Open-source large language models (LLMs) have become popular, allowing researchers, developers, and organizations to access these models to foster innovation and experimentation. This encourages collaboration from the open-source community to contribute to developments and improvement of LLMs. Open-source LLMs provide transparency to the model architecture, training process, and training data, which allows researchers to understand how the model works and identify potential biases and address ethical concerns. These open-source LLMs are democratizing generative AI by making advanced natural language processing (NLP) technology available to a wide range of users to build mission-critical business applications. GPT-NeoX, LLaMA, Alpaca, GPT4All, Vicuna, Dolly, and OpenAssistant are some of the popular open-source LLMs.
OpenChatKit is an open-source LLM used to build general-purpose and specialized chatbot applications, released by Together Computer in March 2023 under the Apache-2.0 license. This model allows developers to have more control over the chatbot’s behavior and tailor it to their specific applications. OpenChatKit provides a set of tools, base bot, and building blocks to build fully customized, powerful chatbots. The key components are as follows:
- An instruction-tuned LLM, fine-tuned for chat from EleutherAI’s GPT-NeoX-20B with over 43 million instructions on 100% carbon negative compute. The
GPT-NeoXT-Chat-Base-20Bmodel is based on EleutherAI’s GPT-NeoX model, and is fine-tuned with data focusing on dialog-style interactions. - Customization recipes to fine-tune the model to achieve high accuracy on your tasks.
- An extensible retrieval system enabling you to augment bot responses with information from a document repository, API, or other live-updating information source at inference time.
- A moderation model, fine-tuned from GPT-JT-6B, designed to filter which questions the bot responds to.
The increasing scale and size of deep learning models present obstacles to successfully deploy these models in generative AI applications. To meet the demands for low latency and high throughput, it becomes essential to employ sophisticated methods like model parallelism and quantization. Lacking proficiency in the application of these methods, numerous users encounter difficulties in initiating the hosting of sizable models for generative AI use cases.
In this post, we show how to deploy OpenChatKit models (GPT-NeoXT-Chat-Base-20B and GPT-JT-Moderation-6B) models on Amazon SageMaker using DJL Serving and open-source model parallel libraries like DeepSpeed and Hugging Face Accelerate. We use DJL Serving, which is a high-performance universal model serving solution powered by the Deep Java Library (DJL) that is programming language agnostic. We demonstrate how the Hugging Face Accelerate library simplifies deployment of large models into multiple GPUs, thereby reducing the burden of running LLMs in a distributed fashion. Let’s get started!
Extensible retrieval system
An extensible retrieval system is one of the key components of OpenChatKit. It enables you to customize the bot response based on a closed domain knowledge base. Although LLMs are able to retain factual knowledge in their model parameters and can achieve remarkable performance on downstream NLP tasks when fine-tuned, their capacity to access and predict closed domain knowledge accurately remains restricted. Therefore, when they’re presented with knowledge-intensive tasks, their performance suffers to that of task-specific architectures. You can use the OpenChatKit retrieval system to augment knowledge in their responses from external knowledge sources such as Wikipedia, document repositories, APIs, and other information sources.
The retrieval system enables the chatbot to access current information by obtaining pertinent details in response to a specific query, thereby supplying the necessary context for the model to generate answers. To illustrate the functionality of this retrieval system, we provide support for an index of Wikipedia articles and offer example code demonstrating how to invoke a web search API for information retrieval. By following the provided documentation, you can integrate the retrieval system with any dataset or API during the inference process, allowing the chatbot to incorporate dynamically updated data into its responses.
Moderation model
Moderation models are important in chatbot applications to enforce content filtering, quality control, user safety, and legal and compliance reasons. Moderation is a difficult and subjective task, and depends a lot on the domain of the chatbot application. OpenChatKit provides tools to moderate the chatbot application and monitor input text prompts for any inappropriate content. The moderation model provides a good baseline that can be adapted and customized to various needs.
