Colmeia Apache é um sistema de data warehouse baseado em SQL para processamento de conjuntos de dados altamente distribuídos na plataforma Apache Hadoop. Há dois componentes principais no Apache Hive: o mecanismo de consulta Hive SQL e o metastore Hive (HMS). O metastore do Hive é um repositório de metadados sobre as tabelas SQL, como nomes de bancos de dados, nomes de tabelas, esquema, informações de serialização e desserialização, localização de dados e detalhes de partição de cada tabela. Apache Hive, Apache Spark, Presto e Trino podem usar um Hive Metastore para recuperar metadados para executar consultas. O metastore Hive pode ser hospedado em um cluster Apache Hadoop ou pode ser apoiado por um banco de dados relacional externo a um cluster Hadoop. Embora o metastore do Hive armazene os metadados das tabelas, os dados reais da tabela podem residir em Serviço de armazenamento simples da Amazon (Amazon S3), o Hadoop Distributed File System (HDFS) do cluster Hadoop ou qualquer outro armazenamento de dados compatível com o Hive.
Como o Apache Hive foi construído sobre o Apache Hadoop, muitas organizações usam o software desde o momento em que usam o Hadoop para processamento de big data. Além disso, o metastore do Hive fornece integração flexível com muitos outros softwares de big data de código aberto, como Apache HBase, Apache Spark, Presto e Apache Impala. Portanto, as organizações passaram a hospedar grandes volumes de metadados de seus conjuntos de dados estruturados no metastore do Hive. Um metastore é uma parte crítica de um data lake, e ter essas informações disponíveis, onde quer que residam, é importante. No entanto, muitos serviços de análise da AWS não se integram nativamente com o metastore Hive e, portanto, as organizações tiveram que migrar seus dados para o Cola AWS Catálogo de dados para usar esses serviços.
Formação AWS Lake lançou o suporte para gerenciando o acesso do usuário aos metastores do Apache Hive por meio de uma conexão federada do AWS Glue. Anteriormente, você podia usar o Lake Formation para gerenciar permissões de usuário em Catálogo de dados do AWS Glue apenas recursos. Com a conexão Hive metastore do AWS Glue, você pode se conectar a um banco de dados em um metastore Hive externo ao Data Catalog, mapeá-lo para um banco de dados federado no Data Catalog, aplicar permissões Lake Formation no banco de dados e tabelas Hive, compartilhá-los com outras contas da AWS e consultá-los usando serviços como Amazona atena, Espectro Amazon Redshift, Amazon EMRe AWS Glue ETL (extrair, transformar e carregar). Para obter detalhes adicionais sobre como funciona a integração do metastore do Hive com o Lake Formation, consulte Gerenciando permissões em conjuntos de dados que usam metastores externos.
Os casos de uso para integração do metastore do Hive com o Catálogo de Dados incluem o seguinte:
- Um metastore Apache Hive externo usado para cargas de trabalho de big data legadas, como clusters Hadoop locais com dados no Amazon S3
- Cargas de trabalho transitórias do Amazon EMR com dados subjacentes no Amazon S3 e o metastore Hive em Serviço de banco de dados relacional da Amazon (Amazon RDS).
Nesta postagem, demonstramos como aplicar as permissões do Lake Formation em um banco de dados e tabelas metastore do Hive e consultá-los usando o Athena. Ilustramos um caso de uso de compartilhamento entre contas, em que um administrador Lake Formation na conta de produtor A compartilha um banco de dados Hive federado e tabelas usando LF-Tags para a conta de consumidor B.
Visão geral da solução
A conta do produtor A hospeda um metastore Apache Hive em um cluster EMR, com dados subjacentes no Amazon S3. Lançamos o conector metastore AWS Glue Hive de Repositório de aplicativos sem servidor da AWS na conta A e crie a conexão metastore do Hive no catálogo de dados da conta A. Depois de criarmos a conexão HMS, criamos um banco de dados no Catálogo de Dados da conta A (chamado banco de dados federado) e o mapeamos para um banco de dados no metastore do Hive usando a conexão. As tabelas do banco de dados Hive podem ser acessadas pelo administrador do Lake Formation na conta A, assim como qualquer outra tabela no Data Catalog. O administrador continua a configurar o controle de acesso baseado em tags Lake Formation (LF-TBAC) no banco de dados Hive federado e o compartilha com a conta B.
Os usuários do data lake na conta B acessarão o banco de dados Hive e as tabelas da conta A, assim como consultar qualquer outro recurso compartilhado do Data Catalog usando as permissões Lake Formation.
O diagrama a seguir ilustra essa arquitetura.
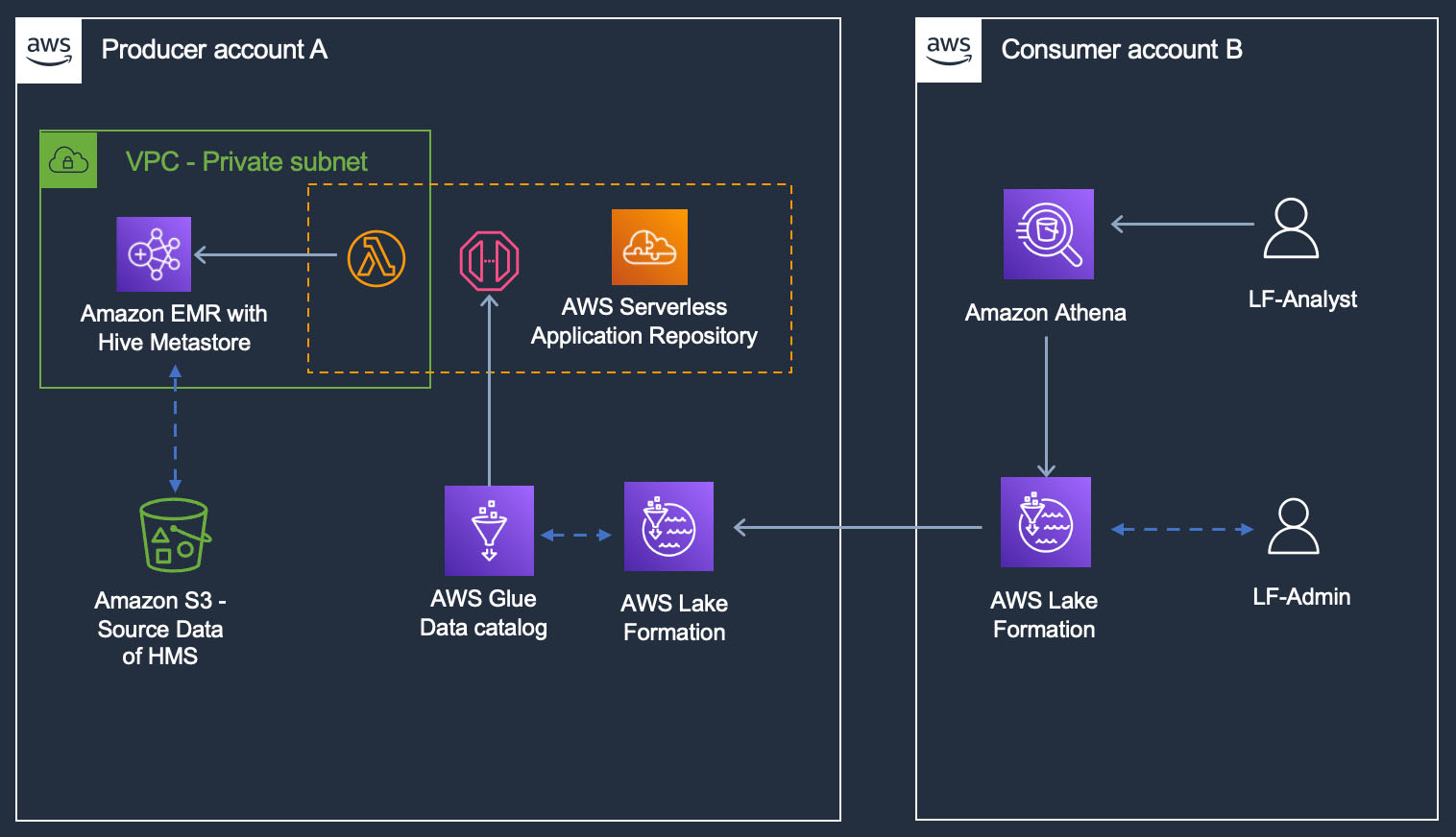
A solução consiste em etapas em ambas as contas. Na conta A, execute as seguintes etapas:
- Crie um bucket do S3 para hospedar os dados de amostra.
- Inicie um cluster EMR 6.10 com o Hive. Baixe os dados de amostra para o bucket do S3. Crie um banco de dados e tabelas externas, apontando para os dados de exemplo baixados, em seu metastore Hive.
- Implantar o aplicativo GlueDataCatalogFederation-HiveMetastore do AWS Serverless Application Repository e configure-o para usar o metastore do Amazon EMR Hive. Isso criará uma conexão do AWS Glue com o metastore do Hive que aparece no console do Lake Formation.
- Usando a conexão metastore do Hive, crie um banco de dados federado no Catálogo de dados do AWS Glue.
- Crie LF-Tags e associe-os ao banco de dados federado.
- Conceda permissões nos LF-Tags para a conta B. Conceda permissões de banco de dados e tabelas para a conta B usando expressões LF-Tag.
Na conta B, execute as seguintes etapas:
- Como administrador do data lake, revise e aceite o Gerenciador de acesso a recursos da AWS (AWS RAM) convida para os compartilhamentos da conta A.
- O administrador do data lake vê o banco de dados e as tabelas compartilhados. O administrador cria um link de recurso para o banco de dados e concede permissões refinadas a um analista de dados nesta conta.
- Tanto o administrador do data lake quanto o analista de dados consultam as tabelas do Hive disponíveis para eles usando o Athena.
A conta A tem as seguintes personas:
- hmsblog-produtorsteward – Gerencia o data lake na conta do produtor A
A conta B tem as seguintes personas:
- hmsblog-consumidor – Gerencia o data lake na conta do consumidor B
- analista de hmsblog – Um analista de dados que precisa de acesso a tabelas Hive selecionadas
Pré-requisitos
Para seguir o tutorial deste post, você precisa do seguinte:
Configuração do Lake Formation e do AWS CloudFormation na conta A
Para simplificar a configuração, temos um administrador do IAM registrado como administrador do data lake. Conclua as seguintes etapas:
- Faça login no Console de gerenciamento da AWS e escolha o
us-west-2Região. - No console do Lake Formation, em Permissões no painel de navegação, escolha Funções e tarefas administrativas.
- Escolha Gerencie Administradores no Administradores de data lake seção.
- Debaixo Usuários e funções IAM, escolha o usuário administrador do IAM com o qual você está conectado e escolha Salvar.
- Escolha Pilha de Lançamento para implantar o modelo CloudFormation:

- Escolha Próximo.
- Forneça um nome para a pilha e escolha Próximo.
- Na próxima página, escolha Próximo.
- Revise os detalhes na página final e selecione Reconheço que o AWS CloudFormation pode criar recursos do IAM.
- Escolha Crie.
A criação da pilha leva cerca de 10 minutos. A pilha estabelece a configuração da conta A do produtor da seguinte forma:
- Cria um bucket de data lake S3
- Registra o bucket do data lake no Lake Formation com o Ativar federação de catálogo bandeira
- Inicia um cluster EMR 6.10 com Hive e executa duas etapas no Amazon EMR:
- Baixa os dados de amostra do bucket S3 público para o bucket recém-criado
- Cria um banco de dados Hive e quatro tabelas externas para os dados no Amazon S3, usando um script HQL
- Cria um usuário do IAM (
hmsblog-producersteward) e define esse usuário como administrador do Lake Formation - Cria LF-Tags (
LFHiveBlogCampaignRole=Admin,Analyst)
Revise a saída da pilha do CloudFormation na conta A
Para revisar a saída de sua pilha do CloudFormation, conclua as seguintes etapas:
- Faça login no console como o usuário administrador do IAM usado anteriormente para executar o modelo do CloudFormation.
- Abra o console do CloudFormation em outra guia do navegador.
- Revise e anote a pilha Saídas detalhes da aba.

