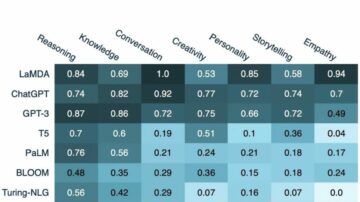
Survival analysis is a popular statistical method to investigate the expected duration of time until an event of interest occurs. We can recall it from medicine as patients’ survival time analysis, from engineering as reliability analysis or time-to-failure analysis, and from economics as duration analysis.
Besides these disciplines, survival analysis can also be used by HR teams to understand and create insights about their employee engagement, retention, and satisfaction — which is a hot topic nowadays 🌶 🌶 🌶
According to Achievers’ Employee Engagement and Retention Report, 52% of workers plan on looking for new jobs in 2021 and a recent survey participated by over 30,000 workers in 31 countries shows that 40% of employees are thinking of quitting their jobs. Forbes calls this trend “Turnover Tsunami”, mostly driven by pandemic burnout and Linkedin experts predict the arrival of big talent migration and discuss under #GreatResignation and #GreatReshuffle topics.
As always data can help to understand employee engagement & retention to reduce turnover and build more engaged, committed, and satisfied teams.
Some examples of what HR teams can dig in the employee turnover data are:
What are the certain characteristics of employees that stay/leave?
Are there similarities in attrition rates between groups of employees?
What are the probabilities of employees leave after a certain amount of time? (i.e. after 2 years)
In this article, we will build a survival analysis that helps to answer these questions. You can also check out the Jupyter Notebook on my GitHub for the full analysis. Let’s start! ☕️
Data Selection
We will use a fictional Employee Attrition & Performance dataset created by IBM available on Kaggle to explore employee attrition rates and important employee characteristics to predict survival duration of current employees.
Before modeling the survival function, let’s cover some basic terminology and concepts behind survival analysis.
Event is the experience of interest such as survive/death or stay/resign
Survival time is the duration until the event of interest occurs i.e. duration until an employee quits
Censorship Problem 🚫
Censored observationshappen in time-to-event data if the event has not been recorded for some individuals. This can be due to two main reasons:
Event has not yet occurred (i.e. survival time is unknown/misleading for those who are not resigned yet)
Missing data (i.e. dropout) or losing contact
There are three types of censorship:
Left-Censored: Survival duration is less than the observed duration
Right-Censored: Survival duration is greater than the observed duration
Interval-Censored: Survival duration can’t exactly be defined
The most common type is right-censored and it is usually taken care of by survival analysis. However, the other two might indicate a problem in the data and might require further investigation.
Survival Function
T is when the event occurs and t is any point of time during the observation, survival S(t) is the probability of T greater than t. In other words, survival function is the probability of an individual will survive after time t.
S(t) = Pr(T > t)
An illustration of a survival curve:
The probability of an individual survives longer than 2 years is 60% — Image by the author
Some important characteristics of survival function: 🔆
T ≥ 0 and 0 < t < ∞
It is non-increasing
If t=0, then S(t)=1(survival probability is 1 at time 0)
If t=∞, then S(t)=0(survival probability goes to 0 as time goes to infinity
Hazard Function
Hazard function or hazard rate, h(t), is the probability of an individual who has survived until time t and experiencing the event of interest at exactly at time t. Hazard function and survival function can be derived from each other by using the following formula.
Hazard Function
Kaplan-Meier Estimator
Being a non-parametric estimator, Kaplan-Meier doesn’t require making initial assumptions about the distribution of data. It also takes care of right-censored observations by computing the survival probabilities from observed survival times. It uses the product rule from probability and in fact, it is also called a product-limit estimator.
Survival Probability as time t
where:
d_i: number of events happened at time t_i
n_i: number of subjects that have survived up to time t_i
We can think the survival probability at time t_i is equal to the product of the probability of surviving at prior time t_i-1 and the percentage chance of surviving at time t_i.👇
The survival probability of t=2 is the survival probability of t=1 multiplied with the percentage chance of surviving at time t=2.
Survival Function with KMF
We can model with Kaplan-Meier Fitter using the lifelines package. While fitting data to kmf, we should specify durations (years spent at the company) and event_observed (attrition value: 1 or 0).
from lifelines import KaplanMeierFitter # Initiate and fit
kmf = KaplanMeierFitter()
kmf.fit(durations=df.YearsAtCompany, event_observed=df.Attrition) # Plot the survival function
kmf.survival_function_.plot()
plt.title('Survival Curve estimated with Kaplan-Meier Fitter')
plt.show()
# Print survival probabilities at each year
kmf.survival_function_
Timeline continues up to year 40.
We can see that probability of an individual survives longer than 2 years at the company is 92% however probability of surviving longer than 10 years is dropped to 77%.
We can also plot survival function with the confidence intervals.
# Plot the survival function with confidence intervals
kmf.plot_survival_function()
plt.show()
Note that, wide confidence interval indicates that the model is less certain at that time usually due to fewer data points.
Survival Function of Different Groups with KMF
We can plot survival curves of different groups such as gender to see whether if the probabilities change.