OpenChatKit has a 6-billion-parameter moderation model, GPT-JT-Moderation-6B, which can moderate the chatbot to limit the inputs to the moderated subjects. Although the model itself does have some moderation built in, TogetherComputer trained a GPT-JT-Moderation-6B model with Ontocord.ai’s OIG-moderation dataset. This model runs alongside the main chatbot to check that both the user input and answer from the bot don’t contain inappropriate results. You can also use this to detect any out of domain questions to the chatbot and override when the question is not part of the chatbot’s domain.
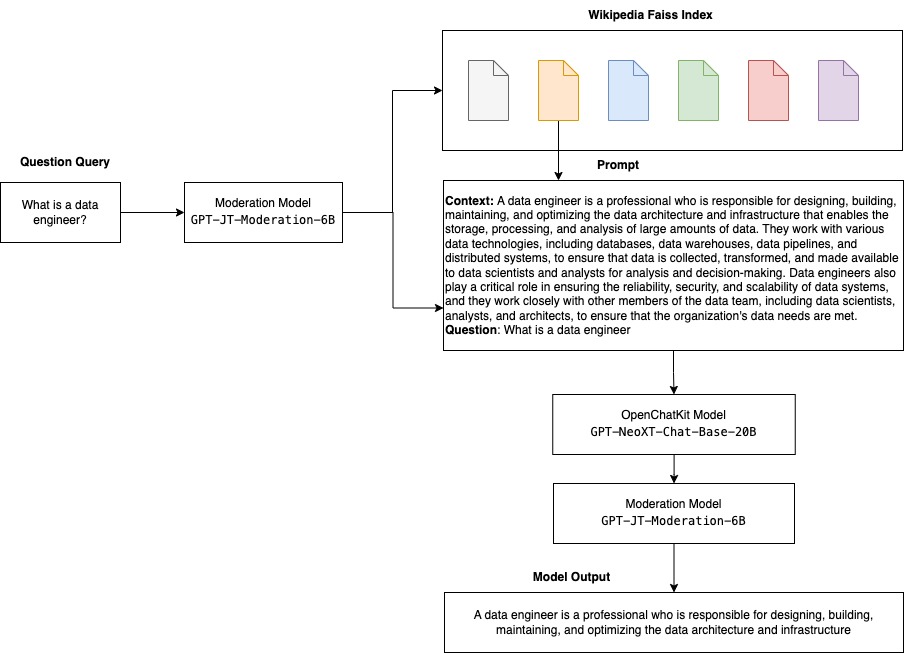
The following diagram illustrates the OpenChatKit workflow.
Extensible retrieval system use cases
Although we can apply this technique in various industries to build generative AI applications, for this post we discuss use cases in the financial industry. Retrieval augmented generation can be employed in financial research to automatically generate research reports on specific companies, industries, or financial products. By retrieving relevant information from internal knowledge bases, financial archives, news articles, and research papers, you can generate comprehensive reports that summarize key insights, financial metrics, market trends, and investment recommendations. You can use this solution to monitor and analyze financial news, market sentiment, and trends.
Solution overview
The following steps are involved to build a chatbot using OpenChatKit models and deploy them on SageMaker:
- Download the chat base
GPT-NeoXT-Chat-Base-20Bmodel and package the model artifacts to be uploaded to Amazon Simple Storage Service (Amazon S3). - Use a SageMaker large model inference (LMI) container, configure the properties, and set up custom inference code to deploy this model.
- Configure model parallel techniques and use inference optimization libraries in DJL serving properties. We will use Hugging Face Accelerate as the engine for DJL serving. Additionally, we define tensor parallel configurations to partition the model.
- Create a SageMaker model and endpoint configuration, and deploy the SageMaker endpoint.
You can follow along by running the notebook in the GitHub repo.
