Os modelos de aprendizado de máquina tornaram-se um componente integral da tomada de decisões em vários setores, mas muitas vezes encontram dificuldades ao lidar com conjuntos de dados diversos ou barulhentos. É aí que o Ensemble Learning entra em jogo.
Este artigo irá desmistificar a aprendizagem em conjunto e apresentar seu poderoso algoritmo de floresta aleatória. Não importa se você é um cientista de dados em busca de aprimorar seu kit de ferramentas ou um desenvolvedor em busca de insights práticos para construir modelos robustos de aprendizado de máquina, este artigo é destinado a todos!
Ao final deste artigo, você obterá um conhecimento profundo do Ensemble Learning e de como funcionam as Florestas Aleatórias em Python. Portanto, seja você um cientista de dados experiente ou simplesmente curioso para expandir suas habilidades de aprendizado de máquina, junte-se a nós nesta aventura e aprimore seus conhecimentos em aprendizado de máquina!
O aprendizado conjunto é uma abordagem de aprendizado de máquina na qual as previsões de vários modelos fracos são combinadas entre si para obter previsões mais fortes. O conceito por trás da aprendizagem em conjunto é diminuir o viés e os erros de modelos únicos, aproveitando o poder preditivo de cada modelo.
Para ter um exemplo melhor vamos dar um exemplo de vida imagine que você viu um animal e não sabe a que espécie esse animal pertence. Então, em vez de perguntar a um especialista, você pergunta a dez especialistas e receberá o voto da maioria deles. Isso é conhecido como votação difícil.
Votação difícil é quando levamos em consideração as previsões de classe para cada classificador e então classificamos uma entrada com base no máximo de votos para uma classe específica. Por outro lado, votação suave é quando levamos em consideração as previsões de probabilidade para cada classe por cada classificador e, em seguida, classificamos uma entrada para a classe com probabilidade máxima com base na probabilidade média (média das probabilidades do classificador) para essa classe.
O aprendizado conjunto é sempre usado para melhorar o desempenho do modelo, o que inclui melhorar a precisão da classificação e diminuir o erro médio absoluto para modelos de regressão. Além desse conjunto, os alunos sempre produzem um modelo mais estável. Os alunos do Ensemble trabalham melhor quando os modelos não estão correlacionados, então cada modelo pode aprender algo único e trabalhar para melhorar o desempenho geral.
Embora a aprendizagem em conjunto possa ser aplicada de várias maneiras, quando se trata de aplicá-la na prática, existem três estratégias que ganharam muita popularidade devido à sua fácil implementação e uso. Essas três estratégias são:
- Bagging: Bagging, abreviação de agregação de bootstrap, é uma estratégia de aprendizado conjunto na qual os modelos são treinados usando amostras aleatórias do conjunto de dados.
- Empilhamento: Stacking, abreviação de generalização empilhada, é uma estratégia de aprendizado conjunto na qual treinamos um modelo para combinar vários modelos treinados em nossos dados.
- Impulsionar: Boosting é uma técnica de aprendizado conjunto que se concentra na seleção de dados classificados incorretamente para treinar os modelos.
Vamos nos aprofundar em cada uma dessas estratégias e ver como podemos usar Python para treinar esses modelos em nosso conjunto de dados.
O ensacamento coleta amostras aleatórias de dados e usa algoritmos de aprendizagem e a média para encontrar probabilidades de ensacamento; também conhecido como agregação de bootstrap; agrega resultados de vários modelos para obter um resultado amplo.
Essa abordagem envolve:
- Divisão do conjunto de dados original em vários subconjuntos com substituição.
- Desenvolva modelos básicos para cada um desses subconjuntos.
- Executar todos os modelos simultaneamente antes de executar todas as previsões para obter as previsões finais.
Scikit-learn nos fornece a capacidade de implementar tanto um Classificador de ensacamento e BaggingRegressor. Um BaggingMetaEstimator identifica subconjuntos aleatórios de um conjunto de dados original para ajustar cada modelo base e, em seguida, agrega previsões individuais do modelo base? -? por meio de votação ou média? -? em uma previsão final, agregando previsões individuais do modelo base em uma previsão agregada usando votação ou média . Este método reduz a variância ao randomizar seu processo de construção.
Vejamos um exemplo em que usamos o estimador de ensacamento usando o scikit learn:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
O classificador de ensacamento leva em consideração vários parâmetros:
- estimador_base: O modelo básico usado na abordagem de ensacamento. Aqui usamos o classificador de árvore de decisão.
