Today, we are excited to announce that the Falcon 180B foundation model developed by Technology Innovation Institute (TII) and trained on Amazon SageMaker is available for customers through Amazon SageMaker JumpStart to deploy with one-click for running inference. With a 180-billion-parameter size and trained on a massive 3.5-trillion-token dataset, Falcon 180B is the largest and one of the most performant models with openly accessible weights. You can try out this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. In this post, we walk through how to discover and deploy the Falcon 180B model via SageMaker JumpStart.
What is Falcon 180B
Falcon 180B is a model released by TII that follows previous releases in the Falcon family. It’s a scaled-up version of Falcon 40B, and it uses multi-query attention for better scalability. It’s an auto-regressive language model that uses an optimized transformer architecture. It was trained on 3.5 trillion tokens of data, primarily consisting of web data from RefinedWeb (approximately 85%). The model has two versions: 180B and 180B-Chat. 180B is a raw, pre-trained model, which should be further fine-tuned for most use cases. 180B-Chat is better suited to taking generic instructions. The Chat model has been fine-tuned on chat and instructions datasets together with several large-scale conversational datasets.
The model is made available under the Falcon-180B TII License and Acceptable Use Policy.
Falcon 180B was trained by TII on Amazon SageMaker, on a cluster of approximately 4K A100 GPUs. It used a custom distributed training codebase named Gigatron, which uses 3D parallelism with ZeRO, and custom, high-performance Triton kernels. The distributed training architecture used Amazon Simple Storage Service (Amazon S3) as the sole unified service for data loading and checkpoint writing and reading, which particularly contributed to the workload reliability and operational simplicity.
What is SageMaker JumpStart
With SageMaker JumpStart, ML practitioners can choose from a growing list of best-performing foundation models. ML practitioners can deploy foundation models to dedicated SageMaker instances within a network isolated environment, and customize models using Amazon SageMaker for model training and deployment.
