Introduction
Large Language Models (LLMs) are crucial in various applications such as chatbots, search engines, and coding assistants. Enhancing LLM inference efficiency is vital due to the significant memory and computational demands during the ‘decode’ phase of LLM operations, which handles token processing one at a time per request. Batching, a key technique, helps manage the costs associated with fetching model weights from memory, thus boosting throughput by optimizing memory bandwidth utilization.

Table of contents
The Bottleneck of Large Language Models (LLMs)
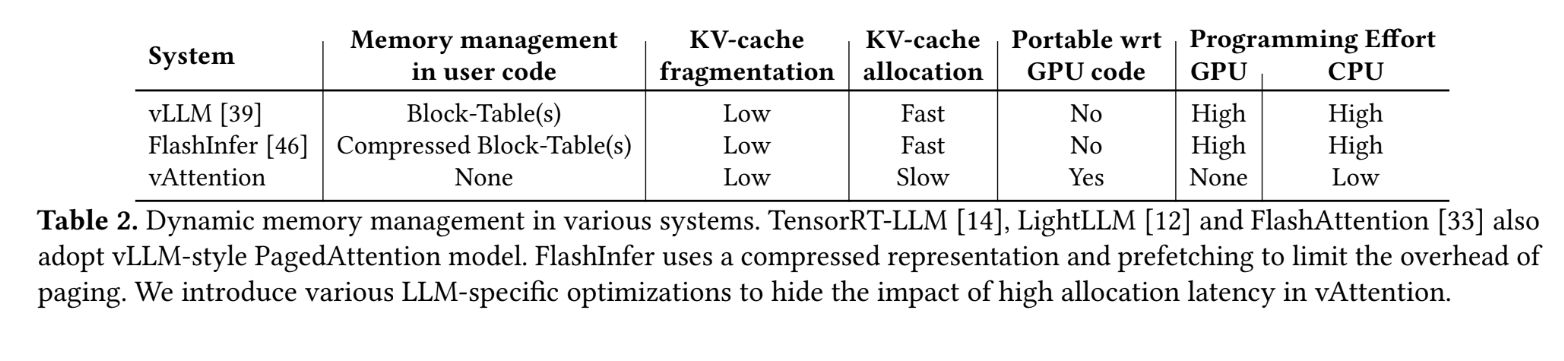
One of the primary challenges in deploying LLMs efficiently is memory management, particularly during the ‘decode’ phase, which is memory-bound. Traditional methods involve reserving a fixed amount of GPU memory for the KV cache, the in-memory state maintained for each inference request. While straightforward, this approach leads to significant memory wastage due to internal fragmentation; requests typically use less memory than reserved, and substantial portions remain unused, thus hampering throughput as the systems cannot effectively support large batch sizes.
Traditional Approaches and Their Limitations
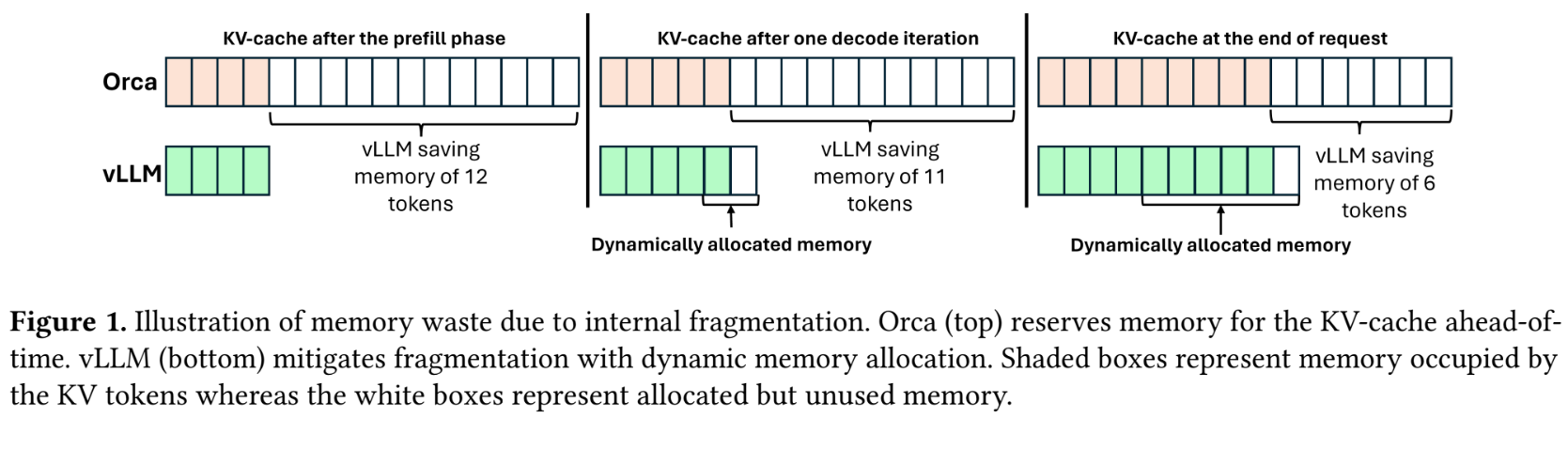
To address the inefficiencies of fixed memory allocation, the PagedAttention method was introduced. Inspired by the operating systems’ virtual memory management, PagedAttention allows dynamic memory allocation for the KV cache, significantly reducing memory wastage by allocating small memory blocks dynamically as needed rather than reserving large chunks of memory upfront. Despite its advantages in reducing fragmentation, PagedAttention introduces its own set of challenges. It requires changes to the memory layout from contiguous to non-contiguous virtual memory, necessitating alterations in the attention kernels to accommodate these changes. Moreover, it complicates the software architecture by adding layers of memory management that traditionally belong to operating systems, leading to increased software complexity and potential performance overhead due to additional memory management tasks being handled in user space.
