Cada organização tem seu próprio conjunto de padrões e práticas que fornecem segurança e governança para seu ambiente da AWS. Amazon Sage Maker é um serviço totalmente gerenciado para preparar dados e criar, treinar e implantar modelos de aprendizado de máquina (ML) para qualquer caso de uso com infraestrutura, ferramentas e fluxos de trabalho totalmente gerenciados. O SageMaker fornece um conjunto de modelos para organizações que desejam começar rapidamente com fluxos de trabalho de ML e pipelines de integração contínua e entrega contínua (CI/CD) DevOps.
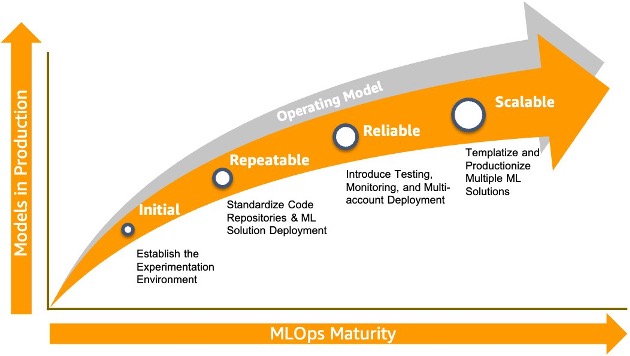
A maioria dos clientes corporativos já tem uma prática de MLOps bem estabelecida com um ambiente padronizado – por exemplo, um repositório padronizado, infraestrutura e proteções de segurança – e deseja estender seu processo de MLOps para ferramentas AutoML sem código e com pouco código também. Eles também têm muitos processos que precisam ser cumpridos antes de promover um modelo para produção. Eles estão procurando uma maneira rápida e fácil de passar da fase inicial para uma fase operacional repetível, confiável e eventualmente escalável, conforme descrito no diagrama a seguir. Para mais informações, consulte Roteiro básico de MLOps para empresas com o Amazon SageMaker.
Embora essas empresas tenham equipes robustas de ciência de dados e MLOps para ajudá-las a criar pipelines confiáveis e escaláveis, elas desejam que os usuários da ferramenta AutoML de baixo código produzam artefatos de código e modelo de maneira que possam ser integrados às suas práticas padronizadas, aderindo às suas estrutura de repositório de código e com validações, testes, etapas e aprovações apropriadas.
Eles estão procurando um mecanismo para as ferramentas de baixo código gerarem todo o código-fonte para cada etapa das tarefas do AutoML (pré-processamento, treinamento e pós-processamento) em uma estrutura de repositório padronizada que possa fornecer a seus cientistas de dados especializados a capacidade de visualizar , validar e modificar o fluxo de trabalho de acordo com suas necessidades e, em seguida, gerar um modelo de pipeline personalizado que pode ser integrado a um ambiente padronizado (onde eles definiram seu repositório de código, ferramentas de criação de código e processos).
Este post mostra como ter um processo repetível com ferramentas de baixo código como Piloto automático do Amazon SageMaker de modo que possa ser perfeitamente integrado ao seu ambiente, para que você não precise orquestrar esse fluxo de trabalho de ponta a ponta por conta própria. Demonstramos como usar CI/CD o código de ferramentas low-code/no-code para integrá-lo ao seu ambiente MLOps, ao mesmo tempo em que aderimos às práticas recomendadas de MLOps.
Visão geral da solução
Para demonstrar o fluxo de trabalho orquestrado, usamos o disponível publicamente Conjunto de dados de renda do censo de adultos da UCI de 1994 para prever se uma pessoa tem uma renda anual superior a $ 50,000 por ano. Este é um problema de classificação binária; as opções para a variável de meta de renda são acima de US$ 50,000 ou abaixo de US$ 50,000.
A tabela a seguir resume os principais componentes do conjunto de dados.
| Características do conjunto de dados | Multivariada | Número de Instâncias | 48842 | Área | Redes Sociais |
| Características do atributo: | Categórico, Inteiro | Número de atributos: | 14 | Data de doação | 1996-05-01 |
| Tarefas associadas: | Classificação | Valores ausentes? | Sim | Número de acessos à Web | 2749715 |
A tabela a seguir resume as informações do atributo.
| Nome da coluna | Descrição |
| Idade | Contínuo |
| Classe de trabalho | Privado, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Sem remuneração, Nunca trabalhou |
| fnlwgt | contínuo |
| educação | Bacharelado, alguma faculdade, 11º, HS-grad, Prof-escola, Assoc-acdm, Assoc-voc, 9º, 7º-8º, 12º, Mestrado, 1º-4º, 10º, Doutorado, 5º-6º, Pré-escola. |
| educação-num | contínuo |
| Estado civil | Casado-cônjuge, Divorciado, Nunca casado, Separado, Viúvo, Casado-cônjuge-ausente, Casado-AF-cônjuge. |
| ocupação | ech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protetora, Forças Armadas |
| relacionamento | Esposa, Filho próprio, Marido, Fora da família, Outro parente, Solteiro. |
| raça | Branco, Asiático-Pac-Ilhéu, Amer-Indian-Eskimo, Outro, Preto |
| sexo | Feminino, Masculino |
| Ganho de capital | Contínuo |
| perda de capital | Contínuo |
| horas por semana | Contínuo |
