Today we are excited to announce that the Llama Guard model is now available for customers using Amazon SageMaker JumpStart. Llama Guard provides input and output safeguards in large language model (LLM) deployment. It’s one of the components under Purple Llama, Meta’s initiative featuring open trust and safety tools and evaluations to help developers build responsibly with AI models. Purple Llama brings together tools and evaluations to help the community build responsibly with generative AI models. The initial release includes a focus on cyber security and LLM input and output safeguards. Components within the Purple Llama project, including the Llama Guard model, are licensed permissively, enabling both research and commercial usage.
Now you can use the Llama Guard model within SageMaker JumpStart. SageMaker JumpStart is the machine learning (ML) hub of Amazon SageMaker that provides access to foundation models in addition to built-in algorithms and end-to-end solution templates to help you quickly get started with ML.
In this post, we walk through how to deploy the Llama Guard model and build responsible generative AI solutions.
Llama Guard model
Llama Guard is a new model from Meta that provides input and output guardrails for LLM deployments. Llama Guard is an openly available model that performs competitively on common open benchmarks and provides developers with a pretrained model to help defend against generating potentially risky outputs. This model has been trained on a mix of publicly available datasets to enable detection of common types of potentially risky or violating content that may be relevant to a number of developer use cases. Ultimately, the vision of the model is to enable developers to customize this model to support relevant use cases and to make it effortless to adopt best practices and improve the open ecosystem.
Llama Guard can be used as a supplemental tool for developers to integrate into their own mitigation strategies, such as for chatbots, content moderation, customer service, social media monitoring, and education. By passing user-generated content through Llama Guard before publishing or responding to it, developers can flag unsafe or inappropriate language and take action to maintain a safe and respectful environment.
Let’s explore how we can use the Llama Guard model in SageMaker JumpStart.
Foundation models in SageMaker
SageMaker JumpStart provides access to a range of models from popular model hubs, including Hugging Face, PyTorch Hub, and TensorFlow Hub, which you can use within your ML development workflow in SageMaker. Recent advances in ML have given rise to a new class of models known as foundation models, which are typically trained on billions of parameters and are adaptable to a wide category of use cases, such as text summarization, digital art generation, and language translation. Because these models are expensive to train, customers want to use existing pre-trained foundation models and fine-tune them as needed, rather than train these models themselves. SageMaker provides a curated list of models that you can choose from on the SageMaker console.
You can now find foundation models from different model providers within SageMaker JumpStart, enabling you to get started with foundation models quickly. You can find foundation models based on different tasks or model providers, and easily review model characteristics and usage terms. You can also try out these models using a test UI widget. When you want to use a foundation model at scale, you can do so easily without leaving SageMaker by using pre-built notebooks from model providers. Because the models are hosted and deployed on AWS, you can rest assured that your data, whether used for evaluating or using the model at scale, is never shared with third parties.
Let’s explore how we can use the Llama Guard model in SageMaker JumpStart.
Discover the Llama Guard model in SageMaker JumpStart
You can access Code Llama foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in Amazon SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
In SageMaker Studio, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and prebuilt solutions, under Prebuilt and automated solutions.
