Building a data platform involves various approaches, each with its unique blend of complexities and solutions. A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. In this post, we delve into a case study for a retail use case, exploring how the Data Build Tool (dbt) was used effectively within an AWS environment to build a high-performing, efficient, and modern data platform.
dbt is an open-source command line tool that enables data analysts and engineers to transform data in their warehouses more effectively. It does this by helping teams handle the T in ETL (extract, transform, and load) processes. It allows users to write data transformation code, run it, and test the output, all within the framework it provides. dbt enables you to write SQL select statements, and then it manages turning these select statements into tables or views in Amazon Redshift.
Use case
The Enterprise Data Analytics group of a large jewelry retailer embarked on their cloud journey with AWS in 2021. As part of their cloud modernization initiative, they sought to migrate and modernize their legacy data platform. The aim was to bolster their analytical capabilities and improve data accessibility while ensuring a quick time to market and high data quality, all with low total cost of ownership (TCO) and no need for additional tools or licenses.
dbt emerged as the perfect choice for this transformation within their existing AWS environment. This popular open-source tool for data warehouse transformations won out over other ETL tools for several reasons. dbt’s SQL-based framework made it straightforward to learn and allowed the existing development team to scale up quickly. The tool also offered desirable out-of-the-box features like data lineage, documentation, and unit testing. A crucial advantage of dbt over stored procedures was the separation of code from data—unlike stored procedures, dbt doesn’t store the code in the database itself. This separation further simplifies data management and enhances the system’s overall performance.
Let’s explore the architecture and learn how to build this use case using AWS Cloud services.
Solution overview
The following architecture demonstrates the data pipeline built on dbt to manage the Redshift data warehouse ETL process.
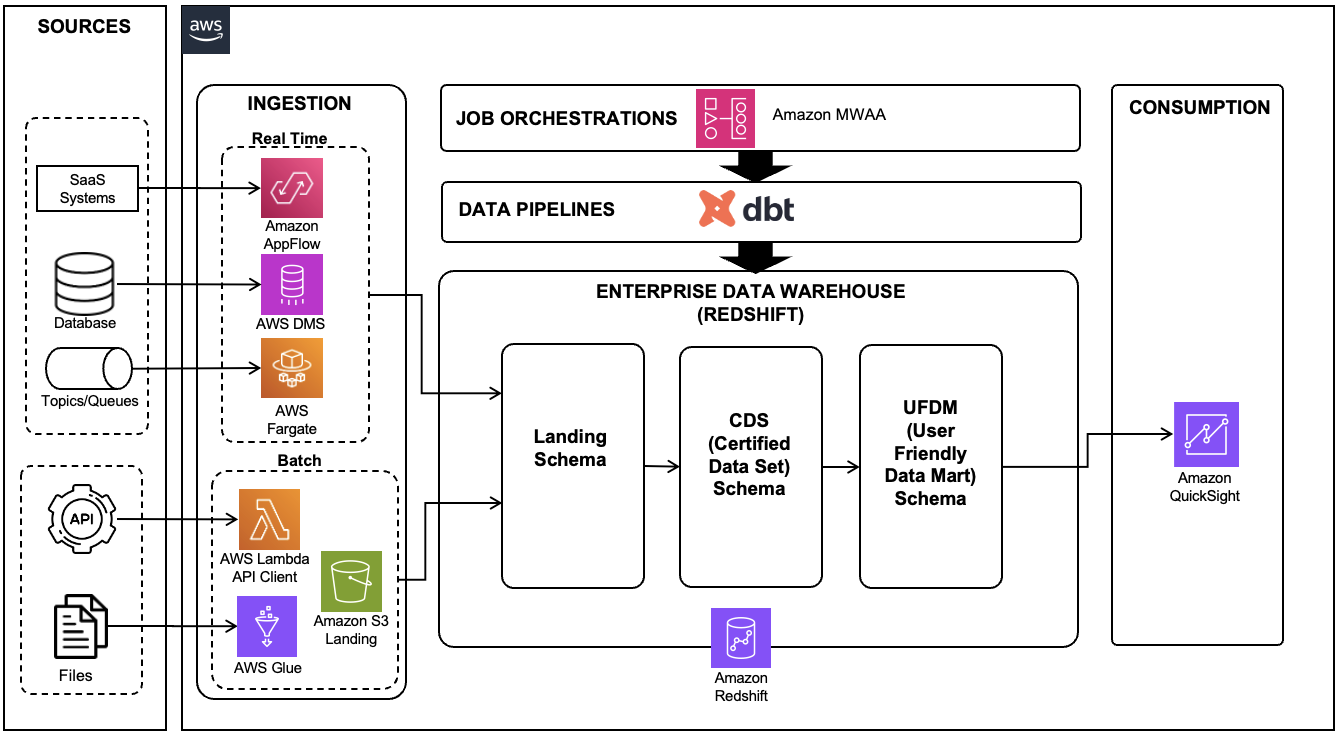
Figure 1 : Modern data platform using AWS Data Services and dbt
This architecture consists of the following key services and tools:
- Amazon Redshift was utilized as the data warehouse for the data platform, storing and processing vast amounts of structured and semi-structured data
- Amazon QuickSight served as the business intelligence (BI) tool, allowing the business team to create analytical reports and dashboards for various business insights
- AWS Database Migration Service (AWS DMS) was employed to perform change data capture (CDC) replication from various source transactional databases
- AWS Glue was put to work, loading files from the SFTP location to the Amazon Simple Storage Service (Amazon S3) landing bucket and subsequently to the Redshift landing schema