| país nativo | Estados Unidos, Camboja, Inglaterra, Porto Rico, Canadá, Alemanha, Outlying-US (Guam-USVI-etc), Índia, Japão, Grécia, Sul, China, Cuba, Irã, Honduras, Filipinas, Itália, Polônia, Jamaica , Vietnã, México, Portugal, Irlanda, França, República Dominicana, Laos, Equador, Taiwan, Haiti, Colômbia, Hungria, Guatemala, Nicarágua, Escócia, Tailândia, Iugoslávia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holanda-Holanda . |
| classe | Classe de renda, <=50K ou >=50K |
Nesta postagem, mostramos como usar o Amazon SageMaker Projects, uma ferramenta que ajuda as organizações a configurar e padronizar ambientes para MLOps com ferramentas de AutoML de baixo código, como Autopilot e Gerenciador de dados do Amazon SageMaker.
O piloto automático elimina o trabalho pesado de construir modelos de ML. Você simplesmente fornece um conjunto de dados tabulares e seleciona a coluna de destino para prever, e o Autopilot explora automaticamente diferentes soluções para encontrar o melhor modelo. Em seguida, você pode implantar o modelo diretamente na produção com apenas um clique ou iterar nas soluções recomendadas para melhorar ainda mais a qualidade do modelo.
O Data Wrangler fornece uma solução completa para importar, preparar, transformar, caracterizar e analisar dados. Você pode integrar um fluxo de preparação de dados do Data Wrangler em seus fluxos de trabalho de ML para simplificar e agilizar o pré-processamento de dados e a engenharia de recursos usando pouca ou nenhuma codificação. Você também pode adicionar seus próprios scripts e transformações Python para personalizar fluxos de trabalho. Usamos o Data Wrangler para realizar o pré-processamento no conjunto de dados antes de enviar os dados ao piloto automático.
O SageMaker Projects ajuda as organizações a configurar e padronizar ambientes para automatizar diferentes etapas envolvidas em um ciclo de vida de ML. Embora os notebooks sejam úteis para a construção e experimentação de modelos, uma equipe de cientistas de dados e engenheiros de ML que compartilham código precisa de uma maneira mais escalável de manter a consistência do código e o controle de versão rígido.
Para ajudá-lo a começar com os paradigmas comuns de construção e implantação de modelos, o SageMaker Projects oferece um conjunto de modelos primários (modelos 1P). Os modelos 1P geralmente se concentram na criação de recursos para construção e treinamento de modelos. Os modelos incluem projetos que usam serviços nativos da AWS para CI/CD, como AWS CodeBuild e AWS Code Pipeline. Os Projetos SageMaker podem oferecer suporte a ofertas de modelos personalizados, em que as organizações usam um Formação da Nuvem AWS modelo para executar uma pilha do Terraform e criar os recursos necessários para um fluxo de trabalho de ML.
As organizações podem querer estender os modelos 1P para oferecer suporte a casos de uso além do simples treinamento e implantação de modelos. Modelos de projetos personalizados são uma maneira de criar um fluxo de trabalho padrão para projetos de ML. Você pode criar vários modelos e usar Gerenciamento de acesso e identidade da AWS (IAM) políticas para gerenciar o acesso a esses modelos em Estúdio Amazon SageMaker, garantindo que cada um de seus usuários acesse projetos dedicados para seus casos de uso.
Para saber mais sobre projetos do SageMaker e como criar modelos de projeto personalizados alinhados com as práticas recomendadas, consulte Crie modelos de projeto SageMaker personalizados - práticas recomendadas.
Esses modelos personalizados são criados como Catálogo de serviços da AWS produtos e provisionados como modelos de organização na interface do usuário do Studio. É aqui que os cientistas de dados podem escolher um modelo e ter seu fluxo de trabalho de ML inicializado e pré-configurado. Os projetos são provisionados usando produtos do AWS Service Catalog. Os modelos de projeto são usados pelas organizações para provisionar projetos para cada uma de suas equipes.
Nesta postagem, mostramos como criar um modelo de projeto personalizado para ter um fluxo de trabalho MLOps de ponta a ponta usando projetos SageMaker, AWS Service Catalog e Pipelines Amazon SageMaker integrando Data Wrangler e Autopilot com humanos no loop para facilitar as etapas de treinamento e implantação do modelo. Os humanos no loop são as diferentes pessoas envolvidas em uma prática de MLOps trabalhando de forma colaborativa para um fluxo de trabalho bem-sucedido de criação e implantação de ML.
O diagrama a seguir ilustra o fluxo de trabalho de automação de código baixo/sem código de ponta a ponta.