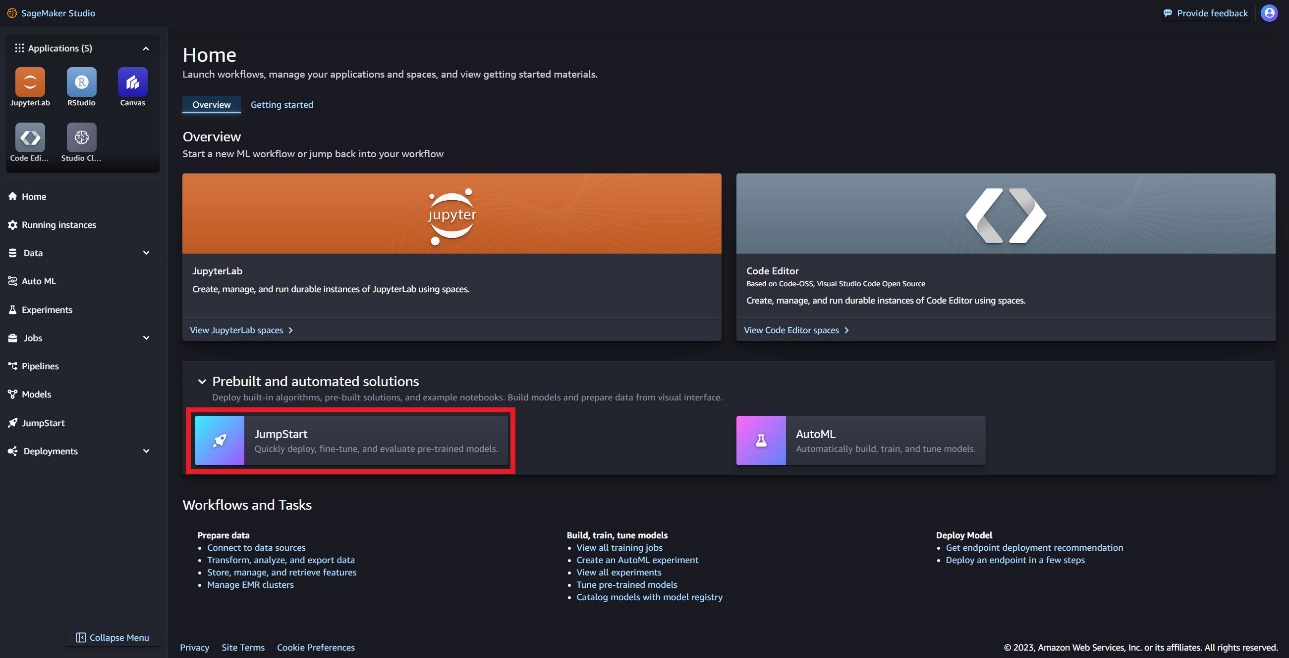
On the SageMaker JumpStart landing page, you can find the Llama Guard model by choosing the Meta hub or searching for Llama Guard.

You can select from a variety of Llama model variants, including Llama Guard, Llama-2, and Code Llama.

You can choose the model card to view details about the model such as license, data used to train, and how to use. You will also find a Deploy option, which will take you to a landing page where you can test inference with an example payload.

Deploy the model with the SageMaker Python SDK
You can find the code showing the deployment of Llama Guard on Amazon JumpStart and an example of how to use the deployed model in this GitHub notebook.
In the following code, we specify the SageMaker model hub model ID and model version to use when deploying Llama Guard:
You can now deploy the model using SageMaker JumpStart. The following code uses the default instance ml.g5.2xlarge for the inference endpoint. You can deploy the model on other instance types by passing instance_type in the JumpStartModel class. The deployment might take a few minutes. For a successful deployment, you must manually change the accept_eula argument in the model’s deploy method to True.
This model is deployed using the Text Generation Inference (TGI) deep learning container. Inference requests support many parameters, including the following:
- max_length – The model generates text until the output length (which includes the input context length) reaches
max_length. If specified, it must be a positive integer. - max_new_tokens – The model generates text until the output length (excluding the input context length) reaches
max_new_tokens. If specified, it must be a positive integer. - num_beams – This indicates the number of beams used in the greedy search. If specified, it must be an integer greater than or equal to
num_return_sequences. - no_repeat_ngram_size – The model ensures that a sequence of words of
no_repeat_ngram_sizeis not repeated in the output sequence. If specified, it must be a positive integer greater than 1. - temperature – This parameter controls the randomness in the output. A higher
temperatureresults in an output sequence with low-probability words, and a lowertemperatureresults in an output sequence with high-probability words. Iftemperatureis 0, it results in greedy decoding. If specified, it must be a positive float. - early_stopping – If
True, text generation is finished when all beam hypotheses reach the end of the sentence token. If specified, it must be Boolean. - do_sample – If
True, the model samples the next word as per the likelihood. If specified, it must be Boolean. - top_k – In each step of text generation, the model samples from only the
top_kmost likely words. If specified, it must be a positive integer. - top_p – In each step of text generation, the model samples from the smallest possible set of words with cumulative probability
top_p. If specified, it must be a float between 0–1. - return_full_text – If
True, the input text will be part of the output generated text. If specified, it must be Boolean. The default value isFalse. - stop – If specified, it must be a list of strings. Text generation stops if any one of the specified strings is generated.
