Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) models using SQL. In previous posts, we demonstrated how you can use the automatic model training capability of Redshift ML to train classification and regression models. Redshift ML allows you to create a model using SQL and specify your algorithm, such as XGBoost. You can use Redshift ML to automate data preparation, preprocessing, and selection of your problem type (for more information, refer to Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML). You can also bring a model previously trained in Amazon SageMaker into Amazon Redshift via Redshift ML for local inference. For local inference on models created in SageMaker, the ML model type must be supported by Redshift ML. However, remote inference is available for model types that are not natively available in Redshift ML.
Over time, ML models grow old, and even if nothing drastic happens, small changes accumulate. Common reasons why ML models needs to be retrained or audited include:
- Data drift – Because your data has changed over time, the prediction accuracy of your ML models may begin to decrease compared to the accuracy exhibited during testing
- Concept drift – The ML algorithm that was initially used may need to be changed due to different business environments and other changing needs
You may need to refresh the model on a regular basis, automate the process, and reevaluate your model’s improved accuracy. As of this writing, Amazon Redshift doesn’t support versioning of ML models. In this post, we show how you can use the bring your own model (BYOM) functionality of Redshift ML to implement versioning of Redshift ML models.
We use local inference to implement model versioning as part of operationalizing ML models. We assume that you have a good understanding of your data and the problem type that is most applicable for your use case, and have created and deployed models to production.
Solution overview
In this post, we use Redshift ML to build a regression model that predicts the number of people that may use the city of Toronto’s bike sharing service at any given hour of a day. The model accounts for various aspects, including holidays and weather conditions, and because we need to predict a numerical outcome, we used a regression model. We use data drift as a reason for retraining the model, and use model versioning as part of the solution.
After a model is validated and is being used on a regular basis for running predictions, you can create versions of the models, which requires you to retrain the model using an updated training set and possibly a different algorithm. Versioning serves two main purposes:
- You can refer to prior versions of a model for troubleshooting or audit purposes. This enables you to ensure that your model still retains high accuracy before switching to a newer model version.
- You can continue to run inference queries on the current version of a model during the model training process of the new version.
At the time of this writing, Redshift ML doesn’t have native versioning capabilities, but you can still achieve versioning by implementing a few simple SQL techniques by using the BYOM capability. BYOM was introduced to support pre-trained SageMaker models to run your inference queries in Amazon Redshift. In this post, we use the same BYOM technique to create a version of an existing model built using Redshift ML.
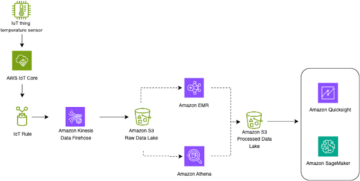
The following figure illustrates this workflow.
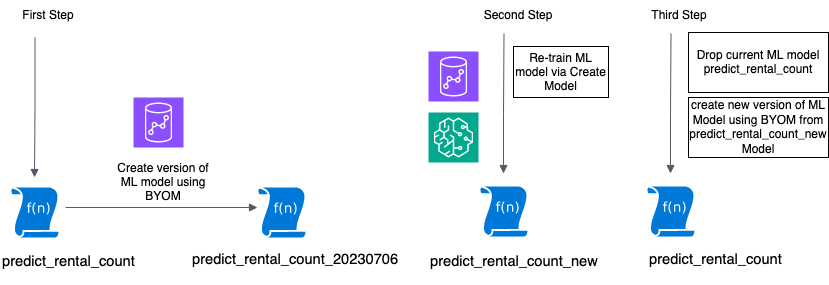
In the following sections, we show you how to can create a version from an existing model and then perform model retraining.
Prerequisites
As a prerequisite for implementing the example in this post, you need to set up a Redshift cluster or Amazon Redshift Serverless endpoint. For the preliminary steps to get started and set up your environment, refer to Create, train, and deploy machine learning models in Amazon Redshift using SQL with Amazon Redshift ML.
We use the regression model created in the post Build regression models with Amazon Redshift ML. We assume that it is already been deployed and use this model to create new versions and retrain the model.
Create a version from the existing model
The first step is to create a version of the existing model (which means saving developmental changes of the model) so that a history is maintained and the model is available for comparison later on.
The following code is the generic format of the CREATE MODEL command syntax; in the next step, you get the information needed to use this command to create a new version:
Next, we collect and apply the input parameters to the preceding CREATE MODEL code to the model. We need the job name and the data types of the model input and output values. We collect these by running the show model command on our existing model. Run the following command in Amazon Redshift Query Editor v2:

Note the values for AutoML Job Name, Function Parameter Types, and the Target Column (trip_count) from the model output. We use these values in the CREATE MODEL command to create the version.
The following CREATE MODEL statement creates a version of the current model using the values collected from our show model command. We append the date (the example format is YYYYMMDD) to the end of the model and function names to track when this new version was created.
This command may take few minutes to complete. When it’s complete, run the following command:

We can observe the following in the output:
- AutoML Job Name is the same as the original version of the model
- Function Name shows the new name, as expected
- Inference Type shows
Local, which designates this is BYOM with local inference
You can run inference queries using both versions of the model to validate the inference outputs.
The following screenshot shows the output of the model inference using the original version.

The following screenshot shows the output of model inference using the version copy.