- AWS Lambda functioned as a client program, calling third-party APIs and loading the data into Redshift tables
- AWS Fargate, a serverless container management service, was used to deploy the consumer application for source queues and topics
- Amazon Managed Workflows for Apache Airflow (Amazon MWAA) was used to orchestrate different tasks of dbt pipelines
- dbt, an open-source tool, was employed to write SQL-based data pipelines for data stored in Amazon Redshift, facilitating complex transformations and enhancing data modeling capabilities
Let’s take a closer look at each component and how they interact in the overall architecture to transform raw data into insightful information.
Data sources
As part of this data platform, we are ingesting data from diverse and varied data sources, including:
- Transactional databases – These are active databases that store real-time data from various applications. The data typically encompasses all transactions and operations that the business engages in.
- Queues and topics – Queues and topics come from various integration applications that generate data in real time. They represent an instantaneous stream of information that can be used for real-time analytics and decision-making.
- Third-party APIs – These provide analytics and survey data related to ecommerce websites. This could include details like traffic metrics, user behavior, conversion rates, customer feedback, and more.
- Flat files – Other systems supply data in the form of flat files of different formats. These files, stored in an SFTP location, might contain records, reports, logs, or other kinds of raw data that can be further processed and analyzed.
Data ingestion
Data from various sources are grouped into two major categories: real-time ingestion and batch ingestion.
Real-time ingestion uses the following services:
- AWS DMS – AWS DMS is used to create CDC replication pipelines from OLTP (Online Transaction Processing) databases. The data is loaded into Amazon Redshift in near-real time to ensure that the most recent information is available for analysis. You can also use Amazon Aurora zero-ETL integration with Amazon Redshift to ingest data directly from OLTP databases to Amazon Redshift.
- Fargate –Fargate is used to deploy Java consumer applications that ingest data from source topics and queues in real time. This real-time data consumption can help the business make immediate and data-informed decisions. You can also use Amazon Redshift Streaming Ingestion to ingest data from streaming engines like Amazon Kinesis Data Streams or Amazon Managed Streaming for Apache Kafka (Amazon MSK) into Amazon Redshift.
Batch ingestion uses the following services:
- Lambda – Lambda is used as a client for calling third-party APIs and loading the resultant data into Redshift tables. This process has been scheduled to run daily, ensuring a consistent batch of fresh data for analysis.