A Game Changer for LLM Memory Management
vAttention marks a significant advancement in managing memory for Large Language Models (LLMs), enhancing the speed and efficiency of model operations without the need for an extensive system overhaul. By maintaining the virtual memory’s contiguity, vAttention ensures a more streamlined approach, leveraging existing system support for dynamic memory allocation, which is less complex and more manageable than previous methods.
What is vAttention?
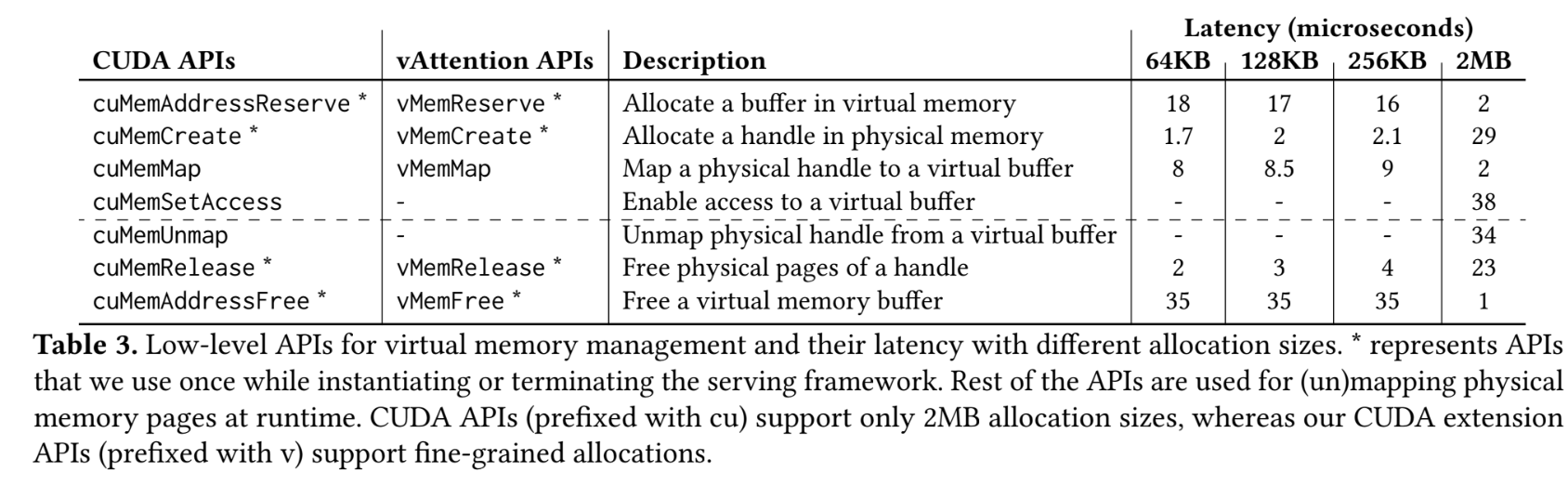
vAttention introduces a refined strategy for memory management in LLMs by utilizing a system that maintains contiguous virtual memory while enabling dynamic physical memory allocation on demand. This approach simplifies handling KV-cache memories without committing physical memory in advance, mitigating common fragmentation issues and allowing for greater flexibility and efficiency. The system seamlessly integrates with existing server frameworks, requiring minimal changes to the attention kernel or memory management practices.
Key Advantages of vAttention: Speed, Efficiency, and Simplicity
The primary benefits of vAttention include enhanced processing speed, operational efficiency, and simplified integration. By avoiding non-contiguous memory allocation, vAttention enhances the runtime performance of LLMs, which are capable of generating tokens up to nearly two times faster than previous methods. This speed improvement does not sacrifice efficiency, as the system effectively manages GPU memory usage to accommodate varying batch sizes without excess wastage. Additionally, the simplicity of vAttention’s integration helps preserve the original structure of LLMs, facilitating easier updates and maintenance without necessitating significant code rewrites or specialized memory management. This simplification extends to the system’s ability to work with unchanged attention kernels, reducing the learning curve and deployment time for developers.