- n_estimadores: O número de estimadores que usaremos na abordagem de ensacamento.
- max_samples: O número de amostras que serão extraídas do conjunto de treinamento para cada estimador base.
- max_features: O número de recursos que serão usados para treinar cada estimador base.
Agora vamos encaixar esse classificador no conjunto de treinamento e pontuá-lo.
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
Podemos fazer o mesmo para tarefas de regressão, a diferença é que em vez disso usaremos estimadores de regressão.
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)O empilhamento é uma técnica para combinar vários estimadores, a fim de minimizar seus vieses e produzir previsões precisas. As previsões de cada estimador são então combinadas e alimentadas em um metamodelo de previsão final treinado por meio de validação cruzada; o empilhamento pode ser aplicado a problemas de classificação e regressão.
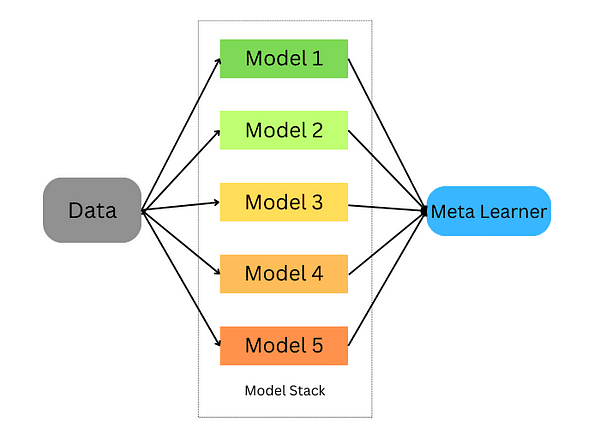
Empilhamento de aprendizagem de conjunto
O empilhamento ocorre nas seguintes etapas:
- Divida os dados em um conjunto de treinamento e validação
- Divida o conjunto de treinamento em K dobras
- Treine um modelo básico em k-1 dobras e faça previsões na k-ésima dobra
- Repita até ter uma previsão para cada dobra
- Ajustar o modelo base em todo o conjunto de treinamento
- Use o modelo para fazer previsões no conjunto de testes
- Repita as etapas 3 a 6 para outros modelos básicos
- Use previsões do conjunto de testes como recursos de um novo modelo (o metamodelo)
- Faça previsões finais no conjunto de testes usando o metamodelo
Neste exemplo abaixo, começamos criando dois classificadores base (RandomForestClassifier e GradientBoostingClassifier) e um metaclassificador (LogisticRegression) e usamos validação cruzada K-fold para usar previsões desses classificadores em dados de treinamento (conjunto de dados iris) para recursos de entrada para nosso metaclassificador (LogisticRegression).
Depois de usar a validação cruzada K-fold para fazer previsões dos classificadores básicos em conjuntos de dados de teste como recursos de entrada para nosso metaclassificador, predições em conjuntos de teste usando ambos os conjuntos juntos e avaliam sua precisão em relação às contrapartes do conjunto empilhado.
# Load the dataset
data = load_iris()
X, y = data.data, data.target # Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Define base classifiers
base_classifiers = [ RandomForestClassifier(n_estimators=100, random_state=42), GradientBoostingClassifier(n_estimators=100, random_state=42)
] # Define a meta-classifier
meta_classifier = LogisticRegression() # Create an array to hold the predictions from base classifiers
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers))) # Perform stacking using K-fold cross-validation
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train): train_fold, val_fold = X_train[train_index], X_train[val_index] train_target, val_target = y_train[train_index], y_train[val_index] for i, clf in enumerate(base_classifiers): cloned_clf = clone(clf) cloned_clf.fit(train_fold, train_target) base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold) # Train the meta-classifier on base classifier predictions
meta_classifier.fit(base_classifier_predictions, y_train) # Make predictions using the stacked ensemble
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers): stacked_predictions[:, i] = clf.predict(X_test) # Make final predictions using the meta-classifier
final_predictions = meta_classifier.predict(stacked_predictions) # Evaluate the stacked ensemble's performance
accuracy = accuracy_score(y_test, final_predictions)
print(f"Stacked Ensemble Accuracy: {accuracy:.2f}")Boosting é uma técnica de conjunto de aprendizado de máquina que reduz preconceitos e variações, transformando alunos fracos em alunos fortes. Esses alunos fracos são aplicados sequencialmente ao conjunto de dados; primeiro criando um modelo inicial e ajustando-o ao conjunto de treinamento. Uma vez identificados os erros do primeiro modelo, outro modelo é projetado para corrigi-los.