Invoke a SageMaker endpoint
You may programmatically retrieve example payloads from the JumpStartModel object. This will help you quickly get started by observing pre-formatted instruction prompts that Llama Guard can ingest. See the following code:
After you run the preceding example, you can see how your input and output would be formatted by Llama Guard:
Similar to Llama-2, Llama Guard uses special tokens to indicate safety instructions to the model. In general, the payload should follow the below format:
User prompt shown as {user_prompt} above, can further include sections for content category definitions and conversations, which looks like the following:
In the next section, we discuss the recommended default values for the task, content category, and instruction definitions. The conversation should alternate between User and Agent text as follows:
Moderate a conversation with Llama-2 Chat
You can now deploy a Llama-2 7B Chat model endpoint for conversational chat and then use Llama Guard to moderate input and output text coming from Llama-2 7B Chat.
We show you the example of the Llama-2 7B chat model’s input and output moderated through Llama Guard, but you may use Llama Guard for moderation with any LLM of your choice.
Deploy the model with the following code:
You can now define the Llama Guard task template. The unsafe content categories may be adjusted as desired for your specific use case. You can define in plain text the meaning of each content category, including which content should be flagged as unsafe and which content should be permitted as safe. See the following code:
Next, we define helper functions format_chat_messages and format_guard_messages to format the prompt for the chat model and for the Llama Guard model that required special tokens:
You can then use these helper functions on an example message input prompt to run the example input through Llama Guard to determine if the message content is safe:
The following output indicates that the message is safe. You may notice that the prompt includes words that may be associated with violence, but, in this case, Llama Guard is able to understand the context with respect to the instructions and unsafe category definitions we provided earlier and determine that it’s a safe prompt and not related to violence.
Now that you have confirmed that the input text is determined to be safe with respect to your Llama Guard content categories, you can pass this payload to the deployed Llama-2 7B model to generate text:
The following is the response from the model:
Finally, you may wish to confirm that the response text from the model is determined to contain safe content. Here, you extend the LLM output response to the input messages and run this whole conversation through Llama Guard to ensure the conversation is safe for your application:
You may see the following output, indicating that response from the chat model is safe:
Clean up
After you have tested the endpoints, make sure you delete the SageMaker inference endpoints and the model to avoid incurring charges.
Conclusion
In this post, we showed you how you can moderate inputs and outputs using Llama Guard and put guardrails for inputs and outputs from LLMs in SageMaker JumpStart.
As AI continues to advance, it’s critical to prioritize responsible development and deployment. Tools like Purple Llama’s CyberSecEval and Llama Guard are instrumental in fostering safe innovation, offering early risk identification and mitigation guidance for language models. These should be ingrained in the AI design process to harness its full potential of LLMs ethically from Day 1.
Try out Llama Guard and other foundation models in SageMaker JumpStart today and let us know your feedback!
This guidance is for informational purposes only. You should still perform your own independent assessment, and take measures to ensure that you comply with your own specific quality control practices and standards, and the local rules, laws, regulations, licenses, and terms of use that apply to you, your content, and the third-party model referenced in this guidance. AWS has no control or authority over the third-party model referenced in this guidance, and does not make any representations or warranties that the third-party model is secure, virus-free, operational, or compatible with your production environment and standards. AWS does not make any representations, warranties, or guarantees that any information in this guidance will result in a particular outcome or result.
About the authors
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He is interested in the confluence of machine learning with cloud computing. Evan received his undergraduate degree from Cornell University and master’s degree from the University of California, Berkeley. In 2021, he presented a paper on adversarial neural networks at the ICLR conference. In his free time, Evan enjoys cooking, traveling, and going on runs in New York City.
 Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in the future and bring economic and social prosperity. In her spare time, Rachna likes spending time with her family, hiking, and listening to music.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Karl Albertsen leads product, engineering, and science for Amazon SageMaker Algorithms and JumpStart, SageMaker’s machine learning hub. He is passionate about applying machine learning to unlock business value.
