<!—->
<!– –>

It has been proven time and time again that a business application’s outages are very costly. The estimated cost of an average downtime can run USD 50,000 to 500,000 per hour, and more as businesses are actively moving to digitization. The complexity of applications is growing as well, so Site Reliability Engineers (SREs) require hours—and sometimes days—to identify and resolve problems.
To alleviate this problem, we have introduced the new feature Probable Root Cause as part of Intelligent Incident Remediation from Instana®. Upon the creation of Incidents, Instana automatically analyzes call statistics, topology and surrounding information using Causal AI; and quickly and efficiently identifies the probable source of the application failure. This allows SREs to resolve incidents by directly looking at the source of the problem, instead of symptoms— saving them many hours of work and avoiding considerable cost for the business.
The results in this space often depend on the well-known triple: the data, the assumptions made and the method applied.
The Data
Instana monitors 100% of every call trace, maintaining information about the infrastructure and application for API calls, database queries, messaging and much more. It also maintains infrastructure and application metrics at one-second granularity, as well as events, a dynamic application and infrastructure topology and further relevant data points for its users. This means that Instana has unparalleled data granularity and availability, allowing us to use causal AI to identify probable root causes with specific detail and accuracy.
The Assumptions
One of the core assumptions about root cause analysis in most IT management tools is that the topology of an application is always available and complete at a very granular level. For many IT management tools, this assumption fails because IT management processes are specialized and disparate teams own separate portions of a multi-layered application. This occurs often due to separation of duties between teams, the use of different monitoring tools across an organization and a variety of other possible management process related reasons.
IT Management tools may not have full observability into the topology of a multi-layered application. However, due to our use of causal AI and a versatile algorithm, we are able identify root causes even in cases with limited data granularity and a partial topology. We can even provide insight in the absence of noisy tracing.
The Method
Using causal AI, we can identify root causes of application-impacting faults by joining disparate data sources, such as calls, metrics, events and topology. Not only that, we are also able to showcase how and why certain entities were identified as probable cause, allowing for confidence and trustworthiness of the identified problematic entities. Causal AI gives us a powerful insight on the localization and investigation of problematic components.
An example use case with Stan the SRE
Let’s walk through an experience that Stan the SRE faces. Stan is an SRE that works at a small company that has the robot-shop application deployed on a Kubernetes cluster that is being monitored by Instana. They recently turned on the probable root cause feature and configured a few application smart alerts.

One day he receives this message from the Slack alert channel that was configured with the smart alerts set up on company’s robot-shop application. He learns that there seems to be a performance issue in the robot-shop application. Stan clicks on the incident to examine more information for the investigation process.
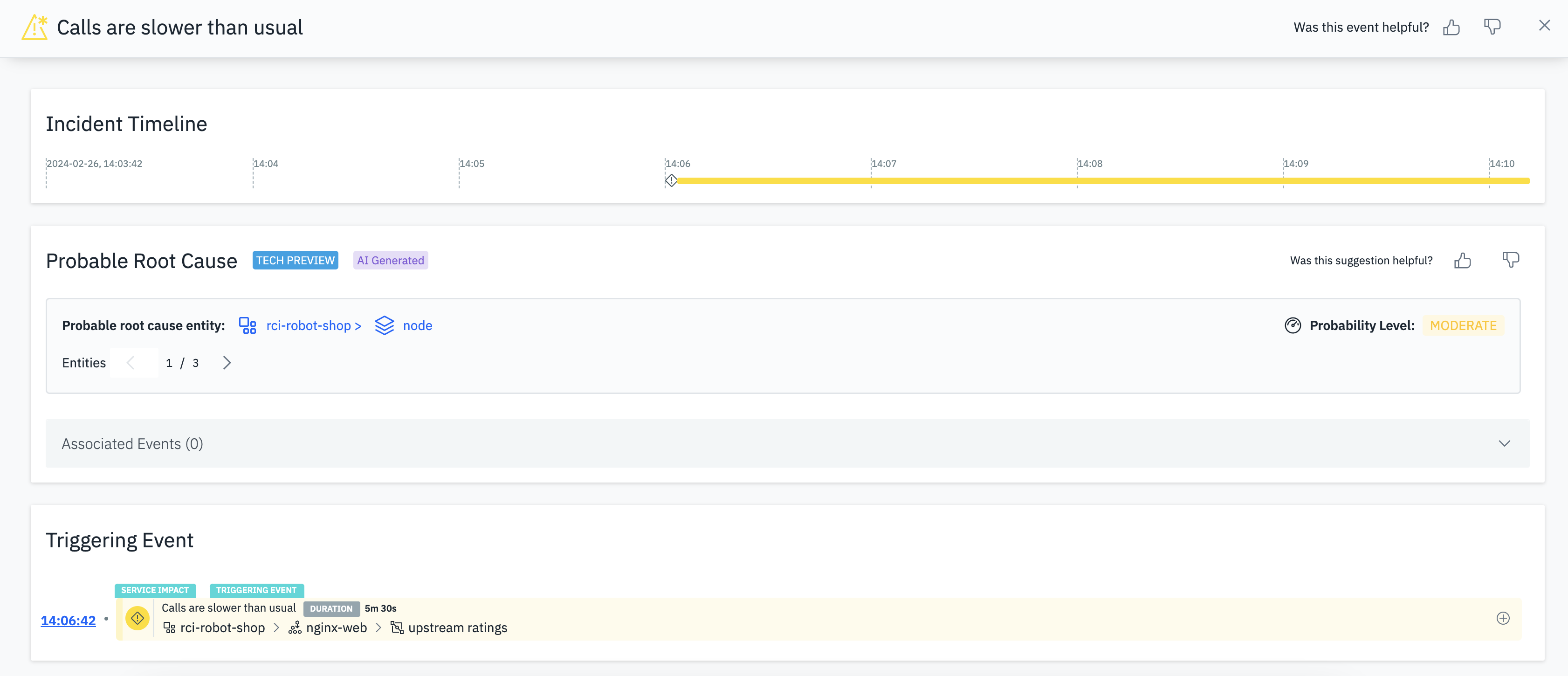
