„Dane ukryte w tekście, dźwięku, mediach społecznościowych i innych nieustrukturyzowanych źródłach mogą stanowić przewagę konkurencyjną dla firm, które wiedzą, jak je wykorzystać”
Tylko 18% organizacji w a Badanie Deloitte 2019 zgłosiło, że potrafi korzystać z danych nieustrukturyzowanych. Większość danych, od 80% do 90%, to dane nieustrukturyzowane. Jest to duży, niewykorzystany zasób, który może zapewnić przedsiębiorstwom przewagę konkurencyjną, jeśli tylko dowiedzą się, jak z niego skorzystać. Wyciągnięcie wniosków z tych danych może być trudne, szczególnie jeśli konieczne jest ich sklasyfikowanie, oznaczenie lub oznaczenie. Amazon Comprehend klasyfikacja niestandardowa może być przydatna w tej sytuacji. Amazon Comprehend to usługa przetwarzania języka naturalnego (NLP), która wykorzystuje uczenie maszynowe do odkrywania cennych spostrzeżeń i powiązań w tekście.
Kategoryzacja lub klasyfikacja dokumentów przynosi znaczne korzyści we wszystkich domenach biznesowych –
- Ulepszone wyszukiwanie i pobieranie – Kategoryzacja dokumentów według odpowiednich tematów lub kategorii znacznie ułatwia użytkownikom wyszukiwanie i odzyskiwanie potrzebnych dokumentów. Mogą wyszukiwać w ramach określonych kategorii, aby zawęzić wyniki.
- Zarządzanie wiedzą – Systematyczne kategoryzowanie dokumentów pomaga uporządkować bazę wiedzy organizacji. Ułatwia odnalezienie odpowiednich informacji i dostrzeżenie powiązań pomiędzy powiązanymi treściami.
- Usprawnione przepływy pracy – Automatyczne sortowanie dokumentów może pomóc w usprawnieniu wielu procesów biznesowych, takich jak przetwarzanie faktur, obsługa klienta lub zgodność z przepisami. Dokumenty mogą być automatycznie kierowane do właściwych osób lub przepływów pracy.
- Oszczędność kosztów i czasu – Ręczna kategoryzacja dokumentów jest żmudna, czasochłonna i kosztowna. Techniki AI mogą przejąć to przyziemne zadanie i kategoryzować tysiące dokumentów w krótkim czasie i przy znacznie niższych kosztach.
- Pokolenie wglądu – Analiza trendów w kategoriach dokumentów może dostarczyć przydatnych informacji biznesowych. Na przykład wzrost liczby skarg klientów w danej kategorii produktu może oznaczać pewne problemy, którymi należy się zająć.
- Zarządzanie i egzekwowanie polityki – Skonfigurowanie reguł kategoryzacji dokumentów pomaga zapewnić, że dokumenty są poprawnie klasyfikowane zgodnie z polityką organizacji i standardami zarządzania. Pozwala to na lepsze monitorowanie i audytowanie.
- Spersonalizowane doświadczenia – W kontekście takim jak zawartość witryny internetowej kategoryzacja dokumentów umożliwia wyświetlanie użytkownikom dostosowanych treści na podstawie ich zainteresowań i preferencji określonych na podstawie ich zachowań podczas przeglądania. Może to zwiększyć zaangażowanie użytkowników.
Złożoność opracowania dostosowanego do potrzeb modelu uczenia maszynowego klasyfikacyjnego różni się w zależności od różnych aspektów, takich jak jakość danych, algorytm, skalowalność i wiedza dziedzinowa, żeby wymienić tylko kilka. Ważne jest, aby zacząć od jasnej definicji problemu, czystych i odpowiednich danych i stopniowo przechodzić przez różne etapy opracowywania modelu. Firmy mogą jednak tworzyć własne, unikalne modele uczenia maszynowego, korzystając z niestandardowej klasyfikacji Amazon Comprehend, aby automatycznie klasyfikować dokumenty tekstowe na kategorie lub tagi, aby spełnić specyficzne wymagania biznesowe i mapować je na technologię biznesową i kategorie dokumentów. Ponieważ znakowanie i kategoryzacja przez ludzi nie jest już konieczna, może to zaoszczędzić firmom mnóstwo czasu, pieniędzy i pracy. Uprościliśmy ten proces, automatyzując cały proces szkoleniowy.