- Escolha o link abaixo Valor para
ProducerStewardCredentials.
Isso abrirá o Gerenciador de segredos da AWS console.
- Escolha Recuperar valor e anote as credenciais de
hmsblog-producersteward.

Configurar uma conexão federada do AWS Glue na conta A
Para configurar uma conexão federada do AWS Glue, conclua as seguintes etapas:
- Abra o console do AWS Serverless Application Repository em outra guia do navegador.
- No painel de navegação, escolha Aplicativos disponíveis.
- Selecionar Mostrar aplicativos que criam funções IAM personalizadas ou políticas de recursos.
- Na barra de pesquisa, digite Cola.
Isso listará vários aplicativos.
- Escolha o aplicativo chamado
GlueDataCatalogFederation-HiveMetastore.
Isso abrirá o AWS Lambda página de configuração do console para uma função do Lambda que executa o código do aplicativo do conector.

Para configurar a função Lambda, você precisa de detalhes do cluster EMR iniciado pela pilha do CloudFormation.
- Em outra guia do navegador, abra o console do Amazon EMR.
- Navegue até o cluster iniciado para esta postagem e anote os seguintes detalhes na página de detalhes do cluster:
- DNS público do nó primário
- ID de sub-rede
- ID do grupo de segurança do nó primário


- De volta à página de configuração do Lambda, em Revise, configure e implante, Na As configurações do aplicativo seção, forneça os seguintes detalhes. Deixe o restante como os valores padrão.
- Escolha ColaConnectionName, entrar
hive-metastore-connection. - Escolha HiveMetastoreURIs entrar
thrift://<Primary-node-public-DNS-of your-EMR>:9083. For example, thrift://ec2-54-70-203-146.us-west-2.compute.amazonaws.com:9083, Onde9083é a porta metastore do Hive no cluster EMR. - Escolha IDs de grupo de segurança VPCS, insira o ID do grupo de segurança do nó primário do EMR.
- Escolha IDs de sub-rede VPCS, insira o ID de sub-rede do cluster EMR.
- Escolha ColaConnectionName, entrar
- Escolha Implantação.

Espere pelo Criação Concluída status do aplicativo Lambda. Você pode revisar os detalhes do aplicativo Lambda no console do Lambda.

- Abra o console do Lake Formation e, no painel de navegação, escolha Compartilhamento de dados.
Você deveria ver hive-metastore-connection para Coneções.

- Escolha-o e revise os detalhes.

- No painel de navegação, em Funções e tarefas administrativas, escolha Tags LF.
Você deve ver a tag LF criada LFHiveBlogCampaignRole com dois valores: Analyst e Admin.

