncentruje się na pomaganiu klientom w koordynowaniu obciążeń AI przy użyciu kontenerów i przyspieszonej infrastruktury obliczeniowej w AWS.
Aleks Iankoulski jest głównym architektem rozwiązań w ML/AI Frameworks, który koncentruje się na pomaganiu klientom w koordynowaniu obciążeń AI przy użyciu kontenerów i przyspieszonej infrastruktury obliczeniowej w AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/scale-ai-training-and-inference-for-drug-discovery-through-amazon-eks-and-karpenter/
- :ma
- :Jest
- :nie
- ][P
- $W GÓRĘ
- 1
- 10
- 100
- 10000
- 125
- 16
- 2%
- 200
- 200m
- 22
- 24
- 26
- 28
- 30
- 300
- 4
- 40
- 5
- 6
- 70
- 8
- 80
- a
- zdolność
- Zdolny
- O nas
- przyśpieszyć
- przyśpieszony
- do przyjęcia
- dostęp
- dostępny
- pomieścić
- w poprzek
- Działania
- Dodaj
- Dodatek
- Dodatkowy
- adres
- Dodaje
- zaawansowany
- powinowactwo
- Po
- AI
- Modele AI
- Trening AI
- Wszystkie kategorie
- pozwala
- wzdłuż
- również
- zawsze
- Amazonka
- Amazon EC2
- Amazon Web Services
- an
- i
- każdy
- api
- Aplikacja
- pojawia się
- odpowiedni
- Zastosowanie
- stosowany
- dotyczy
- podejście
- architektoniczny
- architektura
- SĄ
- obszary
- sztuczny
- sztuczna inteligencja
- Sztuczna inteligencja (AI)
- AS
- At
- samochód
- zautomatyzowane
- automaty
- automatycznie
- dostępny
- uniknąć
- AWS
- na podstawie
- partie
- BE
- być
- zanim
- zachowanie
- za
- poniżej
- BEST
- Ulepsz Swój
- Poza
- biologia
- Blokować
- obie
- Dolny
- przynieść
- Bringing
- przeglądarka
- budować
- ale
- by
- nazywa
- Połączenia
- CAN
- Rak
- chorych na raka
- kandydatów
- możliwości
- Pojemność
- wielkie litery
- Etui
- Przyczyny
- ZOBACZ
- chemiczny
- chemia
- Apteka
- Dodaj
- wybrał
- Klasy
- Kliniczne
- Chmura
- infrastruktura chmurowa
- Grupa
- kod
- zbiera
- łączenie
- w porównaniu
- konkurenci
- kompletny
- Zakończony
- obliczenia
- obliczać
- komputer
- computing
- systemu
- skonfigurowany
- konsolidacja
- konsolidacja
- konstrukty
- Pojemnik
- Pojemniki
- zawiera
- kontrola
- odwrotnie
- rdzeń
- Koszty:
- Koszty:
- mógłby
- CPU
- Stwórz
- stworzony
- tworzy
- Tworzenie
- CSI
- krzywa
- zwyczaj
- Klientów
- cykl
- tablica rozdzielcza
- dane
- punkty danych
- analiza danych
- Podejmowanie decyzji
- głęboko
- głęboka nauka
- Domyślnie
- określić
- Definiuje
- dostawa
- wykazać
- rozwijać
- Wdrożenie
- wdraża się
- Wnętrze
- zaprojektowany
- wykryte
- oprogramowania
- schemat
- różne
- zróżnicowany
- Transmitowanie
- skierowany
- Dyrektor
- odkrycie
- Zakłócenie
- do
- Doker
- dokumentacja
- zrobić
- na dół
- dziesiątki
- napędzany
- kierowca
- lek
- odkrycie narkotyków
- z powodu
- dynamicznie
- każdy
- ebs
- faktycznie
- wydajny
- łatwy
- Elementy
- pusty
- umożliwiać
- włączony
- Umożliwia
- koniec końców
- Punkt końcowy
- inżynier
- ogromny
- dość
- Środowisko
- wyposażony
- ustanowiony
- Eter (ETH)
- wydarzenie
- Każdy
- dokładnie
- przykład
- Przede wszystkim system został opracowany
- eksperyment
- eksperymentalny
- ekspert
- odkryj
- narażony
- ułatwiać
- FAST
- szybciej
- kilka
- mniej
- filet
- Skupiać
- koncentruje
- obserwuj
- następujący
- W razie zamówieenia projektu
- podział
- Framework
- Ramy
- Częstotliwość
- od
- pełny
- Ogólne
- wygenerowane
- generuje
- generacja
- generatywny
- generatywna sztuczna inteligencja
- generator
- otrzymać
- GPU
- GPU
- większy
- Zarządzanie
- Gość
- Guest Post
- uchwyt
- Have
- he
- pomoc
- pomoc
- pomaga
- tutaj
- jego
- hostowane
- GODZINY
- W jaki sposób
- Jednak
- http
- HTTPS
- IAM
- Identyfikacja
- if
- ilustruje
- obraz
- zdjęcia
- tryb rozkazujący
- podnieść
- poprawa
- in
- włączony
- Zwiększać
- wzrastający
- Infrastruktura
- nieodłączny
- początkowy
- początkowo
- Innowacyjny
- wgląd
- zainstalowany
- przykład
- instancje
- zamiast
- instrukcje
- niewystarczający
- zintegrowany
- integracja
- Inteligencja
- zinterpretować
- problemy
- IT
- iteracja
- jpg
- właśnie
- Klawisz
- Uprzejmy
- Kubernetes
- Etykiety
- Brak
- duży
- Utajenie
- uruchomić
- Przywództwo
- Wycieki
- nauka
- najmniej
- lewo
- poziom
- Dźwignia
- dożywotni
- Limity
- załadować
- miejscowy
- długo
- dłużej
- poszukuje
- niski
- maszyna
- uczenie maszynowe
- utrzymać
- robić
- WYKONUJE
- zarządzane
- maksymalizacji
- maksymalny
- Może..