W pierwszej części tego wpisu na blogu składającego się z wielu serii dowiesz się, jak utworzyć skalowalny potok szkoleniowy i przygotować dane szkoleniowe dla modeli Comrehend Custom Classification. Wprowadzimy niestandardowy potok szkolenia klasyfikatorów, który można wdrożyć na koncie AWS za pomocą kilku kliknięć. Korzystamy ze zbioru danych wiadomości BBC i będziemy szkolić klasyfikator w celu zidentyfikowania klasy (np. polityka, sport), do której należy dokument. Pipeline umożliwi Twojej organizacji szybkie reagowanie na zmiany i szkolenie nowych modeli bez konieczności rozpoczynania za każdym razem od zera. Możesz łatwo skalować i trenować wiele modeli w zależności od potrzeb.
Wymagania wstępne
- Aktywne konto AWS (kliknij tutaj aby utworzyć nowe konto AWS)
- Dostęp do Amazon Comprehend, Amazon S3, Amazon Lambda, Amazon Step Function, Amazon SNS i Amazon CloudFormation
- Dane szkoleniowe (półstruktura lub tekst) przygotowane w następnej sekcji
- Podstawowa wiedza na temat Pythona i ogólnie uczenia maszynowego
Przygotuj dane treningowe
To rozwiązanie może przyjmować dane wejściowe w obu przypadkach format tekstu (np. CSV) lub formacie półstrukturalnym (np. PDF).
Wprowadzanie tekstu
Amazon Comprehend klasyfikacja niestandardowa obsługuje dwa tryby: wiele klas i wiele etykiet.
W trybie wieloklasowym do każdego dokumentu można przypisać jedną i tylko jedną klasę. Dane szkoleniowe należy przygotować w postaci dwukolumnowego pliku CSV, w którym każda linia pliku zawiera jedną klasę oraz tekst dokumentu demonstrującego tę klasę.
Przykład dla Zbiór danych wiadomości BBC:
W trybie wielu etykiet każdy dokument ma przypisaną co najmniej jedną klasę, ale może mieć ich więcej. Dane szkoleniowe powinny mieć postać dwukolumnowego pliku CSV, przy czym każda linia pliku zawiera jedno lub więcej zajęć oraz tekst dokumentu szkoleniowego. Należy wskazać więcej niż jedną klasę, umieszczając pomiędzy każdą klasą separator.
Żaden nagłówek nie powinien być dołączany do pliku CSV dla żadnego z trybów uczenia.
Dane wejściowe półstrukturalne
Zaczynając od 2023, Amazon Comprehend obsługuje teraz modele szkoleniowe przy użyciu dokumentów częściowo ustrukturyzowanych. Dane szkoleniowe dotyczące wprowadzania danych półstrukturalnych składają się z zestawu oznaczonych dokumentów, które mogą być wstępnie zidentyfikowanymi dokumentami z repozytorium dokumentów, do którego już masz dostęp. Poniżej znajduje się przykład pliku adnotacji z danymi CSV wymaganymi do szkolenia (Przykładowe dane):
Plik CSV z adnotacjami zawiera trzy kolumny: Pierwsza kolumna zawiera etykietę dokumentu, druga kolumna to nazwa dokumentu (tzn. nazwa pliku), a ostatnia kolumna to numer strony dokumentu, który chcesz uwzględnić w zbiór danych szkoleniowych. W większości przypadków, jeśli plik CSV z adnotacjami znajduje się w tym samym folderze co wszystkie inne dokumenty, wystarczy podać nazwę dokumentu w drugiej kolumnie. Jeśli jednak plik CSV znajduje się w innej lokalizacji, w drugiej kolumnie należy określić ścieżkę do lokalizacji, np. path/to/prefix/document1.pdf.
Szczegóły dotyczące przygotowania danych treningowych znajdziesz w artykule tutaj.