O fluxo de trabalho inclui as seguintes etapas:
- A equipe de operações ou a equipe de plataforma inicia o modelo CloudFormation para configurar os pré-requisitos necessários para provisionar o modelo SageMaker personalizado.
- Quando o modelo está disponível no SageMaker, o Data Science Lead usa o modelo para criar um projeto SageMaker.
- A criação do projeto SageMaker iniciará um produto AWS Service Catalog que adiciona dois códigos iniciais ao AWS CodeCommit repositórios:
- O código inicial para o pipeline de construção de modelo inclui um pipeline que pré-processa o Conjunto de dados UCI Machine Learning Adulto usando o Data Wrangler, cria automaticamente um modelo de ML com visibilidade total usando o Autopilot, avalia o desempenho de um modelo usando uma etapa de processamento e registra o modelo em um registro de modelo com base no desempenho do modelo.
- O código inicial para a implantação do modelo inclui uma etapa CodeBuild para encontrar o modelo mais recente que foi aprovado no registro do modelo e criar arquivos de configuração para implantar os modelos do CloudFormation como parte dos pipelines de CI/CD usando o CodePipeline. O modelo do CloudFormation implanta o modelo em ambientes de preparação e produção.
- A primeira confirmação do código inicial inicia um pipeline CI/CD usando CodePipeline que aciona um pipeline SageMaker, que é uma série de etapas interconectadas codificadas usando um gráfico acíclico direcionado (DAG). Neste caso, as etapas envolvidas são informática usando um fluxo do Data Wrangler, treinando o modelo usando o piloto automático, criando o modelo, avaliando o modelo, e se a avaliação for aprovada, registrando o modelo.
Para obter mais detalhes sobre como criar pipelines do SageMaker usando o piloto automático, consulte Inicie experimentos do Amazon SageMaker Autopilot diretamente de dentro do Amazon SageMaker Pipelines para automatizar facilmente fluxos de trabalho de MLOps.
- Depois que o modelo é registrado, o aprovador do modelo pode aprovar ou rejeitar o modelo no Studio.
- Quando o modelo é aprovado, um pipeline de implantação do CodePipeline integrado ao segundo código inicial é acionado.
- Esse pipeline cria um endpoint escalonável sem servidor do SageMaker para o ambiente de preparação.
- Há uma etapa de teste automatizada no pipeline de implantação que será testada no endpoint de preparo.
- Os resultados do teste são armazenados em Serviço de armazenamento simples da Amazon (Amazônia S3). O pipeline será interrompido para um aprovador de implantação de produção, que pode revisar todos os artefatos antes da aprovação.
- Depois de aprovado, o modelo é implantado na produção na forma de endpoint sem servidor escalável. Os aplicativos de produção agora podem consumir o endpoint para inferência.
As etapas de implantação consistem no seguinte:
- Crie o modelo de projeto personalizado do SageMaker para Autopilot e outros recursos usando o AWS CloudFormation. Esta é uma tarefa de configuração única.
- Crie o projeto SageMaker usando o modelo personalizado.
Nas seções a seguir, procedemos com cada uma dessas etapas com mais detalhes e exploramos a página de detalhes do projeto.
Pré-requisitos
Este passo a passo inclui os seguintes pré-requisitos:
Crie recursos de solução com o AWS CloudFormation
Você pode baixar e iniciar o Modelo CloudFormation por meio do console do AWS CloudFormation, o Interface de linha de comando da AWS (AWS CLI), o SDK ou simplesmente escolhendo Pilha de Lançamento:
![]()
O modelo CloudFormation também está disponível no Repositório de código GitHub de amostras da AWS. O repositório contém o seguinte:
- A Modelo CloudFormation para configurar o modelo de projeto SageMaker personalizado para piloto automático
- código semente com o código ML para configurar os pipelines do SageMaker para automatizar o processamento de dados e as etapas de treinamento
- A pasta de projeto para o modelo CloudFormation usado pelo AWS Service Catalog mapeado para o modelo de projeto SageMaker personalizado que será criado
O modelo CloudFormation usa vários parâmetros como entrada.
A seguir estão os parâmetros de informações do produto do AWS Service Catalog:
- Nome do Produto – O nome do produto AWS Service Catalog ao qual o modelo MLOps personalizado do projeto SageMaker será associado
- Descrição do Produto – A descrição do produto AWS Service Catalog
- Product Owner – O proprietário do produto Catálogo de Serviços
- Distribuidor de produtos – O distribuidor do produto Catálogo de Serviços
A seguir estão os parâmetros de informações de suporte do produto AWS Service Catalog:
- Descrição do suporte do produto – Uma descrição de suporte para este produto
- E-mail de suporte do produto – Um endereço de e-mail da equipe que oferece suporte ao produto AWS Service Catalog
- URL de suporte do produto – Um URL de suporte para o produto AWS Service Catalog
A seguir estão os parâmetros de configuração do repositório de código-fonte:
- URL para a versão compactada do seu repositório GitHub – Use os padrões se você não estiver bifurcando o repositório AWS Samples.
- Nome e ramificação do seu repositório GitHub – Devem corresponder à pasta raiz do zip. Use os padrões se você não estiver bifurcando o repositório AWS Samples.
- StudioUserExecutionRole – Forneça o ARN da função IAM de execução do usuário do Studio.
Depois de iniciar a pilha do CloudFormation a partir desse modelo, você pode monitorar seu status no console do AWS CloudFormation.
Quando a pilha estiver completa, copie o valor do CodeStagingBucketName chave no Saídas tab da pilha do CloudFormation e salve-o em um editor de texto para uso posterior.