He is presented with the incident page with the new probable root cause panel. The incident page gives Stan some more actionable information, but importantly, he now has a direction to begin and resolve his investigation. The probable root cause points to a specific process within the robot-shop application. This process represents one instance (out of three replicas) of the catalogue service.
He then clicks on the Probable root cause entity link, sending Stan to the call analysis page where he immediately looks at the erroneous calls that ended up with this downstream latency impact.
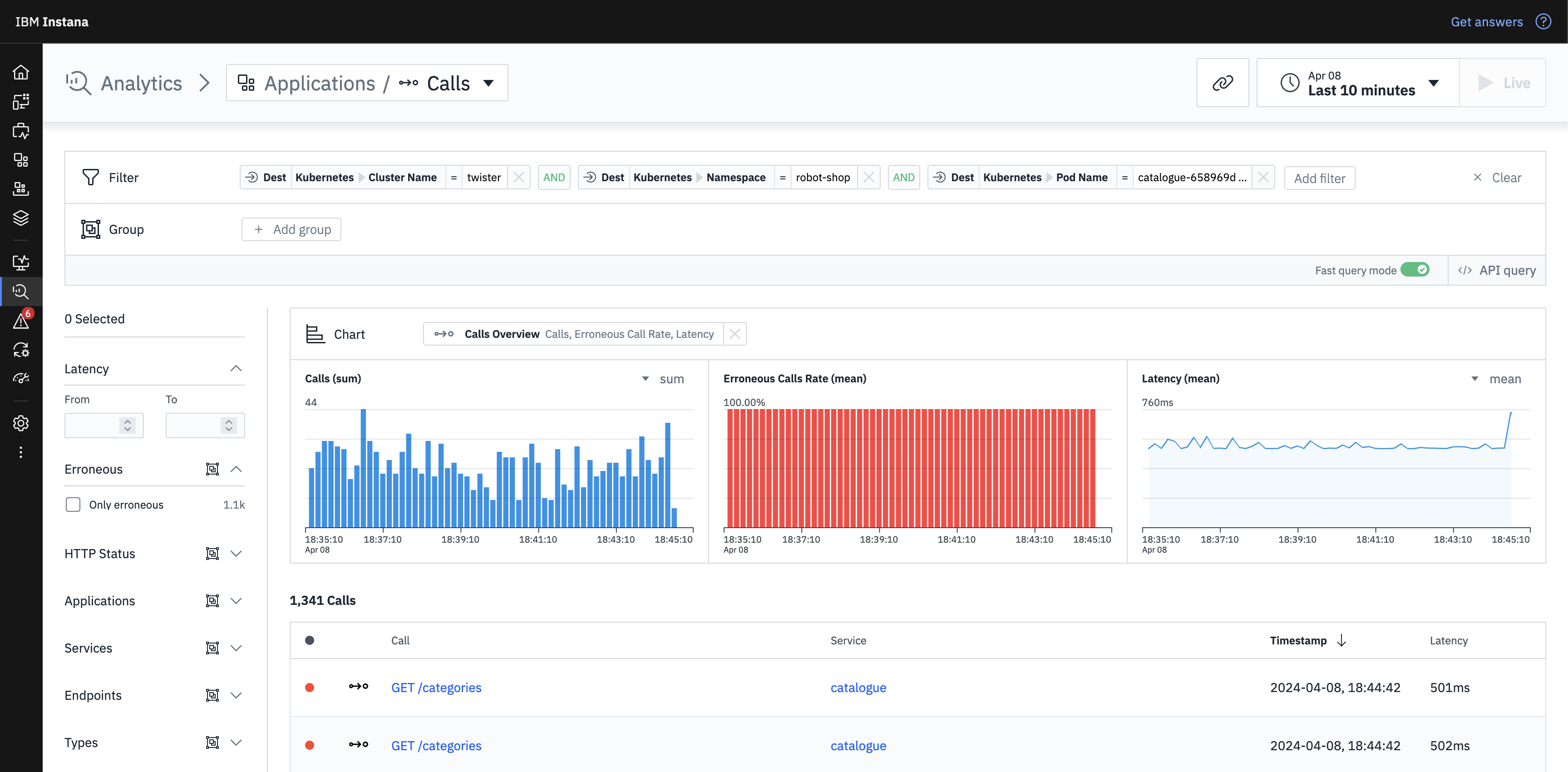
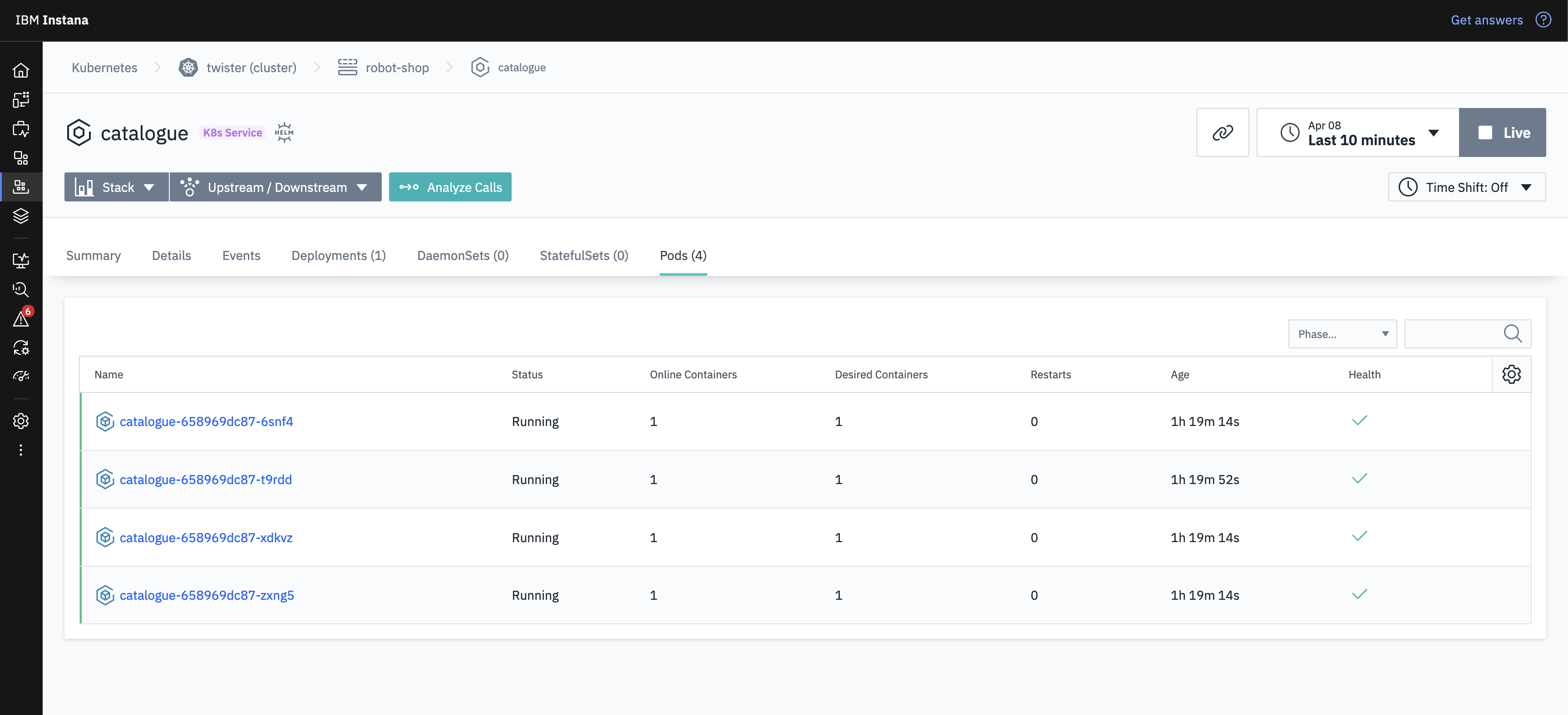
He sees that all the calls to this instance of the catalogue pod were failing with a 503 (Service Unavailable) error. This leads him to check some more infrastructure metrics and he saw that the free memory of that pod was running low and that it’s been running without restart for quite some time. He restarts the pod to remediate in the short term and flags this to review to ensure that this doesn’t happen in the future.
Here, we can see that Stan saved a lot of time in his incident investigation and remediation workflow. Without the probable root cause feature, he would have had to start from incident notification, explore the application dashboards, look at the call traces manually, trace back the call trace until he found the catalogue service, then look further to identify which pod was the problem. He would then have to validate that this is the root cause and remediate accordingly. With the probable root cause feature, Stan saves most of that time and money and can jump straight to remediation.
A vision for the future