Omówienie rozwiązania
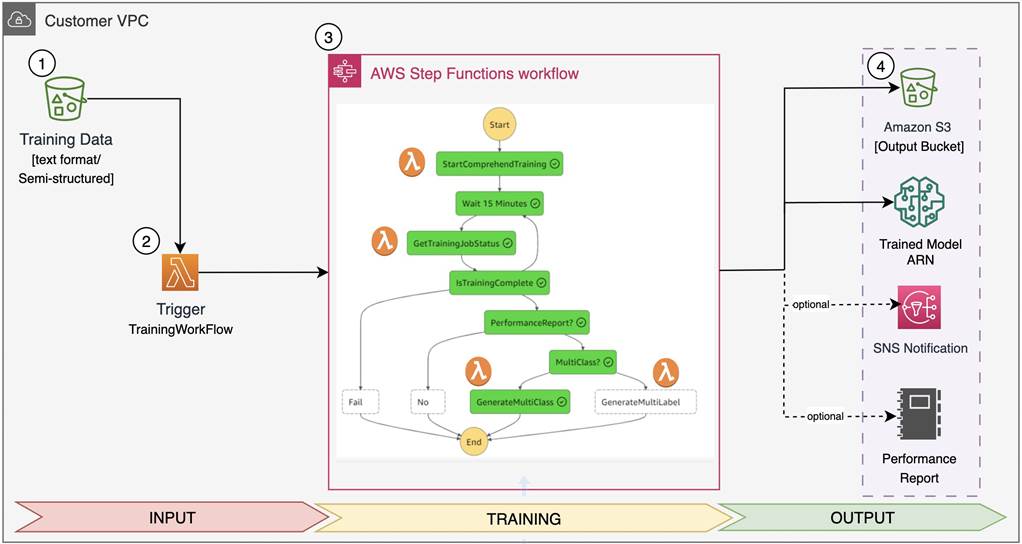
- Amazon Comprehend potok szkoleniowy rozpoczyna się w momencie przesłania danych szkoleniowych (plik .csv do wprowadzania tekstu i plik adnotacji .csv do wprowadzania danych półstrukturalnych) do dedykowanej usługi Amazon Simple Storage Service (Amazon S3) wiaderko.
- An AWS Lambda funkcja jest wywoływana przez Amazon S3 wyzwalacz w taki sposób, że za każdym razem, gdy obiekt jest przesyłany do określonego Amazon S3 lokalizacji, funkcja AWS Lambda pobiera nazwę segmentu źródłowego oraz nazwę klucza przesłanego obiektu i przekazuje go do szkolenia funkcja kroku workflow.
- W funkcji kroku uczenia, po otrzymaniu nazwy zbioru danych szkoleniowych i nazwy klucza obiektu jako parametrów wejściowych, niestandardowy przepływ pracy uczenia modelu rozpoczyna się jako seria funkcji lambda, jak opisano:
StartComprehendTraining: Ta funkcja AWS Lambda definiuje aComprehendClassifierobiekt w zależności od typu plików wejściowych (tj. tekstowy lub częściowo ustrukturyzowany), a następnie rozpoczyna się plik an Amazon Comprehend niestandardowe zadanie szkoleniowe w zakresie klasyfikacji, dzwoniąc utwórz_klasyfikator_dokumentów Application Programming Interfact (API), który zwraca zadanie szkoleniowe Amazon Resource Names (ARN). Następnie funkcja ta sprawdza status zadania szkoleniowego poprzez wywołanie opisz_klasyfikator_dokumentów API. Na koniec zwraca ARN zadania szkoleniowego i status zadania jako dane wyjściowe do następnego etapu przepływu pracy szkoleniowej.GetTrainingJobStatus: Ta AWS Lambda sprawdza status zadania szkoleniowego co 15 minut, dzwoniąc opisz_klasyfikator_dokumentów API, dopóki status zadania szkoleniowego nie zmieni się na Ukończone lub Niepowodzenie.GenerateMultiClassorGenerateMultiLabel: Jeśli wybierzesz tak w celu uzyskania raportu wydajności podczas uruchamiania stosu, jedna z tych dwóch lambd AWS przeprowadzi analizę zgodnie z wynikami modelu Amazon Comprehend, który generuje analizę wydajności dla poszczególnych klas i zapisuje ją w Amazon S3.GenerateMultiClass: Ta lambda AWS zostanie wywołana, jeśli wpiszesz Multiklasa i wybierasz tak do raportu wydajności.GenerateMultiLabel: Ta lambda AWS zostanie wywołana, jeśli wpiszesz MultiLabel i wybierasz tak do raportu wydajności.