Crie o projeto SageMaker usando o novo modelo personalizado
Para criar seu projeto SageMaker, conclua as seguintes etapas:
- Faça login no Studio. Para mais informações, veja Integrado ao domínio do Amazon SageMaker.
- Na barra lateral do Studio, escolha o ícone inicial.
- Escolha implantações no menu e, em seguida, escolha Projectos.
- Escolha Criar projeto.
- Escolha Modelos de organização para visualizar o novo modelo MLOps personalizado.
- Escolha Selecione o modelo do projeto.

- Escolha Detalhes do Projeto, insira um nome e uma descrição para seu projeto.
- Escolha MLOpsS3Bucket, insira o nome do bucket do S3 que você salvou anteriormente.

- Escolha Criar projeto.
Uma mensagem é exibida indicando que o SageMaker está provisionando e configurando os recursos.

Quando o projeto for concluído, você receberá uma mensagem de sucesso e seu projeto será listado no Projectos Lista.
Explorar os detalhes do projeto
Na página de detalhes do projeto, você pode visualizar várias guias associadas ao projeto. Vamos nos aprofundar em cada uma dessas guias em detalhes.
Repositórios
Esta guia lista os repositórios de código associados a este projeto. Você pode escolher clonar repositório para Caminho local para clonar os dois repositórios de código inicial criados no CodeCommit pelo projeto SageMaker. Esta opção fornece acesso Git aos repositórios de código do próprio projeto SageMaker.

Quando a clonagem do repositório estiver concluída, o caminho local aparecerá no Caminho local coluna. Você pode escolher o caminho para abrir a pasta local que contém o código do repositório no Studio.

A pasta estará acessível no painel de navegação. Você pode usar o ícone do navegador de arquivos para ocultar ou mostrar a lista de pastas. Você pode fazer as alterações de código aqui ou escolher o ícone do Git para preparar, confirmar e enviar a alteração.