- AWS Glue – AWS Glue is used to load files into Amazon Redshift through the S3 data lake. You can also use features like auto-copy from Amazon S3 (feature under preview) to ingest data from Amazon S3 to Amazon Redshift. However, the focus of this post is more on data processing within Amazon Redshift, rather than on the data loading process. Data ingestion, whether real time or batch, forms the basis of any effective data analysis, enabling organizations to gather information from diverse sources and use it for insightful decision-making.
Data warehousing using Amazon Redshift
In Amazon Redshift, we’ve established three schemas, each serving as a different layer in the data architecture:
- Landing layer – This is where all data ingested by our services initially lands. It’s raw, unprocessed data straight from the source.
- Certified dataset (CDS) layer – This is the next stage, where data from the landing layer undergoes cleaning, normalization, and aggregation. The cleansed and processed data is stored in this certified dataset schema. It serves as a reliable, organized source for downstream data analysis.
- User-friendly data mart (UFDM) layer – This final layer uses data from the CDS layer to create data mart tables. These are specifically tailored to support BI reports and dashboards as per the business requirements. The goal of this layer is to present the data in a way that is most useful and accessible for end-users.
This layered approach to data management allows for efficient and organized data processing, leading to more accurate and meaningful insights.
Data pipeline
dbt, an open-source tool, can be installed in the AWS environment and set up to work with Amazon MWAA. We store our code in an S3 bucket and orchestrate it using Airflow’s Directed Acyclic Graphs (DAGs). This setup facilitates our data transformation processes in Amazon Redshift after the data is ingested into the landing schema.
To maintain modularity and handle specific domains, we create individual dbt projects. The nature of the data reporting—real-time or batch—affects how we define our dbt materialization. For real-time reporting, we define materialization as a view, loading data into the landing schema using AWS DMS from database updates or from topic or queue consumers. For batch pipelines, we define materialization as a table, allowing data to be loaded from various types of sources.
In some instances, we have had to build data pipelines that extend from the source system all the way to the UFDM layer. This can be accomplished using Airflow DAGs, which we discuss further in the next section.
To wrap up, it’s worth mentioning that we deploy a dbt webpage using a Lambda function and enable a URL for this function. This webpage serves as a hub for documentation and data lineage, further bolstering the transparency and understanding of our data processes.
ETL job orchestration
In our data pipeline, we follow these steps for job orchestration:
- Establish a new Amazon MWAA environment. This environment serves as the central hub for orchestrating our data pipelines.
- Install dbt in the new Airflow environment by adding the following dependency to your
requirements.txt: - Develop DAGs with specific tasks that call upon dbt commands to carry out the necessary transformations. This step involves structuring our workflows in a way that captures dependencies among tasks and ensures that tasks run in the correct order. The following code shows how to define the tasks in the DAG:
- Create DAGs that solely focus on dbt transformation. These DAGs handle the transformation process within our data pipelines, harnessing the power of dbt to convert raw data into valuable insights.
The following image shows how this workflow would be seen on the Airflow UI . 
- Create DAGs with AWS Glue for ingestion. These DAGs use AWS Glue for data ingestion tasks. AWS Glue is a fully managed ETL service that makes it easy to prepare and load data for analysis. We create DAGs that orchestrate AWS Glue jobs for extracting data from various sources, transforming it, and loading it into our data warehouse.
The following image shows how this workflow would be seen on the Airflow UI.

- Create DAGs with Lambda for ingestion. Lambda lets us run code without provisioning or managing servers. These DAGs use Lambda functions to call third-party APIs and load data into our Redshift tables, which can be scheduled to run at certain intervals or in response to specific events.
The following image shows how this workflow would be seen on the Airflow UI.

We now have a comprehensive, well-orchestrated process that uses a variety of AWS services to handle different stages of our data pipeline, from ingestion to transformation.
Conclusion
The combination of AWS services and the dbt open-source project provides a powerful, flexible, and scalable solution for building modern data platforms. It’s a perfect blend of manageability and functionality, with its easy-to-use, SQL-based framework and features like data quality checks, configurable load types, and detailed documentation and lineage. Its principles of “code separate from data” and reusability make it a convenient and efficient tool for a wide range of users. This practical use case of building a data platform for a retail organization demonstrates the immense potential of AWS and dbt for transforming data management and analytics, paving the way for faster insights and informed business decisions.