- Po pomyślnym zakończeniu szkolenia rozwiązanie generuje następujące wyniki:
- Niestandardowy model klasyfikacji: wyszkolony model ARN będzie dostępny na Twoim koncie na potrzeby przyszłych prac wnioskowania.
- Matryca zamieszania [Opcjal]: Macierz zamieszania (
confusion_matrix.json) będą dostępne w wynikach zdefiniowanych przez użytkownika Amazon S3 ścieżka, w zależności od wyboru użytkownika. - Usługa prostego powiadomienia Amazon powiadomienie [Opcjal]: Wiadomość e-mail z powiadomieniem zostanie wysłana do subskrybentów o statusie zadania szkoleniowego, w zależności od początkowego wyboru użytkownika.
Opis przejścia
Uruchomienie rozwiązania
Aby wdrożyć potok, wykonaj następujące kroki:
- Dodaj Uruchom stos przycisk:
![]()
- Wybierz Dalej

- Określ szczegóły potoku za pomocą opcji pasujących do Twojego przypadku użycia:

Informacje dla każdego szczegółu stosu:
- Nazwa stosu (wymagane) – nazwa, którą w tym celu podałeś Tworzenie chmury AWS stos. Nazwa musi być unikalna w regionie, w którym ją tworzysz.
- Q01ClassifierInput BucketName (wymagane) – Nazwa segmentu Amazon S3 do przechowywania danych wejściowych. Powinna to być unikalna na całym świecie nazwa, a stos AWS CloudFormation pomaga utworzyć wiadro podczas jego uruchamiania.
- Q02ClassifierOutput BucketName (wymagane) – Nazwa segmentu Amazon S3 do przechowywania danych wyjściowych z Amazon Comrehend i potoku. Powinna to być także nazwa unikalna w skali globalnej.
- Q03Format wejściowy – Wybór rozwijany, możesz wybrać XNUMX (jeśli dane treningowe to pliki CSV) lub półstruktura (jeśli dane treningowe mają charakter półstrukturalny [np. pliki PDF]) w oparciu o format wejściowy danych.
- Q04Język – Wybór rozwijany, wybór języka dokumentów z obsługiwanej listy. Należy pamiętać, że obecnie obsługiwany jest tylko język angielski, jeśli format wejściowy jest półstrukturalny.
- Q05MultiClass – Wybór rozwijany, wybierz tak jeśli wprowadzone dane to tryb MultiClass. W przeciwnym razie wybierz Nie.
- Q06Ogranicznik etykiety – Wymagane tylko w przypadku odpowiedzi Q05MultiClass Nie. Ten ogranicznik jest używany w danych treningowych w celu oddzielenia poszczególnych klas.
- Zestaw danych Q07Validation – Wybór rozwijany, zmień odpowiedź na tak jeśli chcesz przetestować wydajność przeszkolonego klasyfikatora za pomocą własnych danych testowych.
- Q08S3Ścieżka walidacji – Wymagane tylko w przypadku odpowiedzi Q07ValidationDataset tak.
- Q09Raport wydajności – Wybór rozwijany, wybierz tak jeśli chcesz wygenerować raport wydajności na poziomie klasy po szkoleniu modelowym. Raport zostanie zapisany w określonym zasobniku wyjściowym w Q02ClassifierOutputBucketName.
- P10Powiadomienie e-mailem – Wybór rozwijany. Wybierać tak jeśli chcesz otrzymać powiadomienie po przeszkoleniu modelu.
