This post is co-written with Karthik Kondamudi and Jenny Thompson from Stitch Fix.
Stitch Fix is a personalized clothing styling service for men, women, and kids. At Stitch Fix, we have been powered by data science since its foundation and rely on many modern data lake and data processing technologies. In our infrastructure, Apache Kafka has emerged as a powerful tool for managing event streams and facilitating real-time data processing. At Stitch Fix, we have used Kafka extensively as part of our data infrastructure to support various needs across the business for over six years. Kafka plays a central role in the Stitch Fix efforts to overhaul its event delivery infrastructure and build a self-service data integration platform.
If you’d like to know more background about how we use Kafka at Stitch Fix, please refer to our previously published blog post, Putting the Power of Kafka into the Hands of Data Scientists. This post includes much more information on business use cases, architecture diagrams, and technical infrastructure.
In this post, we will describe how and why we decided to migrate from self-managed Kafka to Amazon Managed Streaming for Apache Kafka (Amazon MSK). We’ll start with an overview of our self-managed Kafka, why we chose to migrate to Amazon MSK, and ultimately how we did it.
- Kafka clusters overview
- Why migrate to Amazon MSK
- How we migrated to Amazon MSK
- Navigating challenges and lessons learned
- Conclusion
Kafka Clusters Overview
At Stitch Fix, we rely on several different Kafka clusters dedicated to specific purposes. This allows us to scale these clusters independently and apply more stringent SLAs and message delivery guarantees per cluster. This also reduces overall risk by minimizing the impact of changes and upgrades and allows us to isolate and fix any issues that occur within a single cluster.
Our main Kafka cluster serves as the backbone of our data infrastructure. It handles a multitude of critical functions, including managing business events, facilitating microservice communication, supporting feature generation for machine learning workflows, and much more. The stability, reliability, and performance of this cluster are of utmost importance to our operations.
Our logging cluster plays a vital role in our data infrastructure. It serves as a centralized repository for various application logs, including web server logs and Nginx server logs. These logs provide valuable insights for monitoring and troubleshooting purposes. The logging cluster ensures smooth operations and efficient analysis of log data.
Why migrate to Amazon MSK
In the past six years, our data infrastructure team has diligently managed our Kafka clusters. While our team has acquired extensive knowledge in maintaining Kafka, we have also faced challenges such as rolling deployments for version upgrades, applying OS patches, and the overall operational overhead.
At Stitch Fix, our engineers thrive on creating new features and expanding our service offerings to delight our customers. However, we recognized that allocating significant resources to Kafka maintenance was taking away precious time from innovation. To overcome this challenge, we set out to find a managed service provider that could handle maintenance tasks like upgrades and patching while granting us complete control over cluster operations, including partition management and rebalancing. We also sought an effortless scaling solution for storage volumes, keeping our costs in check while being ready to accommodate future growth.
After thorough evaluation of multiple options, we found the perfect match in Amazon MSK because it allows us to offload cluster maintenance to the highly skilled Amazon engineers. With Amazon MSK in place, our teams can now focus their energy on developing innovative applications unique and valuable to Stitch Fix, instead of getting caught up in Kafka administration tasks.
Amazon MSK streamlines the process, eliminating the need for manual configurations, additional software installations, and worries about scaling. It simply works, enabling us to concentrate on delivering exceptional value to our cherished customers.
How we migrated to Amazon MSK
While planning our migration, we desired to switch specific services to Amazon MSK individually with no downtime, ensuring that only a specific subset of services would be migrated at a time. The overall infrastructure would run in a hybrid environment where some services connect to Amazon MSK and others to the existing Kafka infrastructure.
We decided to start the migration with our less critical logging cluster first and then proceed to migrating the main cluster. Although the logs are essential for monitoring and troubleshooting purposes, they hold relatively less significance to the core business operations. Additionally, the number and types of consumers and producers for the logging cluster is smaller, making it an easier choice to start with. Then, we were able to apply our learnings from the logging cluster migration to the main cluster. This deliberate choice enabled us to execute the migration process in a controlled manner, minimizing any potential disruptions to our critical systems.