You can now discover and deploy Falcon 180B with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your VPC controls, helping ensure data security. Falcon 180B is discoverable and can be deployed in Regions where the requisite instances are available. At present, ml.p4de instances are available in US East (N. Virginia) and US West (Oregon).
Discover models
You can access the foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
In SageMaker Studio, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and prebuilt solutions, under Prebuilt and automated solutions.
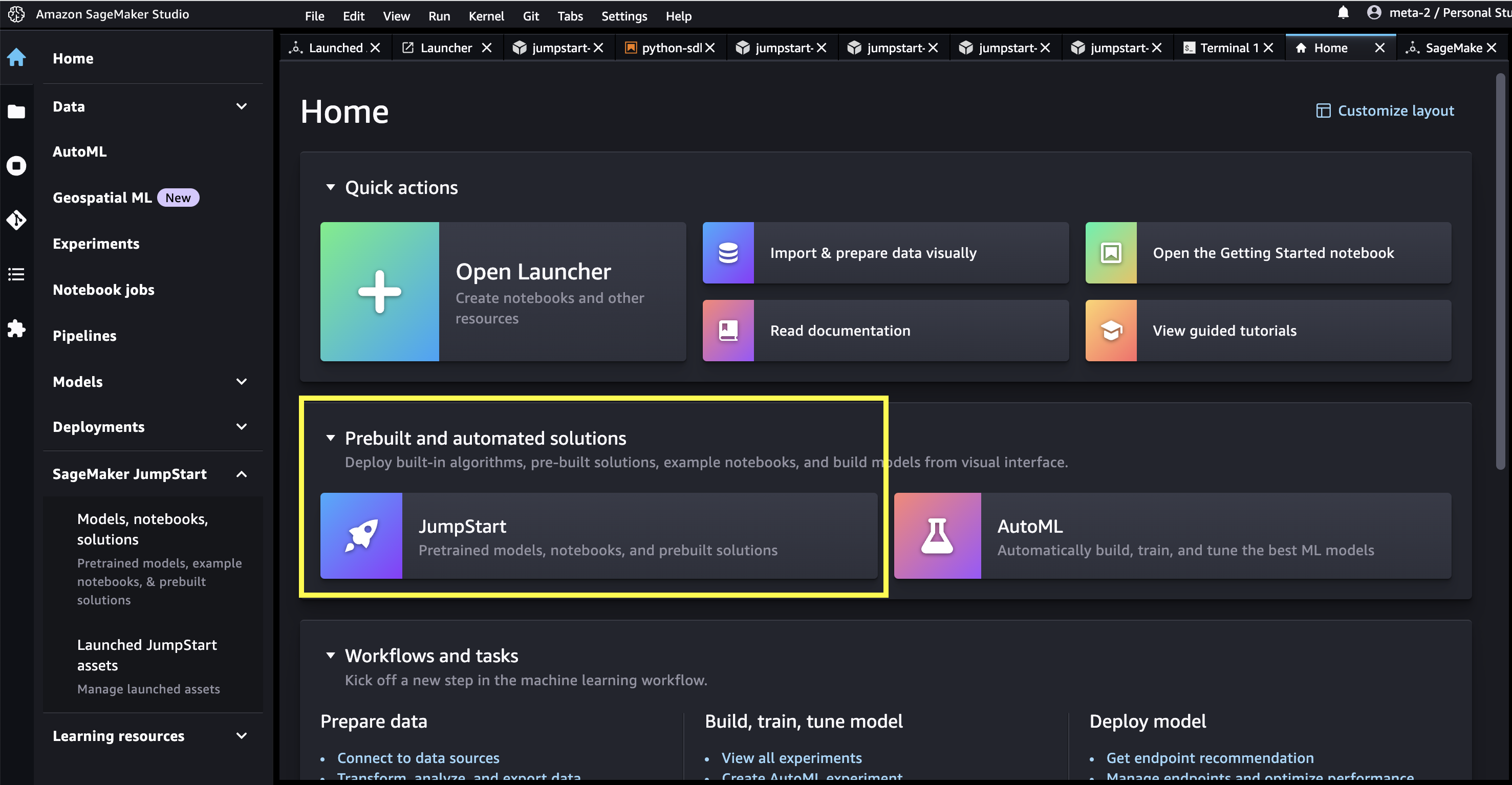
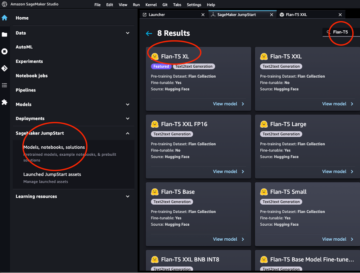
From the SageMaker JumpStart landing page, you can browse for solutions, models, notebooks, and other resources. You can find Falcon 180B in the Foundation Models: Text Generation carousel.

You can also find other model variants by choosing Explore all Text Generation Models or searching for Falcon.

You can choose the model card to view details about the model such as license, data used to train, and how to use. You will also find two buttons, Deploy and Open Notebook, which will help you use the model (the following screenshot shows the Deploy option).

Deploy models
When you choose Deploy, the model deployment will start. Alternatively, you can deploy through the example notebook that shows up by choosing Open Notebook. The example notebook provides end-to-end guidance on how to deploy the model for inference and clean up resources.
To deploy using a notebook, we start by selecting an appropriate model, specified by the model_id. You can deploy any of the selected models on SageMaker with the following code:
This deploys the model on SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel. To learn more, refer to the API documentation. After it’s deployed, you can run inference against the deployed endpoint through a SageMaker predictor. See the following code:
Inference parameters control the text generation process at the endpoint. The max new tokens control refers to the size of the output generated by the model. Note that this is not the same as the number of words because the vocabulary of the model is not the same as the English language vocabulary and each token may not be an English language word. Temperature controls the randomness in the output. Higher temperature results in more creative and hallucinated outputs. All the inference parameters are optional.