- P11Identyfikator e-mail – Wprowadź prawidłowy adres e-mail, na który chcesz otrzymywać powiadomienia o raportach wyników. Pamiętaj, że musisz potwierdzić subskrypcję ze swojego adresu e-mail po uruchomieniu stosu AWS CloudFormation, zanim będziesz mógł otrzymać powiadomienie o zakończeniu szkolenia.
- W sekcji opcji stosu Amazon Configure dodaj opcjonalne tagi, uprawnienia i inne zaawansowane ustawienia.

- Dodaj Następna
- Przejrzyj szczegóły stosu i wybierz opcję Potwierdzam to Tworzenie chmury AWS może stworzyć AWS IAM zasoby.

- Dodaj Prześlij. Spowoduje to zainicjowanie wdrożenia potoku na Twoim koncie AWS.
- Po pomyślnym wdrożeniu stosu można rozpocząć korzystanie z potoku. Stwórz
/training-datafolder w określonej lokalizacji Amazon S3 w celu wprowadzenia danych. Notatka: Amazon S3 automatycznie stosuje szyfrowanie po stronie serwera (SSE-S3) dla każdego nowego obiektu, chyba że określisz inną opcję szyfrowania. Proszę odnieś się Ochrona danych w Amazon S3 aby uzyskać więcej informacji na temat ochrony danych i szyfrowania w Amazon S3.

- Prześlij swoje dane treningowe do folderu. (Jeśli dane szkoleniowe mają charakter półstrukturalny, prześlij wszystkie pliki PDF przed przesłaniem informacji o etykiecie w formacie .csv).
Jesteś skończony! Pomyślnie wdrożyłeś potok i możesz sprawdzić stan potoku w funkcji wdrożonego kroku. (Będziesz miał przeszkolony model w panelu niestandardowej klasyfikacji Amazon Comprehend).

Jeśli wybierzesz model i jego wersję wewnątrz Amazon Comprehend Konsoli, możesz teraz zobaczyć więcej szczegółów na temat właśnie wytrenowanego modelu. Obejmuje wybrany tryb, który odpowiada opcji Q05MultiClass, liczbę etykiet oraz liczbę wytrenowanych i testowanych dokumentów znajdujących się w danych szkoleniowych. Możesz także sprawdzić ogólną wydajność poniżej; jeśli jednak chcesz sprawdzić szczegółową wydajność każdej klasy, zapoznaj się z raportem wydajności wygenerowanym przez wdrożony potok.
Limity usług
Twoje konto AWS ma domyślne limity Amazon Comprehend i Tekst Amazona, jeśli dane wejściowe są w formacie półstruktury. Aby wyświetlić limity usług, zobacz tutaj dla Amazon Comprehend i tutaj dla Tekst Amazona.
Sprzątać
Aby uniknąć ponoszenia bieżących opłat, po zakończeniu usuń zasoby utworzone w ramach tego rozwiązania.
- Na Amazon S3 konsoli, ręcznie usuń zawartość segmentów utworzonych dla danych wejściowych i wyjściowych.
- Na Tworzenie chmury AWS konsola, wybierz Półki na książki w okienku nawigacji.
- Wybierz główny stos i wybierz Usuń.

Spowoduje to automatyczne usunięcie wdrożonego stosu.
- Jesteś wyszkolony Amazon Comprehend niestandardowy model klasyfikacji pozostanie na Twoim koncie. Jeśli już go nie potrzebujesz, wejdź Amazon Comprehend konsoli, usuń utworzony model.
Wnioski
W tym poście pokazaliśmy koncepcję skalowalnego potoku szkoleniowego dla Amazon Comprehend niestandardowe modele klasyfikacji i zapewnianie zautomatyzowanego rozwiązania do efektywnego uczenia nowych modeli. The Tworzenie chmury AWS dostarczony szablon umożliwia łatwe tworzenie własnych modeli klasyfikacji tekstu, dostosowanych do skali zapotrzebowania. Rozwiązanie wykorzystuje niedawno ogłoszoną funkcję Euclid i akceptuje dane wejściowe w formacie tekstowym lub częściowo ustrukturyzowanym.