Over the next few months, we will expand our root causing abilities to go above and beyond what we have today. While localization of probable root causes is impactful in alleviating the mean time to resolution of application faults, there are several opportunities this opens for us to explore in the next few months.
- Enhanced explainability: Thanks to the usage of Causal AI, the algorithm is fully explainable, allowing us to be able to easily build explainability tools that will tell SREs not just where their problem is, but why that conclusion was come to—all in an elegant and automatic fashion. This allows us to build a story and experience around the identified root cause, creating fast and trustworthy intelligent remediation.
- Learn what happened, not just where it happened: We continue to enhance our solutions to not only point to where the root cause occurred but also to better analyze what happened and how. With some more analysis, we can develop a formulation to tell SREs exact explanations for what went wrong within the faulty entity, instead of just pointing to the faulty entity. This also facilitates a more powerful next step in the intelligent incident remediation initiative—action recommendation for remediation.
We believe this is tremendous potential here and we are extremely proud of the work that has been done. This has been a unique collaboration between engineering and IBM® research, allowing us to move quickly and solve problems on the fly.
We believe this is tremendous potential here and we are extremely proud of the work that has been done. This has been a unique collaboration between engineering and IBM® research, allowing us to move quickly and solve problems on the fly.
Note: The Probable Root Cause Feature is currently in tech preview, and triggered upon incidents that are created from an application or service level smart alert configuration. Full version coming soon!
Was this article helpful?