Existem algoritmos e implementações populares para impulsionar técnicas de aprendizagem em conjunto. Vamos explorar os mais famosos.
6.1. AdaBoost
AdaBoost é uma técnica eficaz de aprendizagem em conjunto, que emprega alunos fracos sequencialmente para fins de treinamento. Cada iteração prioriza previsões incorretas enquanto diminui o peso atribuído a instâncias previstas corretamente; esta ênfase estratégica em observações desafiadoras obriga o AdaBoost a se tornar cada vez mais preciso ao longo do tempo, com sua previsão final determinada pela agregação de votos majoritários ou pela soma ponderada de seus alunos fracos.
AdaBoost é um algoritmo versátil adequado para tarefas de regressão e classificação, mas aqui nos concentramos em sua aplicação a problemas de classificação usando o Scikit-learn. Vejamos como podemos usá-lo para tarefas de classificação no exemplo abaixo:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
Neste exemplo, usamos o AdaBoostClassifier do scikit learn e definimos n_estimators como 100. O aprendizado padrão é uma árvore de decisão e você pode alterá-la. Além disso, os parâmetros da árvore de decisão podem ser ajustados.
2. Aumento extremo de gradiente (XGBoost)
eXtreme Gradient Boosting ou é mais popularmente conhecido como XGBoost, é uma das melhores implementações para impulsionar alunos em conjunto devido aos seus cálculos paralelos, o que o torna muito otimizado para execução em um único computador. O XGBoost está disponível para uso por meio do pacote xgboost desenvolvido pela comunidade de aprendizado de máquina.
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)3. LightGBM
LightGBM é outro algoritmo de aumento de gradiente baseado no aprendizado de árvore. No entanto, é diferente de outros algoritmos baseados em árvore, pois usa o crescimento da árvore em termos de folhas, o que faz com que convirja mais rapidamente.

Crescimento da árvore em termos de folhas / Imagem de Light GBM
No exemplo abaixo aplicaremos LightGBM a um problema de classificação binária:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt', 'objective': 'binary', 'num_leaves': 40, 'learning_rate': 0.1, 'feature_fraction': 0.9 }
gbm = lgb.train(params, lgb_train, num_boost_round=200, valid_sets=[lgb_train, lgb_eval], valid_names=['train','valid'], )
O aprendizado conjunto e as florestas aleatórias são modelos poderosos de aprendizado de máquina que são sempre usados por profissionais de aprendizado de máquina e cientistas de dados. Neste artigo, abordamos a intuição básica por trás deles, quando usá-los e, por fim, abordamos seus algoritmos mais populares e como usá-los em Python.
Youssef Rafael é um pesquisador de visão computacional e cientista de dados. Sua pesquisa se concentra no desenvolvimento de algoritmos de visão computacional em tempo real para aplicações de saúde. Ele também trabalhou como cientista de dados por mais de 3 anos nos domínios de marketing, finanças e saúde.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://www.kdnuggets.com/ensemble-learning-techniques-a-walkthrough-with-random-forests-in-python?utm_source=rss&utm_medium=rss&utm_campaign=ensemble-learning-techniques-a-walkthrough-with-random-forests-in-python
- :é
- :não
- :onde
- 1
- 10
- 100
- 12
- 16
- 24
- 40
- 9
- a
- habilidades
- habilidade
- absoluto
- Conta
- precisão
- preciso
- em
- Adição
- avançar
- Aventura
- contra
- agregar
- agregação
- algoritmo
- algoritmos
- Todos os Produtos
- alfa
- tb
- sempre
- an
- e
- animal
- Outro
- Aplicação
- aplicações
- aplicado
- Aplicar
- Aplicando
- abordagem
- SOMOS
- Ordem
- artigo
- AS
- perguntar
- pergunta
- atribuído
- At
- disponível
- média
- média
- base
- baseado
- basic
- BE
- tornam-se
- sido
- antes