Teraz zachęcamy Was, naszych czytelników, do przetestowania tych narzędzi. Możesz znaleźć więcej szczegółów na temat przygotowanie danych treningowych i zrozumieć niestandardowe metryki klasyfikatora. Wypróbuj i przekonaj się na własnej skórze, jak może usprawnić proces uczenia modeli i zwiększyć wydajność. Podziel się z nami swoją opinią!
O autorach
 Sandeep Singh jest starszym analitykiem danych w AWS Professional Services. Jego pasją jest pomaganie klientom we wprowadzaniu innowacji i osiąganiu ich celów biznesowych poprzez opracowywanie najnowocześniejszych rozwiązań opartych na sztucznej inteligencji/ML. Obecnie koncentruje się na generatywnej sztucznej inteligencji, LLM, szybkiej inżynierii i skalowaniu uczenia maszynowego w przedsiębiorstwach. Wprowadza najnowsze osiągnięcia w zakresie sztucznej inteligencji, aby tworzyć wartość dla klientów.
Sandeep Singh jest starszym analitykiem danych w AWS Professional Services. Jego pasją jest pomaganie klientom we wprowadzaniu innowacji i osiąganiu ich celów biznesowych poprzez opracowywanie najnowocześniejszych rozwiązań opartych na sztucznej inteligencji/ML. Obecnie koncentruje się na generatywnej sztucznej inteligencji, LLM, szybkiej inżynierii i skalowaniu uczenia maszynowego w przedsiębiorstwach. Wprowadza najnowsze osiągnięcia w zakresie sztucznej inteligencji, aby tworzyć wartość dla klientów.
 Yanyana Zhanga jest starszym analitykiem danych w zespole Energy Delivery w AWS Professional Services. Jej pasją jest pomaganie klientom w rozwiązywaniu rzeczywistych problemów dzięki wiedzy AI/ML. Ostatnio skupiła się na badaniu potencjału generatywnej sztucznej inteligencji i LLM. Poza pracą uwielbia podróżować, ćwiczyć i odkrywać nowe rzeczy.
Yanyana Zhanga jest starszym analitykiem danych w zespole Energy Delivery w AWS Professional Services. Jej pasją jest pomaganie klientom w rozwiązywaniu rzeczywistych problemów dzięki wiedzy AI/ML. Ostatnio skupiła się na badaniu potencjału generatywnej sztucznej inteligencji i LLM. Poza pracą uwielbia podróżować, ćwiczyć i odkrywać nowe rzeczy.
 Wricka Talukdara jest starszym architektem w zespole Amazon Comprehend Service. Współpracuje z klientami AWS, aby pomóc im wdrożyć uczenie maszynowe na dużą skalę. Poza pracą lubi czytać i fotografować.
Wricka Talukdara jest starszym architektem w zespole Amazon Comprehend Service. Współpracuje z klientami AWS, aby pomóc im wdrożyć uczenie maszynowe na dużą skalę. Poza pracą lubi czytać i fotografować.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- ChartPrime. Podnieś poziom swojej gry handlowej dzięki ChartPrime. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/build-a-classification-pipeline-with-amazon-comprehend-custom-classification-part-i/
- :ma
- :Jest
- $W GÓRĘ
- 1
- 100
- 11
- 15%
- 2023
- 24
- 26
- 7
- 9
- a
- Zdolny
- O nas
- Akceptuje
- dostęp
- Stosownie
- Konto
- Osiągać
- uznać
- w poprzek
- aktywny
- Dodaj
- adres
- zaadresowany
- przyjąć
- zaawansowany
- postępy
- Korzyść
- Po
- AI
- AI / ML
- algorytm
- Wszystkie kategorie
- pozwala
- już
- również
- Amazonka
- Amazon Comprehend