This 180B parameter model is 335GB and requires even more GPU memory to sufficiently perform inference in 16-bit precision. Currently, JumpStart only supports this model on ml.p4de.24xlarge instances. It is possible to deploy an 8-bit quantized model on a ml.p4d.24xlarge instance by providing the env={"HF_MODEL_QUANTIZE": "bitsandbytes"} keyword argument to the JumpStartModel constructor and specifying instance_type="ml.p4d.24xlarge" to the deploy method. However, please note that per-token latency is approximately 5x slower for this quantized configuration.
The following table lists all the Falcon models available in SageMaker JumpStart along with the model IDs, default instance types, maximum number of total tokens (sum of the number of input tokens and number of generated tokens) supported, and the typical response latency per token for each of these models.
| Model Name | Model ID | Default Instance Type | Max Total Tokens | Latency per Token* |
| Falcon 7B | huggingface-llm-falcon-7b-bf16 |
ml.g5.2xlarge | 2048 | 34 ms |
| Falcon 7B Instruct | huggingface-llm-falcon-7b-instruct-bf16 |
ml.g5.2xlarge | 2048 | 34 ms |
| Falcon 40B | huggingface-llm-falcon-40b-bf16 |
ml.g5.12xlarge | 2048 | 57 ms |
| Falcon 40B Instruct | huggingface-llm-falcon-40b-instruct-bf16 |
ml.g5.12xlarge | 2048 | 57 ms |
| Falcon 180B | huggingface-llm-falcon-180b-bf16 |
ml.p4de.24xlarge | 2048 | 45 ms |
| Falcon 180B Chat | huggingface-llm-falcon-180b-chat-bf16 |
ml.p4de.24xlarge | 2048 | 45 ms |
*per-token latency is provided for the median response time of the example prompts provided in this blog; this value will vary based on length of input and output sequences.
Inference and example prompts for Falcon 180B
Falcon models can be used for text completion for any piece of text. Through text generation, you can perform a variety of tasks, such as answering questions, language translation, sentiment analysis, and many more. The endpoint accepts the following input payload schema:
You can explore the definition of these client parameters and their default values within the text-generation-inference repository.
The following are some sample example prompts and the text generated by the model. All outputs here are generated with inference parameters {"max_new_tokens": 768, "stop": ["<|endoftext|>", "###"]}.
Building a website can be done in 10 simple steps:
You may notice this pretrained model generates long text sequences that are not necessarily ideal for dialog use cases. Before we show how the fine-tuned chat model performs for a larger set of dialog-based prompts, the next two examples illustrate how to use Falcon models with few-shot in-context learning, where we provide training samples available to the model. Note that “few-shot learning” does not adjust model weights — we only perform inference on the deployed model during this process while providing a few examples within the input context to help guild model output.
Inference and example prompts for Falcon 180B-Chat
With Falcon 180B-Chat models, optimized for dialogue use cases, the input to the chat model endpoints may contain previous history between the chat assistant and the user. You can ask questions contextual to the conversation that has happened so far. You can also provide the system configuration, such as personas, which define the chat assistant’s behavior. Input payload to the endpoint is the same as the Falcon 180B model except the inputs string value should use the following format:
The following are some sample example prompts and the text generated by the model. All outputs are generated with inference parameters {"max_new_tokens":256, "stop": ["nUser:", "<|endoftext|>", " User:", "###"]}.
In the following example, the user has had a conversation with the assistant about tourist sites in Paris. Next, the user is inquiring about the first option recommended by the chat assistant.
Clean up
After you’re done running the notebook, make sure to delete all resources that you created in the process so your billing is stopped. Use the following code:
Conclusion
In this post, we showed you how to get started with Falcon 180B in SageMaker Studio and deploy the model for inference. Because foundation models are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case. Visit SageMaker JumpStart in SageMaker Studio now to get started.
Resources
About the Authors
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker JumpStart and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Olivier Cruchant is a Principal Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Principal Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
 Karl Albertsen leads Amazon SageMaker’s foundation model hub, algorithms, and partnerships teams.