Over the years, our experienced data infrastructure team has employed Apache Kafka MirrorMaker 2 (MM2) to replicate data between different Kafka clusters. Currently, we rely on MM2 to replicate data from two different production Kafka clusters. Given its proven track record within our organization, we decided to use MM2 as the primary tool for our data migration process.
The general guidance for MM2 is as follows:
- Begin with less critical applications.
- Perform active migrations.
- Familiarize yourself with key best practices for MM2.
- Implement monitoring to validate the migration.
- Accumulate essential insights for migrating other applications.
MM2 offers flexible deployment options, allowing it to function as a standalone cluster or be embedded within an existing Kafka Connect cluster. For our migration project, we deployed a dedicated Kafka Connect cluster operating in distributed mode.
This setup provided the scalability we needed, allowing us to easily expand the standalone cluster if necessary. Depending on specific use cases such as geoproximity, high availability (HA), or migrations, MM2 can be configured for active-active replication, active-passive replication, or both. In our case, as we migrated from self-managed Kafka to Amazon MSK, we opted for an active-passive configuration, where MirrorMaker was used for migration purposes and subsequently taken offline upon completion.
MirrorMaker configuration and replication policy
By default, MirrorMaker renames replication topics by prefixing the name of the source Kafka cluster to the destination cluster. For instance, if we replicate topic A from the source cluster “existing” to the new cluster “newkafka,” the replicated topic would be named “existing.A” in “newkafka.” However, this default behavior can be modified to maintain consistent topic names within the newly created MSK cluster.
To maintain consistent topic names in the newly created MSK cluster and avoid downstream issues, we utilized the CustomReplicationPolicy jar provided by AWS. This jar, included in our MirrorMaker setup, allowed us to replicate topics with identical names in the MSK cluster. Additionally, we utilized MirrorCheckpointConnector to synchronize consumer offsets from the source cluster to the target cluster and MirrorHeartbeatConnector to ensure connectivity between the clusters.
Monitoring and metrics
MirrorMaker comes equipped with built-in metrics to monitor replication lag and other essential parameters. We integrated these metrics into our MirrorMaker setup, exporting them to Grafana for visualization. Since we have been using Grafana to monitor other systems, we decided to use it during migration as well. This enabled us to closely monitor the replication status during the migration process. The specific metrics we monitored will be described in more detail below.
Additionally, we monitored the MirrorCheckpointConnector included with MirrorMaker, as it periodically emits checkpoints in the destination cluster. These checkpoints contained offsets for each consumer group in the source cluster, ensuring seamless synchronization between the clusters.
Network layout
At Stitch Fix, we use several virtual private clouds (VPCs) through Amazon Virtual Private Cloud (Amazon VPC) for environment isolation in each of our AWS accounts. We have been using separate production and staging VPCs since we initially started using AWS. When necessary, peering of VPCs across accounts is handled through AWS Transit Gateway. To maintain the strong isolation between environments we have been using all along, we created separate MSK clusters in their respective VPCs for production and staging environments.
Side note: It will be easier now to quickly connect Kafka clients hosted in different virtual private clouds with recently announced Amazon MSK multi-VPC private connectivity, which was not available at the time of our migration.