- Amazon Web Services
- an
- analiza
- Analizując
- i
- ogłosił
- odpowiedź
- więcej
- api
- Zastosowanie
- dotyczy
- SĄ
- AS
- aspekty
- przydzielony
- At
- audio
- audytu
- zautomatyzowane
- automatycznie
- automatycznie
- automatyzacja
- dostępny
- uniknąć
- z dala
- AWS
- Tworzenie chmury AWS
- AWS Lambda
- Usługi profesjonalne AWS
- baza
- na podstawie
- bbc
- BE
- być
- zanim
- zachowanie
- jest
- należy
- poniżej
- Korzyści
- zrobiony na zamówienie
- Ulepsz Swój
- pomiędzy
- Duży
- Blog
- Przynosi
- Przeglądanie
- budować
- biznes
- procesów biznesowych
- biznes
- ale
- przycisk
- by
- nazywa
- powołanie
- CAN
- walizka
- Etui
- kategorie
- kategoryzowanie
- Kategoria
- zmiana
- Zmiany
- Opłaty
- ZOBACZ
- Wykrywanie urządzeń szpiegujących
- Dodaj
- Wybierając
- klasa
- Klasy
- klasyfikacja
- sklasyfikowany
- Klasyfikuj
- jasny
- kliknij
- zbierać
- Kolumna
- kolumny
- konkurencyjny
- skarg
- kompletny
- Zakończony
- kompleksowość
- spełnienie
- zrozumieć
- Składa się
- pojęcie
- Potwierdzać
- zamieszanie
- połączenia
- Konsola
- zawiera
- zawartość
- treść
- konteksty
- prawidłowo
- odpowiada
- Koszty:
- mógłby
- Stwórz
- Utwórz wartość
- stworzony
- Tworzenie
- Obecnie
- zwyczaj
- klient
- Obsługa klienta
- Klientów
- dane
- Ochrona danych
- jakość danych
- naukowiec danych
- dedykowane
- Domyślnie
- zdefiniowane
- Definiuje
- definicja
- dostawa
- deloitte
- Kreowanie
- demonstruje
- W zależności
- rozwijać
- wdrażane
- Wdrożenie
- opisane
- detal
- szczegółowe
- detale
- ustalona
- rozwijanie
- oprogramowania
- różne
- trudny
- dokument
- dokumenty
- Dolar
- domena
- domeny
- zrobić
- nie
- na dół
- e
- każdy
- łatwiej
- z łatwością
- krawędź
- efektywność
- skutecznie
- bez wysiłku
- starania
- bądź
- umożliwiać
- zachęcać
- szyfrowanie
- energia
- zaręczynowy
- Inżynieria
- Angielski
- wzmacniać
- zapewnić
- Wchodzę
- przedsiębiorstwa
- niezbędny
- Eter (ETH)
- Europie
- Każdy
- przykład
- drogi
- Exploring
- Failed
- Cecha
- informacja zwrotna
- kilka
- Postać
- filet
- Akta
- W końcu
- Znajdź
- firmy
- i terminów, a
- dopasowywanie
- Skupiać
- koncentruje
- następujący
- W razie zamówieenia projektu
- format
- od
- funkcjonować
- Funkcje
- przyszłość
- Generować
- wygenerowane
- generuje
- generatywny
- generatywna sztuczna inteligencja
- Dać
- Globalnie
- zarządzanie
- stopniowo
- Have
- mający
- he
- pomoc
- pomoc
- pomaga
- jej
- W jaki sposób
- How To
- Jednak
- HTML
- HTTPS
- człowiek
- i
- zidentyfikować
- if
- in
- zawierać
- włączony
- obejmuje
- Zwiększać
- wskazany
- Informacja
- początkowy
- Inicjuje
- wprowadzać innowacje
- wkład
- Wejścia
- wewnątrz
- spostrzeżenia
- zainteresowania
- najnowszych
- przedstawiać
- przywołany
- problemy
- IT
- JEGO
- Praca
- jpg
- json
- właśnie
- Klawisz
- wiedza
- Etykieta
- Etykiety
- praca
- język
- duży
- Nazwisko
- uruchomiona
- wodowanie
- UCZYĆ SIĘ
- nauka
- najmniej
- lubić
- Linia
- Lista
- usytuowany
- lokalizacja
- zamknięty
- dłużej
- Partia
- kocha
- niższy
- maszyna
- uczenie maszynowe
- zrobiony
- Główny
- Większość
- WYKONUJE
- podręcznik
- ręcznie
- wiele
- mapa
- Matrix
- Może..