How vAttention Works?
The vAttention mechanism is designed to optimize performance during various phases of computational tasks, focusing particularly on memory management and maintaining consistent output quality. This deep dive into the workings of vAttention will explore its different phases and strategies to enhance system efficiency.
Prefill Phase: Optimizing Memory Allocation for Faster Start-Up
The prefill phase of vAttention addresses the issue of internal fragmentation in memory allocation. Adopting an adaptive memory allocation strategy, vAttention ensures that smaller memory blocks are efficiently utilized, minimizing wasted space. This approach is critical for applications requiring high-density memory, allowing them to run more effectively on constrained systems.
Another key feature of the prefill phase is the ability to overlap memory allocation with processing tasks. This overlapping technique speeds up the system start-up and maintains a smooth operation flow. By initiating memory allocation during idle processing cycles, vAttention can leverage otherwise wasted processor time, enhancing overall system throughput.
Smart reclamation is integral to the prefill phase, where vAttention actively monitors memory usage and reclaims unused memory segments. This dynamic reallocation helps prevent system bloat and memory leaks, ensuring that resources are available for critical tasks when needed. The mechanism is designed to be proactive, keeping the system lean and efficient.
Decode Phase: Sustaining Peak Performance Throughout Inference
During the decode phase, vAttention focuses on sustaining peak performance to ensure consistent throughput. This is achieved through a finely tuned orchestration of computational resources, ensuring each component operates optimally without bottlenecks. The decoding phase is crucial for applications requiring real-time processing and high data throughput, as it balances speed and accuracy.
Through these phases, vAttention demonstrates its effectiveness in enhancing system performance, making it a valuable tool for various applications requiring sophisticated memory and processing management.
Also read: What are the Different Types of Attention Mechanisms?
vAttention vs. PagedAttention
Significant differences in performance and usability reveal a clear preference in most scenarios when comparing vAttention and PagedAttention. vAttention, with its simplified approach to managing attention mechanisms in neural networks, has demonstrated superior efficiency and effectiveness over PagedAttention. This is particularly evident in tasks involving large datasets where attention span needs to be dynamically adjusted to optimize computational resources.
Speed Gains Across Different Scenarios
Performance benchmarks show that vAttention provides notable speed gains across various tasks. In natural language processing tasks, vAttention reduced the training time by up to 30% compared to PagedAttention. Similarly, in image recognition tasks, the speed improvement was approximately 25%. These gains are attributed to vAttention’s ability to more efficiently allocate computational resources by dynamically adjusting its focus based on the data’s complexity and relevance.
The User-Friendliness Factor: vAttention’s Simplicity Wins
One of the standout features of vAttention is its user-friendly design. Unlike PagedAttention, which often requires extensive configuration and fine-tuning, vAttention is designed with simplicity in mind. It requires fewer parameters and less manual intervention, making it more accessible to users with varying levels of expertise in machine learning. This simplicity does not come at the cost of performance, making vAttention a preferred choice for developers looking for an effective yet manageable solution.
Conclusion
As we continue to explore the capabilities of large language models (LLMs), their integration into various sectors promises substantial benefits. The future involves enhancing their understanding of complex data, refining their ability to generate human-like responses, and expanding their application in healthcare, finance, and education.
To fully realize AI’s potential, we must focus on ethical practices. This includes ensuring models do not perpetuate biases and that their deployment considers societal impacts. Collaboration across academia, industry, and regulatory bodies will be vital to developing guidelines that foster innovation while protecting individual rights.
Furthermore, improving the efficiency of LLMs will be crucial to their scalability. Research into more energy-efficient models and methods that reduce the computational burden can make these tools accessible to more users globally, thus democratizing AI benefits.
For more articles like this, explore our blog section today!