For more information about using dbt with Amazon Redshift, see Manage data transformations with dbt in Amazon Redshift.
About the Authors
 Prantik Gachhayat is an Enterprise Architect at Infosys having experience in various technology fields and business domains. He has a proven track record helping large enterprises modernize digital platforms and delivering complex transformation programs. Prantik specializes in architecting modern data and analytics platforms in AWS. Prantik loves exploring new tech trends and enjoys cooking.
Prantik Gachhayat is an Enterprise Architect at Infosys having experience in various technology fields and business domains. He has a proven track record helping large enterprises modernize digital platforms and delivering complex transformation programs. Prantik specializes in architecting modern data and analytics platforms in AWS. Prantik loves exploring new tech trends and enjoys cooking.
 Ashutosh Dubey is a Senior Partner Solutions Architect and Global Tech leader at Amazon Web Services based out of New Jersey, USA. He has extensive experience specializing in the Data and Analytics and AIML field including generative AI, contributed to the community by writing various tech contents, and has helped Fortune 500 companies in their cloud journey to AWS.
Ashutosh Dubey is a Senior Partner Solutions Architect and Global Tech leader at Amazon Web Services based out of New Jersey, USA. He has extensive experience specializing in the Data and Analytics and AIML field including generative AI, contributed to the community by writing various tech contents, and has helped Fortune 500 companies in their cloud journey to AWS.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/create-a-modern-data-platform-using-the-data-build-tool-dbt-in-the-aws-cloud/
- :has
- :is
- :where
- $UP
- 1
- 100
- 11
- 12
- 17
- 20
- 2021
- 500
- 54
- 7
- 8
- a
- About
- accessibility
- accessible
- accomplished
- accurate
- across
- active
- acyclic
- adding
- Additional
- ADvantage
- After
- aggregation
- AI
- aim
- AIML
- All
- All Transactions
- allowed
- Allowing
- allows
- already
- also
- Amazon
- Amazon Web Services
- among
- amounts
- an
- analysis
- Analysts
- Analytical
- analytics
- analyzed
- and
- any
- Apache
- APIs
- Application
- applications
- approach
- approaches
- architecture
- ARE
- AS
- At
- Aurora
- available
- AWS
- AWS Glue
- based
- basis
- BE
- been
- behavior
- Blend
- bolster
- bolstering
- build
- Building
- built
- business
- business intelligence
- by
- call
- calling
- CAN
- capabilities
- capture
- captures
- carry
- case
- case study
- categories
- CDC
- CDS
- central
- certain
- Certified
- change
- check
- checking
- Checks
- choice
- Cleaning
- client
- closer
- Cloud
- cloud services
- code
- combination
- come
- community
- Companies
- complex
- complexities
- component
- comprehensive
- consistent
- consists
- consumer
- Consumers
- consumption
- contain
- Container
- contents
- contributed
- Convenient
- Conversion
- convert
- cooking
- correct
- Cost
- could
- create
- crucial
- customer
- DAG
- daily
- dashboards
- data
- data analysis
- Data Analytics
- Data Lake
- data management
- Data Platform
- data processing
- data quality
- data warehouse
- Database
- databases
- Decision Making
- decisions
- define
- delivering
- delve
- demonstrates
- dependencies
- Dependency
- deploy
- detailed
- details
- Development
- development team
- different
- digital
- digital platforms
- directed
- directly
- discuss
- diverse
- documentation
- does
- Doesn’t
- domains
- each
- ease
- easy
- easy-to-use
- echo
- ecommerce
- Effective
- effectively
- efficient
- else
- embarked
- emerged
- employed
- enable
- enables
- enabling
- encompasses
- engages
- Engineers
- Engines
- Enhances
- enhancing
- ensure
- ensures
- ensuring
- Enterprise
- enterprises
- Environment
- established
- Ether (ETH)