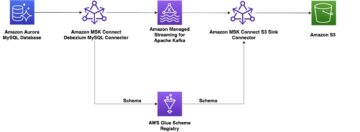
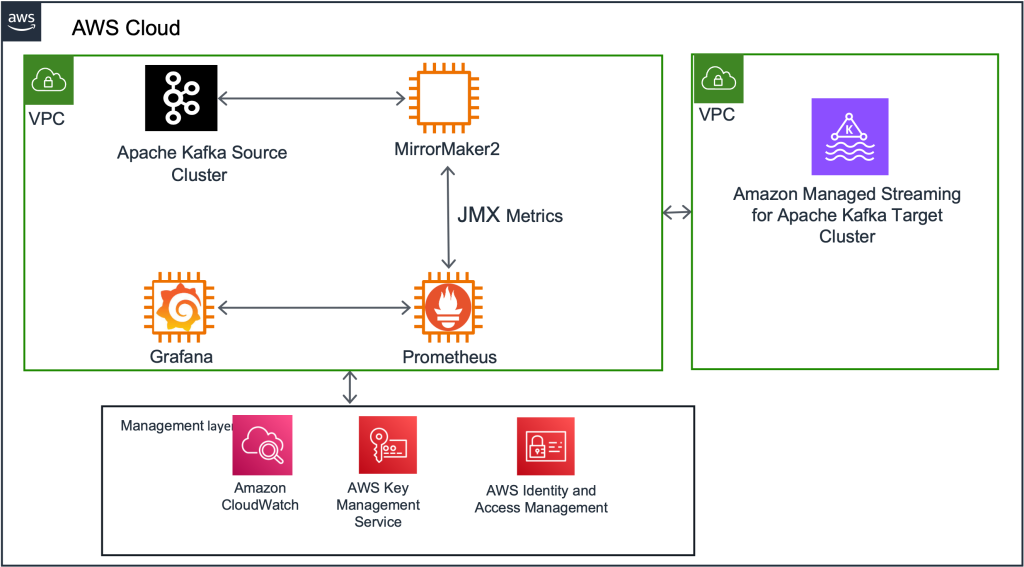
Migration steps: High-level overview
In this section, we outline the high-level sequence of events for the migration process.
![]()
Kafka Connect setup and MM2 deploy
First, we deployed a new Kafka Connect cluster on an Amazon Elastic Compute Cloud (Amazon EC2) cluster as an intermediary between the existing Kafka cluster and the new MSK cluster. Next, we deployed the 3 MirrorMaker connectors to this Kafka Connect cluster. Initially, this cluster was configured to mirror all the existing topics and their configurations into the destination MSK cluster. (We eventually changed this configuration to be more granular, as described in the “Navigating challenges and lessons learned” section below.)
Monitor replication progress with MM metrics
Take advantage of the JMX metrics offered by MirrorMaker to monitor the progress of data replication. In addition to comprehensive metrics, we primarily focused on key metrics, namely replication-latency-ms and checkpoint-latency-ms. These metrics provide invaluable insights into the replication status, including crucial aspects such as replication lag and checkpoint latency. By seamlessly exporting these metrics to Grafana, you gain the ability to visualize and closely track the progress of replication, ensuring the successful reproduction of both historical and new data by MirrorMaker.
Evaluate usage metrics and provisioning
Analyze the usage metrics of the new MSK cluster to ensure proper provisioning. Consider factors such as storage, throughput, and performance. If required, resize the cluster to meet the observed usage patterns. While resizing may introduce additional time to the migration process, it is a cost-effective measure in the long run.
Sync consumer offsets between source and target clusters
Ensure that consumer offsets are synchronized between the source in-house clusters and the target MSK clusters. Once the consumer offsets are in sync, redirect the consumers of the existing in-house clusters to consume data from the new MSK cluster. This step ensures a seamless transition for consumers and allows uninterrupted data flow during the migration.
Update producer applications
After confirming that all consumers are successfully consuming data from the new MSK cluster, update the producer applications to write data directly to the new cluster. This final step completes the migration process, ensuring that all data is now being written to the new MSK cluster and taking full advantage of its capabilities.
Navigating challenges and lessons learned
During our migration, we encountered three challenges that required careful attention: scalable storage, more granular configuration of replication configuration, and memory allocation.
Initially, we faced issues with auto scaling Amazon MSK storage. We learned storage auto scaling requires a 24-hour cool-off period before another scaling event can occur. We observed this when migrating the logging cluster, and we applied our learnings from this and factored in the cool-off period during production cluster migration.
Additionally, to optimize MirrorMaker replication speed, we updated the original configuration to divide the replication jobs into batches based on volume and allocated more tasks to high-volume topics.