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2024/05/llms-get-a-speed-boost/
- :has
- :is
- :not
- :where
- $UP
- 361
- a
- ability
- Academia
- accessible
- accommodate
- accuracy
- achieved
- across
- actively
- adaptive
- adding
- Additional
- Additionally
- address
- addresses
- Adjusted
- adjusting
- Adopting
- advance
- advancement
- advantages
- AI
- allocate
- allocation
- Allowing
- allows
- alterations
- amount
- an
- and
- Application
- applications
- approach
- approaches
- approximately
- architecture
- ARE
- articles
- AS
- assistants
- associated
- At
- attention
- available
- avoiding
- balances
- Bandwidth
- based
- batching
- BE
- being
- benchmarks
- benefits
- biases
- BLAZING
- Bloat
- Blocks
- bodies
- boost
- boosting
- bottleneck
- bottlenecks
- burden
- by
- cache
- CAN
- cannot
- capabilities
- capable
- challenges
- Changer
- Changes
- chatbots
- choice
- clear
- code
- Coding
- collaboration
- come
- committing
- Common
- compared
- comparing
- complex
- complexity
- component
- computational
- Configuration
- considers
- consistent
- constrained
- continue
- Cost
- Costs
- critical
- crucial
- curve
- cycles
- data
- datasets
- Decoding
- deep
- deep dive
- Demand
- demands
- Democratizing
- demonstrated
- demonstrates
- deploying
- deployment
- Design
- designed
- Despite
- developers
- developing
- differences
- different
- dive
- do
- does
- due
- during
- dynamic
- dynamically
- each
- easier
- Education
- Effective
- effectively
- effectiveness
- efficiency
- efficient
- efficiently
- enabling
- Engines
- enhance
- enhanced
- Enhances
- enhancing
- ensure
- ensures
- ensuring
- ethical
- evident
- excess
- existing
- existing system
- expanding
- expertise
- explore
- extends
- extensive
- facilitating
- factor
- faster
- Feature
- Features
- fewer
- finance
- fixed
- Flexibility
- flow
- Focus
- focuses
- focusing
- For
- Foster
- fragmentation
- frameworks
- from
- fully
- future
- Gains
- game
- game-changer
- generate
- generating
- get
- Globally
- GPU
- greater
- guidelines
- handled
- Handles
- Handling
- healthcare
- helps
- High
- HTTPS
- Idle
- image
- Image Recognition
- Impacts
- improvement
- improving
- in
- include
- includes
- increased
- individual
- industry
- inefficiencies
- initiating
- Innovation
- inspired
- integral
- Integrates
- integration
- internal
- intervention
- into
- introduced
- Introduces
- involve
- involves
- involving
- issue
- issues
- IT
- ITS
- jpg
- keeping
- Key
- language
- large
- layers
- Layout
- leading
- Leads
- Leaks
- lean
- learning
- less
- levels
- Leverage
- leveraging
- like
- llm
- looking
- machine
- machine learning
- maintained
- maintaining
- maintains
- maintenance
- make
- MAKES
- Making
- manage
- manageable
- management
- manages
- managing
- manual
- mechanism
- mechanisms
- Memories
- Memory
- methods
- mind
- minimal
- minimizing
- mitigating
- model
- models
- monitors
- more
- Moreover
- most
- must
- Natural
- Natural Language
- Natural Language Processing
- nearly
- necessitating
- Need
- needed
- needs
- networks
- Neural
- neural networks
- New
- New Tech
- notable
- of
- often
- on
- ONE
- operates
- operating
- operating systems
- operation
- operational
- Operations
- Optimize
- optimizing
- or
- orchestration
- original
- otherwise
- output
- over
- overall
- Overhaul
- overhead
- overlap
- own
- parameters
- particularly
- Peak
- per
- performance
- perpetuate
- phase
- phases
- physical
- plato
- Plato Data Intelligence
- PlatoData
- portions
- potential
- practices
- preferred
- preserve
- prevent
- previous
- primary
- Proactive
- processing
- Processor
- promises
- protecting
- provides
- quality
- rather
- Read
- real-time
- realize
- recognition
- reduce
- Reduced
- reducing
- refined
- refining
- regulatory
- relevance
- remain
- request
- requests
- requires
- research
- reserved
- Resources
- responses
- reveal
- rights
- Run
- runtime
- sacrifice
- Scalability
- scenarios
- seamlessly
- Search
- Search engines
- Sectors
- segments
- server
- set
- show
- significant
- significantly
- Similarly
- simplicity
- simplification
- simplified
- simplifies
- sizes
- small
- smaller
- smooth
- societal
- Software
- solution
- sophisticated
- Space
- span
- specialized
- speed
- speeds
- standout
- Start-up
- State
- straightforward
- strategies
- Strategy
- streamlined
- structure
- substantial
- such
- superior
- support
- system
- Systems
- tasks
- tech
- technique
- than
- that
- The
- The Future
- their
- Them
- These
- this
- Through
- throughout
- throughput
- Thus
- time
- times
- to
- token
- Tokens
- tool
- tools
- traditional
- traditionally
- Training
- tuned
- two
- types
- typically
- unchanged
- understanding
- unlike
- unused
- Updates
- usability
- Usage
- use
- User
- user-friendly
- users
- utilization
- utilized
- Utilizing
- Valuable
- various
- varying
- Virtual
- vital
- vs
- was
- wasted
- we
- when
- which
- while
- will
- with
- without
- Work
- workings
- works
- yet
- zephyrnet