- começar
- atrás
- pertence
- abaixo
- MELHOR
- Melhor
- viés
- vieses
- impulsionar
- Bootstrap
- ambos
- amplo
- Prédio
- mas a
- by
- CAN
- desafiante
- alterar
- classe
- classificação
- classificar
- CLF
- combinar
- combinado
- combinando
- vem
- comunidade
- componente
- cálculos
- computador
- Visão de Computador
- conceito
- consideração
- formação
- Convergem
- correta
- corretamente
- correlacionados
- coberto
- crio
- Criar
- curioso
- dados,
- cientista de dados
- conjunto de dados
- conjuntos de dados
- lidar
- decisão
- Tomada de Decisão
- árvore de decisão
- mais profunda
- Padrão
- definir
- Desmistificar
- projetado
- determinado
- desenvolvido
- Developer
- em desenvolvimento
- diferença
- Dificuldade
- mergulho
- diferente
- do
- domínio
- desenhado
- dois
- cada
- fácil
- Eficaz
- ou
- ênfase
- emprega
- encontro
- final
- erro
- erros
- Éter (ETH)
- avaliar
- Cada
- exemplo
- Expandir
- experiente
- especialista
- especialistas
- explorar
- extremo
- famoso
- mais rápido
- Funcionalidades
- Alimentado
- final
- Finalmente
- financiar
- Encontre
- Primeiro nome
- em primeiro lugar
- caber
- apropriado
- Foco
- concentra-se
- dobras
- seguinte
- Escolha
- floresta
- da
- Ganho
- ganhou
- ter
- Growth
- mão
- Ter
- he
- saúde
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- sua
- segurar
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- HTTPS
- i
- identificado
- identifica
- if
- imagem
- fotografia
- executar
- implementação
- implementações
- importar
- melhorar
- melhorar
- in
- inclui
- cada vez mais
- Individual
- indústrias
- do estado inicial,
- entrada
- insights
- em vez disso
- integral
- para dentro
- introduzir
- intuição
- envolve
- IT
- iteração
- ESTÁ
- juntar
- Faça parte
- KDnuggetsGenericName
- Saber
- Conhecimento
- conhecido
- APRENDER
- aprendizagem
- deixar
- aproveitando
- vida
- carregar
- olhar
- procurando
- lote
- máquina
- aprendizado de máquina
- Maioria
- fazer
- FAZ
- muitos
- Marketing
- Importância
- máximo
- significar
- significava
- Meta
- método
- minimizar
- modelo
- modelos
- mais
- a maioria
- Mais populares
- múltiplo
- Novo
- não
- número
- objetivo
- observações
- obter
- of
- frequentemente
- on
- uma vez
- ONE
- queridos
- otimizado
- or
- ordem
- original
- Outros
- A Nossa
- Resultado
- Acima de
- global
- pacote
- Paralelo
- parâmetros
- particular
- realizar
- atuação
- peça
- platão
- Inteligência de Dados Platão
- PlatãoData
- Jogar
- Popular
- popularidade
- poder
- poderoso
- Prática
- prática
- previsto
- predição
- Previsões
- preditivo
- prioriza
- probabilidade
- Problema
- problemas
- processo
- produzir
- fornece
- fins
- Python
- acaso
- em tempo real
- reduz
- regressão
- substituição
- pesquisa
- investigador
- Resultados
- uma conta de despesas robusta
- Execute
- corrida
- s
- mesmo
- Cientista
- cientistas
- scikit-learn
- Ponto
- Vejo
- visto
- selecionando
- conjunto
- Conjuntos
- vários
- Baixo
- simplesmente
- solteiro
- So
- algo
- divisão
- estável
- empilhado
- empilhamento
- Passos
- Estratégico
- estratégias
- Estratégia
- mais forte,
- mais forte
- adequado
- Tire
- toma
- Target
- tarefas
- técnicas
- dez
- teste
- ensaio
- do que
- que
- A
- deles
- Eles
- então
- Lá.
- Este
- deles
- isto
- três
- Através da
- tempo
- para
- juntos
- kit de ferramentas
- Trem
- treinado
- Training
- árvore
- Passando
- dois
- final
- único
- ao contrário
- até
- us
- Uso
- usar
- usava
- usos
- utilização
- validação
- versátil
- muito
- visão
- Voto
- votos
- Votação
- Passo a passo
- maneiras
- we
- peso
- O Quê
- quando
- se
- qual
- enquanto
- inteiro
- precisarão
- de
- Atividades:
- trabalhou
- X
- XGBoostName
- anos
- ainda
- Produção
- Você
- investimentos
- zefirnet