During the initial phase, we initiated replication using a single connector to transfer all topics from the source to target clusters, encompassing a significant number of tasks. However, we encountered challenges such as increasing replication lag for high-volume topics and slower replication for specific topics. Upon careful examination of the metrics, we adopted an alternative approach by segregating high-volume topics into multiple connectors. In essence, we divided the topics into categories of high, medium, and low volumes, assigning them to respective connectors and adjusting the number of tasks based on replication latency. This strategic adjustment yielded positive outcomes, allowing us to achieve faster and more efficient data replication across the board.
Lastly, we encountered Java virtual machine heap memory exhaustion, resulting in missing metrics while running MirrorMaker replication. To address this, we increased memory allocation and restarted the MirrorMaker process.
Conclusion
Stitch Fix’s migration from self-managed Kafka to Amazon MSK has allowed us to shift our focus from maintenance tasks to delivering value for our customers. It has reduced our infrastructure costs by 40 percent and given us the confidence that we can easily scale the clusters in the future if needed. By strategically planning the migration and using Apache Kafka MirrorMaker, we achieved a seamless transition while ensuring high availability. The integration of monitoring and metrics provided valuable insights during the migration process, and Stitch Fix successfully navigated challenges along the way. The migration to Amazon MSK has empowered Stitch Fix to maximize the capabilities of Kafka while benefiting from the expertise of Amazon engineers, setting the stage for continued growth and innovation.
Further reading
About the Authors
![]() Karthik Kondamudi is an Engineering Manager in the Data and ML Platform Group at StitchFix. His interests lie in Distributed Systems and large-scale data processing. Beyond work, he enjoys spending time with family and hiking. A dog lover, he’s also passionate about sports, particularly cricket, tennis, and football.
Karthik Kondamudi is an Engineering Manager in the Data and ML Platform Group at StitchFix. His interests lie in Distributed Systems and large-scale data processing. Beyond work, he enjoys spending time with family and hiking. A dog lover, he’s also passionate about sports, particularly cricket, tennis, and football.
![]() Jenny Thompson is a Data Platform Engineer at Stitch Fix. She works on a variety of systems for Data Scientists, and enjoys making things clean, simple, and easy to use. She also likes making pancakes and Pavlova, browsing for furniture on Craigslist, and getting rained on during picnics.
Jenny Thompson is a Data Platform Engineer at Stitch Fix. She works on a variety of systems for Data Scientists, and enjoys making things clean, simple, and easy to use. She also likes making pancakes and Pavlova, browsing for furniture on Craigslist, and getting rained on during picnics.
![]() Rahul Nammireddy is a Senior Solutions Architect at AWS, focusses on guiding digital native customers through their cloud native transformation. With a passion for AI/ML technologies, he works with customers in industries such as retail and telecom, helping them innovate at a rapid pace. Throughout his 23+ years career, Rahul has held key technical leadership roles in a diverse range of companies, from startups to publicly listed organizations, showcasing his expertise as a builder and driving innovation. In his spare time, he enjoys watching football and playing cricket.
Rahul Nammireddy is a Senior Solutions Architect at AWS, focusses on guiding digital native customers through their cloud native transformation. With a passion for AI/ML technologies, he works with customers in industries such as retail and telecom, helping them innovate at a rapid pace. Throughout his 23+ years career, Rahul has held key technical leadership roles in a diverse range of companies, from startups to publicly listed organizations, showcasing his expertise as a builder and driving innovation. In his spare time, he enjoys watching football and playing cricket.
![]() Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn.