Download the OpenChatKit model
First, we download the OpenChatKit base model. We use huggingface_hub and use snapshot_download to download the model, which downloads an entire repository at a given revision. Downloads are made concurrently to speed up the process. See the following code:
DJL Serving properties
You can use SageMaker LMI containers to host large generative AI models with custom inference code without providing your own inference code. This is extremely useful when there is no custom preprocessing of the input data or postprocessing of the model’s predictions. You can also deploy a model using custom inference code. In this post, we demonstrate how to deploy OpenChatKit models with custom inference code.
SageMaker expects the model artifacts in tar format. We create each OpenChatKit model with the following files: serving.properties and model.py.
The serving.properties configuration file indicates to DJL Serving which model parallelization and inference optimization libraries you would like to use. The following is a list of settings we use in this configuration file:
This contains the following parameters:
- engine – The engine for DJL to use.
- option.entryPoint – The entry point Python file or module. This should align with the engine that is being used.
- option.s3url – Set this to the URI of the S3 bucket that contains the model.
- option.modelid – If you want to download the model from huggingface.co, you can set
option.modelidto the model ID of a pretrained model hosted inside a model repository on huggingface.co (https://huggingface.co/models). The container uses this model ID to download the corresponding model repository on huggingface.co. - option.tensor_parallel_degree – Set this to the number of GPU devices over which DeepSpeed needs to partition the model. This parameter also controls the number of workers per model that will be started up when DJL Serving runs. For example, if we have an 8 GPU machine and we are creating eight partitions, then we will have one worker per model to serve the requests. It’s necessary to tune the parallelism degree and identify the optimal value for a given model architecture and hardware platform. We call this ability inference-adapted parallelism.
Refer to Configurations and settings for an exhaustive list of options.
OpenChatKit models
The OpenChatKit base model implementation has the following four files:
- model.py – This file implements the handling logic for the main OpenChatKit GPT-NeoX model. It receives the inference input request, loads the model, loads the Wikipedia index, and serves the response. Refer to
model.py(created part of the notebook) for additional details.model.pyuses the following key classes:- OpenChatKitService – This handles passing the data between the GPT-NeoX model, Faiss search, and conversation object.
WikipediaIndexandConversationobjects are initialized and input chat conversations are sent to the index to search for relevant content from Wikipedia. This also generates a unique ID for each invocation if one is not supplied for the purpose of storing the prompts in Amazon DynamoDB. - ChatModel – This class loads the model and tokenizer and generates the response. It handles partitioning the model across multiple GPUs using
tensor_parallel_degree, and configures thedtypesanddevice_map. The prompts are passed to the model to generate responses. A stopping criteriaStopWordsCriteriais configured for the generation to only produce the bot response on inference. - ModerationModel – We use two moderation models in the
ModerationModelclass: the input model to indicate to the chat model that the input is inappropriate to override the inference result, and the output model to override the inference result. We classify the input prompt and output response with the following possible labels:- casual
- needs caution
- needs intervention (this is flagged to be moderated by the model)
- possibly needs caution
- probably needs caution
- OpenChatKitService – This handles passing the data between the GPT-NeoX model, Faiss search, and conversation object.
- wikipedia_prepare.py – This file handles downloading and preparing the Wikipedia index. In this post, we use a Wikipedia index provided on Hugging Face datasets. To search the Wikipedia documents for relevant text, the index needs to be downloaded from Hugging Face because it’s not packaged elsewhere. The
wikipedia_prepare.pyfile is responsible for handling the download when imported. Only a single process in the multiple that are running for inference can clone the repository. The rest wait until the files are present in the local file system. - wikipedia.py – This file is used for searching the Wikipedia index for contextually relevant documents. The input query is tokenized and embeddings are created using
mean_pooling. We compute cosine similarity distance metrics between the query embedding and the Wikipedia index to retrieve contextually relevant Wikipedia sentences. Refer towikipedia.pyfor implementation details.