- Media
- Poznaj nasz
- wspominać
- może
- minuty
- Moda
- model
- modele
- Tryby
- pieniądze
- monitorowanie
- jeszcze
- większość
- Góra
- dużo
- wielokrotność
- musi
- Nazwa
- Nazwy
- wąski
- Nawigacja
- niezbędny
- Potrzebować
- potrzebne
- Nowości
- aktualności
- Następny
- nlp
- Nie
- noty
- powiadomienie
- już dziś
- numer
- przedmiot
- Cele
- of
- on
- ONE
- trwający
- tylko
- Option
- Opcje
- or
- organizacja
- organizacji
- Inne
- Inaczej
- ludzkiej,
- na zewnątrz
- wydajność
- zewnętrzne
- koniec
- ogólny
- własny
- strona
- chleb
- płyta
- parametry
- część
- szczególnie
- przechodzić
- namiętny
- ścieżka
- Ludzie
- dla
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- uprawnienia
- fotografia
- rurociąg
- plato
- Analiza danych Platona
- PlatoDane
- Proszę
- polityka
- polityka
- polityka
- możliwy
- Post
- potencjał
- powered
- preferencje
- Przygotować
- przygotowany
- Problem
- problemy
- wygląda tak
- procesów
- przetwarzanie
- Produkt
- profesjonalny
- Programowanie
- ochrona
- zapewniać
- pod warunkiem,
- że
- Python
- jakość
- szybko
- czytelnicy
- Czytający
- real
- otrzymać
- odbieranie
- niedawny
- niedawno
- odnosić się
- region
- regulacyjne
- Zgodność z przepisami
- związane z
- pozostawać
- raport
- Zgłoszone
- składnica
- wymagany
- wymagania
- Zasób
- Zasoby
- Odpowiadać
- Efekt
- powraca
- prawo
- reguły
- run
- taki sam
- Zapisz
- zapisywane
- Skalowalność
- skalowalny
- Skala
- waga
- skalowaniem
- Naukowiec
- zadraśnięcie
- Szukaj
- druga
- Sekcja
- widzieć
- wybór
- senior
- wysłany
- oddzielny
- Serie
- usługa
- Usługi
- zestaw
- ustawienie
- w panelu ustawień
- Share
- ona
- Short
- powinien
- pokazał
- pokazane
- znaczący
- oznaczać
- Prosty
- pojedynczy
- sytuacja
- Obserwuj Nas
- Media społecznościowe
- rozwiązanie
- Rozwiązania
- ROZWIĄZANIA
- kilka
- Źródło
- Źródła
- specyficzny
- określony
- SPORTOWE
- stos
- STAGE
- etapy
- standardy
- początek
- rozpocznie
- state-of-the-art
- Rynek
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- opływowy
- abonentów
- subskrypcja
- Następnie
- Z powodzeniem
- taki
- wsparcie
- Utrzymany
- podpory
- Badanie
- TAG
- dostosowane
- Brać
- Zadanie
- zespół
- tech
- Techniki
- Technologia
- szablon
- test
- XNUMX
- Klasyfikacja tekstu
- niż
- że
- Połączenia
- Źródło
- ich
- Im
- następnie
- Te
- one
- rzeczy
- to
- tysiące
- trzy
- Przez
- czas
- czasochłonne
- do
- narzędzia
- tematy
- Pociąg
- przeszkolony
- Trening
- Podróżowanie
- Trendy
- wyzwalać
- próbować
- drugiej
- rodzaj
- odkryć
- dla
- zrozumieć
- wyjątkowy
- nie wykorzystany
- aż do
- przesłanych
- Uploading
- us
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- zastosowania
- za pomocą
- Cenny
- wartość
- różnorodność
- wersja
- Zobacz i wysłuchaj
- chcieć
- Droga..
- we
- sieć
- usługi internetowe
- Strona internetowa
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- cały
- będzie
- w
- w ciągu
- bez
- Praca
- workflow
- przepływów pracy
- pracujący
- wypracowanie
- działa
- ty
- Twój
- zefirnet
- Zamek błyskawiczny