Karl Albertsen leads product, engineering, and science for Amazon SageMaker Algorithms and JumpStart, SageMaker’s machine learning hub. He is passionate about applying machine learning to unlock business value.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- :has
- :is
- :not
- :where
- $UP
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- Able
- About
- above
- Accept
- access
- According
- Accounts
- Act
- Action
- actions
- active
- activities
- actual
- addition
- Adjusted
- adopt
- advance
- advances
- adversarial
- advice
- against
- Agent
- AI
- AI models
- AI/ML
- Alcohol
- algorithms
- All
- also
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- an
- and
- Announce
- answer
- any
- Application
- applied
- Apply
- Applying
- appropriate
- ARE
- argument
- arguments
- Art
- AS
- assessment
- assist
- Assistant
- associated
- assured
- At
- authority
- Automated
- available
- avoid
- AWS
- based
- basic
- Bayesian
- BE
- Beam
- because
- been
- before
- begin
- behavior
- believes
- below
- benchmarks
- Berkeley
- BEST
- best practices
- between
- billions
- body
- both
- bring
- Brings
- build
- Building
- built-in
- business
- but
- by
- california
- CAN
- cannabis
- card
- case
- cases
- categories
- Category
- cell
- challenges
- Chance
- change
- characteristics
- charges
- chatbots
- check
- chemical
- choice
- Choose
- choosing
- City
- class
- clean
- Cloud
- cloud computing
- code
- color
- coming
- commercial
- committed
- Common
- community
- compatible
- comply
- components
- composition
- computer
- Computer Vision
- computing
- Conference
- conferences
- Confirm
- CONFIRMED
- confluence
- Console
- consumption
- contain
- Container
- contains
- content
- content moderation
- context
- continues
- control
- controlled
- controls
- Conversation
- conversational
- conversations
- cooking
- cornell
- could
- create
- creation
- Crimes
- Criminal
- critical
- curated
- customer
- Customer Service
- Customers
- customize
- cyber
- cyber security
- cycle
- data
- datasets
- day
- Decoding
- deep
- deep learning
- Default
- define
- definitions
- Degree
- deploy
- deployed
- deploying
- deployment
- deployments
- Design
- design process
- desire
- desired
- detailed
- details
- Detection
- Determine
- determined
- develop
- Developer
- developers
- Development
- DICT
- different
- digital
- Digital Art
- Disability
- discover
- Discrimination
- discuss
- do
- does
- Drugs
- Duke
- duke university
- e
- each
- Earlier
- Early
- easily
- Economic
- ecosystem
- Education
- effects
- effortless
- enable
- enabling
- encourage
- end
- end-to-end
- Endpoint
- endpoints
- engage
- engineer
- Engineering
- ensure
- ensures
- Environment
- equal
- especially
- Ether (ETH)
- ethical
- evaluating
- evaluations
- evan
- events
- example
- Except
- exception
- excited
- excluding
- execution
- existing
- expensive
- explore
- express
- extend
- Face
- faced
- false
- family
- Featuring
- few
- financial
- financial crimes
- Find
- firearms
- First
- flagged
- Float
- Focus
- follow
- followed
- following
- follows
- For
- format
- fostering
- Foundation
- Free
- from
- full
- functions
- further
- future
- Gender
- General
- generate
- generated
- generates
- generating
- generation
- generative
- Generative AI
- get
- GitHub
- given
- Giving
- Go
- going
- got
- greater
- Greedy
- guarantees
- Guard
- guidance
- GUNS
- harm
- harness
- hate
- Have
- he
- Health
- help
- helps
- her
- here
- higher
- hiking
- his
- historical
- hosted
- How
- How To
- HTML
- HTTPS
- Hub
- hubs
- i
- ICLR
- ID
- Identification
- Identity
- if
- Illegal
- illinois
- immediately
- import
- improve
- in
- include
- includes
- Including
- independent
- indicate
- indicates
- indicating
- information
- Informational
- ingrained
- initial
- Initiative
- Innovation
- input
- inputs
- instance
- instructions
- instrumental
- integrate
- integrated
- interested
- interests
- Interface
- into
- involving
- IT
- ITS
- jpg
- Kill
- Know
- known
- kyle
- landing
- landing page
- language
- large
- Last
- Laws
- Leads
- learning
- leaving
- Length
- let
- License
- Licensed
- licenses
- like
- likelihood
- likely
- likes
- Limited
- Line
- linux
- List
- Listening
- Llama
- local
- LOOKS
- lower
- machine
- machine learning
- maintain
- make
- manually
- manufactured
- many
- master’s
- May..