- Escolha Permissões LF-Tag e escolha Conceda.
- Escolha Usuários e funções IAM e entre
hmsblog-producersteward. - Debaixo Tags LF, escolha Adicionar LF-Tag.
- Entrar
LFHiveBlogCampaignRolepara Chave e entreAnalysteAdminpara Valores. - Debaixo Permissões, selecione Descrever e Jurídico para Permissões LF-Tag e Permissões concedíveis.
- Escolha Conceda.

Isso dá permissões LF-Tags para o administrador do produtor.
- Efetue logout como usuário administrador do IAM.
Conceder permissões à Lake Formation como administrador do produtor
Conclua as seguintes etapas:
- Entre no console como
hmsblog-producersteward, usando as credenciais da pilha do CloudFormation saída guia que você anotou anteriormente. - No console do Lake Formation, no painel de navegação, escolha Funções e tarefas administrativas.
- Debaixo Criadores de banco de dados, escolha Conceda.

- Adicionar
hmsblog-producerstewardcomo um criador de banco de dados.
- No painel de navegação, escolha Compartilhamento de dados.
- Debaixo Coneções, escolha o
hive-metastore-connectionhiperlink.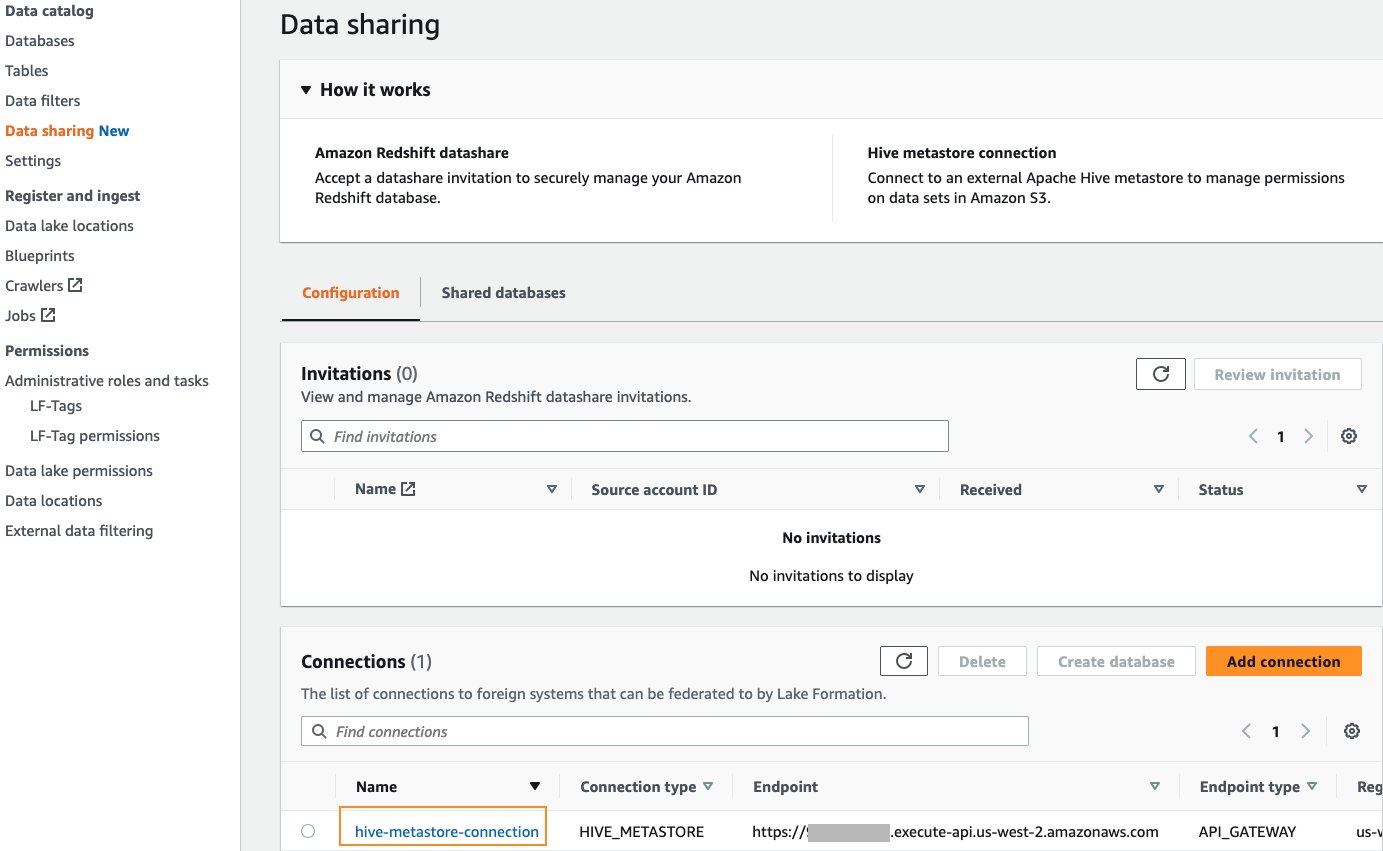
- No Detalhes de conexão página, escolha Criar banco de dados.
- Escolha Nome do banco de dados, entrar
federated_emrhivedb.
Este é o banco de dados federado no Catálogo de dados local do AWS Glue que apontará para um banco de dados metastore do Hive. Este é um mapeamento um-para-um de um banco de dados no Catálogo de Dados para um banco de dados no metastore Hive externo.
- Escolha Identificador de banco de dados, insira o nome do banco de dados no metastore EMR Hive que foi criado pelo script Hive SQL. Para esta postagem, usamos
emrhms_salesdb.
- Depois de criado, selecione
federated_emrhivedbe escolha Ver tabelas.
Isso buscará os metadados do banco de dados e da tabela do metastore Hive no cluster EMR e exibirá as tabelas criadas pelo script Hive.