Dutos
Esta guia lista os pipelines do SageMaker ML que definem etapas para preparar dados, treinar modelos e implantar modelos. Para obter informações sobre os pipelines do SageMaker ML, consulte Criar e gerenciar pipelines do SageMaker.
Você pode escolher o pipeline que está em execução no momento para ver seu status mais recente. No exemplo a seguir, a etapa DataProcessing é executada usando um fluxo de dados do Data Wrangler.

Você pode acessar o fluxo de dados do caminho local do repositório de código que clonamos anteriormente. Escolha o ícone do navegador de arquivos para mostrar o caminho, que está listado no pipelines pasta do repositório de construção do modelo.

No pipelines pasta, abra a pasta do piloto automático.

No autopilot pasta, abra o preprocess.flow arquivo.

Levará um momento para abrir o fluxo do Data Wrangler.
Neste exemplo, três transformações de dados são executadas entre a origem e o destino. Você pode escolher cada transformação para ver mais detalhes.

Para obter instruções sobre como incluir ou remover transformações no Data Wrangler, consulte Transformar dados.
Para mais informações, consulte Preparação unificada de dados e treinamento de modelo com Amazon SageMaker Data Wrangler e Amazon SageMaker Autopilot – Parte 1.
Quando terminar de revisar, escolha o ícone de energia e interrompa os recursos do Data Wrangler em Aplicativos de corrida e Sessões do kernel.

Experimentos
Esta guia lista os experimentos do piloto automático associados ao projeto. Para obter mais informações sobre o piloto automático, consulte Automatize o desenvolvimento de modelos com o Amazon SageMaker Autopilot.
Grupos modelo
Esta guia lista grupos de versões de modelo que foram criados por execuções de pipeline no projeto. Quando a execução do pipeline estiver concluída, o modelo criado na última etapa do pipeline estará acessível aqui.

Você pode escolher o grupo de modelos para acessar a versão mais recente do modelo.

O status da versão do modelo no exemplo a seguir é Pendente. Você pode escolher a versão do modelo e escolher Atualizar o status para atualizar o estado.

Escolha aprovado e escolha Atualizar o status para aprovar o modelo.

Depois que o status do modelo for aprovado, o pipeline de CI/CD de implantação do modelo no CodePipeline será iniciado.

Você pode abrir o pipeline implantado para ver os diferentes estágios no repositório.


Conforme mostrado na captura de tela anterior, esse pipeline tem quatro estágios:
- fonte – Nesse estágio, o CodePipeline verifica o código do repositório do CodeCommit no bucket S3.
- Construa – Nesta etapa, os modelos do CloudFormation são preparados para a implantação do código do modelo.
- ImplantarStaging – Esta etapa é composta por três subetapas:
- ImplantarRecursosStaging – No primeiro subestágio, a pilha do CloudFormation é implantada para criar um endpoint SageMaker sem servidor no ambiente de encenação.
- TesteStaging – No segundo subestágio, o teste automatizado é realizado usando o CodeBuild no endpoint para verificar se a inferência está ocorrendo conforme o esperado. Os resultados do teste estarão disponíveis no bucket S3 com o nome
sagemaker-project-<project ID of the SageMaker project>.
Você pode obter o ID do projeto SageMaker no Configurações guia do projeto SageMaker. Dentro do bucket S3, escolha a pasta do nome do projeto (por exemplo, sagemaker-MLOp-AutoP) e dentro dela, abra a pasta TestArtifa/. Escolha o arquivo objeto nesta pasta para ver os resultados do teste.

Você pode acessar o script de teste a partir do caminho local do repositório de código que clonamos anteriormente. Escolha o ícone do navegador de arquivos para visualizar o caminho. Observe que este será o repositório de implantação. Nesse repositório, abra a pasta de teste e escolha o test.py Arquivo de código Python.

Você pode fazer alterações neste código de teste de acordo com seu caso de uso.
- Aprovar Implantação – Na terceira subetapa, há um processo de aprovação adicional antes da última etapa de implantação em produção. Você pode escolher Avaliações e aprová-lo para prosseguir.

- ImplantarProd – Neste estágio, a pilha do CloudFormation é implantada para criar um endpoint SageMaker sem servidor para o ambiente de produção.
Pontos finais
Esta guia lista os endpoints do SageMaker que hospedam modelos implantados para inferência. Quando todos os estágios do pipeline de implantação do modelo estiverem concluídos, os modelos serão implantados nos endpoints do SageMaker e poderão ser acessados no projeto do SageMaker.