- events
- existing
- experience
- explore
- Exploring
- extend
- extensive
- Extensive Experience
- extract
- facilitates
- facilitating
- faster
- Feature
- Features
- feedback
- field
- Fields
- Files
- final
- flat
- flexible
- flow
- Focus
- follow
- following
- For
- form
- formats
- forms
- Fortune
- Framework
- fresh
- from
- fully
- function
- functionality
- functions
- further
- gather
- generate
- generative
- Generative AI
- Global
- goal
- graphs
- Group
- had
- handle
- Harnessing
- Have
- having
- he
- help
- helped
- helping
- High
- high-performing
- How
- How To
- However
- http
- HTTPS
- Hub
- if
- image
- immediate
- immense
- improve
- in
- include
- Including
- individual
- information
- informed
- Infosys
- initially
- Initiative
- insightful
- insights
- install
- installed
- instances
- integration
- Intelligence
- interact
- into
- involves
- IT
- ITS
- itself
- Java
- Jersey
- jewelry
- Job
- Jobs
- journey
- jpg
- Key
- lake
- landing
- lands
- large
- Large enterprises
- layer
- layered
- layers
- leader
- leading
- LEARN
- Legacy
- Lets
- licenses
- like
- Line
- lineage
- listing
- load
- loading
- location
- Look
- loves
- Low
- made
- maintain
- maintaining
- major
- make
- MAKES
- manage
- managed
- management
- manages
- managing
- Market
- meaningful
- Metrics
- might
- migrate
- migration
- modeling
- Modern
- modernization
- modernize
- more
- most
- multiple
- Nature
- necessary
- Need
- New
- New Jersey
- New Tech
- next
- no
- now
- of
- offered
- on
- online
- open source
- Operations
- or
- orchestration
- order
- organization
- organizations
- Organized
- Other
- our
- out
- output
- over
- overall
- ownership
- package
- part
- partner
- Paving
- per
- perfect
- perform
- performance
- pipeline
- platform
- Platforms
- plato
- Plato Data Intelligence
- PlatoData
- Popular
- Post
- potential
- power
- powerful
- Practical
- Prepare
- present
- Preview
- principles
- procedures
- process
- processed
- processes
- processing
- Program
- Programs
- project
- projects
- properly
- proven
- provide
- provides
- put
- Python
- quality
- Quick
- quickly
- range
- Rates
- rather
- Raw
- raw data
- real
- real-time
- real-time data
- reasons
- recent
- record
- records
- related
- reliable
- replication
- Reporting
- Reports
- represent
- required
- Requirements
- response
- resultant
- retail
- retailer
- Run
- scalable
- Scale
- scheduled
- Section
- see
- seen
- senior
- separate
- served
- Serverless
- Servers
- serves
- service
- Services
- serving
- set
- setup
- several
- Shows
- Simple
- solely
- solution
- Solutions
- some
- sought
- Source
- Sources
- specializes
- specializing
- specific
- specifically
- SQL
- Stage
- stages
- start
- statements
- Step
- Steps
- storage
- store
- stored
- straight
- straightforward
- stream
- streaming
- structured
- structuring
- Study
- Subsequently
- such
- supply
- support
- Survey
- system
- Systems
- T
- table
- tailored
- Take
- targeting
- Task
- tasks
- team
- teams
- tech
- Technology
- test
- Testing
- than
- that
- The
- The Source
- their
- then
- These
- they
- third-party
- this
- three
- Through
- time
- to
- tool
- tools
- topic
- Topics
- Total
- track
- track record
- traffic
- transaction
- transactional
- Transactions
- Transform
- Transformation
- transformations
- transforming
- Transparency
- Trends
- Turning
- two
- types
- typically
- ui
- under
- undergoes
- understanding
- unique
- unit
- Updates
- upon
- URL
- us
- USA
- use
- use case
- used
- useful
- User
- users
- uses
- using
- utilized
- Valuable
- variety
- various
- Vast
- verify
- version
- View
- views
- Warehouse
- Warehousing
- was
- Way..
- we
- web
- web services
- websites
- whether
- which
- while
- wide
- Wide range
- with
- within
- without
- Won
- Work
- workflow
- workflows
- worth
- would
- wrap
- write
- writing
- you
- zephyrnet