Karl Albertsen leads Amazon SageMaker’s foundation model hub, algorithms, and partnerships teams.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- ChartPrime. Elevate your Trading Game with ChartPrime. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/falcon-180b-foundation-model-from-tii-is-now-available-via-amazon-sagemaker-jumpstart/
- :has
- :is
- :not
- :where
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 150
- 20
- 25
- 26
- 3d
- 4k
- 7
- 8
- 9
- a
- A100
- About
- Accepts
- access
- accessible
- Achieve
- active
- add
- Additionally
- address
- After
- against
- algorithms
- All
- allows
- along
- also
- always
- am
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- an
- analysis
- and
- and infrastructure
- Announce
- Another
- answer
- any
- anyone
- appealing
- applications
- applied
- appropriate
- approximately
- architecture
- ARE
- argument
- Art
- article
- AS
- ask
- Assistant
- At
- attention
- attract
- attraction
- Automated
- available
- avenues
- AWS
- based
- battery
- Bayesian
- BE
- beautiful
- because
- been
- before
- behavior
- Better
- between
- billing
- Blog
- boasts
- browser
- builder
- builders
- Building
- business
- but
- by
- cafes
- CAN
- capability
- card
- carousel
- case
- cases
- cell
- change
- check
- Choose
- choosing
- chosen
- City
- Classify
- Cluster
- Cms
- code
- Codebase
- collection
- Columns
- COM
- combined
- Common
- company
- complete
- completion
- computer
- Computer Vision
- conferences
- Configuration
- configurations
- Consisting
- contact
- contain
- Container
- contains
- content
- content management
- context
- contextual
- continuously
- contributed
- control
- controls
- Conversation
- conversational
- Costs
- create
- created
- Creating
- Creative
- Cup
- Current
- Currently
- custom
- customer
- Customer Support
- Customers
- customization
- customize
- data
- data security
- datasets
- day
- de
- decision
- dedicated
- Default
- define
- definition
- demonstrate
- Depending
- deploy
- deployed
- deploying
- deployment
- deploys
- Design
- destination
- details
- Determine
- develop
- developed
- Development
- dialog
- dialogue
- different
- discover
- distributed
- distributed training
- do
- does
- domain
- Domain Name
- DOMAIN NAMES
- done
- dreams
- Duke
- duke university
- during
- each
- ease
- easily
- East
- easy
- enable
- enabling
- end-to-end
- Endpoint
- endpoints
- energy
- Engineering
- English
- ensure
- enterprises
- Environment
- especially
- Ether (ETH)
- Even
- example
- examples
- Except
- excited
- expertise
- explore
- Exploring
- expressed
- extension
- extensions
- extensive
- falcon
- family
- famous
- far
- fascinating
- Features
- few
- Find
- First
- Float
- following
- follows
- For
- format
- Former
- Foundation
- four
- FRAME
- France
- French
- friends
- from
- functioning
- further
- Gardens
- Gem
- generate
- generated
- generates
- generation
- get
- glass
- Go
- goal
- Goals
- going
- good
- got
- GPU
- GPUs
- great
- Growing
- guidance
- guild
- had
- happened
- hate
- Have
- having
- he
- Heart
- help
- helpful
- helping
- helps
- here
- Hidden
- hidden gem
- high-performance
- higher
- his
- history
- Home
- host
- hosting
- How
- How To
- However
- HTML
- HTTPS
- Hub
- i
- ICLR
- iconic
- ID
- ideal
- ids
- if
- illinois
- image
- images
- import
- impressive
- in
- include
- Including
- incredible
- information
- Infrastructure
- Innovation
- input
- inputs
- instance
- Institute
- instructions
- integrated
- interested
- interests
- Interface
- into
- isolated
- IT
- ITS
- jpg
- keyword
- known
- kyle
- landing
- landing page
- language
- large
- Large enterprises
- large-scale
- larger
- largest
- Latency
- latest
- launch
- Laws
- Layout
- Leads
- LEARN
- learning
- Length
- License
- light
- lined
- LINK
- links
- List
- Lists
- loading
- Long
- lower
- Luxembourg
- machine
- machine learning
- made
- make
- Making
- management
- management system
- manages
- many
- marvel
- Mass
- massive
- max
- maximum
- May..
