The large Language Model (LLM) has changed the way people work. With a model such as the GPT family that is used widely, everyone has gotten used to these models. Leveraging the LLM power, we can quickly get our questions answered, debugging code, and others. This makes the model useful in many applications.
One of the LLM challenges is that the model is unsuitable for streaming applications because of the model’s inability to handle long-conversation chat exceeding the predefined training sequence length. Additionally, there is a problem with the higher memory consumption.
That is why these problems above spawn research to solve them. What is this research? Let’s get into it.
StreamingLLM is a framework established by Xiao et al. (2023) research to tackle the streaming application issues. The existing methods are challenged because the attention window constrains the LLMs during pre-training.
The attention window technique might be efficient but suffers when handling texts longer than its cache size. That’s why the researcher tried to use the Key and Value states of several initial tokens (attention sink) with the recent tokens. The comparison of StreamingLLM and the other techniques can be seen in the image below.

StreamingLLM vs Existing Method (Xiao et al. (2023))
We can see how StreamingLLM tackles the challenge using the attention sink method. This attention sink (initial tokens) is used for stable attention computation and combines it with recent tokens for efficiency and maintains stable performance on longer texts.
Additionally, the existing methods suffer from memory optimization. However, LLM avoids these issues by maintaining a fixed-size window on the Key and Value states of the most recent tokens. The author also mentions the benefit of StreamingLLM as the sliding window recomputation baseline by up to 22.2× speedup.
Performance-wise, StreamingLLM provides excellent accuracy compared to the existing method, as seen in the table below.
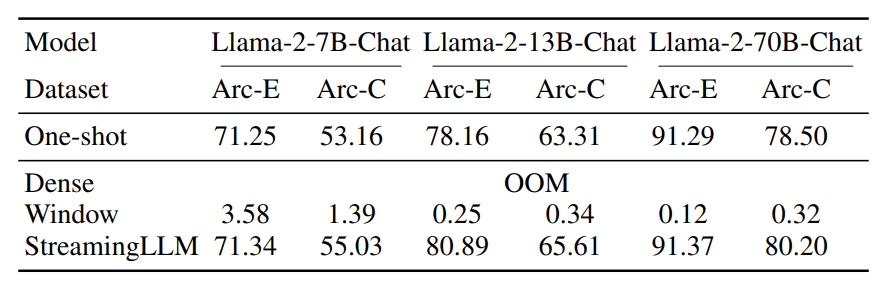
StreamingLLM accuracy (Xiao et al. (2023))
The table above shows that StreamingLLM accuracy can outperform the other methods in the benchmark datasets. That’s why StreamingLLM could have potential for many streaming applications.
To try out the StreamingLLM, you could visit their GitHub page. Clone the repository on your intended directory and use the following code in your CLI to set the environment.
conda create -yn streaming python=3.8
conda activate streaming pip install torch torchvision torchaudio
pip install transformers==4.33.0 accelerate datasets evaluate wandb scikit-learn scipy sentencepiece python setup.py develop
Then, you can use the following code to run the Llama chatbot with LLMstreaming.
CUDA_VISIBLE_DEVICES=0 python examples/run_streaming_llama.py --enable_streaming
The overall sample comparison with StreamingLLM can be shown in the image below.
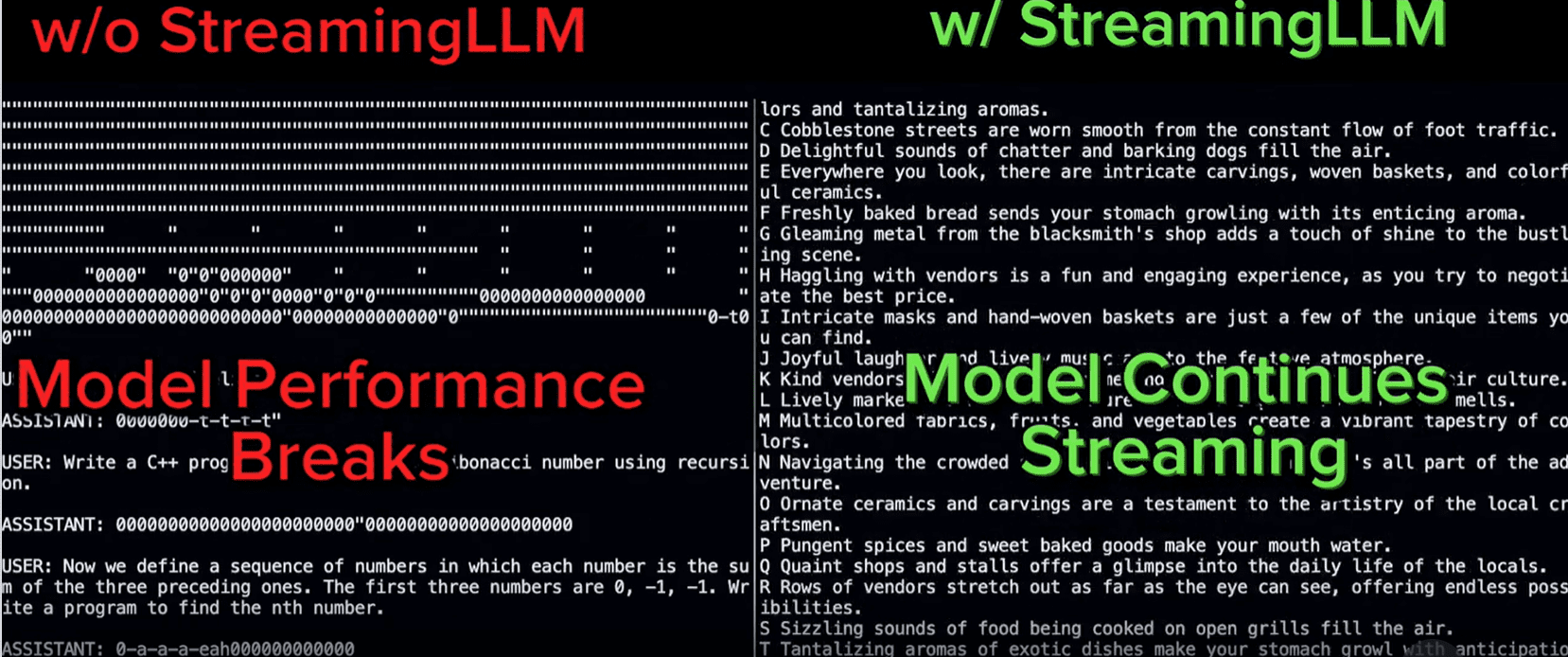