Agora você associa os LF-Tags criados pelo script CloudFormation neste banco de dados federado e os compartilha com a conta do consumidor B usando expressões LF-Tag.
- No painel de navegação, escolha Bases de dados.
- Selecionar
federated_emrhivedbe sobre o Opções menu, escolha Editar LF-Tags. - Escolha Atribuir nova LF-Tag.
- Entrar
LFHiveBlogCampaignRolepara Chaves atribuídas eAdminpara Valores, Em seguida, escolha Salvar.
- No painel de navegação, escolha Permissões do data lake.
- Escolha Conceda.
- Selecionar Contas externas e insira o número B da conta do consumidor.
- Debaixo LF-Tags ou recursos de catálogo, escolha Recurso correspondido por LF-Tags.
- Escolha Adicionar LF-Tag.
- Entrar
LFHiveBlogCampaignRolepara Chave eAdminpara Valores.
- No Permissões de banco de dados seção, selecione Descrever para Permissões de banco de dados e Permissões concedíveis.
- No Permissões de mesa seção, selecione Selecione e descreva para Permissões de mesa e Permissões concedíveis.
- Escolha Conceda.

- No painel de navegação, em Funções e tarefas administrativas, escolha Permissões LF-Tag.
- Escolha Conceda.
- Selecionar Contas externas e insira o ID da conta do consumidor B.
- Debaixo Tags LF, entrar
LFHiveBlogCampaignRolepara Chave e entreAnalysteAdminpara Valores. - Debaixo Permissões, selecione Descrever e Jurídico para Permissões LF-Tag e Permissões concedíveis.
- Escolha Conceda e verifique se as permissões LF-Tag concedidas são exibidas corretamente.

- No painel de navegação, escolha Permissões do data lake.
Você pode revisar e verificar as permissões concedidas à conta B.

- No painel de navegação, em Funções e tarefas administrativas, escolha Permissões LF-Tag.
Você pode revisar e verificar as permissões concedidas à conta B.

- Saia da conta A.
Configuração do Lake Formation e do AWS CloudFormation na conta B
Para simplificar a configuração, usamos um administrador do IAM registrado como administrador do data lake.
- Faça login no Console de gerenciamento da AWS da conta B e selecione o
us-west-2Região. - No console do Lake Formation, em Permissões no painel de navegação, escolha Funções e tarefas administrativas.
- Escolha Gerenciar administradores no Administradores de data lake seção.
- Em Usuários e funções do IAM, escolha o usuário administrador do IAM com o qual você está conectado e escolha Salvar.
- Escolha Pilha de Lançamento para implantar o modelo CloudFormation:
- Escolha Próximo.
- Forneça um nome para a pilha e escolha Próximo.
- Na próxima página, escolha Próximo.
- Revise os detalhes na página final e selecione Reconheço que o AWS CloudFormation pode criar recursos do IAM.
- Escolha Crie.
A criação da pilha deve levar cerca de 5 minutos. A pilha estabelece a configuração da conta do produtor B da seguinte forma:
- Cria um usuário IAM
hmsblog-consumerstewarde define este usuário como administrador do Lake Formation - Cria outro usuário do IAM
hmsblog-analyst - Cria um bucket de data lake do S3 para armazenar os resultados da consulta do Athena, com
ListBuckete escrever permissões de objeto para amboshmsblog-consumerstewardehmsblog-analyst
Anote os detalhes de saída da pilha.

Aceitar compartilhamentos de recursos na conta B
Entre no console como hmsblog-consumersteward e conclua as seguintes etapas:
- No console do AWS CloudFormation, navegue até a pilha Saídas aba.
- Escolha o link para
ConsumerStewardCredentialspara ser redirecionado para o console do Secrets Manager. - No console do Secrets Manager, escolha Recuperar valor secreto e copie a senha para o usuário administrador do consumidor.
- Use o
ConsoleIAMLoginURLvalor do modelo CloudFormation saída para fazer login na conta B com o nome de usuário administrador do consumidorhmsblog-consumerstewarde a senha que você copiou do Secrets Manager. - Abra o console de RAM da AWS em outra guia do navegador.
- No painel de navegação, em Compartilhou comigo, escolha Compartilhamento de recursos para ver os convites pendentes.
Você deve ver dois convites de compartilhamento de recursos da conta A do produtor: um para um compartilhamento no nível do banco de dados e outro para um compartilhamento no nível da tabela.