Configurações
Esta é a última guia na página do projeto e lista as configurações do projeto. Isso inclui o nome e a descrição do projeto, informações sobre o modelo do projeto e SourceModelPackageGroupName, e metadados sobre o projeto.
limpar
Para evitar custos adicionais de infraestrutura associados ao exemplo desta postagem, certifique-se de excluir as pilhas do CloudFormation. Além disso, certifique-se de excluir os endpoints do SageMaker, todos os notebooks em execução e os buckets do S3 que foram criados durante a configuração.
Conclusão
Esta postagem descreveu uma abordagem de pipeline de ML fácil de usar para automatizar e padronizar o treinamento e a implantação de modelos de ML usando projetos SageMaker, Data Wrangler, piloto automático, pipelines e Studio. Esta solução pode ajudá-lo a executar tarefas do AutoML (pré-processamento, treinamento e pós-processamento) em uma estrutura de repositório padronizada que pode fornecer a seus cientistas de dados especializados a capacidade de visualizar, validar e modificar o fluxo de trabalho de acordo com suas necessidades e, em seguida, gerar um pipeline personalizado modelo que pode ser integrado a um projeto SageMaker.
Você pode modificar os pipelines com suas etapas de pré-processamento e pipeline para seu caso de uso e implantar nosso fluxo de trabalho de ponta a ponta. Deixe-nos saber nos comentários como o modelo personalizado funcionou para seu respectivo caso de uso.
Sobre os autores
 Vishal Naik é Arquiteto de Soluções Sênior na Amazon Web Services (AWS). Ele é um construtor que gosta de ajudar os clientes a atender suas necessidades de negócios e resolver desafios complexos com soluções e práticas recomendadas da AWS. Sua principal área de foco inclui Machine Learning, DevOps e Containers. Em seu tempo livre, Vishal adora fazer curtas-metragens sobre viagens no tempo e temas de universos alternativos.
Vishal Naik é Arquiteto de Soluções Sênior na Amazon Web Services (AWS). Ele é um construtor que gosta de ajudar os clientes a atender suas necessidades de negócios e resolver desafios complexos com soluções e práticas recomendadas da AWS. Sua principal área de foco inclui Machine Learning, DevOps e Containers. Em seu tempo livre, Vishal adora fazer curtas-metragens sobre viagens no tempo e temas de universos alternativos.
 Shikhar Kwatra é um arquiteto de soluções especializado em IA/ML da Amazon Web Services, que trabalha com um integrador de sistemas global líder. Ele ganhou o título de um dos mais jovens mestres inventores indianos com mais de 500 patentes nos domínios AI/ML e IoT. Shikhar auxilia na arquitetura, construção e manutenção de ambientes de nuvem escaláveis e econômicos para a organização e oferece suporte ao parceiro GSI na criação de soluções estratégicas do setor na AWS. Shikhar gosta de tocar violão, compor música e praticar mindfulness em seu tempo livre.
Shikhar Kwatra é um arquiteto de soluções especializado em IA/ML da Amazon Web Services, que trabalha com um integrador de sistemas global líder. Ele ganhou o título de um dos mais jovens mestres inventores indianos com mais de 500 patentes nos domínios AI/ML e IoT. Shikhar auxilia na arquitetura, construção e manutenção de ambientes de nuvem escaláveis e econômicos para a organização e oferece suporte ao parceiro GSI na criação de soluções estratégicas do setor na AWS. Shikhar gosta de tocar violão, compor música e praticar mindfulness em seu tempo livre.
 Janisha Anand é gerente de produto sênior da equipe SageMaker Low/No Code ML, que inclui o SageMaker Canvas e o SageMaker Autopilot. Ela gosta de café, de se manter ativa e de passar tempo com a família.
