Image by Author
While searching for a particular topic in a book, we will first visit the index page (which is present at the start of that book) and find which page number contains our topic of interest. Now, imagine how inconvenient it is to find a particular topic in a book without the index page. For this, we have to search every page in the book, which is very time-consuming and frustrating.
A similar issue also occurs in SQL Server when it retrieves data from the database. To overcome this, SQL server also uses indexing which speeds up the data retrieval process, and in this article, we will cover that part. We will cover why indexing is needed and how we can effectively create and delete indexes. The prerequisite of this tutorial is the basic knowledge of SQL commands.
Indexing is a schema object that uses a pointer to retrieve data from the rows, which reduces the I/O(Input/Output) time to locate the data. Indexing can be applied to one or more columns we want to search. They store the column in a separate data structure called B-Tree. One of the main advantages of B-Tree is that it stores the data in sorted order.
If you are wondering why the data can be retrieved faster if it is sorted, then you must read about Linear Search vs Binary Search.
Indexing is one of the most famous methods to improve the performance of SQL queries. They are small, fast and remarkably optimized for relational tables. When we want to search a row without indexing, the SQL performs a full-table scan linearly. In other words, SQL has to scan every row to find the matching conditions, which is very time-consuming. On the other hand, indexing keeps the data sorted, as discussed above.
But we should also be careful, indexing creates a separate data structure which requires extra space, and that can become problematic when the database is large. For good practice, indexing is effective only on frequently used columns and can be avoided on rarely used columns. Below are some scenarios in which indexing might be helpful,
- Number of rows must be (>10000).
- The required column contains a large number of values.
- The required column must not contain a large number of NULL values.
- It is helpful if we frequently sort or group data based on particular columns. Indexing quickly retrieves the sorted data rather than performing a full scan.
And indexing can be avoided when,
- The table is small.
- Or when the values of the column are rarely used.
- Or when the values of the columns are frequently changing.
There may also be a chance when the optimizer detects that a full-table scan takes less time than the indexed table, then the indexing may not be used, even if it exists. This can happen when the table is small, or the column is frequently updated.
Before starting, you must set up MySQL Workbench on your PC to easily follow the tutorial. You can refer to this youtube video for setting up your workbench.
After setting up your workbench, we will create some random data from which we can execute our queries.
Creating Table:
-- Create a table to hold the random data CREATE TABLE employee_info (id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(100), age INT, email VARCHAR(100));
Inserting Data:
-- Insert random data into the table INSERT INTO employee_info (name, age, email)
SELECT CONCAT('User', LPAD(ROW_NUMBER() OVER (), 5, '0')), FLOOR(RAND() * 50) + 20, CONCAT('user', LPAD(ROW_NUMBER() OVER (), 5, '0'), '@xyz.com')
FROM information_schema.tables
LIMIT 100;
It will create a table named employee_info having attributes like name, age and email.
Show the Data:
SELECT *
FROM employee_info;
Output:
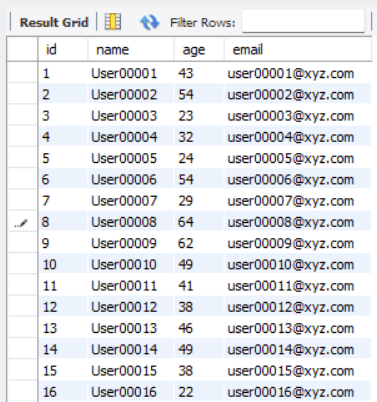
Fig. 1 Sample Database | Image by Author
For creating an index, we can use the CREATE command like that,
Syntax:
CREATE INDEX index_name ON TABLE_NAME (COLUMN_NAME);
In the above query, index_name is the name of the index, table_name is the name of the table and the column_name is the name of the column on which we want to apply indexing.
Ex-
CREATE INDEX age_index ON employee_info (age);
We can also create indexes for multiple columns in the same table,
CREATE INDEX index_name ON TABLE_NAME (col1, col2, col3, ....);
Unique Index: We can also create a unique index for a particular column that doesn’t allow duplicate values to be stored in that column. This maintains the integrity of the data and also further improves the performance.
CREATE UNIQUE INDEX index_name ON TABLE_NAME (COLUMN_NAME);
Note: Indexes can be automatically created for PRIMARY_KEY and UNIQUE columns. We don’t have to create them manually.
Deleting an Index:
We can use the DROP command to delete a particular index from the table.
DROP INDEX index_name ON TABLE_NAME;
We need to specify the index and table names to delete the index.
Show Indexes:
You can also see all the indexes present in your table.
Syntax:
SHOW INDEX
FROM TABLE_NAME;
Ex-
SHOW INDEX
FROM employee_info;
Output:

The below command creates a new index in the existing table.
Syntax:
ALTER TABLE TABLE_NAME ADD INDEX index_name (col1, col2, col3, ...);
Note: The ALTER is not a standard command of ANSI SQL. So it may vary among other databases.
For ex-
ALTER TABLE employee_info ADD INDEX name_index (name); SHOW INDEX
FROM employee_info;
Output:

In the above example, we have created a new index in the existing table. But we cannot modify an existing index. For this, we must first drop the old index and then create a new modified one.
For ex-
DROP INDEX name_index ON employee_info; CREATE INDEX name_index ON employee_info (name, email); SHOW INDEX
FROM employee_info ;
Output:

In this article, we have covered a basic understanding of SQL Indexing. It is also advised to keep indexing narrow, i.e., limited to a few columns, because more indexing can negatively impact performance. Indexing speeds us the SELECT queries and WHERE clause but slows down the insert and update statements. Therefore, applying indexing only on the frequently used columns is a good practice.
Until then, keep reading and keep learning.
Aryan Garg is a B.Tech. Electrical Engineering student, currently in the final year of his undergrad. His interest lies in the field of Web Development and Machine Learning. He have pursued this interest and am eager to work more in these directions.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://www.kdnuggets.com/2023/07/database-optimization-exploring-indexes-sql.html?utm_source=rss&utm_medium=rss&utm_campaign=database-optimization-exploring-indexes-in-sql
- :has
- :is
- :not
- :where
- $UP
- 1
- 10
- 100
- 11
- 20
- 50
- 7
- 9
- a
- About
- above
- add
- advantages
- age
- All
- allow
- also
- am
- among
- an
- and
- applied
- Apply
- Applying
- ARE
- article
- AS
- At
- attributes
- automatically
- avoided
- based
- basic
- BE
- because
- become
- below
- book
- but
- by
- called
- CAN
- cannot
- careful
- Chance
- changing
- Column
- Columns
- COM
- conditions
- contains
- cover
- covered
- create
- created
- creates
- Creating
- Currently
- data
- Database
- databases
- Development
- discussed
- Doesn’t
- don
- down
- Drop
- e
- eager
- easily
- Effective
- effectively
- electrical engineering
- Engineering
- Ether (ETH)
- Even
- Every
- example
- execute
- existing
- exists
- Exploring
- extra
- famous
- FAST
- faster
- few
- field
- final
- Find
- First
- follow
- For
- frequently
- from
- frustrating
- full
- further
- good
- Group
- hand
- happen
- Have
- having
- he
- helpful
- his
- hold
- How
- HTTPS
- i
- ID
- if
- image
- imagine
- Impact
- improve
- improves
- in
- In other
- index
- indexed
- indexes
- integrity
- interest
- into
- issue
- IT
- KDnuggets
- Keep
- Key
- knowledge
- large
- learning
- less
- lies
- like
- LIMIT
- Limited
- machine
- machine learning
- Main
- maintains
- manually
- matching
- May..
- methods
- might
- modified
- modify
- more
- most
- multiple
- must
- Must Read
- MySQL
- name
- Named
- names
- narrow
- Need
- needed
- negatively
- New
- now
- number
- object
- of
- Old
- on
- ONE
- only
- optimization
- optimized
- or
- order
- Other
- our
- over
- Overcome
- page
- part
- particular
- PC
- performance
- performing
- performs
- plato
- Plato Data Intelligence
- PlatoData
- practice
- present
- primary
- process
- queries
- quickly
- random
- rarely
- rather
- Read
- Reading
- reduces
- required
- requires
- ROW
- same
- scan
- scenarios
- Search
- searching
- see
- separate
- set
- setting
- should
- show
- similar
- slows
- small
- So
- some
- Space
- speeds
- SQL
- standard
- start
- Starting
- statements
- store
- stored
- stores
- structure
- Student
- table
- takes
- tech
- than
- that
- The
- Them
- then
- therefore
- These
- they
- this
- time
- time-consuming
- to
- topic
- tutorial
- understanding
- unique
- Update
- updated
- us
- use
- used
- User
- uses
- Values
- very
- Video
- Visit
- vs
- want
- we
- web
- Web development
- when
- which
- why
- Wikipedia
- will
- without
- wondering
- words
- Work
- year
- you
- Your
- youtube
- zephyrnet