- Escolha cada link de compartilhamento de recurso, revise os detalhes e escolha ACEITAR.

Depois de aceitar os convites, o status dos compartilhamentos de recursos muda de Pendente para Ativo.
- Abra o console do Lake Formation em outra guia do navegador.
- No painel de navegação, escolha Bases de dados.
Você deve ver o banco de dados compartilhado federated_emrhivedb da conta do produtor A.
- Escolha o banco de dados e escolha Ver tabelas para revisar a lista de tabelas compartilhadas nesse banco de dados.
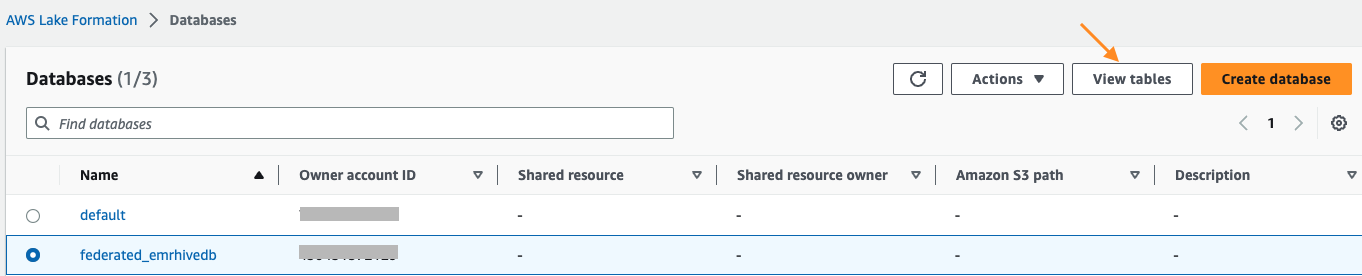
Você deve ver as quatro tabelas do banco de dados Hive que está hospedado no cluster EMR na conta do produtor.

Conceder permissões na conta B
Para conceder permissões na conta B, conclua as etapas a seguir conforme hmsblog-consumersteward:
- No console do Lake Formation, no painel de navegação, escolha Funções e tarefas administrativas.

- Debaixo Criadores de banco de dados, escolha Conceda.
- Escolha Usuários e funções IAM, entrar
hmsblog-consumersteward. - Escolha Permissões de catálogo, selecione Criar banco de dados.
- Escolha Conceda.

Isso permite hmsblog-consumersteward para criar um link de recurso de banco de dados.
- No painel de navegação, escolha Bases de dados.
- Selecionar
federated_emrhivedbe sobre o Opções menu, escolha Criar link de recurso.
- Entrar
rl_federatedhivedbpara Nome do link do recurso e escolha Crie.
- Escolha Bases de dados no painel de navegação.
- Selecione o link do recurso
rl_federatedhivedbe sobre o Opções menu, escolha Conceda. - Escolha
hmsblog-analystpara Usuários e funções IAM.
- Debaixo Permissões de links de recursos, selecione Descrever, Em seguida, escolha Conceda.

- Selecionar Bases de dados no painel de navegação.
- Selecione o link do recurso
rl_federatedhivedbe sobre o Opções menu, escolha Conceder no alvo. - Escolha
hmsblog-analystpara Usuários e funções IAM. - Escolha
hms_productcategoryehms_supplierpara Tabelas.
- Escolha Permissões de mesa, selecione Selecionar e Descrever, Em seguida, escolha Conceda.

- No painel de navegação, escolha Permissões do data lake e revise as permissões concedidas a
hms-analyst.
Consultar o banco de dados Apache Hive do produtor do consumidor Athena
Conclua as seguintes etapas:
- No console do Athena, navegue até o editor de consultas.
- Escolha Editar Configurações para configurar os resultados da consulta do Athena compensados.

- Navegue e escolha o balde S3
hmsblog-athenaresults-<your-account-B>-us-west-2que o modelo CloudFormation criou. - Escolha Salvar.

hmsblog-consumersteward tem acesso a todas as quatro tabelas em federated_emrhivedb da conta do produtor.
- No editor de consultas do Athena, escolha o banco de dados
rl_federatedhivedbe execute uma consulta em qualquer uma das tabelas.
Você conseguiu consultar um banco de dados metastore Apache Hive externo da conta do produtor por meio do Catálogo de dados do AWS Glue e das permissões do Lake Formation usando o Athena da conta do consumidor destinatário.
- Saia do console como
hmsblog-consumerstewarde faça login novamente comohmsblog-analyst. - Use o mesmo método explicado anteriormente para obter as credenciais de login da pilha do CloudFormation Saídas aba.
hmsblog-analyst tem permissões de Descrever no link de recurso e acesso a duas das quatro tabelas do Hive. Você pode verificar se os vê no Bases de dados e Tabelas páginas no console do Lake Formation.