StreamingLLM showed outstanding performance in more extended conversations (Streaming-llm)
That’s all for the introduction of StreamingLLM. Overall, I believe StreamingLLM can have a place in streaming applications and help change how the application works in the future.
Having an LLM in streaming applications would help the business in the long run; however, there are challenges to implement. Most LLMs can’t exceed the predefined training sequence length and have higher memory consumption. Xiao et al. (2023) developed a new framework called StreamingLLM to handle these issues. Using the StreamingLLM, it is now possible to have working LLM in the streaming application.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/introduction-to-streaming-llm-llms-for-infinite-length-inputs?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-streaming-llm-llms-for-infinite-length-inputs
- :has
- :is
- $UP
- 2023
- 22
- 33
- 7
- 8
- 9
- a
- above
- accelerate
- accuracy
- Additionally
- All
- Allianz
- also
- an
- and
- Application
- applications
- ARE
- AS
- Assistant
- At
- attention
- author
- Baseline
- BE
- because
- believe
- below
- Benchmark
- benefit
- business
- but
- by
- cache
- called
- CAN
- challenge
- challenged
- challenges
- change
- changed
- chatbot
- code
- combines
- compared
- comparison
- computation
- consumption
- conversations
- could
- create
- data
- data science
- datasets
- developed
- during
- efficiency
- efficient
- Environment
- established
- evaluate
- everyone
- exceed
- excellent
- existing
- family
- following
- For
- Framework
- from
- future
- get
- handle
- Handling
- Have
- he
- help
- higher
- How
- However
- HTTPS
- i
- image
- implement
- in
- inability
- Indonesia
- initial
- inputs
- install
- intended
- into
- Introduction
- issues
- IT
- ITS
- KDnuggets
- Key
- language
- large
- Length
- leveraging
- Llama
- Long
- longer
- loves
- maintaining
- maintains
- MAKES
- manager
- many
- Media
- Memory
- mentions
- method
- methods
- might
- model
- models
- more
- most
- New
- now
- of
- on
- optimization
- Other
- Others
- our
- out
- Outperform
- outstanding
- overall
- People
- performance
- Place
- plato
- Plato Data Intelligence
- PlatoData
- possible
- potential
- power
- Problem
- problems
- provides
- Python
- Questions
- quickly
- recent
- repository
- research
- researcher
- Run
- s
- Science
- scikit-learn
- see
- seen
- Sequence
- set
- setup
- several
- Share
- showed
- shown
- Shows
- Size
- sliding
- Social
- social media
- SOLVE
- Spawn
- stable
- States
- streaming
- such
- Suffers
- table
- tackle
- Tackles
- technique
- techniques
- than
- that
- The
- The Future
- their
- Them
- There.
- These
- this
- tips
- to
- Tokens
- torch
- Torchvision
- Training
- tried
- try
- use
- used
- useful
- using
- value
- via
- Visit
- vs
- Way..
- we
- What
- What is
- when
- while
- why
- widely
- window
- with
- Work
- working
- works
- would
- writer
- writing
- you
- Your
- zephyrnet