- conversation.py – This file is used for storing and retrieving the conversation thread in DynamoDB for passing to the model and user.
conversation.pyis adapted from the open-source OpenChatKit repository. This file is responsible for defining the object that stores the conversation turns between the human and the model. With this, the model is able to retain a session for the conversation, allowing a user to refer to previous messages. Because SageMaker endpoint invocations are stateless, this conversation needs to be stored in a location external to the endpoint instances. On startup, the instance creates a DynamoDB table if it doesn’t exist. All updates to the conversation are then stored in DynamoDB based on thesession_idkey, which is generated by the endpoint. Any invocation with a session ID will retrieve the associated conversation string and update it as required.
Build an LMI inference container with custom dependencies
The index search uses Facebook’s Faiss library for performing the similarity search. Because this isn’t included in the base LMI image, the container needs to be adapted to install this library. The following code defines a Dockerfile that installs Faiss from the source alongside other libraries needed by the bot endpoint. We use the sm-docker utility to build and push the image to Amazon Elastic Container Registry (Amazon ECR) from Amazon SageMaker Studio. Refer to Using the Amazon SageMaker Studio Image Build CLI to build container images from your Studio notebooks for more details.
The DJL container doesn’t have Conda installed, so Faiss needs to be cloned and compiled from the source. To install Faiss, the dependencies for using the BLAS APIs and Python support need to be installed. After these packages are installed, Faiss is configured to use AVX2 and CUDA before being compiled with the Python extensions installed.
pandas, fastparquet, boto3, and git-lfs are installed afterwards because these are required for downloading and reading the index files.
Create the model
Now that we have the Docker image in Amazon ECR, we can proceed with creating the SageMaker model object for the OpenChatKit models. We deploy GPT-NeoXT-Chat-Base-20B input and output moderation models using GPT-JT-Moderation-6B. Refer to create_model for more details.
Configure the endpoint
Next, we define the endpoint configurations for the OpenChatKit models. We deploy the models using the ml.g5.12xlarge instance type. Refer to create_endpoint_config for more details.
Deploy the endpoint
Finally, we create an endpoint using the model and endpoint configuration we defined in the previous steps:
Run inference from OpenChatKit models
Now it’s time to send inference requests to the model and get the responses. We pass the input text prompt and model parameters such as temperature, top_k, and max_new_tokens. The quality of the chatbot responses is based on the parameters specified, so it’s recommended to benchmark model performance against these parameters to find the optimal setting for your use case. The input prompt is first sent to the input moderation model, and the output is sent to ChatModel to generate the responses. During this step, the model uses the Wikipedia index to retrieve contextually relevant sections to the model as the prompt to get domain-specific responses from the model. Finally, the model response is sent to the output moderation model to check for classification, and then the responses are returned. See the following code:
Refer to sample chat interactions below.

Clean up
Follow the instructions in the cleanup section of the to delete the resources provisioned as part of this post to avoid unnecessary charges. Refer to Amazon SageMaker Pricing for details about the cost of the inference instances.
Conclusion
In this post, we discussed the importance of open-source LLMs and how to deploy an OpenChatKit model on SageMaker to build next-generation chatbot applications. We discussed various components of OpenChatKit models, moderation models, and how to use an external knowledge source like Wikipedia for retrieval augmented generation (RAG) workflows. You can find step-by-step instructions in the GitHub notebook. Let us know about the amazing chatbot applications you’re building. Cheers!
About the Authors
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
 Vikram Elango is a Sr. AIML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is a Sr. AIML Specialist Solutions Architect at AWS, based in Virginia, US. He is currently focused on generative AI, LLMs, prompt engineering, large model inference optimization, and scaling ML across enterprises. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
 Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
Andrew Smith is a Cloud Support Engineer in the SageMaker, Vision & Other team at AWS, based in Sydney, Australia. He supports customers using many AI/ML services on AWS with expertise in working with Amazon SageMaker. Outside of work, he enjoys spending time with friends and family as well as learning about different technologies.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- EVM Finance. Unified Interface for Decentralized Finance. Access Here.