No console do Athena, agora você configura o depósito de resultados de consulta do Athena, semelhante a como você o configurou como hmsblog-consumersteward.
- No editor de consultas, escolha Editar Configurações.
- Navegue e escolha o balde S3
hmsblog-athenaresults-<your-account-B>-us-west-2que o modelo CloudFormation criou. - Escolha Salvar.
- No editor de consultas do Athena, escolha o banco de dados
rl_federatedhivedbe execute uma consulta nas duas tabelas.
- Saia do console como
hmsblog-analyst.
Você foi capaz de restringir o compartilhamento das tabelas metastore externas do Apache Hive usando as permissões do Lake Formation de uma conta para outra e consultá-las usando o Athena. Você também pode consultar as tabelas Hive usando Redshift Spectrum, Amazon EMR e AWS Glue ETL da conta do consumidor.
limpar
Para evitar cobranças nos recursos da AWS criados nesta postagem, você pode executar as etapas a seguir.
Limpar recursos na conta A
Há duas pilhas do CloudFormation associadas à conta do produtor A. Você precisa excluir as dependências e as duas pilhas na ordem correta.
- Faça login como usuário administrador na conta de produtor B.
- No console do Lake Formation, escolha Permissões do data lake no painel de navegação.
- Escolha Conceda.
- Conceda permissões Drop para sua função ou usuário em
federated_emrhivedb.
- No painel de navegação, escolha Bases de dados.
- Selecionar
federated_emrhivedbe sobre o Opções menu, escolha Apagar para excluir o banco de dados federado que está associado à conexão do metastore do Hive.
Isso torna a pilha do CloudFormation da conexão do AWS Glue pronta para ser excluída.