- meaning
- means
- Media
- medieval
- Memory
- message
- method
- might
- Mixing
- mixture
- ML
- MLOps
- model
- models
- more
- most
- motion
- Museum
- Music
- my
- name
- Named
- names
- Navigate
- Navigation
- necessarily
- Need
- negative
- net
- network
- NeurIPS
- Neutral
- New
- next
- night
- no
- note
- notebook
- notebooks
- Notice..
- now
- number
- observers
- of
- Offers
- Oil
- Olivier
- on
- once
- ONE
- only
- openly
- operational
- optimized
- Option
- Options
- or
- Oregon
- Other
- out
- outlined
- output
- over
- page
- pages
- Palace
- papers
- parameter
- parameters
- paris
- Park
- particularly
- partnerships
- payment
- payment method
- People
- per
- perfect
- perform
- performance
- performs
- phd
- phone
- Physics
- piece
- plan
- plato
- Plato Data Intelligence
- PlatoData
- please
- positive
- possible
- Post
- Posts
- Precision
- Predictor
- preparing
- present
- previous
- primarily
- Principal
- problems
- process
- processes
- Product
- promote
- properly
- provide
- provided
- provider
- provides
- providing
- published
- purpose
- put
- Python
- Questions
- quickly
- randomness
- Raw
- Reading
- recipe
- recommended
- refer
- reference
- refers
- Regardless
- regions
- register
- registering
- registrar
- Registration
- relative
- relativity
- released
- Releases
- relevant
- reliability
- reliable
- remember
- repository
- represents
- requires
- requisite
- research
- researcher
- Resources
- response
- Results
- Rich
- Ride
- royalty
- Run
- running
- s
- sagemaker
- salt
- same
- Scalability
- scalable
- Scale
- Scientist
- sdk
- SEA
- Search
- searching
- Season
- Second
- Section
- secure
- security
- see
- seed
- selected
- selecting
- senior
- sentiment
- Series
- service
- Services
- set
- settings
- several
- Share
- shops
- Short
- should
- show
- showed
- Shows
- sign
- Simple
- simplicity
- simply
- single
- Sites
- Size
- Slowly
- small
- So
- so Far
- Social
- social media
- Social Media Posts
- Solutions
- some
- something
- Source
- Space
- specialist
- specified
- speed
- start
- started
- Startups
- States
- station
- statistical
- Steps
- Stop
- stopped
- storage
- store
- street
- String
- studio
- Stunning
- such
- support
- Supported
- Supports
- sure
- symbol
- system
- table
- Take
- taking
- tasks
- taste
- team
- teams
- Technology
- technology innovation
- template
- test
- text
- text generation
- that
- The
- the world
- their
- Them
- theme
- then
- theory
- There.
- These
- they
- Third
- this
- Through
- time
- Time Series
- to
- together
- token
- Tokens
- tool
- tools
- Total
- Tower
- Train
- trained
- Training
- transformer
- translate
- Translation
- Trillion
- trip
- Triton
- try
- tweet
- two
- type
- types
- typical
- ui
- under
- unified
- unique
- university
- until
- Uploading
- us
- use
- use case
- used
- User
- users
- uses
- using
- Vacuum
- value
- Values
- variety
- various
- version
- versions
- via
- Vibe
- Video
- Videos
- View
- views
- virginia
- vision
- Visit
- visitors
- visually
- walk
- want
- was
- watermark
- we
- web
- web hosting
- web services
- web-based
- Website
- week
- Weeks
- WELL
- West
- What
- What is
- when
- which
- while
- will
- windows
- with
- within
- without
- Word
- words
- world
- writing
- yes
- you
- Your
- zephyrnet
- zero