YesNo
More from IBM Instana

February 23, 2024
Observe GenAI with IBM Instana Observability
6 min read – The emergence of generative artificial intelligence (GenAI), powered by large language models (LLMs) has accelerated the widespread adoption of artificial intelligence. GenAI is proving to be very effective in tackling a variety of complex use cases with AI systems operating at levels that are comparable to humans. Organisations are quickly realizing the value of AI and its transformative potential for business, adding trillions of dollars to the economy. Given this emerging landscape, IBM Instana Observability is on a mission to…

January 30, 2024
Average 219% ROI: The Total Economic Impact™ of IBM Instana Observability
2 min read – What can your organization achieve with a modern observability solution? Data from a new Forrester Consulting study showed that a composite organization that used the IBM Instana™ Observability platform achieved a 219% ROI over three years. Likewise, it saw a 90% reduction in troubleshooting time by providing high fidelity data to the right people at the right time. About the study IBM commissioned Forrester to conduct the Total Economic Impact™ (TEI) study by interviewing four clients about the value of their…

January 26, 2024
Instana 2023: Recapping our latest innovation
7 min read – You asked, and we delivered! At Instana, addressing our customers’ needs and creating a simple tool that is easy to use is fundamental to helping our DevOps and SRE teams reduce burnout rates, allowing them to excel in what they do best. Taking all your feedback and market insights into perspective and careful consideration, we are thrilled to announce that in 2023. Our team announced different product capabilities designed to simplify your teams’ ability to observe, debug, remediate and enhance…
IBM Newsletters
Get our newsletters and topic updates that deliver the latest thought leadership and insights on emerging trends.
Subscribe now
More newsletters
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.ibm.com/blog/probable-root-cause-accelerating-incident-remediation-with-causal-ai/
- :has
- :is
- :not
- :where
- $UP
- 00
- 000
- 02
- 06
- 1
- 116
- 2%
- 2023
- 2024
- 23
- 26
- 28
- 29
- 30
- 300
- 36
- 4
- 400
- 41
- 5
- 50
- 500
- 58
- 6
- 7
- 9
- a
- abilities
- ability
- Able
- About
- above
- absence
- accelerated
- accelerating
- accordingly
- accuracy
- Achieve
- achieved
- across
- actionable
- actively
- adding
- addressing
- Adoption
- Advertising
- again
- AI
- AI systems
- AIOps
- Alert
- Alerts
- algorithm
- All
- alleviate
- Allowing
- allows
- also
- always
- amp
- an
- analysis
- analytics
- analyze
- analyzes
- and
- and infrastructure
- Announce
- announced
- api
- Application
- applications
- ARE
- around
- article
- artificial
- artificial intelligence
- AS
- asked
- assumption
- assumptions
- At
- author
- Automatic
- automatically
- availability
- available
- average
- avoiding
- back
- BE
- because
- been
- begin
- being
- believe
- BEST
- Better
- between
- Beyond
- Blog
- Blue
- build
- Building
- burnout
- business
- businesses
- but
- button
- by
- call
- Calls
- CAN
- capabilities
- carbon
- card
- Cards
- careful
- case
- cases
- casual
- CAT
- Category
- Cause
- causes
- causing
- certain
- Channel
- check
- circles
- class
- clients
- Clothing
- Cloud
- Cluster
- collaboration
- color
- come
- coming
- company
- Company’s
- comparable
- complete
- complex
- complexity
- components
- conclusion
- Conduct
- confidence
- Configuration
- configured
- considerable
- consideration
- consulting
- Container
- continue
- copy
- Core
- Cost
- costly
- created
- Creating
- creation
- CSS
- Currently
- custom
- Customers
- dashboards
- data
- data points
- Database
- Date
- day
- Default
- definitions
- deliver
- depend
- deployed
- description
- designed
- detail
- develop
- Development
- DevOps
- different
- digitization
- direction
- directly
- disparate
- do
- Doesn’t
- dollars
- done
- downtime
- due
- dynamic
- easily
- easy
- Economic
- economy
- Effective
- efficiently
- emergence
- emerging
- ended
- Engineering