- Quantum Media Group. IR/PR Amplified. Access Here.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/build-custom-chatbot-applications-using-openchatkit-models-on-amazon-sagemaker/
- :has
- :is
- :not
- :where
- $UP
- 1
- 10
- 100
- 11
- 14
- 15%
- 17
- 195
- 20
- 2023
- 30
- 40
- 8
- a
- ability
- Able
- About
- accelerate
- access
- accuracy
- accurately
- Achieve
- across
- adapted
- Additional
- Additionally
- address
- advanced
- After
- afterwards
- against
- AI
- ai use cases
- AI/ML
- AIML
- align
- All
- Allowing
- allows
- along
- alongside
- also
- Although
- amazing
- Amazon
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- an
- analyze
- and
- answer
- answers
- any
- api
- APIs
- Application
- applications
- Apply
- APT
- architecture
- archives
- ARE
- articles
- artificial
- artificial intelligence
- AS
- associated
- At
- augmented
- Australia
- automatically
- available
- avoid
- AWS
- base
- based
- Baseline
- BE
- because
- become
- becomes
- before
- being
- below
- Benchmark
- between
- biases
- BIN
- Blocks
- body
- Bot
- both
- build
- Build a chatbot
- Building
- built
- burden
- business
- Business Applications
- by
- call
- camping
- CAN
- Capacity
- carbon
- case
- cases
- CD
- charges
- chatbot
- chatbots
- check
- class
- classes
- classification
- Classify
- closed
- Cloud
- CO
- code
- collaboration
- community
- Companies
- compliance
- components
- comprehensive
- Compute
- computer
- Computer Vision
- computing
- Concerns
- Configuration
- configurations
- configured
- Container
- Containers
- contains
- content
- context
- contribute
- control
- controls
- Conversation
- conversations
- cooking
- Corresponding
- Cost
- create
- created
- creates
- Creating
- criteria
- Current
- Currently
- custom
- Customers
- customize
- customized
- data
- data engineer
- datasets
- deep
- deep learning
- defined
- Defines
- defining
- Degree
- demands
- Democratizing
- demonstrate
- demonstrating
- depends
- deploy
- deployment
- Design
- designed
- details
- developers
- developments
- Devices
- different
- difficult
- difficulties
- discuss
- discussed
- distance
- distributed
- distributed computing
- do
- Docker
- document
- documentation
- documents
- does
- Doesn’t
- Dolly
- domain
- domains
- Dont
- download
- downloads
- during
- dynamically
- each
- else
- elsewhere
- embedding
- employed
- enables
- enabling
- encounter
- encourages
- Endpoint
- enforce
- Engine
- engineer
- Engineering
- enterprises
- Entire
- entry
- essential
- Ether (ETH)
- ethical
- EVER
- example
- exist
- expects
- expertise
- extensions
- external
- extremely
- Face
- Factual
- family
- Fashion
- File
- Files
- filter
- filtering
- Finally
- financial
- financial news
- financial products
- Find
- First
- flagged
- focused
- focuses
- focusing
- follow
- following
- follows
- For
- format
- Foster
- four
- friends
- from
- fully
- functionality
- general-purpose
- generate
- generated
- generates
- generation
- generative
- Generative AI
- get
- Git
- given
- good
- GPU
- GPUs
- Handles
- Handling
- Hardware
- Have
- he
- helps
- High
- high-performance
- hiking
- his
- host
- hosted
- hosting
- How
- How To
- HTML
- http
- HTTPS
- HuggingFace
- human
- ID
- identify
- if
- illustrates
- image
- images
- implementation
- implements
- import
- importance
- important
- improvement
- in
- included
- Including
- incorporate
- increasing
- index
- indicate
- indicates
- industries
- industry
- information
- initiating
- Innovation
- input
- inputs
- inside