Let’s do it based on the Environmental Satisfaction column, where we have the following inputs:
1=‘Low’ 2=‘Medium’ 3=‘High’ 4=‘Very High’
To keep things simpler, I will aggregate Low and Medium together under “Low Environmental Satisfaction” and High and Very High under “High Environmental Satisfaction”.
# Define the low and high satisfaction
Low = ((df.EnvironmentSatisfaction == 1) | (df.EnvironmentSatisfaction == 2)) High = ((df.EnvironmentSatisfaction == 3) | (df.EnvironmentSatisfaction == 4)) # Plot the survival function
ax = plt.subplot() kmf = KaplanMeierFitter()
kmf.fit(durations=df[Low].YearsAtCompany,
event_observed=df[Low].Attrition, label='Low Satisfaction')
kmf.survival_function_.plot(ax=ax) kmf.fit(durations=df[High].YearsAtCompany, event_observed=df[High].Attrition, label='High Satisfaction')
kmf.survival_function_.plot(ax=ax) plt.title('Survival Function based on Environmental Satisfaction')
plt.show()
As we can see individuals with high environmental satisfaction have higher survival probabilities than ones with low satisfaction.
We can perform the same analysis also on “gender” and “work-life balance”.
In the Work-Life Balance plot above, we can see individuals with high work-life balance tend to stay longer at the company compared to ones with low work-life balance.
However, in the Gender plot, male and female survival curves go almost head to head which makes it difficult to understand whether if there is a difference or not. To investigate this, we can run a log-rank hypothesis test.
Having null hypothesis indicating male and female survival curves are identical and alternative hypothesis indicating they are not identical. If the p-value of the log-rank test is lower than 0.05 we can reject the null hypothesis.
p-value is greater than 0.05, we do not reject the null hypothesis. In other words, we do not reject the hypothesis of male and female survival curves are identical. ☑️
If we run the log-rank test for “work-life balance”; we find p-value is 0.04. It is lower than 0.05 so we reject the null hypothesis. In other words, we reject the hypothesis of survival curves of individuals with low work-life and high work-life balance are identical.
If we had more than 2 groups (such as low, medium, high work-life balance) we could use pairwise_lograng_test()or multivariate_logrank_test().
Cox Proportional-Hazards Model
Cox-PH model is a regression model to discover the relationship between the survival time of individuals and predictor variable(s). It works with both categorical and numerical predictor variables. We will use Cox-PH model to not only investigate which are the factors that have high & low impact on survival but also to predict future survival probabilities of current employees.
Predicting Survival Time with Cox-PH Model
Let’s select a set of columns we want to investigate. Due to personal curiosity, I selected the following ones:
Let’s fit the selected data to CoxPHFitter and specify survival duration and event columns.
from lifelines import CoxPHFitter # Initialize and fit the model
coxph = CoxPHFitter()
coxph.fit(df, duration_col='YearsAtCompany', event_col='Attrition') # Print model summary
coxph.print_summary()
model summary
In model summary, exp(coef) is the hazard ratio which indicates how much the baseline hazard changes due to one-unit change in the corresponding factor. For example, if environmental satisfaction changes one unit:
hazards ratio: 0.79
hazards change: 0.79–1 = -0.21
survival time change: (1/0.79)-1 = 0.26 → 26% increase in survival time
Model summary also shows the significance of factor variables. Looking at p we can learn “Percent Salary Hike” and “Relationship Satisfaction” are not significant. We can also see this with the factor effects plot below.
# Plot factor effects coxph.plot()
Factor effects (lower effect close to 0)
To predict employee survival probabilities we need to create a new dataframe with current employees: where the attrition is 0, and an array specifying “years at the company”. After that, we can predict survival duration. We need to specify years spent at the company array in predict_survival_function to start the timeline for each individual accordingly.
# Current employees
df_new = df.loc[df['Attrition'] == 0] # Years at the company of current employees
df_new_obs = df_new['YearsAtCompany'] # Predict survival probabilities coxph.predict_survival_function(df_new,conditional_after=df_new_obs)
Predictions — columns are employees, index is the timeline
Predicted survival probability of employee n.1 after 10 more years is 80% however it is 53% for employee n.4.
Like other regression models, also Cox-PH model makes initial assumptions about data. To check if assumptions hold, we can use check_assumptions.
# Check the Cox-PH model assumptions
coxph.check_assumptions(df)
Proportional hazard assumption looks okay.
We are good! 🌴
Otherwise, we might have needed to manipulate some of the variables.
Conclusion
In this article, we have answered some of the important questions companies might have about their employee characteristics and the effects on attrition. We used Kaplan-Meier fitter to calculate and plot survival probabilities and Cox-PH model to predict the survival probabilities of current employees for next years. These predictions are very insightful as they let us know which factors decrease and increase survival probabilities and who are the employees at risk in the short term. Using these predictions companies can put extra effort to prevent losing employees and eventually build more engaged, productive, and happy teams! 🙌
Bonus
We’ve seen how to analyze differences in survival curves among different groups. We can use this feature in A/B testing— where we can investigate if a new feature/change causes a significant change in the survival rate.