- Engineers
- enhance
- ensure
- Enter
- entities
- entity
- error
- estimated
- Ether (ETH)
- Even
- events
- Every
- exact
- examine
- example
- Excel
- Exit
- Expand
- experience
- Explainability
- explanations
- explore
- extremely
- faces
- facilitates
- failing
- fails
- Failure
- false
- Fashion
- FAST
- faults
- faulty
- Feature
- February
- feedback
- few
- fidelity
- flags
- focal
- follow
- fonts
- For
- formulation
- Forrester
- found
- four
- Free
- from
- full
- fully
- fundamental
- further
- future
- genai
- generative
- generator
- get
- given
- gives
- glasses
- Go
- granular
- Grid
- Growing
- had
- happen
- happened
- Have
- he
- Heading
- height
- helpful
- helping
- here
- High
- High Fidelity
- him
- his
- HOURS
- How
- However
- HTTPS
- Humans
- Hybrid
- hybrid cloud
- IBM
- ICO
- ICON
- identified
- identifies
- identify
- image
- immediately
- Impact
- impactful
- importantly
- in
- incident
- incidents
- index
- information
- Infrastructure
- Innovation
- insight
- insights
- instance
- instead
- Intelligence
- Intelligent
- into
- intrinsic
- introduced
- investigation
- issue
- IT
- IT Management
- ITS
- January
- joining
- jpg
- jump
- just
- Kubernetes
- landscape
- language
- laptop
- large
- Latency
- latest
- Leadership
- Leads
- learning
- learns
- Level
- levels
- likewise
- Limited
- LINK
- local
- locale
- Localization
- Look
- looking
- LOOKS
- Lot
- Low
- made
- maintaining
- maintains
- management
- Management Tools
- manager
- manually
- many
- Market
- market insights
- max-width
- May..
- mean
- means
- Memory
- message
- messaging
- method
- Metrics
- min
- minutes
- Mission
- Mobile
- models
- Modern
- money
- monitored
- monitoring
- monitors
- months
- more
- most
- move
- moving
- much
- multi-layered
- Navigation
- needs
- New
- new feature
- Newsletters
- next
- nothing
- notification
- now
- observe
- occurred
- of
- off
- often
- on
- ONE
- only
- opens
- operating
- opportunities
- optimized
- or
- Organisations
- organization
- Other
- our
- out
- Outages
- over
- own
- page
- panel
- part
- partial
- People
- per
- performance
- person
- perspective
- PHP
- platform
- plato
- Plato Data Intelligence
- PlatoData
- plugin
- Point
- points
- policy
- portions
- position
- possible
- Post
- potential
- powered
- powerful
- presented
- Preview
- primary
- Problem
- problems
- process
- processes
- Product
- Profile
- proud
- proven
- provide
- providing
- proving
- queries
- quickly
- quite
- Rates
- Reading
- realizing
- reasons
- receives
- recently
- Recommendation
- reduce
- reduction
- related
- relevant
- reliability
- remediation
- represents
- require
- research
- Resolution
- resolve
- responsive
- Results
- review
- right
- robots
- ROI
- root
- Run
- running
- saved
- saving
- saw
- scientists
- Screen
- scripts
- see
- seems
- sees
- sending
- seo
- separate
- service
- set
- several
- Short
- showcase
- showed
- side
- Simple
- simplify
- site
- Sitting
- slack
- small
- smart
- Smart glasses
- So
- solution
- Solutions
- SOLVE
- some
- sometimes
- Source
- Sources
- Space
- specialized
- specific
- Sponsored
- squares
- start
- statistics
- Step
- Story
- straight
- Study
- subscribe
- such
- Surrounding
- SVG
- Systems
- table
- tackling
- taking
- team
- teams
- tech
- tell
- term
- tertiary
- thanks
- that
- The
- The Future
- The Source
- their
- Them
- theme
- then
- There.
- they
- this
- thought
- thought leadership
- three
- thrilled
- Through
- time
- timeline
- Title
- to
- today
- tool
- tools
- top
- topic
- Total
- trace
- Tracing
- transformative
- tremendous
- Trends
- triggered
- trillions
- Triple
- trustworthiness
- trustworthy
- Turned
- type
- unavailable
- unique
- unparalleled
- until
- Updates
- upon
- URL
- us
- Usage
- use
- use case
- used
- users
- using
- VALIDATE
- value
- variety
- versatile
- version
- very
- vision
- W
- walk
- was
- we
- WELL
- well-known
- went
- were
- What
- which
- while
- why
- widespread
- will
- with
- within
- without
- WordPress
- Work
- workflow
- working
- works
- would
- written
- Wrong
- years
- Your
- zephyrnet