- zmierzyć
- Mechanizmy
- średni
- Poznaj nasz
- Spotkanie
- Pamięć
- łączy się
- Metadane
- metal
- metryczny
- Metryka
- migrować
- migracja
- miliony
- minimalizowanie
- Misja
- ML
- model
- modele
- monitory
- miesięcy
- jeszcze
- wielokrotność
- musi
- Nazwa
- O imieniu
- niezbędny
- Potrzebować
- potrzebne
- Nowości
- nowo
- Nie
- węzeł
- węzły
- powieść
- numer
- liczny
- Nvidia
- obserwować
- zauważony
- uzyskane
- of
- on
- Na żądanie
- ONE
- tylko
- koncepcja
- open source
- operator
- Szanse
- optymalizacja
- Optymalizacja
- zoptymalizowane
- or
- Inne
- ludzkiej,
- na zewnątrz
- koniec
- własny
- pacjent
- pacjenci
- w oczekiwaniu
- dla
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonuje
- okres
- Miejsce
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- pods
- zwrotnica
- polityka
- polityka
- możliwy
- Post
- powered
- mocny
- przewidzieć
- proroczy
- teraźniejszość
- pierwotny
- Główny
- Zasady
- prywatny
- wygląda tak
- obrobiony
- przetwarzanie
- produkować
- Program
- projekt
- niska zabudowa
- Białko
- zapewniać
- że
- pełnomocnik
- publiczny
- cel
- pytanie
- szybko
- R
- real
- w czasie rzeczywistym
- Przyczyny
- zmniejszyć
- zmniejsza
- oczyścić
- region
- polegać
- szczątki
- usunąć
- Usunięto
- usuwa
- usuwanie
- otrzymuje
- odpowiedzieć
- zażądać
- wywołań
- wymagać
- wymagany
- wymagania
- Wymaga
- Zasób
- Zasoby
- odpowiedzialny
- rewers
- prawo
- Rola
- korzeń
- run
- bieganie
- taki sam
- skalowalny
- Skala
- skala ai
- łuskowaty
- waga
- skalowaniem
- scenariusz
- zaplanowane
- szeregowanie
- Naukowcy
- skrypty
- Szukaj
- poszukiwania
- druga
- sekund
- Sekcja
- bezpieczeństwo
- widziany
- semantyka
- wysłać
- wysyła
- serwer
- służy
- usługa
- Usługi
- służąc
- zestaw
- ustawienie
- osiada
- prezentowany
- pokazane
- Targi
- znacznie
- podobny
- upraszczać
- symulacja
- pojedynczy
- Rozmiar
- mały
- mniejszy
- gładki
- So
- Tworzenie
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Typ przestrzeni
- Specyfikacje
- określony
- okular
- prędkość
- Spot
- standard
- początek
- startup
- Stan
- Cel
- zatrzymany
- przechowywanie
- Struktura
- podsieci
- sukces
- taki
- wystarczający
- przełożony
- dostarczanie
- wsparcie
- podpory
- pewnie
- system
- stół
- trwa
- kierowania
- cele
- zespół
- Technologies
- szablon
- kilkadziesiąt
- Terraform
- niż
- że
- Połączenia
- Państwo
- ich
- Im
- następnie
- Terapeutyczny
- lecznictwo
- Tam.
- a tym samym
- Te
- one
- to
- tysiące
- próg
- Przez
- wydajność
- czas
- czasy
- do
- wziął
- narzędzia
- Top
- Trening
- prawdziwy
- drugiej
- rodzaj
- typy
- typowy
- wyjątkowy
- bez precedensu
- aż do
- dyspozycyjność
- pilny
- us
- posługiwać się
- używany
- za pomocą
- utylizacja
- v1
- Wartości
- Naprawiono
- wszechstronny
- wersja
- przez
- Tom
- kłęby
- vs
- Luki w zabezpieczeniach
- solucja
- poszukiwany
- była
- we
- sieć
- Aplikacja internetowa
- przeglądarka internetowa
- usługi internetowe
- tydzień
- DOBRZE
- były
- Co
- Co to jest
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- KIM
- będzie
- w
- w ciągu
- Praca
- pracownik
- jamla
- ty
- Twój
- zefirnet