Todd McGrath is a data streaming specialist at Amazon Web Services where he advises customers on their streaming strategies, integration, architecture, and solutions. On the personal side, he enjoys watching and supporting his 3 teenagers in their preferred activities as well as following his own pursuits such as fishing, pickleball, ice hockey, and happy hour with friends and family on pontoon boats. Connect with him on LinkedIn.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/stitch-fix-seamless-migration-transitioning-from-self-managed-kafka-to-amazon-msk/
- :has
- :is
- :not
- :where
- $UP
- 100
- 40
- a
- ability
- Able
- About
- accommodate
- Accounts
- Achieve
- achieved
- acquired
- across
- active
- activities
- addition
- Additional
- Additionally
- address
- adjusting
- Adjustment
- administration
- adopted
- ADvantage
- AI/ML
- All
- allocated
- allocation
- allowed
- Allowing
- allows
- along
- also
- alternative
- Although
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- analysis
- and
- announced
- Another
- any
- Apache
- Apache Kafka
- Application
- applications
- applied
- Apply
- Applying
- approach
- architecture
- ARE
- AS
- aspects
- At
- attention
- auto
- availability
- available
- avoid
- away
- AWS
- Backbone
- background
- based
- BE
- because
- been
- before
- behavior
- being
- below
- benefiting
- BEST
- best practices
- between
- Beyond
- Blog
- board
- both
- Browsing
- build
- builder
- built-in
- business
- business operations
- by
- CAN
- capabilities
- Career
- careful
- case
- cases
- categories
- caught
- central
- centralized
- challenge
- challenges
- changed
- Changes
- check
- choice
- chose
- clients
- closely
- Clothing
- Cloud
- cloud native
- Cluster
- comes
- Communication
- Companies
- complete
- Completes
- completion
- comprehensive
- Compute
- concentrate
- confidence
- Configuration
- configurations
- configured
- Connect
- Connectivity
- Consider
- consistent
- consume
- consumer
- Consumers
- contained
- continued
- control
- controlled
- Core
- cost-effective
- Costs
- could
- created
- Creating
- cricket
- critical
- crucial
- Currently
- Customers
- data
- data infrastructure
- data integration
- Data Lake
- Data Platform
- data processing
- data science
- decided
- dedicated
- Default
- delight
- delivering
- delivery
- Depending
- deployed
- deployment
- deployments
- describe
- described
- desired
- destination
- detail
- developing
- diagrams
- DID
- different
- digital
- diligently
- directly
- disruptions
- distributed
- distributed systems
- diverse
- divide
- divided
- Dog
- downtime
- driving
- during
- each
- easier
- easily
- easy
- efficient
- effortless
- efforts
- eliminating
- embedded
- emerged
- empowered
- enabled
- enabling
- encompassing
- energy
- engineer
- Engineering
- Engineers
- ensure
- ensures
- ensuring
- Environment
- environments
- equipped
- essence
- essential
- Ether (ETH)
- evaluation
- Event
- events
- eventually
- examination
- exceptional
- execute
- existing
- Expand
- expanding
- experienced
- expertise
- extensive
- extensively
- faced
- facilitating
- factored
- factors
- family
- faster
- Feature
- Features
- final
- Find
- First
- Fishing
- Fix
- flexible
- flow
- Focus
- focused
- following
- follows
- Football
- For
- For Consumers
- found
- Foundation
- friends
- from
- full
- function
- functions
- future
- future growth
- Gain
- gateway
- General
- generation
- getting
- given
- granting
- Group
- Growth
- guarantees
- guidance
- handle
- handled
- Handles
- Hands
- happy
- Have
- he
- Held
- helping
- High
- high-level
- highly
- hiking
- him
- his
- historical
- hold
- hosted
- hour
- How
- However
- HTML
- HTTPS
- Hybrid
- ICE
- identical
- if
- Impact
- importance
- in
- included
- includes
- Including
- increased
- increasing
- independently
- Individually
- industries
- information
- Infrastructure
- initial
- initially
- initiated
- innovate
- Innovation
- innovative
- insights
- instance
- instead
- integrated
- integration
- interests
- intermediary
- into
- introduce
- invaluable
- isolation
- issues
- IT
- ITS
- Java
- Jobs
- jpg
- kafka
- keeping
- Key
- kids
- Know
- knowledge
- lake
- large-scale
- Latency
- Leadership
- learned
- learning
- less
- Lessons
- lie
- like
- likes
- Listed
- log
- logging
- Long
- Low
- machine
- machine learning
- Main
- maintain
- maintaining
- maintenance
- Making
- managed
- management
- manager
- managing
- manner
- manual
- many
- Match
- Maximize
- May..