- insights
- install
- installed
- instance
- instructions
- insurance
- insurance industry
- integrate
- Intelligence
- interactions
- internal
- intervention
- into
- investment
- investment recommendations
- involved
- IT
- ITS
- itself
- Java
- jpg
- json
- Jupyter Notebook
- Key
- Know
- knowledge
- Labels
- language
- large
- Large enterprises
- Latency
- Leadership
- learning
- least
- Legal
- Leverage
- libraries
- Library
- License
- like
- LIMIT
- List
- Llama
- loads
- local
- location
- logic
- Lot
- Low
- machine
- machine learning
- made
- Main
- make
- Making
- many
- March
- Market
- market sentiment
- Market Trends
- mask
- matching
- Meet
- messages
- methods
- Metrics
- million
- ML
- model
- models
- moderate
- moderation
- module
- Monitor
- more
- multiple
- name
- Natural
- Natural Language
- Natural Language Processing
- necessary
- Need
- needed
- needs
- negative
- news
- next-generation
- nlp
- no
- notebook
- number
- numerous
- object
- objects
- obstacles
- obtaining
- of
- offer
- on
- ONE
- only
- open source
- optimal
- optimization
- Option
- Options
- or
- organization
- organizations
- OS
- Other
- out
- output
- outside
- over
- override
- own
- package
- packaged
- packages
- pandas
- papers
- Parallel
- parameter
- parameters
- part
- pass
- passed
- Passing
- path
- Pattern
- performance
- performing
- platform
- plato
- Plato Data Intelligence
- PlatoData
- Point
- Popular
- possible
- Post
- potential
- powered
- powerful
- predict
- Predictions
- preparing
- present
- presented
- previous
- Principal
- problems
- process
- processing
- produce
- Products
- Programming
- properties
- provide
- provided
- provides
- providing
- purpose
- Push
- Python
- pytorch
- quality
- question
- Questions
- range
- ranging
- Reading
- reasons
- receives
- Recipes
- recommendations
- recommended
- reducing
- related
- released
- relevant
- remains
- remarkable
- Reports
- repository
- request
- requests
- required
- research
- researchers
- Resources
- response
- responses
- responsible
- REST
- restricted
- result
- Results
- retain
- return
- Run
- running
- runs
- Safety
- sagemaker
- Scale
- scaling
- Search
- searching
- Section
- sections
- see
- send
- sent
- sentence
- sentiment
- serve
- serves
- Services
- serving
- session
- set
- setting
- settings
- should
- show
- Simple
- since
- single
- sizable
- Size
- Snapshot
- So
- solution
- Solutions
- some
- sophisticated
- Source
- Sources
- specialist
- specialized
- specific
- specified
- speed
- Spending
- started
- startup
- Startups
- Step
- Steps
- stopping
- storage
- stored
- stores
- String
- studio
- Successfully
- such
- Suffers
- summarize
- supplied
- supplying
- support
- Supports
- sydney
- system
- table
- Task
- tasks
- team
- techniques
- Technologies
- Technology
- that
- The
- The Source
- their
- Them
- then
- There.
- thereby
- therefore
- These
- this
- thought
- thought leadership
- throughput
- time
- to
- together
- tokenized
- tools
- trained
- Training
- Transparency
- Traveling
- Trends
- true
- turns
- two
- type
- under
- understand
- unique
- Universal
- until
- Update
- updated
- Updates
- uploaded
- URI
- us
- use
- use case
- used
- User
- users
- uses
- using
- utility
- value
- various
- VICUNA
- virginia
- vision
- wait
- want
- we
- web
- web services
- WELL
- What
- when
- which
- wide
- Wide range
- Wikipedia
- will
- with
- without
- Work
- worked
- worker
- workers
- workflow
- workflows
- working
- works
- would
- X
- you
- Your
- zephyrnet