- No painel de navegação, escolha Funções e tarefas administrativas.
- Debaixo Criadores de banco de dados, selecione Revogar e remover
hmsblog-producerstewardpermissões. - No console do CloudFormation, exclua a pilha chamada
serverlessrepo-GlueDataCatalogFederation-HiveMetastoreem primeiro lugar.
Este é aquele criado por seu aplicativo AWS SAM para a conexão do metastore do Hive. Aguarde até que ele conclua a exclusão.
- Exclua a pilha do CloudFormation que você criou para a configuração da conta do produtor.
Isso exclui os buckets S3, o cluster EMR, as funções e políticas personalizadas do IAM e os LF-Tags, banco de dados, tabelas e permissões.
Limpar recursos na conta B
Conclua as etapas a seguir na conta B:
- Revogar permissão para
hmsblog-consumerstewardcomo criador do banco de dados, semelhante às etapas da seção anterior. - Exclua a pilha do CloudFormation que você criou para a configuração da conta do consumidor.
Isso exclui os usuários do IAM, o bucket do S3 e todas as permissões do Lake Formation.
Se houver links de recursos e permissões restantes, exclua-os manualmente no Lake Formation de ambas as contas.
Conclusão
Nesta postagem, mostramos como iniciar o aplicativo de federação de metastore do AWS Glue Hive no AWS Serverless Application Repository, configurá-lo com um metastore Hive em execução em um cluster EMR, criar um banco de dados federado no Catálogo de dados do AWS Glue e mapeá-lo para um banco de dados metastore Hive no cluster EMR. Ilustramos como compartilhar e acessar as tabelas do banco de dados Hive para um cenário entre contas e os benefícios de usar o Lake Formation para restringir permissões.
Todos os recursos do Lake Formation, como compartilhamento com entidades IAM dentro da mesma conta, compartilhamento com contas externas, compartilhamento com entidades IAM de contas externas, restrição de acesso a colunas e configuração de filtros de dados, funcionam em bancos de dados e tabelas Hive federados. Você pode usar qualquer um dos serviços de análise da AWS integrados ao Lake Formation, como Athena, Redshift Spectrum, AWS Glue ETL e Amazon EMR para consultar o banco de dados e as tabelas federadas do Hive.
Incentivamos você a verificar os recursos do conector de federação de metastore do AWS Glue Hive e explorar as permissões do Lake Formation em seu banco de dados e tabelas Hive. Comente esta postagem ou fale com sua equipe de contas da AWS para compartilhar comentários sobre esse recurso.
Para mais detalhes, consulte Gerenciando permissões em conjuntos de dados que usam metastores externos.
Sobre os autores
 Aarthi Srinivasan é arquiteto sênior de Big Data na AWS Lake Formation. Ela gosta de criar soluções de data lake para clientes e parceiros da AWS. Quando não está no teclado, ela explora as últimas tendências de ciência e tecnologia e passa o tempo com sua família.
Aarthi Srinivasan é arquiteto sênior de Big Data na AWS Lake Formation. Ela gosta de criar soluções de data lake para clientes e parceiros da AWS. Quando não está no teclado, ela explora as últimas tendências de ciência e tecnologia e passa o tempo com sua família.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/query-your-apache-hive-metastore-with-aws-lake-formation-permissions/
- :tem
- :é
- :não
- :onde
- $UP
- 10
- 100
- 11
- 13
- 19
- 27
- 31
- 32
- 7
- 8
- 9
- a
- Capaz
- Sobre
- ACEITAR
- Acesso
- acessível
- Conta
- Contas
- reconhecer
- real
- Adicional
- admin
- administradores
- Depois de
- Todos os Produtos
- permite
- tb
- Apesar
- Amazon
- Amazon EMR
- Amazon RDS
- Amazon Web Services
- an
- analista
- analítica
- e
- Outro
- qualquer
- apache
- Apache Spark
- Aplicação
- aplicações
- Aplicar
- Aplicativos
- arquitetura
- SOMOS
- AS
- Jurídico
- associado
- disponível
- evitar
- AWS
- Formação da Nuvem AWS
- Cola AWS
- Formação AWS Lake
- b
- em caminho duplo
- Apoiado
- Barra
- BE
- sido
- Benefícios
- Grande
- Big Data
- software de big data
- ambos
- navegador
- Prédio
- construído
- by
- chamado
- CAN
- casas
- casos
- catálogo
- Alterações
- acusações
- verificar
- Escolha
- Agrupar
- código
- Coluna
- COM
- como
- comentar
- completar
- componentes
- Computar
- Configuração
- configurado
- Contato
- da conexão
- consiste
- cônsul
- consumidor
- continua
- ao controle
- correta
- corretamente
- poderia
- crio
- criado
- cria
- criação
- criador
- Credenciais
- crítico
- personalizadas
- Clientes
- dados,
- analista de dados
- lago data
- informática
- data warehouse
- banco de dados
- conjuntos de dados
- Padrão
- demonstrar
- implantar
- descreve
- detalhes
- Ecrã
- distribuído
- não
- down
- download
- Cair
- cada
- Mais cedo
- editor
- encorajar
- Motor
- Entrar
- estabelece
- Éter (ETH)
- exemplo
- explicado
- explorar
- explora
- expressões
- externo
- extrato
- família
- Característica
- Funcionalidades
- Federação
- retornos
- Envie o
- filtros
- final
- Primeiro nome
- flexível
- seguir
- seguinte
- segue
- Escolha
- treinamento
- quatro
- da
- função
- ter
- dá
- conceder
- concedido
- subsídios
- Grupo
- tinha
- Hadoop
- Ter
- ter
- sua experiência
- altamente
- Colméia
- hospedeiro
- hospedado
- anfitriões
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- http
- HTTPS
- enorme
- IAM
- ID
- ilustra
- importante
- in
- incluir
- INFORMAÇÕES
- integrar
- integrado
- integração
- para dentro
- convida
- IT
- ESTÁ
- jpg
- apenas por
- Guarda
- Chave
- lago
- mais recente
- lançamento
- lançado
- Deixar
- esquerda
- Legado
- como
- gostos
- LINK
- Links
- Lista
- carregar
- local
- localização
- log
- registrado
- entrar
- FAZ
- gerencia
- de grupos
- Gerente
- gestão
- manualmente
- muitos
- mapa,
- mapeamento
- correspondido
- Menu
- metadados
- método
- poder
- migrado
- minutos
- mais
- nome
- Nomeado
- nomes
- Navegar
- Navegação
- você merece...
- Cria
- Novo
- recentemente
- Próximo
- nó
- nota
- notado
- agora
- número
- objeto
- of
- on
- ONE
- só
- aberto
- open source
- or
- ordem
- organizações
- Outros
- Fora
- saída
- página
- páginas
- pão
- parte
- Parceiros
- Senha
- pendente
- realizar
- permissão
- permissões
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- por favor
- ponto
- políticas
- Publique
- anterior
- anteriormente
- primário
- diretores
- em processamento
- produtor
- fornecer
- fornece
- público
- consultas
- RAM
- pronto
- região
- registrado
- remover
- repositório
- recurso
- Recursos
- DESCANSO
- restringir
- restringindo
- Resultados
- rever
- Tipo
- papéis
- Execute
- corrida
- é executado
- Sam
- mesmo
- cenário
- Ciência
- Ciência e Tecnologia
- Pesquisar
- Segredo
- Seção
- segurança
- Vejo
- vê
- selecionado
- senior
- Serverless
- Serviços
- conjunto
- Conjuntos
- contexto
- instalação
- Partilhar
- compartilhado
- ações
- compartilhando
- ela
- rede de apoio social
- mostrou
- Shows
- assinar
- semelhante
- simples
- Software
- solução
- Soluções
- Faísca
- Espectro
- SQL
- pilha
- Pilhas
- Status
- Passos
- armazenamento
- loja
- lojas
- estruturada
- sub-rede
- tal
- ajuda
- .
- mesa
- Tire
- toma
- Converse
- Profissionais
- Tecnologia
- modelo
- que
- A
- a segurança
- deles
- Eles
- então
- Lá.
- assim sendo
- Este
- deles
- isto
- Através da
- tempo
- para
- topo
- Transformar
- Tendências
- tutorial
- dois
- para
- subjacente
- usar
- caso de uso
- usava
- Utilizador
- usuários
- utilização
- valor
- Valores
- vário
- verificar
- Ver
- volumes
- esperar
- Armazém
- foi
- we
- web
- serviços web
- foram
- quando
- QUEM
- precisarão
- de
- dentro
- Atividades:
- trabalho
- escrever
- yaml
- Você
- investimentos
- zefirnet