- measure
- medium
- Meet
- Memory
- Men
- message
- Metrics
- migrate
- migrated
- migrating
- migration
- minimizing
- mirror
- missing
- ML
- Mode
- Modern
- modified
- Monitor
- monitored
- monitoring
- more
- more efficient
- much
- multiple
- multitude
- name
- Named
- namely
- names
- native
- necessary
- Need
- needed
- needs
- New
- New Features
- newly
- next
- NGINX
- no
- note
- now
- number
- observed
- occur
- of
- offered
- Offerings
- Offers
- offline
- offsets
- on
- once
- only
- operating
- operational
- Operations
- Optimize
- Options
- or
- organization
- organizations
- original
- OS
- Other
- Others
- our
- out
- outcomes
- outline
- over
- overall
- Overcome
- Overhaul
- overview
- own
- Pace
- parameters
- part
- particularly
- passion
- passionate
- past
- Patches
- Patching
- patterns
- per
- percent
- perfect
- performance
- period
- personal
- Personalized
- phase
- Place
- planning
- platform
- plato
- Plato Data Intelligence
- PlatoData
- playing
- plays
- please
- positive
- Post
- potential
- power
- powered
- powerful
- practices
- Precious
- preferred
- previously
- primarily
- primary
- private
- proceed
- process
- processing
- producer
- Producers
- Production
- Progress
- project
- proper
- proven
- provide
- provided
- provider
- publicly
- publicly listed
- published
- purposes
- Putting
- quickly
- range
- rapid
- ready
- real-time
- real-time data
- rebalancing
- recently
- recognized
- record
- redirect
- Reduced
- reduces
- refer
- relatively
- reliability
- rely
- replicated
- replication
- repository
- reproduction
- required
- requires
- Resources
- respective
- restarted
- resulting
- retail
- Risk
- Role
- roles
- Rolling
- Run
- running
- Scalability
- scalable
- Scale
- scaling
- Scaling Solution
- Science
- scientists
- seamless
- seamlessly
- Section
- Self-service
- senior
- separate
- Sequence
- server
- serves
- service
- Service Provider
- Services
- set
- setting
- setup
- several
- she
- shift
- showcasing
- side
- significance
- significant
- Simple
- simply
- since
- single
- SIX
- skilled
- smaller
- smooth
- Software
- solution
- Solutions
- some
- sought
- Source
- specialist
- specific
- speed
- Spending
- Sports
- Stability
- Stage
- staging
- standalone
- start
- started
- Startups
- Status
- Step
- Steps
- storage
- Strategic
- Strategically
- strategies
- streaming
- streams
- strong
- Subsequently
- successful
- Successfully
- such
- support
- Supporting
- Switch
- synchronization
- Systems
- taken
- taking
- Target
- tasks
- team
- teams
- Technical
- Technologies
- teenagers
- telecom
- tennis
- that
- The
- The Future
- The Source
- their
- Them
- then
- These
- they
- things
- this
- thompson
- three
- Thrive
- Through
- throughout
- throughput
- time
- to
- tool
- topic
- Topics
- track
- track record
- transfer
- Transformation
- transit
- transition
- transitioning
- two
- types
- Ultimately
- unique
- Update
- updated
- upgrades
- upon
- us
- Usage
- use
- used
- using
- utilized
- VALIDATE
- Valuable
- value
- variety
- various
- version
- Virtual
- virtual machine
- visualization
- visualize
- vital
- volume
- volumes
- was
- watching
- Way..
- we
- web
- web server
- web services
- WELL
- were
- when
- which
- while
- why
- will
- with
- within
- Women
- Work
- workflows
- works
- would
- write
- written
- years
- yielded
- you
- yourself
- zephyrnet