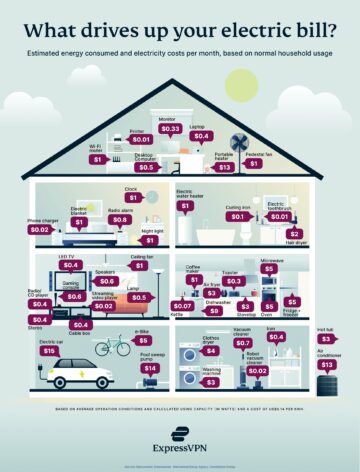
Meta has just unveiled Meta.AI, an AI assistant powered by its state-of-the-art Llama 3 technology. This launch is widely interpreted as a direct challenge to the dominance of OpenAI’s ChatGPT, signaling a shift towards a higher standard for AI-mediated communication.
The introduction of Meta.AI closely follows the debut of Llama 3, Meta’s latest iteration of its open-source LLM framework, featuring versions boasting 8 billion and 70 billion parameters. These iterations have demonstrated superior performance in various evaluation benchmarks, solidifying Meta’s position as a formidable contender in the field.
What sets Meta’s approach apart is its commitment to open-source development. In contrast to certain competitors, Meta has opted to make the foundational Llama 3 model accessible to the public, fostering an environment conducive to experimentation, innovation, and collaborative progress among developers. However, there may be constraints imposed on large cloud corporations seeking access to the model.
Meta.AI
Meta.AI also enjoys a strategic advantage in terms of accessibility. By seamlessly integrating the AI assistant with Meta’s established social media platforms such as Facebook, Instagram, and WhatsApp, Meta ensures widespread availability to an extensive user base. This integration holds the promise of revolutionizing user interactions on these platforms, offering assistance with tasks, facilitating content creation, and delivering tailored experiences.
From a technical standpoint, Llama 3 presents two versions – an 8 billion parameter iteration and a 70 billion parameter variant – both prioritizing efficiency while delivering robust performance across diverse tasks. Meta has additionally hinted at the prospect of developing even more potent models in the future.
Llama 3 and Meta.AI

According to a recent company announcement, the latest Llama 3 models have been trained on an impressive dataset of over 15 trillion tokens, dwarfing the previous generation’s training corpus of 2 trillion tokens. This exponential increase in training data underscores the substantial advancement in model capabilities.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://techstartups.com/2024/04/19/meta-launches-meta-ai-to-compete-with-chatgpt/
- :has
- :is
- 15%
- 2%
- 70
- 8
- a
- access
- accessibility
- accessible
- across
- Additionally
- advancement
- ADvantage
- AI
- AI assistant
- also
- among
- an
- and
- Announcement
- apart
- approach
- AS
- Assistance
- Assistant
- At
- availability
- base
- BE
- been
- benchmarks
- Billion
- boasting
- both
- by
- capabilities
- certain
- challenge
- ChatGPT
- closely
- Cloud
- collaborative
- commitment
- Communication
- company
- Company Announcement
- compete
- competitors
- constraints
- content
- content-creation
- contrast
- Corporations
- creation
- data
- delivering
- demonstrated
- developers
- developing
- Development
- direct
- diverse
- Dominance
- efficiency
- ensures
- Environment
- established
- evaluation
- Even
- Experiences
- exponential
- extensive
- facilitating
- Featuring
- field
- follows
- For
- formidable
- fostering
- foundational
- Framework
- future
- Have
- higher
- hinted
- holds
- However
- HTTPS
- imposed
- impressive
- in
- Increase
- Innovation
- Integrating
- integration
- interactions
- Introduction
- iteration
- iterations
- ITS
- jpg
- just
- large
- latest
- launch
- launches
- Llama
- llm
- make
- May..
- Media
- Meta
- model
- models
- more
- of
- offering
- on
- open source
- over
- parameter
- parameters
- performance
- Platforms
- plato
- Plato Data Intelligence
- PlatoData
- position
- potent
- powered
- presents
- previous
- prioritizing
- Progress
- promise
- prospect
- public
- recent
- Revolutionizing
- robust
- seamlessly
- seeking
- Sets
- shift
- Social
- social media
- social media platforms
- solidifying
- standard
- standpoint
- Startups
- state-of-the-art
- Strategic
- substantial
- such
- superior
- tailored
- tasks
- tech
- tech startups
- Technical
- Technology
- terms
- The
- The Future
- There.
- These
- this
- to
- Tokens
- towards
- trained
- Training
- Trillion
- two
- underscores
- unveiled
- User
- Variant
- various
- versions
- while
- widely
- widespread
- with
- zephyrnet