Janisha Anand é gerente de produto sênior da equipe SageMaker Low/No Code ML, que inclui o SageMaker Canvas e o SageMaker Autopilot. Ela gosta de café, de se manter ativa e de passar tempo com a família.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- EVM Finanças. Interface unificada para finanças descentralizadas. Acesse aqui.
- Grupo de Mídia Quântica. IR/PR Amplificado. Acesse aqui.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/bring-sagemaker-autopilot-into-your-mlops-processes-using-a-custom-sagemaker-project/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 10
- 100
- sec 10
- 12
- 17
- 1994
- 214
- 220
- 30
- 500
- 7
- 9
- sec 9
- a
- Sobre
- Acesso
- acessível
- acessando
- realizar
- ativo
- acíclico
- adicionar
- Adicional
- endereço
- Adiciona
- Adulto
- AI / ML
- SIDA
- alinhado
- Todos os Produtos
- já
- tb
- Apesar
- Amazon
- Amazon Sage Maker
- Piloto automático do Amazon SageMaker
- Gerenciador de dados do Amazon SageMaker
- Pipelines Amazon SageMaker
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- analisar
- e
- anual
- qualquer
- aplicações
- abordagem
- apropriado
- aprovação
- aprovações
- aprovar
- aprovou
- SOMOS
- ÁREA
- AS
- associado
- At
- atributos
- automatizar
- Automatizado
- automaticamente
- automatizando
- Automação
- AutoML
- piloto automático
- disponível
- evitar
- AWS
- Formação da Nuvem AWS
- baseado
- BE
- sido
- antes
- MELHOR
- melhores práticas
- entre
- Pós
- Ramo
- trazer
- navegador
- construir
- construtor
- Prédio
- negócio
- by
- Cambodja
- CAN
- Pode obter
- Localização: Canadá
- lona
- casas
- casos
- catálogo
- Censo
- desafios
- alterar
- Alterações
- características
- verificar
- Cheques
- China
- Escolha
- escolha
- classe
- classificação
- clique
- Na nuvem
- código
- códigos
- Codificação
- Café
- Columbia
- Coluna
- comentários
- commit
- comum
- Empresas
- completar
- integrações
- componentes
- Configuração
- consiste
- cônsul
- consumir
- Containers
- contém
- contínuo
- ao controle
- núcleo
- custos
- crio
- criado
- cria
- Criar
- criação
- Cuba
- Atualmente
- personalizadas
- Clientes
- personalizar
- DAG
- dados,
- Preparação de dados
- informática
- ciência de dados
- dedicado
- profundo
- defaults
- definido
- Entrega
- demonstrar
- implantar
- implantado
- Implantação
- desenvolvimento
- implanta
- descrito
- descrição
- destino
- detalhe
- detalhes
- Desenvolvimento
- DevOps
- diferente
- dirigido
- diretamente
- domínios
- feito
- não
- download
- durante
- cada
- Mais cedo
- ganhou
- facilmente
- fácil
- fácil de usar
- Equador
- editor
- ou
- elimina
- end-to-end
- Ponto final
- endpoints
- Engenharia
- Engenheiros
- Inglaterra
- garantir
- assegurando
- Entrar
- Empreendimento
- clientes corporativos
- empresas
- Meio Ambiente
- ambientes
- Éter (ETH)
- avaliação
- avaliação
- eventualmente
- exemplo
- execução
- esperado
- experimentos
- especialista
- explorar
- estender
- facilitar
- família
- Característica
- Envie o
- Arquivos
- filmes
- Encontre
- Primeiro nome
- fluxo
- Foco
- seguinte
- Escolha
- Bifurcação
- formulário
- Foundation
- quatro
- França
- da
- cheio
- totalmente
- mais distante
- geralmente
- gerar
- Alemanha
- ter
- Git
- GitHub
- Global
- governo
- pós-graduação
- gráfico
- maior
- Grécia
- Grupo
- Do grupo
- Guatemala
- Acontecimento
- Ter
- he
- pesado
- levantamento pesado
- ajudar
- útil
- ajuda
- ajuda
- sua experiência
- SUA PARTICIPAÇÃO FAZ A DIFERENÇA
- Esconder
- sua
- Início
- HONDURAS
- Hong
- hospedeiro
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- Humanos
- Hungria
- IAM
- ÍCONE
- ICS
- ID
- Identidade
- if
- ilustra
- importar
- melhorar
- in
- incluir
- inclui
- Passiva
- Índia
- indiano
- indicador
- indústria
- INFORMAÇÕES
- Infraestrutura
- do estado inicial,