As you can see, the inference outputs are the same.
You have now learned how to create a version of a previously trained Redshift ML model.
Retrain your Redshift ML model
After you create a version of an existing model, you can retrain the existing model by simply creating a new model.
You can create and train a new model using same CREATE MODEL command but using different input parameters, datasets, or problem types as applicable. For this post, we retrain the model on newer datasets. We append _new to the model name so it’s similar to the existing model for identification purposes.
In the following code, we use the CREATE MODEL command with a new dataset available in the training_data table:
Run the following command to check the status of the new model:
Replace the existing Redshift ML model with the retrained model
The last step is to replace the existing model with the retrained model. We do this by dropping the original version of the model and recreating a model using the BYOM technique.
First, check your retrained model to ensure the MSE/RMSE scores are staying stable between model training runs. To validate the models, you can run inferences by each of the model functions on your dataset and compare the results. We use the inference queries provided in Build regression models with Amazon Redshift ML.
After validation, you can replace your model.
Start by collecting the details of the predict_rental_count_new model.

Note the AutoML Job Name value, the Function Parameter Types values, and the Target Column name in the model output.
Replace the original model by dropping the original model and then creating the model with the original model and function names to make sure the existing references to the model and function names work:
The model creation should complete in a few minutes. You can check the status of the model by running the following command:
When the model status is ready, the newer version predict_rental_count of your existing model is available for inference and the original version of the ML model predict_rental_count_20230706 is available for reference if needed.
Please refer to this GitHub repository for sample scripts to automate model versioning.
Conclusion
In this post, we showed how you can use the BYOM feature of Redshift ML to do model versioning. This allows you to have a history of your models so that you can compare model scores over time, respond to audit requests, and run inferences while training a new model.
For more information about building different models with Redshift ML, refer to Amazon Redshift ML.
About the Authors
 Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build next-generation analytics solutions using other AWS Analytics services.
Rohit Bansal is an Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build next-generation analytics solutions using other AWS Analytics services.
 Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/implement-model-versioning-with-amazon-redshift-ml/
- :has
- :is
- :not
- $UP
- 100
- 11
- 25
- 5000
- 7
- a
- About
- Accounts
- Accumulate
- accuracy
- Achieve
- algorithm
- allows
- already
- also
- Amazon
- Amazon Web Services
- an
- Analysts
- analytics
- and
- any
- applicable
- Apply
- ARE
- AS
- aspects
- assume
- At
- audit
- audited
- automate
- Automatic
- available
- AWS
- basis
- BE
- because
- been
- before
- begin
- being
- between
- both
- bring
- build
- Building
- built
- business
- but
- by
- CAN
- capabilities
- capability
- case
- changed
- Changes
- changing
- check
- City
- Cloud
- code
- collect
- Collecting
- Column
- Common
- compare
- compared
- comparison
- complete
- conditions
- continue
- create
- created
- creates
- Creating
- creation
- Current
- Customers
- data
- Data Preparation
- data warehouse
- datasets
- Date
- day
- decrease
- Default
- demonstrated
- deploy
- deployed
- details
- developers
- developmental
- different
- do
- Doesn’t
- Dropping
- due
- during
- each
- editor
- enables
- end
- Endpoint
- ensure
- Environment
- environments
- Ether (ETH)
- Even
- example
- exhibited
- existing
- experience
- Feature
- few
- Figure
- First
- following
- For
- format
- from
- function
- functionality
- functions
- get
- given
- good
- Grow
- happens
- Have
- he
- helping
- High
- history
- holidays
- hour
- How
- How To
- However
- HTML
- http
- HTTPS
- IAM
- Identification
- if
- illustrates
- implement
- implementing
- improved
- in
- include
- Including
- information
- initially
- input
- into
- introduced
- IT
- Job
- journey
- jpg
- large-scale
- Last
- later
- learned
- learning
- local
- machine
- machine learning
- Main
- make
- May..
- means
- minutes
- ML
- model
- models
- more
- most
- must
- name
- names
- native
- Need
- needed
- needs
- New
- newer
- next
- next-generation
- nothing
- now
- number
- numerical
- objective
- observe
- of
- off
- Old
- on
- or
- original
- Other
- our
- Outcome
- output
- outputs
- over
- own
- parameter
- parameters
- part
- passionate
- People
- perform
- plato
- Plato Data Intelligence
- PlatoData
- possibly
- Post
- Posts
- power
- predict
- prediction
- Predictions
- Predicts
- preliminary
- preparation
- previous
- previously
- Prior
- Problem
- process
- Production
- provided
- purposes
- queries
- reason
- reasons
- refer
- reference
- references
- regression
- regular
- replace
- requests
- requires
- Respond
- Results
- retains
- retraining
- returns
- Run
- running
- runs
- sagemaker
- same
- saving
- scientists
- scores
- scripts
- sections
- see
- selection
- senior
- serves
- service
- Services
- set
- settings
- sharing
- should
- show
- showed
- Shows
- similar
- Simple
- simply
- small
- So
- solution
- Solutions
- specialist
- specializes
- SQL
- stable
- started
- Statement
- Status
- staying
- Step
- Steps
- Still
- such
- support
- Supported
- sure
- syntax
- table
- Take
- Target
- technique
- techniques
- than
- that
- The
- the information
- their
- then
- These
- this
- Through
- time
- to
- track
- Train
- trained
- Training
- two
- type
- types
- understanding
- updated
- use
- use case
- used
- using
- VALIDATE
- validated
- validation
- value
- Values
- various
- version
- versions
- via
- Warehouse
- was
- we
- Weather
- web
- web services
- when
- which
- while
- why
- with
- within
- Work
- workflow
- works
- writing
- XGBoost
- years
- you
- Your
- zephyrnet