- meaning
- measures
- Media
- mental
- Mental health
- message
- messages
- Meta
- method
- methods
- might
- minutes
- mitigation
- mix
- ML
- model
- models
- moderate
- moderation
- monitoring
- more
- most
- Music
- must
- Must Read
- National
- needed
- networks
- Neural
- neural networks
- NeurIPS
- never
- New
- New York
- new york city
- next
- no
- notebook
- notebooks
- Notice..
- now
- number
- object
- observing
- of
- offering
- on
- ONE
- only
- open
- openly
- operational
- Option
- Options
- or
- Origin
- Other
- our
- out
- Outcome
- output
- outputs
- over
- own
- ownership
- page
- Paper
- papers
- parameter
- parameters
- part
- particular
- parties
- pass
- Passing
- passionate
- People
- per
- perform
- performs
- person
- personal
- phd
- Plain
- plan
- planning
- plato
- Plato Data Intelligence
- PlatoData
- policy
- Popular
- positive
- possible
- Post
- potential
- potentially
- practices
- Predictor
- preparing
- presented
- prevent
- Principal
- Prioritize
- probability
- process
- processes
- Product
- Production
- project
- prompts
- prosperity
- provide
- provided
- providers
- provides
- publicly
- published
- Publishing
- purposes
- put
- Python
- pytorch
- quality
- quickly
- Race
- randomness
- range
- rather
- reach
- Reaches
- Read
- received
- recent
- recommended
- refer
- regarding
- regulated
- regulations
- related
- release
- relevant
- religion
- repeated
- replace
- requests
- required
- research
- researcher
- Resources
- respect
- responding
- response
- responsible
- responsibly
- REST
- result
- Results
- return
- review
- Rise
- Risk
- Risky
- roadmap
- Role
- roles
- rules
- Run
- runs
- safe
- safeguards
- Safety
- sagemaker
- SageMaker Inference
- scalable
- Scale
- Science
- Scientist
- sdk
- Search
- searching
- Second
- Section
- sections
- secure
- security
- see
- select
- senior
- sensitive
- sentence
- sentiments
- Sequence
- Series
- service
- Services
- set
- Sexual
- shared
- should
- show
- showed
- showing
- shown
- single
- smallest
- So
- Social
- social media
- Society
- Software
- Software Engineer
- solution
- Solutions
- special
- specific
- specified
- Spending
- standards
- started
- Starting
- statistical
- statistics
- Step
- Steps
- Still
- Stops
- Strategic
- strategies
- studio
- successful
- such
- Suicide
- support
- Supports
- sure
- syntax
- system
- Systems
- Take
- Task
- tasks
- team
- template
- templates
- tensorflow
- terms
- test
- tested
- text
- text generation
- than
- that
- The
- The Future
- the information
- theft
- their
- Them
- themselves
- then
- There.
- These
- they
- Third
- third parties
- third-party
- this
- those
- Through
- time
- Time Series
- to
- tobacco
- today
- together
- token
- Tokens
- tool
- tools
- Topics
- trafficking
- Train
- trained
- Training
- Translation
- Traveling
- true
- Trust
- try
- TURN
- types
- typically
- ui
- Ultimately
- under
- understand
- university
- University of California
- unlock
- until
- us
- Usage
- use
- use case
- used
- User
- uses
- using
- value
- Values
- variety
- version
- View
- violated
- Violating
- violence
- vision
- visual
- walk
- want
- Way..
- we
- Weapons
- web
- web services
- web-based
- What
- when
- whether
- which
- WHO
- whole
- wide
- widget
- will
- wish
- with
- within
- without
- Word
- words
- Work
- workflow
- working
- would
- york
- you
- Your
- zephyrnet