- entrada
- instruções
- integrar
- integrado
- Integração
- integração
- interconectado
- para dentro
- Inventores
- envolvido
- iot
- Irão
- Irlanda
- IT
- Itália
- ESTÁ
- se
- Jamaica
- Japão
- jpg
- apenas por
- apenas um
- Chave
- Saber
- Sobrenome
- mais tarde
- mais recente
- lançamento
- lança
- conduzir
- principal
- APRENDER
- aprendizagem
- wifecycwe
- facelift
- como
- Line
- Lista
- Listado
- listas
- pequeno
- local
- procurando
- lote
- ama
- máquina
- aprendizado de máquina
- a manter
- manutenção
- Maioria
- fazer
- Fazendo
- gerencia
- gerenciados
- Gerente
- maneira
- dominar
- Match
- Posso..
- mecanismo
- Menu
- mensagem
- metadados
- México
- Mindfulness
- ML
- MLOps
- modelo
- modelos
- modificar
- momento
- Monitore
- mais
- Música
- nome
- Navegação
- você merece...
- necessário
- Cria
- Novo
- não
- nota
- laptops
- agora
- objeto
- of
- Ofertas
- Oferece
- on
- ONE
- aberto
- operando
- Opção
- Opções
- or
- orquestrada
- ordem
- organização
- organizações
- Outros
- A Nossa
- delineado
- Acima de
- próprio
- proprietário
- página
- pão
- parâmetros
- parte
- parceiro
- passou
- Patentes
- caminho
- realizar
- atuação
- realizada
- pessoa
- Peru
- fase
- Filipinas
- oleoduto
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- Polônia
- políticas
- Portugal
- Publique
- poder
- prática
- práticas
- predizer
- preparação
- Preparar
- preparado
- pré-requisitos
- Problema
- processo
- processos
- em processamento
- produzir
- Produto
- informações do produto
- gerente de produto
- Produção
- Produtos
- projeto
- Detalhes do Projeto
- projetos
- Promoção
- fornecer
- fornece
- provisão
- publicamente
- Empurrar
- Python
- qualidade
- Links
- rapidamente
- receber
- Recomenda
- registrado
- registradores
- registro
- confiável
- remover
- Repetivel
- repositório
- requeridos
- Recursos
- aqueles
- Resultados
- rever
- revendo
- roadmap
- uma conta de despesas robusta
- Tipo
- raiz
- Execute
- corrida
- é executado
- sábio
- Pipelines SageMaker
- vendas
- Salvar
- escalável
- Ciência
- cientistas
- Escócia
- Scripts
- Sdk
- sem problemas
- Segundo
- seções
- segurança
- Vejo
- semente
- senior
- Série
- Serverless
- serviço
- Serviços
- conjunto
- Configurações
- instalação
- vários
- compartilhando
- ela
- Baixo
- rede de apoio social
- mostrar
- mostrar
- mostrando
- simples
- simplificar
- simplesmente
- So
- solução
- Soluções
- RESOLVER
- fonte
- código fonte
- Sul
- especialista
- Passar
- pilha
- Pilhas
- Etapa
- Estágio
- encenação
- padrão
- padrões
- começo
- começado
- começa
- Status
- Passo
- Passos
- Dê um basta
- armazenamento
- armazenadas
- Estratégico
- simplificar
- rigoroso
- estrutura
- estudo
- sucesso
- bem sucedido
- tal
- ajuda
- Apoiar
- suportes
- certo
- .
- mesa
- Taiwan
- Tire
- toma
- Target
- Tarefa
- tarefas
- Profissionais
- equipes
- modelo
- modelos
- Terraform
- teste
- testado
- ensaio
- testes
- ประเทศไทย
- do que
- que
- A
- A fonte
- deles
- Eles
- então
- Lá.
- Este
- deles
- Terceiro
- isto
- aqueles
- três
- tempo
- viagem no tempo
- Título
- para
- Tobago
- ferramenta
- ferramentas
- Trem
- Training
- Transformar
- Transformação
- transformações
- viagens
- desencadeado
- dois
- ui
- para
- Universo
- Atualizar
- URL
- us
- usar
- caso de uso
- usava
- Utilizador
- usuários
- usos
- utilização
- VALIDAR
- valor
- Valores
- vário
- versão
- controle de versão
- via
- Vietnã
- Ver
- Vishal
- visibilidade
- Passo a passo
- queremos
- Caminho..
- we
- web
- serviços web
- BEM
- foram
- quando
- qual
- enquanto
- QUEM
- precisarão
- de
- dentro
- trabalhou
- de gestão de documentos
- fluxos de trabalho
- trabalhar
- yaml
- ano
- Você
- Mais jovem
- investimentos
- zefirnet
- Zip